在GitHub上找了一篇文献,想复现一下,记录一下其中遇到的环境配置问题。
我也不是很懂相关的操作,只是用来记录,如果我的操作有什么不必要或错误的地方,辛苦大家耐心指正。
1. 把yml文件安装到conda安装路径下的envs文件夹下:
把cmd转到保存着yml文件对应路径中

在该路径下安装yml文件(我理解为解压别人在电脑上配置好的环境及其安装的包),输入:
conda env create -f environment.yml
等待安装成功之后,就会在conda的安装路径下的envs文件夹中找到新添加的环境(例如我这里的Project 就是新添加的环境)
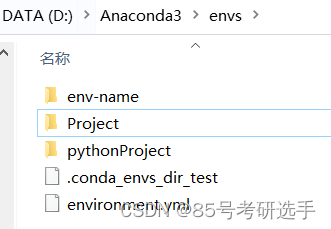
我在安装yml文件的时候,在Installing pip dependencies这一步出现了错误,并且失败。询问大佬,发现这些包可以后续离线安装,就没解决,继续下面的操作啦。
之后用anaconda prompt编辑器激活Project环境,然后在里面添加了scr目录,注意e后面有个“.”
conda activate Project
pip install -e .
解析在这里:
pip install -e . 解析
2.jupyter中配置环境
这里参考的是使用 nb_conda_kernels 添加所有环境
采纳的方法
用anaconda prompt编辑器激活Project环境
conda activate Project # this is the environment for your project and code
conda install ipykernel
conda deactivate
conda activate base # could be also some other environment
conda install nb_conda_kernels
jupyter notebook
解释:
调用conda install ipykernel下载内核
这个方法就是一键添加所有 conda 环境
注意:这里的 conda install nb_conda_kernels 是在 base 环境下操作的。
安装好后,打开 jupyter notebook 就会显示所有的 conda 环境啦,点击随意切换。

第二种方法
conda create -n my-conda-env # creates new virtual env
conda activate my-conda-env # activate environment in terminal
conda install ipykernel # install Python kernel in new conda env
ipython kernel install --user --name=my-conda-env-kernel # configure Jupyter to use Python kernel
jupyter notebook # run jupyter from system
解释:
只有 Python 内核会在 conda 环境中运行,系统中的 Jupyter 或不同的 conda 环境将被使用——它没有安装在 conda 环境中。
通过调用ipython kernel install将 jupyter 配置为使用 conda 环境作为内核.
缺点是:新建一个环境,就要重复操作一次。
3. pycharm中配置环境
用pycharm打开代码所在文件夹,配置解释器
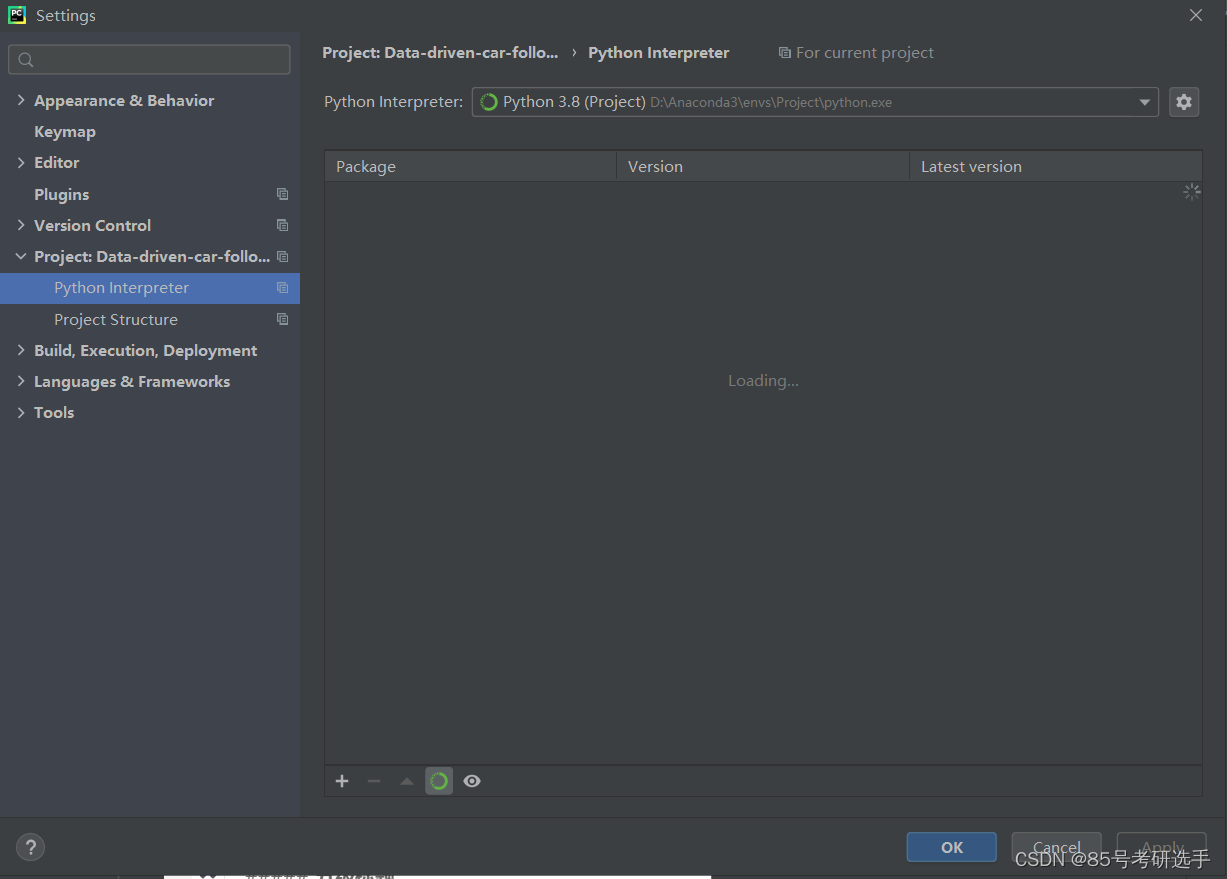

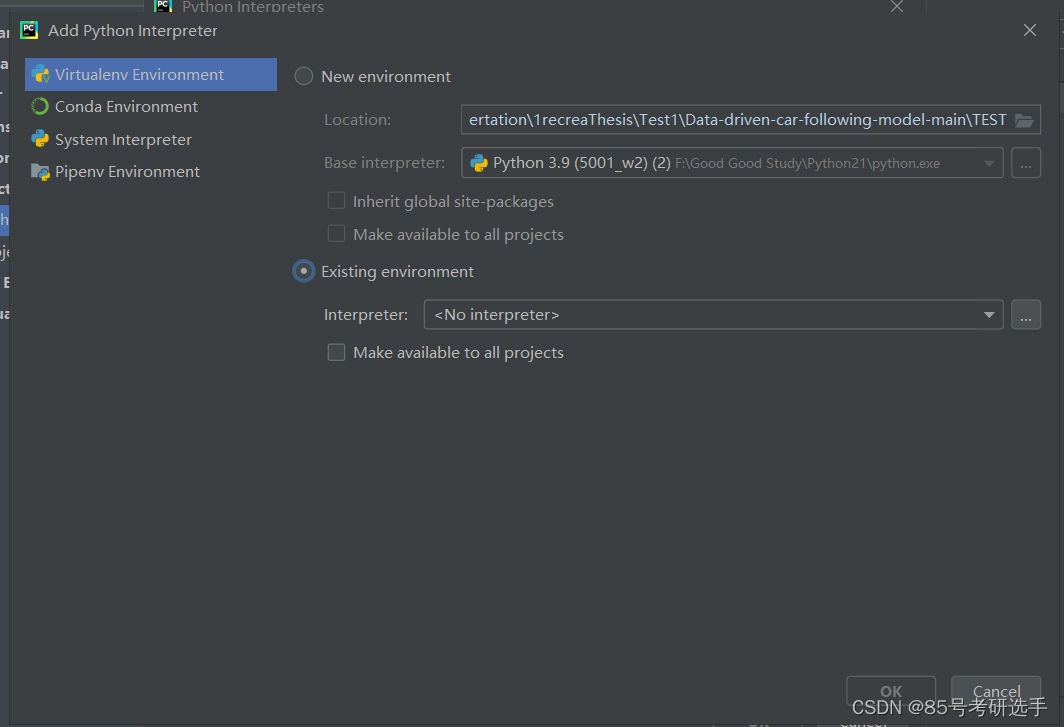
选择“existing environment”按钮,点击“…”
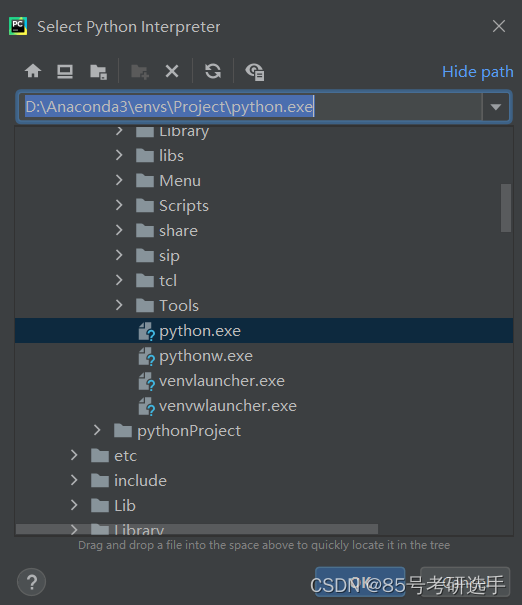
选择Project里面的Python.exe
利用jupyter打开指定文件夹的方法
参考链接是这个
在Windows 下打开到文件的位置,然后在该位置下,按住 shfit + 鼠标右键,选择在此处打开命令密口(W)
输入
jupyter notebook ./ # jupyter notebook 打开当前文件夹
pycharm和jupyter中的模块导入详解
参考这篇文章和这篇文章
最终我呈现的效果如下:
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
import sys,os
path_module = os.path.abspath(os.path.join('G:\\SEU\study_Python\\jupyter_file\\Data-driven-car-following-model-main\\datadrivencarfollowing-v1\\src'))
if path_module not in sys.path:
sys.path.append(path_module)
#import src
import Cleanup
import Transformation
import FileProcessing
