哈夫曼压缩原理就是构建二叉树,出现频率高的字母用更少的位数来表示,实现压缩的效果
比如字符串abcbbc
构建哈夫曼树

这样构建出编码表b->0,a->10, c->11
原本6个字符要48位来表示,现在只需要9位来表示即可
1. 首先将文本文件的每一个字符进行统计,构建编码表,这个编码表大概50几k
void readTxt(string file,Character *cList)
{
ifstream infile;
infile.open(file.data()); //将文件流对象与文件连接起来
assert(infile.is_open()); //若失败,则输出错误消息,并终止程序运行
char c;
infile >> noskipws;
while (!infile.eof())
{
addList(c,cList);
infile>>c;
}
infile.close(); //关闭文件输入流
}
void addList(char c,Character *cList){
//为空就退出
if(!c) return;
totalNum++;
int i=0;
for(;i<cnumber;i++){
if(c==cList[i].data){
break;
}
}
cList[i].number++;
if(i==cnumber){
cList[cnumber].data = c;
cnumber++;
}
if(i>0 && cList[i].number>cList[i-1].number){
int num = cList[i].number;
char ch = cList[i].data;
cList[i].data = cList[i-1].data;
cList[i].number = cList[i-1].number;
cList[i-1].data = ch;
cList[i-1].number = num;
}
}
1. 根据huffman树原理,构建编码表(如下图所示),词频越高则用更小的编码表示
//换行符
string enterCode;
typedef struct node{
char ch; //存储该节点表示的字符,只有叶子节点用的到
int val; //记录该节点的权值
structnode *self,*left,*right; //三个指针,分别用于记录自己的地址,左孩子的地址和右孩子的地址
friend booloperator <(const node &a,constnode &b) //运算符重载,定义优先队列的比较结构
{
return a.val>b.val; //这里是权值小的优先出队列
}
}node;
int codeTablePlace = 0;
node *myroot;
priority_queue<node> p; //定义优先队列
char res[10000]; //用于记录哈夫曼编码
void dfs(node *root,int level,CodeTableItem *codetable,Character *cList) //哈夫曼编码表
{
if(root->left==root->right) //叶子节点的左孩子地址一定等于右孩子地址,且一定都为NULL;叶子节点记录有字符
{
if(level==0) //“AAAAA”这种只有一字符的情况
{
res[0]='0';
level++;
}
res[level]='\0'; //字符数组以'\0'结束
//printf("%c=>%s\n",root->ch,res);
//搜索在统计表中的位置
for(int j=0;j<cnumber;j++){
if(root->ch==cList[j].data){
codetable[j].data = root->ch;
codetable[j].code =res;
}
}
// codetable[codeTablePlace].data = root->ch;
// codetable[codeTablePlace].code = res;
if(int(root->ch)==10)
enterCode =res;
// codeTablePlace++;
}
else
{
res[level]='0'; //左分支为0
dfs(root->left,level+1,codetable,cList);
res[level]='1'; //右分支为1
dfs(root->right,level+1,codetable,cList);
}
}
void huffman(Character *hash,CodeTableItem *codeTable) //构建哈夫曼树
{
node *root,fir,sec;
for(int i=0;i<cnumber;i++)
{
root=(node *)malloc(sizeof(node)); //开辟节点
root->self=root; //记录自己的地址,方便父节点连接自己
root->left=root->right=NULL; //该节点是叶子节点,左右孩子地址均为NULL
root->ch=hash[i].data; //记录该节点表示的字符
root->val=hash[i].number; //记录该字符的权值
p.push(*root); //将该节点压入优先队列
}
//下面循环模拟建树过程,每次取出两个最小的节点合并后重新压入队列
//当队列中剩余节点数量为1时,哈夫曼树构建完成
while(p.size()>1)
{
fir=p.top();p.pop(); //取出最小的节点
sec=p.top();p.pop(); //取出次小的节点
root=(node *)malloc(sizeof(node)); //构建新节点,将其作为fir,sec的父节点
root->self=root; //记录自己的地址,方便该节点的父节点连接
root->left=fir.self; //记录左孩子节点地址
root->right=sec.self; //记录右孩子节点地址
root->val=fir.val+sec.val;//该节点权值为两孩子权值之和
p.push(*root); //将新节点压入队列
}
fir=p.top();p.pop(); //弹出哈夫曼树的根节点
myroot = fir.self;
dfs(fir.self,0,codeTable,CList); //输出叶子节点记录的字符和对应的哈夫曼编码
}
1. 接下来是压缩的关键部分,首先读入一行的字符,通过编码表将该行加密成01串。根据01串构造一个个字符,一个char型字符是1个字节,也就是8个01就可以通过移位和加一来构建一个char类型,然后将该字符写入文件。这里要注意的是一行最后要加上换行符号的编码,直接读取一行是不会读取到换行符的。其次是一行最后的一个字符一般是没有构建完的,这样就会在最后一个字符的ASCII码的二进制表示前面引入几个0,应该将该字符记录下来,在新的一行构建字符的时候将该字符补全。

/*加密文件*/
string tempstr="";
ofstream out;
//记录上一行尾部没有填充完的字符leftChar和还剩多少位填完leftBit;
char leftChar=0;
int leftBit=0;
void encodeLine(string line,string path,CodeTableItem *cTable){
if (line=="" ) {
return;
}
if (out.is_open())
{
//将一行文本加密成二进制字符串
string str= "";
for(int i=0;i<line.size();i++){
for(int j=0;j<cnumber;j++){
if(line[i]==cTable[j].data){
str+=cTable[j].code;
break;
}
}
}
//加上换行符
str+=enterCode;
int count = 0;
unsigned char c=leftChar;
//先把上一行字符填充完
for(int i=0;i<leftBit;i++){
c<<=1;
if(str[i]=='1'){
c = c + 1;
}
}
//cout<<str<<"-";
//tempstr+=c;
char ch1 = c;
out<<ch1;
//加密这一行剩下的
for(int i=leftBit;i<str.size();i++){
c<<=1;
count++;
if(str[i]=='1'){
c = c + 1;
}
// //一个字节存满,将改字节保存
if(count==8){
ch1 = c;
out<<ch1;
//tempstr+=c;
c = 0;
count=0;
}
}
//记录没有保存的字符
leftChar = c;
leftBit = 8-count;
out<<tempstr;
//cout<<"1";
}
}
void encodeHuffman(string file,string path,CodeTableItem *cTable){
//读取文件,一个个字符加密
ifstream infile;
infile.open(file.data()); //将文件流对象与文件连接起来
assert(infile.is_open()); //若失败,则输出错误消息,并终止程序运行
infile >> noskipws;
string line;
while (std::getline(infile, line)) {
encodeLine(line,path,cTable);
}
infile.close();
}
解密过程也很简单,就是加密的逆过程读取一个字符将其解密成01串,然后顺着01串遍历huffman树,如果是叶子节点就输出字符,并且回到根节点准备下一个字符的解密。
//解密
void decodeHuffman(string file){
node *p = myroot;
ifstream infile;
infile.open(file.data()); //将文件流对象与文件连接起来
assert(infile.is_open()); //若失败,则输出错误消息,并终止程序运行
unsigned char c;
infile >> noskipws;
int wordcount=0;
infile>>c;
while(!infile.eof())
{
infile>>c;
string str = "";
int beichushu = 128;
for(int i=0;i<8;i++){
int bit = (int)c/beichushu;
if(bit==1){
p = p->right;
str+= "1";
}
else{
str+= "0";
p = p->left;
}
if(p->left==NULL){
//cout<<p->ch;
out<<p->ch;
//当执行到最后一个字符就结束,不要继续输出后面多余字符
wordcount++;
if(wordcount==totalNum)
return;
p = myroot;
}
c <<= 1;
}
//cout<<str;
//cout<<wordcount;
}
infile.close(); //关闭文件输入流
}
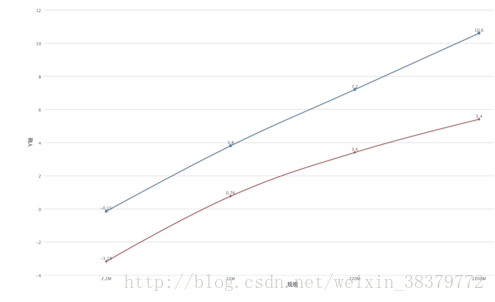
mac上只有zip,所以直接用命令行查看压缩时间。压缩cacm.all压缩时间

我的算法与zip的对比
| 规模 |
我的压缩时间 |
zip时间 |
我的压缩率 |
zip压缩率 |
| 2.2M |
0.9s |
0.11s |
63.6% |
31.8% |
| 22M |
14.3s |
1.7s |
65.3% |
35% |
| 220M |
148.6s |
10.8s |
65.5% |
32% |
| 2200M |
1522.1s |
63.2s |
65.7 |
30% |
将他们时间取对数后发现,我的代码几乎是线性递增的,我这个文件是有原来的cacm文件多次复制张贴而来,所以构成的哈夫曼树是一样的,压缩率也就差不多一样。而zip就比较神奇,也是预料之中,可能是它出现次数越多的字母的权重越大,是时间在逐渐减少,而且压缩率也降低。
完整代码
由于忙着赶作业写得有点乱,代码也没有美化和优化,现在闲下来反而不想弄了
#include <iostream>
#include <iostream>
#include <fstream>
#include <cassert>
#include <string>
#include <time.h>
#include<queue>
#include<stdlib.h>
#include<bitset>
using namespace std;
class Character
{
public:
char data;
int number;
Character(){
data = ' ';
number = 0;
}
};
class CodeTableItem{
public:
char data;
string code;
};
//字符统计表
Character CList[200];
int cnumber=0,totalNum =0;
void addList(char c,Character *cList){
//为空就退出
if(!c) return;
totalNum++;
int i=0;
for(;i<cnumber;i++){
if(c==cList[i].data){
break;
}
}
cList[i].number++;
if(i==cnumber){
cList[cnumber].data = c;
cnumber++;
}
if(i>0 && cList[i].number>cList[i-1].number){
int num = cList[i].number;
char ch = cList[i].data;
cList[i].data = cList[i-1].data;
cList[i].number = cList[i-1].number;
cList[i-1].data = ch;
cList[i-1].number = num;
}
}
void readTxt(string file,Character *cList)
{
ifstream infile;
infile.open(file.data()); //将文件流对象与文件连接起来
assert(infile.is_open()); //若失败,则输出错误消息,并终止程序运行
char c;
infile >> noskipws;
while (!infile.eof())
{
addList(c,cList);
infile>>c;
}
infile.close(); //关闭文件输入流
}
//换行符
string enterCode;
typedef struct node{
char ch; //存储该节点表示的字符,只有叶子节点用的到
int val; //记录该节点的权值
structnode *self,*left,*right; //三个指针,分别用于记录自己的地址,左孩子的地址和右孩子的地址
friend booloperator <(const node &a,constnode &b) //运算符重载,定义优先队列的比较结构
{
return a.val>b.val; //这里是权值小的优先出队列
}
}node;
int codeTablePlace = 0;
node *myroot;
priority_queue<node> p; //定义优先队列
char res[10000]; //用于记录哈夫曼编码
void dfs(node *root,int level,CodeTableItem *codetable,Character *cList) //哈夫曼编码表
{
if(root->left==root->right) //叶子节点的左孩子地址一定等于右孩子地址,且一定都为NULL;叶子节点记录有字符
{
if(level==0) //“AAAAA”这种只有一字符的情况
{
res[0]='0';
level++;
}
res[level]='\0'; //字符数组以'\0'结束
//printf("%c=>%s\n",root->ch,res);
//搜索在统计表中的位置
for(int j=0;j<cnumber;j++){
if(root->ch==cList[j].data){
codetable[j].data = root->ch;
codetable[j].code =res;
}
}
// codetable[codeTablePlace].data = root->ch;
// codetable[codeTablePlace].code = res;
if(int(root->ch)==10)
enterCode =res;
// codeTablePlace++;
}
else
{
res[level]='0'; //左分支为0
dfs(root->left,level+1,codetable,cList);
res[level]='1'; //右分支为1
dfs(root->right,level+1,codetable,cList);
}
}
void huffman(Character *hash,CodeTableItem *codeTable) //构建哈夫曼树
{
node *root,fir,sec;
for(int i=0;i<cnumber;i++)
{
root=(node *)malloc(sizeof(node)); //开辟节点
root->self=root; //记录自己的地址,方便父节点连接自己
root->left=root->right=NULL; //该节点是叶子节点,左右孩子地址均为NULL
root->ch=hash[i].data; //记录该节点表示的字符
root->val=hash[i].number; //记录该字符的权值
p.push(*root); //将该节点压入优先队列
}
//下面循环模拟建树过程,每次取出两个最小的节点合并后重新压入队列
//当队列中剩余节点数量为1时,哈夫曼树构建完成
while(p.size()>1)
{
fir=p.top();p.pop(); //取出最小的节点
sec=p.top();p.pop(); //取出次小的节点
root=(node *)malloc(sizeof(node)); //构建新节点,将其作为fir,sec的父节点
root->self=root; //记录自己的地址,方便该节点的父节点连接
root->left=fir.self; //记录左孩子节点地址
root->right=sec.self; //记录右孩子节点地址
root->val=fir.val+sec.val;//该节点权值为两孩子权值之和
p.push(*root); //将新节点压入队列
}
fir=p.top();p.pop(); //弹出哈夫曼树的根节点
myroot = fir.self;
dfs(fir.self,0,codeTable,CList); //输出叶子节点记录的字符和对应的哈夫曼编码
}
/*加密文件*/
string tempstr="";
ofstream out;
//记录上一行尾部没有填充完的字符leftChar和还剩多少位填完leftBit;
char leftChar=0;
int leftBit=0;
void encodeLine(string line,string path,CodeTableItem *cTable){
if (line=="" ) {
return;
}
if (out.is_open())
{
//将一行文本加密成二进制字符串
string str= "";
for(int i=0;i<line.size();i++){
for(int j=0;j<cnumber;j++){
if(line[i]==cTable[j].data){
str+=cTable[j].code;
break;
}
}
}
//加上换行符
str+=enterCode;
int count = 0;
unsigned char c=leftChar;
//先把上一行字符填充完
for(int i=0;i<leftBit;i++){
c<<=1;
if(str[i]=='1'){
c = c + 1;
}
}
//cout<<str<<"-";
//tempstr+=c;
char ch1 = c;
out<<ch1;
//加密这一行剩下的
for(int i=leftBit;i<str.size();i++){
c<<=1;
count++;
if(str[i]=='1'){
c = c + 1;
}
// //一个字节存满,将改字节保存
if(count==8){
ch1 = c;
out<<ch1;
//tempstr+=c;
c = 0;
count=0;
}
}
//记录没有保存的字符
leftChar = c;
leftBit = 8-count;
out<<tempstr;
//cout<<"1";
}
}
void encodeHuffman(string file,string path,CodeTableItem *cTable){
//读取文件,一个个字符加密
ifstream infile;
infile.open(file.data()); //将文件流对象与文件连接起来
assert(infile.is_open()); //若失败,则输出错误消息,并终止程序运行
infile >> noskipws;
string line;
while (std::getline(infile, line)) {
encodeLine(line,path,cTable);
}
infile.close();
}
//解密
void decodeHuffman(string file){
node *p = myroot;
ifstream infile;
infile.open(file.data()); //将文件流对象与文件连接起来
assert(infile.is_open()); //若失败,则输出错误消息,并终止程序运行
unsigned char c;
infile >> noskipws;
int wordcount=0;
infile>>c;
while(!infile.eof())
{
infile>>c;
string str = "";
int beichushu = 128;
for(int i=0;i<8;i++){
int bit = (int)c/beichushu;
if(bit==1){
p = p->right;
str+= "1";
}
else{
str+= "0";
p = p->left;
}
if(p->left==NULL){
//cout<<p->ch;
out<<p->ch;
//当执行到最后一个字符就结束,不要继续输出后面多余字符
wordcount++;
if(wordcount==totalNum)
return;
p = myroot;
}
c <<= 1;
}
//cout<<str;
//cout<<wordcount;
}
infile.close(); //关闭文件输入流
}
void testWrite(string savePath){
string str = "";
for(int i=0;i<1000;i++){
str+='a';
}
ofstream ofile; //定义输出文件
ofile.open(savePath); //作为输出文件打开
for(int i=0;i<10;i++){
ofile<<str;
}
ofile.close();
}
int main(int argc, const char * argv[]) {
srand((unsigned)time(NULL));//用时间做种,每次产生随机数不一样
clock_t start,finish;
double time;
start = clock();
string file ="/Users/ish/Documents/code/c++/Huffman/cacm.all";
string encodeFile="/Users/ish/Documents/code/c++/Huffman/encode.all";
string decodefile="/Users/ish/Documents/code/c++/Huffman/decode.all";
//构建统计表
readTxt(file,CList);
//动态初始化编码表
CodeTableItem *codeTable =new CodeTableItem[cnumber];
//构建树并且建立编码表
huffman(CList,codeTable);
//输出编码表
// for(int i=0;i<cnumber;i++){
// cout<<codeTable[i].data<<"->"<<codeTable[i].code<<endl;
// }
//加密
out.open(encodeFile);
encodeHuffman(file, encodeFile,codeTable);
out.close();
//解密
out.open(decodefile);
decodeHuffman(encodeFile);
out.close();
finish=clock();
time = static_cast<double>(finish - start)/CLOCKS_PER_SEC*1000; //ms
cout<<"运行时间为:"<<time<<"ms"<<endl;
return 0;
}