作者:wjmishuai
1.引言
本文中介绍的人脸识别系统是基于这两篇论文:
《Very deep convolutional networks for large-scale image recognition》
第一篇论文介绍了海量数据集下的图片检索方法。第二篇文章将这种思想应用到人脸识别系统中,实现基于深度学习的人脸识别。
2.关于深度学习的简要介绍
现阶段为止,
对于图像分类来说,都是使用人工提取特征的方式来提取图像的特征。为了提高识别的准确率,我们首先需要收集大量的数据,然后利用更强大的模型提取特征,并使用更好的算法来防止过拟合。直到最近几年,带有标签的数据集的规模还是很小的。如果识别任务比较简单,利用小规模的数据集完全可以。例如,针对MNIST数据集上的数字识别程序已经
接近人类的识别能力了
,并且错误率<0.3%。但是我们都清楚,实际环境中的物体和实验环境中的物体之间的差异还是比较大的,所以,如果想要识别自然环境中的目标,必须使用更大的训练集。事实上,图片数据集过小的问题已经被广泛认可的,并且得到了解决。比如ImageNet数据集由
22000个类别,
15000000多张带标记的高分辨率图像组成
。
如何从数以百万计的图像中学习成千上万的目标?我们需要一个学习能力较强的模型。然而,由于识别目标的任务有巨大的复杂性,这就意味着这一问题无法仅仅通过指定大型的数据集,比如引入ImageNet是无法解决问题的。因此我们训练的模型必须弥补先验知识中没有的信息。利用卷积神经网络(CNN)构成的模型,通过深度学习较强的学习能力来表达一张图片可以很好的对图片进行分类。
VGG是2014年谷歌公司参与imagenet竞赛的一个模型,对于图像分类的效果很好
。因此我们将这个网络应用到人脸识别中。
3. 人脸识别系统的原理
神经网络提取特征的过程:
一张人脸图片是由基本的edge构成。但是更结构化,更复杂,具有概念性的特征如何表示?这就需要更高层次的特征表示,比如V2,V4。因此V1是像素级特征。V2看V1是像素级的,层次递进,高层表达由低层表达的组合而成。专业点说就是基basis。V1取提出的basis是边缘,然后V2层是V1层这些basis的组合,这时候V2区得到的又是高一层的basis。即上一层的basis组合的结果,上上层又是上一层的组合basis……

直观上说,就是找到make sense的小patch再将其进行combine,就得到了上一层的feature,递归地向上learning feature。
在不同object上做training是,所得的edge basis 是非常相似的,但object parts和models 就会completely different了(那咱们分辨car或者face是不是容易多了):

从文本来说,一个doc表示什么意思?我们描述一件事情,用什么来表示比较合适?用一个一个字嘛,我看不是,字就是像素级别了,起码应该是term,换句话说每个doc都由term构成,但这样表示概念的能力就够了嘛,可能也不够,需要再上一步,达到topic级,有了topic,再到doc就合理。但每个层次的数量差距很大,比如doc表示的概念->topic(千-万量级)->term(10万量级)->word(百万量级)
VGG_Face 网络的配置,列出了每一层滤波器的大小和数量,并且指明了步长和padding的方式:
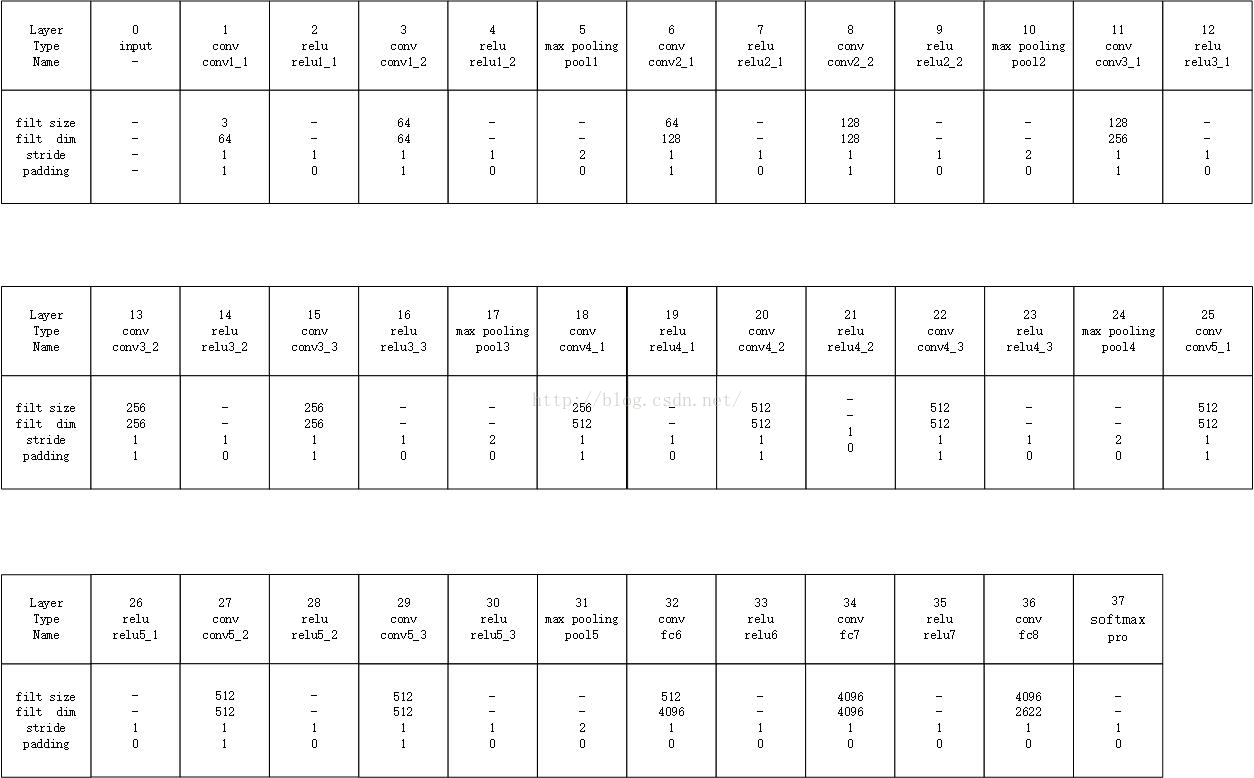
相关参数的介绍:http://blog.csdn.net/wjmishuai/article/details/50890214
4. 模型的训练过程
如果没有实验条件的话,不建议训练vgg_net。时间太长了,除非你有泰坦x显卡或者更好的显卡,这里给出训练的过程(基于caffe框架),有条件的可以做一下:
5.预训练好的模型