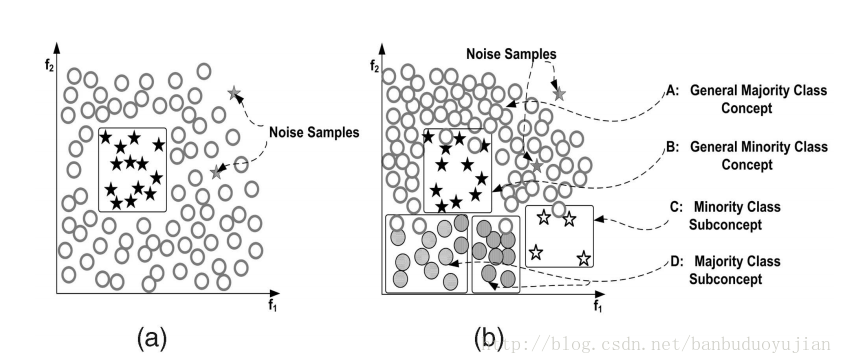
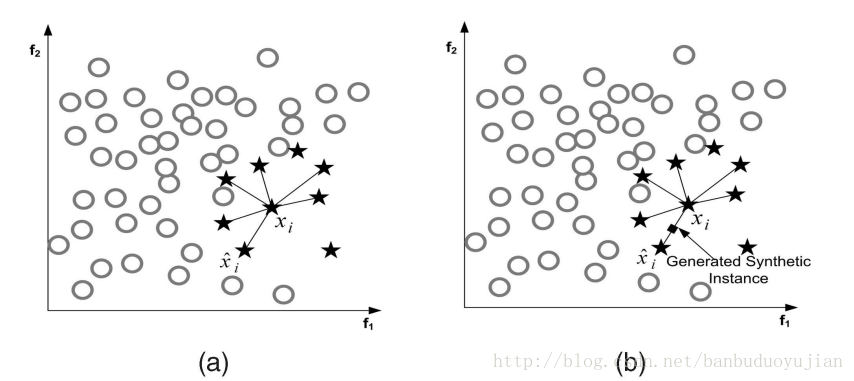
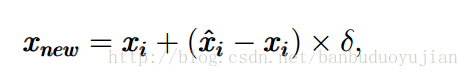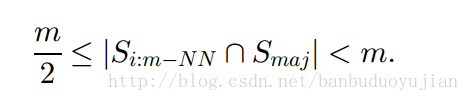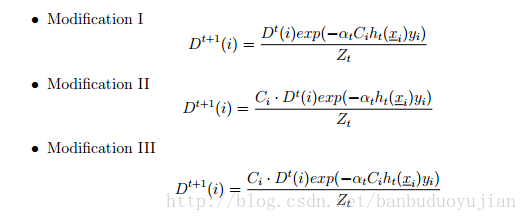本文分什么是非均衡数据、非均衡数据对算法的影响、怎样处理非均衡学习以及非均衡学习评估这四个方面进行叙述。在这里,正例或者星号代表多数类,负例或者圆圈代表少数类。 1、非均衡问题 非均衡问题有多重形式: (1)intrinsic:数据固有属性,数据集中的正负样本数目不太可能相等 (2)extrinsic:由于传输等外部问题造成的非均衡数据集 (3)relativ imbalanced:负例数量足够多,但相对于正例,负例相对较少 (4)absolute rarity:负例数量非常少,缺少数据 (5)within-class imbalanced:类内部不均衡问题 上图中存在的类型: a图:relativ imbalanced b图:relativ imbalanced、overlapping、underrepresentation 在图b中,如果对噪声也进行学习,可能会出现过拟合。 如果数据集本身很小且维度非常高,再加上非均衡分布问题,就可能出现以下情况: 其一、由于数据集非常小,与absolute rarity相关的问题都可能出现在小数据集里; 其二、数据集过小,可能使得模型失效,产生过拟合。 可以看出,过拟合有很多种情况:噪音、数据集过小、特征高维、训练测试集分布不一样、特征不相关、规则过于细化等都可能引起过拟合。 2、非均衡数据对算法的影响 一般说来,非均衡数据不利于算法学习,但在一些领域,某种程度的不均衡对算法的影响较小,甚至可以与抽样均衡数据相媲美。但对很多分类算法而言,由于非均衡数据的存在,分类器会使得正例的准确率接近100%,而负例的准确率只有0-10%。例如,在防流失项目中,正负例样本数目相差较大,而我们恰恰想让负例的预测准确率提高,因此我们就要对这种不均衡造成的影响进行消除。 3、非均衡问题的处理方法 3.1抽样方法 3.1.1 Random Oversampling and Undersampling 这里说下这两种方法的优缺点。 优点:方法简单,易于实现,能按照任何比例对原始数据集进行改造 缺点:Oversampling由于对原始的负例进行了复制,这就有可能导致分类器生成多个子规则对负例进行划分,从而造成规则过于细化,导致过拟合。 Undersampling由于从原始数据集中移除数据,可能会导致对正例学习出现缺失。 3.1.2 Synthetic Sampling with Data Generation SMOTE算法过程: (1)如图a所示,首先为每一个负例选择K=6个最近的负例 (2)从xi的负例中随机的选择一个,按下面的公式生成新的负例: 其中最后的伽马在[0,1]之间。 SMOTE算法克服了oversampling算法多次复制带来的缺陷,但SMOTE方法为原始数据集中的每一个负例产生相同个数的新负例,并没有考虑与原始负例相邻的正例,这就可能造成 类重叠问题(overlapping),因此有了Adaptive Synthetic Sampling 3.1.3 Adaptive Synthetic Sampling 该方法能够克服SMOTE算法可能造成的类重叠问题,这里介绍下Borderline-SMOTE算法 Borderline-SMOTE算法为每一个负例选出m个最近邻居,然后利用以下公式进行筛选: 其中|.|表示每个负例的m个最近邻与正例的交集。可以看出,如果交集个数小于0.5m或者等于m都会被过滤掉,不会进行后续的SMOTE方法。因为等于m说明该负例周围全是正例,所以该负例极有可能是噪音数据。只有位于正例与负例交接边缘的负例才会进行SMOTE算法。 3.1.4 Cluster-Based Sampling Method 基于聚类的重抽样方法的大概过程分为两步: (1)首先分别对正负例进行K-means聚类 (2)聚类之后进行Oversampling等系列方法 举例说明,假设我们运行K-means方法分别对正负例进行了聚类,结果如下: 正例三个簇,个数分别为:20 , 5, 12 负例两个簇,个数分别为:4 ,6 可以看出,正负例簇中个数最大的为20,所以正例其他两个簇通过oversampling都提高到20个实例,负例簇都提高到(20+20+20)/2=30 个实例。 最后变为,正例三个簇:20,20,20 负例两个簇:30,30 总结下这种基于聚类的抽样算法的优点: 该算法不仅可以解决类间不平衡问题,而且还能解决类内部不平衡问题。 3.2 Cost-Sensitive Methods\for Imbalanced Learning 这部分会涉及集成学习问题(Ensemble learning),在此简单说下集成学习问题。狭义上讲,集成学习是指多个一样的个体分类器共同参与决策,但这些分类器的参数不同。如bagging、boosting方法。广义上讲,只要使用多个分类器来解决问题就是集成学习。 集成学习的有效条件:其一、单一分类器的错误率都应当低于0.5,否则,集成学习反而会增加错误率。其二、个体分类器应该具有一定的差异。 对集成学习而言,个体分类器的生成方法有多种形式,例如基于样本处理法,基于特征选择方法,交叉验证法,随机扰动法等。这里简单介绍下boosting与bagging方法,这两种都是基于样本的处理方法。 (1)bagging方法:对原始数据集进行有放回抽样,得到k个数据集Di(i=1,2,,,,k),由每个Di训练一个分类器Mi。在分类时,每个Mi返回一个类预测,把的票最高的类标签作为预测结果。 可以看出:其一、bagging通过重新选取样本增加了个体分类器的差异,从而提高了模型的泛化能力。其二、bagging提高不稳定学习算法的效果明显,对稳定算法效果不明显,甚至使预测效果降低。 (2)Boosting算法 从理论上讲,即使弱分类器的效果比随机猜测好一点,boosting方法也可以使得最终错误率明显降低。boosting算法从不同的数据分布上学习不同的弱分类器,然后通过不同的策略组合这些弱分类器。在文献[2]指出,在弱分类器比较简单的情况下,boosting的效果要好于bagging。 为什么弱分类器通过boosting方法进行组合能够得到不错的效果呢?换句话说,boosting方法能够有什么好处呢?可能存在以下两种情况: 其一,boosting通过改变数据集的分布使得弱分类器更加关注“误分类”问题,从而提高这些“误分类”的准确率;弱分类对数据分布改变较为敏感,从而使得弱分类器体现出差异。boosting通过前面的模型对数据分布进行改变,这种改变就会体现在后续的模型中。 其二,boosting降低了bias与variance。为什么boosting能够降低bias,我觉得因为在生成子模型的过程中,模型会逐步加强对错分类的学习,从而使得整体的准确率上升,使得学习得到的弱分类器们能够越来越很好的拟合数据集,从而降低bias。为什么boosting能够降低variance呢?因为基于不同的数据分布,弱分类器之间呈现出差异性,从而防止过拟合,所以降低了variance。 [2]中提到了两种boosting算法,AdaBoost.M1和AdaBoost.M2。在此谈谈AdaBoost.M1算法,如下图所示: 可以看出,前一个弱分类器错误率越低,则数据分布改变强度越小;前一个弱分类器错误率越高,则数据分布改变程度越高。在最终确定类别时,错误率越低的分类器拥有越大的权重。 AdaBoost.M1主要的缺陷是它不能够处理错误率高于0.5的弱分类器,因此,在二分类中,要求正确率大于0.5相对较容易,但在多分类中,这一条件较难满足。下面谈谈为什么弱分类器错误率小于0.5,AdaBoost.M1算法可以明显降低总体错误率的理论依据,如下图所示: 3.2.1Cost-Sensitive Dataspace Weighting with Adaptive Boosting 既然抽样能够解决非均衡问题,那么我们为什么还要引入Cost-Sensitive learning呢?有以下几个原因: 其一、最佳的数据分布是难以知道的。其二、抽样的标准是不确定的。其三、undersampling 与 oversampling存在各自的缺陷。boosting可以通过权重更新策略,消除探索最佳的分布与探索具有代表性样本带来的额外开销。我们知道,AdaBoost本身会越来越重视误分类的实例,由于小样本经常被分错,所以在后续的算法中,弱分类器会加强对小样本的学习,从而使小样本的正确率提高。但是,相关研究表明,Adaboost对小样本的分类并不能令人满意。可能的原因是:AdaBoost算法是以总体准确率为导向的算法,因为多数类对总体准确率贡献较大,因此AdaBoost会偏向于尽可能把多数类分准确。因此,现在的问题是怎样对AdaBoost进行改造,使其更加偏向于我们感兴趣的少数类。 在Adaboost中,对所有正确分类的instance都以相同的比例降低权重,对所有的误分类实例都以相同的比例增加权重,不管这些被分类的实例是来自多数类还是少数类。在非均衡数据集中,由于少数类占得比重很小,即使少数类中多数被误分类,多数类少数被误分类,也可能在下一轮的弱分类学习时,多数类的总体权重仍然高于小数类的总体权重。因此,理想的boosting能够识别实例属于多数类还是少数类,并且增大少数类的误分类代价。因此,可以在Adaboost的权重更新策略中引入代价因子,有以下三种方式: (过完春节 再续) [1] Learning from Imbalanced Data [2] Experiments with a New Boosting Algorithm