指数增强策略
目录
指数增强策略
1. 策略原理
2. 策略步骤
3. 策略代码
4. 回测结果和稳健性分析
1. 策略原理
说到指数增强,就不得不说指数。
在进行股票投资时,有一种分类方式是将投资分为主动型投资和被动型投资。被动型投资是指完全复制指数,跟随指数的投资方式。与被动型投资相反,主动型投资是根据投资者的知识结合经验进行主动选股,不是被动跟随指数。主动型投资者期望获得超越市场的收益,被动型投资者满足于市场平均收益率水平。
指数增强是指在跟踪指数的基础上,采用一些判断基准,将不看好的股票权重调低或平仓,将看好的股票加大仓位,以提高收益率的方法。
既然如此,我已经判断出来哪只是“好股票”,哪只是“一般”的股票,为什么不直接买入?而是要买入指数呢?
指数增强不同于其他主动投资方式,除了注重获取超越市场的收益,还要兼顾降低组合风险,注重收益的稳定性。如果判断失误,只买入选中股票而非指数会导致投资者承受巨大亏损。
怎样选择股票?
和alpha对冲策略类似,指数增强仅仅是一个思路,怎样选择“好股”还需投资者结合自身经验判断。
本策略利用“动量”这一概念,认为过去5天连续上涨的股票具备继续上涨的潜力,属于强势股;过去5天连续下跌的股票未来会继续下跌,属于弱势股。
2. 策略步骤
第一步:选择跟踪指数,以权重大于0.35%的成分股为股票池。
第二步:根据个股价格动量来判断是否属于优质股,即连续上涨5天则为优势股;间隔连续下跌5天则为劣质股。
第三步:将优质股权重调高0.2,劣质股权重调低0.2。
回测时间:2017-07-01 08:00:00 到 2017-10-01 16:00:00
回测选股股票池:沪深300成分股
回测初始资金:1000万
3. 策略代码
# coding=utf-8
from __future__ import print_function, absolute_import, unicode_literals
import numpy as np
from gm.api import *
from pandas import DataFrame
'''
本策略以0.8为初始权重跟踪指数标的沪深300中权重大于0.35%的成份股.
个股所占的百分比为(0.8*成份股权重)*100%.然后根据个股是否:
1.连续上涨5天 2.连续下跌5天
来判定个股是否为强势股/弱势股,并对其把权重由0.8调至1.0或0.6
回测时间为:2017-07-01 08:50:00到2017-10-01 17:00:00
'''
def init(context):
# 资产配置的初始权重,配比为0.6-0.8-1.0
context.ratio = 0.8
# 获取沪深300当时的成份股和相关数据
stock300 = get_history_constituents(index='SHSE.000300', start_date='2017-06-30', end_date='2017-06-30')[0][
'constituents']
stock300_symbol = []
stock300_weight = []
for key in stock300:
# 保留权重大于0.35%的成份股
if (stock300[key] / 100) > 0.0035:
stock300_symbol.append(key)
stock300_weight.append(stock300[key] / 100)
context.stock300 = DataFrame([stock300_weight], columns=stock300_symbol, index=['weight']).T
print('选择的成分股权重总和为: ', np.sum(stock300_weight))
subscribe(symbols=stock300_symbol, frequency='1d', count=5, wait_group=True)
def on_bar(context, bars):
# 若没有仓位则按照初始权重开仓
for bar in bars:
symbol = bar['symbol']
position = context.account().position(symbol=symbol, side=PositionSide_Long)
if not position:
buy_percent = context.stock300['weight'][symbol] * context.ratio
order_target_percent(symbol=symbol, percent=buy_percent, order_type=OrderType_Market,
position_side=PositionSide_Long)
print(symbol, '以市价单开多仓至仓位:', buy_percent)
else:
# 获取过去5天的价格数据,若连续上涨则为强势股,权重+0.2;若连续下跌则为弱势股,权重-0.2
recent_data = context.data(symbol=symbol, frequency='1d', count=5, fields='close')['close'].tolist()
if all(np.diff(recent_data) > 0):
buy_percent = context.stock300['weight'][symbol] * (context.ratio + 0.2)
order_target_percent(symbol=symbol, percent=buy_percent, order_type=OrderType_Market,
position_side=PositionSide_Long)
print('强势股', symbol, '以市价单调多仓至仓位:', buy_percent)
elif all(np.diff(recent_data) < 0):
buy_percent = context.stock300['weight'][symbol] * (context.ratio - 0.2)
order_target_percent(symbol=symbol, percent=buy_percent, order_type=OrderType_Market,
position_side=PositionSide_Long)
print('弱势股', symbol, '以市价单调多仓至仓位:', buy_percent)
if __name__ == '__main__':
'''
strategy_id策略ID,由系统生成
filename文件名,请与本文件名保持一致
mode实时模式:MODE_LIVE回测模式:MODE_BACKTEST
token绑定计算机的ID,可在系统设置-密钥管理中生成
backtest_start_time回测开始时间
backtest_end_time回测结束时间
backtest_adjust股票复权方式不复权:ADJUST_NONE前复权:ADJUST_PREV后复权:ADJUST_POST
backtest_initial_cash回测初始资金
backtest_commission_ratio回测佣金比例
backtest_slippage_ratio回测滑点比例
'''
run(strategy_id='strategy_id',
filename='main.py',
mode=MODE_BACKTEST,
token='token_id',
backtest_start_time='2017-07-01 08:00:00',
backtest_end_time='2017-10-01 16:00:00',
backtest_adjust=ADJUST_PREV,
backtest_initial_cash=10000000,
backtest_commission_ratio=0.0001,
backtest_slippage_ratio=0.0001)
4. 回测结果和稳健性分析
设定初始资金1000万,手续费率为0.01%,滑点比率为0.01%。回测结果如下图所示。回测期结果如下图所示:

回测期累计收益率为2.76%,年化收益率为11.34%,沪深300指数收益率为5.09%,整体跑输指数。最大回撤为1.88%,胜率为74.62%。
为了探究策略的稳健性,改变回测期,策略表现如下表所示。
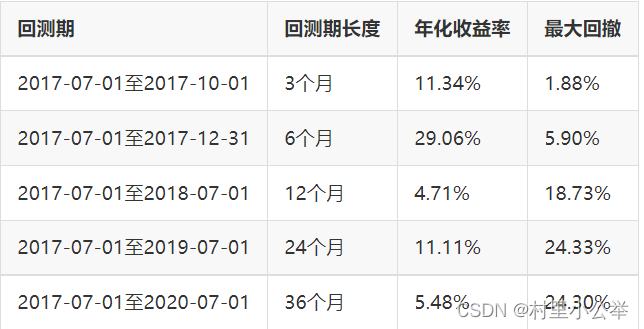
由上表可知,改变策略回测周期长度,策略收益率均为正,但都处于较低水平(除了2017年7月1日至2018年7月1日收益率达到29.06%)。随着策略回测期拉长,最大回撤不断增大。
注:来自掘金量化