目录
匈牙利算法(Hungarian method Edmonds)
例题1 有完美匹配
例题2 无完美匹配
代码实现
变量及函数说明
测试数据1
测试结果1
测试数据2
测试结果
匈牙利算法(Hungarian method Edmonds)
以任意一个匹配M作为开始。(可取M=∅。)
①若M已饱和X的每个顶点,停止(M为完美匹配)。否则,取X中M-不饱和顶点u,今:S<-{u},T=∅。
②若N(S)=T,则停止,算法结束(无完美匹配);否则N(S)⊃T,转到下一步。
③取y∈N(S)\T,若y为M-饱和的,设yz∈M,则令S=S∪(z),T=T∪{y},转步骤②;否则,y为M-不饱和的,存在M-可扩路P,令M=M△E(P),转到步骤①。
M-饱和的:边uv∈M,则称点u与v为M-饱和的。
M-不饱和的:与点w相关联的所有边都不属于M,则称点m为M-不饱和的。
N(S):点集S的邻集,图中所有与S中的点相邻接的顶点的集合。
M-交错路:p是G的一条通路,如果p中的边为属于M中的边与不属于M但属于G中的边交替出现,则称p是一条M-交错路。
M-可扩路(增广路)P:属于M的边和不属于M的边(即已匹配和待匹配的边)在P上交替出现,起点与终点都是M-不饱和的。
E(P): M-可扩路(增广路)P的边的集合。
M△E(P)=(M∪E(P))\(M∩E(P))
由可扩路(增广路)的定义可以推出下述三个结论:
(1)P的路径个数必定为奇数,第一条边和最后一条边都不属于M。
(2)将M和P进行异或操作可以得到一个更大的匹配M,比之前的匹配M多1。
(3)M为G的最大匹配当且仅当不存在M的增广路径。
例题1 有完美匹配
从下图中给定的M={x1y2,x5y4}开始,用匈牙利算法求完美匹配。
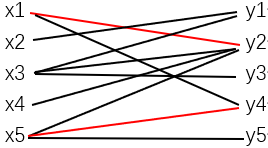 初始图
初始图
1)M没有饱和X的每个顶点,取X中M-不饱和的顶点x3,令S={x3},T=∅,则N(S)={y1,y2,y3},N(S)⊃T, 取y3∈N(S)\T,y3为M-不饱和的,找到M-可扩路P=x3y3,令M=M△E(P)={ x1y2, x3y3,x5y4}
 添加x3y3
添加x3y3
2)M没有饱和X的每个顶点,取X中M-不饱和的顶点x2,令S={x2},T=∅,则N(S)={y1},N(S)⊃T, 取y1∈N(S)\T,y1为M-不饱和的,找到M-可扩路P=x2y1,令M=M△E(P)={ x1y2,x2y1,x3y3,x5y4}
 添加x2y1
添加x2y1
3)M没有饱和X的每个顶点,取X中M-不饱和的顶点x4,令S={x4},T=∅,则N(S)={y2}, N(S)⊃T, 取y2∈N(S)\T,y2为M-饱和的,且y2x1∈M(y2x1=x1y2),令S=S∪{x1}={x1, x4},T=T∪{y2}={y2}。
N(S)={y2,y4}, N(S)⊃T, 取y4∈N(S)\T,y4为M-饱和的,且y4x5∈M(y4x5=x5y4),令S=S∪{x5}={x1, x4,x5},T=T∪{y4}={y2,y4}。
N(S)={y2,y4,y5}, N(S)⊃T, 取y5∈N(S)\T,y5为M-不饱和的,找到M-可扩路P=x4y2x1y4x5y5,令M=M△E(P)={ x1y2,x2y1,x3y3,x5y4}△{x4y2,y2x1,x1y4,y4x5,x5y5}={ x1y4, x2y1,x3y3,x4y2,x5y5},M包含X的每个顶点,停止。
(可扩路的寻找,可以倒推,y5是由于x5引入的,x5是由于y4引入的,y4是由于x1引入的,x1是由于y2引入的,y2是由于刚开始取的x4)
 添加x5y5,x1y4,x4y2,去除x1y2,x5y4
添加x5y5,x1y4,x4y2,去除x1y2,x5y4
注意:在考试中手写时,不必从与x相连的y中遍历,例如1)并没有选择x3y1,因为很明显x2只连接了y1。当然,你接下来看代码实现时,就没有手写这么简单了,手写时你已经对深搜进行了部分剪枝,请耐心看代码。
手算验证:M为空,x4仅与y2相连,M={x4y2};x2仅与y1相连M={x2y1,x4y2};x3与y1、y2、y3相连,y1与y2已是M-饱和的,x3仅能与y3匹配,M={x2y1,x3y3,x4y2 };x1与y2、y4相连,y2已是M-饱和的,x1仅能与y4匹配,M={x1y4, x2y1,x3y3,x4y2};仅剩x5与y5,两者是边的两点,匹配即可,故存在完美匹配M={ x1y4, x2y1,x3y3,x4y2,x5y5}。
例题2 无完美匹配
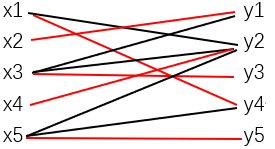
从下图中给定M=∅开始,用匈牙利算法求完美匹配。
 初始图
初始图
1)M没有饱和X的每个顶点,取X中M-不饱和的顶点x1,令S={x1},T=∅,则N(S)={y2,y3},N(S)⊃T, 取y2∈N(S)\T,y2为M-不饱和的,找到M-可扩路P=x1y2,令M=M△E(P)={ x1y2}
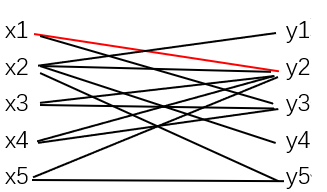 添加x1y2
添加x1y2
2)M没有饱和X的每个顶点,取X中M-不饱和的顶点x2,令S={x2},T=∅,则N(S)={y1,y2,y4,y5},N(S)⊃T, 取y1∈N(S)\T,y1为M-不饱和的,找到M-可扩路P=x2y1,令M=M△E(P)={ x1y2,x2y1}
 添加x2y1
添加x2y1
3)M没有饱和X的每个顶点,取X中M-不饱和的顶点x3,令S={x3},T=∅,则N(S)={y2,y3},N(S)⊃T, 取y3∈N(S)\T,y3为M-不饱和的,找到M-可扩路P=x3y3,令M=M△E(P)={ x1y2,x2y1,x3y3}
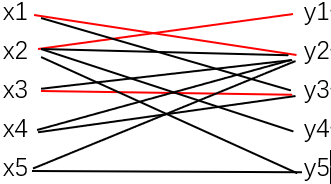 添加x3y3
添加x3y3
M没有饱和X的每个顶点,取X中M-不饱和的顶点x4,令S={x4},T=∅,则N(S)={y2,y3},N(S)⊃T, 取y2∈N(S)\T,y2为M-饱和的,且y2x1∈M(y2x1=x1y2),令S=S∪{x1}={x1, x4},T=T∪{y2}={y2}。
N(S)={ y2,y3}, N(S)⊃T, 取y3∈N(S)\T,y3为M-饱和的,且y3x3∈M(y3x3=x3y3),令S=S∪{x3}={x1, x4,x3},T=T∪{y3}={y2,y3}。
N(S)={y2,y3}=T={y2,y3},结束,没有完美匹配。
注意:手写时可以直接取x1,x3,x4即可,可以看出他们都是连接的y2,y3,两个y没有办法匹配给3个x。
代码实现
通过例子可以看出,S并没有必要,只需要N(S)再原来基础上更新即可,为简化,代码没有加入S。
变量及函数说明
int M[] 初始为 - 1, 下标为X下标,值为匹配的Y集合中的元素下标 ,做对称差时覆盖即可
bool X[Maxnum], Y[Maxnum] 初始为false, 用于判断X, Y集合中元素是否为M饱和的
vector<int> P 可扩路P,初始为空,记录X,Y集合中在P上的元素的下标
set<Vartype> NS, T 对应算法N(S)与T
bool visitedx[Maxnum], visitedy[Maxnum] 每次深搜时标记是否已遍历。
void Init(Graph &G) 初始化函数,参数:图G,功能:初始化图G
void Print(Graph G) 打印图函数,参数:图G,功能:以矩阵形式打印图,可去除
void PrintP(Graph G) 打印路径函数,参数:图G,功能:打印路径P
void PrintM(Graph G) 打印匹配集合M函数,参数:图G,功能:打印匹配集合M
void Delta() 对称差函数,参数:无,功能:M与E(P)做对称差
void DFS(Graph G,bool x,int start) 深度遍历函数(递归形式)参数:图G,X点集,开始结点下标start 作用:深度遍历,找可扩路
/*
Project: Hungarian method Edmonds
Date: 2020/01/02
Author: Frank Yu
void Init(Graph &G) 初始化函数,参数:图G,功能:初始化图G
void Print(Graph G) 打印图函数,参数:图G,功能:以矩阵形式打印图,可去除
void PrintP(Graph G) 打印路径函数,参数:图G,功能:打印路径P
void PrintM(Graph G) 打印匹配集合M函数,参数:图G,功能:打印匹配集合M
void Delta() 对称差函数,参数:无,功能:M与E(P)做对称差
void DFS(Graph G,bool x,int start) 深度遍历函数(递归形式)参数:图G,X点集,开始结点下标start 作用:深度遍历,找可扩路
*/
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<string>
#include<set>
#include<list>
#include<queue>
#include<vector>
#include<map>
#include<stack>
#include<iterator>
#include<algorithm>
#include<iostream>
#define Vartype string //顶点类型
#define EdgeType int
#define Maxnum 100 //二部图点集最大数量
using namespace std;
//图的数据结构
typedef struct Graph
{
Vartype X[Maxnum];
Vartype Y[Maxnum];
EdgeType Edge[Maxnum][Maxnum];//边表
int xnum, ynum,edgenum;//顶点数
}Graph;
//M 下标为X下标,值为匹配的Y集合中的元素下标 初始-1
int M[Maxnum];
//M是否饱和X、Y 饱和为True,不饱和为False
bool X[Maxnum],Y[Maxnum];
//可扩路P
vector<int> P;
//邻接点集合与T集合
set<Vartype> NS, T;
//标记是否已遍历过
bool visitedx[Maxnum], visitedy[Maxnum];
//初始化函数
void Init(Graph &G)
{
memset(G.Edge, 0, sizeof(G.Edge));
cout << "请输入X、Y顶点集个数:" << endl;
cin >> G.xnum >> G.ynum;
Vartype temp;
cout << "请输入X顶点集顶点名称:" << endl;
for (int i = 0; i < G.xnum; i++)
{
cin >> temp;
G.X[i] = temp;
}
//for (int i = 0; i < G.xnum; i++) cout << G.X[i] << '\t' << endl;
cout << "请输入Y顶点集顶点名称:" << endl;
for (int i = 0; i < G.ynum; i++)
{
cin >> temp;
G.Y[i] = temp;
}
//for (int i = 0; i < G.xnum; i++) cout << G.X[i] << '\t' << endl;
cout << "请输入边数:" << endl;
cin >> G.edgenum;
cout << "请输入边,空格分隔(例如: x y):" << endl;
Vartype x, y;
for (int i = 0; i < G.edgenum; i++)
{
cin >> x >> y;
int p1 = -1,p2 = -1;
for (int j = 0; j < G.xnum; j++)
if (!x.compare(G.X[j])) { p1 = j; break; }
for (int k = 0; k < G.ynum; k++)
if (!y.compare(G.Y[k])) { p2 = k; break;}
//cout << p1 << " " << p2;
if (p1 != -1 && p2 != -1)
{
G.Edge[p1][p2] = 1;
}
else
{
cout << "未找到该边,请检查端点是否输入有误!" << endl;
break;
}
}
}
//打印图函数
void Print(Graph G)
{
cout << '\t';
for (int i = 0; i < G.ynum; i++) cout << G.Y[i] << '\t';
cout << endl;
for (int i = 0; i < G.xnum; i++)
{
cout << G.X[i] << '\t';
for (int j = 0; j < G.ynum; j++)cout << G.Edge[i][j]<<'\t';
cout << endl;
}
}
//输出可扩路
void PrintP(Graph G)
{
cout << "P:";
for (int i = 0; i < P.size(); i++)
{
if (i % 2 == 0)cout << G.X[P[i]];
else cout << G.Y[P[i]];
}
cout << endl;
}
//输出集合M
void PrintM(Graph G)
{
bool flag = false;
cout << "M:{";
for (int i = 0; i < G.xnum; i++)
{
if (M[i] != -1 && !flag) { cout << G.X[i] << G.Y[M[i]]; flag = true; }
else if (M[i]!=-1&&flag)cout << ","<< G.X[i] << G.Y[M[i]];
}
cout <<"}"<<endl;
}
//集合M与E(P)做对称差
void Delta()
{
vector<int>::iterator it;
for (it = P.begin(); it != P.end();it++)
{
int x = *it;
it++;
int y = *it;
X[x] = true;
Y[y] = true;
M[x] = y;
}
}
//深度遍历函数(递归形式)参数:图G,X点集开始结点下标start 作用:深度遍历
void DFS(Graph G,bool x,int start)
{
/*
cout << "DFS(";
if (x)cout << "x,";
else cout << "y,";
cout << start << ")" << endl;*/
//X顶点集
if (x)
{
P.push_back(start);
cout << "当前路:" << endl;
PrintP(G);
visitedx[start] = true;
for (int i = 0; i < G.ynum; i++) if (G.Edge[start][i] == 1)NS.insert(G.Y[i]);
if (NS.size() == T.size())
{
cout << "N(S)==T,没有完美匹配" << endl;
system("pause");
}
for (int i = 0; i < G.ynum; i++)
{
//取Y中M - 饱和顶点
if (G.Edge[start][i] == 1 && !visitedy[i] && Y[i])//是邻接点且未访问 M - 饱和顶点Y[i]
{
T.insert(G.Y[i]);
cout << "取Y中M - 饱和顶点" << G.Y[i] << endl;
DFS(G,false,i);//递归深度遍历结点集Y
}
//Y为M - 不饱和顶点 找到可扩路P 与M做对称差
if (G.Edge[start][i] == 1 && !visitedy[i] && !Y[i])
{
cout << G.Y[i]<< "为M - 不饱和顶点,找到可扩路" << endl;
P.push_back(i);
PrintP(G);
Delta();
PrintM(G);
//返回步骤一
for (int i = 0; i < G.xnum; i++)
{
memset(visitedx, false, sizeof(visitedx));
memset(visitedy, false, sizeof(visitedy));
P.clear();
NS.clear();
T.clear();
//取X中M - 不饱和顶点
if (!X[i])DFS(G, true, i);
}
cout << "找到完美匹配";
PrintM(G);
cout << endl;
system("pause");
}
}
P.pop_back();
cout << "返回上一层前的路径:" << endl;
PrintP(G);
return;//返回至上一层
}
else//Y顶点集
{
//cout << G.Y[start];
P.push_back(start);
cout << "当前路:" << endl;
PrintP(G);
visitedy[start] = true;
for (int j = 0; j < G.xnum; j++)
{
if (M[j]==start)//找到Y[start]X[j]属于M
{
cout << "存在"<<G.Y[start]<<G.X[j]<<"属于M" << endl;
DFS(G, true, j);//递归深度遍历结点集X
}
}
P.pop_back();
cout << "返回上一层前的路径:" << endl;
PrintP(G);
return ;//返回至上一层
}
}
//匈牙利算法
int Hungarian(Graph &G)
{
int i;
memset(M, -1, sizeof(M));
cout << "1.输入初始M 2.M从空集开始" << endl;
cout << "请选择:";
cin >> i;
if (1 == i)
{
int num;
cout << "请输入M中边的数量:" << endl;
cin >> num;
cout << "请输入边,空格分隔(例如: x y):" << endl;
Vartype x, y;
for (int i = 0; i < num; i++)
{
cin >> x >> y;
int p1 = -1, p2 = -1;
for (int j = 0; j < G.xnum; j++)
if (!x.compare(G.X[j])) { p1 = j; break; }
for (int k = 0; k < G.ynum; k++)
if (!y.compare(G.Y[k])) { p2 = k; break; }
if (p1 != -1 && p2 != -1)
{
M[p1] = p2;
X[p1] = true;
Y[p2] = true;
}
else
{
cout << "未找到该边,请检查端点是否输入有误!" << endl;
break;
}
}
}
PrintM(G);
//步骤1 判断M是否饱和所有X元素
for (int i = 0; i < G.xnum; i++)
{
memset(visitedx, false, sizeof(visitedx));
memset(visitedy, false, sizeof(visitedy));
P.clear();
NS.clear();
T.clear();
//取X中M - 不饱和顶点
if (!X[i])DFS(G, true, i);
}
cout << "找到完美匹配";
PrintM(G);
cout<< endl;
return 0;
}
//主函数
int main()
{
Graph G;
Init(G);
Print(G);
Hungarian(G);
return 0;
}
以上面两个例题做测试
测试数据1
5 5
x1 x2 x3 x4 x5
y1 y2 y3 y4 y5
10
x1 y2
x1 y4
x2 y1
x3 y1
x3 y2
x3 y3
x4 y2
x5 y2
x5 y4
x5 y5
1 2
x1 y2
x5 y4
测试结果1
 部分结果
部分结果
 部分结果
部分结果
 实际深搜树
实际深搜树
测试数据2
5 5
x1 x2 x3 x4 x5
y1 y2 y3 y4 y5
12
x1 y2
x1 y3
x2 y1
x2 y2
x2 y4
x2 y5
x3 y2
x3 y3
x4 y2
x4 y3
x5 y3
x5 y5
2
测试结果
 部分结果
部分结果
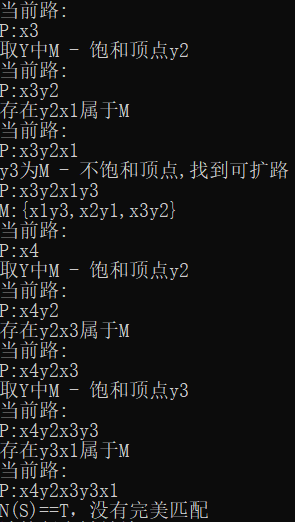 部分结果
部分结果
更多数据结构与算法实现:数据结构(严蔚敏版)与算法的实现(含全部代码)
有问题请下方评论,转载请注明出处,并附有原文链接,谢谢!如有侵权,请及时联系。