1.前言
这是第一次写技术博客,打算是总结一遍数据结构与算法,并尽量结合Leetcode来提升自己,希望各位朋友多提意见!第一轮是基础总结,涵盖的数据结构和相关算法有数组、栈与队列、链表、递归、二叉树、二叉搜索树、堆、排序算法。
2.数组基础定义
官方定义:将元素顺序地存放在一块连续的存储区里,元素之间的顺序关系由它们的存储顺序自然表示。
一句话总结:将数据码成一排进行存放。

优点:快速查询 —> 最好应用于“索引有语义”的情况
注意:并不是所有有语义的索引都适用,比如身份证号(如13131413415153),不太适合开辟从0到这么大的数的空间,浪费!
Anyway,这里我们主要处理索引没语义的情况下数组的使用。
正式开始前,会先提前列出数组的特点如下:
-
占用一段连续的内存空间,支持随机(索引)访问,且时间复杂度为O(1)
-
添加元素时间复杂度:O(n)
-
删除元素时间复杂度:O(n)
3.数组增删改查
3.1基本功能
这里我们为了构造一个动态数组,定义了一个数组类(即Class Array),并根据不同需求构造不同功能。
这里值得注意的是capacity指的是数组最大容量,而size是数组有效元素的数目。
class Arr:
def __init__(self, capacity=10):
"""
构造函数
:param capacity: 数组最大容量,不指定的话默认为10
"""
self._capacity = capacity
self._size = 0 # 数组有效元素的数目,初始化为0
self._data = [None] * self._capacity # 由于python的list是动态扩展的,而我们要实现底层具有固定容量、占用一段连续的内存空间的数组,所以用None来作为无效元素的标识
def __getitem__(self, item):
"""让Arr类支持索引操作"""
return self._data[item]
def getSize(self):
"""返回数组有效元素的个数"""
return self._size
def getCapacity(self):
"""返回当前数组的容量"""
return self._capacity
def isEmpty(self):
"""判断当前数组是否为空"""
return self._size == 0
3.2添加元素
一开始想怎么往数组最后加一个元素,实现如下:
def addLast(self, elem):
if self._size == self._capacity:
raise Exception('illegal argument, failed array is already full')
self._data[self._size] = e
self._size += 1
但是能不能有一个add方法可以往数组中随意位置添加一个元素呢?思路:向数组中添加一个元素,注意数组占用的是一段连续的内存空间,所以在添加元素后,数组还是要保证这个特点的,因此需要将后面的元素都向后挪一个位置,而且要注意要先从尾部开始挪,防止元素之间的覆盖。
def add(self, index, elem):
"""
时间复杂度:O(n)
:param index: 添加的元素所在的索引
:param elem: 所要添加的元素
"""
if index < 0 or index > self._size: # 插入的位置无效
raise Exception('Add Filed. Require 0 <= index <= self._size')
if self._size == self._capacity: # 满了
raise Exception('illegal argument, failed array is already full')
for i in range(self._size - 1, index - 1, -1): # 从尾部开始挪动元素,在index处腾出一个空间
# 一定要注意在步长为负数的情况下,区间是左开右闭区间,即(index, self._size - 1],所以是index-1,与正常的左闭右开区间是相反的!
self._data[i + 1] = self._data[i]
self._data[index] = elem # 将该位置赋值为elem
self._size += 1 # 数组有效元素数加1
接下来,addLast和addFirst方法就可以直接调用add方法了。
def addLast(self, elem):
"""
向数组尾部添加元素
时间复杂度:O(1)
:param elem: 所要添加的元素
"""
self.add(self._size, elem) # 直接调用add方法,注意不用再次判定合法性了,因为add函数中已经判断过了
def addFirst(self, elem):
"""
想数组头部添加元素
时间复杂度:O(n)
:param elem: 所要添加的元素
"""
self.add(0, elem) # 同理直接调用add方法
3.3查询和修改元素
def get(self, index):
"""
获得索引index处的元素
时间复杂度:O(1)
:param index: 数组索引
:return: 数组索引处的值
"""
if index < 0 or index >= self._size: # 判断index的合法性
raise Exception('Get failed. Index is illegal.')
return self._data[index]
def getFirst(self):
"""
获得数组首位置元素的值
:return: 首位置元素的值
"""
return self.get(0) # 直接调用get函数,安全可靠
def getLast(self):
"""
获得数组末尾元素的值
:return: 末尾元素的值
"""
return self.get(self._size - 1) # 直接调用get函数,安全可靠
def set(self, index, elem):
"""
将索引为index的元素的值设为elem
时间复杂度:O(1)
:param index: 索引
:param elem: 新的值
"""
if index < 0 or index >= self._size: # 判断index的合法性
raise Exception('Sat failed. Index is illegal.')
self._data[index] = elem
3.4包含、搜索和删除元素
这里讲一下删除的思路:删除索引为index的元素。index后面的元素都要向前移动一个位置
def contains(self, elem):
"""
查看数组中是否存在元素elem,最好不要传入一个浮点数,你懂得。。
时间复杂度:O(n)
:param elem: 目标元素
:return: bool值,存在为真
"""
for i in range(self._size): # 遍历
if self._data[i] == elem:
return True # 找到了就返回True
return False # 遍历完了还没找到,就返回False
def find(self, elem):
"""
在数组中查找元素,并返回元素所在的索引。(如果数组中存在多个elem,只返回最左边elem的索引)
时间复杂度:O(n)
:param elem: 目标元素
:return: 元素所在的索引,没找到则返回-1(无效值)
"""
for i in range(self._size): # 遍历数组
if self._data[i] == elem:
return i # 找到就返回索引
return -1 # 没找到返回-1
def findAll(self, elem):
"""
找到值为elem全部元素的索引
:param elem: 目标元素
:return: 一个列表,值为全部elem的索引
"""
ret_list = Arr() # 建立一个新的数组用于存储索引值
for i in range(self._size): # 遍历数组
if self._data[i] == elem:
ret_list.addLast(i) # 找到就将索引添加进ret_list
return ret_list
def remove(self, index):
"""
删除索引为index的元素。index后面的元素都要向前移动一个位置
时间复杂度:O(n)
:param index: 目标索引
:return: 位于该索引的元素的值
"""
if index < 0 or index >= self._size: # index合法性检查
raise Exception('Remove failed.Require 0 <= index < self._size')
ret = self._data[index] # 拷贝一下index处的元素,便于返回
for i in range(index + 1, self._size): # index后面的元素都向前挪一个位置
self._data[i - 1] = self._data[i]
self._size -= 1 # 维护self._size
return ret
def removeFirst(self):
"""
删除数组首位置的元素
时间复杂度:O(n)
:return: 数组首位置的元素
"""
return self.remove(0) # 调用remove函数
def removeLast(self):
"""
删除数组末尾的元素
时间复杂度:O(1)
:return: 数组末尾的元素
"""
return self.remove(self._size - 1) # 调用remove函数
def removeElement(self, elem):
"""
删除数组中为elem的元素,如果数组中不存在elem,那么什么都不做。如果存在多个相同的elem,只删除最左边的那个
时间复杂度:O(n)
:param elem: 要删除的目标元素
"""
index = self.find(elem) # 尝试找到目标元素(最左边的)的索引
if index != -1: # elem在数组中就删除,否则什么都不做
self.remove(index) # 调用remove函数
def removeAllElement(self, elem):
"""
删除数组内所有值为elem的元素,可以用递归来写,这里用的迭代的方法。elem不存在就什么都不做
:param elem: 要删除的目标元素
"""
while True:
index = self.find(elem) # 循环来找elem,如果elem不存在就什么都不做,存在就继续删除
if index != -1: # 若存在
self.remove(index)
else:
break
3.5其他
def get_Max_index(self):
"""
获取数组中的最大元素的索引,返回最大元素的索引值,如果有多个最大值,默认返回最左边那个的索引
时间复杂度:O(n)
:return: 最大元素的索引
"""
if self.isEmpty():
raise Exception('Error, array is Empty!')
max_elem_index = 0 # 记录最大值的索引,初始化为0
for i in range(1, self.getSize()): # 从索引1开始遍历,一直到数组尾部
if self._data[i] > self._data[max_elem_index]: # 如果当前索引的值大于最大值索引处元素的值
max_elem_index = i # 更新max_elem_index,这样它还是当前最大值的索引
return max_elem_index # 遍历完后,将数组的最大值的索引返回
def removeMax(self):
"""
删除数组中的最大元素,返回最大元素的值,如果有多个最大值,默认值删除最左边那个
时间复杂度:O(n)
:return: 最大元素
"""
return self.remove(self.get_Max_index()) # 直接调用remove函数删除最大值
def get_Min_index(self):
"""
获取数组中的最小元素的索引,返回最小元素的索引值,如果有多个最小值,默认返回最左边那个的索引
时间复杂度:O(n)
:return: 最小元素的索引
"""
if self.isEmpty():
raise Exception('Error, array is Empty!')
min_elem_index = 0 # 记录最小值的索引,初始化为0
for i in range(1, self.getSize()): # 从索引1开始遍历,一直到数组尾部
if self._data[i] < self._data[min_elem_index]: # 如果当前索引的值小于最小值索引处元素的值
min_elem_index = i # 更新min_elem_index,这样它还是当前最小值的索引
return min_elem_index # 遍历完后,将数组的最小值的索引返回
def removeMin(self):
"""
删除数组中的最小元素,返回最小元素的值,如果有多个最小值,默认值删除最左边那个
时间复杂度:O(2n),可以看成是O(n)的
:return: 最小元素
"""
return self.remove(self.get_Min_index())
def swap(self, index1, index2):
"""
交换分别位于索引index1和索引index2处的元素
:param index1: 索引1
:param index2: 索引2
"""
if index1 < 0 or index2 < 0 or index1 >= self._size or index2 >= self._size: # 合法性检查
raise Exception('Index is illegal')
self._data[index1], self._data[index2] = self._data[index2], self._data[index1] # 交换元素
def printArr(self):
"""对数组元素进行打印"""
for i in range(self._size):
print(self._data[i], end=' ')
print('\nSize: %d-----Capacity: %d' % (self.getSize(), self.getCapacity()))
3.6检验
让我们写一段代码来试试我们的方法o不ok。
import numpy as np
np.random.seed(7)
test = Arr()
print(test.getSize())
print(test.getCapacity())
print(test.isEmpty())
for i in range(8):
test.add(0, np.random.randint(5))
test.printArr()
test.addLast(2)
test.printArr()
print(test.get(3))
test.set(3, 10)
test.printArr()
print(test.contains(10))
print(test.find(4))
test.findAll(1).printArr()
test.remove(3)
test.printArr()
test.removeFirst()
test.removeLast()
test.printArr()
test.removeElement(4)
test.printArr()
test.removeAllElement(3)
test.printArr()
for i in range(30):
test.addLast(np.random.randint(10))
test.printArr()
print(test[3])
test.swap(0, 1)
test.printArr()
结果如下:
0
10
True
1 0 1 4 3 3 1 4
Size: 8-----Capacity: 10
1 0 1 4 3 3 1 4 2
Size: 9-----Capacity: 10
4
1 0 1 10 3 3 1 4 2
Size: 9-----Capacity: 10
True
7
0 2 6
Size: 3-----Capacity: 10
1 0 1 3 3 1 4 2
Size: 8-----Capacity: 10
0 1 3 3 1 4
Size: 6-----Capacity: 10
0 1 3 3 1
Size: 5-----Capacity: 10
0 1 1
Size: 3-----Capacity: 10
0 1 1 8 7 6 4 0 7 0 7 6 3 5 8 8 7 5 0 0 2 8 9 6 4 9 7 3 3 8 3 0 1
Size: 33-----Capacity: 40
8
1 0 1 8 7 6 4 0 7 0 7 6 3 5 8 8 7 5 0 0 2 8 9 6 4 9 7 3 3 8 3 0 1
Size: 33-----Capacity: 40
应该是OK了吧。
4.动态数组及其时间复杂度
4.1动态数组的实现
如果已有的数组已经装满了,根据已有的方法,是会抛出异常的,所以我们的思路是:开辟一个两倍容量的数组(这样能保证扩容后的空间跟原来保持一个数量级,性能方面有好处),依次把原数组的数据复制到新数组(capacity加倍,size不变)。



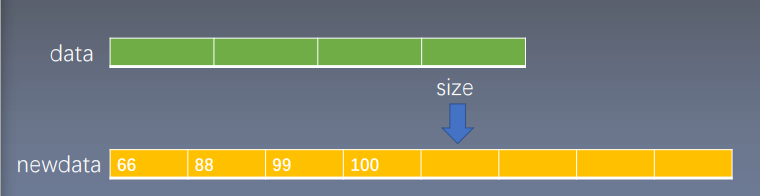
# private
def _resize(self, new_capacity):
"""
数组容量放缩至new_capacity,私有成员函数
:param new_capacity: 新的容量
"""
new_arr = Arr(new_capacity) # 建立一个新的数组new_arr,容量为new_capacity
for i in range(self._size):
new_arr.addLast(self._data[i]) # 将当前数组的元素按当前顺序全部移动到new_arr中
self._capacity = new_capacity # 数组容量变为new_capacity
self._data = new_arr._data # 将new_arr._data赋值给self._data,从而完成数组的容量放缩操作
那么接下来,我们可以回过头改写原来的add方法。
def add(self, index, elem):
"""
向数组中添加一个元素,注意数组占用的是一段连续的内存空间,所以在添加元素后,数组还是要保证这个特点的,因此需要将后面的元素都向后挪一个位置,而且要注意要先从
尾部开始挪,防止元素之间的覆盖
时间复杂度:O(n)
:param index: 添加的元素所在的索引
:param elem: 所要添加的元素
"""
if index < 0 or index > self._size: # 插入的位置无效
raise Exception('Add Filed. Require 0 <= index <= self._size')
if self._size == self._capacity: # 满了
self._resize(self._capacity * 2) # 默认扩容当前容量的二倍。容量翻倍要比容量加上一个固定值要好,这样做均摊复杂度为O(1)。具体请百度
for i in range(self._size - 1, index - 1, -1): # 从尾部开始挪动元素,在index处腾出一个空间
# 一定要注意在步长为负数的情况下,区间是左开右闭区间,即(index, self._size - 1],所以是index-1,与正常的左闭右开区间是相反的!
self._data[i + 1] = self._data[i]
self._data[index] = elem # 将该位置赋值为elem
self._size += 1 # 数组有效元素数加1
同理,当有效元素个数是总容量的1/2时,为了不浪费剩余容量,我们也可以将容量减少至一半,下面我们对remove方法动手:
def remove(self, index):
"""
删除索引为index的元素。index后面的元素都要向前移动一个位置
时间复杂度:O(n)
:param index: 目标索引
:return: 位于该索引的元素的值
"""
if index < 0 or index >= self._size: # index合法性检查
raise Exception('Remove failed.Require 0 <= index < self._size')
ret = self._data[index] # 拷贝一下index处的元素,便于返回
for i in range(index + 1, self._size): # index后面的元素都向前挪一个位置
self._data[i - 1] = self._data[i]
self._size -= 1 # 维护self._size
self._data[self._size] = None # 最后一个元素的垃圾回收
if self._size and self._capacity // self._size == 2: # 如果当前有效元素为总容量的二分之一且还存在有效元素,则将容量缩减为原来的一半
self._resize(self._capacity // 2)
return ret
此时,我们才算真正实现了动态数组!
4.2增删改查时间复杂度
But,我们开始考虑一下动态数组的时间复杂度。
注意:一般会考虑最坏情况。
-
添加操作 : O(n)

-
删除操作 :O(n)

-
修改操作 :

-
查询操作:

总结动态数组时间复杂度分析:

4.3动态数组均摊复杂度
但这时候会想到,addLast方法是O(1),只有触发resize方法后才会变成O(n),可是并不适合什么时候都会触发resize来扩容的呀。举个如下例子:

9次addLast操作,触发resize,从而需要8次转移操作,总共进行了17次基本操作。因此平均每次addLast进行了2次基本操作。
推广开来,假设capacity=m,m+1次addLast操作,触发resize,从而需要m次转移操作,总共进行了2m+1次基本操作。因此平均每次addLast进行了2次基本操作。
所以,我们可以说addLast的均摊复杂度是O(1),跟我们当前数组有多少个元素没关系。同理对于removeLast一样。
通俗来说,这样算均摊复杂度是比算最坏情况有意义的,因为最坏的情况不是每次都出现。实际考量中,如果一个相对比较耗时的操作(如这里resize)不是经常被触发,它的耗时可以被分摊到其他基本操作上的。
4.4复杂度震荡
这个时候我想到一个比较极端的情况,如果一个数组已经满了,再在尾部加一个元素,触发resize,从而复杂度是O(n),但接着我需要删掉刚刚的元素,这时容量变成原来一半了,又触发resize,从而复杂度又是O(n)。
可是我们前面才讲过addLast和removeLast的均摊复杂度是O(1)啊,究其原因,原来是我们其实减容减的太着急了。所以我们可以试着等有效元素个数是总容量的1/4时,再去减容。
def remove(self, index):
"""
删除索引为index的元素。index后面的元素都要向前移动一个位置
时间复杂度:O(n)
:param index: 目标索引
:return: 位于该索引的元素的值
"""
if index < 0 or index >= self._size: # index合法性检查
raise Exception('Remove failed.Require 0 <= index < self._size')
ret = self._data[index] # 拷贝一下index处的元素,便于返回
for i in range(index + 1, self._size): # index后面的元素都向前挪一个位置
self._data[i - 1] = self._data[i]
self._size -= 1 # 维护self._size
self._data[self._size] = None # 最后一个元素的垃圾回收
if self._size and self._capacity // self._size == 4: # 如果当前有效元素为总容量的四分之一且还存在有效元素,则将容量缩减为原来的一半
self._resize(self._capacity // 2)
return ret
5.Python列表与字典操作的时间复杂度
5.1列表操作时间复杂度

5.2字典操作时间复杂度

6.致谢
这是第一次学着去在博客总结自己的学习经历,也希望看过的朋友多多指教!也希望自己能坚持下去!