Python界的网红机器学习,这股浪潮已经逐渐成为热点,而Python是机器学习方向的头牌语言,用机器学习来玩一些好玩的项目一定很有意思。比如根据你的职业,婚姻,家庭,教育时间等等来预测你的收入,这么神奇!不信的话,一起跟我往下看。

1.数据集
收入问题一直是大家比较关心的热点,在kaggle比赛中,也出现过此类的数据集,因此,本次小实战的数据集就是来源于kaggle比赛的数据集,数据集长得样子如下:
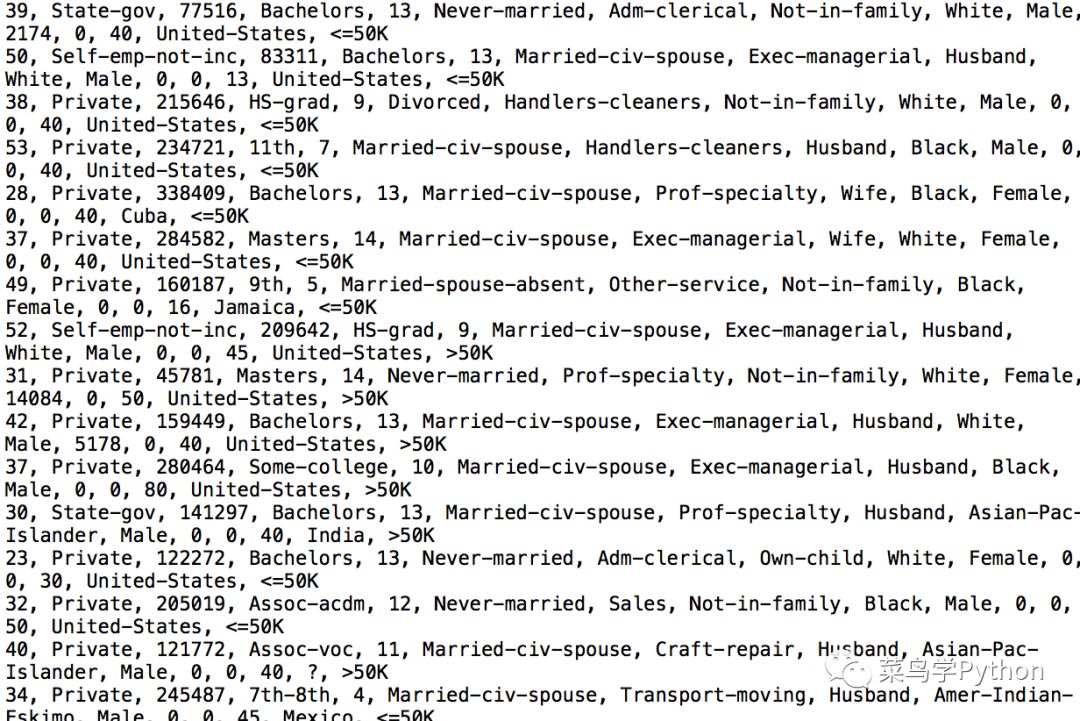
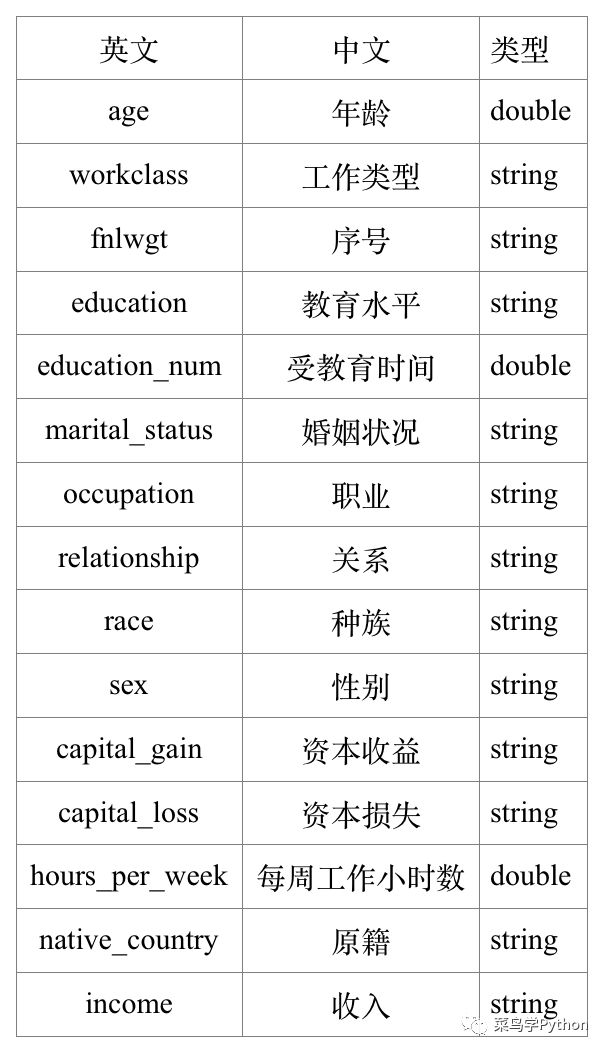
上面密密麻麻一堆记录了几万人的收入数据,每个人的收入数据其实就是下面这些特征值,比如你的年龄,工作类型啊,婚否,教育水平啊,时间啊,职业等等,详细如下:
1).导入数据集
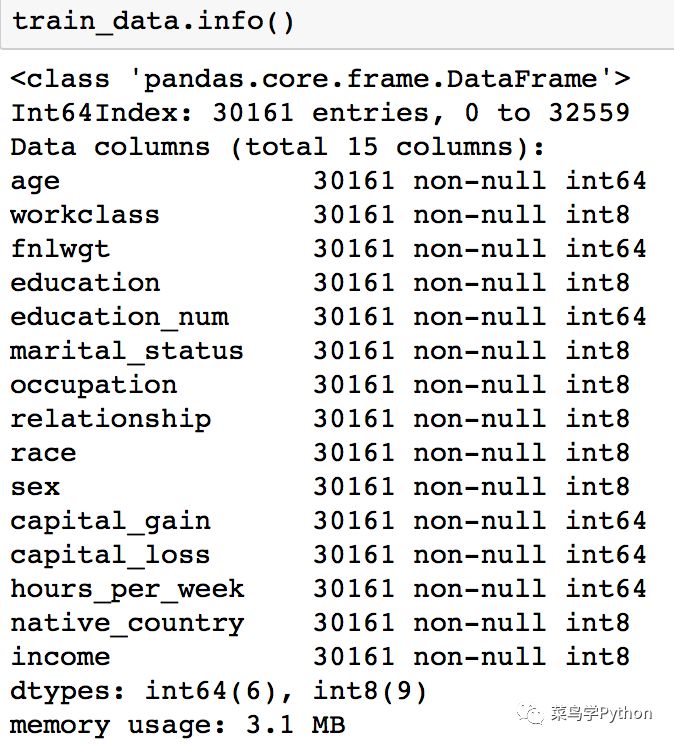
我们将训练集和测试集加入列标签,然后查看训练集的信息,如下图所示:
2.数据清洗
2).去掉缺失值
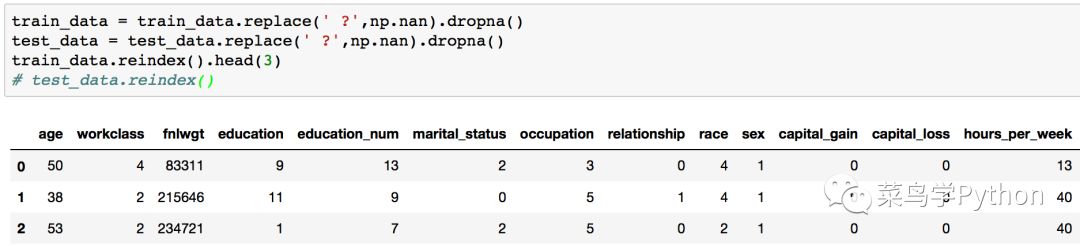
数据集中存在缺失值,并且以‘ ?’形式来代替,所以我们要对这样的数据进行剔除。并将剔除后的数据集进行重新排序,如下图所示:
3).数值处理
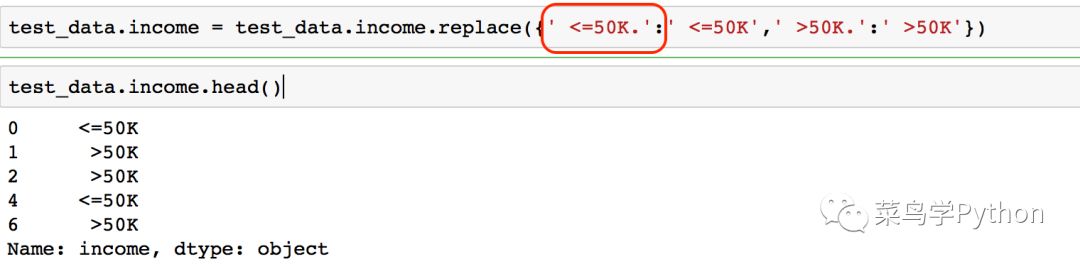
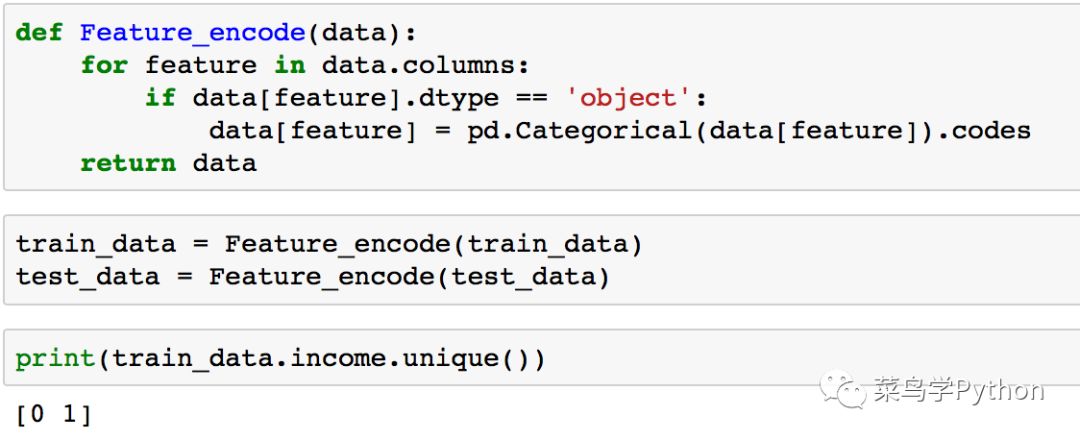
转化完成后,原先数据集中的字符串便被数字所代替,例如‘income’中的数据,原先是’<=50K’和’>50K’。现在分别对应为0和1。其他的列也是同样的改变方式。也就是说最后我们预测收入如果为0,表示收入小于50k。
到目前为止,数据清洗的工作基本上完成,下面,我们通过pandas库中的交叉表函数(crosstab)来观察‘受教育时间’和收入之间的关系:
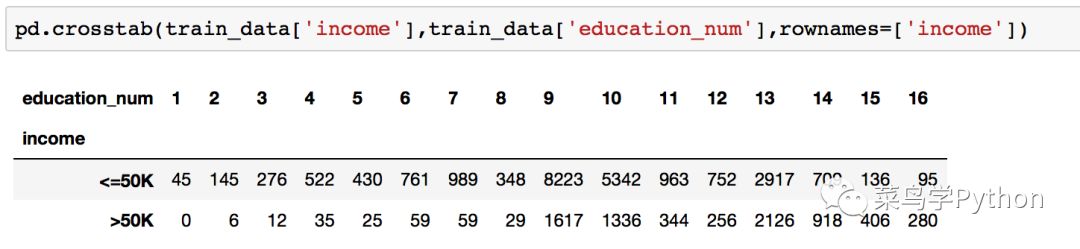
其中‘income’下的1代表收入大于50K,由上图可以看出,当受教育时间小于8年时,收入大于50K的人数可谓是寥寥无几,所以说从统计概率的角度上讲,九年义务教育,对大家的收入还是很有帮助的。
3.用决策树来构建模型
什么是决策树,看下面这个形象的比如,就一清二楚了。

社区大妈经验丰富,有一套自己的判断逻辑。假设“抽烟”、“染发”和“讲脏话”是社区大妈认为的区分“好坏”学生的三项关键特征,那么这样一个有先后次序的判断逻辑就构成一个决策树模型。在决策树中,最能区分类别的特征将作为最先判断的条件,然后依次向下判断各个次优特征。决策树的核心就在于如何选取每个节点的最优判断条件,也即特征选择的过程。
而在每一个判断节点,决策树都会遵循一套IF-THEN的规则:
IF “抽烟” THEN -> “坏学生”
ELSE
IF “染发” THEN -> “坏学生”
ELSE IF “讲脏话” THEN -> “坏学生”
ELSE -> “好学生”
通过sklearn库提供的决策树算法,可以很方便的进行分类:
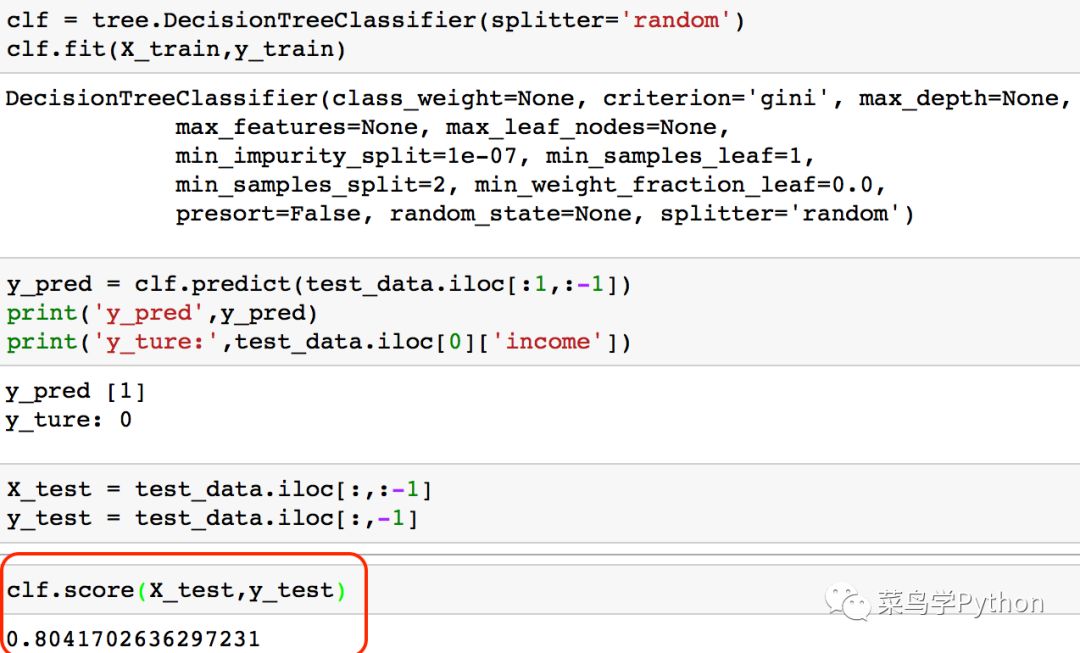
首先是建立一个clf的决策树分类器
然后将我们的训练数据导入fit函数,这里我们用到数据集中所有的特征值,因为数据集中的特征值只有14维,并不是很高的特征维度,因此,并不需要进行降维处理。
接着将数据导入训练决策树算法,训练完成后再我们的测试集上进行测试,
最后训练结果显示,准确率在80%左右,效果还是很不错的。
4.预测你的收入
看到这里小白是不是有点晕,这个模型到底靠不靠谱,我们用更直观的收入的例子来试试就知道啦:
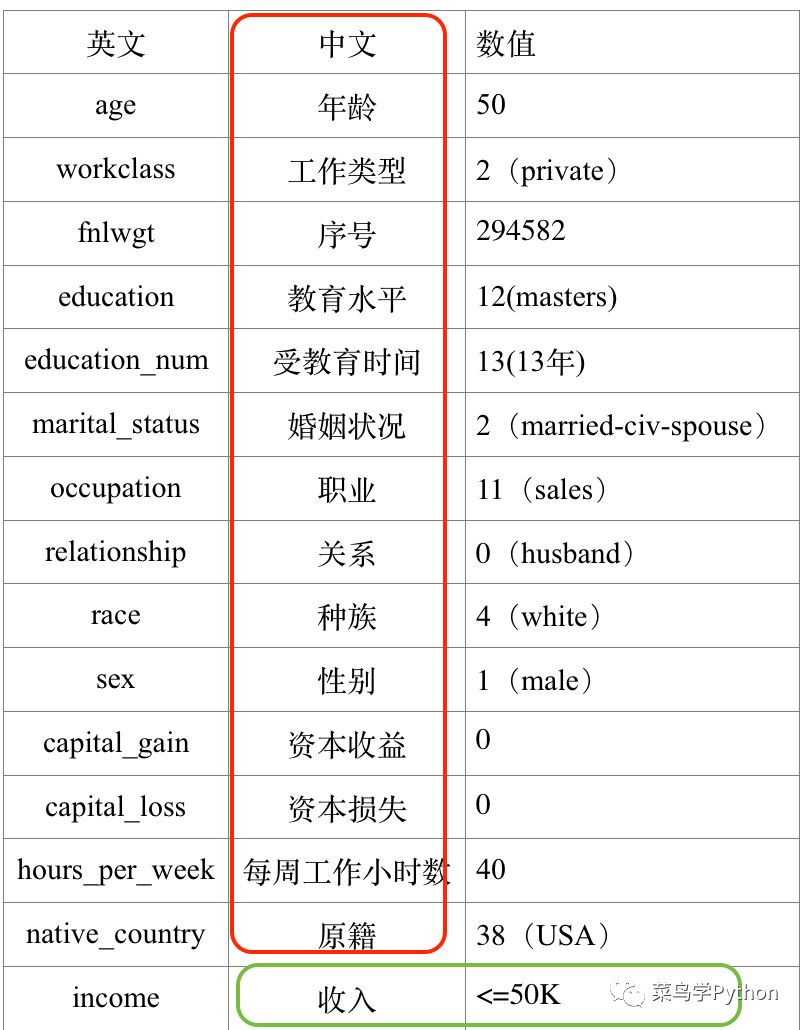
上面的这个人有一堆参数,如果我们输入模型里面,通过模型来预测一些它的收入到底是多少呢,是不是真的是小于50K:
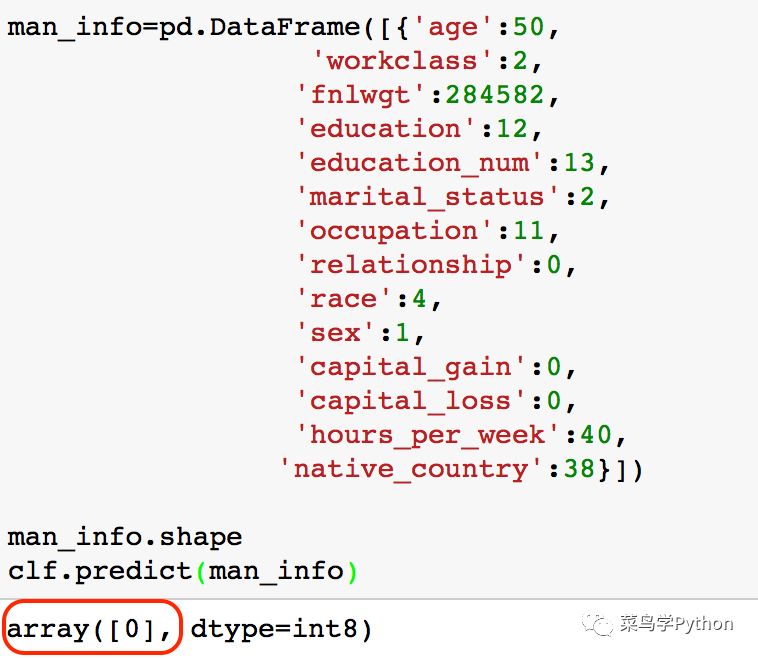
这里的array[0]表示最后的预测收入是小于50k的,而实际上这组数据的收入也确实如此!懂点机器学习还是很有用的,尤其是喂了大量的数据之后,当然我们还可以通过网格来寻找最佳参数,有兴趣的同学可以动手试试!
本公众号回复【收入】即可获得源码

日常推荐
终于有人把云计算、大数据和人工智能讲明白了!
今日问题
什么是系统调用?它和库函数调用有什么区别?
打卡格式:打卡第n天,答:xxx
