本文为翻译官网“Aggregations”部分但有一定改动之后的文章
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.3/search-aggregations.html
聚合框架帮助提供基于搜索查询的聚合数据。它基于称为聚合的简单构建块,可以组合这些构建块来构建数据的复杂摘要。
聚合可以看作是在一组文档上构建分析信息的工作单元。执行的上下文定义了这个文档集是什么(例如,在搜索请求的已执行查询/过滤器的上下文中执行顶级聚合)。
有许多不同类型的聚合,每种聚合都有自己的目的和输出。为了更好地理解这些类型,通常更容易将它们分为四个主要家族:
Bucketing(桶聚合)
一组构建桶的聚合,其中每个桶与一个键和一个文档标准相关联。在执行聚合时,将对上下文中的每个文档评估所有桶条件,当一个条件匹配时,将认为该文档“落入”相关桶。在聚合过程结束时,我们将得到一个桶列表——每个桶都有一组“属于”它的文档。
Metric(指标聚合)
在一组文档上跟踪和计算度量的聚合。
Matrix(矩阵聚合)
一组聚合,对多个字段进行操作,并根据从请求的文档字段中提取的值生成矩阵结果。与度量和桶聚合不同,这个聚合系列还不支持脚本。
Pipeline(管道聚合)
聚合其他聚合的输出及其相关指标的聚合。即可对其他聚合的结果进行操作
接下来是有趣的部分。由于每个桶有效地定义了一个文档集(属于该桶的所有文档),因此可以在桶级别上关联聚合,并且这些聚合将在该桶的上下文中执行。这就是聚合的真正威力所在:聚合可以嵌套!
桶状聚合可以有子聚合(桶状或度量)。子聚合将针对其父聚合生成的桶进行计算。嵌套聚合的级别/深度没有硬性限制(可以将聚合嵌套在“父”聚合下,父聚合本身是另一个更高级别聚合的子聚合)。
聚合对数据的双重表示进行操作。因此,当运行在绝对值大于2^53时,结果可能是近似的。
如何构建聚合
下面的代码片段捕获了聚合的基本结构:
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
JSON中的
aggregations使用键aggs保存要计算的聚合。每个聚合都与用户定义的逻辑名称相关联(例如,如果聚合计算平均价格,则将其命名为avg_price是有意义的)。这些逻辑名称还将用于惟一地标识响应中的聚合。每个聚合都有一个特定的类型(在上面的代码片段中<aggregation_type>),通常是命名的聚合体中的第一个键。每种类型的聚合都定义了自己的主体,这取决于聚合的性质(例如,特定字段上的平均聚合将定义计算平均值的字段)。在聚合类型定义的同一级别上,可以有选择地定义一组附加的聚合,不过,这只有在您定义的聚合具有桶的性质时才有意义。在这种情况下,您在桶聚合级别上定义的子聚合将为由桶聚合构建的所有桶计算。例如,如果在范围聚合下定义了一组聚合,则将为所定义的范围桶计算子聚合。
聚合的值来源
有些聚合处理从聚合文档中提取的值。通常,值将从使用聚合字段键设置的特定文档字段中提取。也可以定义一个脚本来生成值(每个文档)。
当为聚合配置了字段和脚本设置时,脚本将被视为值脚本。普通脚本是在文档级别上评估的(即脚本可以访问与文档相关的所有数据),而值脚本是在值级别上评估的。在这种模式下,从配置的字段中提取值,脚本用于对这些值/秒应用“转换”。
在使用脚本时,还可以定义lang和params设置。前者定义了所使用的脚本语言(假设Elasticsearch中有适当的语言,可以默认使用,也可以作为插件使用)。后者支持将脚本中的所有“动态”表达式定义为参数,这使得脚本在调用之间保持自身静态(这将确保使用Elasticsearch中缓存的编译脚本)。Elasticsearch使用映射中的字段类型来确定如何运行聚合并格式化响应。然而,在两种情况下Elasticsearch无法找出这些信息:未映射的字段(例如跨多个索引的搜索请求,其中只有一些字段有字段的映射)和纯脚本。对于这些情况,可以使用value_type选项给Elasticsearch一个提示,它接受以下值:string、long(适用于所有整数类型)、double(适用于所有小数类型,如float或scaled_float)
该系列中的聚合基于从正在聚合的文档中以某种方式提取的值来计算度量。值通常从文档的字段中提取(使用字段数据),但也可以使用脚本生成。
数值度量聚合是一种特殊类型的度量聚合,它输出数值。一些聚合输出单个数值度量(如avg),被称为单值数值度量聚合,其他聚合生成多个度量(如stats),被称为多值数值度量聚合。当这些聚合作为某些桶聚合的直接子聚合(一些桶聚合允许您根据数值指标对返回的桶进行排序)时,单值和多值数值度量聚合之间的区别就发挥了作用
一个单值度量聚合,用于计算从聚合文档中提取的数值的平均值。这些值可以从文档中的特定数值字段中提取,也可以由提供的脚本生成。
假设数据由代表学生考试成绩(0到100之间)的文档组成,我们可以用以下方法平均他们的分数:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : { "avg" : { "field" : "grade" } }
}
}
上面的聚合计算了所有文档的平均等级。聚合类型是avg,字段设置定义了计算平均值的文档的数字字段。上述操作将返回以下内容:
{
...
"aggregations": {
"avg_grade": {
"value": 75.0
}
}
}
聚合的名称(上面的avg_grade)也可以作为键,通过该键可以从返回的响应中检索聚合结果。
使用脚本
根据脚本计算平均分数:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"source" : "doc.grade.value"
}
}
}
}
}
这将使用简单的脚本语言将脚本参数解释为内联脚本,并且没有脚本参数。要使用存储脚本,请使用以下语法:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"id": "my_script",
"params": {
"field": "grade"
}
}
}
}
}
}
上面的my_script为已经存储在ES的脚本。
值脚本
结果证明,考试成绩远远超出了学生的水平,需要进行评分修正。我们可以使用值脚本来获得新的平均值:
POST /exams/_search?size=0
{
"aggs" : {
"avg_corrected_grade" : {
"avg" : {
"field" : "grade",
"script" : {
"lang": "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}
Missing value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /exams/_search?size=0
{
"aggs" : {
"grade_avg" : {
"avg" : {
"field" : "grade",
"missing": 10
}
}
}
}
在grade字段中没有值的文档将与值为10的文档归入同一个bucket。即将没有值的文档的值视为10
一个单值度量聚合,用于计算从聚合文档中提取的数值的加权平均值。这些值可以从文档中的特定数值字段中提取。
在计算常规平均值时,每个数据点都有相同的“权重”……它对最终值的贡献相同。另一方面,加权平均对每个数据点的权重不同。每个数据点对最终值的贡献量从文档中提取,或由脚本提供。
加权平均值为∑(值*权值)/∑(权值)
常规平均值可以被认为是加权平均值,其中每个值的隐含权重为1。
weighted_avg参数:
value:
提供值的字段或脚本的配置
必选
weight:
提供权重的字段或脚本的配置
必选
format:
数字响应格式化程序
可选
value_type
关于纯脚本或未映射字段的值的提示
可选
value和weight对象具有每个字段特定的配置:
value参数:
field
应该从中提取值的字段
必选
missing
如果字段完全缺失,则使用该值
可选
weight参数:
field
应该从中提取权重的字段
必选
missing
如果字段完全缺失,则使用权重
可选
如果我们的文档有一个“grade”字段,包含0-100的数字分数,和一个“weight”字段,包含一个任意的数字权重,我们可以使用以下方法计算加权平均值:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
这将产生如下的响应:
{
...
"aggregations": {
"weighted_grade": {
"value": 70.0
}
}
}
虽然每个字段允许多个值,但只允许一个权重。如果聚合遇到一个有多个权重的文档(例如,权重字段是一个多值字段),它将抛出异常。如果遇到这种情况,您将需要为权重字段指定一个脚本,并使用该脚本将多个值组合为要使用的单个值。
这个权重将独立应用于从值字段中提取的每个值。
下面的例子展示了一个有多个值的文档如何用一个权重取平均:
POST /exams/_doc?refresh
{
"grade": [1, 2, 3],
"weight": 2
}
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
这三个值(1、2和3)将作为独立的值被包含,它们的权重都是2:
{
...
"aggregations": {
"weighted_grade": {
"value": 2.0
}
}
}
聚合返回2.0作为结果,这与我们手工计算时所期望的结果相匹配:
((1*2) + (2*2) + (3*2)) / (2+2+2) == 2
使用脚本
值和权重都可以从脚本派生,而不是从字段派生。作为一个简单的例子,下面将使用脚本向文档中的grade和weight添加1:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"script": "doc.grade.value + 1"
},
"weight": {
"script": "doc.weight.value + 1"
}
}
}
}
}
Missing value
missing参数定义了如何处理缺少值的文档。value和weight的默认行为是不同的:
默认情况下,如果缺少值字段,则忽略文档,并将聚合转移到下一个文档。如果缺少权重字段,则假定其权重为1(与正常平均值类似)。
这两个默认值都可以被missing参数覆盖:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade",
"missing": 2
},
"weight": {
"field": "weight",
"missing": 3
}
}
}
}
}
计算不同值的近似计数的单值度量集合。值可以从文档中的特定字段提取,也可以由脚本生成。
假设您正在索引商店销售情况,并希望计算与查询匹配的已销售产品的唯一数量:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type"
}
}
}
}
响应:
{
...
"aggregations" : {
"type_count" : {
"value" : 3
}
}
}
精度控制
这个聚合也支持precision_threshold选项:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type",
"precision_threshold": 100
}
}
}
}
precision_threshold选项允许以内存换取准确性,并定义了一个唯一的计数,低于该计数将接近于准确。超过这个值,计数可能会变得更加模糊。最大支持的值是40000,超过这个数字的阈值与40000的阈值具有相同的效果。默认值是3000。
计数是近似的
计算精确的计数需要将值加载到散列集中并返回其大小。这在处理高基数集and/or值时无法扩展,因为所需的内存使用以及在节点之间通信这些每个碎片集的需求会占用太多集群资源。
这种基数聚合基于hyperloglog++算法,该算法基于具有一些有趣属性的值的哈希值进行计数:
对于c的精度阈值,我们使用的实现大约需要c * 8字节。
下图显示了在阈值之前和之后误差的变化情况:
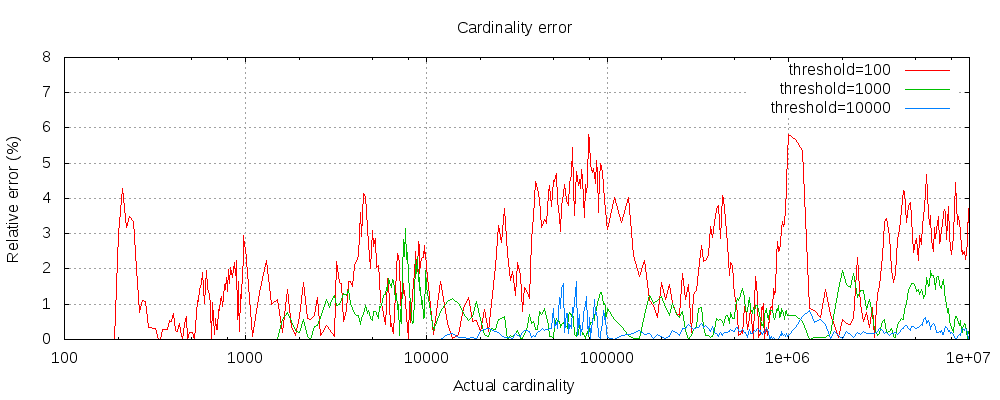
对于所有3个阈值,计数已经精确到配置的阈值。虽然不能保证,但情况很可能就是这样。实践中的准确性取决于所讨论的数据集。一般来说,大多数数据集始终表现出良好的准确性。还要注意,即使阈值低至100,即使在计算数百万项时,误差仍然非常低(如上图所示,误差为1-6%)。
hyperloglog++算法依赖于哈希值的前导零,数据集中哈希值的准确分布会影响基数的准确性。
还请注意,即使阈值低至100,即使在计算数百万项时,误差仍然非常低。
预先计算散列
对于基数较高的字符串字段,在索引中存储字段值的散列,然后在该字段上运行基数聚合可能更快。这可以通过从客户端提供哈希值来实现,也可以通过使用mapper-murmur3插件让Elasticsearch为您计算哈希值来实现。
预计算哈希通常只在非常大和/或高基数字段上有用,因为它节省CPU和内存。然而,在数字字段上,哈希非常快,存储原始值所需的内存与存储哈希值相同或更少。对于低基数的字符串字段也是如此,特别是考虑到这些字段有一个优化,以确保每个段的每个唯一值最多计算一次哈希值。
使用脚本
基数度量支持脚本,但是由于散列需要动态计算,因此性能受到了明显的影响。
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script": {
"lang": "painless",
"source": "doc['type'].value + ' ' + doc['promoted'].value"
}
}
}
}
}
这将使用简单的脚本语言将脚本参数解释为内联脚本,并且没有脚本参数。要使用存储脚本,请使用以下语法:
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script" : {
"id": "my_script",
"params": {
"type_field": "type",
"promoted_field": "promoted"
}
}
}
}
}
}
Missing value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /sales/_search?size=0
{
"aggs" : {
"tag_cardinality" : {
"cardinality" : {
"field" : "tag",
"missing": "N/A"
}
}
}
}
tag段中没有值的文档将与值为N/A的文档归入同一个bucket。
一个多值度量聚合,计算从聚合文档中提取的数值的统计信息。这些值可以从文档中的特定数值字段中提取,也可以由提供的脚本生成。
extended_stats聚合是统计聚合的扩展版本,其中添加了额外的指标,如sum_of_squares平方和、variance方差、std_deviation标准差和std_deviation_bounds标准差界限。
假设数据由表示学生考试成绩(0到100)的文档组成
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : { "extended_stats" : { "field" : "grade" } }
}
}
上述聚合计算所有文档的等级统计信息。聚合类型是extended_stats,字段设置定义了计算统计数据的文档的数字字段。上述操作将返回以下内容:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0,
"sum_of_squares": 12500.0,
"variance": 625.0,
"std_deviation": 25.0,
"std_deviation_bounds": {
"upper": 125.0,
"lower": 25.0
}
}
}
}
聚合的名称(上面的grades_stats)还可以作为键,通过该键可以从返回的响应中检索聚合结果。
标准差界限
默认情况下,extended_stats指标将返回一个名为std_deviation_bounds的对象,它提供了一个距离平均值正负两个标准偏差的间隔。这可能是可视化数据方差的有用方法。如果你想要一个不同的边界,例如三个标准差,你可以在请求中设置sigma:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"field" : "grade",
"sigma" : 3
}
}
}
}
Sigma控制从平均值显示多少个正/负标准差
Sigma可以是任何非负的双精度,这意味着你可以要求非整数值,比如1.5。0值是有效的,但只返回上界和下界的平均值。
标准偏差和边界要求正态
默认情况下会显示标准偏差及其边界,但它们并不总是适用于所有数据集。数据必须是正态分布的,这样度量才有意义。标准差背后的统计数据假设正态分布数据,因此如果数据严重向左或向右倾斜,则返回的值将具有误导性。
使用脚本
基于脚本计算成绩统计:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"script" : {
"source" : "doc['grade'].value",
"lang" : "painless"
}
}
}
}
}
这将使用painless脚本语言将脚本参数解释为inline脚本,并且没有脚本参数。要使用存储脚本,请使用以下语法:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"script" : {
"id": "my_script",
"params": {
"field": "grade"
}
}
}
}
}
}
值脚本
结果证明,考试成绩远远超出了学生的水平,需要进行评分修正。我们可以使用value脚本来获取新的统计数据:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"field" : "grade",
"script" : {
"lang" : "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}
Missing value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"field" : "grade",
"missing": 0
}
}
}
}
在grade字段中没有值的文档将与值为0的文档归入同一个bucket。
一个度量聚合,用于计算包含字段的所有geo_point值的边界框。
例如:
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "52.374081,4.912350", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "52.369219,4.901618", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "52.371667,4.914722", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "51.222900,4.405200", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "48.861111,2.336389", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "48.860000,2.327000", "name": "Musée d'Orsay"}
POST /museums/_search?size=0
{
"query" : {
"match" : { "name" : "musée" }
},
"aggs" : {
"viewport" : {
"geo_bounds" : {
"field" : "location",
"wrap_longitude" : true
}
}
}
}
geo_bounds聚合指定用于获取边界的字段
Wrap_longitude是一个可选参数,用于指定是否允许边界框与国际日期变更线重叠。默认值为true
以上聚合的响应:
{
...
"aggregations": {
"viewport": {
"bounds": {
"top_left": {
"lat": 48.86111099738628,
"lon": 2.3269999679178
},
"bottom_right": {
"lat": 48.85999997612089,
"lon": 2.3363889567553997
}
}
}
}
}
从地理点场的所有坐标值计算加权质心的度量聚合。
例如:
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "52.374081,4.912350", "city": "Amsterdam", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "52.369219,4.901618", "city": "Amsterdam", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "52.371667,4.914722", "city": "Amsterdam", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "51.222900,4.405200", "city": "Antwerp", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "48.861111,2.336389", "city": "Paris", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "48.860000,2.327000", "city": "Paris", "name": "Musée d'Orsay"}
POST /museums/_search?size=0
{
"aggs" : {
"centroid" : {
"geo_centroid" : {
"field" : "location"
}
}
}
}
geo_centroid聚合指定用于计算质心的字段。(注:字段必须是Geo-point类型)
以上聚合的响应:
{
...
"aggregations": {
"centroid": {
"location": {
"lat": 51.00982965203002,
"lon": 3.9662131341174245
},
"count": 6
}
}
}
geo_centroid聚合在作为子聚合组合到其他桶聚合时更有趣。
例如:
POST /museums/_search?size=0
{
"aggs" : {
"cities" : {
"terms" : { "field" : "city.keyword" },
"aggs" : {
"centroid" : {
"geo_centroid" : { "field" : "location" }
}
}
}
}
}
上面的示例使用geo_centroid作为术语桶聚合的子聚合,用于查找每个城市中博物馆的中心位置。
以上聚合的响应:
{
...
"aggregations": {
"cities": {
"sum_other_doc_count": 0,
"doc_count_error_upper_bound": 0,
"buckets": [
{
"key": "Amsterdam",
"doc_count": 3,
"centroid": {
"location": {
"lat": 52.371655656024814,
"lon": 4.909563297405839
},
"count": 3
}
},
{
"key": "Paris",
"doc_count": 2,
"centroid": {
"location": {
"lat": 48.86055548675358,
"lon": 2.3316944623366
},
"count": 2
}
},
{
"key": "Antwerp",
"doc_count": 1,
"centroid": {
"location": {
"lat": 51.22289997059852,
"lon": 4.40519998781383
},
"count": 1
}
}
]
}
}
}
一个单值指标聚合,用于跟踪并返回从聚合文档中提取的数值中的最大值。这些值可以从文档中的特定数值字段中提取,也可以由提供的脚本生成。
最小和最大聚合作用于数据的双重表示。因此,当运行在绝对值大于2^53时,结果可能是近似的。
计算所有文档的最大价格值
POST /sales/_search?size=0
{
"aggs" : {
"max_price" : { "max" : { "field" : "price" } }
}
}
响应:
{
...
"aggregations": {
"max_price": {
"value": 200.0
}
}
}
可以看到,聚合的名称(上面的max_price)还可以作为键,通过该键可以从返回的响应中检索聚合结果。
使用脚本
max聚合还可以计算脚本的最大值。下面的例子计算了最高价格:
POST /sales/_search
{
"aggs" : {
"max_price" : {
"max" : {
"script" : {
"source" : "doc.price.value"
}
}
}
}
}
这将使用Painless脚本语言,没有脚本参数。要使用存储脚本,请使用以下语法:
POST /sales/_search
{
"aggs" : {
"max_price" : {
"max" : {
"script" : {
"id": "my_script",
"params": {
"field": "price"
}
}
}
}
}
}
值脚本
假设我们的索引中文件的价格是以美元为单位的,但我们希望以欧元计算最大价格(为了本例的目的,假设汇率为1.2)。我们可以使用一个值脚本在每个值聚合之前应用转化率:
POST /sales/_search
{
"aggs" : {
"max_price_in_euros" : {
"max" : {
"field" : "price",
"script" : {
"source" : "_value * params.conversion_rate",
"params" : {
"conversion_rate" : 1.2
}
}
}
}
}
}
Missing Value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /sales/_search
{
"aggs" : {
"grade_max" : {
"max" : {
"field" : "grade",
"missing": 10
}
}
}
}
在grade字段中没有值的文档将与值为10的文档归入同一个bucket。
一个单值指标聚合,用于跟踪并返回从聚合文档中提取的数值中的最小值。这些值可以从文档中的特定数值字段中提取,也可以由提供的脚本生成。
最小和最大聚合作用于数据的双重表示。因此,当运行在绝对值大于2^53时,结果可能是近似的。
计算所有文档的最小价格值:
POST /sales/_search?size=0
{
"aggs" : {
"min_price" : { "min" : { "field" : "price" } }
}
}
响应:
{
...
"aggregations": {
"min_price": {
"value": 10.0
}
}
}
可以看到,聚合的名称(上面的min_price)还用作从返回的响应中检索聚合结果的键。
使用脚本
最小聚合还可以计算脚本的最小值。下面的例子计算了最低价格:
POST /sales/_search
{
"aggs" : {
"min_price" : {
"min" : {
"script" : {
"source" : "doc.price.value"
}
}
}
}
}
这将使用Painless脚本语言,没有脚本参数。要使用存储脚本,请使用以下语法:
POST /sales/_search
{
"aggs" : {
"min_price" : {
"min" : {
"script" : {
"id": "my_script",
"params": {
"field": "price"
}
}
}
}
}
}
值脚本
假设我们的索引中文件的价格是以美元为单位的,但是我们想要计算以欧元为单位的最小值(为了这个例子,假设汇率是1.2)。我们可以使用一个值脚本在每个值聚合之前应用转化率:
POST /sales/_search
{
"aggs" : {
"min_price_in_euros" : {
"min" : {
"field" : "price",
"script" : {
"source" : "_value * params.conversion_rate",
"params" : {
"conversion_rate" : 1.2
}
}
}
}
}
}
Missing value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /sales/_search
{
"aggs" : {
"grade_min" : {
"min" : {
"field" : "grade",
"missing": 10
}
}
}
}
在grade字段中没有值的文档将与值为10的文档归入同一个bucket。
一种多值度量聚合,计算从聚合文档中提取的数值的一个或多个百分位数。这些值可以从文档中的特定数值字段中提取,也可以由提供的脚本生成。
百分位表示观测值的某个百分比出现的点。例如,95的值是大于观测值95%的值。
百分位数通常用于寻找异常值。在正态分布中,0.13百分位和99.87百分位代表与平均值的三个标准差。任何超出三个标准差的数据通常都被认为是异常。
当检索到一个百分比范围时,可以使用它们来估计数据分布,并确定数据是否倾斜、双峰等。
假设你的数据包括网站加载时间。平均加载时间和中值加载时间对管理员来说用处不大。最大值可能很有趣,但它很容易被一个缓慢的响应所逐渐改变。
让我们看看表示加载时间的百分比范围:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time"
}
}
}
}
字段load_time必须是一个数字字段
默认情况下,百分比度量将生成一个百分比范围:[1,5,25,50,75,95,99]。响应将是这样的:
{
...
"aggregations": {
"load_time_outlier": {
"values" : {
"1.0": 5.0,
"5.0": 25.0,
"25.0": 165.0,
"50.0": 445.0,
"75.0": 725.0,
"95.0": 945.0,
"99.0": 985.0
}
}
}
}
如您所见,聚合将返回默认范围内每个百分位数的计算值。如果我们假设响应时间以毫秒为单位,那么很明显,网页通常在10-725毫秒内加载,但偶尔会达到945-985ms。
通常,管理员只对异常值感兴趣——极端的百分位数。我们可以只指定我们感兴趣的百分比(所请求的百分比必须是0-100之间的值):
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"percents" : [95, 99, 99.9]
}
}
}
}
使用percents参数指定要计算的特定百分比
Keyed Response
默认情况下,keyed标志被设置为true,它将每个桶关联一个唯一的字符串键,并以哈希而不是数组的形式返回范围。将keyed标志设置为false将禁用此行为:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"keyed": false
}
}
}
}
响应:
{
...
"aggregations": {
"load_time_outlier": {
"values": [
{
"key": 1.0,
"value": 5.0
},
{
"key": 5.0,
"value": 25.0
},
{
"key": 25.0,
"value": 165.0
},
{
"key": 50.0,
"value": 445.0
},
{
"key": 75.0,
"value": 725.0
},
{
"key": 95.0,
"value": 945.0
},
{
"key": 99.0,
"value": 985.0
}
]
}
}
}
使用脚本
百分比指标支持脚本编制。例如,如果我们的加载时间以毫秒为单位,但我们想要以秒为单位计算百分位数,我们可以使用脚本实时转换它们:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"script" : {
"lang": "painless",
"source": "doc['load_time'].value / params.timeUnit",
"params" : {
"timeUnit" : 1000
}
}
}
}
}
}
字段参数替换为脚本参数,该脚本使用脚本生成计算百分比的值
脚本像其他脚本一样支持参数化输入
这将使用简单的脚本语言将脚本参数解释为内联脚本,并且没有脚本参数。要使用存储脚本,请使用以下语法:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"script" : {
"id": "my_script",
"params": {
"field": "load_time"
}
}
}
}
}
}
百分位数(通常)是近似值
有许多不同的算法来计算百分位数。简单的实现只是将所有值存储在一个排序数组中。要找到第50个百分位数,只需找到my_array[count(my_array) * 0.5]处的值。
显然,简单的实现不能伸缩——排序的数组随着数据集中值的数量线性增长。要计算Elasticsearch集群中数十亿个值的百分比,需要计算近似的百分比。
百分比度量使用的算法称为TDigest
在使用这一指标时,有一些指导原则需要牢记:
下表显示了均匀分布上的相对误差,这取决于收集到的值的数量和要求的百分位数:

它显示了极端百分位数的精度如何更好。对于大量的值,误差减小的原因是大数定律使得值的分布越来越均匀,而t摘要树可以更好地总结它。在更倾斜的分布上就不是这样了。
压缩
近似算法必须平衡内存利用率和估计精度。这个平衡可以使用压缩参数来控制:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"tdigest": {
"compression" : 200
}
}
}
}
}
压缩控制内存使用和近似错误
TDigest算法使用一些“节点”来近似百分位数——可用的节点越多,与数据量成正比的精度(和大内存占用)就越高。压缩参数将最大节点数限制为20 *compressing。
因此,通过增加压缩值,可以以占用更多内存为代价提高百分位数的准确性。更大的压缩值也会使算法变慢,因为底层树数据结构的大小会增加,导致更昂贵的操作。默认压缩值为100。
一个“节点”大约使用32个字节的内存,所以在最坏的情况下(大量数据按顺序到达),默认设置将产生一个大约64KB大小的TDigest。在实践中,数据往往更随机,TDigest将使用更少的内存。
HDR直方图
此设置公开了HDR直方图的内部实现,将来可能会更改语法。
HDR直方图(High Dynamic Range Histogram,高动态范围直方图)是一种替代实现,在计算延迟测量的百分比时非常有用,因为它可以比t摘要实现更快,但代价是占用更大的内存。该实现维护一个固定的最坏情况百分比错误(指定为有效数字的数量)。这意味着,如果在直方图中记录从1微秒到1小时(3,600,000,000微秒)的值,并将其设置为3位有效数字,则对于1毫秒以内的值,它将保持1微秒的值分辨率
HDR直方图可以通过在请求中指定method参数来使用:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"percents" : [95, 99, 99.9],
"hdr": {
"number_of_significant_value_digits" : 3
}
}
}
}
}
hdr对象指示应该使用hdr直方图来计算百分位数,并且可以在对象中指定此算法的具体设置
Number_of_significant_value_digits指定直方图值的有效位数的分辨率
hdr直方图只支持正数值,如果传入负值则会出错。如果值的范围是未知的,使用HDRHistogram也不是一个好主意,因为这可能会导致高内存使用。
Missing value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
GET latency/_search
{
"size": 0,
"aggs" : {
"grade_percentiles" : {
"percentiles" : {
"field" : "grade",
"missing": 10
}
}
}
}
在grade字段中没有值的文档将与值为10的文档归入同一个bucket。
计算从聚合文档中提取的数值的一个或多个百分比的多值度量聚合。这些值可以从文档中的特定数值字段中提取,也可以由提供的脚本生成。
请参阅百分位数(通常)近似和压缩以获得关于百分位数排名聚合的近似和内存使用的建议
百分位表示观测值低于某一数值的百分比。例如,如果一个值大于或等于观测值的95%,则说它位于第95百分位。
假设你的数据包括网站加载时间。你可能有一个服务协议,95%的页面加载在500毫秒内完成,99%的页面加载在600毫秒内完成。
让我们看看表示加载时间的百分比范围:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"field" : "load_time",
"values" : [500, 600]
}
}
}
}
字段load_time必须是一个数字字段
响应将是这样的:
{
...
"aggregations": {
"load_time_ranks": {
"values" : {
"500.0": 55.00000000000001,
"600.0": 64.0
}
}
}
}
根据这些信息,您可以确定您正在达到99%的加载时间目标,但还没有达到95%的加载时间目标
**Keyed **
默认情况下,keyed标志被设置为true,将一个唯一的字符串键与每个桶关联,并以哈希而不是数组的形式返回范围。将keyed标志设置为false将禁用此行为:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_ranks": {
"percentile_ranks": {
"field": "load_time",
"values": [500, 600],
"keyed": false
}
}
}
}
响应:
{
...
"aggregations": {
"load_time_ranks": {
"values": [
{
"key": 500.0,
"value": 55.00000000000001
},
{
"key": 600.0,
"value": 64.0
}
]
}
}
}
使用脚本
百分位指标支持脚本编制。例如,如果我们的加载时间以毫秒为单位,但我们想要以秒为单位指定值,我们可以使用脚本实时转换它们:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"values" : [500, 600],
"script" : {
"lang": "painless",
"source": "doc['load_time'].value / params.timeUnit",
"params" : {
"timeUnit" : 1000
}
}
}
}
}
}
这将使用简单的脚本语言将脚本参数解释为内联脚本,并且没有脚本参数。要使用存储脚本,请使用以下语法:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"values" : [500, 600],
"script" : {
"id": "my_script",
"params": {
"field": "load_time"
}
}
}
}
}
}
HDR直方图
同百分比聚合
Missing value
同百分比聚合
使用脚本执行以提供指标输出的指标聚合
例如
POST ledger/_search?size=0
{
"query" : {
"match_all" : {}
},
"aggs": {
"profit": {
"scripted_metric": {
"init_script" : "state.transactions = []",
"map_script" : "state.transactions.add(doc.type.value == 'sale' ? doc.amount.value : -1 * doc.amount.value)",
"combine_script" : "double profit = 0; for (t in state.transactions) { profit += t } return profit",
"reduce_script" : "double profit = 0; for (a in states) { profit += a } return profit"
}
}
}
}
Init_script是可选参数,其他脚本都是必选参数。
上面的聚合演示了如何使用脚本聚合计算销售和成本交易的总利润。
以上聚合的响应:
{
"took": 218,
...
"aggregations": {
"profit": {
"value": 240.0
}
}
}
上面的例子也可以使用存储脚本指定,如下所示:
POST ledger/_search?size=0
{
"aggs": {
"profit": {
"scripted_metric": {
"init_script" : {
"id": "my_init_script"
},
"map_script" : {
"id": "my_map_script"
},
"combine_script" : {
"id": "my_combine_script"
},
"params": {
"field": "amount"
},
"reduce_script" : {
"id": "my_reduce_script"
}
}
}
}
}
init, map和combine脚本的脚本参数必须在全局params对象中指定,以便在脚本之间共享。
允许的返回类型
虽然任何有效的脚本对象都可以在单个脚本中使用,但脚本必须只返回或存储在状态对象中以下类型:
脚本范围
脚本化的指标聚合在执行的4个阶段使用脚本:
init_script
在收集任何文件之前执行。允许聚合设置任何初始状态。
在上面的例子中,init_script在state对象中创建了一个数组transactions。
map_script
每收集一个文件执行一次。这是必需的脚本。如果没有指定combine_script,则结果状态需要存储在state对象中。
在上面的例子中,map_script检查类型字段的值。如果值为sale,则将amount字段的值添加到transactions数组中。如果type字段的值不为sale,则将amount字段的负数添加到transactions中。
combine_script
文档收集完成后,在每个分片上执行一次。这是必需的脚本。允许聚合合并从每个分片返回的状态。
在上面的例子中,combine_script遍历所有存储的transactions,对profit变量中的值求和,最后返回profit。
reduce_script
在所有分片返回结果后,在协调节点上执行一次。这是必需的脚本。脚本提供了对变量states的访问,该变量states是每个shard上combine_script结果的数组。
在上面的例子中,reduce_script迭代每个shard返回的利润,然后返回最终的合并利润,该利润将在聚合的响应中返回。
示例
想象这样一种情况,你将以下文档索引到一个包含2个分片的索引中:
PUT /transactions/_bulk?refresh
{"index":{"_id":1}}
{"type": "sale","amount": 80}
{"index":{"_id":2}}
{"type": "cost","amount": 10}
{"index":{"_id":3}}
{"type": "cost","amount": 30}
{"index":{"_id":4}}
{"type": "sale","amount": 130}
假设文档1和3最终在碎片A上,文档2和4最终在碎片b上。下面是上面例子中每个阶段的聚合结果的细分。
init_script之前
State初始化为一个新的空对象。
"state" : {}
init_script之后
在执行任何文档收集之前,这将在每个shard上运行一次,因此我们将在每个shard上有一个副本:
分片A:
"state" : {
"transactions" : []
}
分片B:
"state" : {
"transactions" : []
}
map_script之后
每个shard收集它的文档,并在收集的每个文档上运行map_script:
分片A:
"state" : {
"transactions" : [ 80, -30 ]
}
分片B:
"state" : {
"transactions" : [ -10, 130 ]
}
combine_script之后
在文档收集完成后,在每个shard上执行combine_script,并将每个shard的所有交易减少到单个利润数字(通过将事务数组中的值相加),并将其传递回协调节点:
分片A:
50
分片B:
120
reduce_script之后
reduce_script接收一个包含每个shard的combine脚本结果的状态数组:
"states" : [
50,
120
]
它将分片的响应减少到最终的总体利润数字(通过求和值),并将其作为聚合的结果返回以产生响应:
{
...
"aggregations": {
"profit": {
"value": 170
}
}
}
其他参数
params
可选的。一个对象,其内容将作为变量传递给init_script、map_script和combine_script。这对于允许用户控制聚合的行为和在脚本之间存储状态非常有用。如果没有指定,默认值相当于提供:
"params" : {}
Empty Buckets
如果脚本度量聚合的父桶没有收集任何文档,则将从分片返回一个空值的聚合响应。在这种情况下,reduce_script的状态变量将包含null作为来自该分片的响应。因此,Reduce_script应该期望并处理来自分片的空响应。
一个多值度量聚合,计算从聚合文档中提取的数值的统计信息。这些值可以从文档中的特定数值字段中提取,也可以由提供的脚本生成。
返回的统计数据包括:min, max, sum, count和avg。
假设数据由表示学生考试成绩(0到100)的文档组成
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "grade" } }
}
}
上述聚合计算所有文档的等级统计信息。聚合类型是统计数据,字段设置定义了计算统计数据的文档的数字字段。上述操作将返回以下内容:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0
}
}
}
聚合的名称(上面的grades_stats)还可以作为键,通过该键可以从返回的响应中检索聚合结果。
使用脚本
基于脚本计算成绩统计:
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : {
"script" : {
"lang": "painless",
"source": "doc['grade'].value"
}
}
}
}
}
这将使用简单的脚本语言将脚本参数解释为内联脚本,并且没有脚本参数。要使用存储脚本,请使用以下语法:
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : {
"script" : {
"id": "my_script",
"params" : {
"field" : "grade"
}
}
}
}
}
}
值脚本
结果证明,考试成绩远远超出了学生的水平,需要进行评分修正。我们可以使用一个值脚本来获取新的统计数据:
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : {
"field" : "grade",
"script" : {
"lang": "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}
Missing value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : {
"field" : "grade",
"missing": 0
}
}
}
}
在grade字段中没有值的文档将与值为0的文档归入同一个bucket。
一种单值度量聚合,将从聚合文档中提取的数值进行汇总。这些值可以从文档中的特定数值字段中提取,也可以由提供的脚本生成。
假设数据由代表销售记录的文档组成,我们可以将所有帽子的销售价格加起来:
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : { "sum" : { "field" : "price" } }
}
}
响应
{
...
"aggregations": {
"hat_prices": {
"value": 450.0
}
}
}
聚合的名称(上面的hat_prices)还可以作为键,通过该键可以从返回的响应中检索聚合结果。
使用脚本
我们还可以使用一个脚本来获取销售价格:
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : {
"sum" : {
"script" : {
"source": "doc.price.value"
}
}
}
}
}
这将使用简单的脚本语言将脚本参数解释为内联脚本,并且没有脚本参数。要使用存储脚本,请使用以下语法:
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : {
"sum" : {
"script" : {
"id": "my_script",
"params" : {
"field" : "price"
}
}
}
}
}
}
值脚本
也可以使用_value从脚本中访问字段值。例如,这将是所有帽子价格的平方和:
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"square_hats" : {
"sum" : {
"field" : "price",
"script" : {
"source": "_value * _value"
}
}
}
}
}
Missing value
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : {
"sum" : {
"field" : "price",
"missing": 100
}
}
}
}
top_hits指标聚合器跟踪正在聚合的最相关的文档。这个聚合器打算用作子聚合器,以便每个桶聚合顶部匹配的文档。
top_hits聚合器可以通过桶聚合器有效地将结果集按特定字段分组。一个或多个桶聚合器决定将结果集分成哪些属性。
设置:
from
与您想获取的第一个结果的偏移量。
size
每个桶返回的顶部匹配命中的最大数量。默认情况下,返回前三个匹配的命中值。
sort
顶部匹配的点击应该如何排序。默认情况下,按主查询的分数排序。
每次命中支持的功能
top_hits聚合返回常规的搜索命中数,因为每个命中数可以支持很多特性:
例如:
在下面的示例中,我们将销售按类型分组,并根据类型显示上一次销售。对于每笔销售,源中只包含日期和价格字段。
POST /sales/_search?size=0
{
"aggs": {
"top_tags": {
"terms": {
"field": "type",
"size": 3
},
"aggs": {
"top_sales_hits": {
"top_hits": {
"sort": [
{
"date": {
"order": "desc"
}
}
],
"_source": {
"includes": [ "date", "price" ]
},
"size" : 1
}
}
}
}
}
}
响应:
{
...
"aggregations": {
"top_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "hat",
"doc_count": 3,
"top_sales_hits": {
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_type": "_doc",
"_id": "AVnNBmauCQpcRyxw6ChK",
"_source": {
"date": "2015/03/01 00:00:00",
"price": 200
},
"sort": [
1425168000000
],
"_score": null
}
]
}
}
},
{
"key": "t-shirt",
"doc_count": 3,
"top_sales_hits": {
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_type": "_doc",
"_id": "AVnNBmauCQpcRyxw6ChL",
"_source": {
"date": "2015/03/01 00:00:00",
"price": 175
},
"sort": [
1425168000000
],
"_score": null
}
]
}
}
},
{
"key": "bag",
"doc_count": 1,
"top_sales_hits": {
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_type": "_doc",
"_id": "AVnNBmatCQpcRyxw6ChH",
"_source": {
"date": "2015/01/01 00:00:00",
"price": 150
},
"sort": [
1420070400000
],
"_score": null
}
]
}
}
}
]
}
}
}
字段折叠示例
字段折叠或结果分组是一种将结果集逻辑地分组并将每个组返回top文档的功能。组的顺序由组中第一个文档的相关性决定。在Elasticsearch中,这可以通过桶聚合器实现,桶聚合器将top_hits聚合器包装为子聚合器。
在下面的例子中,我们搜索抓取的网页。对于每个网页,我们存储主体和网页所属的域名。通过在域名字段上定义一个术语聚合器,我们将网页的结果集按域名分组。然后将top_hits聚合器定义为子聚合器,以便每个桶收集顶部匹配的命中数。
此外,还定义了一个max聚合器,它被术语聚合器的顺序特性用于按桶中最相关文档的相关度顺序返回桶。
POST /sales/_search
{
"query": {
"match": {
"body": "elections"
}
},
"aggs": {
"top_sites": {
"terms": {
"field": "domain",
"order": {
"top_hit": "desc"
}
},
"aggs": {
"top_tags_hits": {
"top_hits": {}
},
"top_hit" : {
"max": {
"script": {
"source": "_score"
}
}
}
}
}
}
}
目前,需要使用最大(或最小)聚合器,以确保来自术语聚合器的桶是根据每个域名最相关的网页的分数排序的。不幸的是,top_hits聚合器还不能在术语聚合器的order选项中使用。
在嵌套或反向嵌套聚合器中支持Top_hits
如果top_hits聚合器包装在嵌套或reverse_nested聚合器中,则返回嵌套命中。嵌套点击在某种意义上是隐藏的迷你文档,它是常规文档的一部分,在映射中已配置了嵌套字段类型。如果top_hits聚合器被包装在嵌套或反向嵌套的聚合器中,则top_hits聚合器具有取消隐藏这些文档的能力。在嵌套类型映射中阅读关于嵌套的更多信息。
如果已配置嵌套类型,单个文档实际上被索引为多个Lucene文档,并且它们共享相同的id。为了确定嵌套命中的标识,需要的不仅仅是id,这就是为什么嵌套命中还包括它们的嵌套标识。嵌套标识保存在搜索命中的_nested字段下,包括数组字段和嵌套命中所属数组字段中的偏移量。偏移量是以零为基础的。
让我们看看它在真实样本上是如何工作的。考虑以下映射:
PUT /sales
{
"mappings": {
"properties" : {
"tags" : { "type" : "keyword" },
"comments" : {
"type" : "nested",
"properties" : {
"username" : { "type" : "keyword" },
"comment" : { "type" : "text" }
}
}
}
}
}
comments是一个数组,在product对象下保存嵌套文档。
还有一些文件:
PUT /sales/_doc/1?refresh
{
"tags": ["car", "auto"],
"comments": [
{"username": "baddriver007", "comment": "This car could have better brakes"},
{"username": "dr_who", "comment": "Where's the autopilot? Can't find it"},
{"username": "ilovemotorbikes", "comment": "This car has two extra wheels"}
]
}
现在可以执行以下top_hits聚合(包裹在嵌套聚合中):
POST /sales/_search
{
"query": {
"term": { "tags": "car" }
},
"aggs": {
"by_sale": {
"nested" : {
"path" : "comments"
},
"aggs": {
"by_user": {
"terms": {
"field": "comments.username",
"size": 1
},
"aggs": {
"by_nested": {
"top_hits":{}
}
}
}
}
}
}
}
Top命中带有嵌套命中的响应片段,位于数组字段注释的第一个槽中:
{
...
"aggregations": {
"by_sale": {
"by_user": {
"buckets": [
{
"key": "baddriver007",
"doc_count": 1,
"by_nested": {
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": 0.3616575,
"hits": [
{
"_index": "sales",
"_type" : "_doc",
"_id": "1",
"_nested": {
"field": "comments",
"offset": 0
},
"_score": 0.3616575,
"_source": {
"comment": "This car could have better brakes",
"username": "baddriver007"
}
}
]
}
}
}
...
]
}
}
}
}
包含嵌套命中的数组字段的名称
如果嵌套命中包含数组,则定位
嵌套命中的来源
如果请求_source,则只返回嵌套对象的源的一部分,而不是文档的整个源。嵌套内部对象级别上存储的字段也可以通过位于嵌套或reverse_nested聚合器中的top_hits聚合器访问。
只有嵌套的命中会有_nested字段,非嵌套的(常规)命中不会有_nested字段。
如果_source未启用,_nested中的信息也可以用于解析其他地方的原始源代码。
如果映射中定义了多层嵌套对象类型,那么_nested信息也可以是分层的,以便表示两层或更深层次的嵌套命中的标识。
在下例中,嵌套命中位于nested_grand_child_field字段的第一个槽,然后位于nested_child_field字段的第二个慢速:
...
"hits": {
"total" : {
"value": 2565,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "a",
"_type": "b",
"_id": "1",
"_score": 1,
"_nested" : {
"field" : "nested_child_field",
"offset" : 1,
"_nested" : {
"field" : "nested_grand_child_field",
"offset" : 0
}
}
"_source": ...
},
...
]
}
...
一个单值度量聚合,用于计算从聚合文档中提取的值的数量。这些值可以从文档中的特定字段中提取,也可以由提供的脚本生成。通常,此聚合器将与其他单值聚合一起使用。例如,在计算平均值时,人们可能会对计算平均值的值的数量感兴趣。
POST /sales/_search?size=0
{
"aggs" : {
"types_count" : { "value_count" : { "field" : "type" } }
}
}
响应:
{
...
"aggregations": {
"types_count": {
"value": 7
}
}
}
聚合的名称(上面的types_count)还可以作为键,通过该键可以从返回的响应中检索聚合结果。
使用脚本
计算脚本生成的值:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"value_count" : {
"script" : {
"source" : "doc['type'].value"
}
}
}
}
}
这将使用简单的脚本语言将脚本参数解释为内联脚本,并且没有脚本参数。要使用存储脚本,请使用以下语法:
POST /sales/_search?size=0
{
"aggs" : {
"types_count" : {
"value_count" : {
"script" : {
"id": "my_script",
"params" : {
"field" : "type"
}
}
}
}
}
}
这种单值聚合近似于其搜索结果的绝对偏差中位数。
中位数绝对偏差是可变性的衡量标准。它是一个健壮的统计量,这意味着它对于描述可能有异常值或可能不是正态分布的数据很有用。对于这样的数据,它可以比标准偏差更具描述性。
它被计算为每个数据点偏离整个样本中位数的中位数。
GET reviews/_search
{
"size": 0,
"aggs": {
"review_average": {
"avg": {
"field": "rating"
}
},
"review_variability": {
"median_absolute_deviation": {
"field": "rating"
}
}
}
}
Rating必须是一个数字字段
由此产生的中位数绝对偏差为2,告诉我们评级存在相当大的可变性。审稿人必须对这个产品有不同的意见。
{
...
"aggregations": {
"review_average": {
"value": 3.0
},
"review_variability": {
"value": 2.0
}
}
}
近似值
计算中位数绝对偏差的简单实现将整个样本存储在内存中,因此这种聚合反而计算一个近似值。它使用TDigest数据结构来近似样本中值和样本中值偏差的中值。有关tdigest近似特性的更多信息,请参见百分位数(通常)近似。
资源使用和TDigest的分位数近似的准确性之间的权衡,以及因此该聚合的中位数绝对偏差近似的准确性,是由压缩参数控制的。更高的压缩设置以更高的内存使用为代价提供更准确的近似。有关TDigest压缩参数的特性的更多信息,请参见compression
这个聚合的默认压缩值是1000。在这个压缩级别上,这种聚合通常在精确结果的5%以内,但观察到的性能将取决于样本数据。
使用脚本
这个度量聚合支持脚本。在我们上面的例子中,产品评论的等级是1到5。如果我们想将它们修改为1到10的等级,我们可以使用脚本。
提供一个内联脚本:
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"script": {
"lang": "painless",
"source": "doc['rating'].value * params.scaleFactor",
"params": {
"scaleFactor": 2
}
}
}
}
}
}
提供一个存储脚本:
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"script": {
"id": "my_script",
"params": {
"field": "rating"
}
}
}
}
}
}
Missing value
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"field": "rating",
"missing": 5
}
}
}
}
桶聚合不像指标聚合那样计算字段的指标,相反,它们创建文档的桶。每个桶都与一个标准相关联(取决于聚合类型),该标准确定当前上下文中的文档是否“属于”它。换句话说,存储桶有效地定义了文档集。除了存储桶本身,存储桶聚合还计算并返回“落入”每个存储桶的文档数量。
与度量聚合相反,桶聚合可以容纳子聚合。这些子聚合将为它们的“父”桶聚合所创建的桶聚合。
有不同的桶聚合器,每个都有不同的“桶”策略。有的定义单个桶,有的定义固定数量的多个桶,还有的在聚合过程中动态创建桶。
单个响应中允许的最大桶数名为search.max_buckets的动态集群设置限制。它默认为10,000,尝试返回超过限制的请求将失败并出现异常。
一个桶聚合返回一种形式的邻接矩阵。该请求提供了命名筛选器表达式的集合,类似于筛选器聚合请求。响应中的每个桶表示交叉滤波器矩阵中的一个非空单元格。
给定名为A, B和C的过滤器,响应将返回具有以下名称的桶:
| A | B | C | |
|---|---|---|---|
| A | A | A&B | A&C |
| B | B | B&C | |
| C | C |
交叉的桶(例如A&C)使用两个过滤器名称的组合(由&字符分隔)进行标记。请注意,响应不包括“C&A”桶,因为这将是与“A&C”相同的一组文档。这个矩阵是对称的,所以我们只返回它的一半。为此,我们对筛选器名称字符串进行排序,并始终使用“&”分隔符左边最小的一个作为值。
如果客户端希望使用与字符默认值以外的分隔符字符串,则可以在请求中传递另一个分隔符参数。
例如:
PUT /emails/_bulk?refresh
{ "index" : { "_id" : 1 } }
{ "accounts" : ["hillary", "sidney"]}
{ "index" : { "_id" : 2 } }
{ "accounts" : ["hillary", "donald"]}
{ "index" : { "_id" : 3 } }
{ "accounts" : ["vladimir", "donald"]}
GET emails/_search
{
"size": 0,
"aggs" : {
"interactions" : {
"adjacency_matrix" : {
"filters" : {
"grpA" : { "terms" : { "accounts" : ["hillary", "sidney"] }},
"grpB" : { "terms" : { "accounts" : ["donald", "mitt"] }},
"grpC" : { "terms" : { "accounts" : ["vladimir", "nigel"] }}
}
}
}
}
}
在上面的例子中,我们分析电子邮件消息来查看哪些组的人交换了消息。我们将分别获得每个组的计数,以及记录了交互的组对的消息计数。
响应:
{
"took": 9,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"interactions": {
"buckets": [
{
"key":"grpA",
"doc_count": 2
},
{
"key":"grpA&grpB",
"doc_count": 1
},
{
"key":"grpB",
"doc_count": 2
},
{
"key":"grpB&grpC",
"doc_count": 1
},
{
"key":"grpC",
"doc_count": 1
}
]
}
}
}
用法
这个聚合本身可以提供创建无向加权图所需的所有数据。然而,当与子聚合(如date_histogram)一起使用时,结果可以提供执行动态网络分析所需的额外级别的数据,其中检查随着时间的推移的交互变得非常重要。
局限性
对于N个过滤器,生成的桶矩阵可以是N²/2,因此默认的最大过滤器为100个。可以使用index.max_adjacency_matrix更改此设置。
一个类似于日期直方图聚合的多桶聚合,除了提供一个用于作为每个桶的宽度的间隔之外,它提供了一个目标桶数,表明所需的桶数,并且桶的间隔将自动选择以最好地实现该目标。返回的桶数总是小于或等于这个目标数。
buckets字段是可选的,如果没有指定,将默认为10个桶。
请求10个桶的目标。
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"auto_date_histogram" : {
"field" : "date",
"buckets" : 10
}
}
}
}
键
在内部,日期表示为一个64位数字,表示一个以毫秒为单位的时间戳。这些时间戳作为桶键返回。key_as_string是使用format参数指定的格式将相同的时间戳转换为格式化的日期字符串:
如果没有指定格式,那么它将使用字段映射中指定的第一个日期格式。
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"auto_date_histogram" : {
"field" : "date",
"buckets" : 5,
"format" : "yyyy-MM-dd"
}
}
}
}
支持表达日期格式模式
响应:
{
...
"aggregations": {
"sales_over_time": {
"buckets": [
{
"key_as_string": "2015-01-01",
"key": 1420070400000,
"doc_count": 3
},
{
"key_as_string": "2015-02-01",
"key": 1422748800000,
"doc_count": 2
},
{
"key_as_string": "2015-03-01",
"key": 1425168000000,
"doc_count": 2
}
],
"interval": "1M"
}
}
}
间隔
根据聚合收集的数据选择返回桶的时间间隔,使返回的桶数小于等于请求的桶数。可能返回的间隔是:
seconds
1 5 10 30的倍数
minutes
1 5 10 30的倍数
hours
1,3, 12的倍数
days
1和7的倍数
months
1和3的倍数
years
1、5、10、20、50和100的倍数
在最坏的情况下,每天的桶数对于请求的桶数来说太多,返回的桶数将是请求桶数的1/7。
时区
日期时间以UTC标准存储在Elasticsearch中。默认情况下,所有的桶和舍入也是用UTC完成的。time_zone参数可用于指示桶存储应使用不同的时区。
时区可以指定为ISO 8601 UTC偏移量(例如+01:00或-08:00),也可以指定为时区id (TZ数据库中使用的标识符,如America/Los_Angeles)。
考虑下面例子
PUT my_index/log/1?refresh
{
"date": "2015-10-01T00:30:00Z"
}
PUT my_index/log/2?refresh
{
"date": "2015-10-01T01:30:00Z"
}
PUT my_index/log/3?refresh
{
"date": "2015-10-01T02:30:00Z"
}
GET my_index/_search?size=0
{
"aggs": {
"by_day": {
"auto_date_histogram": {
"field": "date",
"buckets" : 3
}
}
}
}
如果没有指定时区,则使用UTC,从2015年10月1日午夜UTC开始返回三个1小时桶:
{
...
"aggregations": {
"by_day": {
"buckets": [
{
"key_as_string": "2015-10-01T00:00:00.000Z",
"key": 1443657600000,
"doc_count": 1
},
{
"key_as_string": "2015-10-01T01:00:00.000Z",
"key": 1443661200000,
"doc_count": 1
},
{
"key_as_string": "2015-10-01T02:00:00.000Z",
"key": 1443664800000,
"doc_count": 1
}
],
"interval": "1h"
}
}
}
如果指定的time_zone为-01:00,则midnight从UTC时间零点前一小时开始:
GET my_index/_search?size=0
{
"aggs": {
"by_day": {
"auto_date_histogram": {
"field": "date",
"buckets" : 3,
"time_zone": "-01:00"
}
}
}
}
现在仍然返回三个1小时桶,但第一个桶在2015年9月30日晚上11:00开始,因为这是指定时区桶的本地时间。
{
...
"aggregations": {
"by_day": {
"buckets": [
{
"key_as_string": "2015-09-30T23:00:00.000-01:00",
"key": 1443657600000,
"doc_count": 1
},
{
"key_as_string": "2015-10-01T00:00:00.000-01:00",
"key": 1443661200000,
"doc_count": 1
},
{
"key_as_string": "2015-10-01T01:00:00.000-01:00",
"key": 1443664800000,
"doc_count": 1
}
],
"interval": "1h"
}
}
}
key_as_string值表示指定时区每天的午夜。
当使用遵循DST(日光节约时间)变化的时区时,接近这些变化发生时刻的存储桶的大小可能与邻近的存储桶略有不同。例如,考虑在欧洲中部时区开始夏令时:2016年3月27日凌晨2点,时钟拨快1小时至当地时间凌晨3点。如果聚合的结果是每日桶,则覆盖当天的桶将只保存23小时的数据,而其他桶通常保存24小时。对于较短的间隔,例如12小时,也是如此。在这里,我们只有3月27日上午的11小时桶
脚本使用
与普通的date_histogram一样,它同时支持文档级脚本和值级脚本。但是,该聚合不支持min_doc_count、extended_bounds和order参数。
最小间隔参数
minimum_interval允许调用者指定应该使用的最小舍入间隔。这可以使收集过程更有效,因为聚合不会试图以低于minimum_interval的任何时间间隔舍入。
minimum_interval接受的单位是:
yearmonthdayhourminutesecondPOST /sales/_search?size=0
{
"aggs" : {
"sale_date" : {
"auto_date_histogram" : {
"field" : "date",
"buckets": 10,
"minimum_interval": "minute"
}
}
}
}
Misssing value
POST /sales/_search?size=0
{
"aggs" : {
"sale_date" : {
"auto_date_histogram" : {
"field" : "date",
"buckets": 10,
"missing": "2000/01/01"
}
}
}
}
一个特殊的单桶聚合,它选择在join字段中定义的具有指定类型的子文档。
这个聚合只有一个选项:
type
应选择的子类型。
例如,假设我们有一个问题和答案的索引。应答类型在映射中有以下join字段:
PUT child_example
{
"mappings": {
"properties": {
"join": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}
问题文档包含一个标记字段,答案文档包含一个所有者字段。使用子聚合,可以将标记桶映射到单个请求中的所有者桶,即使这两个字段存在于两种不同的文档中。
一个问题文档的例子:
PUT child_example/_doc/1
{
"join": {
"name": "question"
},
"body": "<p>I have Windows 2003 server and i bought a new Windows 2008 server...",
"title": "Whats the best way to file transfer my site from server to a newer one?",
"tags": [
"windows-server-2003",
"windows-server-2008",
"file-transfer"
]
}
回答文件的例子:
PUT child_example/_doc/2?routing=1
{
"join": {
"name": "answer",
"parent": "1"
},
"owner": {
"location": "Norfolk, United Kingdom",
"display_name": "Sam",
"id": 48
},
"body": "<p>Unfortunately you're pretty much limited to FTP...",
"creation_date": "2009-05-04T13:45:37.030"
}
PUT child_example/_doc/3?routing=1&refresh
{
"join": {
"name": "answer",
"parent": "1"
},
"owner": {
"location": "Norfolk, United Kingdom",
"display_name": "Troll",
"id": 49
},
"body": "<p>Use Linux...",
"creation_date": "2009-05-05T13:45:37.030"
}
可以构建以下请求,将两者连接在一起:
POST child_example/_search?size=0
{
"aggs": {
"top-tags": {
"terms": {
"field": "tags.keyword",
"size": 10
},
"aggs": {
"to-answers": {
"children": {
"type" : "answer"
},
"aggs": {
"top-names": {
"terms": {
"field": "owner.display_name.keyword",
"size": 10
}
}
}
}
}
}
}
}
类型指向名称answer的类型/映射。
上面的示例返回顶部问题标签,每个标签返回顶部答案所有者。
可能的响应:
{
"took": 25,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped" : 0,
"failed": 0
},
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"top-tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "file-transfer",
"doc_count": 1,
"to-answers": {
"doc_count": 2,
"top-names": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Sam",
"doc_count": 1
},
{
"key": "Troll",
"doc_count": 1
}
]
}
}
},
{
"key": "windows-server-2003",
"doc_count": 1,
"to-answers": {
"doc_count": 2,
"top-names": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Sam",
"doc_count": 1
},
{
"key": "Troll",
"doc_count": 1
}
]
}
}
},
{
"key": "windows-server-2008",
"doc_count": 1, #带有file-transfer、windows-server-2003等标记的问题文档的数量。
"to-answers": {
"doc_count": 2, #与带有file-transfer、windows-server-2003等标记的问题文档相关的答案文档的数量。
"top-names": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Sam",
"doc_count": 1
},
{
"key": "Troll",
"doc_count": 1
}
]
}
}
}
]
}
}
}
从不同来源创建复合桶的多桶聚合。
与其他多桶聚合不同,复合聚合可用于高效地对多级聚合中的所有桶进行分页。这种聚合提供了一种方式来流化特定聚合的所有桶,类似于滚动对文档的作用。
复合桶是由为每个文档提取/创建的值的组合构建的,每个组合都被视为一个复合桶。
例如以下文件:
{
"keyword": ["foo", "bar"],
"number": [23, 65, 76]
}
当关键字和数字被用作聚合的值源时,创建以下复合桶:
{ "keyword": "foo", "number": 23 }
{ "keyword": "foo", "number": 65 }
{ "keyword": "foo", "number": 76 }
{ "keyword": "bar", "number": 23 }
{ "keyword": "bar", "number": 65 }
{ "keyword": "bar", "number": 76 }
值来源
sources参数控制应用于构建复合桶的源。定义源的顺序很重要,因为它还控制键返回的顺序。
每个源的名称必须是唯一的。
有三种不同类型的值源:
术语值源相当于一个简单的术语聚合。这些值从字段或脚本中提取,与术语聚合完全相同。
例如:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{ "product": { "terms" : { "field": "product" } } }
]
}
}
}
}
像术语聚合一样,也可以使用脚本为复合桶创建值:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{
"product": {
"terms" : {
"script" : {
"source": "doc['product'].value",
"lang": "painless"
}
}
}
}
]
}
}
}
}
直方图值源可以应用于数值上,在值上建立固定的大小间隔。interval参数定义了数值应该如何转换。例如,设置为5的间隔将把任何数值转换为与其最接近的间隔,101的值将转换为100,这是100到105之间的间隔的键。
例如:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{ "histo": { "histogram" : { "field": "price", "interval": 5 } } }
]
}
}
}
}
这些值是从一个数值字段或返回数值的脚本构建的:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{
"histo": {
"histogram" : {
"interval": 5,
"script" : {
"source": "doc['price'].value",
"lang": "painless"
}
}
}
}
]
}
}
}
}
date_直方图与直方图值源相似,不同的是间隔由日期/时间表达式指定:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{ "date": { "date_histogram" : { "field": "timestamp", "calendar_interval": "1d" } } }
]
}
}
}
}
上面的示例每天创建一个时间间隔,并将所有时间戳值转换为与其最近的时间间隔的开始。可用的间隔表达式:year,quarter,month,week,day,hour,minute,second
时间值也可以通过时间单位解析所支持的缩写来指定。注意,不支持小数时间值,但是您可以通过转换到另一个时间单位来解决这个问题(例如,1.5h可以指定为90m)。
Format
在内部,日期表示为一个64位数字,表示一个以毫秒为单位的时间戳。这些时间戳作为桶键返回。可以返回一个格式化的日期字符串,而不是使用format参数指定的格式:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{
"date": {
"date_histogram" : {
"field": "timestamp",
"calendar_interval": "1d",
"format": "yyyy-MM-dd"
}
}
}
]
}
}
}
}
时区
日期时间以UTC标准存储在Elasticsearch中。默认情况下,所有的桶和舍入也是用UTC完成的。time_zone参数可用于指示桶存储应使用不同的时区。
时区可以指定为ISO 8601 UTC偏移量(例如+01:00或-08:00),也可以指定为时区id (TZ数据库中使用的标识符,如America/Los_Angeles)。
不同的值来源混合
参数sources接受一个值数组source。可以混合不同的值源来创建复合桶。例如:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{ "date": { "date_histogram": { "field": "timestamp", "calendar_interval": "1d" } } },
{ "product": { "terms": {"field": "product" } } }
]
}
}
}
}
这将从两个值源(date_histogram和terms)创建的值创建复合桶。每个桶由两个值组成,分别对应于聚合中定义的每个值源。允许任何类型的组合,并且数组中的顺序保留在组合桶中。
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{ "shop": { "terms": {"field": "shop" } } },
{ "product": { "terms": { "field": "product" } } },
{ "date": { "date_histogram": { "field": "timestamp", "calendar_interval": "1d" } } }
]
}
}
}
}
排序
默认情况下,组合桶按自然顺序排序。值按其值的升序排序。当请求多个值源时,对每个值源进行排序,复合桶的第一个值与另一个复合桶的第一个值进行比较,如果它们相等,则复合桶中的下一个值用于断开连接。这意味着复合桶[foo, 100]被认为比[foobar, 0]小,因为foo被认为比foobar小。可以为每个值s定义排序的方向
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{ "date": { "date_histogram": { "field": "timestamp", "calendar_interval": "1d", "order": "desc" } } },
{ "product": { "terms": {"field": "product", "order": "asc" } } }
]
}
}
}
}
当比较来自date_histogram源的值时,将按降序对组合桶进行排序;当比较来自terms源的值时,将按升序对组合桶进行排序。
Missing Bucket
默认情况下,没有给定源值的文档将被忽略。通过将missing_bucket设置为true(默认为false),可以将它们包含在响应中:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"sources" : [
{ "product_name": { "terms" : { "field": "product", "missing_bucket": true } } }
]
}
}
}
}
在上面的例子中,源product_name将为没有字段product值的文档发出显式空值。源代码中指定的顺序指示空值应该排在第一位(升序asc)还是最后一位(降序desc)。
Size
size参数可以设置为定义应该返回多少个复合桶。每个复合桶被视为单个桶,因此将大小设置为10将返回从值源创建的前10个复合桶。响应包含每个组合桶的值,该数组包含从每个值源提取的值。
After
如果复合桶的数量太高(或未知),不能在单个响应中返回,则可以将检索拆分为多个请求。由于复合桶本质上是扁平的,因此请求的大小恰好是响应中将返回的复合桶的数量(假设它们至少是要返回的复合桶的大小)。如果要检索所有复合桶,最好使用较小的大小(例如100或1000),然后使用after参数检索下一个结果。例如:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"size": 2,
"sources" : [
{ "date": { "date_histogram": { "field": "timestamp", "calendar_interval": "1d" } } },
{ "product": { "terms": {"field": "product" } } }
]
}
}
}
}
响应:
{
...
"aggregations": {
"my_buckets": {
"after_key": { #查询返回的最后一个复合桶。
"date": 1494288000000,
"product": "mad max"
},
"buckets": [
{
"key": {
"date": 1494201600000,
"product": "rocky"
},
"doc_count": 1
},
{
"key": {
"date": 1494288000000,
"product": "mad max"
},
"doc_count": 2
}
]
}
}
}
after_key等于在Pipeline聚合进行任何过滤之前在响应中返回的最后一个桶。如果管道聚合过滤/删除了所有桶,那么after_key将包含过滤前的最后一个桶。
after参数可用于检索在上一轮返回的最后一个复合桶之后的复合桶。在下面的例子中,最后一个桶可以在after_key中找到,下一轮结果可以用:
GET /_search
{
"aggs" : {
"my_buckets": {
"composite" : {
"size": 2,
"sources" : [
{ "date": { "date_histogram": { "field": "timestamp", "calendar_interval": "1d", "order": "desc" } } },
{ "product": { "terms": {"field": "product", "order": "asc" } } }
],
"after": { "date": 1494288000000, "product": "mad max" } #应将聚合限制为按所提供的值排序的桶。
}
}
}
}
响应:
{
...
"aggregations": {
"my_buckets": {
"after_key": {
"date": 1494201600000,
"product": "rocky"
},
"buckets": [
{
"key": {
"date": 1494460800000,
"product": "apocalypse now"
},
"doc_count": 1,
"the_avg": {
"value": 10.0
}
},
{
"key": {
"date": 1494374400000,
"product": "mad max"
},
"doc_count": 1,
"the_avg": {
"value": 27.0
}
},
{
"key": {
"date": 1494288000000,
"product" : "mad max"
},
"doc_count": 2,
"the_avg": {
"value": 22.5
}
},
{
"key": {
"date": 1494201600000,
"product": "rocky"
},
"doc_count": 1,
"the_avg": {
"value": 10.0
}
}
]
}
}
}
管道聚合
复合agg目前与管道聚合不兼容,在大多数情况下也没有意义。例如,由于复合aggs的分页特性,单个逻辑分区(例如一天)可能分布在多个页面上。由于管道聚合纯粹是对桶的最终列表进行后处理,因此在复合页面上运行类似导数的东西可能会导致不准确的结果,因为它只考虑了该页面上的“部分”结果。
将来可能会支持自包含到单个桶的管道agg(例如bucket_selector)。
这种多桶聚合类似于正常的直方图,但它只能用于日期值。因为日期在Elasticsearch内部表示为长值,所以也可以在日期上使用正常的直方图,但不那么准确。这两个api的主要区别在于,在这里可以使用日期/时间表达式指定间隔。基于时间的数据需要特殊的支持,因为基于时间的间隔并不总是固定的长度。
日历和固定时间间隔
在配置日期直方图聚合时,可以通过两种方式指定时间间隔:日历感知时间间隔和固定时间间隔。
日历感知间隔可以理解夏令时改变特定日期的长度,月份有不同的天数,闰秒可以附加到特定的年份。
相比之下,固定间隔总是SI单位的倍数,并且不会根据日历上下文而改变。
两种间隔不建议混合使用
日历时间间隔
使用calendar_interval参数配置日历感知间隔。日历间隔只能以单位的“单数”数量指定(1d, 1M等)。不支持2d等倍数,并将抛出异常。
日历间隔的公认单位是:
minute(m,1m)
所有的分钟从00秒开始。
一分钟是指定时区中第一分钟的00秒和下一分钟的00秒之间的间隔,补偿了中间的任何闰秒,这样小时后的分秒数在开始和结束时是相同的。
hour(h,1h)
所有时间从00分00秒开始。
一小时(1h)是指定时区内第一个小时的00:00分与下一个小时的00:00分之间的间隔,补偿了中间的闰秒,这样小时后的分秒数在开始和结束时是相同的。
day(d,1d)
所有的日子都尽可能早地开始,通常是00:00:00(午夜)。
一天(1d)是指定时区中一天的开始和第二天的开始之间的间隔,补偿了其间的任何时间变化。
week(w,1w)
“星期”为“day_of_week:hour:minute:second”的开始日期与指定时区下一周的星期中的同一天和下一周的时间之间的间隔。
month(M,1M)
一个月是指定时区中该月的开始日和日期与次月的同一天和日期之间的间隔,以便该月的开始日和日期与结束日相同。
quarter(q,1q)
1 季度(1q)是一个月的开始日期和三个月后的同一日期和时间之间的间隔,这样在开始和结束时,月的日期和时间是相同的。
year(y,1y)
一年(1y)是指从某月某日的开始日期和某月某日的开始日期和结束日期,到指定时区下一年某月某日和某日的相同日期和时间的间隔。
日历间隔示例
例如,下面是一个聚合请求桶的时间间隔为日历时间的一个月:
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
}
}
}
}
如果您尝试使用多个日历单元,聚合将失败,因为只支持单个日历单元:
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "2d"
}
}
}
}
{
"error" : {
"root_cause" : [...],
"type" : "x_content_parse_exception",
"reason" : "[1:82] [date_histogram] failed to parse field [calendar_interval]",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "The supplied interval [2d] could not be parsed as a calendar interval.",
"stack_trace" : "java.lang.IllegalArgumentException: The supplied interval [2d] could not be parsed as a calendar interval."
}
}
}
固定时间间隔
固定的时间间隔由fixed_interval参数配置。
与日历感知的间隔相比,固定间隔是固定数量的SI单位,无论它们落在日历上的哪个位置,都不会偏离。一秒总是由1000毫秒组成。这允许在任何多个支持的单元中指定固定的间隔。
固定间隔的公认单位为:
milliseconds (ms)
seconds(s)
定义为每1000毫秒
minutes(m)
所有的分钟从00秒开始。
定义为每60秒(60,000毫秒)
hour(h)
所有时间从00分00秒开始。定义为每分钟60分钟(3,600,000毫秒)
day(d)
所有的日子都尽可能早地开始,通常是00:00:00(午夜)。
定义为24小时(86,400,000毫秒)
固定时间间隔示例
如果我们尝试重新创建之前的"month" calendar_interval,我们可以用30个固定的天来近似:
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"fixed_interval" : "30d"
}
}
}
}
但是如果我们尝试使用一个不受支持的日历单位,比如周,我们会得到一个异常:
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"fixed_interval" : "2w"
}
}
}
}
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"fixed_interval" : "2w"
}
}
}
}
注意
在所有情况下,当指定的结束时间不存在时,实际结束时间是该时间之后最近的可用时间。
广泛分布的应用程序还必须考虑一些变幻莫测的情况,比如有些国家在凌晨12:01开始和停止夏令时,因此每年在周日结束时只有一分钟,周六则有59分钟,还有一些国家决定跨越国际日期变更线。像这样的情况会使不规则时区偏移看起来很容易。
像往常一样,严格的测试,特别是围绕时间变化事件的测试,将确保您的时间间隔规格是您所期望的。
警告:为了避免意想不到的结果,所有连接的服务器和客户端必须同步到可靠的网络时间服务。
不支持小数时间值,但可以通过转换到另一个时间单位来解决这个问题(例如,1.5h可以指定为90m)。
您还可以使用时间单位解析所支持的缩写来指定时间值。
Keys
在内部,日期表示为一个64位数字,表示时间戳,单位为毫秒-自-epoch(01/01/1970午夜UTC)。这些时间戳作为桶的键名返回。key_as_string是使用format参数规范转换为格式化日期字符串的时间戳:
如果不指定格式,则使用字段映射中指定的第一个日期格式。
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "1M",
"format" : "yyyy-MM-dd"
}
}
}
}
专用于日期值的范围聚合。这种聚合与普通范围聚合的主要区别在于,from和to值可以用Date Math表达式表示,而且还可以指定from和to响应字段返回的日期格式。注意,这个聚合包括每个范围的from值,而不包括to值。
POST /sales/_search?size=0
{
"aggs": {
"range": {
"date_range": {
"field": "date",
"format": "MM-yyyy",
"ranges": [
{ "to": "now-10M/M" }, #<现在减去10个月,四舍五入到月初。
{ "from": "now-10M/M" } #>=现在减去10个月,四舍五入到月初。
]
}
}
}
}
响应:
{
...
"aggregations": {
"range": {
"buckets": [
{
"to": 1.4436576E12,
"to_as_string": "10-2015",
"doc_count": 7,
"key": "*-10-2015"
},
{
"from": 1.4436576E12,
"from_as_string": "10-2015",
"doc_count": 0,
"key": "10-2015-*"
}
]
}
}
}
Missing Value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。这是通过添加一组fieldname: value映射来指定每个字段的默认值来实现的。
POST /sales/_search?size=0
{
"aggs": {
"range": {
"date_range": {
"field": "date",
"missing": "1976/11/30",
"ranges": [
{
"key": "Older",
"to": "2016/02/01"
},
{
"key": "Newer",
"from": "2016/02/01",
"to" : "now/d"
}
]
}
}
}
}
日期字段中没有值的文档将被添加到“Older”bucket中,就像它们的日期值为“1976-11-30”一样。
时区
日期可以通过指定time_zone参数从其他时区转换为UTC。
时区可以指定为ISO 8601 UTC偏移量(例如+01:00或-08:00),也可以指定为TZ数据库中的一个时区id。
time_zone参数还应用于日期数学表达式的舍入。以在CET时区舍入到一天的开始为例,您可以执行以下操作:
POST /sales/_search?size=0
{
"aggs": {
"range": {
"date_range": {
"field": "date",
"time_zone": "CET",
"ranges": [
{ "to": "2016/02/01" }, #此日期将转换为2016-02-01T00:00:00.000+01:00。
{ "from": "2016/02/01", "to" : "now/d" }, #now/d将四舍五入到欧洲中部时区当天的开始。
{ "from": "now/d" }
]
}
}
}
}
Keyed响应
将keyyed标志设置为true将为每个bucket关联一个唯一的字符串键,并以哈希而不是数组的形式返回范围:
POST /sales/_search?size=0
{
"aggs": {
"range": {
"date_range": {
"field": "date",
"format": "MM-yyy",
"ranges": [
{ "to": "now-10M/M" },
{ "from": "now-10M/M" }
],
"keyed": true
}
}
}
}
响应:
{
...
"aggregations": {
"range": {
"buckets": {
"*-10-2015": {
"to": 1.4436576E12,
"to_as_string": "10-2015",
"doc_count": 7
},
"10-2015-*": {
"from": 1.4436576E12,
"from_as_string": "10-2015",
"doc_count": 0
}
}
}
}
}
也可以为每个范围定制键:
POST /sales/_search?size=0
{
"aggs": {
"range": {
"date_range": {
"field": "date",
"format": "MM-yyy",
"ranges": [
{ "from": "01-2015", "to": "03-2015", "key": "quarter_01" },
{ "from": "03-2015", "to": "06-2015", "key": "quarter_02" }
],
"keyed": true
}
}
}
}
响应:
{
...
"aggregations": {
"range": {
"buckets": {
"quarter_01": {
"from": 1.4200704E12,
"from_as_string": "01-2015",
"to": 1.425168E12,
"to_as_string": "03-2015",
"doc_count": 5
},
"quarter_02": {
"from": 1.425168E12,
"from_as_string": "03-2015",
"to": 1.4331168E12,
"to_as_string": "06-2015",
"doc_count": 2
}
}
}
}
}
与采样器聚合一样,这是一个过滤聚合,用于将任何子聚合的处理限制为得分最高的文档样本。diverfied_sampler聚合增加了限制共享一个共同值(如“author”)的匹配数量的能力。
任何优秀的市场研究人员都会告诉你,在处理数据样本时,重要的是样本代表了各种健康的观点,而不是被任何单一的声音所扭曲。使用这些多样化设置的聚合和抽样也是如此,可以提供一种方法来消除内容中的偏见(人口过多的地理位置、时间轴上的大峰值或过度活跃的论坛垃圾邮件制造者)。
用例示例:
将分析的重点集中在高相关性匹配上,而不是低质量匹配的潜在长尾
通过确保来自不同来源的内容的公平呈现来消除分析中的偏见
减少聚合的运行成本,可以只使用样本产生有用的结果,例如,significant_terms
字段或脚本设置的选择用于提供用于重复数据删除的值,max_docs_per_value设置控制在任何一个共享公共值的分片上收集的文档的最大数量。max_docs_per_value的默认设置是1。
如果选择的字段或脚本为单个文档产生多个值,聚合将抛出一个错误(出于效率考虑,不支持使用多值字段进行重复数据删除)。
例如:
我们可能想看看哪些标签与StackOverflow论坛帖子中的#elasticsearch紧密相关,但忽略了一些高产用户倾向于将#Kibana拼写为#Cabana的影响。
POST /stackoverflow/_search?size=0
{
"query": {
"query_string": {
"query": "tags:elasticsearch"
}
},
"aggs": {
"my_unbiased_sample": {
"diversified_sampler": {
"shard_size": 200,
"field" : "author"
},
"aggs": {
"keywords": {
"significant_terms": {
"field": "tags",
"exclude": ["elasticsearch"]
}
}
}
}
}
}
响应:
{
...
"aggregations": {
"my_unbiased_sample": {
"doc_count": 151,#共抽取151份文献。
"keywords": {#因为我们要求样本中任何一位作者最多提供一篇文章,所以,significant_terms聚合的结果不会因任何一位作者的怪癖而产生偏差。
"doc_count": 151,
"bg_count": 650,
"buckets": [
{
"key": "kibana",
"doc_count": 150,
"score": 2.213,
"bg_count": 200
}
]
}
}
}
}
脚本示例:
在这个场景中,我们可能希望对字段值的组合进行多样化。我们可以使用脚本生成标签字段中多个值的散列,以确保我们没有一个由相同的重复标签组合组成的示例。
POST /stackoverflow/_search?size=0
{
"query": {
"query_string": {
"query": "tags:kibana"
}
},
"aggs": {
"my_unbiased_sample": {
"diversified_sampler": {
"shard_size": 200,
"max_docs_per_value" : 3,
"script" : {
"lang": "painless",
"source": "doc['tags'].hashCode()"
}
},
"aggs": {
"keywords": {
"significant_terms": {
"field": "tags",
"exclude": ["kibana"]
}
}
}
}
}
}
响应:
{
...
"aggregations": {
"my_unbiased_sample": {
"doc_count": 6,
"keywords": {
"doc_count": 6,
"bg_count": 650,
"buckets": [
{
"key": "logstash",
"doc_count": 3,
"score": 2.213,
"bg_count": 50
},
{
"key": "elasticsearch",
"doc_count": 3,
"score": 1.34,
"bg_count": 200
}
]
}
}
}
}
shard_size
shard_size参数限制在每个碎片上处理的样例中收集多少个得分最高的文档。缺省值为100。
max_docs_per_value
max_docs_per_value是一个可选参数,用于限制每个重复数据删除值所允许的文档数量。默认值为“1”。
excution_hint
可选的execution_hint设置会影响重复数据删除值的管理。在执行重复数据删除时,每个选项将在内存中保留shard_size值,但保留的值类型可以按以下方式控制:
默认设置是,如果该信息从Lucene索引中可用,则使用global_ordinals,否则返回到map。bytes_hash设置在某些情况下可能更快,但由于哈希冲突的可能性,在重复数据删除逻辑中引入了误报的可能性。请注意,Elasticsearch将忽略执行提示的选择,如果它不适用,并且这些提示没有向后兼容性保证。
局限性
不能嵌套在breadth_first聚合下
作为一个基于质量的过滤器,diverfied_sampler聚合需要访问为每个文档生成的相关性评分。因此,它不能嵌套在将collect_mode从默认的depth_first模式切换为breadth_first的术语聚合下,因为这会丢弃分数。在这种情况下,将抛出一个错误。
有限的分离逻辑。
重复数据删除逻辑只应用于一个分片级,因此不会应用于跨分片。
地理位置/日期字段没有专门的语法
目前,用于定义多样化值的语法是通过选择字段或脚本来定义的——没有添加用于表示地理或日期单位(如“7d”(7天))的语法糖。这种支持可能会在以后的版本中添加,用户目前必须使用脚本创建这些类型的值。
定义当前文档集上下文中与指定筛选器匹配的所有文档的单个桶。这通常用于将当前聚合上下文缩小到特定的一组文档。
例如:
POST /sales/_search?size=0
{
"aggs" : {
"t_shirts" : {
"filter" : { "term": { "type": "t-shirt" } },
"aggs" : {
"avg_price" : { "avg" : { "field" : "price" } }
}
}
}
}
在上面的例子中,我们计算所有t恤类型的产品的平均价格。
响应:
{
...
"aggregations" : {
"t_shirts" : {
"doc_count" : 3,
"avg_price" : { "value" : 128.33333333333334 }
}
}
}
定义一个多桶聚合,其中每个桶与一个过滤器相关联。每个桶将收集与它相关联的筛选器匹配的所有文档。
例如:
PUT /logs/_bulk?refresh
{ "index" : { "_id" : 1 } }
{ "body" : "warning: page could not be rendered" }
{ "index" : { "_id" : 2 } }
{ "body" : "authentication error" }
{ "index" : { "_id" : 3 } }
{ "body" : "warning: connection timed out" }
GET logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"filters" : {
"errors" : { "match" : { "body" : "error" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
在上面的例子中,我们分析日志消息。聚合将构建两个日志消息集合(桶)——一个用于所有包含错误的日志消息,另一个用于所有包含警告的日志消息。
{
"took": 9,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"messages": {
"buckets": {
"errors": {
"doc_count": 1
},
"warnings": {
"doc_count": 2
}
}
}
}
}
匿名过滤器
filters字段也可以作为过滤器数组提供,如下所示:
GET logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"filters" : [
{ "match" : { "body" : "error" }},
{ "match" : { "body" : "warning" }}
]
}
}
}
}
过滤后的桶将按照请求中提供的相同顺序返回。这个例子的响应是:
{
"took": 4,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"messages": {
"buckets": [
{
"doc_count": 1
},
{
"doc_count": 2
}
]
}
}
}
other Bucket
other_bucket参数可以设置为向响应中添加一个桶,该桶将包含不匹配任何给定过滤器的所有文档。取值说明如下:
false:
不计算另一个桶
true:
如果正在使用命名过滤器,则返回另一个桶(默认命名为_other_);如果正在使用匿名过滤器,则返回最后一个桶
参数other_bucket_key可用于将另一个桶的key设置为默认值_other_以外的值。设置此参数将隐式地将other_bucket参数设置为true。
下面的代码段显示了一个响应,其中请求另一个桶命名为other_messages。
PUT logs/_doc/4?refresh
{
"body": "info: user Bob logged out"
}
GET logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"other_bucket_key": "other_messages",
"filters" : {
"errors" : { "match" : { "body" : "error" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
PUT logs/_doc/4?refresh
{
"body": "info: user Bob logged out"
}
GET logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"other_bucket_key": "other_messages",
"filters" : {
"errors" : { "match" : { "body" : "error" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
响应:
{
"took": 3,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"messages": {
"buckets": {
"errors": {
"doc_count": 1
},
"warnings": {
"doc_count": 2
},
"other_messages": {
"doc_count": 1 #info级别的日志数量
}
}
}
}
}
在搜索执行上下文中定义所有文档的单个桶。此上下文由索引和所搜索的文档类型定义,但不受搜索查询本身的影响。即在全局聚合器下面的聚合不会受到查询条件中的条件影响,将视为查询全部
全局聚合器只能作为顶级聚合器,因为在另一个桶聚合器中嵌入全局聚合器没有意义。
例如:
POST /sales/_search?size=0
{
"query" : {
"match" : { "type" : "t-shirt" }
},
"aggs" : {
"all_products" : {
"global" : {}, #全局聚合的主体为空
"aggs" : { #为此全局聚合注册的子聚合
"avg_price" : { "avg" : { "field" : "price" } }
}
},
"t_shirts": { "avg" : { "field" : "price" } }
}
}
上面的聚合演示了如何在搜索上下文中计算所有文档的聚合(本例中为avg_price),而不考虑查询(在我们的示例中,它将计算目录中所有产品的平均价格,而不仅仅是“衬衫”的平均价格)。
响应:
{
...
"aggregations" : {
"all_products" : {
"doc_count" : 7,# 聚合的文档数量(在本例中是搜索上下文中的所有文档)
"avg_price" : {
"value" : 140.71428571428572 #指数中所有产品的平均价格
}
},
"t_shirts": {
"value" : 128.33333333333334 # 所有t恤的平均价格
}
}
}
基于多桶值源的聚合,可应用于从文档中提取的数值。它在值上动态地构建固定大小(也就是间隔)的桶。例如,如果文档有一个包含价格(数字)的字段,我们可以配置这个聚合以动态地构建间隔为5的桶(对于价格,它可能表示$5)。当聚合执行时,将计算每个文档的价格字段,并将四舍五入到最接近的存储桶—例如,如果价格为32,存储桶大小为5,则四舍五入将产生结果
bucket_key = Math.floor((value - offset) / interval) * interval + offset
interval必须是正小数,而offset必须是[0,interval)中的小数(大于或等于0且小于interval的小数)
以下代码段根据产品的价格以50为间隔进行“桶”:
POST /sales/_search?size=0
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50
}
}
}
}
下面可能是响应:
{
...
"aggregations": {
"prices" : {
"buckets": [
{
"key": 0.0,
"doc_count": 1
},
{
"key": 50.0,
"doc_count": 1
},
{
"key": 100.0,
"doc_count": 0
},
{
"key": 150.0,
"doc_count": 2
},
{
"key": 200.0,
"doc_count": 3
}
]
}
}
}
最低文件数量
上面的响应显示没有文档的价格落在[100,150)的范围内。默认情况下,响应将用空桶填充直方图中的空白。通过min_doc_count设置,可以改变这一点,并请求具有更高最小计数的桶:
POST /sales/_search?size=0
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"min_doc_count" : 1
}
}
}
}
响应:
{
...
"aggregations": {
"prices" : {
"buckets": [
{
"key": 0.0,
"doc_count": 1
},
{
"key": 50.0,
"doc_count": 1
},
{
"key": 150.0,
"doc_count": 2
},
{
"key": 200.0,
"doc_count": 3
}
]
}
}
}
默认情况下,直方图返回数据本身范围内的所有桶,也就是说,具有最小值的文档(带有直方图的文档)将确定最小桶(键值最小的桶),具有最高值的文档将确定最大桶(键值最高的桶)。通常,当请求空桶时,这会导致混乱,特别是当数据也被过滤时。
为了理解其中的原因,让我们看一个例子:
假设您正在过滤请求,以获取值在0到500之间的所有文档,此外,您希望使用间隔为50的直方图对每个价格的数据进行切片。您还可以指定"min_doc_count": 0,因为您希望获得所有桶,甚至是空桶。如果碰巧所有产品(文档)的价格都高于100,那么您将获得的第一个桶将是以100为键的桶。这是令人困惑的,因为很多时候,您也希望这些桶在0 - 100之间。
通过extended_bounds设置,您现在可以“强制”直方图聚合在特定的最小值上开始构建桶,也可以一直构建到最大值(即使不再有文档)。使用extended_bounds只在min_doc_count为0时才有意义(如果min_doc_count大于0,空桶将永远不会返回)。
注意(顾名思义)extended_bounds并不过滤桶。意思是,如果extended_bounds。Min比从文档中提取的值要高,文档仍然会规定第一个桶是什么(extended_bounds也是如此。Max和最后一桶)。对于过滤桶,应该使用适当的from/to设置将直方图聚合嵌套在范围过滤器聚合下。
例如:
POST /sales/_search?size=0
{
"query" : {
"constant_score" : { "filter": { "range" : { "price" : { "to" : "500" } } } }
},
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"extended_bounds" : {
"min" : 0,
"max" : 500
}
}
}
}
}
排序
默认情况下,返回的桶是按键升序排序的,不过可以使用顺序设置控制顺序行为。支持与术语聚合相同的顺序功能。
偏移量
默认情况下,桶键从0开始,然后以间隔间隔的步长继续,例如,如果间隔为10,前三个桶(假设其中有数据)将是[0,10),[10,20),[20,30)。桶的边界可以通过使用offset选项来移动。
这可以用一个例子来最好地说明。如果有10个值从5到14的文档,那么使用间隔10将生成两个存储桶,每个存储桶有5个文档。如果使用额外的偏移量5,则只有一个存储桶[5,15)包含所有的10个文档。
偏移量会在原本的基础上将起始值加上偏移量
响应格式
默认情况下,桶以有序数组的形式返回。也可以将响应请求为哈希,而不是由桶的键来确定:
POST /sales/_search?size=0
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"keyed" : true
}
}
}
}
响应:
{
...
"aggregations": {
"prices": {
"buckets": {
"0.0": {
"key": 0.0,
"doc_count": 1
},
"50.0": {
"key": 50.0,
"doc_count": 1
},
"100.0": {
"key": 100.0,
"doc_count": 0
},
"150.0": {
"key": 150.0,
"doc_count": 2
},
"200.0": {
"key": 200.0,
"doc_count": 3
}
}
}
}
}
Missing Value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /sales/_search?size=0
{
"aggs" : {
"quantity" : {
"histogram" : {
"field" : "quantity",
"interval": 10,
"missing": 0
}
}
}
}
quantity字段中没有值的文档将与值为0的文档归入同一个bucket。
就像专用的日期范围聚合一样,IP类型的字段也有专用的范围聚合:
例如:
GET /ip_addresses/_search
{
"size": 10,
"aggs" : {
"ip_ranges" : {
"ip_range" : {
"field" : "ip",
"ranges" : [
{ "to" : "10.0.0.5" },
{ "from" : "10.0.0.5" }
]
}
}
}
}
响应:
{
...
"aggregations": {
"ip_ranges": {
"buckets" : [
{
"key": "*-10.0.0.5",
"to": "10.0.0.5",
"doc_count": 10
},
{
"key": "10.0.0.5-*",
"from": "10.0.0.5",
"doc_count": 260
}
]
}
}
}
IP范围也可以定义为CIDR掩码:
GET /ip_addresses/_search
{
"size": 0,
"aggs" : {
"ip_ranges" : {
"ip_range" : {
"field" : "ip",
"ranges" : [
{ "mask" : "10.0.0.0/25" },
{ "mask" : "10.0.0.127/25" }
]
}
}
}
}
响应:
{
...
"aggregations": {
"ip_ranges": {
"buckets": [
{
"key": "10.0.0.0/25",
"from": "10.0.0.0",
"to": "10.0.0.128",
"doc_count": 128
},
{
"key": "10.0.0.127/25",
"from": "10.0.0.0",
"to": "10.0.0.128",
"doc_count": 128
}
]
}
}
}
Keyed响应
将keyyed标志设置为true将为每个bucket关联一个唯一的字符串键,并以哈希而不是数组的形式返回范围:
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "to" : "10.0.0.5" },
{ "from" : "10.0.0.5" }
],
"keyed": true
}
}
}
}
响应:
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "to" : "10.0.0.5" },
{ "from" : "10.0.0.5" }
],
"keyed": true
}
}
}
}
也可以为每个范围定制键:
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "key": "infinity", "to" : "10.0.0.5" },
{ "key": "and-beyond", "from" : "10.0.0.5" }
],
"keyed": true
}
}
}
}
响应:
{
...
"aggregations": {
"ip_ranges": {
"buckets": {
"infinity": {
"to": "10.0.0.5",
"doc_count": 10
},
"and-beyond": {
"from": "10.0.0.5",
"doc_count": 260
}
}
}
}
}
基于单桶聚合的字段数据,它创建当前文档集上下文中缺少字段值(实际上是缺少字段或具有配置的NULL值集)的所有文档的桶。此聚合器通常与其他字段数据桶聚合器(例如范围)一起使用,以返回由于缺少字段数据值而无法放置在任何其他桶中的所有文档的信息。
例如:
POST /sales/_search?size=0
{
"aggs" : {
"products_without_a_price" : {
"missing" : { "field" : "price" }
}
}
}
在上面的例子中,我们得到了没有价格的产品的总数。
响应:
{
...
"aggregations" : {
"products_without_a_price" : {
"doc_count" : 00
}
}
}
支持聚合嵌套文档的特殊单桶聚合。
例如,假设我们有一个产品索引,每个产品都有一个经销商列表——每个经销商都有自己的产品价格。映射可以是这样的:
PUT /products
{
"mappings": {
"properties" : {
"resellers" : { #Resellers是一个包含嵌套文档的数组。
"type" : "nested",
"properties" : {
"reseller" : { "type" : "text" },
"price" : { "type" : "double" }
}
}
}
}
}
下面的请求添加了两个经销商的产品:
PUT /products/_doc/0
{
"name": "LED TV", #我们正在为name属性使用动态映射。
"resellers": [
{
"reseller": "companyA",
"price": 350
},
{
"reseller": "companyB",
"price": 500
}
]
}
下面的请求返回一个产品可以购买的最低价格:
GET /products/_search
{
"query" : {
"match" : { "name" : "led tv" }
},
"aggs" : {
"resellers" : {
"nested" : {
"path" : "resellers"
},
"aggs" : {
"min_price" : { "min" : { "field" : "resellers.price" } }
}
}
}
}
正如您在上面看到的,嵌套聚合需要顶层文档中嵌套文档的路径。然后可以在这些嵌套文档上定义任何类型的聚合。
响应:
{
...
"aggregations": {
"resellers": {
"doc_count": 2,
"min_price": {
"value": 350
}
}
}
}
一个特殊的单桶聚合,它选择具有指定类型的父文档,如连接字段中定义的那样。
这个聚合只有一个选项:
type:应选择的子类型。例如,假设我们有一个问题和答案的索引。应答类型在映射中有以下join字段:
PUT parent_example
{
"mappings": {
"properties": {
"join": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}
问题文档包含一个标记字段,答案文档包含一个所有者字段。使用父聚合,所有者桶可以映射到单个请求中的标记桶,即使这两个字段存在于两种不同的文档中。
一个问题文档的例子:
PUT parent_example/_doc/1
{
"join": {
"name": "question"
},
"body": "<p>I have Windows 2003 server and i bought a new Windows 2008 server...",
"title": "Whats the best way to file transfer my site from server to a newer one?",
"tags": [
"windows-server-2003",
"windows-server-2008",
"file-transfer"
]
}
回答文件的例子:
PUT parent_example/_doc/2?routing=1
{
"join": {
"name": "answer",
"parent": "1"
},
"owner": {
"location": "Norfolk, United Kingdom",
"display_name": "Sam",
"id": 48
},
"body": "<p>Unfortunately you're pretty much limited to FTP...",
"creation_date": "2009-05-04T13:45:37.030"
}
PUT parent_example/_doc/3?routing=1&refresh
{
"join": {
"name": "answer",
"parent": "1"
},
"owner": {
"location": "Norfolk, United Kingdom",
"display_name": "Troll",
"id": 49
},
"body": "<p>Use Linux...",
"creation_date": "2009-05-05T13:45:37.030"
}
可以构建以下请求,将两者连接在一起:
POST parent_example/_search?size=0
{
"aggs": {
"top-names": {
"terms": {
"field": "owner.display_name.keyword",
"size": 10
},
"aggs": {
"to-questions": {
"parent": {
"type" : "answer" #类型指向名称answer的类型/映射。
},
"aggs": {
"top-tags": {
"terms": {
"field": "tags.keyword",
"size": 10
}
}
}
}
}
}
}
}
上面的示例返回顶部答案所有者和每个所有者的顶部问题标签。
可能的反应:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"top-names": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Sam",
"doc_count": 1, #带“山姆”、“喷子”等标签的答卷数量。
"to-questions": {
"doc_count": 1, #与带有Sam、Troll等标记的回答文档相关的问题文档的数量。
"top-tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "file-transfer",
"doc_count": 1
},
{
"key": "windows-server-2003",
"doc_count": 1
},
{
"key": "windows-server-2008",
"doc_count": 1
}
]
}
}
},
{
"key": "Troll",
"doc_count": 1,
"to-questions": {
"doc_count": 1,
"top-tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "file-transfer",
"doc_count": 1
},
{
"key": "windows-server-2003",
"doc_count": 1
},
{
"key": "windows-server-2008",
"doc_count": 1
}
]
}
}
}
]
}
}
}
基于聚合的多桶值源,允许用户定义一组范围——每个范围代表一个桶。在聚合过程中,从每个文档提取的值将根据每个桶范围和相关/匹配文档的“桶”进行检查。注意,这个聚合包括每个范围的from值,而不包括to值。
例如:
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 100.0 },
{ "from" : 100.0, "to" : 200.0 },
{ "from" : 200.0 }
]
}
}
}
}
响应:
{
...
"aggregations": {
"price_ranges" : {
"buckets": [
{
"key": "*-100.0",
"to": 100.0,
"doc_count": 2
},
{
"key": "100.0-200.0",
"from": 100.0,
"to": 200.0,
"doc_count": 2
},
{
"key": "200.0-*",
"from": 200.0,
"doc_count": 3
}
]
}
}
}
Keyed 响应
将keyyed标志设置为true将为每个bucket关联一个唯一的字符串键,并以哈希而不是数组的形式返回范围:
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"keyed" : true,
"ranges" : [
{ "to" : 100 },
{ "from" : 100, "to" : 200 },
{ "from" : 200 }
]
}
}
}
}
响应:
{
...
"aggregations": {
"price_ranges" : {
"buckets": {
"*-100.0": {
"to": 100.0,
"doc_count": 2
},
"100.0-200.0": {
"from": 100.0,
"to": 200.0,
"doc_count": 2
},
"200.0-*": {
"from": 200.0,
"doc_count": 3
}
}
}
}
}
也可以为每个范围定制键:
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"keyed" : true,
"ranges" : [
{ "key" : "cheap", "to" : 100 },
{ "key" : "average", "from" : 100, "to" : 200 },
{ "key" : "expensive", "from" : 200 }
]
}
}
}
}
响应:
{
...
"aggregations": {
"price_ranges" : {
"buckets": {
"cheap": {
"to": 100.0,
"doc_count": 2
},
"average": {
"from": 100.0,
"to": 200.0,
"doc_count": 2
},
"expensive": {
"from": 200.0,
"doc_count": 3
}
}
}
}
}
脚本
范围聚合接受一个脚本参数。此参数允许定义将在聚合执行期间执行的内联脚本。
下面的例子展示了如何使用内联脚本语言和无脚本参数:
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"script" : {
"lang": "painless",
"source": "doc['price'].value"
},
"ranges" : [
{ "to" : 100 },
{ "from" : 100, "to" : 200 },
{ "from" : 200 }
]
}
}
}
}
也可以使用存储脚本。下面是一个简单的存储脚本:
POST /_scripts/convert_currency
{
"script": {
"lang": "painless",
"source": "doc[params.field].value * params.conversion_rate"
}
}
这个新的存储脚本可以像这样在范围聚合中使用:
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"script" : {
"id": "convert_currency", #已存储脚本Id
"params": { #执行存储的脚本时使用的参数
"field": "price",
"conversion_rate": 0.835526591
}
},
"ranges" : [
{ "from" : 0, "to" : 100 },
{ "from" : 100 }
]
}
}
}
}
值脚本
假设产品的价格是美元,但我们想要欧元的价格范围。我们可以使用值脚本在聚合之前转换价格(假设转化率为0.8)
GET /sales/_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"script" : {
"source": "_value * params.conversion_rate",
"params" : {
"conversion_rate" : 0.8
}
},
"ranges" : [
{ "to" : 35 },
{ "from" : 35, "to" : 70 },
{ "from" : 70 }
]
}
}
}
}
子聚合
下面的示例不仅将文档“桶”到不同的桶中,而且还计算每个价格范围内的价格统计信息
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 100 },
{ "from" : 100, "to" : 200 },
{ "from" : 200 }
]
},
"aggs" : {
"price_stats" : {
"stats" : { "field" : "price" }
}
}
}
}
}
响应:
{
...
"aggregations": {
"price_ranges": {
"buckets": [
{
"key": "*-100.0",
"to": 100.0,
"doc_count": 2,
"price_stats": {
"count": 2,
"min": 10.0,
"max": 50.0,
"avg": 30.0,
"sum": 60.0
}
},
{
"key": "100.0-200.0",
"from": 100.0,
"to": 200.0,
"doc_count": 2,
"price_stats": {
"count": 2,
"min": 150.0,
"max": 175.0,
"avg": 162.5,
"sum": 325.0
}
},
{
"key": "200.0-*",
"from": 200.0,
"doc_count": 3,
"price_stats": {
"count": 3,
"min": 200.0,
"max": 200.0,
"avg": 200.0,
"sum": 600.0
}
}
]
}
}
}
如果子聚合也基于与范围聚合相同的值源(如上面示例中的统计值聚合),则可以为其省略值源定义。下面将返回与上面相同的响应:
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 100 },
{ "from" : 100, "to" : 200 },
{ "from" : 200 }
]
},
"aggs" : {
"price_stats" : {
"stats" : {} #我们不需要指定价格,因为默认情况下我们从父范围聚合中“继承”了它
}
}
}
}
}
一个基于多桶值源的聚合,它可以找到“罕见”术语——位于分布的长尾且不常见的术语。从概念上讲,这类似于按_count升序排序的术语聚合。正如术语聚合文档中所指出的,实际上按计数升序排列一个术语agg会产生无限错误。相反,您应该使用rare_terms聚合
语法
rare_terms聚合单独看起来像这样:
{
"rare_terms": {
"field": "the_field",
"max_doc_count": 1
}
}
rare_terms参数:
| 参数名称 | 描述 | 要求 | 默认值 |
|---|---|---|---|
field |
我们希望在这个字段找到稀有术语 | 必选 | |
max_doc_count |
一个术语应该出现的最大文档数量。 | 可选 | 1 |
precision |
内部布谷鸟过滤器的精度。精度越小,近似值越高,但内存占用越高。不能小于0.00001 | 可选 | 0.01 |
include |
应该包含在聚合中的术语 | 可选 | |
exclude |
应该从集合中排除的术语 | 可选 | |
missing |
如果文档没有聚合字段,则应使用的值 | 可选 |
例如:
GET /_search
{
"aggs" : {
"genres" : {
"rare_terms" : {
"field" : "genre"
}
}
}
}
响应:
{
...
"aggregations" : {
"genres" : {
"buckets" : [
{
"key" : "swing",
"doc_count" : 1
}
]
}
}
}
在本例中,我们看到的唯一存储单元是“swing”存储单元,因为它是一个文档中出现的唯一术语。如果我们将max_doc_count增加到2,我们将看到更多的桶:
GET /_search
{
"aggs" : {
"genres" : {
"rare_terms" : {
"field" : "genre",
"max_doc_count": 2
}
}
}
}
现在显示了doc_count为2的“jazz”术语:
{
...
"aggregations" : {
"genres" : {
"buckets" : [
{
"key" : "swing",
"doc_count" : 1
},
{
"key" : "jazz",
"doc_count" : 2
}
]
}
}
}
最大文档数量
max_doc_count参数用于控制一个术语可以拥有的文档计数的上限。rare_terms agg不像terms agg那样有大小限制。这意味着将返回与max_doc_count条件匹配的术语。聚合以这种方式进行,以避免影响术语聚合的升序问题。
然而,这确实意味着如果选择错误,将返回大量结果。为了限制这种设置的危险,max_doc_count的最大值为100。
最大桶限制
罕见术语聚合更容易使搜索出错。Max_buckets软限制比其他聚合由于它的工作方式。在聚合收集结果时,max_bucket软限制是在每个分片的基础上计算的。一个术语可能在一个分片上是“稀有的”,但一旦所有的分片结果合并在一起,它就变成了“不稀有的”。这意味着单个碎片往往会收集更多的桶,而不是真正罕见的,因为它们只有自己的本地视图。这个列表最终会在协调节点上被修剪成正确的、更小的稀有术语列表……但分片可能会
当对可能有许多“稀有”术语的字段进行聚合时,可能需要增加max_buckets软限制。或者,你可能需要找到一种方法来过滤结果以返回更少的稀有值(更小的时间跨度,按类别过滤等),或者重新评估你对“稀有”的定义(例如,如果某个东西出现了10万次,它真的是“稀有”吗?)
文件数量是近似值
确定数据集中“稀有”术语的简单方法是将所有值放在一个映射中,随着访问每个文档增加计数,然后返回底部的n行。这甚至不能超过中等规模的数据集。分片方法只从每个分片中保留“前n个”值(也就是术语聚合)是失败的,因为问题的长尾性质意味着如果不简单地从所有分片中收集所有值,就不可能找到“前n个”底部值。
相反,Rare Terms聚合使用了不同的近似算法:
执行后,值的映射是max_doc_count阈值下的“稀有”术语的映射。然后这个map和CuckooFilter与所有其他碎片合并。如果有大于阈值的术语(或出现在不同分片的CuckooFilter中),则该术语将从合并列表中删除。值的最终映射作为“稀有”项返回给用户。
CuckooFilters有可能返回假阳性(他们可以说一个值在他们的集合中存在,而实际上它不存在)。由于CuckooFilter用于查看一个术语是否超过阈值,这意味着来自CuckooFilter的假阳性将错误地认为一个值是常见的,而实际上它不是(从而将它从最终的桶列表中排除)。实际上,这意味着聚合表现出假阴性行为,因为过滤器的使用与人们通常认为的近似集隶属关系草图“相反”。
论文中更详细地描述了CuckooFilters:
范斌等。“布谷鸟滤镜:实际上比开花效果更好。”第十届ACM国际新兴网络实验与技术会议论文集。ACM, 2014年。
精确率
虽然内部的CuckooFilter本质上是近似的,但假阴性率可以通过一个精确的参数来控制。这允许用户用更多的运行时内存换取更准确的结果。
默认的精度是0.001,最小的(例如,最精确和最大的内存开销)是0.00001。下面是一些图表,展示了聚合的准确性如何受到不同术语的精度和数量的影响。
x轴显示聚合所看到的不同值的数量,y轴显示误差百分比。每个线系列代表一个“稀有”条件(范围从1个稀有物品到10万个稀有物品)。例如,橙色的“10”行表示在1-20m不同的值中,有10个值是“罕见的”(doc_count == 1)
对于测试条件,默认精度0.001保持< 2.5%的精度,并且随着不同值数量的增加,精度以受控的线性方式缓慢降低。
默认精度为0.001的内存配置文件为1.748,其中n是聚合所看到的不同值的数量(也可以粗略估计,例如,2000万个唯一值大约是30mb的内存)。内存使用与不同值的数量是线性的,无论选择哪种精度,精度只影响内存剖面的斜率。
相比之下,2000万个桶的等效术语聚合大约是20m * 69b == ~1.38gb(69字节是对空桶成本的非常乐观的估计,远低于断路器的成本)。因此,尽管rare_terms agg相对较重,但它仍然比等效的terms聚合小几个数量级
过滤值
可以过滤将要为其创建的桶的值。这可以使用基于正则表达式字符串或精确值数组的include和exclude参数来完成。此外,include子句可以使用分区表达式进行筛选
示例:
GET /_search
{
"aggs" : {
"genres" : {
"rare_terms" : {
"field" : "genre",
"include" : "swi*",
"exclude" : "electro*"
}
}
}
}
在上面的示例中,将为所有以swi开头的标记创建存储桶,以electro开头的标记除外(因此将聚合标记swing,但不聚合标记electro_swing)。包含正则表达式将确定“允许”聚合哪些值,而排除正则表达式将确定不应该聚合哪些值。当定义了两者时,排除具有优先级,即首先计算包含,然后才计算排除。
用精确的值过滤值
对于基于精确值的匹配,include和exclude参数可以简单地接受一个字符串数组,该数组表示在索引中找到的术语:
GET /_search
{
"aggs" : {
"genres" : {
"rare_terms" : {
"field" : "genre",
"include" : ["swing", "rock"],
"exclude" : ["jazz"]
}
}
}
}
Missing Value
missing参数定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
GET /_search
{
"aggs" : {
"genres" : {
"rare_terms" : {
"field" : "genre",
"missing": "N/A"
}
}
}
}
在tags字段中没有值的文档将与值为N/ a的文档归入同一个bucket。
嵌套、RareTerms和评分子聚合
RareTerms聚合必须在breadth_first模式下操作,因为它需要在超过文档计数阈值时删除术语。这一需求意味着RareTerms聚合与某些需要depth_first的聚合组合不兼容。特别是,对嵌套内的子聚合进行评分会迫使整个聚合树以depth_first模式运行。这将引发一个异常,因为RareTerms无法处理depth_first。
作为一个具体的例子,如果rare_terms聚合是嵌套聚合的子聚合,并且是rare_terms的子聚合之一
特殊的单桶聚合,支持从嵌套文档聚合到父文档。实际上,这个聚合可以跳出嵌套的块结构并链接到其他嵌套结构或根文档,这允许在嵌套聚合中嵌套不属于嵌套对象的其他聚合。
reverse_nested聚合必须在嵌套聚合中定义。
选项:
例如,假设我们有一个包含问题和评论的票证系统的索引。注释作为嵌套文档内联到问题文档中。映射可以是这样的:
PUT /issues
{
"mappings": {
"properties" : {
"tags" : { "type" : "keyword" },
"comments" : { #注释是一个数组,在问题对象下保存嵌套的文档。
"type" : "nested",
"properties" : {
"username" : { "type" : "keyword" },
"comment" : { "type" : "text" }
}
}
}
}
}
下面的聚合将返回评论最多的评论者的用户名,以及每个评论最多的评论者所评论的问题的顶部标签:
GET /issues/_search
{
"query": {
"match_all": {}
},
"aggs": {
"comments": {
"nested": {
"path": "comments"
},
"aggs": {
"top_usernames": {
"terms": {
"field": "comments.username"
},
"aggs": {
"comment_to_issue": {
"reverse_nested": {}, #反向嵌套聚合,连接回根/主文档级别,因为没有定义路径。如果映射中定义了多层嵌套对象类型,那么通过path选项,reverse_nested聚合可以连接回不同的级别
"aggs": {
"top_tags_per_comment": {
"terms": {
"field": "tags"
}
}
}
}
}
}
}
}
}
}
正如您在上面看到的,reverse_nested聚合被放到了嵌套聚合中,因为这是dsl中唯一可以使用reverse_nested聚合的地方。它的唯一目的是连接回嵌套结构中较高层的父文档。
响应:
{
"aggregations": {
"comments": {
"doc_count": 1,
"top_usernames": {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets": [
{
"key": "username_1",
"doc_count": 1,
"comment_to_issue": {
"doc_count": 1,
"top_tags_per_comment": {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets": [
{
"key": "tag_1",
"doc_count": 1
}
...
]
}
}
}
...
]
}
}
}
}
一种过滤聚合,用于将任何子聚合的处理限制为得分最高的文档样本。
用例示例:
例子:
在StackOverflow数据上查询流行术语javascript或更罕见的术语kibana将匹配许多文档-其中大多数缺少kibana这个词。为了将significant_terms聚合集中在得分最高的文档上,这些文档更有可能匹配查询中最有趣的部分,我们使用了一个示例。
POST /stackoverflow/_search?size=0
{
"query": {
"query_string": {
"query": "tags:kibana OR tags:javascript"
}
},
"aggs": {
"sample": {
"sampler": {
"shard_size": 200
},
"aggs": {
"keywords": {
"significant_terms": {
"field": "tags",
"exclude": ["kibana", "javascript"]
}
}
}
}
}
}
响应:
{
...
"aggregations": {
"sample": {
"doc_count": 200,#共抽取文件200份。因此,执行嵌套的significant_terms聚合的成本是有限的,而不是无限的。
"keywords": {
"doc_count": 200,
"bg_count": 650,
"buckets": [
{
"key": "elasticsearch",
"doc_count": 150,
"score": 1.078125,
"bg_count": 200
},
{
"key": "logstash",
"doc_count": 50,
"score": 0.5625,
"bg_count": 50
}
]
}
}
}
}
如果没有采样器聚合,请求查询会考虑低质量匹配的完整“长尾”,因此会识别不太重要的术语,如jquery和angular,而不是专注于更有洞察力的kibana相关术语。
POST /stackoverflow/_search?size=0
{
"query": {
"query_string": {
"query": "tags:kibana OR tags:javascript"
}
},
"aggs": {
"low_quality_keywords": {
"significant_terms": {
"field": "tags",
"size": 3,
"exclude":["kibana", "javascript"]
}
}
}
}
响应:
{
...
"aggregations": {
"low_quality_keywords": {
"doc_count": 600,
"bg_count": 650,
"buckets": [
{
"key": "angular",
"doc_count": 200,
"score": 0.02777,
"bg_count": 200
},
{
"key": "jquery",
"doc_count": 200,
"score": 0.02777,
"bg_count": 200
},
{
"key": "logstash",
"doc_count": 50,
"score": 0.0069,
"bg_count": 50
}
]
}
}
}
Shard_size
shard_size参数限制在每个碎片上处理的样例中收集多少个得分最高的文档。缺省值为100。
局限性
不能嵌套在breadth_first聚合下
作为基于质量的过滤器,采样器聚合需要访问为每个文档生成的相关性评分。因此,它不能嵌套在将collect_mode从默认的depth_first模式切换为breadth_first的术语聚合下,因为这会丢弃分数。在这种情况下,将抛出一个错误。
返回集合中有趣或不寻常的项的聚合。
用例示例:
在所有这些情况下,所选择的术语不仅仅是一组中最流行的术语。这些术语的流行程度在前景和背景之间发生了重大变化。如果“H5N1”一词只存在于1000万个文档索引中的5个文档中,但却在构成用户搜索结果的100个文档中的4个中被发现,那么这就很重要,可能与他们的搜索非常相关。5/10,000,000 vs 4/100在频率上是一个很大的摆动。
一组分析
在最简单的情况下,感兴趣的前景集是与查询匹配的搜索结果,用于统计比较的背景集是从中收集结果的索引。
例如:
GET /_search
{
"query" : {
"terms" : {"force" : [ "British Transport Police" ]}
},
"aggregations" : {
"significant_crime_types" : {
"significant_terms" : { "field" : "crime_type" }
}
}
}
响应:
{
...
"aggregations" : {
"significant_crime_types" : {
"doc_count": 47347,
"bg_count": 5064554,
"buckets" : [
{
"key": "Bicycle theft",
"doc_count": 3640,
"score": 0.371235374214817,
"bg_count": 66799
}
...
]
}
}
}
当查询所有警察部队的所有犯罪指数时,这些结果表明,英国交通警察部队作为处理不成比例的大量自行车盗窃的部队脱颖而出。通常情况下,自行车盗窃只占犯罪总数的1%(66799/5064554),但对于负责处理铁路和车站犯罪的英国交通警察来说,自行车盗窃占犯罪总数的7%(3640/47347)。这一频率显著增加了7倍,因此这种异常现象被强调为最主要的犯罪类型。
使用查询来发现异常的问题是,它只给了我们一个子集来进行比较。为了发现所有其他警察部队的异常情况,我们必须对每个不同的部队重复查询。
在索引中寻找不寻常的模式可能是一种乏味的方法
多层分析
跨多个类别执行分析的一种更简单的方法是使用父级聚合对准备进行分析的数据进行分段。
使用父聚合进行分段的示例:
GET /_search
{
"aggregations": {
"forces": {
"terms": {"field": "force"},
"aggregations": {
"significant_crime_types": {
"significant_terms": {"field": "crime_type"}
}
}
}
}
}
响应:
{
...
"aggregations": {
"forces": {
"doc_count_error_upper_bound": 1375,
"sum_other_doc_count": 7879845,
"buckets": [
{
"key": "Metropolitan Police Service",
"doc_count": 894038,
"significant_crime_types": {
"doc_count": 894038,
"bg_count": 5064554,
"buckets": [
{
"key": "Robbery",
"doc_count": 27617,
"score": 0.0599,
"bg_count": 53182
}
...
]
}
},
{
"key": "British Transport Police",
"doc_count": 47347,
"significant_crime_types": {
"doc_count": 47347,
"bg_count": 5064554,
"buckets": [
{
"key": "Bicycle theft",
"doc_count": 3640,
"score": 0.371,
"bg_count": 66799
}
...
]
}
}
]
}
}
}
现在我们可以使用单个请求对每个警察部队进行异常检测。
我们可以使用其他形式的顶级聚合来分割数据,例如通过地理区域来识别特定犯罪类型的不寻常热点:
GET /_search
{
"aggs": {
"hotspots": {
"geohash_grid": {
"field": "location",
"precision": 5
},
"aggs": {
"significant_crime_types": {
"significant_terms": {"field": "crime_type"}
}
}
}
}
}
本例使用geohash_grid聚合来创建表示地理区域的结果桶,在每个桶中,我们可以在这些紧密关注的区域中识别犯罪类型的异常级别。
在更高的geohash_grid缩放级别和更大的覆盖区域上,我们将开始看到整个警察部队可能正在处理不寻常数量的特定犯罪类型。
显然,基于时间的顶级分割将有助于识别每个时间点的当前趋势,其中简单的术语聚合通常会显示在所有时间槽中持续存在的非常流行的“常量”。
分数是如何计算的?
分数返回的数字主要是为了对不同的建议进行合理的排名,而不是最终用户容易理解的东西。分数来自前景和背景集的文档频率。简而言之,如果一个词在子集中出现的频率和在背景中出现的频率有显著差异,那么这个词就被认为是显著的。可以配置术语的排序方式,请参阅“参数”部分。
用于自由文本字段
可以有效地在标记化的自由文本字段上使用significant_terms聚合来建议:
选择一个自由文本字段作为重要术语分析的主题可能会非常昂贵!它将尝试将每个唯一的单词加载到RAM中。建议只在较小的索引上使用它。
使用“像这样但不是这样”的模式
你可以先搜索一个结构化的字段,比如category:adultMovie,然后在自由文本的“movie_description”字段上使用significant_terms来发现错误分类的内容。使用建议的单词(我将把它们留给你的想象),然后搜索所有没有标记为类别:成人电影但包含这些关键词的电影。你现在有了一个分类不好的电影的排名列表,你应该重新分类,或者至少从“家庭友好”类别中删除。
每个术语的显著性得分也可以为排序m提供有用的提升设置
在上下文中查看时,自由文本的significant ant_terms更容易理解。从自由文本字段中获取建议的significant_terms的结果,并在带有突出显示子句的同一字段的术语查询中使用它们,以向用户显示文档示例片段。当这些术语以正确的情况、正确的顺序和一定的上下文毫无章法地、高亮地呈现时,它们的意义就更明显了。
自定义背景集
通常,前台文档集与索引中所有文档的背景集是“不同的”。然而,有时使用较窄的背景集作为比较的基础可能是有用的。例如,在一个包含世界各地内容的索引中查询与“Madrid”相关的文档,可能会发现“Spanish”是一个重要的术语。这可能是真的,但如果你想要一些更集中的术语,你可以在术语西班牙上使用background_filter来建立一个更窄的文档集作为上下文。有了这个背景,“西班牙语”现在就被视为很常见了
局限性
重要项必须是索引值
与术语聚合不同,目前不可能使用脚本生成的术语进行计数。由于signant_terms聚合必须同时考虑前景和背景频率,因此在整个索引上使用脚本来获得用于比较的背景频率将非常昂贵。出于类似的原因,docvalue也不支持作为术语数据源。
不分析浮点字段
浮点字段目前不支持作为signant_terms分析的主题。虽然整数或长字段可以用来表示像银行账号或类别号这样的概念,但浮点字段通常用于表示某种东西的数量。因此,单个浮点项对于这种形式的频率分析是没有用的。
用作父聚合
如果有等效的match_all查询或没有查询条件提供索引的子集,则不应将signant_terms聚合用作最顶端的聚合——在这种情况下,前台集与后台集完全相同,因此在观察文档频率和从中提出合理建议方面没有差异。
另一个需要考虑的问题是,在分片级别上,significant_terms聚合产生了许多候选结果,只有在合并所有分片的所有统计数据后,这些结果才会在缩减节点上被删除。因此,就RAM而言,将大型子聚合嵌入到稍后会丢弃许多候选术语的significant ant_terms聚合之下可能效率低下且代价高昂。在这些情况下,执行两次搜索是明智的——第一次搜索提供一个合理的significant_terms列表,然后将这个短列表添加到第二个查询中,以返回并获取所需的子agg
近似计算
包含在结果中提供的术语的文档的数量是基于从每个碎片返回的样本的总和,因此可能是:
像大多数设计决策一样,这是一种权衡的基础,我们选择以牺牲一些(通常是小的)不准确性为代价来提供快速的性能。但是,在下一节中介绍的大小和碎片大小设置提供了帮助控制精度级别的工具。
参数
JLH得分
通过添加该参数,可以将JLH分数作为显著性评分
"jlh": {
}
分数来自前景和背景集的文档频率。流行度的绝对变化(foregroundPercent - backgroundPercent)将有利于常见术语,而流行度的相对变化(foregroundPercent/ backgroundPercent)将有利于罕见术语。稀有vs普通本质上是精度vs召回率的平衡,因此绝对和相对变化相乘,以提供精度和召回率之间的最佳点。
交互信息
通过添加参数,可以将Manning et al.,章节13.5.1“information Retrieval”中描述的互信息作为显著性评分
"mutual_information": {
"include_negatives": true
}
交互信息不区分用于子集的描述性术语和用于子集之外的文档的描述性术语。因此,重要项可以包含在子集内比子集外出现频率高或低的项。要过滤掉在子集中出现频率低于子集外文档中的术语,可以将include_negatives设置为false。
默认情况下,假设桶中的文档也包含在后台。相反,如果您定义了一个自定义背景过滤器,该过滤器表示您所查看的一组不同的文档
"background_is_superset": false
在集合中返回有趣或不寻常的自由文本术语的聚合。它类似于重要术语聚合,但不同之处在于:
基于聚合的多桶值源,动态构建桶—每个桶一个唯一值。
例子:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : { "field" : "genre" }
}
}
}
术语聚合应该是关键字类型的字段或适合于桶聚合的任何其他数据类型的字段。为了与文本一起使用它,你需要启用fielddata。
响应:
{
...
"aggregations" : {
"genres" : {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets" : [
{
"key" : "electronic",
"doc_count" : 6
},
{
"key" : "rock",
"doc_count" : 3
},
{
"key" : "jazz",
"doc_count" : 2
}
]
}
}
}
对于每个术语,文档上的错误上限都要计算在内,请参见下文
当有很多唯一的术语时,Elasticsearch只返回顶部的术语;这个数字是不属于响应的所有桶的文档计数的总和
顶部桶的列表,top的含义由order定义
默认情况下,术语聚合将返回doc_count排序的前10个术语的桶。可以通过设置size参数来改变这种默认行为。
Size
size参数可以设置为定义应从整个术语列表中返回多少个术语桶。默认情况下,协调搜索过程的节点将请求每个分片提供自己的top size术语桶,一旦所有分片响应,它将把结果减少到最终列表,然后返回给客户端。这意味着,如果唯一项的数量大于size,则返回的列表略有偏差且不准确(可能是项计数略有偏差,甚至可能是本应位于最大大小桶中的项为n)
如果您想检索嵌套术语聚合中的所有术语或术语的所有组合,则应该使用Composite聚合,该聚合允许对所有可能的术语进行分页,而不是设置一个大于术语聚合中字段基数的大小。术语聚合的目的是返回顶部的术语,不允许分页。
文件数量是近似值
如上所述,术语聚合中的文档计数(以及任何子聚合的结果)并不总是准确的。这是因为每个碎片提供了它自己的有序术语列表视图,这些视图被组合起来以给出最终视图。考虑以下场景:
发出一个请求,以获得字段产品中的前5个术语,按照从3个碎片的索引中降序排列文档计数。在这种情况下,每个碎片被要求给出它的前5个项。
GET /_search
{
"aggs" : {
"products" : {
"terms" : {
"field" : "product",
"size" : 5
}
}
}
}
这三个分片的条款如下所示,括号中为各自的文档计数:
Shard_size
请求的大小越高,结果就越准确,但同时,计算最终结果的成本也越高(这既是由于在分片级别上管理的优先级队列更大,也是由于节点和客户端之间的数据传输更大)。
shard_size参数可用于最小化因请求更大而带来的额外工作。定义后,它将确定协调节点将从每个分片请求多少项。一旦所有的分片都响应了,协调节点就会根据大小参数将它们减少到最终结果——这样可以提高返回项的准确性,并避免将大量桶列表流回客户端的开销。
Shard_size不能小于size(因为它没有多大意义)。当它是时,Elasticsearch将重写它并将其重置为等于size。
默认的shard_size为(size * 1.5 + 10)。
计算文档计数错误
有两个错误值可以显示在术语聚合上。第一个给出了一个整体的聚合值,该值表示没有进入最终术语列表的术语的最大潜在文档计数。这是根据从每个碎片返回的最后一项的文档计数的总和来计算的。对于上面给出的例子,这个值是46(2 + 15 + 29)。这意味着在最坏的情况下,没有返回的术语可能具有第四高的文档计数。
{
...
"aggregations" : {
"products" : {
"doc_count_error_upper_bound" : 46,
"sum_other_doc_count" : 79,
"buckets" : [
{
"key" : "Product A",
"doc_count" : 100
},
{
"key" : "Product Z",
"doc_count" : 52
}
...
]
}
}
}
每个桶文档计数错误
第二个错误值可以通过将参数show_term_doc_count_error设置为true来启用:
GET /_search
{
"aggs" : {
"products" : {
"terms" : {
"field" : "product",
"size" : 5,
"show_term_doc_count_error": true
}
}
}
}
这显示了聚合返回的每个术语的错误值,它表示文档计数中最坏情况下的错误,在决定shard_size参数的值时非常有用。这是通过将所有不返回该项的碎片返回的最后一个项的文档计数相加来计算的。在上面的例子中,产品C的文档计数错误将是15,因为碎片B是唯一没有返回术语的碎片,而它返回的最后一个术语的文档计数是15。C产品的实际文件数是54份,所以文件数是实际的
{
...
"aggregations" : {
"products" : {
"doc_count_error_upper_bound" : 46,
"sum_other_doc_count" : 79,
"buckets" : [
{
"key" : "Product A",
"doc_count" : 100,
"doc_count_error_upper_bound" : 0
},
{
"key" : "Product Z",
"doc_count" : 52,
"doc_count_error_upper_bound" : 2
}
...
]
}
}
}
这些错误只能在术语按文档数量降序排列时以这种方式计算。当聚合是由术语值本身排序时(升序或降序),在文档计数中没有错误,因为如果一个shard没有返回出现在另一个shard结果中的特定术语,那么它的索引中一定没有该术语。当聚合按子聚合排序或按文档计数升序排序时,无法确定文档计数中的错误,并将其赋值为-1表示这一点。
排序
通过设置顺序参数,可以自定义存储桶的顺序。默认情况下,桶按照doc_count降序排列。可以更改这种行为,如下所示:
不鼓励按升序_count排序或按子聚合排序,因为这会增加文档计数的错误。当查询单个分片时,或者当正在聚合的字段在索引时被用作路由键时,这是没问题的:在这些情况下,结果将是准确的,因为分片具有不相交的值。然而,错误是无界的。一个仍然有用的特殊情况是按最小或最大聚合排序:计数不会准确,但至少会正确地选择顶部的桶。
根据桶的doc _count升序排列:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "_count" : "asc" }
}
}
}
}
以升序方式按字母顺序对桶进行排序:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "_key" : "asc" }
}
}
}
}
6.0.0版弃用。
使用_key而不是_term来按桶的术语排序
按单个值度量子聚合(由聚合名称标识)对桶进行排序:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "max_play_count" : "desc" }
},
"aggs" : {
"max_play_count" : { "max" : { "field" : "play_count" } }
}
}
}
}
根据多值度量子聚合(由聚合名称标识)对桶进行排序:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "playback_stats.max" : "desc" }
},
"aggs" : {
"playback_stats" : { "stats" : { "field" : "play_count" } }
}
}
}
}
管道aggs不能用于排序
管道聚合在所有其他聚合已经完成后的reduce阶段运行。因此,它们不能用于排序。
还可以根据层次结构中的“更深”聚合对桶进行排序。只要聚合路径是单桶类型,就支持这种方法,其中路径中的最后一个聚合可以是单桶类型的聚合,也可以是度量类型的聚合。如果它是单桶类型,顺序将由桶中文档的数量定义(即doc_count),如果它是一个度量类型,则应用与上述相同的规则(在多值度量聚合的情况下,路径必须指示要排序的度量名称,而在单值度量聚合的情况下,排序将是
路径定义格式如下:
AGG_SEPARATOR = '>' ;
METRIC_SEPARATOR = '.' ;
AGG_NAME = <the name of the aggregation> ;
METRIC = <the name of the metric (in case of multi-value metrics aggregation)> ;
PATH = <AGG_NAME> [ <AGG_SEPARATOR>, <AGG_NAME> ]* [ <METRIC_SEPARATOR>, <METRIC> ] ;
GET /_search
{
"aggs" : {
"countries" : {
"terms" : {
"field" : "artist.country",
"order" : { "rock>playback_stats.avg" : "desc" }
},
"aggs" : {
"rock" : {
"filter" : { "term" : { "genre" : "rock" }},
"aggs" : {
"playback_stats" : { "stats" : { "field" : "play_count" }}
}
}
}
}
}
}
上面将根据摇滚歌曲的平均播放次数对艺术家的国家桶进行排序。
通过提供一个排序条件数组,可以使用多个条件来对桶进行排序,如下所示:
GET /_search
{
"aggs" : {
"countries" : {
"terms" : {
"field" : "artist.country",
"order" : [ { "rock>playback_stats.avg" : "desc" }, { "_count" : "desc" } ]
},
"aggs" : {
"rock" : {
"filter" : { "term" : { "genre" : "rock" }},
"aggs" : {
"playback_stats" : { "stats" : { "field" : "play_count" }}
}
}
}
}
}
}
上面将根据摇滚歌曲的平均播放次数,然后根据它们的doc_count按降序排序,对艺术家的国家桶进行排序。
如果两个bucket对于所有排序条件都具有相同的值,则bucket的term值将按升序字母顺序用作分分符,以防止bucket的排序不确定。
Minimum document count
可以使用min_doc_count选项只返回匹配超过配置的命中数的条件:
GET /_search
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"min_doc_count": 10
}
}
}
}
上面的聚合只会返回在10次或更多的命中中找到的标签。缺省值为1。
术语在分片级别上被收集和排序,并在第二步中与从其他分片收集的术语合并。但是,该碎片没有关于可用的全局文档计数的信息。是否将一个术语添加到候选列表的决定仅取决于使用本地分片频率在分片上计算的顺序。min_doc_count条件仅在合并所有碎片的本地术语统计数据后应用。在某种程度上,决定增加一个术语作为念珠菌
shard_min_doc_count参数
参数shard_min_doc_count规定了shard的确定性,即是否应该根据min_doc_count将术语添加到候选列表中。只有当术语在集合中的本地分片频率高于shard_min_doc_count时,才会考虑它们。如果您的字典包含许多低频率的术语,并且您对它们不感兴趣(例如拼写错误),那么您可以设置shard_min_doc_count参数,以过滤掉碎片级别上的候选术语,这些术语即使在合并l之后也不会达到所需的min_doc_count
设置min_doc_count=0还将返回没有匹配任何命中的术语的桶。但是,返回的一些文档计数为0的术语可能只属于已删除的文档或来自其他类型的文档,因此不能保证match_all查询会为这些术语找到正的文档计数。
当不对doc_count降序排序时,min_doc_count的高值可能会返回一些小于size的桶,因为没有从碎片收集足够的数据。通过增加shard_size可以找回丢失的桶。将shard_min_doc_count设置得过高将导致在分片级别上过滤掉术语。这个值应该设置得比min_doc_count/#shards低得多。
脚本
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"script" : {
"source": "doc['genre'].value",
"lang": "painless"
}
}
}
}
}
这将把脚本参数解释为一个内联脚本,使用默认脚本语言,没有脚本参数。要使用存储脚本,请使用以下语法:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"script" : {
"id": "my_script",
"params": {
"field": "genre"
}
}
}
}
}
}
值脚本
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"script" : {
"source" : "'Genre: ' +_value",
"lang" : "painless"
}
}
}
}
}
过滤值
可以过滤将要为其创建的桶的值。这可以使用基于正则表达式字符串或精确值数组的include和exclude参数来完成。此外,include子句可以使用分区表达式进行筛选。
使用正则表达式过滤值
GET /_search
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"include" : ".*sport.*",
"exclude" : "water_.*"
}
}
}
}
在上面的例子中,将为所有包含单词sport的标记创建bucket,以water_开头的标记除外(因此标记water_sports将不会被聚合)。包含正则表达式将确定“允许”聚合哪些值,而排除正则表达式将确定不应该聚合哪些值。当定义了两者时,排除具有优先级,即首先计算包含,然后才计算排除。
用精确的值过滤值
对于基于精确值的匹配,include和exclude参数可以简单地接受一个字符串数组,该数组表示在索引中找到的术语:
GET /_search
{
"aggs" : {
"JapaneseCars" : {
"terms" : {
"field" : "make",
"include" : ["mazda", "honda"]
}
},
"ActiveCarManufacturers" : {
"terms" : {
"field" : "make",
"exclude" : ["rover", "jensen"]
}
}
}
}
使用分区过滤值
有时,单个请求/响应对中处理的唯一术语太多,因此将分析分解为多个请求会很有用。这可以通过在查询时将字段值分组到许多分区中,并且在每个请求中只处理一个分区来实现。考虑这个请求,它正在寻找最近没有记录任何访问的帐户:
GET /_search
{
"size": 0,
"aggs": {
"expired_sessions": {
"terms": {
"field": "account_id",
"include": {
"partition": 0,
"num_partitions": 20
},
"size": 10000,
"order": {
"last_access": "asc"
}
},
"aggs": {
"last_access": {
"max": {
"field": "access_date"
}
}
}
}
}
}
此请求正在查找客户帐户子集的最后登录访问日期,因为我们可能希望过期一些很久没有看到的客户帐户。num_partitions设置要求将唯一的account_id均匀地组织到20个分区中(0到19)。该请求中的分区设置只考虑归入分区0的account_ids。后续请求应该请求分区1和分区2等,以完成过期帐户分析。
注意,返回结果数量的大小设置需要使用num_partitions进行调优。对于这个特定的帐户过期示例,平衡size和num_partitions值的过程如下:
如果我们有一个断路器错误,我们试图在一个请求中做太多的事情,必须增加num_partitions。如果请求成功,但日期排序测试响应中的最后一个帐户ID仍然是我们可能希望过期的帐户,那么我们可能丢失了感兴趣的帐户,并且将数字设置得过低。我们必须
最终,这是在管理处理单个请求所需的Elasticsearch资源和客户端应用程序为完成任务必须发出的请求量之间的平衡。
多字段术语聚合
术语聚合不支持从同一文档中的多个字段收集术语。原因是,术语agg并不收集字符串术语值本身,而是使用全局序数来生成字段中所有唯一值的列表。全局序数可以带来重要的性能提升,而跨多个字段是不可能实现的。
有两种方法可以跨多个字段执行terms agg:
脚本
使用脚本从多个字段检索术语。这将禁用全局序数优化,并且比从单个字段收集术语要慢,但它为您提供了在搜索时实现此选项的灵活性。
copy_to字段
如果您事先知道希望从两个或多个字段收集术语,那么在映射中使用copy_to在索引时创建一个新的专用字段,该字段包含来自两个字段的值。您可以在这个单一字段上进行聚合,这将受益于全局序数优化。
收集模式
延迟子聚合的计算
对于具有许多唯一项和少量所需结果的字段,可以更有效地延迟子聚合的计算,直到顶部的父级aggs被修剪。通常,聚合树的所有分支都在一次深度优先过程中展开,然后才进行任何修剪。在某些情况下,这可能是非常浪费的,并且可能会受到内存限制。一个示例问题场景是在电影数据库中查询10个最受欢迎的演员和5个最常见的合作演员:
GET /_search
{
"aggs" : {
"actors" : {
"terms" : {
"field" : "actors",
"size" : 10
},
"aggs" : {
"costars" : {
"terms" : {
"field" : "actors",
"size" : 5
}
}
}
}
}
}
尽管参与者的数量可能相对较少,我们只想要50个结果桶,但在计算过程中,桶的组合数量会激增——单个参与者可以产生n²个桶,其中n是参与者的数量。明智的做法是,首先确定10位最受欢迎的演员,然后再考虑与这10位演员搭档的最佳演员。这种替代策略就是我们所说的breadth_first收集模式,与depth_first模式相对。
对于基数大于请求大小的字段或基数未知的字段(例如数值字段或脚本),breadth_first是默认模式。可以重写默认的启发式,并直接在请求中提供一个收集模式:
GET /_search
{
"aggs" : {
"actors" : {
"terms" : {
"field" : "actors",
"size" : 10,
"collect_mode" : "breadth_first"
},
"aggs" : {
"costars" : {
"terms" : {
"field" : "actors",
"size" : 5
}
}
}
}
}
}
当使用breadth_first模式时,处于最上层桶的文档集将被缓存以供后续重播,因此这样做的内存开销与匹配文档的数量成线性关系。注意,在使用breadth_first设置时,order参数仍然可以用于引用来自子聚合的数据——父聚合理解需要在任何其他子聚合之前首先调用这个子聚合。
嵌套聚合(如top_hits)需要访问使用breadth_first收集模式的聚合下的得分信息,需要在第二次传递时重播查询,但只针对属于顶部桶的文档。
执行提示
可以通过不同的机制来执行术语聚合:
Elasticsearch尝试使用合理的默认值,因此这通常不需要配置。
Global_ordinals是关键字字段的默认选项,它使用全局序数动态分配桶,因此内存使用与聚合范围内文档的值的数量是线性的。
只有当匹配查询的文档很少时,才应该考虑Map。否则,基于顺序的执行模式要快得多。默认情况下,map仅在对脚本运行聚合时使用,因为它们没有序数
GET /_search
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"execution_hint": "map" #取值为map, global_ordinals
}
}
}
}
请注意,Elasticsearch将忽略此执行提示,如果它不适用,并且这些提示没有向后兼容性保证。
Missing Value
GET /_search
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"missing": "N/A"
}
}
}
}
混合字段类型
在多个索引上聚合时,聚合字段的类型在所有索引中可能不相同。有些类型是相互兼容的(整数和长或浮点和双精度),但当类型是十进制和非十进制数的混合时,术语聚合将把非十进制数提升为十进制数。这可能会导致桶值精度的损失。
管道聚合处理从其他聚合(而不是从文档集)产生的输出,向输出树添加信息。有许多不同类型的管道聚合,每种聚合计算来自其他聚合的不同信息,但这些类型可以分为两类:
Parent
一系列管道聚合,提供其父聚合的输出,并能够计算新桶或新聚合以添加到现有桶中。
Sibing
管道聚合,提供同级聚合的输出,并能够计算与同级聚合处于同一级别的新聚合。
管道聚合可以引用它们执行计算所需的聚合,方法是使用buckets_path参数指示所需度量的路径。定义这些路径的语法可以在下面的buckets_path语法部分中找到。
管道聚合不能有子聚合,但根据类型,它可以在buckets_path中引用另一个管道,允许管道聚合被链接。例如,你可以把两个导数连在一起来计算二阶导数(即一个导数的一个导数)。
因为管道聚合只添加到输出中,当链接管道聚合时,每个管道聚合的输出将包含在最终输出中。
buckets_path语法
大多数管道聚合需要另一个聚合作为它们的输入。输入聚合是通过buckets_path参数定义的,它遵循特定的格式:
AGG_SEPARATOR = '>' ;
METRIC_SEPARATOR = '.' ;
AGG_NAME = <the name of the aggregation> ;
METRIC = <the name of the metric (in case of multi-value metrics aggregation)> ;
PATH = <AGG_NAME> [ <AGG_SEPARATOR>, <AGG_NAME> ]* [ <METRIC_SEPARATOR>, <METRIC> ] ;
例如,路径“my_bucket>my_stats.”Avg”将指向“my_stats”指标中的Avg值,该指标包含在“my_bucket”桶聚合中。
从管道聚合的位置看,路径是相对的;它们不是绝对路径,路径不能“向上”返回到聚合树。例如,这个移动平均值被嵌入到一个date_histogram中,并引用了一个“兄弟”指标“the_sum”:
POST /_search
{
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"timestamp",
"calendar_interval":"day"
},
"aggs":{
"the_sum":{
"sum":{ "field": "lemmings" }
},
"the_movavg":{
"moving_avg":{ "buckets_path": "the_sum" }
}
}
}
}
}
buckets_path还用于兄弟管道聚合,其中聚合位于一系列桶的“旁边”,而不是嵌入在它们的“内部”。例如,max_bucket聚合使用buckets_path指定嵌入在同级聚合中的度量值:
POST /_search
{
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"max_monthly_sales": {
"max_bucket": {
"buckets_path": "sales_per_month>sales" #Buckets_path指示这个max_bucket聚合,我们需要sales_per_month日期直方图中的销售聚合的最大值。
}
}
}
}
特殊路径
buckets_path可以使用一个特殊的“_count”路径,而不是到度量值的路径。这指示管道聚合使用文档计数作为其输入。例如,移动平均可以计算每个桶的文档数量,而不是特定的指标:
POST /_search
{
"aggs": {
"my_date_histo": {
"date_histogram": {
"field":"timestamp",
"calendar_interval":"day"
},
"aggs": {
"the_movavg": {
"moving_avg": { "buckets_path": "_count" } #通过使用_count而不是度量名称,我们可以计算直方图中文档计数的移动平均值
}
}
}
}
}
buckets_path还可以使用“_bucket_count”和多桶聚合的路径,以在管道聚合中使用该聚合返回的桶数,而不是度量。例如,可以在这里使用bucket_selector来过滤不包含桶的桶,用于内部术语聚合:
POST /sales/_search
{
"size": 0,
"aggs": {
"histo": {
"date_histogram": {
"field": "date",
"calendar_interval": "day"
},
"aggs": {
"categories": {
"terms": {
"field": "category"
}
},
"min_bucket_selector": {
"bucket_selector": {
"buckets_path": {
"count": "categories._bucket_count"
},
"script": {
"source": "params.count != 0"
}
}
}
}
}
}
}
通过使用_bucket_count而不是一个度量名称,我们可以过滤出不包含类别聚合桶
处理聚合名称中的圆点
支持另一种语法来处理名称中有点的聚合或指标,例如99.9百分位数。这个指标可以被称为:
"buckets_path": "my_percentile[99.9]"
处理数据中的空白
现实世界中的数据通常是嘈杂的,有时还包含空白——数据根本不存在的地方。出现这种情况的原因有很多,最常见的是:
间隙策略是一种机制,用于在遇到“间隙”或丢失数据时通知管道聚合所需的行为。所有管道聚合都接受gap_policy参数。目前有两种间隙政策可供选择:
skip
此选项将丢失的数据视为bucket不存在。它将跳过该桶,并使用下一个可用值继续计算。
insert_zeros
该选项将用零(0)替换缺失的值,管道聚合计算将照常进行。
一个兄弟管道聚合,用于计算兄弟聚合中指定度量的(平均)平均值。指定的度量必须是数字,并且同级聚合必须是多桶聚合。
语法
avg_bucket聚合单独看起来像这样:
{
"avg_bucket": {
"buckets_path": "the_sum"
}
}
avg_bucket参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
我们希望求平均值的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
format |
格式应用于此聚合的输出值 | 可选 | null |
下面的代码段计算了每月总销售额的平均值:
POST /_search
{
"size": 0,
"aggs": {
"sales_per_month": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"avg_monthly_sales": {
"avg_bucket": {
"buckets_path": "sales_per_month>sales"
}
}
}
}
下面可能是响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"avg_monthly_sales": {
"value": 328.33333333333333
}
}
}
父管道聚合,用于计算父直方图(或date_histogram)聚合中指定度量的导数。指定的度量值必须是数值,并且包围的直方图必须将min_doc_count设置为0(直方图聚合的默认值)。
语法
"derivative": {
"buckets_path": "the_sum"
}
derivative的参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
format |
格式应用于此聚合的输出值 | 可选 | null |
一次导数
下面的代码段计算了每月总销售额的导数:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
},
"sales_deriv": {
"derivative": {
"buckets_path": "sales"
}
}
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
},
"sales_deriv": {
"value": -490.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
},
"sales_deriv": {
"value": 315.0
}
}
]
}
}
}
第一桶没有导数,因为我们至少需要2个数据点来计算导数
衍生价值单位由销售汇总和父柱状图隐含定义,因此在本例中,单位将是 / 月,假设价格字段的单位为 /月,假设价格字段的单位为 /月,假设价格字段的单位为。
桶中的文档数量由doc_count表示
二阶导数
二阶导数可以通过将导数管道聚合链接到另一个导数管道聚合的结果上来计算,如下例所示,它将计算每月总销售额的一阶导数和二阶导数:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
},
"sales_deriv": {
"derivative": {
"buckets_path": "sales"
}
},
"sales_2nd_deriv": {
"derivative": {
"buckets_path": "sales_deriv"
}
}
}
}
}
}
响应:
{
"took": 50,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
},
"sales_deriv": {
"value": -490.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
},
"sales_deriv": {
"value": 315.0
},
"sales_2nd_deriv": {
"value": 805.0
}
}
]
}
}
}
前两部分没有二阶导数,因为我们需要至少两个一阶导数的数据点来计算二阶导数
单位
导数聚合允许指定导数值的单位。这将在响应normalized_value中返回一个额外的字段,该字段报告所需x轴单位的导数值。在下面的例子中,我们计算每月总销售额的导数,但要求以每天销售额为单位的销售额的导数:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
},
"sales_deriv": {
"derivative": {
"buckets_path": "sales",
"unit": "day" #Unit指定用于导数计算的x轴的单位
}
}
}
}
}
}
响应:
{
"took": 50,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
},
"sales_deriv": {
"value": -490.0, #价值以每月的原始单位报告
"normalized_value": -15.806451612903226 #Normalized_value以所需的每天单位报告
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
},
"sales_deriv": {
"value": 315.0,
"normalized_value": 11.25
}
}
]
}
}
}
一个同级管道聚合,它用同级聚合中指定度量的最大值标识桶,并输出桶的值和键。指定的度量必须是数字,并且同级聚合必须是多桶聚合。
语法
{
"max_bucket": {
"buckets_path": "the_sum"
}
}
max_bucket参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
format |
格式应用于此聚合的输出值 | 可选 | null |
下面的代码段计算了每月总销售额的最大值:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"max_monthly_sales": {
"max_bucket": {
"buckets_path": "sales_per_month>sales"
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"max_monthly_sales": {
"keys": ["2015/01/01 00:00:00"], #Keys是一个字符串数组,因为最大值可能出现在多个bucket中
"value": 550.0
}
}
}
一个同级管道聚合,它用同级聚合中指定度量的最小值标识桶,并输出桶的值和键。指定的度量必须是数字,并且同级聚合必须是多桶聚合。
语法
{
"min_bucket": {
"buckets_path": "the_sum"
}
}
min_bucket参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
format |
格式应用于此聚合的输出值 | 可选 | null |
下面的代码段计算了每月总销售额的最小值:
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"min_monthly_sales": {
"min_bucket": {
"buckets_path": "sales_per_month>sales"
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"min_monthly_sales": {
"keys": ["2015/02/01 00:00:00"],
"value": 60.0
}
}
}
Keys是一个字符串数组,因为最小值可能出现在多个bucket中
一个兄弟管道聚合,用于计算兄弟聚合中指定指标的所有桶的和。指定的度量必须是数字,并且同级聚合必须是多桶聚合。
语法
{
"sum_bucket": {
"buckets_path": "the_sum"
}
}
sum_bucket参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
format |
格式应用于此聚合的输出值 | 可选 | null |
下面的代码段计算了所有月销售桶的总和:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"sum_monthly_sales": {
"sum_bucket": {
"buckets_path": "sales_per_month>sales"
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"sum_monthly_sales": {
"value": 985.0
}
}
}
一个兄弟管道聚合,它计算兄弟聚合中指定指标的所有桶的各种统计数据。指定的度量必须是数字,并且同级聚合必须是多桶聚合。
语法
{
"stats_bucket": {
"buckets_path": "the_sum"
}
}
stats_bucket参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
format |
格式应用于此聚合的输出值 | 可选 | null |
下面的代码段计算每月销售额的统计数据:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"stats_monthly_sales": {
"stats_bucket": {
"buckets_path": "sales_per_month>sales"
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"stats_monthly_sales": {
"count": 3,
"min": 60.0,
"max": 550.0,
"avg": 328.3333333333333,
"sum": 985.0
}
}
}
一个兄弟管道聚合,它计算兄弟聚合中指定指标的所有桶的各种统计数据。指定的度量必须是数字,并且同级聚合必须是多桶聚合。
与stats_bucket聚合相比,该聚合提供了更多的统计信息(平方和、标准偏差等)。
语法
{
"extended_stats_bucket": {
"buckets_path": "the_sum"
}
}
extended_stats_bucket参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
format |
格式应用于此聚合的输出值 | 可选 | null |
sigma |
要显示的高于/低于平均值的标准差数 | 可选 | 2 |
下面的代码段计算了每月销售桶的扩展统计数据:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"stats_monthly_sales": {
"extended_stats_bucket": {
"buckets_path": "sales_per_month>sales"
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"stats_monthly_sales": {
"count": 3,
"min": 60.0,
"max": 550.0,
"avg": 328.3333333333333,
"sum": 985.0,
"sum_of_squares": 446725.0,
"variance": 41105.55555555556,
"std_deviation": 202.74505063146563,
"std_deviation_bounds": {
"upper": 733.8234345962646,
"lower": -77.15676792959795
}
}
}
}
一个兄弟管道聚合,计算兄弟聚合中指定指标的所有桶的百分比。指定的度量必须是数字,并且同级聚合必须是多桶聚合。
语法
{
"percentiles_bucket": {
"buckets_path": "the_sum"
}
}
percentiles_bucket参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
format |
格式应用于此聚合的输出值 | 可选 | null |
percents |
要计算的百分位数列表 | 可选 | [ 1, 5, 25, 50, 75, 95, 99 ] |
keyed |
标志,该标志将范围返回为哈希值而不是键值对数组 | 可选 | true |
下面的代码段计算了每月总销售额的百分比:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"percentiles_monthly_sales": {
"percentiles_bucket": {
"buckets_path": "sales_per_month>sales",
"percents": [ 25.0, 50.0, 75.0 ]
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"percentiles_monthly_sales": {
"values" : {
"25.0": 375.0,
"50.0": 375.0,
"75.0": 550.0
}
}
}
}
Percentiles_bucket实现
百分位数桶返回最近的输入数据点,不大于请求的百分位数;它不在数据点之间插补。
百分位数是精确计算的,而不是近似值(不像百分位数度量)。这意味着该实现在内存中维护一个排序的数据列表,以便在丢弃数据之前计算百分位数。如果试图在单个percentiles_bucket中计算数百万个数据点的百分比,可能会遇到内存压力问题。
6.4.0中已弃用。移动平均线聚合已经被弃用,取而代之的是更通用的移动函数聚合。新的移动函数聚合提供了与移动平均线聚合相同的所有功能,但也提供了更大的灵活性。
若想使用,参见文档
给定一系列有序的数据,移动函数聚合将在数据上滑动一个窗口,并允许用户指定在每个数据窗口上执行的自定义脚本。为了方便起见,预定义了一些常用函数,如最小/最大,移动平均等。
这在概念上与移动平均线管道聚合非常相似,只是它提供了更多的功能。
语法
{
"moving_fn": {
"buckets_path": "the_sum",
"window": 10,
"script": "MovingFunctions.min(values)"
}
}
moving_fn参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
感兴趣的度量的路径 | 必选 | |
window |
在直方图上“滑动”的窗口的大小 | 必选 | |
script |
应该在每个数据窗口上执行的脚本 | 必选 |
Moving_fn聚合必须嵌入到直方图或date_histogram聚合中。它们可以像任何其他指标聚合一样嵌入:
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"calendar_interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movfn": {
"moving_fn": {
"buckets_path": "the_sum",
"window": 10,
"script": "MovingFunctions.unweightedAvg(values)"
}
}
}
}
}
}
一个名为“my_date_histo”的日期直方图在“timestamp”字段上构造,以一天为间隔
和度量用于计算字段的和。这可以是任何数值度量(sum, min, max等)
最后,我们指定一个moving_fn聚合,它使用“the_sum”指标作为输入。
移动平均线是通过首先指定一个字段的直方图或date_histogram来构建的。然后,您可以选择在该直方图中添加数值指标,例如总和。最后,moving_fn被嵌入到直方图中。然后使用buckets_path参数“指向”直方图内的一个兄弟指标(参见buckets_path语法了解buckets_path的语法描述。
来自上述聚合的响应示例如下:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"my_date_histo": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"the_sum": {
"value": 550.0
},
"the_movfn": {
"value": null
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"the_sum": {
"value": 60.0
},
"the_movfn": {
"value": 550.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"the_sum": {
"value": 375.0
},
"the_movfn": {
"value": 305.0
}
}
]
}
}
}
自定义用户脚本
移动函数聚合允许用户指定任意脚本来定义自定义逻辑。每次收集新的数据窗口时,都会调用该脚本。这些值在values变量中提供给脚本。然后,脚本应该执行某种计算,并发出一个double作为结果。不允许发射null,但是允许发射NaN和+/- Inf。
例如,这个脚本将简单地返回窗口中的第一个值,如果没有可用值,则返回NaN:
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"date",
"calendar_interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg": {
"moving_fn": {
"buckets_path": "the_sum",
"window": 10,
"script": "return values.length > 0 ? values[0] : Double.NaN"
}
}
}
}
}
}
预先构建的功能
为了方便起见,已经预先构建了一些函数,可以在moving_fn脚本上下文中使用:
max()min()sum()stdDev()unweightedAvglinearWeightedAvgewma()holt()holtWinters()这些函数可以从MovingFunctions命名空间获得。例如MovingFunctions.max ()
父管道聚合,用于计算父直方图(或date_histogram)聚合中指定度量的累积和。指定的度量值必须是数值,并且包围的直方图必须将min_doc_count设置为0(直方图聚合的默认值)。
语法
{
"cumulative_sum": {
"buckets_path": "the_sum"
}
}
cumulative_sum参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
format |
格式应用于此聚合的输出值 | 可选 | null |
下面的代码段计算了每月总销售额的累积总和:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
},
"cumulative_sales": {
"cumulative_sum": {
"buckets_path": "sales"
}
}
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
},
"cumulative_sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
},
"cumulative_sales": {
"value": 610.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
},
"cumulative_sales": {
"value": 985.0
}
}
]
}
}
}
一个父管道聚合,它执行一个脚本,该脚本可以在父多桶聚合中的指定指标上执行每个桶计算。指定的度量必须是数值,脚本必须返回数值。
语法
{
"bucket_script": {
"buckets_path": {
"my_var1": "the_sum", #这里,my_var1是脚本中要使用的桶路径的变量名,the_sum是该变量要使用的指标的路径。
"my_var2": "the_value_count"
},
"script": "params.my_var1 / params.my_var2"
}
}
bucket_script参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
script |
为该聚合运行的脚本。脚本可以内联、文件或索引。 | 必选 | |
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
format |
格式应用于此聚合的输出值 | 可选 | null |
下面的代码段计算了t恤销售额与每月总销售额的比例:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "price"
}
},
"t-shirts": {
"filter": {
"term": {
"type": "t-shirt"
}
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"t-shirt-percentage": {
"bucket_script": {
"buckets_path": {
"tShirtSales": "t-shirts>sales",
"totalSales": "total_sales"
},
"script": "params.tShirtSales / params.totalSales * 100"
}
}
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"total_sales": {
"value": 550.0
},
"t-shirts": {
"doc_count": 1,
"sales": {
"value": 200.0
}
},
"t-shirt-percentage": {
"value": 36.36363636363637
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"total_sales": {
"value": 60.0
},
"t-shirts": {
"doc_count": 1,
"sales": {
"value": 10.0
}
},
"t-shirt-percentage": {
"value": 16.666666666666664
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"total_sales": {
"value": 375.0
},
"t-shirts": {
"doc_count": 1,
"sales": {
"value": 175.0
}
},
"t-shirt-percentage": {
"value": 46.666666666666664
}
}
]
}
}
}
父管道聚合,它执行一个脚本,该脚本决定当前桶是否将保留在父多桶聚合中。指定的度量必须是数字,脚本必须返回布尔值。如果脚本语言是表达式,则允许返回数值。在这种情况下,0.0将被计算为false,所有其他值将被计算为true。
bucket_selector聚合,像所有管道聚合一样,在所有其他兄弟聚合之后执行。这意味着使用bucket_selector聚合来过滤响应中返回的桶并不能节省运行聚合的执行时间。
语法
{
"bucket_selector": {
"buckets_path": {
"my_var1": "the_sum", #这里,my_var1是脚本中要使用的桶路径的变量名,the_sum是该变量要使用的指标的路径。
"my_var2": "the_value_count"
},
"script": "params.my_var1 > params.my_var2"
}
}
bucket_selector参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
script |
为该聚合运行的脚本。脚本可以内联、文件或索引。 | 必选 | |
buckets_path |
也就是我们要求导的桶的路径 | 必选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
下面的代码片段只保留当月总销售额超过200的桶:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "price"
}
},
"sales_bucket_filter": {
"bucket_selector": {
"buckets_path": {
"totalSales": "total_sales"
},
"script": "params.totalSales > 200"
}
}
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"total_sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"total_sales": {
"value": 375.0
},
}
]
}
}
}
父管道聚合,对其父多桶聚合的桶进行排序。零个或多个排序字段可以与相应的排序顺序一起指定。每个桶可以根据它的_key、_count或它的子聚合进行排序。此外,还可以设置来自和size的参数,以便截断结果桶。
与所有管道聚合一样,bucket_sort聚合在所有其他非管道聚合之后执行。这意味着排序只应用于已经从父聚合返回的桶。例如,如果父聚合是terms,并且它的大小设置为10,那么bucket_sort将只对这10个返回的术语桶进行排序。
语法
{
"bucket_sort": {
"sort": [
{"sort_field_1": {"order": "asc"}},#这里,sort_field_1是要用作主排序的变量的桶路径,它的顺序是升序的。
{"sort_field_2": {"order": "desc"}},
"sort_field_3"
],
"from": 1,
"size": 3
}
}
bucket_sort参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
sort |
要排序的字段列表。有关更多细节,请参阅 sort . |
可选 | |
from |
位于设定值之前的桶将被截断 | 可选 | 0 |
size |
要返回的桶数。默认为父聚合的所有桶 | 可选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
下面的代码片段按降序返回总销售额最高的3个月对应的桶:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "price"
}
},
"sales_bucket_sort": {
"bucket_sort": {
"sort": [
{"total_sales": {"order": "desc"}}
],
"size": 3
}
}
}
}
}
}
响应:
{
"took": 82,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"total_sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"total_sales": {
"value": 375.0
},
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"total_sales": {
"value": 60.0
},
}
]
}
}
}
不排序的截断
也可以使用这个聚合来截断结果桶,而不进行任何排序。为此,只需使用from和/或size参数,而不指定sort。
下面的例子简单地截断了结果,只返回第二个桶:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"bucket_truncate": {
"bucket_sort": {
"from": 1,
"size": 1
}
}
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2
}
]
}
}
}
此功能处于技术预览阶段,在未来的版本中可能会更改或删除。Elastic将尽最大努力修复任何问题,但技术预览中的功能不受官方GA功能的支持SLA的约束。
该系列中的聚合操作多个字段,并根据从请求的文档字段中提取的值生成矩阵结果。与度量和桶聚合不同,这个聚合系列还不支持脚本。
matrix_stats聚合是一个数值聚合,它在一组文档字段上计算以下统计信息:
count:计算中包含的每个领域样本的数量mean:每个字段的平均值。variance:每场测量样本如何从平均值展开。skewness: 每一场测量都量化了平均值周围的非对称分布。kurtosis:每个现场测量量化分布的形状。covariance: 定量描述一个领域的变化如何与另一个领域相关联的矩阵。correlation: 协方差矩阵缩放到-1到1的范围,包括。描述场分布之间的关系。下面的例子演示了如何使用矩阵统计来描述收入和贫困之间的关系。
GET /_search
{
"aggs": {
"statistics": {
"matrix_stats": {
"fields": ["poverty", "income"]
}
}
}
}
聚合类型是matrix_stats, fields设置定义了用于计算统计信息的字段集(作为数组)。上述请求返回以下响应:
{
...
"aggregations": {
"statistics": {
"doc_count": 50,
"fields": [{
"name": "income",
"count": 50,
"mean": 51985.1,
"variance": 7.383377037755103E7,
"skewness": 0.5595114003506483,
"kurtosis": 2.5692365287787124,
"covariance": {
"income": 7.383377037755103E7,
"poverty": -21093.65836734694
},
"correlation": {
"income": 1.0,
"poverty": -0.8352655256272504
}
}, {
"name": "poverty",
"count": 50,
"mean": 12.732000000000001,
"variance": 8.637730612244896,
"skewness": 0.4516049811903419,
"kurtosis": 2.8615929677997767,
"covariance": {
"income": -21093.65836734694,
"poverty": 8.637730612244896
},
"correlation": {
"income": -0.8352655256272504,
"poverty": 1.0
}
}]
}
}
}
doc_count字段指示计算统计信息所涉及的文档数量。
多值字段
matrix_stats聚合将每个文档字段视为独立的示例。mode参数控制聚合对数组或多值字段使用的数组值。该参数可以为以下参数之一:
avg:(默认)使用所有值的平均值。min:选择最小的值。max:选择最大的值。sum:使用所有值的和。median:使用所有值的中位数。Missing Value
GET /_search
{
"aggs": {
"matrixstats": {
"matrix_stats": {
"fields": ["poverty", "income"],
"missing": {"income" : 50000}
}
}
}
}
经常使用的聚合(例如显示在网站主页上的聚合)可以被缓存以获得更快的响应。这些缓存的结果与非缓存聚合返回的结果相同——您永远不会得到过时的结果。
更多细节请参见分片请求缓存。
在许多情况下需要聚合,但不需要搜索命中。对于这些情况,可以通过设置size=0来忽略命中。例如:
GET /twitter/_search
{
"size": 0,
"aggregations": {
"my_agg": {
"terms": {
"field": "text"
}
}
}
}
将size设置为0可以避免执行搜索的获取阶段,从而提高请求的效率。
您可以在请求时将元数据片段与各个聚合相关联,这些聚合将在响应时就地返回。
考虑这个例子,我们希望将蓝色与我们的术语聚合相关联。
GET /twitter/_search
{
"size": 0,
"aggs": {
"titles": {
"terms": {
"field": "title"
},
"meta": {
"color": "blue"
}
}
}
}
然后,这块元数据将返回到标题术语聚合的位置
{
"aggregations": {
"titles": {
"meta": {
"color" : "blue"
},
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets": [
]
}
},
...
}
有时您需要知道聚合的确切类型,以便解析其结果。typed_keys参数可用于更改响应中的聚合名称,以其内部类型作为前缀。
考虑以下名为tweets_over_time的数据直方图聚合,它有一个名为top_users的子“top_hits”聚合:
GET /twitter/_search?typed_keys
{
"aggregations": {
"tweets_over_time": {
"date_histogram": {
"field": "date",
"calendar_interval": "year"
},
"aggregations": {
"top_users": {
"top_hits": {
"size": 1
}
}
}
}
}
}
在响应中,聚合名称将分别更改为date_histogram#tweets_over_time和top_hits#top_users,反映每个聚合的内部类型:
{
"aggregations": {
"date_histogram#tweets_over_time": {
"buckets" : [
{
"key_as_string" : "2009-01-01T00:00:00.000Z",
"key" : 1230768000000,
"doc_count" : 5,
"top_hits#top_users" : {
"hits" : {
"total" : {
"value": 5,
"relation": "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index": "twitter",
"_type": "_doc",
"_id": "0",
"_score": 1.0,
"_source": {
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"user": "kimchy",
"likes": 0
}
}
]
}
}
}
]
}
},
...
}
对于某些聚合,返回的类型可能与请求提供的类型不相同。Terms、Significant Terms和Percentiles聚合就是这种情况,其中返回的类型还包含关于目标字段类型的信息:lterms(用于Long字段上的术语聚合)、sigsterms(用于String字段上的重要术语聚合)、tdigest_percentiles(用于基于TDigest算法的百分位数聚合)。
"sort": [
{"sort_field_1": {"order": "asc"}},#这里,sort_field_1是要用作主排序的变量的桶路径,它的顺序是升序的。
{"sort_field_2": {"order": "desc"}},
"sort_field_3"
],
"from": 1,
"size": 3
}
}
bucket_sort参数:
| 参数名 | 描述 | 要求 | 默认值 |
|---|---|---|---|
sort |
要排序的字段列表。有关更多细节,请参阅 sort . |
可选 | |
from |
位于设定值之前的桶将被截断 | 可选 | 0 |
size |
要返回的桶数。默认为父聚合的所有桶 | 可选 | |
gap_policy |
在数据中发现空白时应用的策略 | 可选 | skip |
下面的代码片段按降序返回总销售额最高的3个月对应的桶:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "price"
}
},
"sales_bucket_sort": {
"bucket_sort": {
"sort": [
{"total_sales": {"order": "desc"}}
],
"size": 3
}
}
}
}
}
}
响应:
{
"took": 82,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"total_sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"total_sales": {
"value": 375.0
},
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"total_sales": {
"value": 60.0
},
}
]
}
}
}
不排序的截断
也可以使用这个聚合来截断结果桶,而不进行任何排序。为此,只需使用from和/或size参数,而不指定sort。
下面的例子简单地截断了结果,只返回第二个桶:
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
},
"aggs": {
"bucket_truncate": {
"bucket_sort": {
"from": 1,
"size": 1
}
}
}
}
}
}
响应:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2
}
]
}
}
}
此功能处于技术预览阶段,在未来的版本中可能会更改或删除。Elastic将尽最大努力修复任何问题,但技术预览中的功能不受官方GA功能的支持SLA的约束。
该系列中的聚合操作多个字段,并根据从请求的文档字段中提取的值生成矩阵结果。与度量和桶聚合不同,这个聚合系列还不支持脚本。
matrix_stats聚合是一个数值聚合,它在一组文档字段上计算以下统计信息:
count:计算中包含的每个领域样本的数量mean:每个字段的平均值。variance:每场测量样本如何从平均值展开。skewness: 每一场测量都量化了平均值周围的非对称分布。kurtosis:每个现场测量量化分布的形状。covariance: 定量描述一个领域的变化如何与另一个领域相关联的矩阵。correlation: 协方差矩阵缩放到-1到1的范围,包括。描述场分布之间的关系。下面的例子演示了如何使用矩阵统计来描述收入和贫困之间的关系。
GET /_search
{
"aggs": {
"statistics": {
"matrix_stats": {
"fields": ["poverty", "income"]
}
}
}
}
聚合类型是matrix_stats, fields设置定义了用于计算统计信息的字段集(作为数组)。上述请求返回以下响应:
{
...
"aggregations": {
"statistics": {
"doc_count": 50,
"fields": [{
"name": "income",
"count": 50,
"mean": 51985.1,
"variance": 7.383377037755103E7,
"skewness": 0.5595114003506483,
"kurtosis": 2.5692365287787124,
"covariance": {
"income": 7.383377037755103E7,
"poverty": -21093.65836734694
},
"correlation": {
"income": 1.0,
"poverty": -0.8352655256272504
}
}, {
"name": "poverty",
"count": 50,
"mean": 12.732000000000001,
"variance": 8.637730612244896,
"skewness": 0.4516049811903419,
"kurtosis": 2.8615929677997767,
"covariance": {
"income": -21093.65836734694,
"poverty": 8.637730612244896
},
"correlation": {
"income": -0.8352655256272504,
"poverty": 1.0
}
}]
}
}
}
doc_count字段指示计算统计信息所涉及的文档数量。
多值字段
matrix_stats聚合将每个文档字段视为独立的示例。mode参数控制聚合对数组或多值字段使用的数组值。该参数可以为以下参数之一:
avg:(默认)使用所有值的平均值。min:选择最小的值。max:选择最大的值。sum:使用所有值的和。median:使用所有值的中位数。Missing Value
GET /_search
{
"aggs": {
"matrixstats": {
"matrix_stats": {
"fields": ["poverty", "income"],
"missing": {"income" : 50000}
}
}
}
}
经常使用的聚合(例如显示在网站主页上的聚合)可以被缓存以获得更快的响应。这些缓存的结果与非缓存聚合返回的结果相同——您永远不会得到过时的结果。
更多细节请参见分片请求缓存。
在许多情况下需要聚合,但不需要搜索命中。对于这些情况,可以通过设置size=0来忽略命中。例如:
GET /twitter/_search
{
"size": 0,
"aggregations": {
"my_agg": {
"terms": {
"field": "text"
}
}
}
}
将size设置为0可以避免执行搜索的获取阶段,从而提高请求的效率。
您可以在请求时将元数据片段与各个聚合相关联,这些聚合将在响应时就地返回。
考虑这个例子,我们希望将蓝色与我们的术语聚合相关联。
GET /twitter/_search
{
"size": 0,
"aggs": {
"titles": {
"terms": {
"field": "title"
},
"meta": {
"color": "blue"
}
}
}
}
然后,这块元数据将返回到标题术语聚合的位置
{
"aggregations": {
"titles": {
"meta": {
"color" : "blue"
},
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets": [
]
}
},
...
}
有时您需要知道聚合的确切类型,以便解析其结果。typed_keys参数可用于更改响应中的聚合名称,以其内部类型作为前缀。
考虑以下名为tweets_over_time的数据直方图聚合,它有一个名为top_users的子“top_hits”聚合:
GET /twitter/_search?typed_keys
{
"aggregations": {
"tweets_over_time": {
"date_histogram": {
"field": "date",
"calendar_interval": "year"
},
"aggregations": {
"top_users": {
"top_hits": {
"size": 1
}
}
}
}
}
}
在响应中,聚合名称将分别更改为date_histogram#tweets_over_time和top_hits#top_users,反映每个聚合的内部类型:
{
"aggregations": {
"date_histogram#tweets_over_time": {
"buckets" : [
{
"key_as_string" : "2009-01-01T00:00:00.000Z",
"key" : 1230768000000,
"doc_count" : 5,
"top_hits#top_users" : {
"hits" : {
"total" : {
"value": 5,
"relation": "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index": "twitter",
"_type": "_doc",
"_id": "0",
"_score": 1.0,
"_source": {
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"user": "kimchy",
"likes": 0
}
}
]
}
}
}
]
}
},
...
}
对于某些聚合,返回的类型可能与请求提供的类型不相同。Terms、Significant Terms和Percentiles聚合就是这种情况,其中返回的类型还包含关于目标字段类型的信息:lterms(用于Long字段上的术语聚合)、sigsterms(用于String字段上的重要术语聚合)、tdigest_percentiles(用于基于TDigest算法的百分位数聚合)。
基本包含官网内容,希望对你有帮助。手快敲断了,望点赞收藏。后续还会更新更多的官网内容,可以点个关注方便知晓后续更新哦。或许后面的内容对你有帮助呢。你们想要看什么内容可以在评论区告诉我,我尽量满足大家哦!!