8.1 CUDA Stream
前面的章节只介绍了核函数在GPU内部的执行流程,忽略了CPU与GPU之间的交互过程。可以看出,CPU与GPU之间的交互涉及两个操作:数据传输和核函数执行。CPU将任务添加到不同的队列中,GPU驱动程序则负责执行队列中的任务。这两个任务是相互独立的,可以并发运行,即GPU在执行核函数时,可以同时进行CPU与GPU之间的数据传输,这就是所谓的计算与传输重叠(overlap)。
在程序中实现计算与传输重叠功能,需要使用CUDA流(stream)。流可以理解为一系列异步的GPU指令队列,这些操作按照主机代码确定的顺序在GPU上执行。流内各个指令的执行顺序是严格固定的,多个流之间则是可以异步/并行的(下图:CUDA 流)。
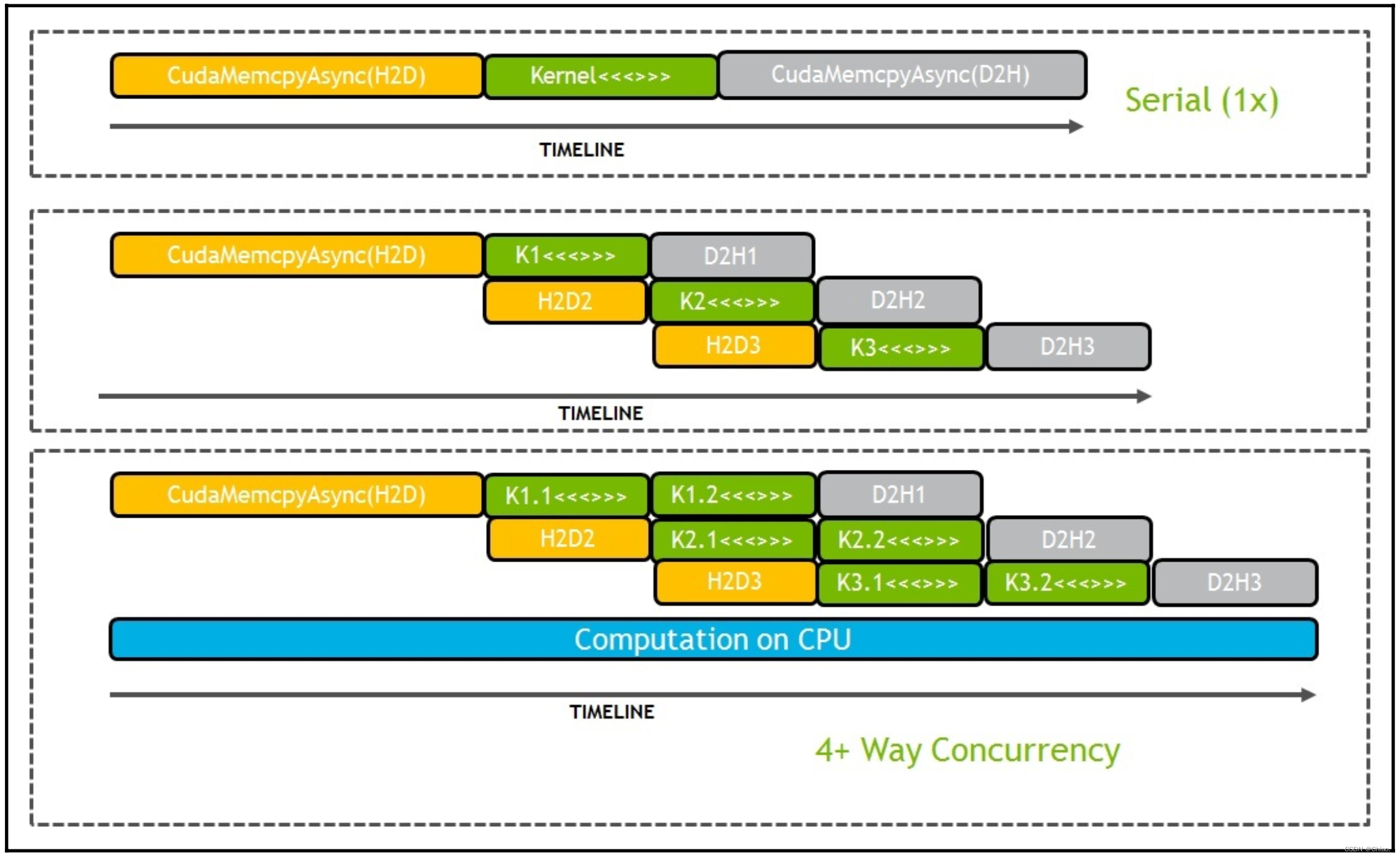
抽象出CUDA流这一概念在加速应用程序方面起到重要作用,它提供了一种更高的并行层级。以前提到的并行层级从细到粗:Thread、Thread Block、Grid,它们都是在Kernel Launch当中发生的,而Kernel Launch加上数据传输现在还可以打包到CUDA 流当中,再加上了一个粗粒度的并行层级。
CUDA流除了提供了一种更高层级的并行方式,更多情况下,我们使用CUDA 流是为了隐藏其中的一些开销。例如,流1在执行数据拷贝操作时,数据传输引擎的带宽是占满了,但是流2正在执行的Kernel引擎却并不受到影响。如果没有流的概念,流2的kernel只能等流1数据拷贝结束之后才能进行(上图)。
CUDA流还可以分为两类:
- 非空流(NULL Stream):隐式定义(implicitly declared)的流。之前在没有介绍CUDA 流时,我们程序中实际上都是存在一个这样的非空流的。
- 空流(non-NULL Stream):显式定义(explicitly declared)的流。
总结
基于流的异步内核启动(Kernel Launch)和数据传输支持以下类型的粗粒度并发:
- 重叠主机和设备计算;
- 重叠主机计算和设备数据传输;
- 重叠主机设备数据传输和设备计算;
- 并发设备计算(多个设备)
当然也有不支持并发的情况:
- 主机上page-locked内存的分配;
- 设备内存的分配;
- 设备内存的设置(
Memeset());
- 同一个设备上内存的复制;
流的创建与销毁
特别注意,内存的复制使用下面的异步函数:
cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count, cudaMemcpyKind kind, cudaStream_t stream=0)
使用这个API才可以在最后的参数里面指定CUDA 流。
以及Kernel Launch函数的执行配置当中也是可以指定CUDA流的:
kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list);
// 创建流
cudaStream_t stream_0, stream_1;
CHECK(cudaStreamCreate(&stream_0));
CHECK(cudaStreamCreate(&stream_1));
...
// 数据转移
CHECK(cudaMemcpyAsync(d_a_0, h_a+i, sizeof(int) * N, cudaMemcpyHostToDevice, stream_0));
...
// 流的同步,保证流执行完毕。以前都是使用|\textsf{cudaDeviceSynchronize()}|来进行同步的,而流的层级明显高于Device。
CHECK(cudaStreamSynchronize(stream_0));
...
// 流销毁
CHECK( cudaStreamDestroy( stream_0 ) );
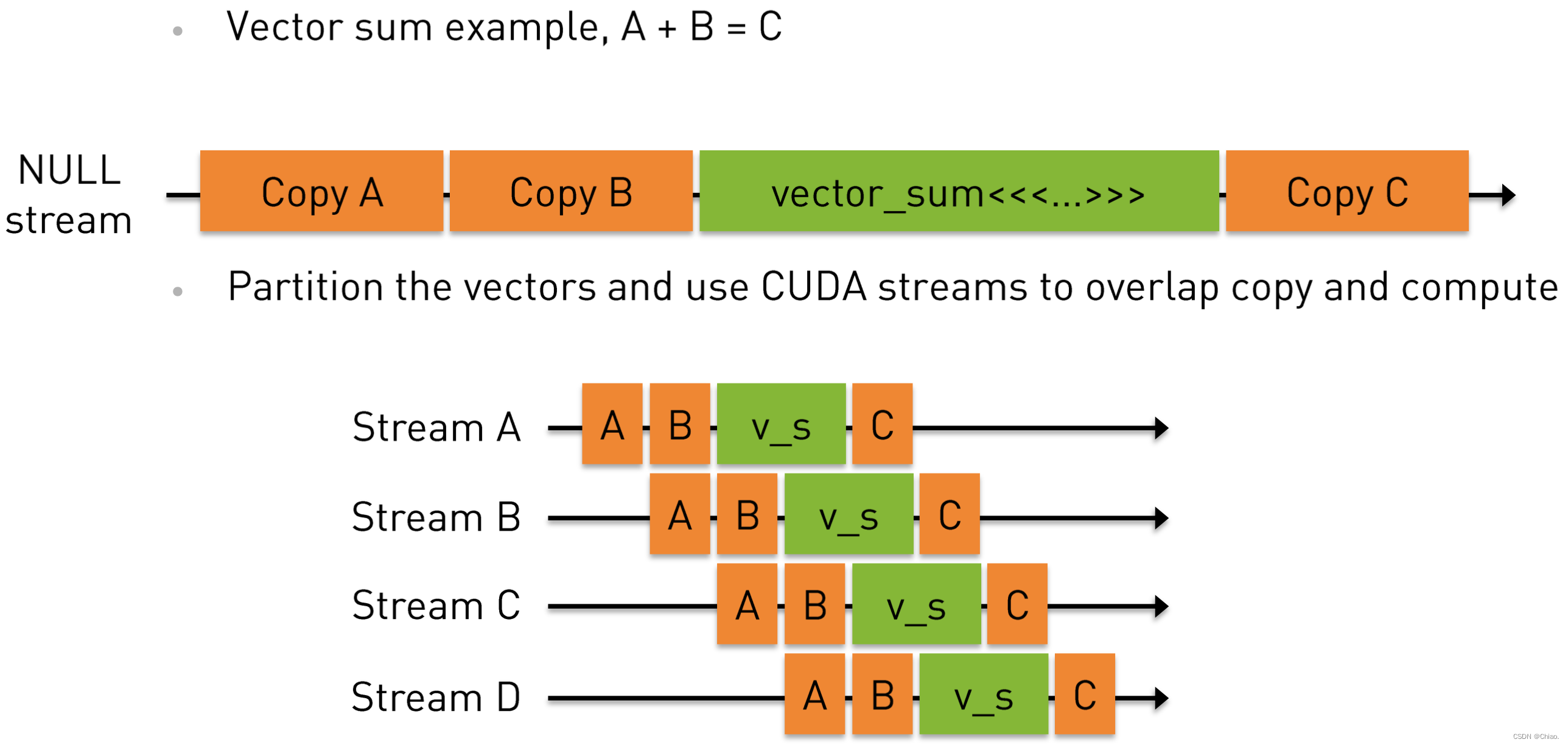
CUDA 流加速程序运行:以向量加法为例
for (int i = 0; i < nstreams; i++){
int offset = i * eles_per_stream;
cudaMemcpyAsync(&d_A[offset], &h_A[offset], eles_per_stream * sizeof(int), cudaMemcpyHostToDevice, streams[i]);
cudaMemcpyAsync(&d_B[offset], &h_B[offset], eles_per_stream * sizeof(int), cudaMemcpyHostToDevice, streams[i]);
|$\ldots$|
vector_sum<<<|$\ldots$|, streams[i]>>>(d_A + offset, d_B + offset, d_C + offset);
cudaMemcpyAsync(&h_C[offset], &d_C[offset], eles_per_stream * sizeof(int), cudaMemcpyDeviceToHost, streams[i]);
}
for (int i = 0; i < nstreams; i++)
cudaStreamSynchronize(streams[i]); // 一定要记得同步!
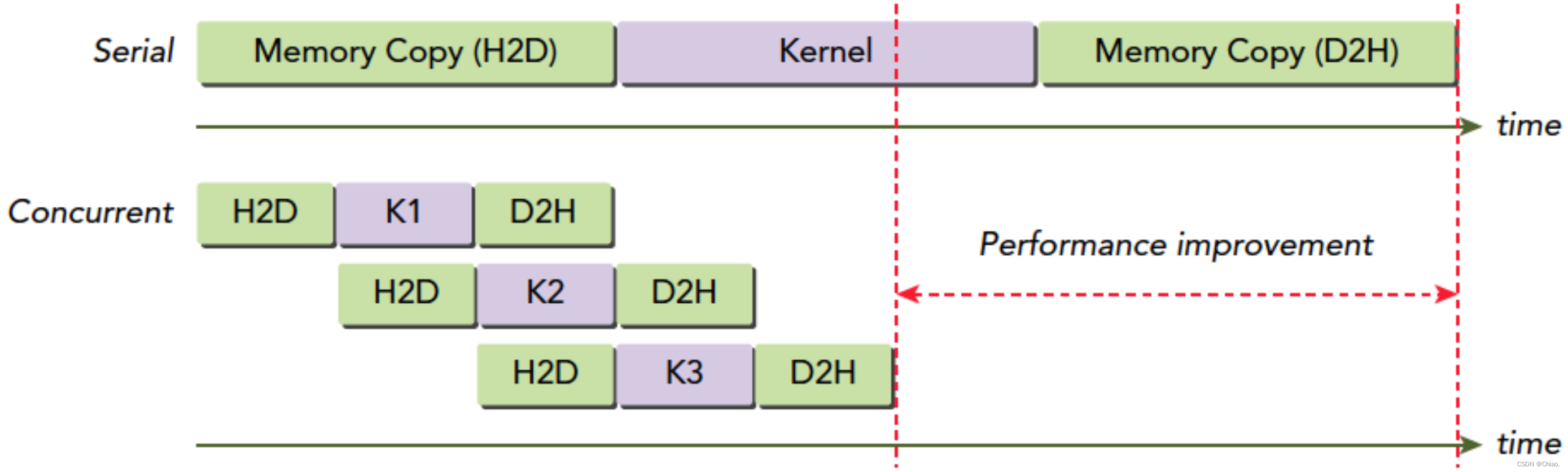
当for循环结束时,队列中应当包含了许多等待GPU执行的工作。如果想确保GPU执行完了计算与内存复制等操作,那么就需要等GPU与主机同步。也就是说,主机在继续执行之前,需要首先等待GPU执行完成cudaStreamSynchronize()。
同时调度某个流的所有操作可能无意中阻塞另一个流的复制操作或者核函数的执行操作。解决方案是:在将操作放入流的队列时采用宽度优先的方式而非深度优先的方式。
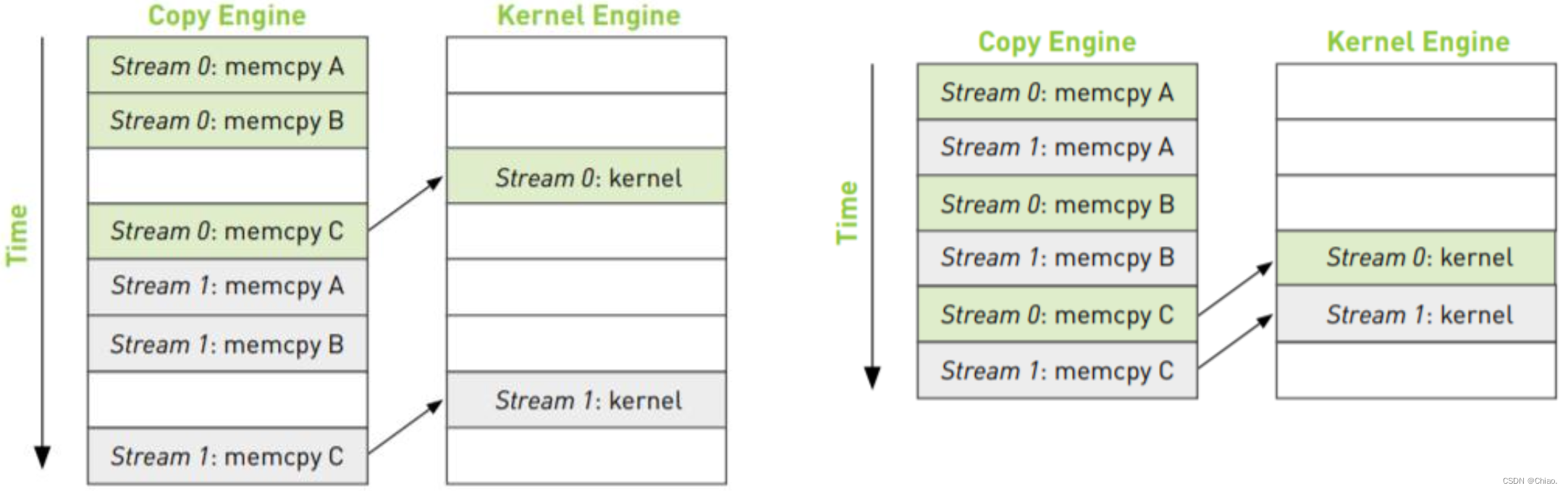
如果数据传输量特别小,kernel里计算的时间特别少,那么CUDA流加速的效果不明显。具体申请多少个CUDA 流最合适这都是依据实时硬件资源而说不准的,但申请太多会是得不偿失的。
8.2 CUDA Libraries
CUDA自2007年问世到现在,已经拥有100多个库了,之前我们手动实现的一些方法,例如矩阵乘法等,实际上都已经有库为我们准备好相应的API了。NVIDIA提供这么多库的目的就是为了让开发者更好地使用GPU。
CUDA库和CPU编程所用到的库没有什么区别,都是一系列接口的集合,主要好处是,只需要编写host代码,调用相应API即可,可以节约很多开发时间,而且我们完全可以信任这些库能够达到很好的性能。当然,完全依赖于这些库而对CUDA性能优化一无所知也是不行的,我们依然需要手动做一些改进来挖掘出更好的性能。
目前CUDA库主要由以下六个部分组成:
- Math Libraries
- Image and Video Libraries
- Deep Learning
- Parallel Algorithms
- Communication Libraries
- Partner Libraries(OpenCV、FFmpeg…)
8.2.1 A Common Library Workflow
下面是一个使用CUDA库的具体步骤,当然,各个库的使用可能不尽相同,但是不会逃脱下面的几个步骤,差异基本上就是少了哪几步而已。
- 创建一个库的句柄来管理上下文信息;
- 数据准备:
- 分配device存储空间给输入输出;
- 如果输入的格式并不是库中API支持的需要做一下转换:例如精度对齐、数组是行主序还是列主序、是否有特殊的结构体。
- 填充device Memory数据:类似cudaMemcpy的初始化函数,大部分库都有自己的API来实现这个功能,例如当使用cuBLAS的时候,我们要将一个vector传送到device,使用的就是
cubalsSetVector()。
- 配置执行:
- 配置library computation以便执行:通过Handle配置计算参数。
- 调用库函数来让GPU工作;
- 后处理:
- 取回device Memory中的结果:这一步将计算结果从device送回host,是上面填充device Memory数据的反过程。
- 如果取回的结果不是APP的原始格式,就做一次转换:是上面如果输入的格式并不是库中API支持的需要做一下转换的反过程。
- 释放CUDA资源;
- 继续其它的工作。
其中,关于一个库的句柄Handle,其包含了该库的一些上下文信息,比如数据格式、device的使用等。我们可以认为这是一个存放在host对程序员透明的描述性文件object,这个object包含了跟这个库相关联的一些信息。例如,我们可定希望所有的库的操作运行在一个特别的CUDA stream,尽管不同的库使用不同函数名字,但是大多数都会规定所有的库操作以一定的stream发生(比如cuSPARSE使用cusparseSetSStream、cuBLAS使用cublasSetStream、cuFFT使用cufftSetStream)。stream的信息就会保存在这个handle中。
8.2.2 cuBLAS库
cuBLAS库是基于NVIDIA CUDA运行时的BLAS(Basic Linear Algebra Subprograms)实现。cuBLAS level1是专门的vector之间操作。level2是矩阵和向量之间的操作。level3是矩阵和矩阵之间的操作。相对于cuSPARSE,cuBLAS不支持稀疏矩阵数据格式,它只支持而且善于稠密矩阵和向量的使用。
以下是使用cuBLAS库实现矩阵乘法的代码:
#include <cstdio>
#include "../matmul/error.cuh"
#include |\colorbox{OrangeRed!40}{<cublas\_v2.h>}|
void print_matrix(int R, int C, double* A, const char* name)
{
printf("%s = \n", name);
for (int r = 0; r < R; ++r)
{
for (int c = 0; c < C; ++c)
{
printf("%10.6f", A[c * R + r]);
}
printf("\n");
}
}
int main(void){
int m = 2, n = 2, k = 3;
int mn = m * n, mk = m * k, nk = n * k;
double *h_a, *h_b, *h_c;
CHECK(cudaHostAlloc((void **)&h_a, sizeof(double)*mn, cudaHostAllocDefault)); // 用cudaHostAlloc会出错
CHECK(cudaHostAlloc((void **)&h_b, sizeof(double)*nk, cudaHostAllocDefault));
CHECK(cudaHostAlloc((void **)&h_c, sizeof(double)*mk, cudaHostAllocDefault));
for(int i=0; i<mn; i++){
h_a[i] = i;
}
print_matrix(m, n, h_a, "A");
for(int i=0; i<nk; i++){
h_b[i] = i;
}
print_matrix(n, k, h_b, "B");
for(int i=0; i<mk; i++){
h_c[i] = 0;
}
double *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **)&d_a, sizeof(double)*mn));
CHECK(cudaMalloc((void **)&d_b, sizeof(double)*nk));
CHECK(cudaMalloc((void **)&d_c, sizeof(double)*mk));
|\colorbox{OrangeRed!40}{cublasSetVector}|(mn, sizeof(double), h_a, 1, d_a, 1);
|\colorbox{OrangeRed!40}{cublasSetVector}|(nk, sizeof(double), h_b, 1, d_b, 1);
|\colorbox{OrangeRed!40}{cublasSetVector}|(mk, sizeof(double), h_c, 1, d_c, 1);
|\colorbox{OrangeRed!40}{cublasHandle\_t}| handle;
|\colorbox{OrangeRed!40}{cublasCreate}|(&handle);
double alpha = 1.0;
double beta = 0.0;
|\colorbox{OrangeRed!40}{cublasDgemm}|(handle, CUBLAS_OP_N, CUBLAS_OP_N,
m, k, n, &alpha, d_a, m, d_b, n, &beta, d_c, m);
|\colorbox{OrangeRed!40}{cublasDestroy}|(handle);
|\colorbox{OrangeRed!40}{cublasGetVector}|(mk, sizeof(double), d_c, 1, h_c, 1);
print_matrix(m, k, h_c, "C = A x B");
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_c));
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
return 0;
}
8.2.3 CV-CUDA
在以往的视觉模型开发与应用中,我们往往更重视模型本身的优化,提升其速度与效果。相反,却忽视了图像的预处理与后处理阶段的优化,当模型计算效率越来越高时,它们最终可能会变成整个图像任务的瓶颈。
为了解决这样的瓶颈,NVIDIA和字节跳动机器学习团队开源了包含众多图像预处理算子库CV_CUDA,它能够运行在GPU上,算子速度能够达到OpenCV在CPU上运行速度的百倍左右。如果使用CV-CUDA作为后端替换OpenCV和TorchVision,整个推理的吞吐量能达到原来的二十多倍。此外,不仅仅是速度的提升,在效果上CV-CUDA的计算精度上已经对齐OpenCV,因此训练推理能无缝衔接。
为什么OpenCV仍然不够好?Torchvision呢?
在CV领域,应用最广泛的图像处理库当然是长久维护的OpenCV了,其广泛的图像处理操作能基本满足视觉任务的预/后处理。但是随着图像任务负载的加大,其速度已经逐渐跟不上,因为OpenCV绝大多数图像操作都是CPU实现,缺少GPU实现。同时,少数有GPU实现的算子仍存在以下三大问题:
- 部分算子的CPU和GPU计算结果精度无法对齐;
- 部分算子GPU性能比CPU还弱;
- 处理流程中既包含CPU算子,也包含GPU算子,这会额外增加内存与显存中的空间申请与数据迁移/数据拷贝。
Torchvision面临和OpenCV一样的问题,除此之外,工程师部署模型为了效率更可能使用C++实现推理过程,因此将没办法使用Torchvision而需要转向OpenCV这样的C++视觉库。
8.2.4 cuDNN库
NVIDIA CUDA® 深度神经网络库 (cuDNN) 是一个 GPU 加速的深度神经网络基元库,能够以高度优化的方式实现标准例程(如前向和反向卷积、池化层、归一化和激活层)。
全球的深度学习研究人员和框架开发者都依赖 cuDNN 来实现高性能 GPU 加速。借助 cuDNN,研究人员和开发者可以专注于训练神经网络及开发软件应用,而不必花时间进行低层级的 GPU 性能调整。cuDNN 可加速广泛应用的深度学习框架,包括 Caffe2、Chainer、Keras、MATLAB、MxNet、PaddlePaddle、PyTorch 和 TensorFlow。
主要特性:
- 为各种常用卷积实现了 Tensor Core 加速,包括 2D 卷积、3D 卷积、分组卷积、深度可分离卷积以及包含 NHWC 和 NCHW 输入及输出的扩张卷积;
- 为诸多计算机视觉和语音模型优化了内核,包括 ResNet、ResNext、EfficientNet、EfficientDet、SSD、MaskRCNN、Unet、VNet、BERT、GPT-2、Tacotron2 和 WaveGlow;
- 支持 FP32、FP16、BF16 和 TF32 浮点格式以及 INT8 和 UINT8 整数格式;
) 4D 张量的任意维排序、跨步和子区域意味着可轻松集成到任意神经网络实现中;
- 能为各种 CNN 体系架构上的融合运算提速。
8.3 结束语
- CUDA编程模型依赖于GPU硬件环境,不同的硬件设备,需要不同的加速手段;
- 在真正的开发过程中,其实有大量的现成的工具,希望大家能够处理一些通用问题的时候,使用现成的工具库;
- 进阶之路既有高处,也有细节。关注最新的动态,能让我们更快的掌握更好的解决问题的手段。