第一部分 --- 证明NFA能够转换为DFA
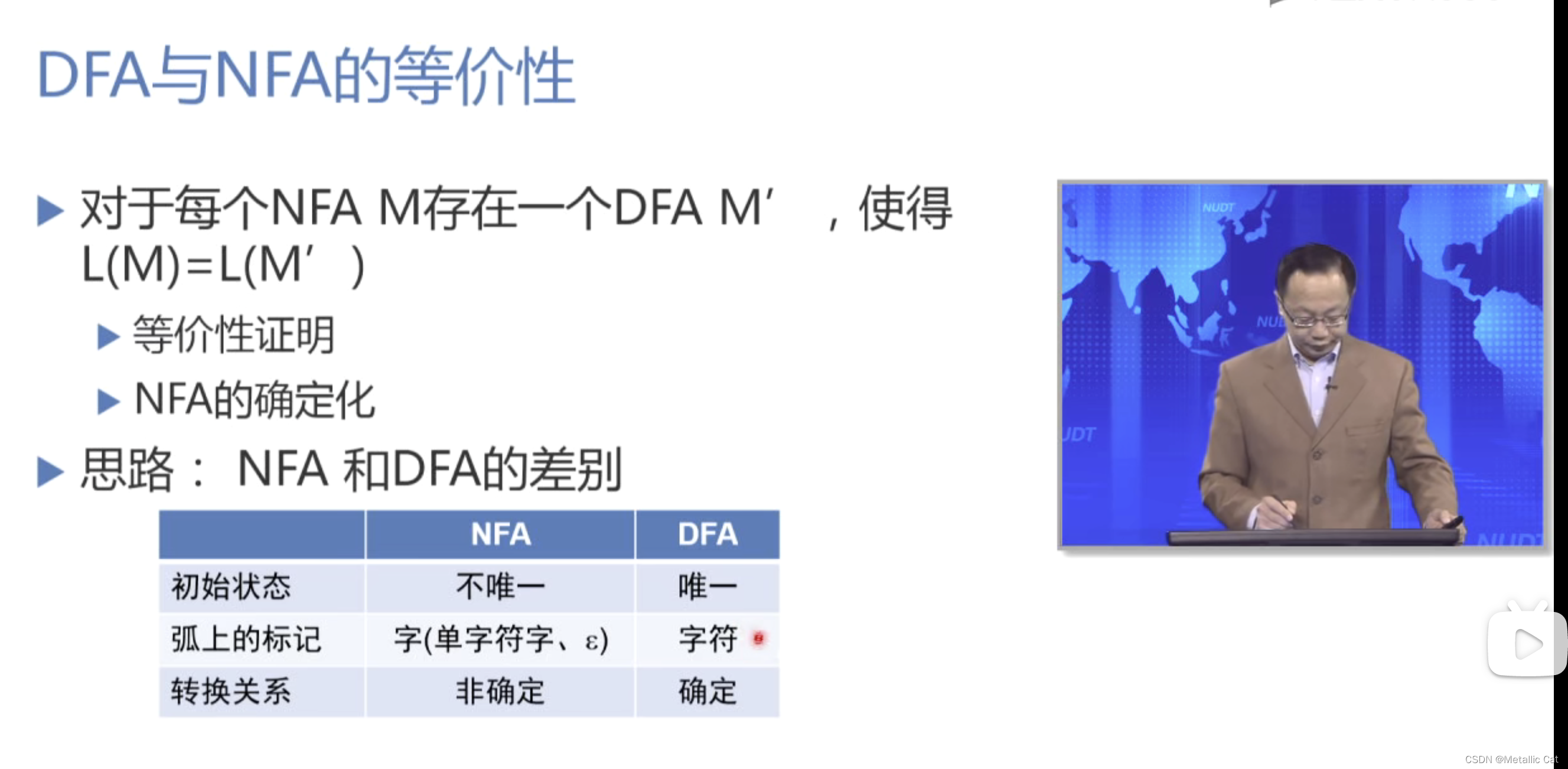

1.So是NFA的初态集合,F是NFA的终态集合
2.通过上面的第一个转换,我们就使得NFA具有了和DFA一样的唯一初态

3.通过上面的第二个转换 --- 不断引入中间状态,直到将字拆分为字符 --- 此时我们就成功的将NFA中输入以字作为判断依据的方式转换为了DFA中以字符作为判断条件的方式
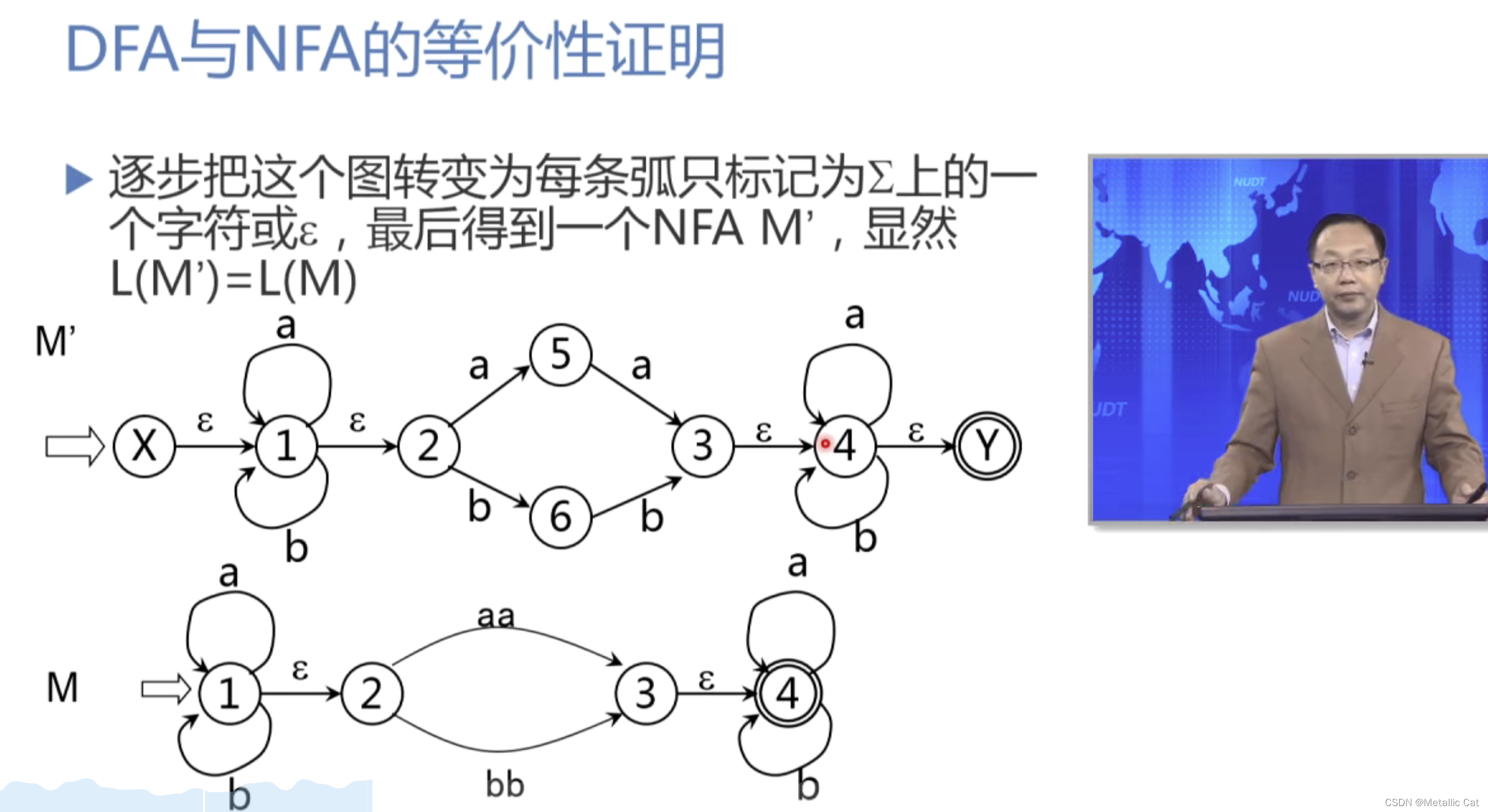


1.以 I 状态集中的某一个状态作为起点,经过一条标志为a的弧后能够到达的所有的状态组成的集合就是 J 集合(PS:除了只经过一条标志为a的弧外,也可以是经过多条标志为空的弧以及一条标志为a的弧,这两种方式是等价的!)
将上面求得的J集合做空集闭包(医婆塞洛 - closure())后得到的新状态集合就是Ia状态集合
1.如果计算出的是空集的话,我们也要求这个空集的空集闭包,并求得到的I状态的Ia和Ib (结果都是空集)
2.这个计算一定能够停止下来,因为这个状态机是有限状态机,子集数是有限的,一定能够计算完并停下来
3.第一次输入的的状态集中的 X 状态是我们在调整NFA时的第一步中插入的唯一初态 X
计算步骤:
1.将只有X状态的状态集进行闭包运算,并求取求得的 I 集合的 Ia和Ib(上面这个状态图中只有a和b,所以只有Ia和Ib,如果有更多的字符话就添加更多的列)
2.计算完后首先看第一列的所有集合包不包含Ia集合,不包含的话直接将Ia集合作为新的I结合放到第一列的下一行继续求其Ia和Ib,求完后重复第2步 ; 如果包含Ia的话就往后检视Ib,处理步骤一样 , 如果在处理完Ib后(处理完最后一个字符后)上一行还有集合没有进行检视的话就返回没被检视的集合,继续按顺序检视。
既不是初态也不是终态的状态集就是状态图中的中间态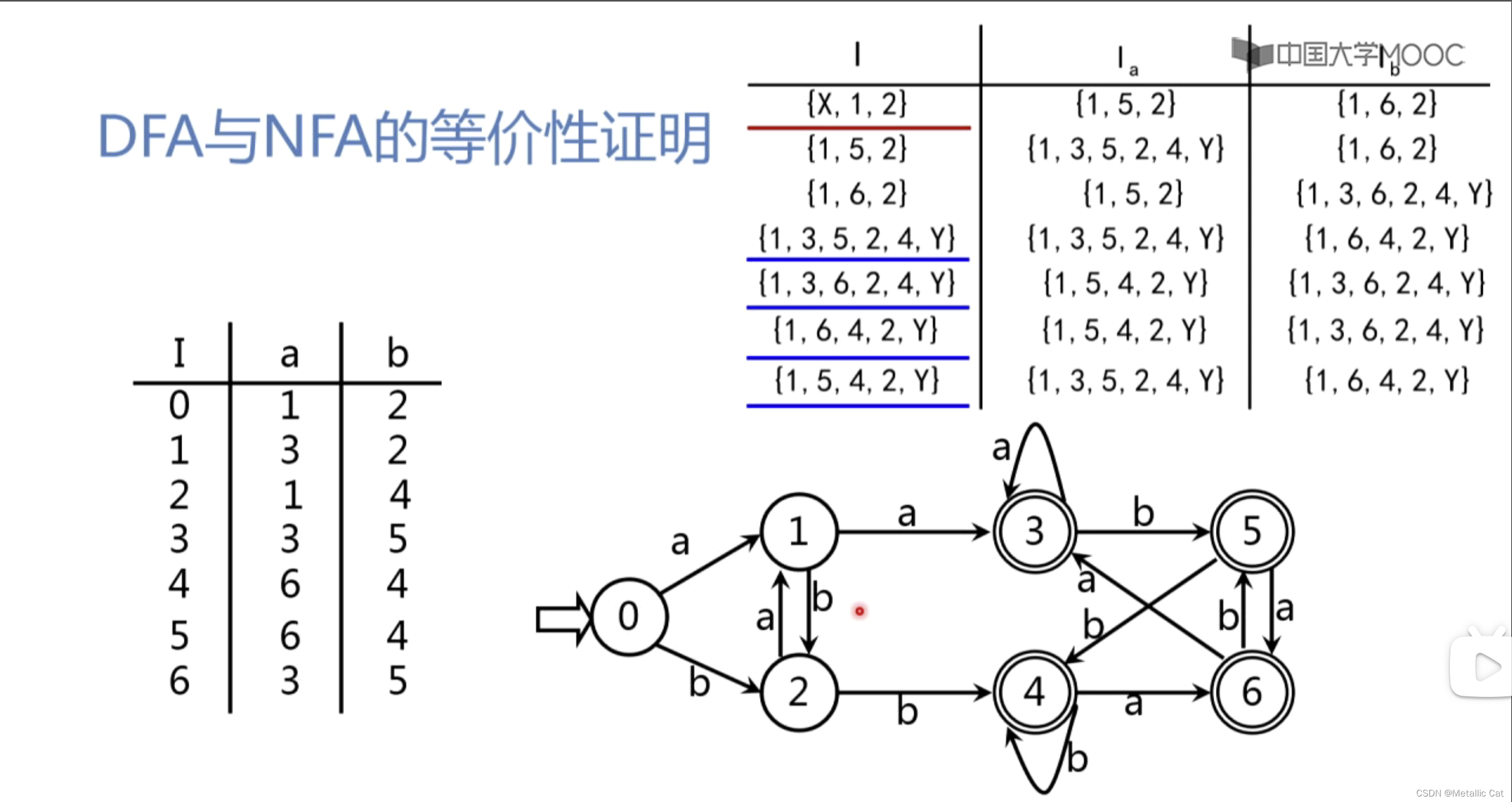
1.根据NFA求出对应的状态转换矩阵,然后将这个状态转换矩阵化简,并根据化简后的状态转换矩阵画出状态图,这个状态图就是和NFA等价的DFA的状态图。
1.在实现一个确定有限自动机时,我们使用的数据结构是二维数组,如果确定有限自动机涉及到的状态越少(字符是固定的),我们创建的二维数组越小
那么问题来了 --- 给定一个确定有限自动机A,我们能否找到一个涉及到的状态数比A少,但是又和A等价的确定有限自动机B呢?
这就是DFA的化简问题
第二部分 --- DFA的化简问题
之所以能够对有限自动机进行化简是因为在其状态图中,存在一些状态识别字的能力是一样的,遇到这种情况时我们可以只保留其中一个状态,这就是有限自动机的化简
1.如果两个状态之间是等价关系的话,那么我们可以将这两个状态合并为一个状态
2.两个状态等价:从一个状态A出发识别出某个字后并在某个终态,如果从状态B出发能够识别出一样的字后也是在终态停止的话(可以停在不同的终态),则称这两个状态等价
上面这一题的答案是B
1.对于状态等价而言,必须是任意给定一个字,从两个状态出发识别出这个字后都在终态停止才叫两个状态等价
2.而对于状态可区分,则是存在一个字,当一个状态出发识别出这个字后停止,而另一个状态在识别出后仍为停止,则称这两个状态可区分
1.将所有等价的状态划分到一个集合中,就这样不停的划分知道整个状态集的所有状态都属于某个集合为止
2.然后选择每个集合中的一个代表状态组成新的状态集,其它的状态都删除掉,此时得到的状态集就是化简后的自动机具有的状态集了

1.这一题的答案是 B ,选出B的依据就是选项下面的那两个原则:终态在识别了一波塞洛(空字符)后依然回到终态,而非终态在识别了一波塞洛(空字符)后依然回到非终态,符合状态可区分定义
2. 关于终态,来到终态后我们就会将识别到的字进行输出
终态加 * 的作用就是将识别到的字回退一个字符后再返回

我们也可以从终态出发去识别字,但是一般从终态出发都会会到终态本身,比如
上面这个终态3在识别到字符A后就会回到它本身并将字符a输出 
1. 这个Ia集合的本质其实就是I集合中的所有状态在识别了a字符后能够到达的所有状态组成的集合

1.现行Π中的两个不同子集这句话就表明了这两个状态子集是可区分的,也就是说存在一个字符使得一个状态子集中的元素识别后到达终态,而另一个状态子集中的元素无法到达终态
2.在上面这个推理的基础上我们可以直接省略中间状态t1和t2,转换为s1在读入aα后到达终态,而s2在读入aα后无法到达终态,此时就可以证明存在一个字使得s1和s2能够被区分(是的,除了存在字符以为,还可以是存在一个字)


2.如果得到的Ia是包含在现行Π中的某一个子集中的话,就不会出现可区分的情况,只会有状态等价的情况
3.如果得到的Ia不包含在现行Π中的某一个集合的话,我们开始对Ia进行拆解,首先Ia中的每一个状态元素一定属于现行Π中的某一个集合,属于相同集合的状态元素划分为一组,设总共划分了n组
4.划分了n组之后我们再去I集合中进行状态划分,首相将能够通过识别a到达3中划分的第一组的状态元素划分为1组,然后是通过识别a能到达第二组的划分为一组....,直到n组都分完之后 i 集合就完成了划分
1.第一步是划分为终态和非终态
2.第二步求第一个子集的Ia,接着将Ia进行划分,划分后对I进行划分,增加现有Π的子集
3.增加之后再对新的集合求Ia,Ib....,求完一个集合后再求下一个集合,不停的求下去直到现有Π中的子集不能够再增加为止

1.化简后第三个子集中有多个状态,此时我们需要在这个子集中取一个代表,我们要做的操作就是选一个状态作为代表,然后将子集中剩下的所有状态发出的弧由代表状态发出,接收的弧由代表状态接收(代表状态自身接收和发出的弧不发生改变)
2.做完第一步操作之后再将除代表状态外的所有状态都删除掉,这样就完成了子集的取代表操作
DFA到DFA这个操作是在对DFA进行化简