一、并发基础
ㅤ
1、进程与线程
ㅤ
进程
- 程序由指令和数据组成,但这些指令要运行,数据要读写,就必须将指令加载至 CPU,数据加载至内存。在指令运行过程中还需要用到磁盘、网络等设备。进程就是用来加载指令、管理内存、管理 IO 的
- 当一个程序被运行,从磁盘加载这个程序的代码至内存,这时就开启了一个进程。
-
进程就可以视为程序的一个实例。大部分程序可以同时运行多个实例进程(例如记事本、画图、浏览器等),也有的程序只能启动一个实例进程(例如网易云音乐、360 安全卫士等)
线程
- 一个进程之内可以分为一到多个线程。
- 一个线程就是一个指令流,将指令流中的一条条指令以一定的顺序交给 CPU 执行
- Java 中,线程作为最小调度单位,进程作为资源分配的最小单位。 在 windows 中进程是不活动的,只是作为线程的容器
二者对比
-
进程基本上相互独立的,而线程存在于进程内,是进程的一个子集
-
进程拥有共享的资源,如内存空间等,供其内部的线程共享
-
进程间通信较为复杂
同一台计算机的进程通信称为 IPC(Inter-process communication)
不同计算机之间的进程通信,需要通过网络,并遵守共同的协议,例如 HTTP
-
线程通信相对简单,因为它们共享进程内的内存,一个例子是多个线程可以访问同一个共享变量
-
线程更轻量,线程上下文切换成本一般上要比进程上下文切换低
ㅤ
2、并发与并行
并发(concurrent)是同一时间应对(dealing with)多件事情的能力
并行(parallel)是同一时间动手做(doing)多件事情的能力
ㅤ
二、线程
ㅤ
1、创建和运行线程
ㅤ
方法一,直接使用 Thread
方法二,使用 Runnable 配合 Thread
方法三,callable(比如配合FutureTask使用,作为FutureTask的一个成员变量,当任务执行时调用callable的call方法,并将返回结果赋给FutureTask的一个成员变量)
ㅤ
关系,Thread的本质是调用runnable的run方法
callable使用案例:
// 创建任务对象
FutureTask<Integer> task3 = new FutureTask<>(() -> {
log.debug("hello");
return 100;
});
// 参数1 是任务对象; 参数2 是线程名字,推荐
new Thread(task3, "t3").start();
// 主线程阻塞,同步等待 task 执行完毕的结果
Integer result = task3.get();
log.debug("结果是:{}", result);
ㅤ
2、 查看进程线程的方法
ㅤ
windows
- 任务管理器可以查看进程和线程数,也可以用来杀死进程
- tasklist
- 查看进程
- taskkill
- 杀死进程
linux
- ps -fe 查看所有进程
- ps -fT -p 查看某个进程(PID)的所有线程
- kill 杀死进程
- top 按大写 H 切换是否显示线程
- top -H -p
- 查看某个进程(PID)的所有线程
Java
- jps
- 命令查看所有 Java 进程
- jstack 查看某个 Java 进程(PID)的所有线程状态
- jconsole 来查看某个 Java 进程中线程的运行情况(图形界面)
ㅤ
ㅤ
3、指令并行原理
支持流水线的处理器(指令重排的原因)
现代 CPU 支持多级指令流水线,例如支持同时执行取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回的处理器,就可以称之为五级指令流水线。这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一条执行时间最长的复杂令),IPC = 1,本质上,流水线技术并不能缩短单条指令的执行时间,但它变相地提高了指令地吞吐率。
指令重排前,一个一个指令执行

ㅤ
指令重排后

在不改变程序结果的前提下,这些指令的各个阶段可以通过重排序和组合来实现指令级并行(提高了吞吐量,也就提高了程序的运行速度)
ㅤ
4、**线程上下文切换(**Thread Context Switch)
因为以下一些原因导致 cpu 不再执行当前的线程,转而执行另一个线程的代码
- 线程的 cpu 时间片用完
- 垃圾回收
- 有更高优先级的线程需要运行
- 线程自己调用了 sleep、yield、wait、join、park、synchronized、lock 等方法
当 Context Switch 发生时,需要由操作系统保存当前线程的状态,并恢复另一个线程的状态,Java 中对应的概念就是程序计数器(Program Counter Register),它的作用是记住下一条 jvm 指令的执行地址,是线程私有的
了解:上下文切换会带来直接和间接两种因素影响程序性能的消耗. 直接消耗包括: CPU寄存器需要保存和加载, 系统调度器的代码需要执行, TLB实例需要重新加载, CPU 的pipeline需要刷掉; 间接消耗指的是多核的cache之间得共享数据, 间接消耗对于程序的影响要看线程工作区操作数据的大小).
ㅤ
5、Thread的常见方法
5.1、start与run
直接调用 run 是在主线程中执行了 run,没有启动新的线程
使用 start 是启动新的线程,通过新的线程间接执行 run 中的代码
ㅤ
5.2、sleep 与 yield
sleep
-
调用 sleep 会让当前线程从 Running 进入 Timed Waiting 状态(阻塞)
-
其它线程可以使用 interrupt 方法打断正在睡眠的线程,这时 sleep 方法会抛出
InterruptedException
-
睡眠结束后的线程未必会立刻得到执行
-
建议用 TimeUnit 的 sleep 代替 Thread 的 sleep 来获得更好的可读性
ㅤ
yield
-
调用 yield 会让当前线程从 Running 进入 Runnable 就绪状态,然后调度执行其它线程
-
具体的实现依赖于操作系统的任务调度器
ㅤ
5.3、线程优先级
- 线程优先级会提示(hint)调度器优先调度该线程,但它仅仅是一个提示,调度器可以忽略它
- 如果 cpu 比较忙,那么优先级高的线程会获得更多的时间片,但 cpu 闲时,优先级几乎没作用
ㅤ
5.4、join、join(time)
需要等待结果返回,才能继续运行(可以实现同步)
ㅤ
5.5、interrupt
打断 sleep,wait,join(join的底层还是调用wait) 的线程(打断后都会抛InterruptedException,并且都会清除标记状态)
打断sleep会清空打断状态
打断正常运行的线程, 不会清空打断状态
ㅤ
5.6、两阶段终止模式
先利用interrupt()来打断sleep或者wait的线程,此时线程并没有直接结束,还有一个料理后事的处理,当料理完后事后线程再结束
while(true) {
Thread current = Thread.currentThread();
if(current.isInterrupted()) {
log.debug("料理后事");
break;
}
try {
Thread.sleep(1000);
log.debug("将结果保存");
} catch (InterruptedException e) {
//继续打断,因为打断状态会被清除
current.interrupt();
}
// 执行监控操作
}
5.6.1、同步模式之 Balking
1. 定义
Balking (犹豫)模式用在一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做了,直接结束返回,比如单例模式
ㅤ
public class MonitorService {
// 用来表示是否已经有线程已经在执行启动了
private volatile boolean starting;
public void start() {
log.info("尝试启动监控线程...");
synchronized (this) {
if (starting) {
return;
}
starting = true;
}
// 真正启动监控线程...
}
}
ㅤ
5.7、打断 park 线程
打断 park 线程, 不会清空打断状态
如果打断标记已经是 true, 则 park 会失效
private static void test4() {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5; i++) {
log.debug("park...");
LockSupport.park();
log.debug("打断状态:{}", Thread.currentThread().isInterrupted());
}
});
t1.start();
sleep(1);
t1.interrupt();
}
21:13:48.783 [Thread-0] c.TestInterrupt - park...
21:13:49.809 [Thread-0] c.TestInterrupt - 打断状态:true
21:13:49.812 [Thread-0] c.TestInterrupt - park...
21:13:49.813 [Thread-0] c.TestInterrupt - 打断状态:true
21:13:49.813 [Thread-0] c.TestInterrupt - park...
21:13:49.813 [Thread-0] c.TestInterrupt - 打断状态:true
21:13:49.813 [Thread-0] c.TestInterrupt - park...
21:13:49.813 [Thread-0] c.TestInterrupt - 打断状态:true
21:13:49.813 [Thread-0] c.TestInterrupt - park...
21:13:49.813 [Thread-0] c.TestInterrupt - 打断状态:true
ㅤ
5.8、不推荐的方法stop,suspend,resume
stop会直接终止线程,直接释放所有占用的资源,会破坏锁结构
suspend和resume对应,前者挂起线程,后者恢复线程(使用会很容易造成死锁)
例子:
Object o=new Object();
Thread t=new Thread(() ->{
synchronized (o){
log.debug("suspend前");
Thread.currentThread().suspend();//挂起
log.debug("suspend后");
}
});
t.start();
Thread.sleep(1000);
synchronized (o){
t.resume();//该行代码永远也不会被执行,导致死锁
}
log.debug("main end");
ㅤ
5.9、五种状态
初始状态
可运行状态(就绪状态)
运行状态
阻塞状态
终止状态
ㅤ
5.10、六种状态(java层面)

NEW 线程刚被创建,但是还没有调用 start() 方法
RUNNABLE 当调用了 start() 方法之后,注意,Java API 层面的 RUNNABLE 状态涵盖了 操作系统 层面的
【可运行状态】、【运行状态】和【阻塞状态】(由于 BIO 导致的线程阻塞,在 Java 里无法区分,仍然认为是可运行)
BLOCKED , WAITING , TIMED_WAITING 都是 Java API 层面对【阻塞状态】的细分,后面会在状态转换一节详述
TERMINATED 当线程代码运行结束
ㅤ
5.11、应用之统筹
join,wait/notify,synchronized实现线程之间的通信
ㅤ
三、共享模型之管程
1、共享带来的问题
1.1、数据一致性问题
多线程时指令交错运行带来的数据一致性问题
比如:i=0,一个线程执行i++,一个线程执行i–,最终结果不一定是0
1.2、临界区
ㅤ
1.3、竞态条件 Race Condition
多个线程在临界区内执行,由于代码的执行序列不同而导致结果无法预测,称之为发生了竞态条件
ㅤ
2、synchronized
2.1互斥
悲观互斥(synchronized,lock),乐观互斥(CAS,原子变量就是使用CAS)
注意
虽然 java 中互斥和同步都可以采用 synchronized 关键字来完成,但它们还是有区别的:
- 互斥是保证临界区的竞态条件发生,同一时刻只能有一个线程执行临界区代码
- 同步是由于线程执行的先后、顺序不同、需要一个线程等待其它线程运行到某个点
ㅤ
2.2变量的线程安全分析
ㅤ
成员变量和静态变量是否线程安全?
局部变量是否线程安全?
ㅤ
2.3、常见线程安全类
- String
- Integer
- StringBuffffer
- Random
- Vector
- Hashtable
- java.util.concurrent 包下的类
这里说它们是线程安全的是指,多个线程调用它们同一个实例的某个方法时,是线程安全的。它们的每个方法是原子的,但注意它们多个方法的组合不是原子的
例如下面是线程不安全的
Hashtable table = new Hashtable();
// 线程1,线程2
if( table.get("key") == null) {
table.put("key", value);
}
ㅤ
2.4、不可变类线程安全性
String、Integer 等都是不可变类,因为其内部的状态不可以改变,因此它们的方法都是线程安全的。String 有 replace,substring 等方法是通过生成一个新对象来保证线程的安全。
ㅤ
2.5、Monitor概念
java对象头

其中klass word为指向类的指针
其中 Mark Word 结构为

ㅤ
Monitor 原理
Monitor 被翻译为监视器或管程
每个 Java 对象都可以关联一个 Monitor 对象,如果使用 synchronized 给对象上锁(重量级)之后,该对象头的Mark Word 中就被设置指向 Monitor 对象的指针
Monitor 结构如下
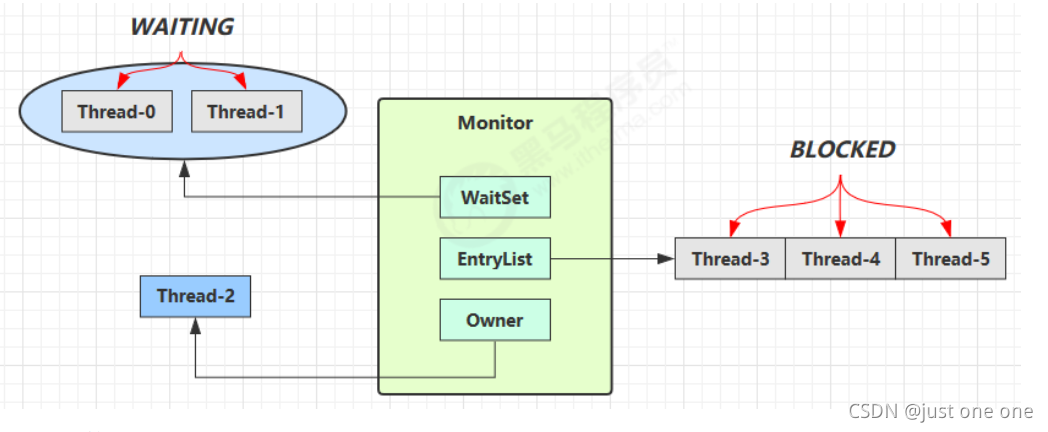
- 刚开始 Monitor 中 Owner 为 null
- 当 Thread-2 执行 synchronized(obj) 就会将 Monitor 的所有者 Owner 置为 Thread-2,Monitor中只能有一个 Owner
- 在 Thread-2 上锁的过程中,如果 Thread-3,Thread-4,Thread-5 也来执行 synchronized(obj),就会进入EntryList BLOCKED
- Thread-2 执行完同步代码块的内容,然后唤醒 EntryList 中等待的线程来竞争锁,竞争的时是非公平的
- 图中 WaitSet 中的 Thread-0,Thread-1 是之前获得过锁,但条件不满足进入 WAITING 状态的线程,后面讲wait-notify 时会分析
注意:
- synchronized 必须是进入同一个对象的 monitor 才有上述的效果
- 不加 synchronized 的对象不会关联监视器,不遵从以上规则
ㅤ
2.6、synchronized原理
两个指令
monitorenter // 将 lock对象 MarkWord 置为 Monitor 指针
monitorexit // 将 lock对象 MarkWord 重置, 唤醒 EntryList
可以自己查看字节码
注意
方法级别的 synchronized 不会在字节码指令中有所体现
ㅤ
3、synchronized原理进阶
3.1、轻量级锁
轻量级锁的使用场景:如果一个对象虽然有多线程要加锁,但加锁的时间是错开的(也就是没有竞争),那么可以使用轻量级锁来优化。
轻量级锁对使用者是透明的,即语法仍然是 synchronized
ㅤ
轻量级锁加锁过程:
几个概念:锁记录对象、锁记录(指向锁记录对象,加锁后存储mark word信息,和mark word一样占用32个字节)、对象指针,锁记录对象=锁记录+对象指针
进入同步代码块时(当偏向锁升级为轻量级锁),此时不会直接关联一个monitor锁对象,而是先看对象是否被其它线程线程加锁,如果对象没有被加锁。则在当前栈帧中创建一个锁记录Lock record对象(内部包含了一个锁记录地址和对象指针),先将mark word的值存入锁记录中,然后使用CAS的方式将对象的mark word修改为锁记录的指针(交换信息),并且改变锁记录对象的对象指针,指向被加锁的对象。如果cas替换成功,此时对象的对象头存储了锁记录地址和状态00,表示由该线程给对象加锁。如果cas失败有两种情况
- 如果是其它线程已经持有了该 Object 的轻量级锁,这时表明有竞争,进入锁膨胀过程(会先自旋,再膨胀)
- 如果是自己执行了 synchronized 锁重入,那么再添加一条 Lock Record 作为重入的计数
当退出 synchronized 代码块(解锁时)如果有取值为 null 的锁记录,表示有重入,这时重置锁记录,表示重入计数减一。
当退出 synchronized 代码块(解锁时)锁记录的值不为 null,这时使用 cas 将 Mark Word 的值恢复给对象头
成功,则解锁成功
失败,说明轻量级锁进行了锁膨胀或已经升级为重量级锁,进入重量级锁解锁流程
ㅤ
锁膨胀过程
锁被线程0占有,那么线程1进行轻量级加锁cas会失败(且自旋也没有获得锁),进入锁膨胀流程
先为对象申请 Monitor 锁,让 对象的mark word重新指向重量级锁地址
然后线程1进入 Monitor 的 EntryList (BLOCKED)
当线程0释放锁时,使用 cas 将 Mark Word 的值恢复给对象头,会失败。这时会进入重量级解锁流程,即按照 Monitor 地址找到 Monitor 对象(应该是想将mark word信息保存到monitor中),设置 Owner 为 null,唤醒 EntryList 中 BLOCKED 线程。
ㅤ
其实加锁的本质就是改变对象头的mark word,让其它线程知道该对象被其它线程加锁,无论是偏向锁,轻量级锁,重量级锁,都是改变mark word
内核态和用户态
内核态与用户态是操作系统的两种运行级别。我们的应用程序一般是处在用户态,但当我们需要硬盘数据读取等相关操作时,这些操作是不能直接在用户态进行的。需要转换到内核态帮我们进行处理。内核态和用户态之间发生切换对性能是有一定影响的。
https://www.cnblogs.com/wely/p/6198681.html
用户态和内核态切换耗时的原因
https://www.cnblogs.com/gtblog/p/12155109.html
ㅤ
ㅤ
3.2、自旋锁
重量级锁竞争的时候,还可以使用自旋来进行优化,如果当前线程自旋成功(即这时候持锁线程已经退出了同步块,释放了锁),这时当前线程就可以避免阻塞。
自旋锁的目的就是为了减少线程用户态和内核态之间的切换。自旋获得的锁任然是重量级锁,只是自旋不会让线程变成阻塞状态(阻塞就会涉及到上面提到的状态切换)。但自旋锁会占用cpu时间。且在多核下才能发挥优势。
在 Java 6 之后自旋锁是自适应的,比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会高,就多自旋几次;反之,就少自旋甚至不自旋,总之,比较智能。Java 7 之后不能控制是否开启自旋功能。
ㅤ
3.3、偏向锁
轻量级锁在没有竞争时(就自己这个线程),每次加锁都需要执行 CAS 操作。
Java 6 中引入了偏向锁来做进一步优化:只有第一次使用 CAS 将线程 ID 设置到对象的 Mark Word 头,之后发现这个线程 ID 是自己的就表示没有竞争,不用重新 CAS。以后只要不发生竞争,这个对象就归该线程所有。
偏向状态
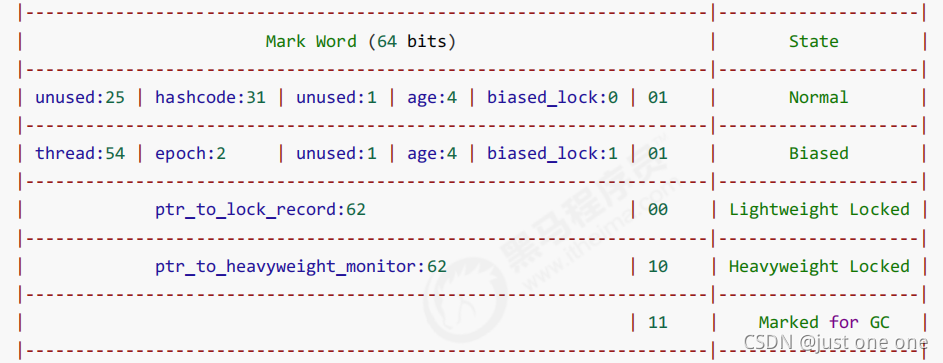
一个对象创建时:
- 如果开启了偏向锁(默认开启),那么对象创建后,markword 值为 0x05 即最后 3 位为 101,这时它的thread、epoch、age 都为 0
- 偏向锁是默认是延迟的,不会在程序启动时立即生效,如果想避免延迟,可以加 VM 参数 -XX:BiasedLockingStartupDelay=0 来禁用延迟(默认大约4秒延迟)
- 如果没有开启偏向锁,那么对象创建后,markword 值为 0x01 即最后 3 位为 001,这时它的 hashcode、age 都为 0,第一次用到 hashcode 时才会赋值
对于偏向锁,在线程获取偏向锁时,会用 Thread ID 和 epoch 值覆盖 identity hash code 所在的位置。如果一个对象的hashCode() 方法已经被调用过一次之后,这个对象还能被设置偏向锁么?答案是不能。因为如果可以的化,那 Mark Word中 的 identity hash code 必然会被偏向线程Id给覆盖,这就会造成同一个对象前后两次调用 hashCode() 方法得到的结果不一致。参考https://blog.csdn.net/weixin_43935927/article/details/114844703
注意
处于偏向锁的对象解锁后,线程 id 仍存储于对象头中
ㅤ
撤销 - 调用对象 hashCode
调用了对象的 hashCode,但偏向锁的对象 MarkWord 中存储的是线程 id,如果调用 hashCode 会导致偏向锁被撤销
- 轻量级锁会在锁记录中记录 hashCode
- 重量级锁会在 Monitor 中记录 hashCode
ㅤ
撤销 - 其它线程使用对象
当有其它线程使用偏向锁对象时,会将偏向锁升级为轻量级锁
ㅤ
撤销 - 调用 wait/notify(本质还是其它线程使用了对象)
ㅤ
批量重偏向
如果对象虽然被多个线程访问,但没有竞争,这时偏向了线程 T1 的对象仍有机会重新偏向 T2,重偏向会重置对象的 Thread ID
当撤销偏向锁阈值超过 20 次后,jvm 会这样觉得,我是不是偏向错了呢,于是会在给这些对象加锁时重新偏向至加锁线程
批量撤销
当撤销偏向锁阈值超过 40 次后,jvm 会这样觉得,自己确实偏向错了,根本就不该偏向。于是整个类的所有对象都会变为不可偏向的,新建的对象也是不可偏向的
ㅤ
偏向锁冲突
自己的理解:当线程1持有偏向锁时,线程2也来尝试获取锁,此时线程2获取偏向锁肯定会失败,线程2根据对象mark word中的线程id找到线程1,如果线程1死亡,那么将对象头设置为无锁状态。如果线程1仍然活着,那么线程1会将对象的markword设置为null,然后尝试获取对象的轻量级锁。线程2也会尝试获取轻量级锁,失败则自旋,自旋失败则升级为重量级锁。
ㅤ
偏向锁总结
已经升级为轻量级锁的对象无法再使用偏向锁
偏向锁偏向是在类级别上的,偏向次数达到一定量(20),那么其它线程去获取锁时就会偏向该线程,如果偏向次数达到40次,那么该类的所有对象无法再偏向其它线程(出现锁竞争直接升级为轻量级锁)。
ㅤ
锁消除
加锁对象只被一个线程访问
public void b() throws Exception {
Object o = new Object();
synchronized (o) {
x++;
}
}
}
ㅤ
锁粗化
对相同对象多次加锁,导致线程发生多次重入,可以使用锁粗化方式来优化,这不同于之前讲的细分锁的粒度。
ㅤ
3.4、Synchronized的执行流程
1、检查Mark Word中偏向锁的标识是否设置成1,锁标志位是否为01,确认为可偏向状态
2、如果为可偏向状态,则检查线程ID是否指向当前线程,如果是则表示当前线程处于偏向锁状态,然后执行同步代码
3、如果线程ID并未指向当前线程,则通过CAS操作竞争锁。如果竞争成功,则将Mark Word中线程ID设置为当前线程,偏向标志位设置为1,锁标志位设置为01,然后执行同步码块
4、如果竞争失败,则说明发生竞争,撤销偏向锁,进而升级为轻量级锁
5、当前线程使用CAS将对象头的Mark Word替换为锁记录指针,如果成功,当前线程获得锁
6、如果替换失败,表示其他线程竞争锁,当前线程尝试自旋获取锁(前提是对象已经关联了一个monitor,否则不会自旋,直接升级为重量级锁。因为自旋锁是解决重量级锁竞争,预防线程进入entrylist,因为会存在状态切换)
7、如果自旋成功,则将monitor中的owner设置为当前线程
8、如果自旋失败,则进入entrylist,进入重量级锁流程
ㅤ
关于整个Synchronized原理非常值得一看。里面也讲到了自旋锁只有在重量级锁竞争是才会出现
https://www.cnblogs.com/yescode/p/14474104.html
3.5、synchronized加锁的整个流程图
ㅤ
参考https://blog.csdn.net/weixin_39882948/article/details/114599536

ㅤ
4、wait notify 原理
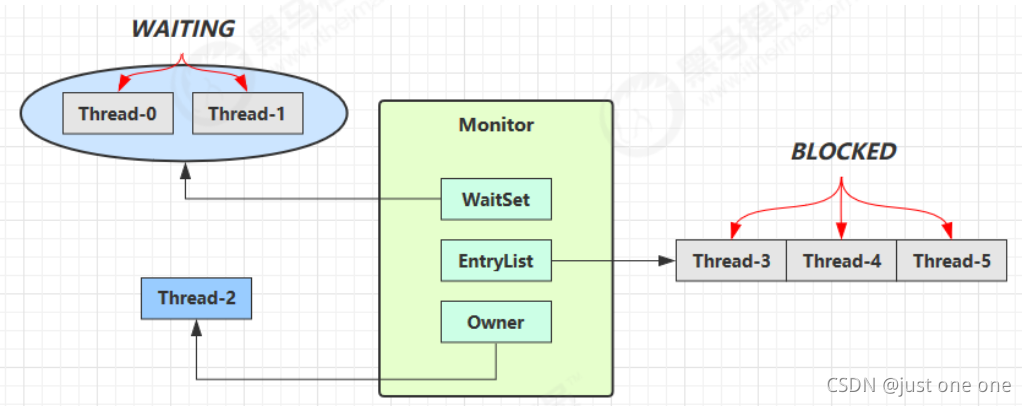
- Owner 线程发现条件不满足,调用 wait 方法,即可进入 WaitSet 变为 WAITING 状态
- BLOCKED 和 WAITING 的线程都处于阻塞状态,不占用 CPU 时间片
- BLOCKED 线程会在 Owner 线程释放锁时唤醒
- WAITING 线程会在 Owner 线程调用 notify 或 notifyAll 时唤醒,但唤醒后并不意味者立刻获得锁,仍需进入EntryList 重新竞争
ㅤ
4.1、wait和sleep的区别
-
sleep 是 Thread 方法,而 wait 是 Object 的方法
-
sleep 不需要强制和 synchronized 配合使用,但 wait 需要和 synchronized 一起用
-
sleep 在睡眠的同时,不会释放对象锁的,但 wait 在等待的时候会释放对象锁
-
它们状态 TIMED_WAITING
ㅤ
4.2、保护性暂停模式
一个线程需要等待另外一个线程的结果,因此这个线程需要先暂停,等待另外一个线程的通知后再运行(wait,notify)
class GuardedObject {
private Object response;
private final Object lock = new Object();
public Object get() {
synchronized (lock) {
// 条件不满足则等待
while (response == null) {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return response;
}
}
public void complete(Object response) {
synchronized (lock) {
// 条件满足,通知等待线程
this.response = response;
lock.notifyAll();
}
}
}
ㅤ
4.3、异步模式之生产者/消费者
1. 定义
要点
- 与前面的保护性暂停中的 GuardObject 不同,不需要产生结果和消费结果的线程一一对应
- 消费队列可以用来平衡生产和消费的线程资源
- 生产者仅负责产生结果数据,不关心数据该如何处理,而消费者专心处理结果数据
- 消息队列是有容量限制的,满时不会再加入数据,空时不会再消耗数据
- JDK 中各种阻塞队列,采用的就是这种模式
当消费者线程无法获取到消息队列的消息时(及消息队列为空),消费者线程就会被阻塞
当消息队列满时,生产者也无法添加消息到消息队列中,生产者线程将会一直被阻塞
当阻塞的生产者线程或者消费者线程达到一定量时,消息队列会有相应的处理策略
5、join 原理
ㅤ
是调用者轮询检查线程 alive 状态
t1.join();
等价于下面的代码
synchronized (t1) {
// 调用者线程进入 t1 的 waitSet 等待, 直到 t1 运行结束
while (t1.isAlive()) {
t1.wait(0);
}
}
注意
join 体现的是【保护性暂停】模式,请参考之
ㅤ
6、Park & Unpark
// 暂停当前线程
LockSupport.park();
// 恢复某个线程的运行
LockSupport.unpark(暂停线程对象)
特点
与 Object 的 wait & notify 相比
- wait,notify 和 notifyAll 必须配合 Object Monitor 一起使用,而 park,unpark 不必
- park & unpark 是以线程为单位来【阻塞】和【唤醒】线程,而 notify 只能随机唤醒一个等待线程,notifyAll 是唤醒所有等待线程,就不那么【精确】
- park & unpark 可以先 unpark,而 wait & notify 不能先 notify
ㅤ
park unpark 原理
首先Paker对象的三个成员counter(计数器),mutex(互斥量),cond(条件变量,类似monitor中的waitset)
线程会关联一个Paker对象,当调用park时,会先检查计数器counter是否为1,是1则将counter设置为0继续运行,如果是0,则线程进入条件变量中阻塞。
当调用unpark时,如果cond条件变量不为空,则唤醒cond条件变量中的线程,线程恢复运行,counter设置为0,如果cond条件变量为空,则将counter设置为1,当下次调用park后可以继续运行,不会被阻塞
总之三种情况:counter为1并且cond为空,counter为0并且cond为null,counter为0并且cond不为null
关于park unpark的bug,总之先park再unpark不会出错
ㅤ
7、重新理解线程状态转换
ㅤ
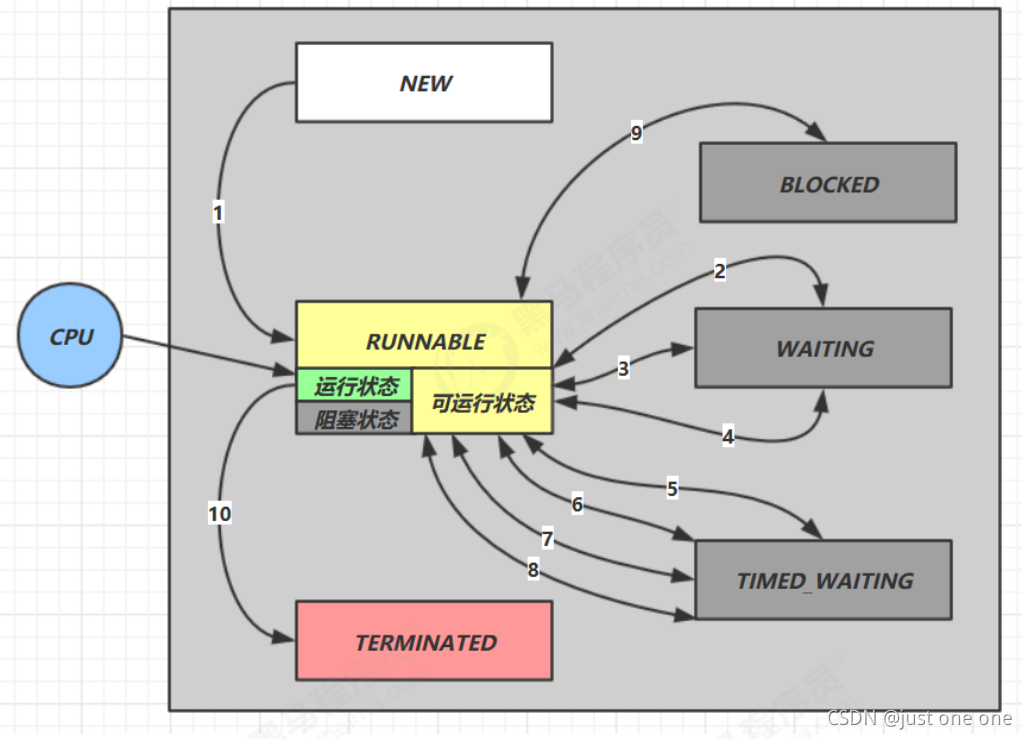
new
runnable
terminated
其中runnable包括
阻塞状态包括
- BLOCKED:synchronized,notifyAll(竞争锁失败)
- WAITING:join,park,wait
- TIMED_WAITING:wait(time),join(time),sleep(time),parkNanos(time)
就绪状态和运行状态为RUNNABLE
ㅤ
8、锁
8.1、锁的粒度
class BigRoom {
private final Object studyRoom = new Object();
private final Object bedRoom = new Object();
public void sleep() {
synchronized (bedRoom) {
log.debug("sleeping 2 小时");
Sleeper.sleep(2);
}
}
public void study() {
synchronized (studyRoom) {
log.debug("study 1 小时");
Sleeper.sleep(1);
}
}
}
将锁的粒度细分
- 好处,是可以增强并发度
- 坏处,如果一个线程需要同时获得多把锁,就容易发生死锁
ㅤ
8.2、死锁
有这样的情况:一个线程需要同时获取多把锁,这时就容易发生死锁
t1 线程 获得 A对象 锁,接下来想获取 B对象 的锁 t2 线程 获得 B对象 锁,接下来想获取 A对象 的锁。这样就会造成死锁。
定位死锁
检测死锁可以使用 jconsole工具,或者使用 jps 定位进程 id,再用 jstack 定位死锁
ㅤ
8.3、活锁
活锁出现在两个线程互相改变对方的结束条件,最后谁也无法结束,例如
new Thread(() -> {
// 期望减到 0 退出循环
while (count > 0) {
sleep(0.2);
count--;
log.debug("count: {}", count);
}
}, "t1").start();
new Thread(() -> {
// 期望超过 20 退出循环
while (count < 20) {
sleep(0.2);
count++;
log.debug("count: {}", count);
}
}, "t2").start();
ㅤ
8.4、饥饿
很多教程中把饥饿定义为,一个线程由于优先级太低,始终得不到 CPU 调度执行,也不能够结束,饥饿的情况不
易演示,讲读写锁时会涉及饥饿问题
ㅤ
四、ReentrantLock
相对于 synchronized 它具备如下特点
- 可中断
- 可以设置超时时间
- 可以设置为公平锁
- 支持多个条件变量
- 与 synchronized 一样,都支持可重入
基本语法
// 获取锁
reentrantLock.lock();
try {
// 临界区
} finally {
// 释放锁
reentrantLock.unlock();
}
ㅤ
1、同步之顺序控制
通过使用wait/notify,reentrantlock的condition,park/unpark来实现线程之间同步控制。
ㅤ
五、共享模型之内存
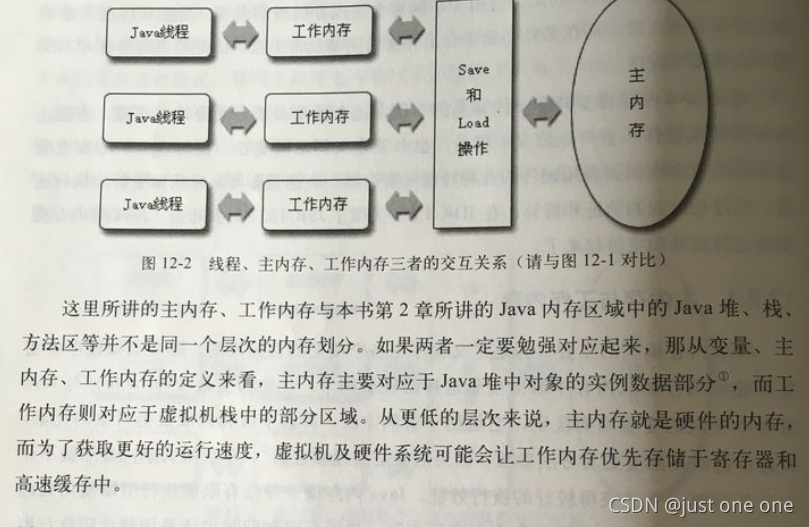
1 Java 内存模型
JMM 即 Java Memory Model,它定义了主存、工作内存抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、CPU 指令优化等。
JMM 体现在以下几个方面
- 原子性 - 保证指令不会受到线程上下文切换的影响
- 可见性 - 保证指令不会受 cpu 缓存的影响
- 有序性 - 保证指令不会受 cpu 指令并行优化的影响
ㅤ
2 可见性
退不出的循环
一个现象,main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
// ....
}
});
t.start();
sleep(1);
run = false; // 线程t不会如预想的停下来
}
ㅤ
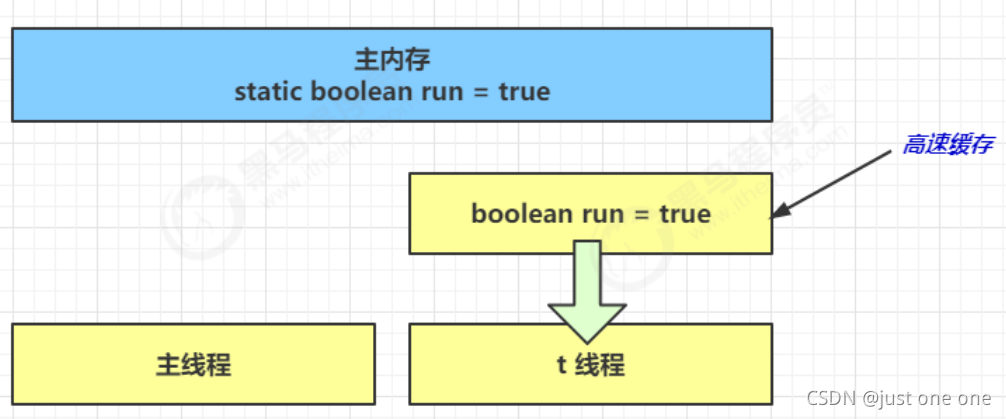
-
初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存。
-
因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率
-
1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值

解决方法
volatile(易变关键字)
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存
ㅤ
可见性 vs 原子性
前面例子体现的实际就是可见性,它保证的是在多个线程之间,一个线程对 volatile 变量的修改对另一个线程可见, 不能保证原子性,仅用在一个写线程,多个读线程的情况。只能保证看到最新值,不能解决指令交错
注意 synchronized 语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是synchronized 是属于重量级操作,性能相对更低
如果在前面示例的死循环中加入 System.out.println() 会发现即使不加 volatile 修饰符,线程 t 也能正确看到对 run 变量的修改了,想一想为什么?(里面使用了synchronized)
这里额外加一句:synchronized在加锁时和解锁时的对象会从主存中读取,但在synchronized代码块内部是不保证可见性的。例子如下,程序执行后仍然会卡在循环中
public class Test {
static class N{
int state=0;
}
public static void main(String[] args) throws InterruptedException {
N n=new N();
new Thread(()-> {
synchronized (n){//加锁时读屏障去主存中读取对象
System.out.println("thread start");
while (n.state==0){
//中间代码块不保证可见性
}
System.out.println("thread end");
}//释放锁时写屏障强制写入主存
}).start();
Thread.sleep(100);
n.state=1;
System.out.println("main end");
}
}
ㅤㅤ
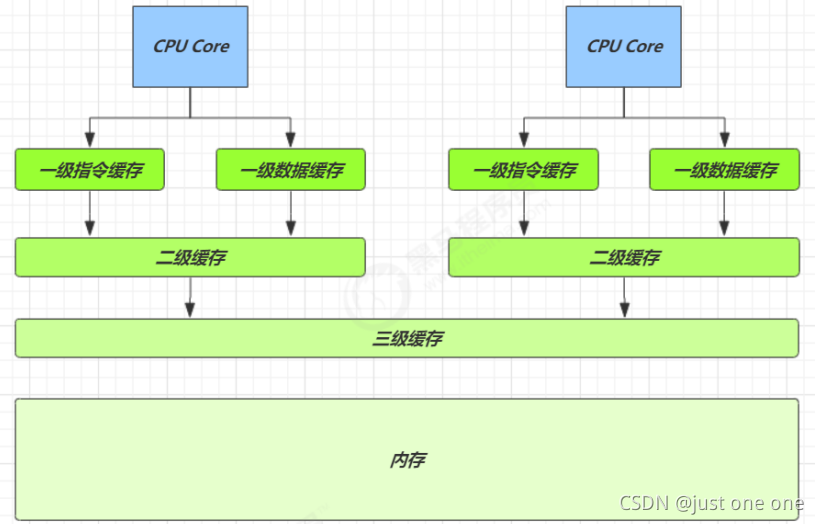
3、CPU 缓存结构原理
ㅤ
3.1结构
ㅤ
查看 cpu 缓存 lscpu

查看cpu 缓存行cat/sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
大小是64
ㅤ
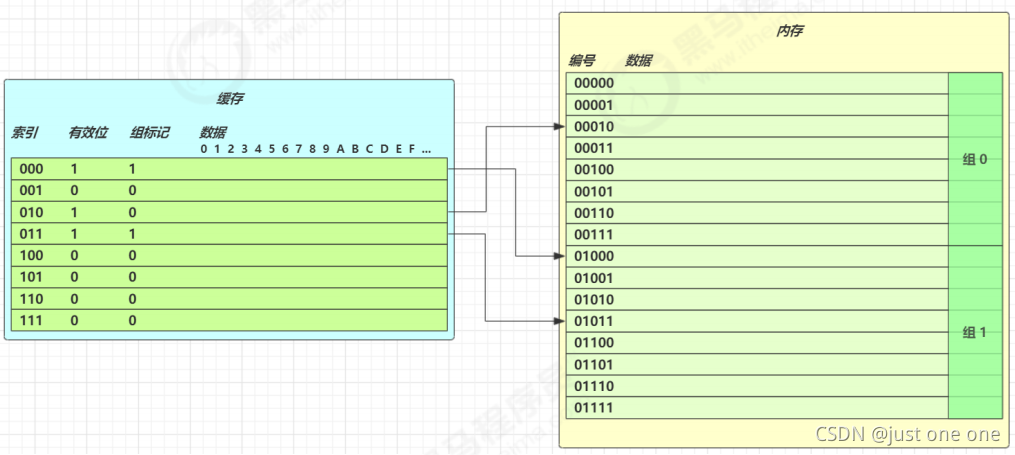
cpu 拿到的内存地址格式是这样的
[高位组标记] [低位索引] [偏移量]
ㅤ
3.2. CPU 缓存读
读取数据流程如下
-
根据低位,计算在缓存中的索引
-
判断是否有效
-
0 去内存读取新数据更新缓存行
-
1 再对比高位组标记是否一致
- 一致,根据偏移量返回缓存数据
- 不一致,去内存读取新数据更新缓存行
ㅤ
3.3 CPU 缓存一致性
MESI中每个缓存行都有四个状态,分别是E(exclusive)、M(modified)、S(shared)、I(invalid)。下面我们介绍一下这四个状态分别代表什么意思。
M:代表该缓存行中的内容被修改了,并且该缓存行只被缓存在该CPU中。这个状态的缓存行中的数据和内存中的不一样,在未来的某个时刻它会被写入到内存中(当其他CPU要读取该缓存行的内容时。或者其他CPU要修改该缓存对应的内存中的内容时(个人理解CPU要修改该内存时先要读取到缓存中再进行修改),这样的话和读取缓存中的内容其实是一个道理)。
E:E代表该缓存行对应内存中的内容只被该CPU缓存,其他CPU没有缓存该缓存对应内存行中的内容。这个状态的缓存行中的内容和内存中的内容一致。该缓存可以在任何其他CPU读取该缓存对应内存中的内容时变成S状态。或者本地处理器写该缓存就会变成M状态。
S:该状态意味着数据不止存在本地CPU缓存中,还存在别的CPU的缓存中。这个状态的数据和内存中的数据是一致的。当有一个CPU修改该缓存行对应的内存的内容时会使该缓存行变成 I 状态。
I:代表该缓存行中的内容时无效的。

ㅤ
MESI 协议
-
E、S、M 状态的缓存行都可以满足 CPU 的读请求
-
E 状态的缓存行,有写请求,会将状态改为 M,这时并不触发向主存的写
-
E 状态的缓存行,必须监听该缓存行的读操作,如果有,要变为 S 状态
-
M 状态的缓存行,必须监听该缓存行的读操作,如果有,先将其它缓存(S 状态)中该缓存行变成 I 状态(即6.的流程),写入主存,自己变为 S 状态
-
S 状态的缓存行,有写请求,走 4. 的流程
-
S 状态的缓存行,必须监听该缓存行的失效操作,如果有,自己变为 I 状态
-
I 状态的缓存行,有读请求,必须从主存读取
ㅤ
MESI协议 ,是一个缓存一致性协议。MESI协议保证了每个缓存中使用的共享变量的副本是一致的。
JMM,包括其中的volatile,synchronized等关键字,解决的是内存一致性问题。
注意,一个是缓存一致性,一个是内存一致性。
缓存一致性(Cache Coherence),硬件层面的问题,指的是由于多核计算机中有多套缓存,各个缓存之间的数据不一致性问题。缓存一致性协议,如MESI解决是多个缓存副本之间的数据的一致性问题。
内存一致性(Memory Consistency),保证的是多线程程序访问内存时可以读到什么值。就是保证并发场景下的程序运行结果和程序员预期是一样的(当然,要通过加锁等方式),包括的就是并发编程中的原子性、有序性和可见性。
Java多线程中,每个线程都有自己的工作内存,需要和主存进行交互。这里的工作内存和计算机硬件的缓存并不是一回事儿,只是可以相互类比。所以,并发编程的可见性问题,是因为各个线程之间的本地内存数据不一致导致的,和计算机缓存并无关系(~也是有一点关系的,缓存其实是算作工作内存的一部分,jit优化时可能将数据放入缓存中)。
缓存一致性协议。用来解决缓存一致性问题的,常用的是MESI协议。
内存一致性模型。屏蔽计算机硬件问题,主要来解决并发编程中的原子性、有序性和一致性问题。
实现内存一致性模型的时候可能会用到缓存一致性模型。
参考:https://www.zhihu.com/question/268021813/answer/576022615
ㅤ
4、同步模式之 Balking
1. 定义
Balking (犹豫)模式用在一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做了,直接结束返回,比如单例模式
public class MonitorService {
// 用来表示是否已经有线程已经在执行启动了
private volatile boolean starting;
public void start() {
log.info("尝试启动监控线程...");
synchronized (this) {
if (starting) {
return;
}
starting = true;
}
// 真正启动监控线程...
}
}
ㅤ
5、有序性
5.1、原理之 volatile
volatile 的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
- 对 volatile 变量的写指令后会加入写屏障
- 对 volatile 变量的读指令前会加入读屏障
如何保证可见性
- 写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
- 而读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
如何保证有序性
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
还是那句话,不能解决指令交错:
- 写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去
- 而有序性的保证也只是保证了本线程内相关代码不被重排序
更底层是读写变量时使用 lock 指令来多核 CPU 之间的可见性与有序性
下面的表是volatile有关的禁止指令重排的行为:

JVM中提供了四类内存屏障指令:
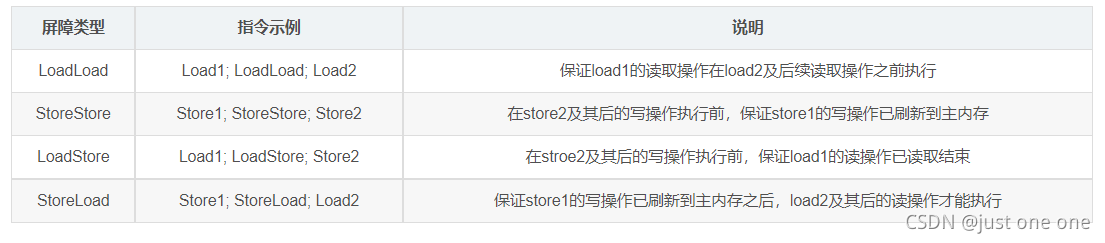
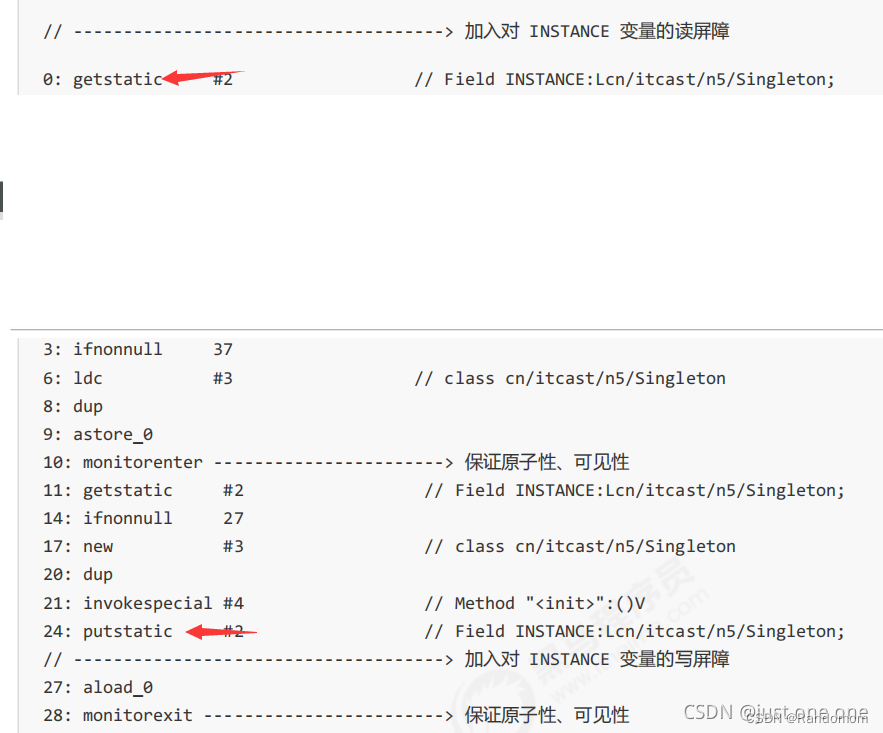
内存屏障参考:https://blog.csdn.net/huyongl1989/article/details/90712393
ㅤ
ㅤ
5.2、happens-before
happens-before 规定了对共享变量的写操作对其它线程的读操作可见,它是可见性与有序性的一套规则总结,抛开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其它线程对该共享变量的读可见。
ㅤ

happens-before完整规则:
(1)同一个线程中的每个Action都happens-before于出现在其后的任何一个Action。
(2)对一个监视器(synchronized)的解锁happens-before于每一个后续对同一个监视器的加锁。
(3)对volatile字段的写入操作happens-before于每一个后续的同一个字段的读操作。
(4)Thread.start()的调用会happens-before于启动线程里面的动作。
(5)Thread中的所有动作都happens-before于其他线程检查到此线程结束或者Thread.join()中返回或者Thread.isAlive()==false。
(6)线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见(通过t2.interrupted 或者t2.isInterrupted)
(7)一个对象构造函数的结束happens-before与该对象的finalizer的开始
(8)如果A动作happens-before于B动作,而B动作happens-before与C动作,那么A动作happens-before于C动作。–传递性
ㅤ
Happens-Before 的语义本质上是一种可见性,A Happens-Before B 意味着 A 事件对 B 事件来说是可见的,无论 A 事件和 B 事件是否发生在同一个线程里。
ㅤ
在循环中jit编译器可能会优化代码,读取数据时会直接从工作内存中读取,导致主存中的数据发生变化也不能及时更新。但一般没有在循环中,jit编译器往往不会进行优化,所以基本上读取数据还是从主存中读取。但即使jit编译器进行了优化,但在循环过程中遇到synchronized这样的代码块(即使该代码块没有任何内容),会使读操作从主存中获取数据。一般出现可见性问题是线程1在一个循环中,线程2修改了值,由于优化的原因,线程1中并不知道值发生了改变。总之因为编译器的优化导致了不一致问题。
ㅤ
CPU空闲后会遵循JVM优化基准,尽可能快的保证数据的可见性,从而从主存同步is变量到工作内存,最终导致程序结束,这也是为什么sleep()方法虽然没有涉及同步操作,但是依然可以使程序终止,因为sleep()方法会释放CPU,但不释放锁!synchronized和join应该也是类似的原因,cpu没有占用的时间比较短。
参考https://www.cnblogs.com/tv151579/p/9395452.html
ㅤ
在多线程情况下,如果只有一个线程写,其它线程读,那么可以考虑用volatile,如果有多个线程写,那么就得加锁了(synchronized,lock)
ㅤ
5.3、DCL
dcl的单例为何要加volatile(防止指令重排,防止先将创建的对象赋给引用后初始化)
ㅤ
六. 共享模型之无锁
1、CAS
ㅤ
注意
其实 CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证【比较-交换】的原子性。
- 在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
注意
volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题(不能保证原子性)
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现【比较并交换】的效果
ㅤ
为什么无锁效率高
无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。
ㅤ
CAS的特点
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下。
无锁竞争时效率:
无锁>偏向锁>原子整型>synchronized 1:5:15:30
ㅤ
2、原子
原子整数
- AtomicBoolean
- AtomicInteger
- AtomicLong
ㅤ
原子引用
- AtomicReference(直接修改成新对象)
- AtomicMarkableReference(维护一个boolean)
- AtomicStampedReference(解决了ABA问题,维护一个int版本号)
ㅤ
原子数组
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
操作原子数组的每个位置都是原子操作
ㅤ
字段更新器
- AtomicReferenceFieldUpdater // 域 字段
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdater
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常。
字段更新器是在原有的对象的成员变量上进行加强,使操作成员变量是原子操作。
而原子整形原子数组是直接作为成员变量或者局部变量。
ㅤ
原子累加器
LongAdder
性能提升的原因很简单,就是在有竞争时,设置多个累加单元,Therad-0 累加 Cell[0],而 Thread-1 累加Cell[1]… 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
原理之伪共享
伪共享的非标准定义为:缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
ㅤ
Unsafe
Unsafe 对象提供了非常底层的,操作内存、线程的方法,Unsafe 对象不能直接调用,只能通过反射获得
ㅤ
3、MESI协议
ㅤ
缓存行状态
CPU的缓存是以缓存行(cache line)为单位的,MESI协议描述了多核处理器中一个缓存行的状态。在MESI协议中,每个缓存行有4个状态,分别是:
- M(修改,Modified):本地处理器已经修改缓存行,即是脏行,它的内容与内存中的内容不一样,并且此 cache 只有本地一个拷贝(专有);
- E(专有,Exclusive):缓存行内容和内存中的一样,而且其它处理器都没有这行数据;
- S(共享,Shared):缓存行内容和内存中的一样, 有可能其它处理器也存在此缓存行的拷贝;
- I(无效,Invalid):缓存行失效, 不能使用。
CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效。
缓存行失效的理解:当有多核时,核1和核2都缓存了同一份数据,那么核1修改,核2的缓存行就会失效。假如核1和核2各缓存了同一份数据,这份数据有两部分组成,当核1修改了其中一部分数据,核1本身的缓存行是不会失效的,失效的是核2,但第二部分数据没有被修改却也失效了。所以要将这两部分分开缓存,各占用一个缓存行。@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的padding,从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效。

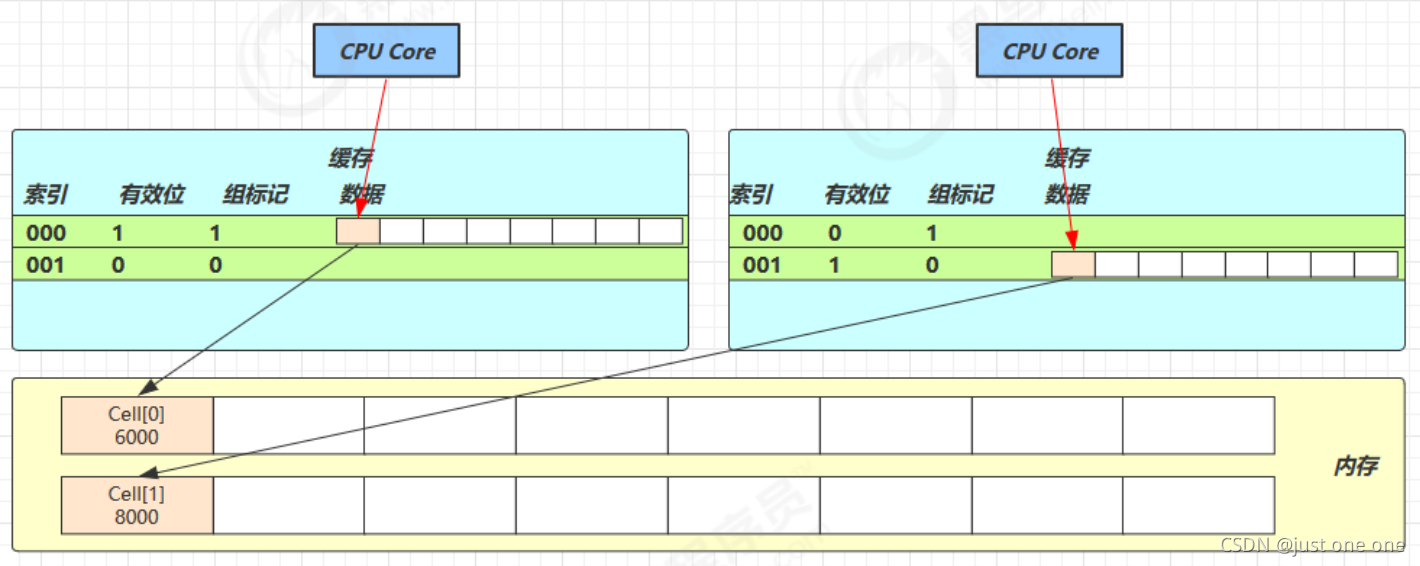
ㅤ
七. 共享模型之不可变
如果一个对象在不能够修改其内部状态(属性),那么它就是线程安全的,因为不存在并发修改啊!这样的对象在Java 中有很多,例如在 Java 8 后,提供了一个新的日期格式化类:
ㅤ
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd");
for (int i = 0; i < 10; i++) {
new Thread(() -> {
LocalDate date = dtf.parse("2018-10-01", LocalDate::from);
log.debug("{}", date);
}).start();
}
ㅤ
final 的使用
发现该类、类中所有属性都是 final 的
- 属性用 final 修饰保证了该属性是只读的,不能修改
- 类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
ㅤ
无状态ㅤ
在 web 阶段学习时,设计 Servlet 时为了保证其线程安全,都会有这样的建议,不要为 Servlet 设置成员变量,这种没有任何成员变量的类是线程安全的
ㅤ
因为成员变量保存的数据也可以称为状态信息,因此没有成员变量就称之为【无状态】
final原理
ㅤ
总之是为了防止指令重排,添加了读写屏障
对于final域,编译器和处理器要遵守两个重排序规则:
1.在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。(先写入final变量,后调用该对象引用)
原因:编译器会在final域的写之后,插入一个StoreStore(写)屏障
2.初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
(先读对象的引用,后读final变量)
编译器会在读final域操作的前面插入一个LoadLoad(读)屏障
ㅤ
八、共享模型之工具
ㅤ
1、线程池
1.1线程池的几个参数
- corePoolSize 核心线程数目 (最多保留的线程数)
- maximumPoolSize 最大线程数目
- keepAliveTime 生存时间 - 针对救急线程
- unit 时间单位 - 针对救急线程
- workQueue 阻塞队列
- threadFactory 线程工厂 - 可以为线程创建时起个好名字
- handler 拒绝策略
ㅤ
1.2 线程池的工作流程
- 线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
- 当线程数达到 corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue 队列排队,直到有空闲的线程。
- 如果队列选择了有界队列,那么任务超过了队列大小时,会创建 maximumPoolSize - corePoolSize 数目的线程来救急。
- 如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略。拒绝策略 jdk 提供了 4 种实现,其它著名框架也提供了实现
- 当高峰过去后,超过corePoolSize 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由keepAliveTime 和 unit 来控制。
ㅤ
1.3任务调度线程池
Timer(不推荐使用)
在『任务调度线程池』功能加入之前,可以使用 java.util.Timer 来实现定时功能。Timer 的优点在于简单易用,但由于所有任务都是由同一个线程来调度,因此所有任务都是串行执行的,同一时间只能有一个任务在执行,前一个任务的延迟或异常都将会影响到之后的任务。
public static void main(String[] args) {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
log.debug("task 1");
sleep(2);
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
log.debug("task 2");
}
};
// 使用 timer 添加两个任务,希望它们都在 1s 后执行
// 但由于 timer 内只有一个线程来顺序执行队列中的任务,因此『任务1』的延时,影响了『任务2』的执行
timer.schedule(task1, 1000);
timer.schedule(task2, 1000);
}
输出
20:46:09.444 c.TestTimer [main] - start...
20:46:10.447 c.TestTimer [Timer-0] - task 1
20:46:12.448 c.TestTimer [Timer-0] - task 2
ScheduledExecutorService(推荐)
schedule
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
// 添加两个任务,希 它们都在 1s 后执行
executor.schedule(() -> {
System.out.println("任务1,执行时间:" + new Date());
try { Thread.sleep(2000); } catch (InterruptedException e) { }
}, 1000, TimeUnit.MILLISECONDS);
executor.schedule(() -> {
System.out.println("任务2,执行时间:" + new Date());
}, 1000, TimeUnit.MILLISECONDS);
scheduleAtFixedRate
以固定的时间间隔循环执行任务(如果任务时间太长会有影响)
scheduleWithFixedDelay(在任务执行完后延迟)
以固定的延迟循环执行任务
ㅤ
1.4正确处理执行任务异常
方法1:主动捉异常
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(() -> {
try {
log.debug("task1");
int i = 1 / 0;
} catch (Exception e) {
log.error("error:", e);
}
});
方法2:使用 Future
ExecutorService pool = Executors.newFixedThreadPool(1);
Future<Boolean> f = pool.submit(() -> {
log.debug("task1");
int i = 1 / 0;
return true;
});
log.debug("result:{}", f.get());
ㅤ
1.5、定时
scheduleAtFixedRate
1.6Fork/Join
Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型运算
Fork/Join 默认会创建与 cpu 核心数大小相同的线程池
ㅤ
2、JUC
2. 1 AQS 原理
全称是 AbstractQueuedSynchronizer,是阻塞式锁和相关的同步器工具的框架
- 用 state 属性来表示资源的状态(分独占模式和共享模式),子类需要定义如何维护这个状态,控制如何获取锁和释放锁
- 提供了基于 FIFO 的等待队列,类似于 Monitor 的 EntryList
- 条件变量来实现等待、唤醒机制,支持多个条件变量,类似于 Monitor 的 WaitSet
ㅤ
2.2、ReentrantReadWriteLock读写锁
读锁共享,写锁独占。读锁无法升级为写锁,但写锁可以降级为读锁,降级后写锁仍然需要手动释放。同样是基于AQS,写锁基本于ReentrantLock一致。读锁是一种共享锁,在获取到读锁后需要锁后需要唤醒后继的读锁。源码可参考https://blog.csdn.net/fxkcsdn/article/details/82217760
ㅤ
2.3 StampedLock
可以基于乐观读(不加锁,使用一个版本号),乐观读失败才加读锁。
StampedLock 不支持条件变量
StampedLock 不支持可重入
ㅤ
2.4Semaphore
信号量,用来限制能同时访问共享资源的线程上限。
使用 Semaphore 限流,在访问高峰期时,让请求线程阻塞,高峰期过去再释放许可。
ㅤ
2.5CountdownLatch
用来进行线程同步协作,等待所有线程完成倒计时。
其中构造参数用来初始化等待计数值,await() 用来等待计数归零,countDown() 用来让计数减一
CyclicBarrier
循环栅栏,用来进行线程协作,等待线程满足某个计数。构造时设置『计数个数』,每个线程执行到某个需要“同步”的时刻调用 await() 方法进行等待,当等待的线程数满足『计数个数』时,继续执行
注意 CyclicBarrier 与 CountDownLatch 的主要区别在于 CyclicBarrier 是可以重用的 CyclicBarrier 可以被比
喻为『人满发车』
ㅤ
线程安全集合类概述
java.util.concurrent.* 下的线程安全集合类,可以发现它们有规律,里面包含三类关键词:
Blocking、CopyOnWrite、Concurrent
遍历时如果发生了修改,对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出ConcurrentModifificationException,不再继续遍历
ㅤ
ConcurrentHashMap
使用了分段锁
jdk1.7维护了一个 segment 数组,每个 segment 对应一把锁
- 优点:如果多个线程访问不同的 segment,实际是没有冲突的,这与 jdk8 中是类似的
- 缺点:Segments 数组默认大小为16,这个容量初始化指定后就不能改变了,并且不是懒惰初始化
jdk1.8使用了synchronized+cas
jdk死链问题
- 究其原因,是因为在多线程环境下使用了非线程安全的 map 集合
- JDK 8 虽然将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序),但仍不意味着能够在多线程环境下能够安全扩容,还会出现其它问题(如扩容丢数据)
Java 8 数组(Node) +( 链表 Node | 红黑树 TreeNode ) 以下数组简称(table),链表简称(bin)
- 初始化,使用 cas 来保证并发安全,懒惰初始化 table
- 树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程会用 synchronized 锁住链表头
- put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put 操作,元素添加至 bin 的尾部
- get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 它会让 get 操作在新table 进行搜索
- 扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时妙的是其它竞争线程也不是无事可做,它们会帮助把其它 bin 进行扩容,扩容时平均只有 1/6 的节点会把复制到新 table 中
- size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中。最后统计数量时累加即可
ㅤ
BlockingQueue
LinkedBlockingQueue
高明之处在于用了两把锁(ReentrantLock)和 一个dummy (哨兵)节点
线程安全分析
- 当节点总数大于 2 时(包括 dummy 节点),putLock 保证的是 last 节点的线程安全,takeLock 保证的是head 节点的线程安全。两把锁保证了入队和出队没有竞争
- 当节点总数等于 2 时(即一个 dummy 节点,一个正常节点)这时候,仍然是两把锁锁两个对象,不会竞争
- 当节点总数等于 1 时(就一个 dummy 节点)这时 take 线程会被 notEmpty 条件阻塞,有竞争,会阻塞
ㅤ
和ArrayBlockingQueue 性能比较
主要列举 LinkedBlockingQueue 与 ArrayBlockingQueue 的性能比较
- Linked 支持有界,Array 强制有界
- Linked 实现是链表,Array 实现是数组
- Linked 是懒惰的,而 Array 需要提前初始化 Node 数组
- Linked 每次入队会生成新 Node,而 Array 的 Node 是提前创建好的
- Linked 两把锁,Array 一把锁
ㅤ
ConcurrentLinkedQueue
ConcurrentLinkedQueue 的设计与 LinkedBlockingQueue 非常像,也是
- 两把【锁】,同一时刻,可以允许两个线程同时(一个生产者与一个消费者)执行
- dummy 节点的引入让两把【锁】将来锁住的是不同对象,避免竞争
- 只是这【锁】使用了 cas 来实现
事实上,ConcurrentLinkedQueue 应用还是非常广泛的
例如之前讲的 Tomcat 的 Connector 结构时,Acceptor 作为生产者向 Poller 消费者传递事件信息时,正是采用了ConcurrentLinkedQueue 将 SocketChannel 给 Poller 使用
ㅤ
CopyOnWriteArrayList
CopyOnWriteArraySet 是它的马甲 底层实现采用了 写入时拷贝 的思想,增删改操作会将底层数组拷贝一份,更改操作在新数组上执行,这时不影响其它线程的并发读,读写分离。 适合『读多写少』的应用场景
get 弱一致性
不要觉得弱一致性就不好
- 数据库的 MVCC 都是弱一致性的表现
- 并发高和一致性是矛盾的,需要权衡