classtvSpider(scrapy.Spider):
name ="douban_tv"
allowed_domain =["movie.douban.com"]def__init__(self,*args,**kwargs):super(tvSpider, self).__init__(*args,**kwargs)
self.start_urls =["https://movie.douban.com/j/search_subjects?type=tv&tag=热门&sort=recommend&page_limit=20&page_start=0"]defparse(self, response):
results = json.loads(response.body)['subjects']for result in results:
tv_item = TvListItem()
url = result['url']
tv_item['url']= url.strip()print(url)
这次我们的思路是先拿到每部电视剧的url,然后再回调二次解析的函数获取详细信息。运行爬虫,可以看到我们已经得到了自己想要的结果。 接下在就迭代使用scrapy.Request()请求每一个url,再使用二次解析函数parse_detait获取详细数据。 two years later。经过漫长的debug,终于得到以下代码代码:

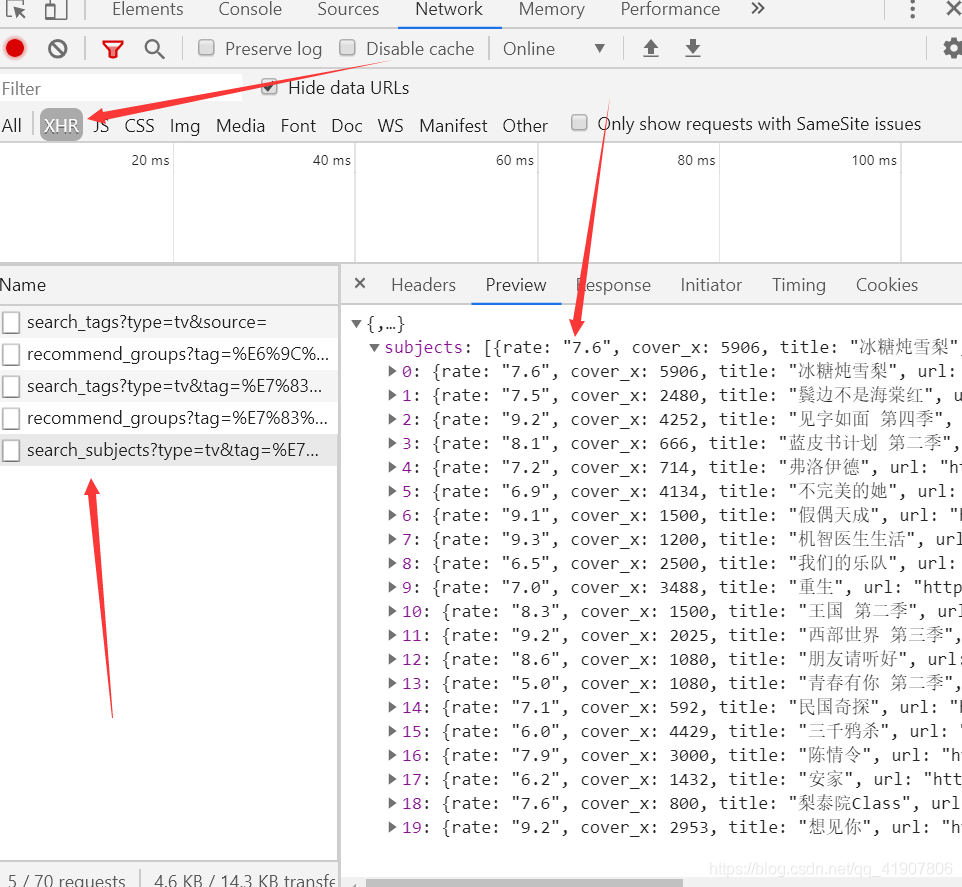

 接下在就迭代使用
接下在就迭代使用