CLIP:Learning Transferable Visual Models From Natural Language Supervision
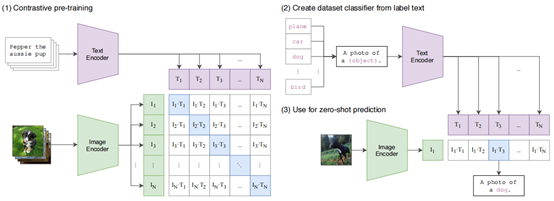
OpenAI的CLIP这篇文章,从互联网收集构建了了4亿个图片-文本对的数据集,对图像和文本通过编码器提取的Embedding使用对比学习方式训练,得到对齐的图像&文本Embedding,并用在Zero-shot学习任务中。训练好的模型开源在:https://github.com/openai/CLIP
论文分享了作者一些观点:
1、不采用图像生成文本的方式,是因为生成方法计算量大,运算速度慢,作者做过生成的尝试,需要大一个数量级的计算量才能和对比法得到相似的效果。
2、从头训练,不适用任何预训练好的图像、语言模型。在数据规模足够大的情况下,使用ViT(Vision Transformer)效果优于ResNet、EfficientNet这些CNN网络,并且计算量更小,训练速度更快。
3、训练时直接对一个batch中的图像、文本embedding计算余弦距离作为logits,使用交叉熵损失。推理时,将预先设置的一些类别的自然语言描述加入提示模板中,例如“这是一张{XXX}的照片”,生成对应的文本Embedding,通过余弦距离做分类。另外作者发现,描述文字越具体,推理分类效果越好,比如“这是一张{XXX}的照片,是一类宠物”,或“这是一只大型{XXX}的照片”。
4、CLIP Zero-shot效果在ImageNet图像分类任务上,甚至超过了全监督训练的同等规模的ResNet、EfficientNet。使用CLIP方法进行Zero-shot推理,在27个不同数据集上进行分类任务,其中16个效果优于在ResNet50做监督训练。作者通过27个数据集的错误分析发现,CLIP方法对以名词为中心的目标分类效果特别好,效果较差的是一些复杂、抽象的图像,例如卫星拍摄图像、淋巴结肿瘤图像、识别最近距离的车等等。作者也分析了,似乎人类更擅从One-shot学习中获得知识。
5、作者对比了在CLIP模型上使用Zero-shot和Few-shot的效果,Zero-shot是直接采用自然语言描述,而Few-shot是每个类别给出一些例子图片,当Few-shot每类样本达到5以上时,才能达到与Zero-shot相同的精度。
6、使用CLIP得到的图像特征训练线形分类器,效果在27中的21个数据集上都好于SOTA的EfficientNet L2 NS模型。
7、作者提到CLIP的局限性,是只能从给定类别中选择,无法像图像描述生成任务那样输出一个类别。