前言
最近在查找OCR开源项目时,发现了商汤公司的MMOCR,它和百度公司的PaddleOCR一样都是用于OCR文本检测和识别的开源框架,里面也集成了很多当下比较优秀的检测与识别模型,比如DBNet, CRNN等。之前有用过PaddleOCR,还真没用过MMOCR。出于好奇,研究了下MMOCR支持的检测与识别模型,发现了在PaddleOCR里没有实现的两个2021年的新模型,一个是用于文本检测的FCENet模型,一个用于文本识别的SegOCR模型,这里主要跟大家分享下FCENet模型。
看MMOCR检测结果还不错, 和DBNet相比(MMOCR测试)好像FCENet的结果更好一些,但是从测试数据上看,FCENet的测试图像分辨率更高,epoch数量也更大,而且好像backbone也不相同,所以仅从数据中就说FCENet比DBNet更好是不可靠的。
MMOCR中DBNet测试结果:

MMOCR中PCENet测试结果:

论文链接:Fourier Contour Embedding for Arbitrary-Shaped Text Detection
摘要(Abstract)
任意形状文本检测的主要挑战就是能够设计一个足够好的文本实例表示,能够允许网络去学习多样的文本几何变化。大部分现有的方法是对图像中文本实例进行空域建模,即在笛卡尔或者极坐标系下的掩膜(mask)或者轮廓点序列建模。然而,掩膜表示可能带来高成本的后处理,点序列的方式对高度弯曲的文本形状建模可能有容量限制的问题。为了解决这些问题,论文在傅里叶域(Fourier,通常说的频域)对文本实例建模,提出一种新颖的傅里叶轮廓嵌入(Fourier Contour Embedding, FCE)的方法来将任意形状的文本轮廓表示为紧凑的特征。论文在此基础上搭建了FCENet,包括特征提取层(backbone),特征金字塔网络(FPN, neck)和由反向傅里叶变换(IFT)和非极大值抑制(NMS)组成的简单后处理。和之前的方法不同,在测试期间,FCENet首先为文本实例预测傅里叶特征,然后根据IFT和NMS来重新构建文本轮廓。实验证明FCE对定位场景文本的轮廓是非常准确的鲁棒的,对高度弯曲的文本形状也是如此;实验也验证了FCENet对任意形状文本检测的效率和优秀的泛化能力。实验结果表明了FCENet在CTW1500和Total-Text数据集上获得当时最优结果,特别是在有挑战性的高度弯曲文本子集中。
1. 介绍(Introduction)

论文中,在傅里叶域中对文本实例轮廓建模取代以前空域建模的方法,通过使用傅里叶变换可以以一种鲁棒且简单的方式通过渐进近似来拟合任何封闭轮廓(所有文本实例都是封闭的吗?如果不是封闭的,会怎么样?)。Fig.1(a)表明傅里叶变换可以准确拟合极其复杂的形状,比如肖像素描,通过使用非常紧促的特征,比如
K
=
125
K=125
K=125,表明随着傅里叶度数
k
k
k的增加,重构的形状越接近真实(Ground Truth)。和
T
e
x
t
R
a
y
TextRay
TextRay 这个在极坐标系下使用文本轮廓点序列的当时最优模型相比,论文提出的傅里叶轮廓表示可以对高度弯曲的文本更好地建模,如Fig.1(b-c)所示。
论文提出FCE方法将文本实例轮廓从点序列转换为傅里叶特征向量。首先,论文提出一种重采样机制来获得每一文本轮廓固定数量的稠密点。为了保证傅里叶特征向量的独特性,论文将文本轮廓域穿过文本中心点的水平线的最右边的交点作为采样起始点,固定采样方向为顺时针方向,沿着文本轮廓进行等间隔采样。其次,空间域中轮廓采样点序列通过傅里叶变换被嵌入到傅里叶域中。
FCE对于文本实例表示而言由三点优势:
- 灵活(Flexible):任何闭合轮廓,包括极其复杂的形状,都可以被准确拟合;
- 紧凑(Compactness):傅里叶特征向量是紧凑的,在实验中,傅里叶度数
K
=
5
K=5
K=5就可以实现文本精确近似;
- 简单(Simplicity):采样点序列与傅里叶特征向量间通过傅里叶变换和反傅里叶变换就可以实现,没有引入复杂的后处理(傅里叶变换与反傅里叶变换不是很耗时吗?即使有快速傅里叶变换方法,但是和普通空间域操作相比还是需要更长的时间)。
配备了FCE,论文搭建了FCENet用于任意形状文本检测。FCENet由三部分组成:backbone - ResNet50_DCN,即配备了可变形卷积的残差网络模型作为特征提取层;特征金字塔网络(FPN)作为neck层;FCE作为head层。这个head层由两个独立的分支组成:分类分支和回归分支。分类分支用来预测文本区域掩膜和文本中心区域掩膜。回归分支用来预测傅里叶域中文本的傅里叶特征向量,然后将该特征向量输入到反向傅里叶变换进行文本轮廓点序列的重建。真实(Ground Truth)文本轮廓点序列用作监督信号。由于FCE的重采样机制,回归分支中的损失兼容不同数据集,即使像CTW1500和Total-Text这样每一个文本实例有不同数量的轮廓点。
实验证实了FCENet对于任意形状文本检测的有效性和优秀的泛化能力。而且,FCENet在CTW1500和Total-Text数据集上超过了当时最优模型,尤其是在高度弯曲文本子集中。
论文的主要贡献:
- 提出FCE方法,它可以准确近似任意闭合形状,包括任意形状的文本轮廓,生成紧凑的傅里叶特征向量;
- 提出FCENet,第一个在傅里叶域中预测文本实例的傅里叶特征向量,然后通过反向傅里叶变换在图像空间域中重建文本轮廓点序列。这个过程可以进行端到端的学习,不需要任何复杂的后处理过程就可以进行推理。
- 对提出的FCE和FCENet进行了大量的实验验证。实验结果表明了FCE具有优秀的表示能力,特别在高度弯曲的文本方面;当在小数据集上进行训练时,FCENet有很好的泛化能力。而且,FCENet在CTW1500和Total-Text数据集上超过了了当时最优模型。(个人表示很期待FCENet在中文检测上的能力)
2. 相关工作(Related Work)
论文主要就文本检测的两个主要方向进行了阐述:基于分割的方法和基于回归的方法,这里就不细说了,大家感兴趣可以自行阅读论文。
3. 方法(Approach)
这一章节,首先引入FCE方法,它可以将任意形状的文本轮廓近似表示为紧凑的傅里叶特征向量。然后提出了配备FCE的FCENet来检测任意形状的文本。
3.1 傅里叶轮廓嵌入(Fourier Contour Embedding)

论文使用一个复函数来表示任一文本闭合轮廓:
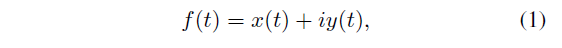
上式中,
i
i
i表示复函数的虚部,
t
∈
[
0
,
1
]
t\in [0,1]
t∈[0,1],
(
x
(
t
)
,
y
(
t
)
)
(x(t),y(t))
(x(t),y(t))表示在时刻
t
t
t的空间坐标。因为
f
f
f是一个闭合轮廓,所以
f
(
t
)
=
f
(
t
+
1
)
f(t)=f(t+1)
f(t)=f(t+1)。
f
(
t
)
f(t)
f(t)的反傅里叶变换表示为:
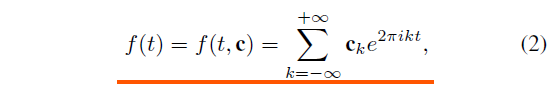
上式中,
k
k
k表示频率,
c
k
c_{k}
ck表示傅里叶系数,用它来描述频率
k
k
k的初始状态。公式中每一个累加单元
c
k
e
2
π
i
k
t
c_{k}e^{2\pi ikt}
cke2πikt表示了一个圆形移动,它使用一个初始右旋向量
c
k
c_{k}
ck和固定频率
k
k
k。因此,这个轮廓可被视为不同频率的圆形移动的组合,如图Fig.2中粉色圆所示。从公式(2)可知,低频单元可以定位粗粒度的文本轮廓,高频单元可定位轮廓的细节。论文经验发现仅保留
K
K
K个最低(论文实验中
K
=
5
K=5
K=5)的频率同时废弃其它频率单元就可以找到满意的近似文本轮廓,如图Fig.5所示。

因为无法获得实际应用中文本轮廓函数
f
f
f的分析形式(个人理解就是连续函数),论文对连续函数
f
f
f离散化到
N
N
N个点,即
f
(
n
N
)
{f(\frac{n}{N})}
f(Nn),这里
n
∈
[
1
,
.
.
.
,
N
]
n\in [1,...,N]
n∈[1,...,N]。这里,公式(2)中的
c
k
c_{k}
ck可通过如下傅里叶变换公式计算:
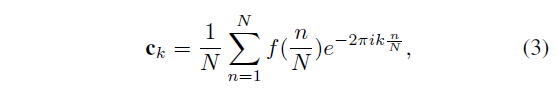
这里,
c
k
=
u
k
+
i
v
k
c_{k}=u_{k} + iv_{k}
ck=uk+ivk,
u
k
u_{k}
uk表示实部,
v
k
v_{k}
vk表示虚部。当
k
=
0
k=0
k=0时,
c
0
=
u
0
+
i
v
0
=
1
N
∑
n
f
(
n
N
)
c_{0} = u_{0} + iv_{0}=\frac{1}{N}\sum_{n}{f(\frac{n}{N})}
c0=u0+iv0=N1∑nf(Nn),表示轮廓的中心位置。对于任一文本轮廓
f
f
f,FCE方法可以用一个紧凑的
2
(
2
K
+
1
)
2(2K+1)
2(2K+1)维的向量
[
u
−
K
,
v
−
K
,
.
.
.
,
u
0
,
v
0
,
.
.
.
,
u
K
,
v
K
]
[u_{-K}, v_{-K}, ..., u_{0}, v_{0}, ..., u_{K}, v_{K}]
[u−K,v−K,...,u0,v0,...,uK,vK]在傅里叶域中表示,论文称它为傅里叶特征向量。
FCE方法包括两个过程:重采样阶段和傅里叶变换阶段。在重采样阶段,在文本轮廓上按照固定采样点数
N
N
N(论文实验中
N
=
400
N=400
N=400)采样,获得重采样点序列
{
f
(
1
N
)
,
.
.
.
,
f
(
1
)
}
\{f(\frac{1}{N}), ..., f(1)\}
{f(N1),...,f(1)}。这个重采样过程是必须的,这是因为不同的数据集文本实例有不同的真实(ground truth)点数,一般相对比较小,比如 CTW1500中有14个轮廓点,然而Total-Text仅有
4
8
4~8
4 8个轮廓点。重采样策略让FCE能够使用相同的配置兼容所有的数据集。在傅里叶变换阶段,重采样点被转换为相应的傅里叶特征向量中。
傅里叶特征向量唯一性:从以上FCE的处理过程中,我们可以很简单的看到:不同的重采样点序列可能导致不同的傅里叶特征向量,即使是对于相同的文本轮廓也是如此。为了保证文本轮廓特征向量的独特性,并且让网络训练更加稳定,论文对起始点,采样方向以及移动速度
f
(
t
)
f(t)
f(t)进行限制:
- 起始点:设置起始点
f
(
0
)
(
或
者
f
(
1
)
)
f(0) (或者f(1))
f(0)(或者f(1))为最右边轮廓与通过中心点
(
u
0
,
v
0
)
(u_{0}, v_{0})
(u0,v0)的水平直线的交点。
- 采样方向:总是研制文本轮廓顺时针方向进行重采样;
- 统一速度:对文本轮廓采样点统一,即相邻采样点距离相同。
(说实话,这部分读了几遍也不理解FCE方法的傅里叶变换过程是怎么学习的,为什么要学习傅里叶变换过程?可能要阅读源码才能理解吧)
3.2 FCENet

基于FCE方法,论文提出了无锚框(anchor free)的FCENet用来检测任意形状的文本。
网络架构
PCENet使用了自顶向下的方式,如图Fig.3所示,包括带可变形卷积网络的ResNet50的特征提取曾作为backbone, 特征金字塔网络作为neck层用来提取多尺度特征,以及傅里叶预测header。这个header包含两个分支,分别用来预测分类与回归。每个分支都由3个
3
×
3
3\times 3
3×3卷积层和1个
1
×
1
1\times 1
1×1卷积层组成,每一卷积层后紧跟着一个
R
e
L
U
ReLU
ReLU非线性激活函数层。
在分类分支,论文预测文本区域(TR, Text Regions)的每一像素的掩膜。论文发现文本中心区域(TCR, Text Center Region)的预测能进一步提升性能。论文认为这就是因为TCR可以 过滤掉文本边界的低质量预测。
在回归分支,对文本中的每一像素回归得到傅里叶特征向量。为了能够处理不同尺度的文本实例,
P
3
,
P
4
,
P
5
P3, P4, P5
P3,P4,P5特征图对应小、中、大的文本实例。
使用IFT和NMS将检测结果从傅里叶域到空间域重建, 如图Fig.4。

生成Ground-Truth
对于分类任务,论文使用了
T
e
x
t
S
n
a
k
e
TextSnake
TextSnake中的方式来获得TCR的掩膜,通过使用收缩因子为
0.3
0.3
0.3来收缩文本区域,如Fig.2中绿色掩膜区域。对于回归任务,论文计算真实(ground truth)轮廓的傅里叶特征向量
c
‾
\overline{c}
c通过使用FCE方法。注意对于在一个文本实例掩膜的所有像素,论文预测文本轮廓,因此需要在在复数域坐标系中
(
0
,
0
)
(0,0)
(0,0)位置对应的像素的傅里叶特征向量。在相同的文本实例中不同的像素共享相同的傅里叶特征向量,除了
c
0
c_{0}
c0。
(从论文中没法了解详细的生成的Ground-Truth的过程,看来还是要看源码啊)
损失函数
基于FCE的网络的优化目标函数如下:
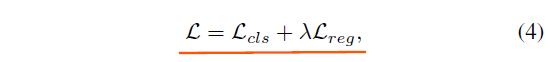
上式中,
L
c
l
s
,
L
r
e
g
L_{cls},L_{reg}
Lcls,Lreg分别表示分类损失和回归损失,
λ
\lambda
λ表示平衡系数,论文中使用
λ
=
1
\lambda = 1
λ=1。
L
c
l
s
L_{cls}
Lcls由两部分组成:
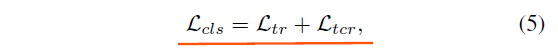
上式中
L
t
r
,
L
t
c
r
L_{tr}, L_{tcr}
Ltr,Ltcr分别表示文本区域与文本中心区域的交叉熵损失。为了解决样本不平衡问题,对于
L
t
r
L_{tr}
Ltr使用
O
H
E
M
OHEM
OHEM正负采样比率为
1
:
3
1:3
1:3。
对于
L
r
e
g
L_{reg}
Lreg,论文不是对预测的傅里叶特征向量与相应的真实值进行最小化距离优化,而是对重建后的空间域文本轮廓进行最小化优化,更能反应文本检测的质量,公式如下:
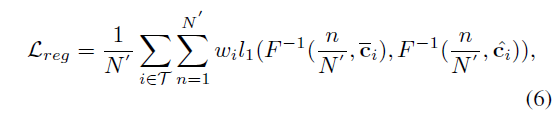
这里
l
1
l_{1}
l1表示
s
m
o
o
t
h
−
l
1
smooth-l_{1}
smooth−l1损失,
F
−
1
(
⋅
)
F^{-1}(\cdot)
F−1(⋅)表示公式(2)中的IFT。
T
T
T表示文本区域像素索引。
c
i
‾
,
c
i
^
\overline{c_{i}}, \hat{c_{i}}
ci,ci^分别表示像素
i
i
i的真实傅里叶特征向量和预测傅里叶特征向量。如果像素
i
i
i属于对应的文本中心区域,那么
w
i
=
1
w_{i}=1
wi=1,否则
w
i
=
0.5
w_{i}=0.5
wi=0.5。
N
′
N^{'}
N′表示在文本轮廓上采样点数。如果
N
′
N^{'}
N′太小(
N
′
<
30
N^{'}<30
N′<30),将造成过拟合。因此,论文实验中设置
N
′
=
50
N^{'}=50
N′=50。
回归损失对于FCENet是非常重要的。在4.4章节的消融研究中,结果表明它分别对CTW1500和Total-Text数据集带来
6.9
%
6.9\%
6.9%和
9.3
%
9.3\%
9.3% h-mean提升。
(读完后的感觉就是,可能看源码会更清晰,捂脸啊)
4.实验(Experiments)
这部分,论文首先验证了FCE对文本实例建模的有效性通过和两个最近SOTA任意形状文本表示方法,比如
T
e
x
t
R
a
y
,
A
B
C
N
e
t
TextRay, ABCNet
TextRay,ABCNet。然后评估FCENet的文本检测能力。论文也对FCENet每一组件的有效性进行了消融研究,通过减少训练数据来验证模型的泛化能力。论文也和最近的SOTA方法在CTW1500和Total-Text数据集上做了大量的对比。因为这些对比数据集也包含大量非弯曲文本,论文构建了一个更有挑战性的子集,它包含高度弯曲或者高度非常规的文本。
之后的具体实验配置与实验结果这里就不细说了,大家感兴趣可以自行阅读论文,特别是对网络超参数配置这块,论文中都有细说,包括卷积核通道数,多尺度特征提取层缩放比例,使用的数据增强策略,论文使用的GPU配置,模型的优化策略等。
这里就简单粘贴下论文实验结果:






总结
说实话,读完这篇论文也就了解了大体概念,至于为什么这样做就能提高文本检测的性能,至今还是不理解,还有就是论文中对FCE的介绍也不是很全面,后面还是看源码可能会有更深的理解,也可能是个人能力太菜,无法理解,上文如有失误,欢迎指正,谢谢大家!