ActiveMQ 功能完善,性能相对差,社区文档很久不更新了,丢失可能低 万级QBS,毫秒延迟,主从高可用
RabbitMQ 基于erlang,扩展性差,社区活跃(中小企业用) 万级QBS,微妙延迟,主从高可用
RocketMQ 阿里开源,定制开发,社区相对活跃,参数化配置可做到0丢失,接口简单(非jms) 10w级QBS,毫秒延迟,分布式
Kafka 大数据类的系统做实时计算或者日志采集,功能较少(核心) 10w级QBS,毫秒延迟,分布式
苏宁 WindQ (HornetQ 的定制版) 在linux平台上直接调用操作系统的AIO
作用:
1,消峰(发送消息,慢慢处理请求)
2,异步(异步调用系统)
3,解耦(下发数据,其他系统选择性,消费)
问题:
1.增加系统复杂度和维护成本
2.消息重复消费(幂等性)
消息重复消费的主要原因在于回馈机制(RabbitMQ是ack,Kafka是offset)
消费者消费完消息后回复ack, 但是刚消费完还没来得及提交系统就重启了,这时候上来就pull消息的时候由于没有提交ack或者offset,消费的还是上条消息。
解决:
1.数据库唯一约束
2.redis 存记录标志,处理过就忽略
消息发送者发送消息时携带一个全局唯一的消息id
消费者获取消费后先根据id在redis/db中查询是否存在消费记录
如果没有消费过就正常消费,消费完毕后写入redis/db
如果消息消费过就直接舍弃
3.消息丢失(可靠性)
1).生产者丢失:发送消息的时候半途丢了,开启MQ事务机制,吞吐量下降,设置合理的重试次数
代码中增加消息表,定期扫描表,重试发送
发送给消息也要有生产者确认机制
2).MQ丢失:开启MQ的持久化
3).消费者丢失:收到消息没来得及消费宕机了,ack机制,自动确认消息改为手动确认
手动ack还有个问题,业务处理过了,断了,没有ack,这个时候就要设计业务代码为幂等性,防止重复处理
4.如何保证消息顺序性
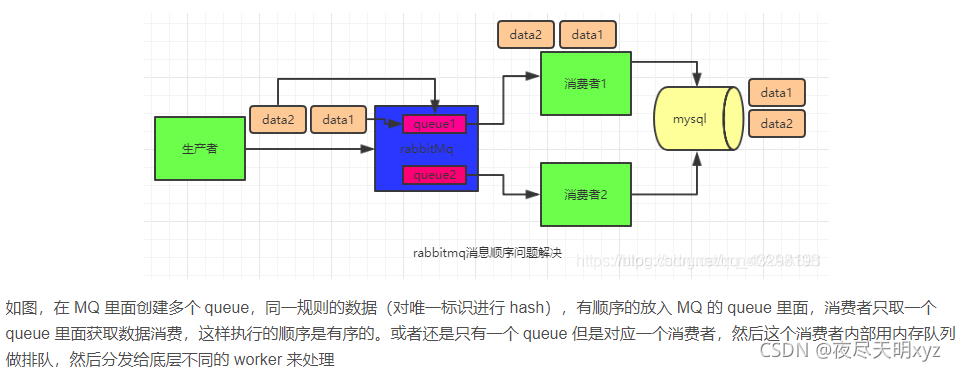
5.如何处理消息积压
消费者宕机
消费能力不足
发送者流量太大
1)临时紧急扩容

2)如果允许,则丢弃消息
https://blog.csdn.net/qq_43298198/article/details/106019759?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-0&spm=1001.2101.3001.4242
rabbitmq 延时队列
第一种

第二种 topic
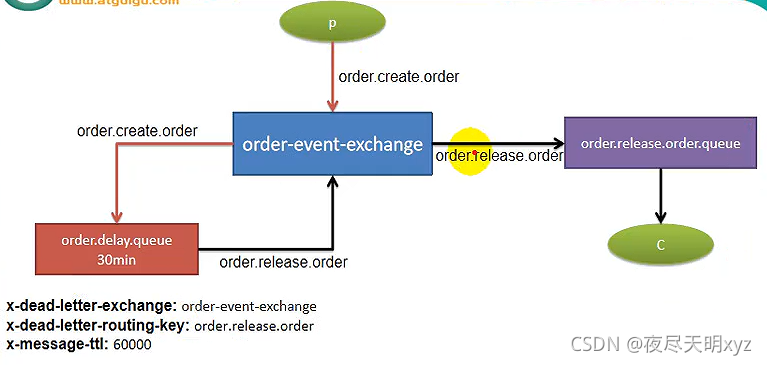
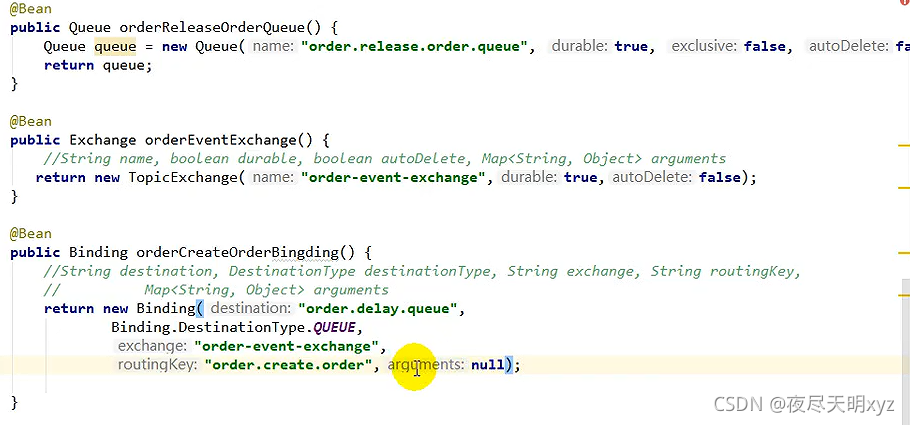
在java代码中MyMqConfig中创建2个队列,2个绑定和1个交换机,@Bean注入

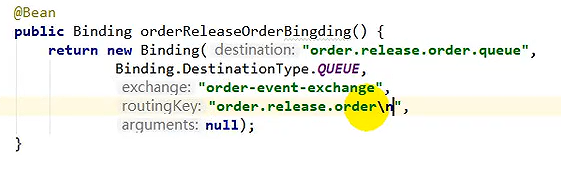
真正的解锁库存业务

@EnableRabbit
加配置文件
加自定义配置