之前尝试了Python+selenium+unittest+HTMLTestRunner(传送门)写了登陆脚本,然后又看了参数化及循环,于是决定写个参数化的登陆脚本。当然遇到问题是在所难免的,几经周折,最后还是完成了参数化脚本。所以写下本帖记录一下,方便以后查阅。现在先来分析一下脚本出现的问题,一开始脚本是这样的:
#构建登陆类,用unittest框架,所以是unittest.testCase
class test(unittest.TestCase):
#构建登陆异常的方法
def test_login(self):
dr=webdriver.Chrome() #调用谷歌浏览器,其他浏览器更改drvier
#需要测试的网页
dr.get('https://passport.cnblogs.com/user/signin')
#构建参数化,格式为[[,,,],[,,,],[,,,]...[,,,],
#最外面[]里的每个[]为一条用例,每条用例的项用,隔开
user_pass=[['1','1','错误的用户名登陆','login_username_error','lblUserNameError',u'用户名错误!'],
['','123456','不输入用户名登陆','login_username_null','lblUserNameError',u'请输入用户名!'],
['testuser','1','错误的密码登陆','login_password_error','lblUserPwdError',u'密码错误'],
['1','','不输入密码登陆','login_username_null','lblUserPwdError',u'请输入密码!']]
#参数化定义变量,变量名自定义,数量为需要变量的数量
#最多不超过参数化的数量,顺序与定义参数化的值顺序一致
for (a,b,c,d,e,f) in user_pass:
#输入用户名,定义a在最前面,所以对应用例的一个值
#find_element_by_id里的值为网页抓取到的元素
dr.find_element_by_id('input1').send_keys(a)
#输入密码,b为参数化的密码
dr.find_element_by_id('input2').send_keys(b)
#点击登陆,click()为点击事件
dr.find_element_by_id('signin').click()
sleep(1)
print (c)#c为参数化的测试目的
#get_screenshot_as_file为截图方法,path为路径
#d为参数化的图片名
dr.get_screenshot_as_file(path+d+".jpg")
#先验证提示类型是否正确,e为会显示错误信息的id元素
assert dr.find_element_by_id(e).text,'提示信息类型错误!'
#如果提示类型正确,就会有错误信息,将错误信息赋值给定义的变量
error_message = dr.find_element_by_id(e).text
#asserEqual()是unittest框架中的一种断言,比较两个值是否相等
#f为参数化预期值
self.assertEqual(error_message,f)
#refresh()为浏览器刷新
dr.refresh()
脚本构建在这里,基本算是完成了,当然完整脚本还要加上import包,还有HTMLTestRunner框架生成报告。但是脚本运行的时候,只运行了一次,后面的参数化没运行。当时好郁闷,查阅各种资料,尝试简单的for循环,发现语句没有出现问题,可就是只运行了一次。然后我就找参数化的原因(也怪自己,想看异常结果,所以参数化故意写错,而且还是第一个),结果一改正,哈哈哈~~脚本跑起来了,原来在for循环的时候,出现错误或者预期与实际不匹配,循环就会结束,不会跳转到下一循环。
想象这样肯定是不行的,测试就是确认和验证预期结果与实际结果的比较,一不对就停止循环,无法实现自动化测试。于是就开始调试脚本,最后想到抛出异常(抛出异常后,即使错误脚本也会默认pass),所以脚本加入try...except...
于是脚本被改成了这样(为了报告更直观,所以加了大量的print显示):
......
try:
assert dr.find_element_by_id(e).text
try:
error_message = dr.find_element_by_id(e).text
self.assertEqual(error_message,f)
print('提示信息正确!预期值与实际值一致:')
print('预期值:'+f)
print('实际值:'+error_message)
except:
print ('提示信息错误!预期值与实际值不符:')
print ('预期值:'+e)
print('实际值:'+error_message)
except
print ('提示信息类型错误,请确认元素名称是否正确!')
脚本终于完善了,又发现之前参数化的内容,少了还好,多了维护起来就很不方便了,于是有想到了python可以读取csv文件,于是将参数文件格式改成这样:
#要读取的scv文件路径,my_file为自定义变量
my_file='C:\\Users\\Administrator\\Desktop\\login1.csv'
#csv.reader()读取csv文件,
#Python3.X用open,Python2.X用file,'r'为读取
#open(file,'r')中'r'为读取权限,w为写入,还有rb,wd等涉及到编码的读写属性
data=csv.reader(open(my_file,'r'))
#user[0]表示csv文件的第一列,user[1]表示第二列,user[N]表示第N列
新建excel文件按(
A列为用户名,B列为密码,C列为测试目的,D列为截图名称,E列为各元素id名,F列为预期值)格式写入用例内容(根据实际情况修改和变化位置),另存为逗号隔开的csv文件即可:

经过几次调整,终于一份完整的脚本写好了,以下就是完整的参数化脚本:
#coing=utf-8
import csv #导入scv库,可以读取csv文件
from selenium import webdriver
import unittest
from time import sleep
import time
import os
dr=webdriver.Chrome()
class test(unittest.TestCase):
def test_login(self):
'''登陆测试'''
#要读取的scv文件路径
my_file='C:\\Users\\Administrator\\Desktop\\login1.csv'
#csv.reader()读取csv文件,
#Python3.X用open,Python2.X用file,'r'为读取
#open(file,'r')中'r'为读取权限,w为写入,还有rb,wd等涉及到编码的读写属性
data=csv.reader(open(my_file,'r'))
#for循环将读取到的csv文件的内容一行行循环,这里定义了user变量(可自定义)
#user[0]表示csv文件的第一列,user[1]表示第二列,user[N]表示第N列
#for循环有个缺点,就是一旦遇到错误,循环就停止,所以用try,except保证循环执行完
for user in data:
dr.get('https://passport.cnblogs.com/user/signin')
#dr.find_element_by_id('input1').clear()
dr.find_element_by_id('input1').send_keys(user[0])
#dr.find_element_by_id('input2').clear()
dr.find_element_by_id('input2').send_keys(user[1])
dr.find_element_by_id('signin').click()
sleep(1)
print ('\n'+'测试项:'+user[2])
dr.get_screenshot_as_file(path+user[3]+".jpg")
try:
assert dr.find_element_by_id(user[4]).text
try:
error_message = dr.find_element_by_id(user[4]).text
self.assertEqual(error_message,user[5])
print('提示信息正确!预期值与实际值一致:')
print('预期值:'+user[5])
print('实际值:'+error_message)
except:
print ('提示信息错误!预期值与实际值不符:')
print ('预期值:'+user[5])
print('实际值:'+error_message)
except:
print ('提示信息类型错误,请确认元素名称是否正确!')
def tearDown(self):
dr.refresh()
if __name__=='__main__':
#导入HTMLTestRunner库,这句也可以放在脚本开头
from HTMLTestRunner import HTMLTestRunner
#定义脚本标题,加u为了防止中文乱码
report_title = u'登陆模块测试报告'
#定义脚本内容,加u为了防止中文乱码
desc = u'登陆模块测试报告详情:'
#定义date为日期,time为时间
date=time.strftime("%Y%m%d")
time=time.strftime("%Y%m%d%H%M%S")
#定义path为文件路径,目录级别,可根据实际情况自定义修改
path= 'D:/Python_test/'+ date +"/login/"+time+"/"
#定义报告文件路径和名字,路径为前面定义的path,名字为report(可自定义),格式为.html
report_path = path+"report.html"
#判断是否定义的路径目录存在,不能存在则创建
if not os.path.exists(path):
os.makedirs(path)
else:
pass
#定义一个测试容器
testsuite = unittest.TestSuite()
#将测试用例添加到容器
testsuite.addTest(test("test_login"))
#将运行结果保存到report,名字为定义的路径和文件名,运行脚本
with open(report_path, 'wb') as report:
runner = HTMLTestRunner(stream=report, title=report_title, description=desc)
runner.run(testsuite)
#关闭report,脚本结束
report.close()
#关闭浏览器
dr.quit()
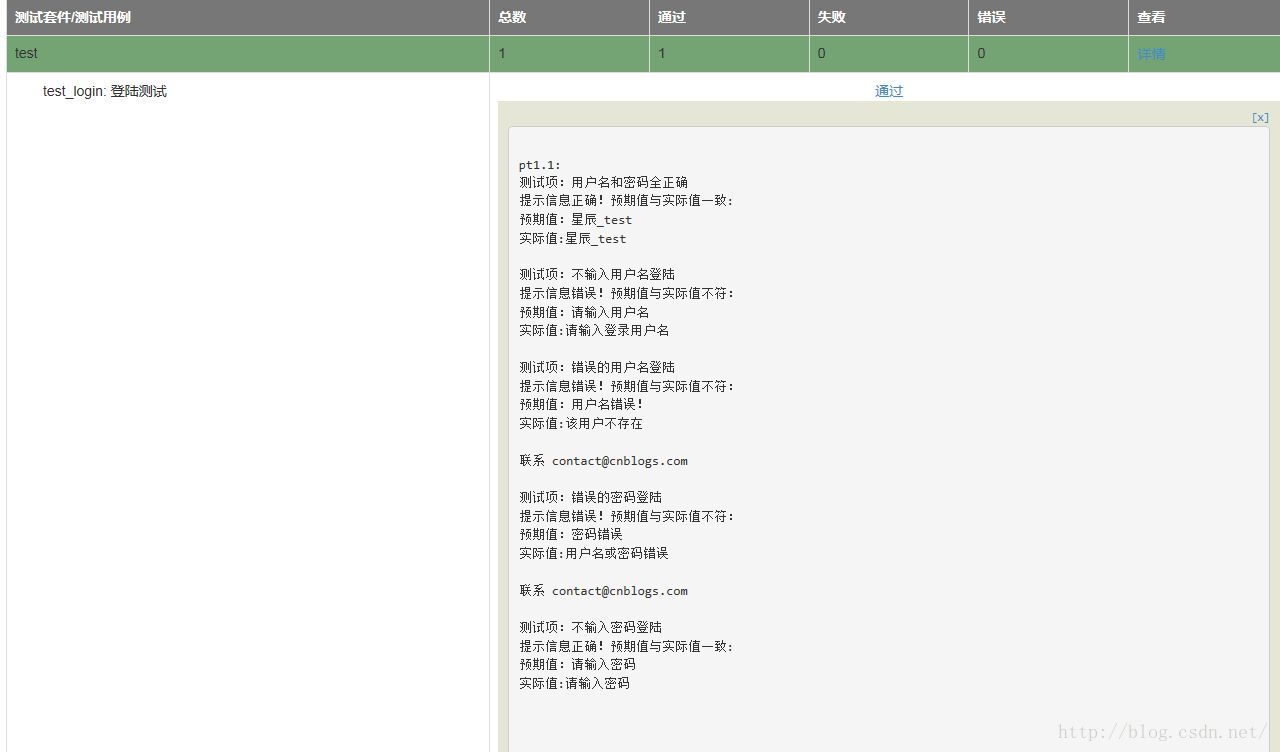
效果图(还是很一目了然的~哈哈哈哈~~~):