一、xlrd库
1、工作簿(book)
(1) 创建工作簿对象
import xlrd
workbook=xlrd.open_workbook("文件路径")
2、工作表(sheet)
(1) 创建工作表对象
创建工作表的对象一般调用关于sheet的方法,一共有三种调用方式。
第一种:通过工作表索引创建
worksheet01=workbook.sheet_by_index(index)
第二种:通过工作表名称
worksheet02=workbook.sheet_by_name(sheet_name)
第三种:通过sheets()方法
worksheet03=workbook.sheets()[index]
worksheet03=workbook.sheets() #可以创建批量sheet对象
实例与结果:
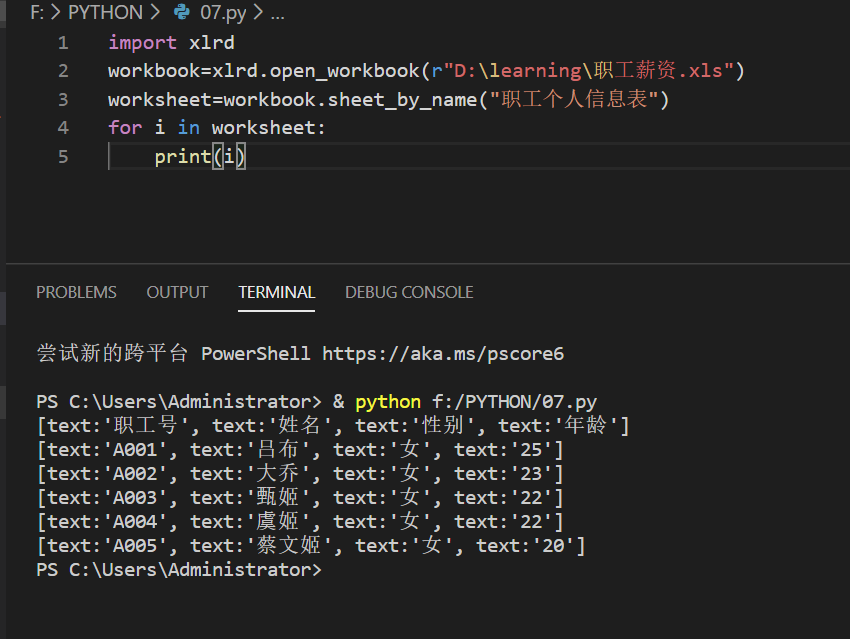
3、单元格(range)
(1)获取单个单元格的值(两种方法)
第一种:通过调用cell()方法中的value属性
cell_value01=worksheet.cell(row,clo).value
第二种:通过调用cell_value()方法
cell_value02=worksheet.cell_value(rowx= ,clox= )
实例与结果:
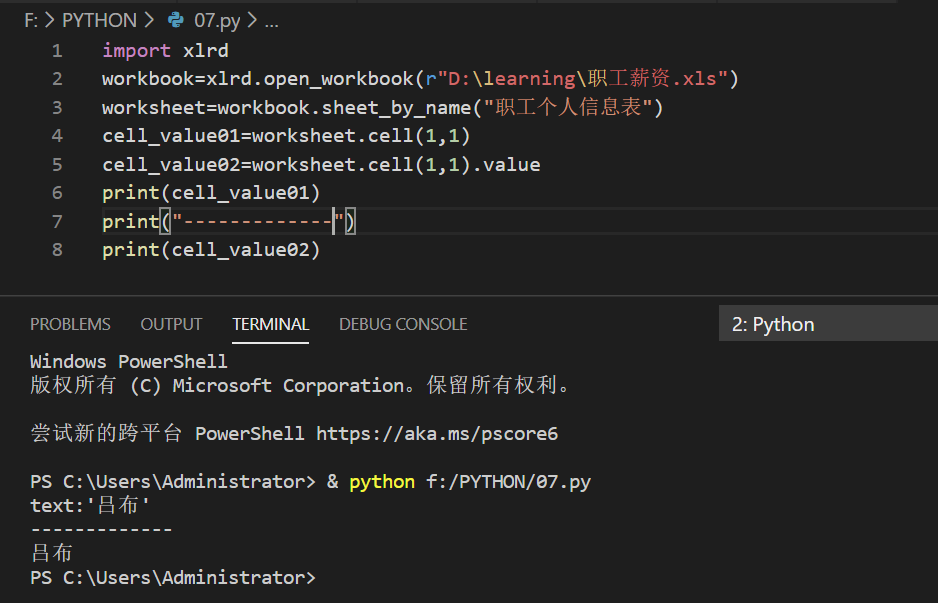
(2)获取单行或单列的值
获取单行的值:
row_value01=worksheet.row(行索引值) #通过调用row()方法
row_value01=worksheet.row_values(行索引值) #通过调用row_values()方法
获取单列的值:
clo_value01=worksheet.clo(列索引值) #通过调用clo()方法
clo_value02=worksheet.clo_values(列索引值) #通过调用clo_values()方法
实例与结果:
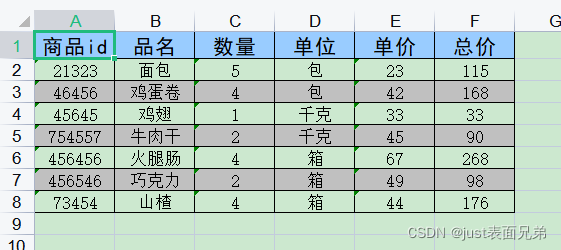
import xlrd
workbook=xlrd.open_workbook(r"D:\learning\商品销售表.xls")
worksheet=workbook.sheets()[0]
clo_value01=worksheet.col_values(0)
clo_value02=worksheet.col_values(5)
row_value01=worksheet.row_values(2)
row_value02=worksheet.row_values(5)
print("clo_value01:",clo_value01)
print("clo_value02:",clo_value01)
print("row_value01:",row_value01)
print("row_value02:",row_value02)

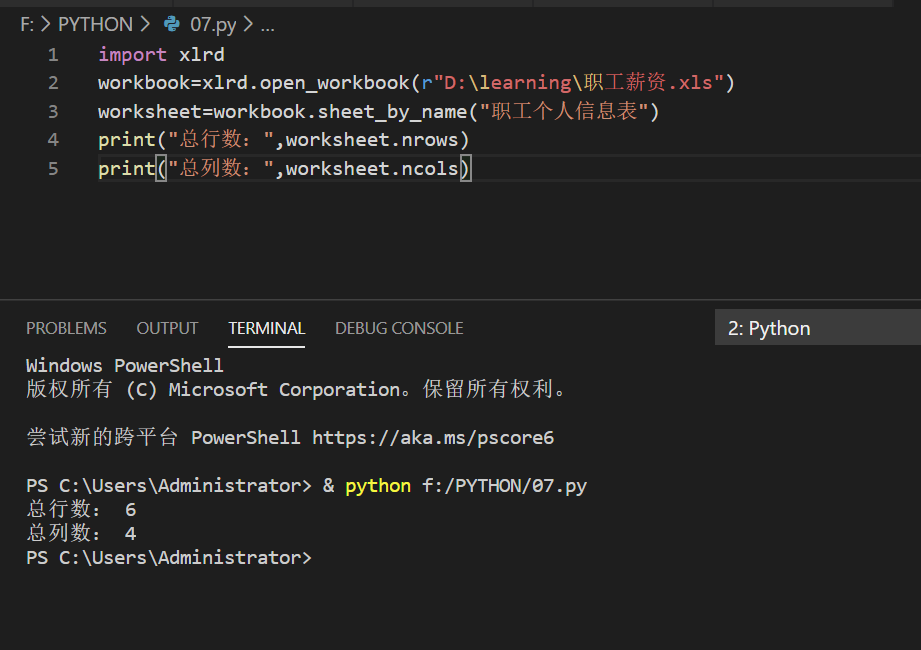
4、获取工作表中的总行列数
total_rows=worksheet.nrows #获取总行数
total_cols=worksheet.ncols #获取总列数
实例与结果:
二、xlwt库
1、工作簿(book)
(1)创建工作簿对象
import xlwt
workbook=xlwt.Workbook("文件路径")
(2)保存工作簿
workbook.save() #传参只能是地址,如有传参则是另存为,若无传参功能类似于保存
2、工作表(sheet)
(1)创建工作表对象
new_worksheet=workbook.add_sheet("工作表名称") #创建一个新的工作表,并将其返回给实例对象
注意⚠:
worksheet=workbook.sheets()[index/sheet_name] 此方法会报错哦!因为xlwt.Workbook中没有sheets()方法,因为不能使用xlwt库来创建已有的工作表
(2)写入数据
worksheet.write(row,clo,value) #通过write()方法将值写入指定的行列中
3、XFStyle风格样式
(1)Font(字体样式)
第一步:初始化XFStyle实例对象
import xlwt
style=xlwt.XFStyle()
第二步:创建属性对象
font=xlwt.Font() #通过调用Font()方法创建属性对象
第三步:对font的属性值初始化
font.name="宋体" #设置字体
font.blod=False/True #设置加粗
font.height= 字号*20 # 设置字体字号
第四步:将属性对象赋予给XFStyle对象中的font属性
style.font=font
第五步:将XFStyle实例对象写入工作表对象中
worksheet.write(row,clo,value,style)
(2)Borders(边界)
- 边框线粗细
borders.top= #设置上边框线大小
borders.bottom= #设置下边框线大小
borders.left= #设置左边框线大小
borders.right= #设置右边框线大小
- 边框线颜色
borders.top_colour= #设置上边框线颜色
borders.bottom_colour= #设置下边框线颜色
borders.left_colour= #设置左边框线颜色
borders.right_colour= #设置右边框线颜色
- 代码实例
import xlwt
style=xlwt.XFStyle()
borders=xlwt.Borders()
borders.left=1
borders.right_colour=33
style.borders=borders
worksheet.write(row,clo,value,style)
(3)Alignment(对齐)
- 属性介绍
| 属性代码 |
描述说明 |
alignment.vert = xlwt.Alignment.VERT_TOP |
水平方向—向上对齐 |
alignment.vert = xlwt.Alignment.VERT_CENTER |
水平方向—居中对齐 |
alignment.vert = xlwt.Alignment.VERT_BOTTOM |
水平方向—向下对齐 |
alignment.horz = xlwt.Alignment.HORZ_TOP |
垂直方向—向左对齐 |
alignment.horz = xlwt.Alignment.HORZ_CENTER |
垂直方向—居中对齐 |
alignment.horz = xlwt.Alignment.HORZ_BOTTOM |
垂直方向—向右对齐 |
- 代码实例
import xlwt
style=xlwt.XFStyle()
alignment=xlwt.Alignment() #创建alignment对象
alignment.vert=xlwt.Alignment.VERT_CENTER #设置文字水平居中
alignment.horz=xlwt.Alignment.HORZ_BOTTOM #设置文字垂直靠底部
style.alignment=alignment #将alignment对象直接赋给style对象的alignment属性
worksheet.write(row,clo,value,style) #将style写入对应的单元格中
(4)Pattern(模式)
- 属性介绍
pattern.pattern=xlwt.Pattern.SOLID_PATTERN #第一个pattern指的是对象,第二个pattern代表属性
pattern.pattern_fore_colour=33 #设置单元格背景颜色
- 代码实例
impotr xlwt
style=xlwt.XFStyle()
pattern=xlwt.Pattern()
pattern.pattern=xlwt.Pattern.SOLID_PATTERN #第一个pattern指的是对象,第二个pattern代表属性
pattern.pattern_fore_colour=33 #设置单元格背景颜色
style.pattern=pattern
worksheet.write(row,clo,value,style) #将style写入对应的单元格中
附加知识:设置行高列宽
1、设置列宽
worksheet.col(index).width=256*n #通过clo()方法中的width属性设置
2、设置行高
worksheet.row(index).height_mismatch=True #初始化数据
worksheet.row(index).height=n*m #通过row()方法中的height属性设置
三、xlwings库
1、Excel程序
(1)打开Excel程序
import xlwings as xw
app=xw.App(visible=True,add_book=False) #打开excel程序
#visible是界面可视属性,add_book代表是否新建一个工作簿
(2)退出Excel程序
app.quit #关闭excel程序
2、工作簿(book)
(1)创建工作簿对象
创建工作簿对象一共有两种方式,
第一种方式:在excel程序中添加新的工作簿或者打开已有工作簿,通过调用app对象,
new_workbook=app.book.add() #创建新的工作簿,无传参时直接新建一个工作簿
workbook=app.books.open("文件路径") #打开已有工作簿
第二种方式:通过调用xlwings库中的Book()方法
workbook=xw.Book("文件路径") #打开已有工作簿
(2)保存工作簿
workbook.save() #若填写地址参数则相当于另存为,若无地址参数则相当于保存
(3)关闭工作簿
workbook.close() #该操作把工作表都关闭,但是excel程序没有被关闭
(4)工作簿属性
- 获取工作簿路径:
workbook.fullname
- 获取工作簿名称:
workbook.name
-
3、工作表(sheet)
(1)创建工作表对象
worksheeet=workbook.sheets[index/sheet_name]
(2)批量创建工作表对象
worksheeet_list=workbook.sheets #返回此工作簿里所有的工作表
#print(worksheeet_list) ---------> Sheets([<Sheet [工作簿名称1.xlsx]工作表名称1>, ...,<Sheet [工作簿名称N.xlsx]工作表名称N>,])
# print(worksheeet_list[index].name) ---------> 工作表名称
(4)常用API
-
获取所有工作表:
listbook=workbook.sheets
-
打开原工作表:
sheet=workbook.sheets["工作表名称或索引位置"]
-
激活活动工作表:
sheet.activate()
-
表格清除:
sheet.clear() 清除内容和样式
sheet.clear_contents() 删除内容
sheet.delete() 删除工作簿
4、单元格(range)
(1)创建单元格对象
workcontent=worksheeet.range("单元格位置").value #参数可以是单个单元格也可以是个范围
#workcontent=worksheeet.range("A1:E1").value=['姓名','级别','学历','薪资','地区']
#workcontent=worksheeet.range("A1").value='姓名'
#workcontent=worksheeet.range("B1").value='级别'
(2)向单元格写入数据
写入单个数据:
workcontent=worksheeet.range("B2").value='级别'
workcontent=worksheeet.range("B2").value='=SUM(A1:A3)' # 输入公式,excel表中计算出结果
写入一行数据:
workcontent=worksheeet.range("A1:E1").value=['姓名','级别','学历','薪资','地区'] #向A1:E1写入数据
workcontent=worksheeet.range("A2").value=('姓名','级别','学历','薪资','地区') # 默认向A2:E3写入数据
workcontent=worksheeet.range('A1').options(transpose=True).value = ['姓名','安其拉','鲁西','狒狒'] #因为transpose的作用将数据转置,再向A2:A4写入数据
写入多行数据:
worksheet.range('a2').value=[['小A','男','三年一班'],
['小B','女','三年二班'],
['小C','女','三年一班'],
['小D','女','三年二班']] # 或者二维元组
worksheet.range('a2').value=df #传入DataFrame类型时,会直接将整个DataFrame表格数据直接写入
注意:不能写入集合,如果传入一个完整的字典时只会插入key。
fg.options(converter,ndim=None,dates=None,transpose=False,expand=None)
# converter:(object) 转换函数 dict、np.array、pd.DataFrame、pd.Series
# ndim:(int) 维度数
# dates:(type) ``datetime.date`` defaults to ``datetime.datetime``
# transpose:(Boolean) 是否转置
# expand:(str) 读取移动方向,table(向下向右)、down(向下)、right(向右)
(3) 读取表格中的数据
worksheet.range('a2').value # 返回A2单元格的数据
worksheet.range('a2:b8').value # 返回a2:b8单元格范围的数据,返回的类型为n元列表
worksheet.range('a2:b8').value.option(np.array,)
(4)获取有效内容的数据
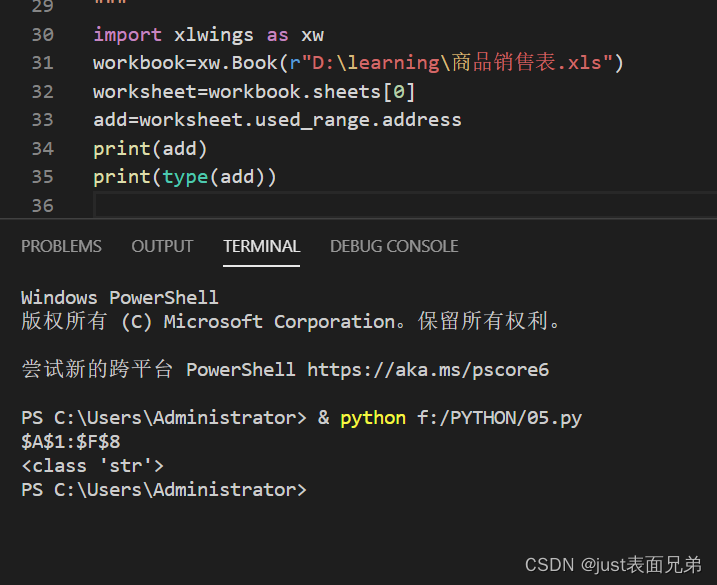
workdata=worksheeet.used_range.value #返回excel表格中有效的数据,并将数据封装成list类型
(5)获取表格有效内容的最后位置
workaddress=worksheeet.used_range.address #返回excel数据最后一个单元格的绝对地址,但是该地址为str类型
#如果要将绝对引用地址变为相对地址则需要对字符处理,worksheeet.used_range.address.replace("$","")
(6)灵活获取Range有效范围的内容
workdata=sheet.range('A2').expand('table').value # 从指定的A2开始获取有效内容
# 或
workdata=sheet.range('A2').options(expand='table').value
(7) 常用API
- 获取当前单元格对象或者单元格范围对象:
fg=sheet.range(范围)
- 获取单元格的行列标:
fg.row / fg.column
- 获取单元格的行高列宽:
fg.row_height / fg.column_width
- 单元格行高列宽自适应:
fg.rows.autofit() / fg.columns.autofit()
- 添加超链接/设定超链接:
fg.add_hyperlink(网址,显示名称,提示) / fg.hyperlink=www.baidu.com
- 获取单元格范围地址:
fg.get_address()
- 清除单元格的内容和格式:
fg.clear()
- 清除单元格的内容:
fg.clear_contents()
- 获取单元格背景颜色/设置单元格背景颜色:
fg.color / fg.color=(r,g,b)
- 合并单元格:
worksheet.range('A1:C6').api.Merge()
- 获取单元格公式:
fg.formula_array
- 在单元格内输入公式:
fg.formula='=公式'
- 单元格所在的行列:
#1.column的意义
column #返回所在的列标
columns #返回指定范围的列对象
fg.columns[下标] #取对应列的值并返回列对象
len(fg.columns) #返回列的长度
fg.column_width #返回所在列的列宽
#2.row的意义
row #返回所在的行标
rows #返回指定范围的行对象
fg.rows[下标] #取对应行的值并返回行对象
len(fg.rows) #返回行的长度
fg.row_width #返回所在行的列宽
#3.自动调节行高列宽
fg.autofit
四、pndas库
1、读取数据
语法: pandas.read_excel(io, sheet_name= 0, header= 0, names=None, index_col= None, usecols=None, squeeze= None, dtype= None, engine= None, converters=None, true_values= None, false_values= None, skiprows= None, nrows= None, na_values=None, keep_default_na= True, na_filter= True, verbose= False, parse_dates=False, date_parser=None, thousands= None, decimal= '.', comment= None, skipfooter= 0, convert_float= None, mangle_dupe_cols= True, storage_options= None)
功能描述: 读取文件的数据,支持的文件类型有xls、 xlsx、 xlsm、 xlsb、 odf、 ods 、odt
返回情况: 返回一个dataframe数据
参数说明:
io:文件路径
sheet_name:工作表 (可以传工作表名称、列表和index值)
header:指定工作表中哪一行作为dataframe的列名,如果不指定则传None
names:自定义dataframe的列名(会直接覆盖header)
index_col:指定dataframe数据中某列作为索引,可传入整数或列表
usecols:指定读取的列,默认None读取所有列,也可传入字符串 eg:“A:E"或"A,C”
squeeze:读取的数据如果是一列数据的话,设置True时会直接返回series类型,设置False时返回DataFrame类型
dtype:指定dataframe中数据的数据类型,一般用字典数据类型传入 eg:dtype={“age”:‘float’}
engine:设置读引擎,如果io参数中不是文件路径或缓冲器时,该值必须设置, {“xlrd”, “openpyxl”, “odf”, “pyxlsb”}
converters: 指定dataframe中数据的数据类型,一般用字典数据类型传入 {“name”:str,“sex”:str,“age”:float}
skiprow:设置跳过的行索引,即跳过几行开始读取数据
nrows:读取的数据的行数
keep_default_na:空内容是否默认为NaN
parse_dates:读取文件时按照指定的解析成日期格式的列
date_parser:读取数据时按照该设置解析成日期格式,{ True(解析成日期并作为结果的index),[index0,index1] 或 [‘column_name1’ ,‘column_name1’] (对指定列解析日期),[[0,1,2]] (对指定列的数据解析日期并组合成一列),{‘new_column_name’:[0,1,2] ((对指定列的数据解析日期并组合成一列,指定列名)}
后续工作中遇到再补充
2、写入数据
(1)写入至新文件
语法: df.to_excel(excel_writer, sheet_name= 'Sheet1', na_rep= '', float_format= None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options= None)
功能描述: 将DataFrame数据写入excel表中
返回情况: 无返回
参数说明:
excel_writer:文件路径或ExcelWriter对象
sheet_name:工作表名
na_rep:缺失数据的填充值,不写默认为空
float_format:浮点数据输出格式,eg:%.2f
columns:要写入excel的列,可传入列表、序列或字符串
header:设置excel的表头数据,可以传入布尔类型、列表或字符串,如果为True时,DataFrame数据的列名写入excel中;如果为False时,DataFrame数据的列名不写入excel中。
index:是否写入行索引
index_label:设置行索引的标签名称,需header和index都设置为False时才生效,如果是多级索引可传入列表
startrow:设置数据写入到excel的第几行,传入整数
startcol:设置数据写入到excel的第几列,传入整数
engine:设置写入引擎,openpyxl 或 xlsxwriter
merge_cells:是否合并单元格
encoding:设置编码方式
后续工作中遇到再补充
(2)写入至已有文件(ExcelWriter类)
1、创建ExcelWriter对象
语法: pandas.ExcelWriter(path, engine= None, date_format= None, datetime_format= None, mode= ‘w’, storage_options= None, if_sheet_exists= None, engine_kwargs: ‘dict | None’ = None, **kwargs)
功能描述: 创建一个ExcelWriter对象
返回情况: 返回一个ExcelWriter对象
参数说明:
path:文件路径 | WriteExcelBuffer |ExcelWriter
engine:设置写入引擎,{“xlsxwriter”,“openpyxl”} 如果为None则默认"io.excel..writer"
date_format:
datetime_format:
mode:设置写或追加模式,{‘w’, ‘a’}
storage_options:
if_sheet_exists:如果遇到sheet已存在时,需要如何处理,取值限制{'error'抛出异常, 'new'创建一个新的sheet, 'replace'删除原内容替换sheet, 'overlay'在原sheet中追加内容 }
engine_kwargs:传递给引擎的参数
ExcelWriter对象的属性及方法
引擎方法:ExcelWriter对象.engine
关闭ExcelWriter:ExcelWriter对象.close()
保存文件:ExcelWriter对象.save()
工作簿:ExcelWriter对象.book
2、写入数据
写入数据需要搭配to_excel
with pandas.ExcelWriter(path,mode='a') as w:
dataframe.to_excel(w,sheet_name='sheetname',index=False,header=False,startrow=2)
w.save()
案例:提取数据到指定模板中
顺便记录下在工作中遇到的一个难题,pandas 1.4版本之前是不能对已有的文件作不删除原内容的基础下追加内容。由于系统设计要求,导入功能只能导入一条数据否则会报错,所以需要导入大量数据时需将每一条数据提取出来放入导入模板才能导入(即每个导入文件中只有一条数据)(涉及全部数据及业务纯属虚构)

import pandas as pd,os,numpy
#def write_data:
file_list=os.listdir('D:\\源数据') # 数据从每个服务点报过来
n=0
for i in file_list:
filename='D:\\源数据\\'+i
data=pd.read_excel(filename,header=1)
print(i)
for j in range(len(data)):
if j==len(data)-1:
w_data=data[j-1:j]
else:
w_data=data[j:j+1]
p='D:\\目标数据\\'+str(n)+'.xlsx'
print('写完第%d个文件'%n)
n=n+1
with pd.ExcelWriter(p,mode='a',if_sheet_exists='overlay', engine="openpyxl") as writer: # engine默认xlwt处理xls文件, openpyxl处理xlsx文件
w_data.to_excel(writer,sheet_name='来穗信息数据',index=False,header=False,startrow=2)
writer.save()
五、openpyxl库
openpyxl 库相比其他库,可以查单元格样式
1、安装与导入
pip install openpyxl
2、工作簿
(1)实例化工作簿对象
语法: Workbook() | load_workbook(文件路径)
功能描述: 创建一个空的工作簿或读取实例化一个工作簿
返回情况: 返回一个工作簿对象
前置条件: from openpyxl import Workbook | from openpyxl import load_workbook
(2)保存文件
语法: 工作簿对象.save(文件路径)
功能描述: 保存工作簿
前置条件: 实例化工作簿对象
(3)其他方法
获取所有工作表的名字: 工作簿对象.sheetnames
获取所有工作表: 工作簿对象.worksheets
3、工作表
(1)工作表对象
语法: 工作簿对象.create_sheet(sheet_name) | 工作簿对象[sheet_name]
功能描述: 创建一个空的工作表或读取一个工作表
返回情况: 返回一个工作表对象
前置条件: 实例化工作簿对象
4、单元格
(1)数据添加
语法: 工作表对象.append(iterable)
功能描述: 向工作表添加数据
参数列表:
iterable:可迭代对象,一行添加
(2)读取数据
语法: 工作表对象.values | 工作表对象["单元格位置"]
功能描述: 向工作表添加数据
参数列表:
单元格位置:可以是单个单元格也可以是多个单元格 ,如:‘A1’:‘C2’、‘C:D’、5:10、
(3)cell方法
语法: 工作表对象.cell( row, column, value=None)
功能描述: 向工作表中指定的单元格添加或读取数据
参数列表:
row:行
column:列
value:添加的值
(4)应用案例
# 读取文件中的数据,讲带有指定背景颜色的单元格内容复制到指定单元格中
import openpyxl
wb=openpyxl.load_workbook(r"c:\Users\admin\Desktop\11.xlsx")
ws=wb["Sheet1"]
for r in ws.iter_rows():
for cell in r:
if cell.fill.fgColor.rgb=="FF00B050": # 背景颜色为绿色
r=cell.row
c=cell.column
ws.cell(r+2,c-2,cell.value)
elif cell.fill.fgColor.rgb=="FFFFC000": # 背景颜色为黄色
r=cell.row
c=cell.column
ws.cell(r+1,c-1,cell.value)
wb.save(r"c:\Users\admin\Desktop\11.xlsx")
附页
xlrd库 、xlwt库、 xlwings库三者区别
|
xlrd库 |
xlwt库 |
xlwings库 |
| 创建工作簿对象 |
open_workbook() |
Workbook() |
Book() / app.book.add() / app.books.open()
|
| 创建工作表对象 |
sheet_by_name() / sheet_by_index() / sheets()[ index] / 批量:sheets()
|
add_sheet() / 没有sheets |
sheets[index/sheet_name] / 批量: sheets
|
| 操作单元格对象 |
cell(row,clo).value / cell_value(rowx= ,clox= )
|
write(row,clo,value) |
range("单元格位置").value |