二叉树
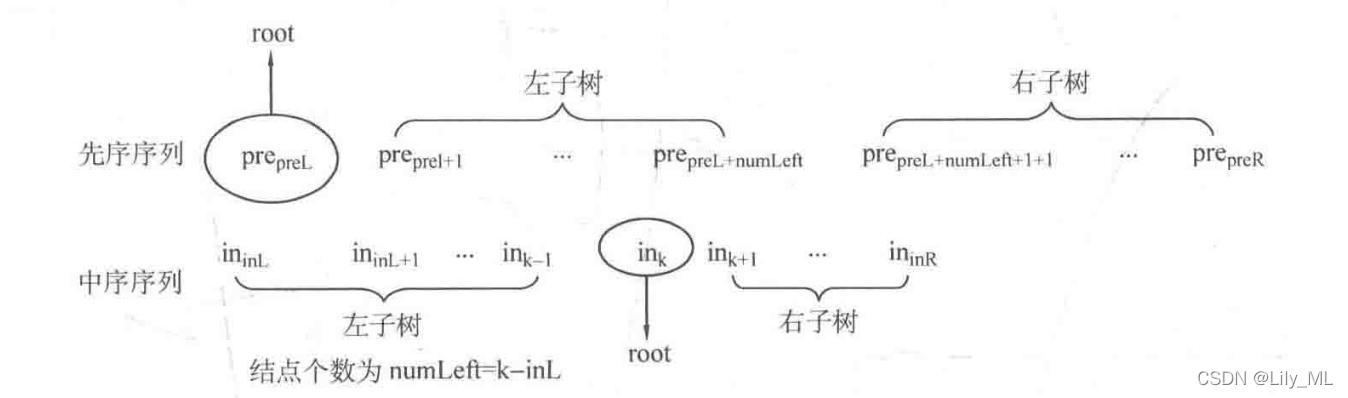
先序和中序确定二叉树
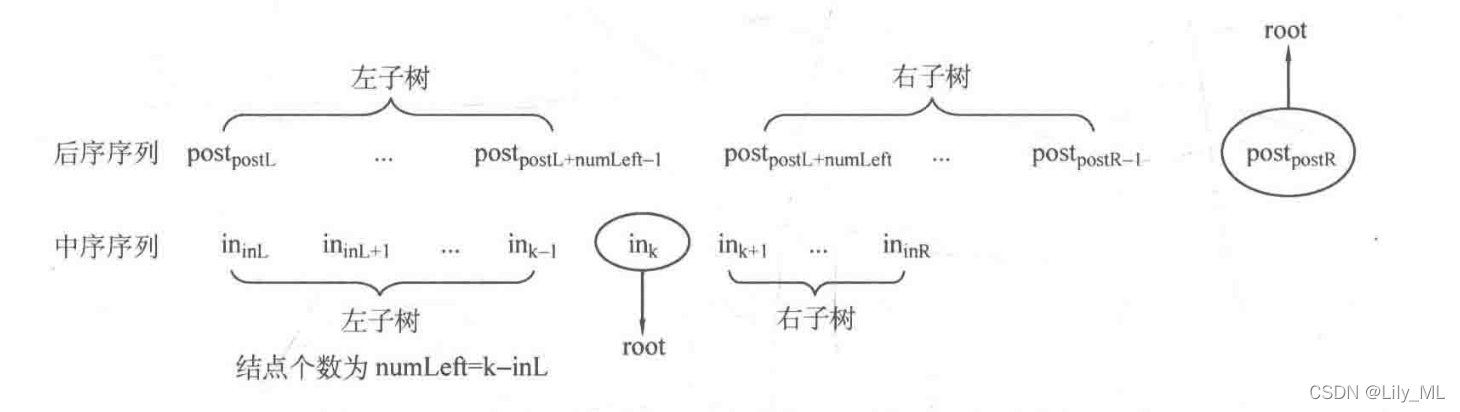
后序以及中序确定二叉树
struct node{
typename data;
node* lchild;
node* rchild;
}
node* root = NULL;
node* newNode(int v) {
node* Node = new node;
Node->data = v;
Node->lchild = Node->rchild = NULL;
return Node;
}
void search(node* root, int x, int newdata) {
if (root == NULL) return ;
if (root->val == x) root->val = newdata;
search(root->lchild, x, newdata);
search(root->rchild, x, newdata);
}
void insert(node* &root, int x) {
if (root == NULL) {
root = newNode(x);
return ;
}
if (由二叉树的性质, x应插入在左子树) {
insert(root->lchild, x);
} else {
insert(root->rchild, x);
}
}
node* Create(int data[], int n) {
node* root = NULL;
for (int i = 0; i < n; i ++) {
insert(root, data[i]);
}
return root;
}
void preorder(node* root) {
void preorder(node* root) {
}
}
void inorder(node* root) {
if (root == NULL) return ;
inorder(root->lchild);
printf("%d\n", root->val);
inorder(root->rchild);
}
void postorder(node* root) {
if (root == NULL) return ;
postorder(root->lchild);
postorder(root->rchild);
printf("%d\n", root->val);
}
void LayerOrder(node* root) {
queue<node*> q;
q.push(root);
while (!q.empty()) {
node* now = q.front();
q.pop();
printf("%d ", now->val);
if (now->lchild != NULL) q.push(now->lchild);
if (now->rchild != NULL) q.push(now->rchild);
}
}
node* createPreIn(int preL, int preR, int inL, int inR) {
if (preL > preR) return NULL;
node* root = new node;
root->val = pre[preL];
int k;
for (k = inL; k <= inR; k ++)
if (in[k] == pre[preL]) break;
int numLeft = k - inL;
root->lchild = createPreIn(preL + 1, preL + numLeft, inL, k - 1);
root->rchild = createPreIn(preL + numLeft + 1, preL, k + 1, inR);
return root;
}
node* createPostIn(int PostL, int PostR, int inL, int inR) {
if (PostL > PostR) return NULL;
node* root = new node;
root->val = post[PostR];
int k;
for (k = inL; k <= inR; k ++)
if (in[k] == posst[PostR]) break;
int numLeft = k - inL;
root->lchild = createPostIn(PostL, PostL + numLeft - 1, inL, k - 1);
root->rchild = createPostIn(PostL + numLeft, PostR - 1, k + 1, inR);
}
struct node {
typename data;
int lchild;
int rchild;
} Node[N];
int index = 0;
int newNode(int v) {
Node[index].data = v;
Node[index].lchild = -1;
Node[index].rchild = -1;
return index ++;
}
void search(int root, int x, int newdata) {
if (root = -1) return;
if (Node[root].data == x) Node[root].data = newdata;
search(Node[root].lchild, x, newdata);
search(Node[root].rchild, x, newdata);
}
void insert(int &root, int x) {
if (root == -1) {
root = newNode(x);
return ;
}
if (由于二叉树的性质x应该插在左子树)
insert(Node[root].lchild, x);
else
insert(Node[root].rchild, x);
}
int Create(int data[], int n) {
int root = 1;
for (int i = 0;i < n; i ++)
insert(root, data[i]);
return root;
}
void preorder(int root) {
if (root == -1) return ;
printf("%d ", Node[root].data);
preorder(Node[root].lchild);
preorder(Node[root].rchild);
}
void inorder(int root) {
if (root == -1) return ;
inorder(Node[root].lchild);
printf("%d ", Node[root].data);
inorder(Node[root].rchild);
}
void postorder(int root) {
if (root == -1) return ;
preorder(Node[root].lchild);
preorder(Node[root].rchild);
printf("%d ", Node[root].data);
}
void LayerOrder(int root) {
queue<int> q;
q.push(root);
while (!q.empty()) {
int now = q.front();
q.pop();
printf("%d ", Node[now].data);
if (Node[now].lchild != -1) q.push(Node[now].lchild);
if (Node[now].rchild != -1) q.push(Node[now].rchild);
}
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)