前言
大家前面学过Python基础知识的都知道,Python为我们封装了列表、字典等高级数据类型,并且他们都带有一系列增、删、改、除的方法,让我们能够很方便的处理一些问题。以目前我们这些人的技术水平可能觉得这些东西就够了,照样能够快速的解决很多的问题。可是随着知识的深入,随着问题不断地变难,很多时候我们去用列表、字典这些高级数据类型来解决问题得话可能显得有点力不从心。世界上没有无用的知识,也没有无用的的人!其实你通过深入的学习之后会发现,数据结构这门课程是独立于语言之外的,管他是用什么语言实现,里面的道道都是一样的,至于用Python这门语言来实现的话,他是否会简单一些,这还有待我们深入的去学习和了解。
Python内置数据类型性能分析
下面我们将结合Python中的timeit模块来深入的分析一下,Python中内置的列表、字典等数据类型的性能,对此你可能会对数据结构的深入学习有更强的期待。
timeit模块
timeit模块可以用来测试一小段Python代码的执行速度。
Python中timeit模块定义了接受两个参数的Timer类。两个参数都是字符串,第一个参数是你要计时的语句或者函数,第二个参数是为第一个参数构建环境的导入语句,也就是第一个参数所在的地方,一般是import语句“from __ main __ inport …”。
class timeit.Timer(stmt='pass', setup='pass', timer=<timer function>)
总结来说:
Timer是测量小段代码执行速度的类。
stmt参数是要测试的代码语句(statment);
setup参数是运行代码时需要的设置;
timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000)
Timer类中测试语句执行速度的对象方法。number参数是测试代码时的测试次数,默认为100万次。方法返回执行代码的平均耗时,一个浮点类型的秒数。
列表内置方法性能分析
下面使用timeit模块中的Timer类来试验一下列表中的各种方法类型的运行时间,找出时间复杂度最低的方法:
from timeit import Timer
def t1():
li = []
for i in range(10000):
li.append(i)
def t2():
li = []
for i in range(10000):
li = li + [i]
# li += [i]
def t3():
li = [i for i in range(10000)]
def t4():
li = list(range(10000))
def t5():
li = []
for i in range(10000):
li.extend([i])
def t7():
li = []
for i in range(10000):
li.insert(0, i)
timer1 = Timer("t1()", "from __main__ import t1")
print("append:", timer1.timeit(1000))
timer2 = Timer("t2()", "from __main__ import t2")
print("+:", timer2.timeit(1000))
timer3 = Timer("t3()", "from __main__ import t3")
print("[i for i in range]:", timer3.timeit(1000))
timer4 = Timer("t4()", "from __main__ import t4")
print("list(range()):", timer4.timeit(1000))
timer5 = Timer("t5()", "from __main__ import t5")
print("extend:", timer5.timeit(1000))
timer6 = Timer("t6()", "from __main__ import t6")
print("append", timer6.timeit(1000))
timer7 = Timer("t7()", "from __main__ import t7")
print("insert(0)", timer7.timeit(1000))
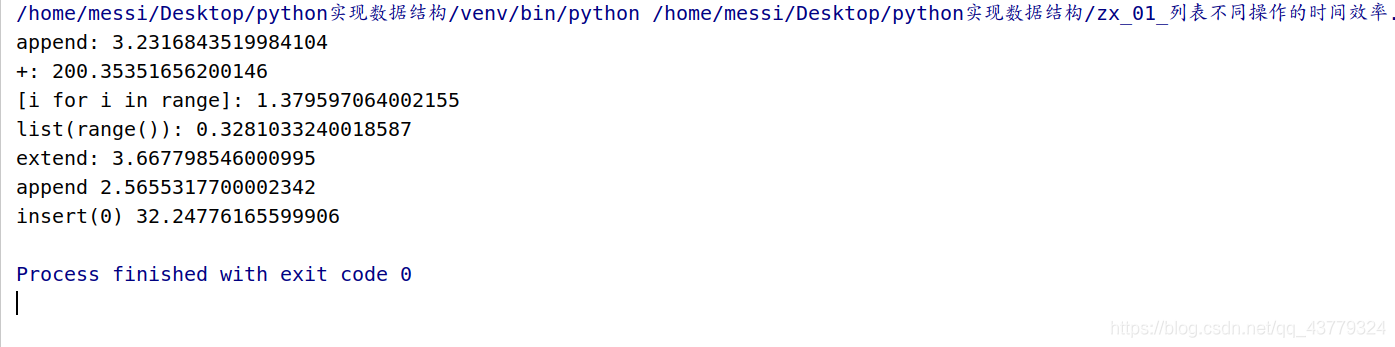
通过以上试验可以发现使用列表生成器的代码的时间复杂度是比较低的,其中+这个操作的时间复杂度较高,原因在于在做+操作时,每两个列表元素相加都会生成第三个列表来储存相加好了的列表元素,加一次就在内存中生成一个列表,如此下来会造成大量的内存得不到释放,严重占用内存空间,且每一步的操作都很费时。
列表内置操作的时间复杂度
列表内置操作的时间复杂度如下图所示:

字典内置操作时间复杂度
列表内置操作的时间复杂度如下图所示:

最后
某些代码和图片来源于我学习的资料。讲到这里或许大家还是不明白我们为什么要学数据结构,更高级的数据结构有什么好处等一系列问题。
我们为了解决问题,需要将数据保存下来,然后根据数据的存储方式来设计算法实现进行处理,那么数据的存储方式不同就会导致需要不同的算法进行处理。我们希望算法解决问题的效率越快越好,于是我们就需要考虑数据究竟如何保存的问题,这就是数据结构。
其实看到这里,列表字典本身就是一种数据结构,只不过是Python封装好了的,其他的高级数据结构类型则需要我们自己去实现,实现的过程就是我们对计算机知识更深入的了解!