Learning under Concept Drift: A Review
Abstract
Concept drift describes unforeseeable changes in the underlying distribution of streaming data over time. Concept driftresearch involves the development of methodologies and techniques for drift detection, understanding and adaptation. Data analysishas revealed that machine learning in a concept drift environment will result in poor learning results if the drift is not addressed. To helpresearchers identify which research topics are significant and how to apply related techniques in data analysis tasks, it is necessarythat a high quality, instructive review of current research developments and trends in the concept drift field is conducted. In addition,due to the rapid development of concept drift in recent years, the methodologies of learning under concept drift have becomenoticeably systematic, unveiling a framework which has not been mentioned in literature. This paper reviews over 130 high qualitypublications in concept drift related research areas, analyzes up-to-date developments in methodologies and techniques, andestablishes a framework of learning under concept drift including three main components: concept drift detection, concept driftunderstanding, and concept drift adaptation. This paper lists and discusses 10 popular synthetic datasets and 14 publicly availablebenchmark datasets used for evaluating the performance of learning algorithms aiming at handling concept drift. Also, concept driftrelated research directions are covered and discussed. By providing state-of-the-art knowledge, this survey will directly supportresearchers in their understanding of research developments in the field of learning under concept drift.
概念漂移描述了流数据的底层分布随时间的变化。概念漂移研究涉及到漂移检测、理解和适应的方法和技术的发展。数据分析表明,在概念漂移环境下,如果不解决漂移问题,机器学习将导致学习效果不佳。为了帮助研究人员确定哪些研究主题是重要的,以及如何在数据分析任务中应用相关技术,有必要对概念漂移领域的当前研究进展和趋势进行高质量、指导性的回顾。此外,由于近年来概念漂移的迅速发展,概念漂移下的学习方法也变得明显的系统化,揭示了一个文献中未曾提及的框架。本文回顾了概念漂移相关研究领域的130多篇高质量出版物,分析了方法和技术的最新进展,建立了概念漂移下的学习框架,包括概念漂移检测、概念漂移理解和概念漂移适应。本文列出并讨论了10个常用的合成数据集和14个公开可用的benchmark数据集,用于评估针对概念漂移的学习算法的性能。并对概念漂移的相关研究方向进行了探讨。通过提供最新的知识,本调查将直接支持研究人员了解概念漂移下学习领域的研究进展。
Introduction
GOVERNMENTSand companies are generating hugeamounts of streaming data and urgently need efficientdata analytics and machine learning techniques to sup-port them making predictions and decisions. However, therapidly changing environment of new products, new mar-kets and new customer behaviors inevitably results in theappearance of concept drift problem. Concept drift meansthat the statistical properties of the target variable, which themodel is trying to predict, change over time in unforeseenways [1]. If the concept drift occurs, the induced pattern ofpast data may not be relevant to the new data, leading topoor predictions and decision outcomes. The phenomenonof concept drift has been recognized as the root cause ofdecreased effectiveness in many data-driven informationsystems such as data-driven early warning systems anddata-driven decision support systems. In an ever-changingand big data environment, how to provide more reliabledata-driven predictions and decision facilities has become acrucial issue.
政府和公司正在生成大量的流数据,迫切需要高效的数据分析和机器学习技术来支持他们做出预测和决策。然而,随着新产品、新市场、新顾客行为的急剧变化,不可避免地会出现概念漂移问题。概念漂移是指模型试图预测的目标变量的统计特性随着时间的推移以不可预见的方式发生变化[1]。如果概念漂移发生,则过去数据的诱导模式可能与新数据无关,从而导致拓扑预测和决策结果。在许多数据驱动的信息系统,如数据驱动的预警系统和数据驱动的决策支持系统中,概念漂移现象被认为是导致系统有效性下降的根本原因。在不断变化的大数据环境中,如何提供更可靠的数据驱动预测和决策工具已成为一个重要的问题。
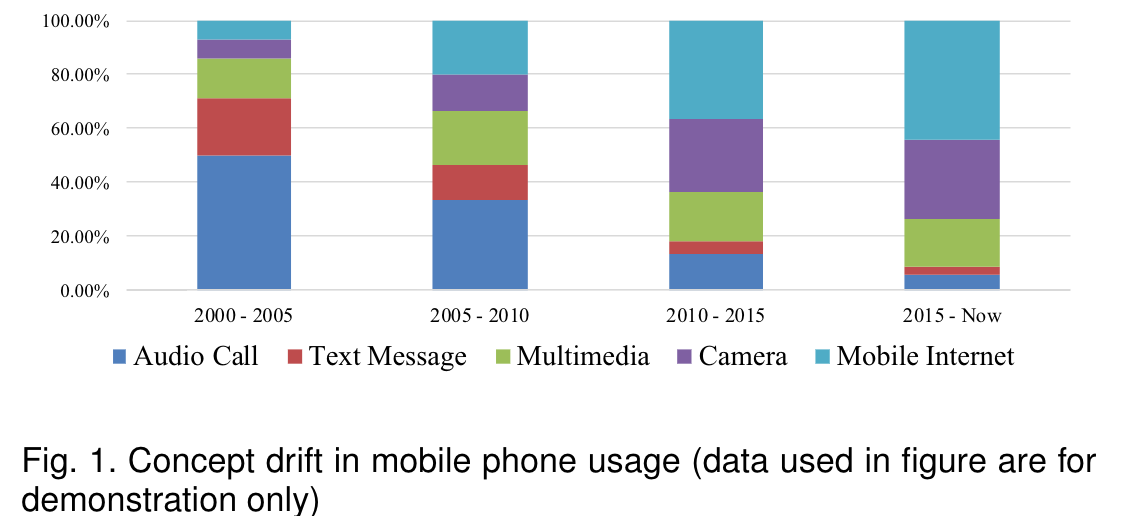
Concept drift problemexists in many real-world situations.Anexamplecanbeseeninthechangesofbehaviorinmobilephoneusage,asshowninFig.1.Fromthebarsinthisfigure,thetimepercentagedistributionofthemobilephoneusagepatternhaschangedfrom“AudioCall”to“Camera”andthento“MobileInternet”overthepasttwodecades
概念漂移问题存在于更现实的情况下-例如使用手机的行为学方法,如图1所示。从图中的数字可以看出,在过去的二十年里,移动电话使用模式的时间百分比分布已经从“音频呼叫”变为“摄像头”和“移动互联网”
Recent attractive research in the field of concept drifttargets more challenging problems, i.e., how to accuratelydetect concept drift in unstructured and noisy datasets [2],[3], how to quantitatively understand concept drift in aexplainable way [4], [5], and how to effectively react to driftby adapting related knowledge [6], [7]
近年来概念漂移领域的研究热点是更具挑战性的问题,即如何在非结构化和噪声数据集中准确地检测概念漂移[2]、[3]、如何以可解释的方式定量理解概念漂移[4]、[5],以及如何运用相关知识有效应对漂移[6],[7]
Solving these challenges endows prediction and decision-making with the adaptability in an uncertain envi-ronment. Conventional research related to machine learninghas been significantly improved by introducing conceptdrift techniques in data science and artificial intelligence in general, and in pattern recognition and data stream miningin particular. These new studies enhance the effectiveness ofanalogical and knowledge reasoning in an ever-changingenvironment. A new topic is formed during this devel-opment: adaptive data-driven prediction/decision systems.In particular, concept drift is a highly prominent and sig-nificant issue in the context of the big data era becausethe uncertainty of data types and data distribution is aninherent nature of big data
在不确定的环境中具有适应性地解决这些挑战性的预测和决策。通过在数据科学和人工智能中引入概念漂移技术,与机器学习相关的传统研究得到了显著改善一般,特别是模式识别和数据流挖掘。这些新的研究增强了在不断变化的环境中进行逻辑推理和知识推理的有效性。在这一发展过程中形成了一个新的课题:自适应数据驱动的预测/决策系统。输入尤其是在大数据时代背景下,概念漂移是一个非常突出和重要的问题,因为数据类型和数据分布的不确定性是大数据的一个内在本质。
Conventional machine learning has two main compo-nents: training/learning and prediction. Research on learn-ing under concept drift presents three new components:drift detection (whether or not drift occurs), drift under-standing (when, how, where it occurs) and drift adaptation(reaction to the existence of drift) as shown in Fig. 2. Thesewill be discussed in Section 3-5.
传统的机器学习有两个主要组成部分:训练/学习和预测。概念漂移下的学习研究提出了三个新的c组件:漂移检测(无论是否发生漂移)、漂移是否存在(何时、如何、在何处发生)和漂移适应(对漂移存在的反应),如图2所示。这些将在第3-5节中讨论。
In literature, a detailed concept drift survey paper [8]was published in 2014 but intentionally left certain sub-problems of concept drift to other publications, such asthedetailsofthedatadistributionchange(P(X)) as mentionedin their Section 2.1. In 2015, another comprehensive surveypaper [9] was published, which surveys and gives tutorialof both the established and the state-of-the-art approaches.It provides a hybrid-view about concept drift from two primary perspectives, active and passive. Both survey pa-pers are comprehensive and can be a good introductionto concept drift researching.However,many new publica-tions have become available in the last three years,even a new category of drift detection methods has a risen,named multiple hypothesis tests drift detection. It is necessary toreview the past research focuses and give the most recentresearch trends about concept drift, which is one of the maincontribution of this survey paper.
在文献中,2014年发表了一份详细的概念漂移调查论文[8],但有意将概念漂移的某些子问题留给其他出版物,如第2.1节中提到的数据分布变化(P(X))详细说明。2015年,又出版了一份综合调查报告[9],对既有和最先进的进行了调查和指导接近。它提供一个关于概念漂移的混合视图two 主动和被动的观点。这两份调查报告都很全面,可以很好地介绍概念漂移研究。但是许多新的出版物在三年前都是可用的,甚至还有一个新的缺陷检测方法,称为多个假设的概念漂移检测。有必要回顾过去的研究热点,给出概念漂移的最新研究趋势,这也是本文的主要贡献之一。
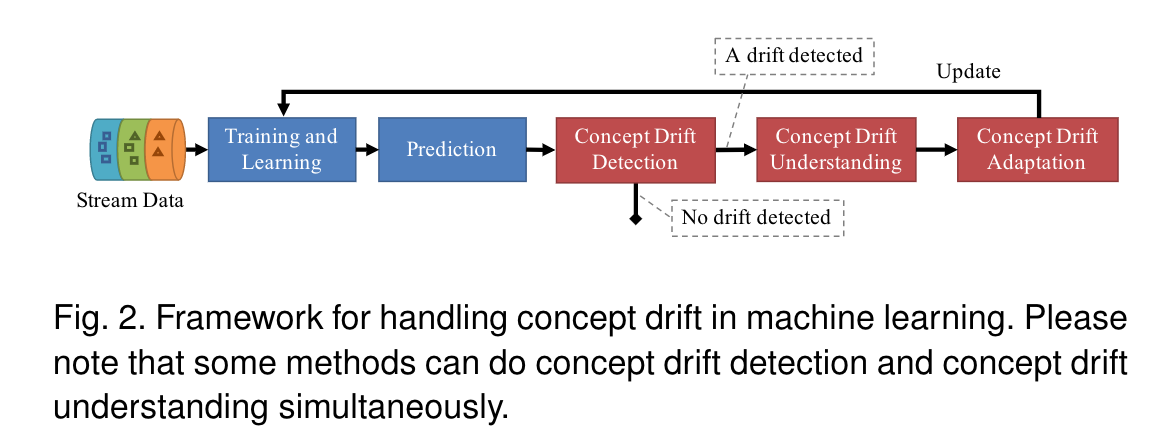
Besides these two publications, four related survey pa-pers [6], [7], [10], [11] have also provided valuable insightsinto how to address concept drift, but their specific researchfocus is only on data stream learning, rather than analyz-ing concept drift adaptation algorithms and understand-ing concept drift. Specifically, paper [7] focuses on datareduction for stream learning incorporating concept drift,while [6] only focuses on investigating the development inlearning ensembles for data stream learning in a dynamicenvironment. [11] concerns the evolution of data streamclustering, and [10] focuses on investigating the current andfuture trends of data stream learning. There is therefore agap in the current literature that requires a fuller pictureof established and the new emerged research on conceptdrift; a comprehensive review of the three major aspectsof concept drift: concept drift detection, understanding andadaptation, as shown in Fig. 2; and a discussion about thenew trend of concept drift research.
除了这两个出版物外,四个相关的调查文献[6]、[7]、[10]、[11]也为如何解决概念漂移提供了有价值的见解,但他们的具体研究重点仅限于数据流学习,而不是分析概念漂移适应算法和理解概念漂移。具体地说,论文[7]侧重于结合概念漂移的流学习的数据简化,而[6]只关注动态环境下数据流学习的集成学习的发展。[11] 关注数据流聚类的发展,并且[10]关注数据流学习的当前和未来趋势。因此,在当前的文献中有gap,它要求对概念漂移的已建立和新出现的研究有一个更全面的描述;对概念漂移的三个主要方面:概念漂移的检测、理解和适应,如图2所示;并讨论概念漂移的新趋势概念漂移研究。
1)It perceptively summarizes concept drift researchachievements and clusters the research into three cat-egories: concept drift detection, understanding andadaptation, providing a clear framework for conceptdrift research development (Fig. 2);
2)It proposes a new component, concept drift under-standing, for retrieving information about the status ofconcept drift in aspects of when, how, and where. Thisalso creates a connection between drift detection anddrift adaptation;
3)It uncovers several very new concept drift techniques,such as active learning under concept drift and fuzzycompetence model-based drift detection, and identifiesrelated research involving concept drift;
4)It systematically examines two sets of concept driftdatasets, Synthetic datasets and Real-world datasets,through multiple dimensions: dataset description,availability, suitability for type of drift, and existingapplications;
5)It suggests several emerging research topics and poten-tial research directions in this area.
The remainder of this paper is structured as follows.In Section 2, the definitions of concept drift are givenand discussed. Section 3 presents research methods andalgorithms in concept drift detection. Section 4 discussesresearch developments in concept drift understanding. Re-search results on drift adaptation (concept drift reaction) arereported in Section 5. Section 6 presents evaluation systemsand related datasets used to test concept drift algorithms.Section 7 summaries related research concerning the conceptdrift problem. Section 8 presents a comprehensive analysisof main findings and future research directions.
1) 它感性地总结了概念漂移的研究成果,并将研究分为三大类:概念漂移检测、理解和适应,为概念漂移研究的发展提供了一个清晰的框架(图2);
2)提出了一个新的组成部分,概念漂移的理解和适应,用于检索有关概念漂移状态的信息,包括时间、方式和位置。这也在漂移检测和漂移适应之间建立了联系;
3)揭示了一些非常新的概念漂移技术,如概念漂移下的主动学习和基于模糊比较模型的漂移检测,并确定了涉及概念漂移的相关研究;
4)系统地考察了两组概念漂移数据集、合成数据集和真实世界数据集,通过多个维度:数据集描述、可用性、漂移类型的适用性和现有应用;
5) 在此基础上,提出了一些新的研究课题和可能的研究方向区域。
那个本文其余部分的结构如下跟在后面第二节,给出并讨论了概念漂移的定义。第三部分介绍了概念漂移检测的研究方法和算法。第4节讨论了概念漂移理解的研究进展。关于漂移适应(概念漂移反应)的研究结果见第5节。第6节介绍了用于测试概念漂移的评估系统和相关数据集算法.章节7综述了概念漂移问题的相关研究。第八部分对主要发现和未来的研究方向进行了综合分析。
Problem Description
Concept drift definition and the sources
Concept drift is a phenomenon in which the statistical prop-erties of a target domain change over time in an arbitraryway [3]. It was first proposed by [12] who aimed to pointout that noise data may turn to non-noise information atdifferent time. These changes might be caused by changesin hidden variables which cannot be measured directly [4].Formally, concept drift is defined as follows:Given a time period[0,t], a set of samples, de-noted asS0,t={d0,…,dt}, wheredi= (Xi,yi)isone observation (or a data instance),Xiis the fea-ture vector,yiis the label, andS0,tfollows a certaindistributionF0,t(X,y).Conceptdriftoccursattimes-tampt+ 1,ifF0,t(X,y)6=Ft+1,∞(X,y),denotedas∃t:Pt(X,y)6=Pt+1(X,y)[2], [8], [13], [14]
概念漂移是一种目标域的统计特性随时间任意变化的现象[3]。它首先是由[12]提出的,目的是指出噪声数据在不同的时间会变成非噪声信息。这些变化可能是由于无法直接测量的隐藏变量的变化引起的[4]以下:给定一个时间段[0,t],一组样本,记为0,t={d0,…,dt},其中di=(Xi,yi)是一个观察(或一个数据实例),Xi是特征向量,yi是标签,s0,t遵循一定的分布f0,t(X,y)。概念漂移发生的时间为tampt+1,ifF0,t(X,y)6=Ft+1,∞(X,y),表示为∃t:Pt(X,y)6=Pt+1(X,y)[2],[8],[13],[14]。
Concept drift has also been defined by various authorsusing alternative names, such as dataset shift [15] or conceptshift [1]. Other related terminologies were introduced in[16]’s work, the authors proposed that concept drift or shiftis only one subcategory of dataset shift and the datasetshift is consists of covariate shift, prior probability shift and concept shift. These definitions clearly stated the researchscope of each research topics. However, since concept drift isusually associated with covariate shift and prior probabilityshift, and an increasing number of publications [2], [8], [13],[14] refer to the term ”concept drift” as the problem inwhich∃t:Pt(X,y)6=Pt+1(X,y). Therefore, we apply thesame definition of concept drift in this survey. Accordingly,concept drift at timetcan be defined as the change ofjoint probability of Xandyat timet. Since the joint probabilityPt(X,y)can be decomposed into two parts asPt(X,y) =Pt(X)×Pt(y|X), concept drift can be triggeredby three sources.
概念漂移也由不同的作者使用其他名称定义,比如dataset shift[15]或concept shift[1]。文献[16]还引入了其他相关术语,提出概念漂移或移位只是数据集移位的一个子范畴,数据集移位由协变量移位、先验概率移位和观念转变。这些定义清楚地说明了每个研究课题的研究范围。然而,由于概念漂移通常与协变量偏移和先验概率偏移有关,越来越多的文献[2]、[8]、[13]、[14]将“概念漂移”称为∃t:Pt(X,y)6=Pt+1(X,y)的问题。因此,我们在本次调查中采用了相同的概念漂移定义。因此,时间漂移可以定义为x和y时刻联合概率的变化。由于jointprobabilityPt(X,y)可以分解为asPt(X,y)=Pt(X)×Pt(y | X)两部分,因此概念漂移可以由三个源触发。
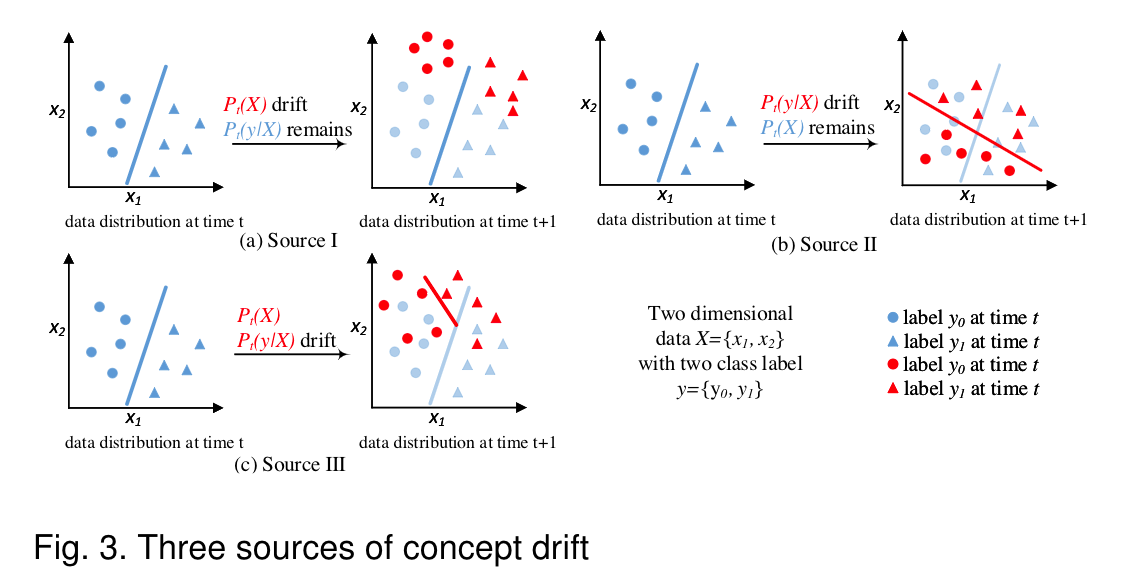
Source I:Pt(X)6=Pt+1(X)whilePt(y|X) =Pt+1(y|X), that is, the research focus is the drift inPt(X)whilePt(y|X)remains unchanged. SincePt(X)drift does not affect the decision boundary, it has alsobeen considered as virtual drift [7], Fig. 3(a).•Source II:Pt(y|X)6=Pt+1(y|X)whilePt(X) =Pt+1(X)whilePt(X)remains unchanged. This driftwill cause decision boundary change and lead to learn-ing accuracy decreasing, which is also called actual drift,Fig. 3(b).•Source III: mixture of Source I and Source II, namelyPt(X)6=Pt+1(X)andPt(y|X)6=Pt+1(y|X). Conceptdrift focus on the drift of bothPt(y|X)andPt(X),since both changes convey important information aboutlearning environment Fig. 3©.Fig. 3 demonstrates how these sources differ from eachother in a two-dimensional feature space. Source I is featurespace drift, and Source II is decision boundary drift. Inmany real-world applications, Source I and Source II occurtogether, which creates Source III
来源一:Pt(X)6=Pt+1(X)whilePt(y | X)=Pt+1(y | X),即研究的焦点是漂移输入(X),而漂移输入(y | X)保持不变。由于(X)漂移不影响判决边界,因此它也被视为虚拟漂移[7],图3(a)。•源二:Pt(y | X)6=Pt+1(y | X),其中Pt(X)=Pt+1(X),而lept(X)保持不变。这种漂移会引起决策边界的变化,并导致学习精度下降,这也被称为实际漂移,图3(b);•震源III:震源I和震源II的混合,即Pt(X)6=Pt+1(X)和Pt(y | X)6=Pt+1(y | X)。
Concept drift关注的是hpt(y | X)和pt(X)的漂移,因为这两种变化都传达了关于学习环境的重要信息图3(c)。图3展示了这些来源在二维特征空间中的区别。源I为特征空间漂移,源II为判定边界漂移。在许多真实世界的应用程序中,源代码I和源代码II占用者创建了源代码III
Concept Drift Detection
*A general framework for drift *
Drift detection refers to the techniques and mechanismsthat characterize and quantify concept drift via identifyingchange points or change time intervals [17]. A generalframework for drift detection contains four stages, as shownin Fig. 5.Stage 1 (Data Retrieval) aims to retrieve data chunksfrom data streams. Since a single data instance cannot carryenough information to infer the overall distribution [2],knowing how to organize data chunks to form a meaningfulpattern or knowledge is important in data stream analysistasks [7].Stage 2 (Data Modeling) aims to abstract the retrieveddata and extract the key features containing sensitive infor-mation, that is, the features of the data that most impacta system if they drift. This stage is optional, because itmainly concerns dimensionality reduction, or sample sizereduction, to meet storage and online speed requirements[4].Stage 3 (Test Statistics Calculation) is the measurement ofdissimilarity, or distance estimation. It quantifies the sever-ity of the drift and forms test statistics for the hypothesistest. It is considered to be the most challenging aspect ofconcept drift detection. The problem of how to define anaccurate and robust dissimilarity measurement is still anopen question. A dissimilarity measurement can also be used in clustering evaluation [11], and to determine thedissimilarity between sample sets [18].Stage 4 (Hypothesis Test) uses a specific hypothesis testto evaluate the statistical significance of the change observedin Stage 3, or the p-value. They are used to determinedrift detection accuracy by proving the statistical boundsof the test statistics proposed in Stage 3. Without Stage4, the test statistics acquired in Stage 3 are meaninglessfor drift detection, because they cannot determine the driftconfidence interval, that is, how likely it is that the changeis caused by concept drift and not noise or random sampleselection bias [3]. The most commonly used hypothesis testsare: estimating the distribution of the test statistics [19],[20], bootstrapping [21], [22], the permutation test [3], andHoeffding’s inequality-based bound identification [23]
漂移检测是指通过识别变化点或变化时间间隔来表征和量化概念漂移的技术和机制[17]。漂移检测的一般框架包括四个阶段,如图5所示。
第1阶段(数据检索)旨在从数据流中检索数据块。由于单个数据实例无法携带全部信息来推断总体分布[2],在数据流分析任务[7]中,了解如何组织数据块以形成有意义的模式或知识是很重要的。
第2阶段(数据建模)旨在提取检索到的数据,并提取包含敏感信息的关键特征,即在数据漂移时对系统影响最大的数据特征。这一阶段是可选的,因为它主要是为了满足存储和在线速度要求而进行的降维或样本量缩减[4]。
第3阶段(测试统计计算)是差异性的测量或距离估计。它量化了漂移的严重程度,并为假设者形成了检验统计量。它被认为是概念漂移检测中最具挑战性的方面。如何定义准确度和鲁棒性的差异性度量仍然是一个有待解决的问题。不同的测量也可以是用于聚类评估[11],并确定样本集之间的差异[18]。
第4阶段(假设检验)使用特定的假设检验来评估第3阶段观察到的变化的统计显著性或p值。它们通过证明第3阶段提出的测试统计量的统计界来确定提升检测精度。随机性检验的意义是随机性的,因为随机性检验是无法确定随机性的。最常用的假设检验有:估计检验统计量的分布[19]、[20]、[21]、[22]、置换检验[3]和基于hoefffding不等式的界识别[23]
It is also worth to mention that, without Stage 1, the concept drift detection problem can be considered as a two-sample test problem which examines whether the popula-tion of two given sample sets are from the same distribution[18]. In other words, any multivariate two-sample test is anoption that can be adopted in Stages 2-4 to detect conceptdrift [18]. However, in some cases, the distribution drift maynot be included in the target features, therefore the selectionof the target feature will affect the overall performance ofa learning system and is a critical problem in concept driftdetection [24].
还值得一提的是,在没有阶段1的情况下,概念漂移检测问题可以看作是一个两样本检验问题,检验两个给定样本集的总体是否来自同一分布[18]。换言之,任何多变量双样本检验都是可以在第2-4阶段采用的一个选项来检测概念漂移[18]。然而,在某些情况下,分布漂移可能不包含在目标特征中,因此目标特征的选择将影响学习系统的整体性能,是概念漂移检测中的一个关键问题[24]
Concept drift detection algorithms
Error rate-based drift detection
PLearner error rate-based drift detection algorithms formthe largest category of algorithms. These algorithms focuson tracking changes in the online error rate of base classi-fiers. If an increase or decrease of the error rate is proven tobe statistically significant, an upgrade process (drift alarm)will be triggered.
基于预学习误差率的漂移检测算法是最大的一类算法。这些算法关注于跟踪基本分类器在线错误率的变化。如果错误率的增加或减少被证明具有统计意义,则将触发升级过程(漂移警报)。
DDM(Drift Detection Method)
Stage 1 通过时间窗实现,如图6所示。当一个新的数据实例可以用于评估时,DDM会检测时间窗口内的总体在线错误率是否显著增加。当错误率变化的置信度达到预警级别时,DDM开始构建一个新的学习器,同时使用旧的学习者进行预测。如果变化达到漂移级别,旧的学习者将被新的学习者代替,进行进一步的预测任务。为了获得在线错误率,DDM需要一个分类器来进行预测。这个过程将训练数据转换为学习模型,这是第二阶段(数据建模)。阶段3的测试统计数据构成在线错误率。假设检验阶段(第四阶段)通过估计在线错误率的分布,计算预警级别和漂移阈值进行假设检验。
类似的还有LLDD [10], EDDM [11], HDDM [12], FW-DDM [13], DELM[14]。
LLDD修改了3,4阶段,将整个漂移检测问题分解为一组基于决策树节点的漂移检测问题。
EDDM利用两个正确分类间的距离改进了DDM的第3阶段,提高了漂移检测的灵敏度。
HDDM 修改阶段4,使用了Hoeffding不等式识别漂移临界区域的方法。
FW-DDM改进了DDM的第一阶段,使用模糊时间窗代替传统的时间窗来解决逐步漂移问题。
DEML没有改变DDM检测算法,而是采用了一种新的基学习器,它是一种单隐层反馈神经网络,称为 ELM [15],以改进漂移确定后的自适应过程。
ECDD[16] 使用EWMA图表来跟踪错误率的变化。用动态均值替代静态均值,动态方差为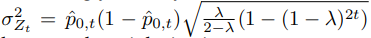 ,其中λ是新数据对比旧数据的权重,作者建议取0.2. =[ ]
,其中λ是新数据对比旧数据的权重,作者建议取0.2. =[ ]
与DDM等类似算法相比,STEPD[17],比较最近的时间窗口和整个时间窗口来检测错误率的变化
ADWIN不需要指定时间窗口大小,需要指定一个足够大的窗口总大小。对所有子窗口计算漂移量。
One of the most-referenced concept drift detection algo-rithms is the Drift Detection Method (DDM) [20]. It wasthe first algorithm to define the warning level and driftlevel for concept drift detection. In this algorithm, Stage1 is implemented by a landmark time window, as shownin Fig. 6. When a new data instance become available forevaluation, DDM detects whether the overall online errorrate within the time window has increased significantly.If the confidence level of the observed error rate changereaches the warning level, DDM starts to build a new learnerwhile using the old learner for predictions. If the changereached the drift level, the old learner will be replacedby the new learner for further prediction tasks. To acquirethe online error rate, DDM needs a classifier to make thepredictions. This process converts training data to a learningmodel, which is considered as the Stage 2 (Data Modeling).The test statistics in Stage 3 constitute the online error rate.The hypothesis test, Stage 4, is conducted by estimatingthe distribution of the online error rate and calculating thewarning level and drift threshold.
漂移检测算法(DDM)是一种最有参考价值的概念漂移检测算法[20]。这是第一个为概念漂移检测定义警告级别和漂移级别的算法。在该算法中,Stage1由地标时间窗口实现,如图6所示。当一个新的数据实例可以用于评估时,DDM会检测时间窗口内的整体在线错误率是否增加很明显。如果观测到的错误率变化的置信水平达到警告水平,DDM开始建立一个新的学习者,同时使用旧的学习者进行预测。如果新的学习者的预测达到新的水平,那么新的学习者将被进一步改变的任务所取代。为了获得在线错误率,DDM需要一个分类器来进行预测。该过程将训练数据转换为学习模型,将其视为第二阶段(数据建模),第三阶段的测试统计数据构成在线误差费率。The假设检验,第四阶段,估计在线错误率的分布,计算警告水平和漂移阈值。
Similar implementations have been adopted and appliedin the Learning with Local Drift Detection (LLDD) [25],Early Drift Detection Method (EDDM) [26], Heoffding’sinequality based Drift Detection Method (HDDM) [23],Fuzzy Windowing Drift Detection Method (FW-DDM) [5],Dynamic Extreme Learning Machine (DELM) [27]. LLDDmodifies Stages 3 and 4, dividing the overall drift detectionproblem into a set of decision tree node-based drift detectionproblems; EDDM improves Stage 3 of DDM using thedistance between two correct classifications to improve thesensitivity of drift detection; HDDM modifies Stage 4 usingHoeffding’s inequality to identify the critical region of adrift; FW-DDM improves Stage 1 of DDM using a fuzzytime window instead of a conventional time window toaddress the gradual drift problem; DEML does not changethe DDM detection algorithm but uses a novel base learner,which is a single hidden layer feedback neural networkcalled Extreme Learning Machine (ELM) [28] to improvethe adaptation process after a drift has been confirmed.EWMA for Concept Drift Detection (ECDD) [29] takes ad-vantage of the error rate to detect concept drift. ECDDemploys the EWMA chart to track changes in the error rate.The implementation of Stages 1-3 of ECDD is the sameas for DDM, while Stage 4 is different. ECDD modifiesthe conventional EWMA chart using a dynamic meanˆp0,tinstead of the conventional static meanp0, whereˆp0,tis theestimated online error rate within time[0,t], andp0impliesthe theoretical error rate when the learner was initially built.Accordingly, the dynamic variance can be calculated byσ2Zt= ˆp0,t(1−ˆp0,t)√λ2−λ(1−(1−λ)2t)whereλcontrolshow much weight is given to more recent data as opposedto older data, andλ= 0.2is recommended by the authors.
类似的实现方法已被采用并应用于学习中:局部漂移检测(LLDD)[25]、早期漂移检测方法(EDDM)[26]、基于Heoffding’sinequality的漂移检测方法(HDDM)[23]、模糊窗口漂移检测方法(FW-DDM)[5]、动态极限学习机(DELM)[27]。lldd修改了第3和第4阶段,将整个漂移检测问题划分为一组基于决策树节点的漂移检测问题;EDDM利用两个正确分类之间的距离改进了DDM的第3阶段,提高了漂移检测的灵敏度;HDDM使用Ho. `’
efffding不等式对第4阶段进行修改,以确定漂移的临界区域;FW-DDM改进了DDM的第1阶段,使用模糊时间窗口代替传统的时间窗口来解决渐变漂移问题;DEML没有改变DDM检测算法,而是使用了一种新的基学习器,它是一个单一的隐层反馈神经网络称为极限学习机(ELM)[28],以改进漂移后的适应过程确认.ewa对于概念漂移检测(ECDD)[29]利用错误率来检测概念漂移。ECD使用EWMA图表跟踪错误中的更改费率。TheECDD第1-3阶段的实施与DDM相同,而第4阶段则不同。ECDD使用动态平均值ˆp0来修改传统的EWMA图表,而不是传统的静态平均值p0,其中ˆp0是时间内估计的在线错误率[0,t],p0表示学习者最初学习时的理论错误率建造。相应地,动态方差可由σ2, Zt=ˆp0,t(1-ˆp0,t) √λ2−λ(1−(1−λ)2t),其中λ control表示较新的数据比较旧的数据具有更大的权重,作者建议λ=0.2。
Also, when the test statistic of the conventional EWMAchart isZt>ˆp0,t+ 0.5LσZt, ECDD will report a conceptdrift warning; whenZt>ˆp0,t+LσZt, ECDD will report aconcept drift. The control limitsLis given by the authorsthrough experimental evaluation.
此外,当常规EWMAchart的检验统计量为Zt>ˆp0,t+0.5LσZt时,ECDD将报告概念漂移警告;当NZT>ˆp0,t+LσZt时,ECDD将报告一个概念漂移。控制限值由作者通过实验评价给出。
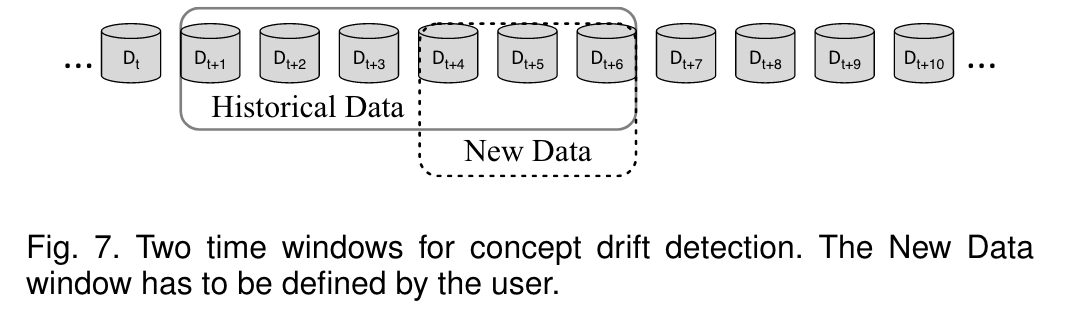
In contrast to DDM and other similar algorithms, Sta-tistical Test of Equal Proportions Detection (STEPD) [30]detects error rate change by comparing the most recenttime window with the overall time window, and for eachtimestamp, there are two time windows in the system, asshown in Fig. 7. The size of the new window must bedefined by the user. According to [30], the test statisticθSTEPDconforms to standard normal distribution, denotedasθSTEPD∼ N(0,1). The significance level of the warninglevel and the drift level were suggested asαw= 0.05andαd= 0.003respectively. As a result, the warning thresholdand drift threshold can be easily calculated.
与DDM和其他类似的算法相比,等比例检测的静态测试(STEPD)[30]通过比较最近的时间窗口和整个时间窗口来检测错误率的变化,并且对于每个时间戳,系统中有两个时间窗口,如图7所示。新窗口的大小必须由用户定义。根据[30],检验统计量θSTEPD符合标准正态分布,表示为θSTEPD∼N(0,1)。警告水平和漂移水平的显著性水平分别为αw=0.05和αd=0.003。因此,可以很容易地计算出警告阈值和漂移阈值。
Another popular two-time window-based drift detectionalgorithm isADaptiveWINdowing (ADWIN) [31]. UnlikeSTEPD, ADWIN does not require users to define the sizeof the compared windows in advance; it only needs tospecify the total sizenof a “sufficiently large” windowW. It then examines all possible cuts ofWand computesoptimal sub-window sizesnhistandnnewaccording to therate of change between the two sub-windowswhistandwnew.The test statistic is the difference of the two sample meansθADWIN=|ˆμhist−ˆμnew|. An optimal cut is found when thedifference exceeds a threshold with a predefined confidenceintervalδ. The author proved that both the false positive rateand false negative rate are bounded byδ. It is worth notingthat many concept drift adaptation methods/algorithms inthe literature are derived from or combined with ADWIN,such as [32]–[35]. Since their drift detection methods areimplemented with almost the same strategy, we will notdiscuss them in detail.
另一种流行的基于两次窗口的漂移检测算法是自适应内插(ADWIN)[31]。与步骤不同,ADWIN不需要用户预先定义比较窗口的大小;它只需要指定一个“足够大”的窗口w的总大小。然后,它检查所有可能的切割,根据两个子窗口之间的变化速度计算最佳子窗口大小nhist和nNew-窗台朝下检验统计量是两个样本均值的差值θADWIN=|μhist-ˆμnew |。当差分超过一个给定置信区间δ的阈值时,找到一个最优割集。作者证明了假阳性率和假阴性率均以δ为界。值得注意的是,文献中的许多概念漂移适应方法/算法都是从ADWIN中衍生出来或与之结合的,如[32]–[35]。由于它们的漂移检测方法是用几乎相同的策略实现的,因此我们将不详细讨论它们。
Data Distribution-based Drift Detection
基于数据分布差异的漂移检测,通过计算数据分布的差异度,来进行检测,不仅可以检查时间维度上的漂移,也可以检测数据集内部的概念差异。然而这些算法的资源消耗通常比上者要高。通常的做法是利用两个滑动窗口来选取数据。
最初使用这种想法的是[18],如果分布有它自己的概率密度函数,则距离可以计算为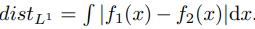 。
。
类似的还有ITA[8],它使用kdqTree来划分 历史数据和 新数据, 然后用KL散度来计算差异性。ITA采用的假设检验方法是将Whist、Wnew合并为Wall,重采样为Whist、Wnew进行bootstrapping,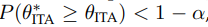 则确定概念漂移,其中α是控制漂移检测灵敏度的显著水平。
则确定概念漂移,其中α是控制漂移检测灵敏度的显著水平。
类似的算法还有SCD[19],n CM[20],PCA-CD [21],EDE[22],LSDD-CDT[21],LSDD-INC[23],LDD-DSDA[24]。
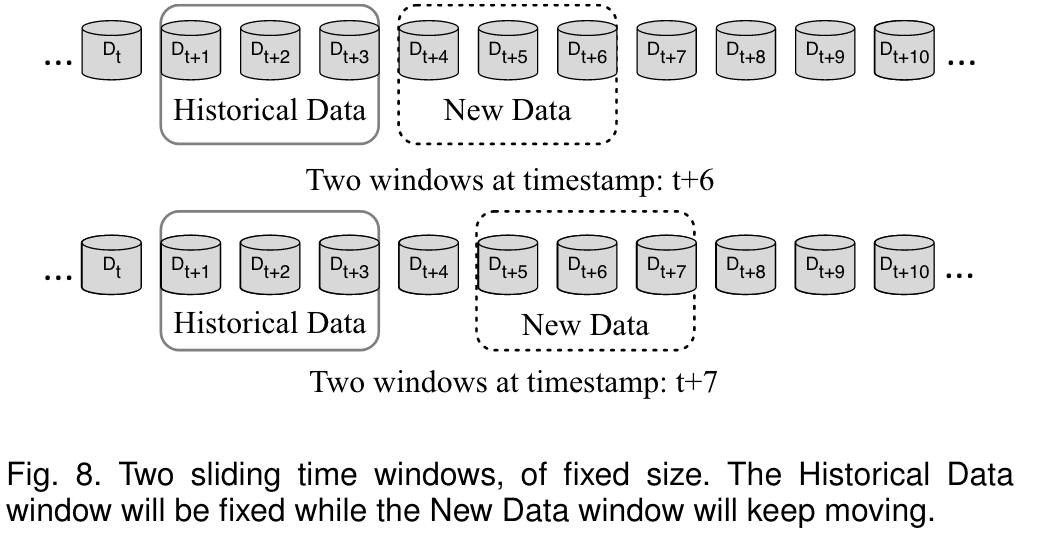
The second largest category of drift detection algorithms isdata distribution-based drift detection. Algorithms of thiscategory use a distance function/metric to quantify thedissimilarity between the distribution of historical data andthe new data. If the dissimilarity is proven to be statisticallysignificantly different, the system will trigger a learningmodel upgradation process. These algorithms address con-cept drift from the root sources, which is the distributiondrift. Not only can they accurately identify the time of drift,they can also provide location information about the drift.However, these algorithms are usually reported as incurringhigher computational cost than the algorithms mentionedin Section 3.2.1 [2]. In addition, these algorithms usuallyrequire users to predefine the historical time window andnew data window. The commonly used strategy is twosliding windows with the historical time window fixed while sliding the new data window [3], [22], [36], as shownin Fig. 8.
第二大类漂移检测算法是基于数据分布的漂移检测。这类算法使用距离函数/度量来量化历史数据和新数据分布之间的差异。如果差异性被证明是统计上显著不同的,系统将触发learningmodel升级过程。这些算法解决了来自根源的概念偏移,即分布裂缝。它们不仅可以准确地识别漂移的时间,还可以提供有关漂移的位置信息漂移。但是,这些算法通常报告为比第3.2.1节[2]中提到的算法产生更高的计算成本。此外,这些算法通常要求用户预先定义历史时间窗口和新的数据窗口。常用的策略是固定历史时间窗的两个滑动窗口滑动新的数据窗口[3]、[22]、[36],如图8所示。
According to the literature, the first formal treatmentof change detection in data streams was proposed by [37].In their study, the authors point out that the most naturalnotion of distance between distributions is total variation,as defined by:TV(P1,P2) = 2supE∈ε|P1(E)−P2(E)|orequivalently, when the distribution has the density func-tionsf1andf2,distL1=∫|f1(x)−f2(x)|dx. This providespractical guidance on the design of a distance functionfor distribution discrepancy analysis. Accordingly, [37] pro-posed a family of distances, called Relativized Discrepancy(RD). The authors also present the significance level of thedistance according to the number of data instances. Thebounds on the probabilities of missed detections and falsealarms are theoretically proven, using Chernoff bounds andthe Vapnik-Chervonenkis dimension. The authors of [37] donot propose novel high-dimensional friendly data modelsfor Stage 2 (data modeling); instead, they stress that asuitable model choice is an open question.
根据文献[37]提出了数据流中变化检测的第一个形式化处理,在他们的研究中,作者指出分布之间距离的最自然的概念是全变差,定义为:TV(P1,P2)=2supE∈ε| P1(E)−P2(E)|或等效,当分布具有密度函数f1和f2时,distL1=∫f1(x)−f2(x)| dx。这对分布差异分析中距离函数的设计具有实际指导意义。因此,[37]提出了一系列距离,称为相对化差异(RD)。作者还根据数据实例的数量给出了距离的显著性水平。利用Chernoff界和Vapnik-Chervonenkis维数,从理论上证明了漏检和误报概率的界。[37]的作者没有为第2阶段(数据建模)提出新的高维友好数据模型;相反,他们强调了可度量的模型选择是一个开放的问题
Multiple Hypothesis Test Drift Detection
并行假设检验
最早的算法是JIT[5],核心思想是拓展CUSUM test,作者给出了给出了漂移检测目标的4种配置方案,1)PCA提取后的特征,移除和小于某一阈值的情况。 2)PCA提取的特征,加上一些原始特征中的通用特征。 3)对每一个特征独立检测。4)检测所有可能组合的特征空间。
相似的LFR[25],考察TP, TN, FP, FN的变化,而不是准确率的变化。
IV-Jac[26]是一种三层检测算法,第一层检测标签层面,第二层是特征层面,第三层决策边界层面。它通过提取 证据权重 WoE,和信息价值 IV,来观察其变化。
串行假设检验
HCDTs**[27]最先设计了 检测层 和 验证层,验证层根据检测层的返回结果决定激活或者休眠,给了两个设计验证层的策略,1)通过最大相似度来计算测试层数据的分布, 2)调整一种已有的假设检验方案。**
HLFR**[28]类似的,使用LFR作为检测层,把验证层简单的使用 0-1损失函数进行评估,超过阈值则为发生概念漂移。
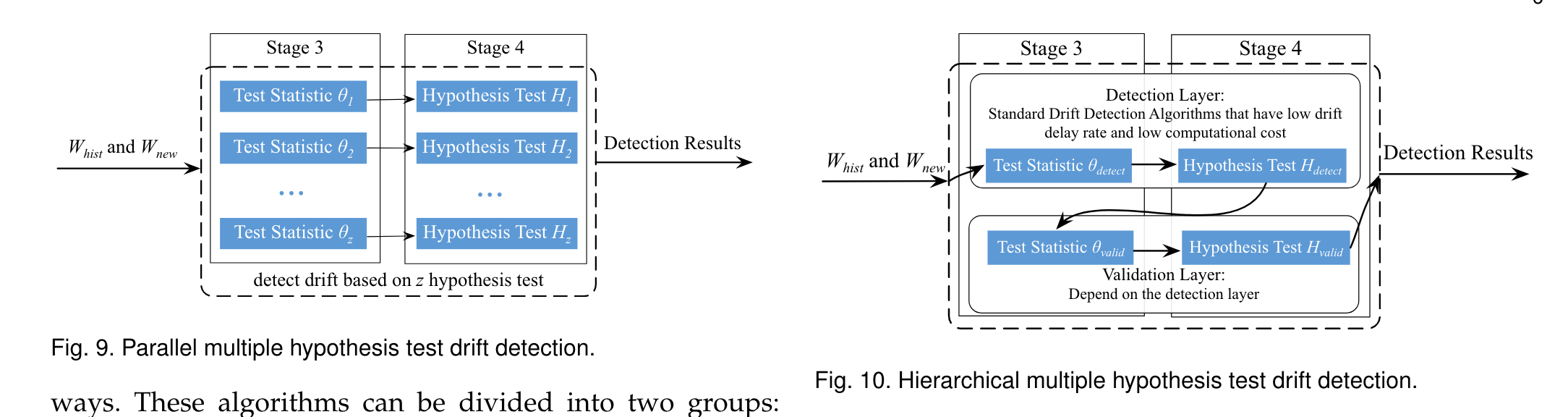
作者认为两个漂移检测器是同质的,就好像它们在概念漂移中是等效的,否则它们是异构的
e-Detector
对于每一组,选择失效系数最小的一个作为基检测器,形成集合。e-Detector根据early-find-early-report规则报告概念漂移,这意味着无论哪个基础检测器检测到漂移,e-Detector都会报告漂移。类似的策略也应用于漂移检测集成(DDE)[49]。
Concept Drift Understanding
Drift understanding refers to retrieving concept drift infor- mation about “When” (the time at which the concept drift occurs and how long the drift lasts), “How” (the severity /degree of concept drift), and “Where” (the drift regions of concept drift). This status information is the output of the drift detection algorithms, and is used as input for drift adaptation.
漂移理解是指检索关于“何时”(概念漂移发生的时间和持续时间)、“如何”(概念漂移的严重程度/程度)和“何处”(概念漂移的漂移区域)的信息。该状态信息是漂移检测算法的输出,并用作漂移自适应的输入。
The time of concept drift occurs(When)
The most basic function of drift detection is to identify the timestamp when a drift occurs. Recalling the definition of concept drift ∃t: Pt(X, y) 不等于sPt+1(X, y), the variable t represents the time at which a concept drift occurs. In drift detection methods/algorithms, an alarm signal is used to indicate whether the concept drift has or has not occurred or not at the current timestamp. It is also a signal for a learning system to adapt to a new concept. Accurately identifying the time a drift occurs is critical to the adaptation process of a learning system; a delay or a false alarm will lead to failure of the learning system to track new concepts.
漂移检测最基本的功能是在发生漂移时识别时间戳。回顾概念漂移∃t的定义:Pt(X,y)̸=Pt+1(X,y),变量t表示概念漂移发生的时间。在漂移检测方法/算法中,报警信号用于指示在当前时间戳中是否发生了概念漂移。这也是学习系统适应新概念的信号。准确识别漂移发生的时间对于学习系统的适应过程至关重要;延迟或错误警报将导致学习系统无法跟踪新概念。
A drift alarm usually has a statistical guarantee with a predefined false alarm rate. Error rate-based drift detection
algorithms monitor the performance of the learning system, based on statistical process control. For example, DDM
[20] sends a drift signal when the learning accuracy of the learner drops below a predefined threshold, which is
chosen by the three-sigma rule [55]. ECCD [29] reports a drift when the online error rate exceeds the control limit
of EWMA. Most data distribution-based drift detection algorithms report a drift alarm when two data samples
have a statistically significant difference. PCA-based drift detection [36] outputs a drift signal when the p-value of
the generalized Wilcoxon test statistic Wl is significantly BF large. The method in [3] confirms that a drift has occurred by verifying whether the empirical competence-based distance is significantly large through permuataion test.
漂移警报通常有一个预先定义的错误警报率的统计保证。基于误差率的漂移检测算法基于统计过程控制来监控学习系统的性能。例如,当学习者的学习精度下降到一个由三西格玛规则[55]选择的预定义阈值以下时,DDM[20]发送一个漂移信号。当在线错误率超过EWMA的控制限值时,ECCD[29]报告一个漂移。大多数基于数据分布的漂移检测算法在两个数据样本具有统计显著差异时报告漂移警报。当广义Wilcoxon检验统计量Wl的p值显著增大时,基于PCA的漂移检测[36]输出漂移信号。文献[3]中的方法通过渗透测试验证经验能力基距离是否显著大,从而确认发生了漂移。
Taking into account the various drift types, concept drift understanding needs to explore the start time point, the change period, and the end time point of concept drift. And these time information could be useful input for the adaptation process of the learning system.
考虑到不同的漂移类型,概念漂移理解需要探索概念漂移的起始时间点、变化周期和结束时间点。这些时间信息可以作为学习系统适应过程的有用输入。
Howerver the drift timestamp alert in existing drift detection algorithms is delayed compared to the actual drifting timestamp, since most drift detectors require a minimum number of new data to evaluate the status of the drift, as shown in Fig. 11. The emergence time of the new concept is therefore still vague. Some concept drift detection algorithms such as DDM [20], EDDM [26], STEPD [30], and HDDM [23], trigger a warning level to indicate a drift may have occurred. The threshold used to trigger warning level is a relaxed condition of the threshold used for the drift level; for example, the warning level is set p-value to 95% or 2σ, and the drift level is set p-value to 99% or 3σ. The data accumulated between the warning level and the drift level are used as the training set for updating a learning model.
与实际漂移时间戳相比,现有漂移检测算法中的漂移时间戳警报被延迟,因为大多数漂移检测器需要最少数量的新数据来评估漂移的状态,如图11所示。因此,新概念的出现时间仍然是模糊的。一些概念漂移检测算法,如DDM[20]、EDDM[26]、STEPD[30]和HDDM[23],会触发警告级别,以指示可能发生了漂移。用于触发警告级别的阈值是用于漂移级别的阈值的放宽条件;例如,将警告级别设置为95%或2σ,将p值设置为99%或3σ。在警告级和漂移级之间积累的数据被用作更新学习模型的训练集。
The severity of concept drift (How)
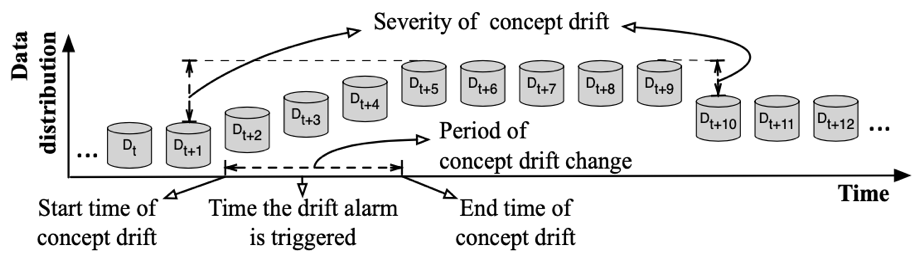
The severity of concept drift refers to using a quantified value to measure the similarity between the new concept and the previous concept, as shown in Fig. 11. Formally, the severity of concept drift can be represented as ∆ = δ(Pt(X, y), Pt+1(X, y)), where δ is a function to measure the discrepancy of two data distributions, and t is the timestamp when the concept drift occurred. ∆ usually is a non-negative value indicating the severity of concept drift. The greater the value of ∆, the larger the severity of the concept drift is.
概念漂移的严重性是指使用量化值来衡量新概念与先前概念之间的相似性,如图11所示。形式上,概念漂移的严重程度可以表示为∆=δ(Pt(X,y),Pt+1(X,y)),其中δ是衡量两个数据分布差异的函数,t是概念漂移发生的时间戳。∆通常为非负值,表示概念漂移的严重程度。Δ值越大,概念漂移的严重程度越大。
In general, error rate-based drift detection cannot directly measure the severity of concept drift, because it
mainly focuses on monitoring the performance of the learning system, not the changes in the concept itself. However,
the degree of decrease in learning accuracy can be used as an indirect measurement to indicate the severity of concept
drift. If learning accuracy has dropped significantly when drift is observed, this indicates that the new concept is
different from the previous one. For example, the severity of concept drift could be reflected by the difference between pi and pmin in [20], [27], denoted as ∆ ∼ pi − pmin;the difference between overall accuracy pˆhist and recent
accuracy pˆnew in [30], expressed as ∆ ∼ pˆnew − pˆhist; and the difference between test statistics in the former window
E[Xˆcut] and test statistics in the later window E[Yˆi−cut] [23], denoted as ∆ ∼ E [Yˆ ] − E [Xˆ ]. However, the meaning icut cut of these differences is not discussed in existing publications. The ability of error rate-based drift detection to output the severity of concept drift is still vague.
一般来说,基于错误率的漂移检测不能直接测量概念漂移的严重程度,因为它主要关注学习系统的性能,而不是概念本身的变化。然而,学习准确度的下降程度可以作为一个间接的衡量指标来衡量概念漂移的严重程度。当观察到漂移时,如果学习精度显著下降,说明新概念与前一个概念不同。例如,概念漂移的严重性可以通过[20]、[27]中pi和pmin之间的差异来反映,用∆∼pi−pmin表示;整体精度pˆhist和[30]中的最近精度pˆnew之间的差异,用∆∼pˆnew−pˆhist表示;以及前窗口E[Xˆcut]中测试统计数据之间的差异来反映后一个窗口E[Yˆi−cut][23]中的测试统计数据,表示为∆∼E[Yˆ]−E[Xˆ]。然而,现有出版物中并未讨论这些差异的含义。基于误码率的漂移检测对于输出概念漂移严重程度的能力还很模糊。
Data distribution-based drift detection methods can di- rectly quantify the severity of concept drift since the mea- surement used to compare two data samples already reflects the difference. For example, [37] employed a relaxation of the total variation distance dA (S1 , S2 ) to measure the difference between two data distributions. [3] proposed a competence-
based empirical distance dCB(S1,S2) to show the difference between two data samples. Other drift detection methods have used information-theoretic distance; for example,Kullback-Leibler divergence* D(W1||W2), also called relative entropy, was used in the study reported in [22]. The range of these distances is [0, 1]. The greater the distance, the larger the severity of the concept drift is. The distance “1” means that a new concept is different from the pervious one, while the distance “0” means that two data concepts are identical. The test statistic δ used in [38] gives an extremely small negative value if the new concept is quite different from the previous concept. The degree of concept drift in [36] is measured by the resulting p-value of the test statistic W l BF and the defined Angle(Dt,Dt+1) of two datasets Dt and Dt+1
基于数据分布的漂移检测方法可以直接量化概念漂移的严重程度,因为用于比较两个数据样本的测量已经反映了差异。例如,[37]采用了总变化距离dA(S1,S2)的松弛来测量差值在两个数据分布之间。[3] 提出了一种基于能力的经验距离dCB(S1,S2)来表示两个数据样本之间的差异。其他漂移检测方法也使用了信息论距离;例如,Kullback-Leibler散度D(W1 | W2),也称为相对熵,在[22]中的研究中被使用。这些距离的范围是[0,1]。距离越远,概念漂移的严重程度就越大。距离“1”表示新概念与上一个概念不同,距离“0”表示两个数据概念相同。如果新概念与以前的概念大不相同,那么[38]中使用的检验统计量δ给出了一个非常小的负值。[36]中概念漂移的程度是通过测试统计量W l BF的结果p值和两个数据集Dt和Dt+1的定义角度(Dt,Dt+1)来测量的
The severity of concept drift can be used as a guideline for choosing drift adaptation strategies. For example, if the severity of drift in a classification task is low, the decision boundary may not move much in the new concept. Thus, adjusting the current learner by incremental learning will be adequate. In contrast, if the severity of the concept drift is high, the decision boundary could change significantly, therefore discarding the old learner and retraining a new one could be better than incrementally updating the old learner. We would like to mention that, even though some researches have promoted the ability to describe and quan- tify the severity of the detected drift, this information is not yet widely utilized in drift adaptation.
概念漂移的严重程度可以作为选择漂移适应策略的指导。例如,如果分类任务中的偏移严重性较低,则新概念中的决策边界可能不会发生太大的移动。因此,通过渐进式学习来调整当前的学习者就足够了。相反,如果概念漂移的严重程度很高,决策边界可能会发生显著变化,因此抛弃旧学习者并重新培训新学习者比逐步更新旧学习者更好。我们要指出的是,尽管一些研究已经提高了描述和量化检测到的漂移严重程度的能力,但这些信息还没有被广泛地用于漂移适应。
The drift regions of concept drift (Where)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ybt5cdIX-1608124180270)(/Users/liyan/Library/Application Support/typora-user-images/image-20201214223854357.png)]
The drift regions of concept drift are the regions of conflict between a new concept and the previous concept. Drift re- gions are located by finding regions in data feature space X where Pt(X, y) and Pt+1(X, y) have significant difference. To illustrate this, we give an example of a classification task in Fig. 12. The data used in this task are uniformly sampled in the range of [0, 10]2 . The left sub-figure is the data sample accumulated at time t, where the decision boundary is x1 + x2 = 8. The middle sub-figure is the data accumulated at time t + 1, where the decision boundary is x1 + x2 = 9. Intuitively, data located in regions 8 ≤ x1 + x2 < 9 have different classes in time t and time t + 1, since the decision boundary has changed. The right sub-figure shows the data located in the drift regions.
概念漂移的漂移区是新概念与前一概念冲突的区域。通过在数据特征空间X中寻找Pt(X,y)和Pt+1(X,y)存在显著差异的区域来定位漂移区域。为了说明这一点,我们在图12中给出了分类任务的示例。此任务中使用的数据在[0,10]2的范围内统一采样。左子图是在时间t累积的数据样本,其中判定边界为x1+x2=8。中间的子图是在时间t+1处累积的数据,其中判定边界为x1+x2=9。直观地说,由于判定边界已经改变,位于区域8≤x1+x2<9的数据在时间t和时间t+1上具有不同的类别。右子图显示了位于漂移区域的数据。
The techniques to identify drift regions are highly de- pendent on the data model used in the drift detection methods/algorithms. Paper [25] detected drift data in lo- cal regions of the instance space by using online error- rate inside the inner-nodes of a decision tree. The whole data feature space is partitioned by decision tree. Each leaf of this decision tree corresponds to a hyper-rectangle in the data feature space. All leaf nodes contain a drift detector. When the leaf nodes are alerted to a drift, the corresponding hyper-rectangles indicate the regions of drift in the data feature space. Similar to [25], [22] utilized the nodes of the kdq-tree with Kulldorff’s spatial scan statistic to identify the regions in which data had changed the most. Once a drift has been reported, Kulldorff’s statistic measures how the two datasets differ only with respect to the region associated with the leaf node of the kdq-tree. The leaf nodes with the greater statistical value of show the drift regions. [2] highlighted the most severe regions of concept drift through top-p-competence areas. Utilizing the RelatedSets of the competence model, the data feature space is partitioned by a set of overlapping hyperspheres. The RelatedSet-based empirical distance defines the distance between two datasets on a particular hypersphere. The drift regions are identified by the corresponding hyperspheres with large empirical distance at top p% level. [4] identified drift regions by monitoring the discrepancy in the regional density of data, which is called the local drift degree. A local region with a corresponding increase or decrease in density will be highlighted as a critical drift region.
漂移区识别技术高度依赖于漂移检测中使用的数据模型方法/算法。论文[25]利用决策树内部节点的在线错误率检测实例空间局部区域的漂移数据。整 与[25]相似,[22]利用kdq树的节点和Kulldorff的空间扫描统计来识别数据变化最大的区域。一旦报告了一个漂移,Kulldorff的统计方法就可以测量这两个数据集之间的差异,只与kdq树的叶节点相关。统计值较大的叶节点显示了漂移区域。[2] 强调了最严重的领域概念漂移通过最高p能力领域。利用能力模型的相关集,将数据特征空间划分为一组重叠的超球面。基于相关集的经验距离定义了特定超球体上两个数据集之间的距离。漂移区是由对应的在p%水平上具有较大经验距离的超球来识别的。[4] 通过监测区域数据密度的差异来识别漂移区域,称为局部漂移度。密度相应增加或减少的局部区域将突出显示为临界漂移区域。
Locating concept drift regions benefits drift adaptation. Paper [56] pointed out that even if the concept of the entire dataset drifts, there are regions of the feature space that will remain stable significantly longer than other regions. In an ensemble scenario, the old learning models of stable regions could still be useful for predicting data instances located within stable regions, or data instances located in drift regions could be used to build a more updated current model. The authors of [3] also pointed out that identifying drift regions can help in recognizing obsolete data that conflict with current concepts and distinguish noise data from novel data. In their later research [2], they utilized top- p-competence areas to edit cases in a case-based reasoning system for fast new concept switching. One step in their drift adaptation is to remove conflict instances. To preserve as many instances of a new concept as possible, they only remove obsolete conflict instances which are outside the drift regions. LDD-DSDA [4] utilized drift regions as an instance selection strategy to construct a training set that continually tracked a new concept.
定位概念漂移区域有利于漂移适应。论文[56]指出,即使整个数据集的概念发生偏移,特征空间中的某些区域将比其他区域保持稳定的时间长得多。在集成场景中,稳定区域的旧学习模型仍然可以用于预测位于稳定区域内的数据实例,或者可以使用位于漂移区域的数据实例来构建更为更新的当前模型。[3]的作者还指出,识别漂移区域有助于识别与当前概念冲突的过时数据,并将噪声数据与新数据区分开来。在他们后来的研究[2]中,他们利用top-p-capability区域在一个基于案例的推理系统中编辑案例,以实现快速的新概念转换。他们适应漂移的一个步骤是删除冲突实例。为了尽可能多地保留新概念的实例,它们只删除漂移区域之外的过时冲突实例。LDD-DSDA[4]利用漂移区域作为一种实例选择策略来构造一个训练集,持续跟踪一个新概念。
Summary of drift understanding
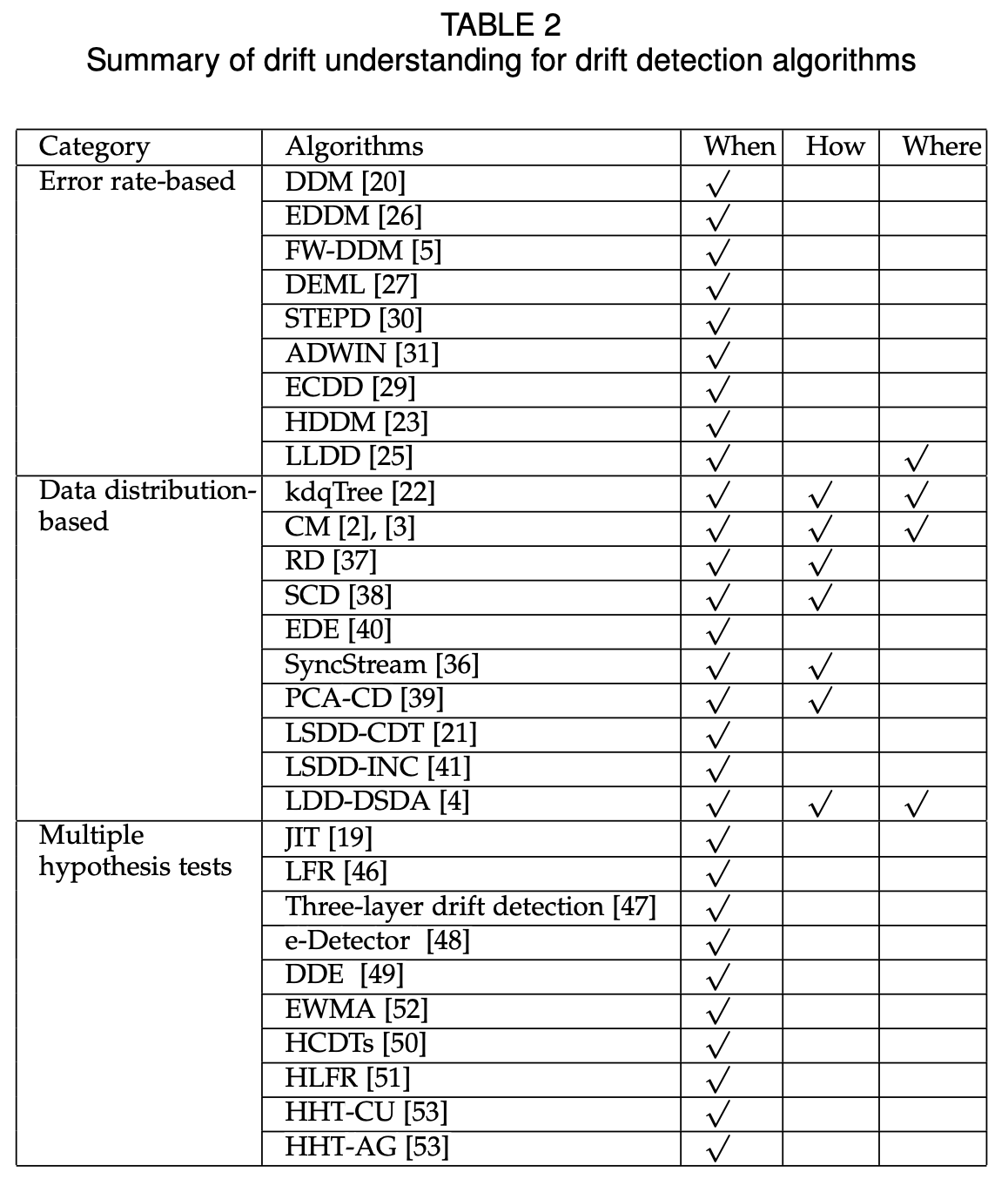
We summarize concept drift detection algorithms according to their ability to identify when, how, and where concept drift occurs, as shown in TABLE 2. All drift detection al- gorithms can identify the occurrence time of concept drift (when), and most data distribution-based drift detection algorithms can also measure the severity of concept drift (how) through the test statistics, but only a few algorithms have the ability to locate drift regions (where).
我们总结了概念漂移检测算法,根据它们识别概念漂移发生的时间、方式和地点的能力,如表2所示。所有的漂移检测算法都能识别概念漂移的发生时间(when),大多数基于数据分布的漂移检测算法也能通过测试统计量来衡量概念漂移的严重程度(how),但只有少数算法能够定位漂移区域(where)。
Drift Adapatation
This section focuses on strategies for updating existing learning models according to the drift, which is known as drift adaptation or reaction. There are three main groups of drift adaptation methods, namely simple retraining, en- semble retraining and model adjusting, that aim to handle different types of drift.
本节重点介绍根据漂移更新现有学习模型的策略,即漂移适应或反应。针对不同类型的漂移,主要有三类漂移适应方法,即简单再训练、组合再训练和模型调整。
Training new models for global drift
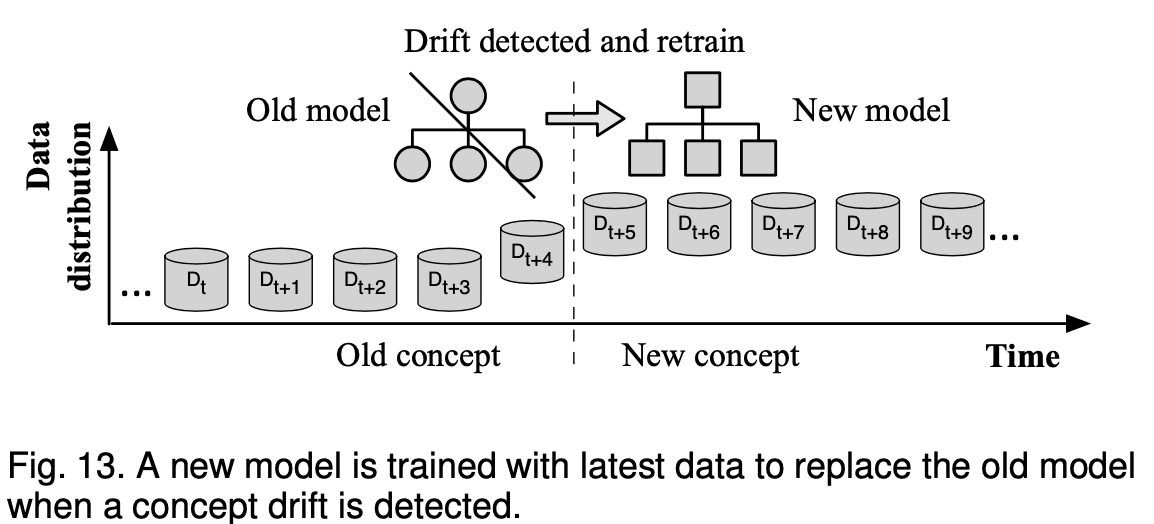
Perhaps the most straightforward way of reacting to concept drift is to retrain a new model with the latest data to replace the obsolete model, as shown in Fig. 13. An explicit concept drift detector is required to decide when to retrain the model (see Section 3 on drift detection). A window strategy is often adopted in this method to preserve the most recent data for retraining and/or old data for distribution change test. Paired Learners [57] follows this strategy and uses two learners: the stable learner and the reactive learner. If the stable learner frequently misclassifies instances that the reactive learner correctly classifies, a new concept is detected and the stable learner will be replaced with the reactive learner. This method is simple to understand and easy to implement, and can be applied at any point in the data stream.
也许应对概念漂移最直接的方法是用最新的数据重新训练一个新的模型来代替过时的模型,如图13所示。需要一个明确的概念漂移检测器来决定何时重新训练模型(见第3节漂移检测)。该方法通常采用窗口策略来保存最新的数据用于再训练和/或保留旧数据用于分布变化测试。配对学习者[57]遵循这一策略,使用两个学习者:稳定学习者和反应性学习者。如果稳定学习者经常对反应性学习者正确分类的实例进行错误分类,则会检测到一个新的概念,并将稳定学习者替换为反应性学习者。该方法简单易懂,易于实现,可应用于数据流中的任何一点。
When adopting a window-based strategy, a trade-off must be made in order to decide an appropriate window size. A small window can better reflect the latest data distribution, but a large window provides more data for training a new model. A popular window scheme algorithm that aims to mitigate this problem is ADWIN [31]. Unlike most earlier works, it does not require the user to guess a fixed size of the windows being compared in advance; instead, it examines all possible cuts of the window and computes optimal sub-window sizes according to the rate of change between the two sub-windows. After the optimal window cut has been found, the window containing old data is dropped and a new model can be trained with the latest window data.
当采用基于窗口的策略时,必须进行权衡,以确定合适的窗口大小。小窗口可以更好地反映最新的数据分布,但大窗口为训练新模型提供了更多的数据。ADWIN[31]是一种流行的窗口方案算法,旨在缓解这一问题。与大多数早期的工作不同,它不需要用户预先猜测正在比较的窗口的固定大小;相反,它检查窗口的所有可能的剪切,并根据两个子窗口之间的变化率计算最佳子窗口大小。找到最优窗口切割后,删除包含旧数据的窗口,并用最新的窗口数据训练新模型。
Instead of directly retraining the model, researchers have also attempted to integrate the drift detection process with the retraining process for specific machine learning algorithms. DELM [27] extends the traditional ELM algo- rithm with the ability to handle concept drift by adaptively adjusting the number of hidden layer nodes. When the classification error rate increases — which could indicate the emergence of a concept drift — more nodes are added to the network layers to improve its approximation capability. Similarly, FP-ELM [58] is an ELM-extended method that adapts to drift by introducing a forgetting parameter to the ELM model. A parallel version of ELM-based method [59] has also been developed for high-speed classification tasks under concept drift. OS-ELM [60] is another online learning ensemble of repressor models that integrates ELM using an ordered aggregation (OA) technique, which overcomes the problem of defining the optimal ensemble size.
研究人员并没有直接对模型进行再训练,而是尝试将漂移检测过程与特定机器学习算法的再训练过程结合起来。DELM[27]扩展了传统的ELM算法,通过自适应地调整隐藏层节点的数量来处理概念漂移。当分类错误率增加时(这可能表明概念漂移的出现),更多的节点被添加到网络层以提高其逼近能力。同样,FP-ELM[58]是一种ELM扩展方法,它通过在ELM模型中引入遗忘参数来适应漂移。基于ELM的方法[59]的并行版本也被开发用于概念漂移下的高速分类任务。OS-ELM[60]是另一种在线学习的抑制因子模型集成,它使用有序聚合(OA)技术集成ELM,克服了定义最佳集成规模的问题。
Instance-based lazy learners for handling concept drift have also been studied intensively. The Just-in-Time adaptive classifier [19], [42] is such a method which follows the ”detect and update model” strategy. For drift detection, it extends the traditional CUSUM test [61] to a pdf-free form. This detection method is then integrated with a kNN classifier [42]. When a concept drift is detected, old instances (more than the last T samples) are removed from the case base. In later work, the authors of [11], [45] extended this algorithm to handle recurrent concepts by computing and comparing current concept to previously stored concepts. NEFCS [2] is another kNN-based adaptive model. A compe- tence model-based drift detection algorithm [3] was used to locate drift instances in the case base and distinguish them from noise instances and a redundancy removal algorithm, Stepwise Redundancy Removal (SRR), was developed to remove redundant instances in a uniform way, guaranteeing that the reduced case base would still preserve enough information for future drift detection.
基于实例的懒惰学习者处理概念漂移的研究也得到了深入的研究。实时自适应分类器[19],[42]就是这样一种遵循“检测和更新模型”策略的方法。对于漂移检测,它将传统的CUSUM检验[61]扩展到pdf自由形式。然后将这种检测方法与kNN分类器结合起来[42]。当检测到概念偏移时,旧实例(多于最后的T个样本)将从案例库中移除。在后来的工作中,文献[11],[45]的作者通过计算和比较当前概念和先前存储的概念,扩展了该算法来处理递归概念。NEFCS[2]是另一种基于kNN的自适应模型。基于竞争模型的漂移检测算法[3]用于在实例库中定位漂移实例并将其与噪声实例区分开来,并开发了一种冗余消除算法,即逐步冗余删除(SRR),以统一的方式删除冗余实例,保证减少的案例库仍能为将来的漂移检测保留足够的信息。
Model ensemble for recurring drift
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bPY5bZFR-1608124180272)(/Users/liyan/Library/Application Support/typora-user-images/image-20201216150305479.png)]
In the case of recurring concept drift, preserving and reusing old models can save significant effort to retrain a new model for recurring concepts. This is the core idea of using ensemble methods to handle concept drift. Ensemble meth- ods have received much attention in stream data mining research community in recent years. Ensemble methods comprise a set of base classifiers that may have different types or different parameters.The output of each base classifier is combined using certain voting rules to predict the newly arrived data. Many adaptive ensemble methods have been developed that aim to handle concept drift by extending classical ensemble methods or by creating specific adaptive voting rules. An example is shown in Fig. 14, where new base classifier is added to the ensemble when concept drift occurs.
在重复出现的概念漂移的情况下,保留和重用旧模型可以节省为重复概念重新训练新模型所做的大量工作。这是使用集成方法处理概念漂移的核心思想。近年来,集成方法在流数据挖掘领域受到了广泛的关注。集成方法包括一组可能具有不同类型或不同参数的基本分类器。每个基地的产量分类器是利用一定的投票规则组合起来预测新到达的数据。许多自适应集成方法已经被开发出来,目的是通过扩展经典集成方法或创建特定的自适应投票规则来处理概念漂移。图14示出了一个例子,其中当概念漂移发生时,新的基本分类器被添加到集成中。
Bagging, Boosting and Random Forests are classical ensemble methods used to improve the performance of single classifiers. They have all been extended for handling streaming data with concept drift. An online version of the bagging method was first proposed in [62] which uses each instance only once to simulate the batch mode bagging. In a later study [63], this method was combined with the ADWIN drift detection algorithm [31] to handle concept drift. When a concept drift is reported, the newly proposed method, called Leveraging Bagging, trains a new classifier on the latest data to replace the existing classifier with the worst performance. Similarly, an adaptive boosting method was developed in [64] which handles concept drift by moni- toring prediction accuracy using a hypothesis test, assuming that classification errors on non-drifting data should follow Gaussian distribution. In a recent work [35], the Adaptive Random Forest (ARF) algorithm was proposed, which ex- tends the random forest tree algorithm with a concept drift detection method, such as ADWIN [31], to decide when to replace an obsolete tree with a new one. A similar work can be found in [65], which uses Hoeffding bound to distinguish concept drift from noise within decision trees.
Bagging、Boosting和Random-Forests是提高单个分类器性能的经典集成方法。它们都被扩展到处理流数据的概念漂移。在[62]中首次提出了一种在线版本的bagging方法,它只使用每个实例一次来模拟批处理模式的bagging。在后来的研究[63]中,该方法与ADWIN漂移检测算法[31]相结合,以处理概念漂移。当一个概念漂移被报告时,新提出的方法称为杠杆Bagging,根据最新数据训练一个新的分类器,以取代性能最差的现有分类器。类似地,在[64]中开发了一种自适应boosting方法,该方法通过使用假设检验监测预测精度来处理概念漂移,假设非漂移数据的分类误差应服从高斯分布。在最近的一项工作[35]中,提出了自适应随机森林(ARF)算法,该算法将随机森林树算法与概念漂移检测方法(如ADWIN[31])扩展,以决定何时用新的树替换过时的树。类似的工作可以在[65]中找到,它使用hoefffding定界来区分决策树中的概念漂移和噪声。
Besides extending classical methods, many new ensem- ble methods have been developed to handle concept drift using novel voting techniques. Dynamic Weighted Majority (DWM) [66] is such an ensemble method that is capable of adapting to drifts with a simple set of weighted voting rules. It manages base classifiers according to the performance of both the individual classifiers and the global ensemble. If the ensemble misclassifies an instance, DWM will train a new base classifier and add it to ensemble. If a base classifier misclassifies an instance, DWM reduces its weight by a factor. When the weight of a base classifier drops below a user defined threshold, DWM removes it from the ensemble. The drawback of this method is that the adding classifier process may be triggered too frequently, introducing performance issues on some occasions, such as when gradual drift occurs. A well-known ensemble method, Learn++NSE [67], mitigates this issue by weighting base classifiers according to their prediction error rate on the latest batch of data. If the error rate of the youngest classifier exceeds 50%, a new classifier will be trained based on the latest data. This method has several other benefits: it can easily adopt almost any base classifier algorithm; it does not store history data, only the latest batch of data, which it only uses once to train a new classifier; and it can handle sudden drift, gradual drift, and recurrent drift because underperforming classifiers can be reactivated or deactivated as needed by adjusting their weights. Other voting strategies than standard weighted voting have also been applied to handle concept drift. Examples include hierarchical ensemble structure [68], [69], short term and long term memory [13], [70] and dynamic ensemble sizes [71], [72].
除了扩展经典方法外,许多新的综合方法也被开发出来,用新的投票技术来处理概念漂移。动态加权多数(DWM)[66]是一种集成方法,能够通过一组简单的加权投票规则来适应漂移。它根据单个分类器和全局集成的性能来管理基本分类器。如果集成错误地分类了一个实例,DWM将训练一个新的基本分类器并将其添加到集成中。如果一个基本分类器错误地对一个实例进行分类,DWM会将其权重减少一个因子。当基本分类器的权重下降到用户定义的阈值以下时,DWM会将其从集成中移除。这种方法的缺点是添加分类器的过程可能触发得太频繁,在某些情况下会引入性能问题,例如当出现逐渐漂移时。一种著名的集成方法Learn++NSE[67],通过根据基分类器对最新一批数据的预测错误率加权,来缓解这一问题。如果最小分类器的错误率超过50%,则根据最新数据训练新的分类器。这种方法还有其他几个好处:它可以很容易地采用几乎任何基本分类器算法;它不存储历史数据,只存储最新一批数据,它只使用一次来训练一个新的分类器;它可以处理突然漂移、逐渐漂移和反复漂移,因为性能不佳的分类器可以根据需要通过调整其权重来重新激活或停用。除标准加权投票外,其他的投票策略也被用于处理概念漂移。示例包括层次集成结构[68]、[69]、短期和长期内存[13]、[70]和动态集成大小[71]、[72]。
A number of research efforts have been made that focus on developing ensemble methods for handling concept drift of certain types. Accuracy Update Ensemble (AUE2) [73] was proposed with an emphasis on handling both sudden drift and gradual drift equally well. It is a batch mode weighted voting ensemble method based on incremental base classifiers. By doing re-weighting, the ensemble is able react quickly to sudden drift. All classifiers are also incrementally trained with the latest data, which ensures that the ensemble evolves with gradual drift. The Optimal Weights Adjustment (OWA) method [74] achieves the same goal by building ensembles using both weighted instances and weighted classifiers for different concept drift types. The authors of [75] considered a special case of concept drift — class evolution — the phenomenon of class emergence and disappearance. Recurring concepts are handled in [76], [77], which monitor concept information to decide when to reactivate previously stored obsolete models. [78] is another method that handles recurring concepts by refining the concept pool to avoid redundancy.
为了解决某些类型的概念漂移问题,人们进行了大量的研究工作。提出了精度更新系综(AUE2)[73],重点是处理好突发漂移和渐变漂移。它是一种基于增量基分类器的批模式加权投票集成方法。通过重新加权,该系综能够对突然漂移做出快速反应。所有的分类器都使用最新的数据进行增量训练,从而保证了集成的渐进性。最优权重调整(OWA)方法[74]通过使用加权实例和加权分类器为不同的概念漂移类型构建集成来实现相同的目标。[75]的作者考虑了概念漂移的一个特例——阶级进化——阶级产生和消失的现象。重复出现的概念在[76]、[77]中处理,它们监控概念信息,以决定何时重新激活先前存储的过时模型。[78]是另一种处理重复出现的概念的方法,它通过细化概念池来避免冗余。
Adjusting existing models for regional drift
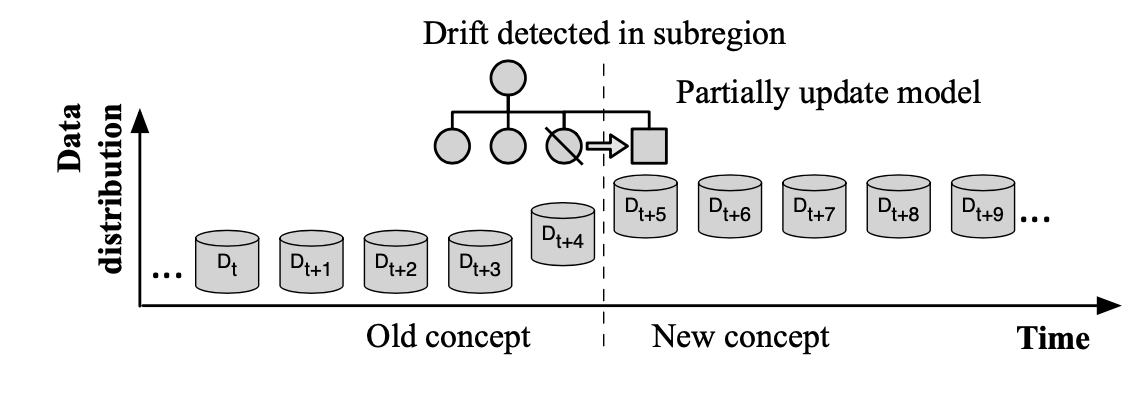
An alternative to retraining an entire model is to develop a model that adaptively learns from the changing data. Such models have the ability to partially update themselves when the underlying data distribution changes, as shown in Fig. 15. This approach is arguably more efficient than retraining when the drift only occurs in local regions. Many methods in this category are based on the decision tree algorithm because trees have the ability to examine and adapt to each sub-region separately.
对整个模型进行再培训的另一种方法是开发一种从不断变化的数据中自适应学习的模型。如图15所示,当基础数据分布发生变化时,这些模型能够部分地自我更新。当漂移只发生在局部地区时,这种方法可以说比再培训更有效。这类方法中的许多方法都是基于决策树算法的,因为树具有分别检查和适应每个子区域的能力。
In a foundational work [79], an online decision tree algorithm, called Very Fast Decision Tree classifier (VFDT) was proposed, which is especially tailored for high speed data streams. It uses Hoeffding bound to limit the num- ber of instances required for node splitting. This method has become very popular because of its several distinct advantages: 1) it only needs to process each instance once and does not store instances in memory or disk; 2) the tree itself only consumes a small amount of space and does not grow with the number of instances it processes unless there is new information in the data; 3) the cost of tree maintenance is very low. An extended version, called CVFDT [80], was later proposed to handle concept drift. In CVFDT, a sliding window is maintained to hold the latest data. An alternative sub-tree is trained based on the window and its performance is monitored. If the alternative sub- tree outperforms its original counterpart, it will be used for future prediction and the original obsolete sub-tree will be pruned. VFDTc [81] is another attempt to make improve- ments to VFDT with several enhancements: the ability to handle numerical attributes; the application of naive Bayes classifiers in tree leaves and the ability to detect and adapt to concept drift. Two node-level drift detection methods were proposed based on monitoring differences between a node and its sub-nodes. The first method uses classification error rate and the second directly checks distribution difference. When a drift is detected on a node, the node becomes a leaf and its descending sub-tree is removed. Later work [82], [83] further extended VFDTc using an adaptive leaf strategy that chooses the best classifier from three options: majority voting, Naive Bayes and Weighted Naive Bayes.
在一项基础工作[79]中,提出了一种在线决策树算法,称为快速决策树分类器(VFDT),它特别适合于高速数据流。它使用hoefffding定界来限制节点拆分所需的实例数。这种方法因其独特的优点而广受欢迎:1)它只需处理每个实例一次,不需要将实例存储在内存或磁盘中;2)在树本身只消耗少量空间,并且不会随着它处理的实例数的增加而增长,除非数据中有新的信息;3)树的维护成本非常低。后来提出了一个扩展版本,称为CVFDT[80],以处理概念漂移。在CVFDT中,保持一个滑动窗口来保存最新的数据。基于该窗口训练了一个备选子树,并对其性能进行了监控。如果替代子树的性能优于原始子树,则它将用于未来的预测,并对原始过时子树进行修剪。vfdc[81]是对VFDT进行改进的又一次尝试,有几个增强:处理数值属性的能力;朴素Bayes分类器在树叶中的应用,以及检测和适应概念漂移的能力。提出了两种基于监测节点与子节点间差异的节点级漂移检测方法。第一种方法使用分类错误率,第二种方法直接检查分布差异。当在一个节点上检测到漂移时,该节点将成为一个叶子,并删除其降序子树。后来的工作[82],[83]进一步扩展了VFDTc,使用自适应叶策略从三个选项中选择最佳分类器:多数投票、朴素贝叶斯和加权朴素贝叶斯。
Despite the success of VFDT, recent studies [84], [85] have shown that its foundation, the Hoeffding bound, may not be appropriate for the node splitting calculation because the variables it computes, the information gain, are not independent. A new online decision tree model [86] was developed based on an alternative impurity measure. The paper shows that this measure also reflects concept drift and can be used as a replacement measure in CVFDT. In the same spirit, another decision tree algorithm (IADEM-3) [87] aims to rectify the use of Hoeffding bound by computing the sum of independent random variables, called relative frequencies. The error rate of sub-trees are monitored to detect drift and are used for tree pruning.
尽管VFDT的成功,最近的研究(84),[85 ]已经表明,它的基础,Hooffin界,可能不适合于节点分裂计算,因为它计算的变量,信息增益,不是独立的。基于替代杂质测度,提出了一种新的在线决策树模型[86]。研究表明,该方法也反映了概念漂移,可以作为CVFDT的替代措施。本着同样的精神,另一种决策树算法(IADEM-3)[87]旨在通过计算独立随机变量的和(称为相对频率)来纠正hoefffding定界的使用。通过监测子树的错误率来检测漂移,并用于树的修剪。
Evaluation,Datasets and Benchmarks
Section 6.1 discusses the evaluation systems used for learn- ing algorithms handling concept drift. Section 6.2 introduces synthetic datasets, which used to simulate specific and controllable types of concept drift. Section 6.3 describes real- world datasets, which used to test the overall performance in a real-life scenario.
第6.1节讨论了用于学习处理概念漂移的算法的评估系统。第6.2节介绍了合成数据集,这些数据集用于模拟特定和可控类型的概念漂移。第6.3节描述了真实世界的数据集,这些数据集用于测试真实场景中的总体性能。
Evaluation Systemes
The evaluation systems is an important part for learning algorithms. Some evaluation methodologies used in learn- ing under concept drift have been mentioned in [8]. We enrich this previous research by reviewing the evaluation systems from three aspects: 1) validation methodology, 2) evaluation metrics, and 3) statistical significance, and each evaluation is followed by its computation equation and usage introduction.
评价系统是学习算法的重要组成部分。在[8]中提到了一些在概念漂移下学习的评价方法。我们从验证方法、评价指标和统计显著性三个方面对评价体系进行了回顾,丰富了以往的研究成果,并对每种评价方法进行了计算公式和使用说明。
Validation methodology refers to the procedure for a learning algorithm to determine which data instances are used as the training set and which are used as the testing set. There are three procedures peculiar to the evaluation for learning algorithms capable of handling concept drift: 1) holdout, 2) prequential, and 3) controlled permutation. In the scenario of a dataset involving concept drift, holdout should follow the rule: when testing a learning algorithm at time t, the holdout set represents exactly the same concept at that time t. Unfortunately, it is only applied on synthetic datasets with predefined concept drift times. Prequential is a popular evaluation scheme used in streaming data. Each data instance is first used to test the learning algorithm, and then to train the learning algorithm. This scheme has the advantage that there is no need to know the drift time of concepts, and it makes maximum use of the available data. The prequential error is computed based on an accumulated sum of a loss function between the prediction and observed label: S = nt=1 f (yˆt , yt ). There are three prequential error rate estimates: a landmark window (interleaved-test-then- train), a sliding window, and a forgetting mechanism [88]. Controlled permutation [89] runs multiple test datasets in which the data order has been permutated in a controlled way to preserve the local distribution, which means that data instances that were originally close to one another in time need to remain close after a permutation. Controlled permutation reduces the risk that their prequential evalua- tion may produce biased results for the fixed order of data in a sequence.
验证方法是指学习算法确定哪些数据实例用作训练集,哪些作为测试集的过程。对于能够处理概念漂移的学习算法,有三种评估程序:1) 维持,2)前序,3)控制置换。在涉及概念漂移的数据集场景中,holdout应该遵循这样的规则:在t时刻测试一个学习算法时,holdout集在t时刻代表完全相同的概念,不幸的是,它只适用于预先定义了概念漂移时间的合成数据集。Prequential是一种流行的流数据评估方法。每个数据实例首先用来测试学习算法,然后训练学习算法。该方案的优点是不需要知道概念的漂移时间,并且最大限度地利用了现有的数据。根据预测值与观测值之间的损失函数的累计和,计算前期误差:S=𛋍nt=1f(yˆt,yt)。有三个预先的错误率估计:一个地标窗口(交叉测试然后-训练),一个滑动窗口和一个遗忘机制[88]。受控置换[89]运行多个测试数据集,在这些数据集中,数据顺序以受控方式进行了置换,以保持局部分布,这意味着原本在时间上彼此接近的数据实例在置换之后需要保持接近。控制排列降低了它们的预先评估可能对序列中固定顺序的数据产生偏差结果的风险。
Evaluation metrics for datasets involving concept driftcould be selected from traditional accuracy measures, suchas precision/recall in retrieval tasks, mean absolute scalederror in regression, or root mean square error in recom-mender systems. In addition to that, the following measuresshould be examined: 1)RAM-hours[90] for the computationcost of the mining process; 2)Kappa statisticκ=p−pran1−pran[91] for classification taking into account class imbalance,wherepis the accuracy of the classifier under consideration(reference classifier) andpranis the accuracy of the randomclassifier; 3)Kappa-Temporal statisticκper=p−pper1−pper[92] for theclassification of streaming data with temporal dependence,wherepperis the accuracy of the persistent classifier (a clas-sifier that predicts the same label as previously observed);4)Combined Kappa statisticκ+=√max(0,κ) max(0,κper)[92], which combines theκandκperby taking the geometricaverage; 5)Prequential AUC[93]; and6)theAveragedNor-malizedAreaUndertheCurve(NAUC)valuesforPreci-sion-RangecurveandRecall-Rangecurve[53], for the clas-sification of streaming data involving concept drift. Apartfrom evaluating the performance of learning algorithms, theaccuracy of the concept drift detection method/algorithmcan be accessed according to the following criteria: 1)truedetection rate, 2)false detection rate, 3)miss detection rate, and4) delay of detection [22].
涉及概念漂移的数据集评价指标可以从传统的精度度量中选择,如检索任务的精度/召回率、回归中的平均绝对标度误差或推荐系统中的均方根误差。除此之外,还应检查以下措施:1)采矿过程计算成本的RAM小时数[90];2)考虑到类别不平衡的分类,Kappa统计κ=p−pran1−pran[91],式中,Pis为考虑中的分类器(参考分类器)的精度,Pranis为随机分类器的精度;3)Kappa时间统计κper=p−pper1−pper[92],用于对具有时间相关性的流数据进行分类,其中Pepper是持久分类器(预测与先前观察到);4)组合Kappa统计量κ+=√max(0,κ)max(0,κper)[92],其结合了κ和κperby取几何平均值;5)预测AUC[93];和6)平均malizedAreaUndertheCurve(NAUC)值,用于概念漂移流数据的分类。从评估学习算法的性能开始,概念漂移检测方法/算法的准确性可根据以下标准进行评估:1)真实检测率,2)错误检测率,3)漏检率,4)检测延迟[22].
Statistical significance is used to compare learning algo- rithms on achieved error rates. The three most frequently used statistical tests for comparing two learning algorithms [94], [95] are: 1) McNemar test [96]: denote the number of data instances misclassified by the first classifier and correctly classified by the second classifier by a, and denote b in the opposite way. The McNemar statistic is computed as M = sign(a−b)×(a−b)2/(a+b) to test whether two classifiers perform equally well. The test follows the χ2 distribution; 2) Sign test: for N data instances, denote the number of data instances misclassified by the first classifier and correctly classifi

统计显著性被用来比较学习算法对获得的错误率。比较两种学习算法[94]、[95]的三种最常用的统计测试是:1)McNemar测试[96]:表示第一个分类器错误分类的数据实例数,第二个分类器正确分类的数据实例数由a表示,反之亦然。McNemar统计量计算为M=符号(a−b)×(a−b)2/(a+b),以测试两个分类器的性能是否相同。检验遵循χ2分布;2)符号检验:对于N个数据实例,表示第一个错误分类的数据实例数通过计算p=𛋍N−TN−TN−TN−TN−T−0.5N−T−k进行单侧符号检验,如果k=B k p小于有效水平,则第二分类器优于第一分类器。3)Wilcoxon的符号秩检验:在N个数据集上进行两个分类器的测试,分别设席席、1、西、2(i=1,…,N)表示测量值。联系数为T和NR=n,t。检验统计量W=nr(符号(Xi,1,Xi,2)×Ri),其中Ri是I=1的排序,由席席,1席席,2乘。如果| W |>Wcritical,Nr(双面),则两个分类器的性能相等被拒绝,其中Wcritical,Nr可以从统计表中获得。所有三个测试都是非参数测试。Nemenyi测试[97]用于比较两种以上的学习算法。这是一个比较所有学习算法与多个数据集的适当测试,基于算法在所有数据集中的平均排名。Nemenyi测试由以下内容组成:如果相应的平均等级至少相差临界差CD=qαk(k+1)/6N,其中k是学习者的数量,N是数据集的数量,临界值q是基于学习范围统计除以α12√+4)组合Kappa统计量κ=max(0,2。其他测试可以用来比较学习算法和控制算法[97]。
Synthetic Datasets
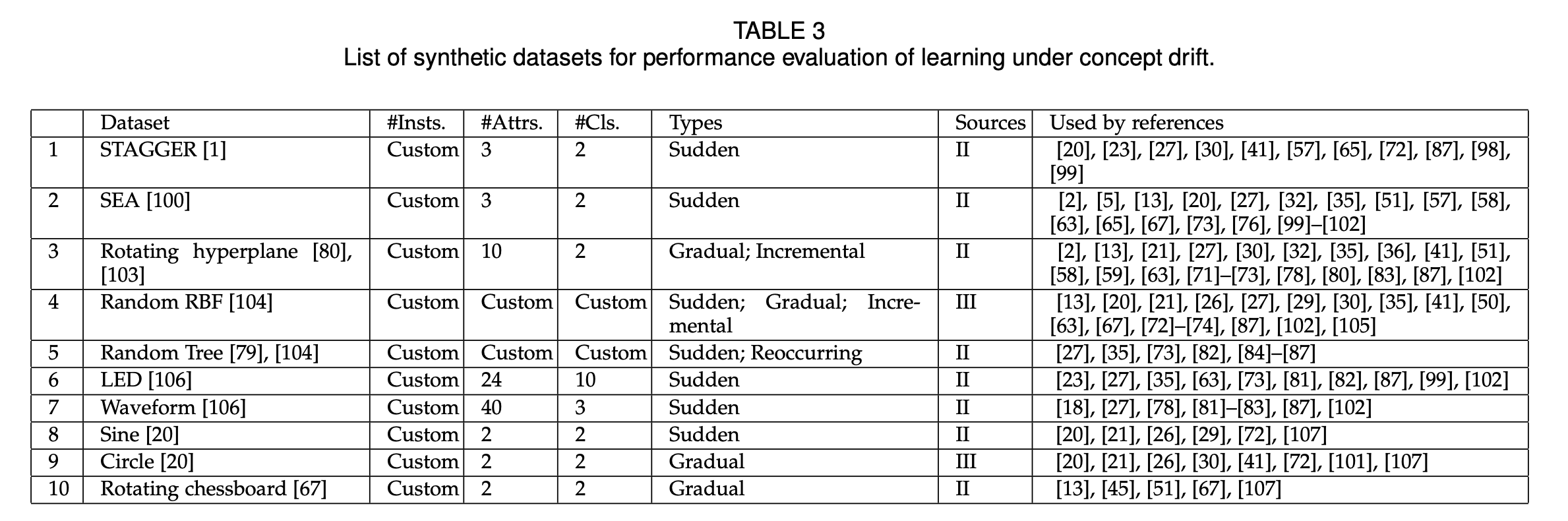
We list several widely used synthetic datasets for evaluat- ing the performance of learning algorithms dealing with concept drift. Since data instances are generated by prede- fined rules and specific parameters, a synthetic dataset is a good option for evaluating the performance of learning algorithms in different concept drift scenarios. The dataset provider, the number of instances (#Insts.), the number of attributes (#Attrs.), the number of classes (#Cls.), types of drift (Types), sources of drift (Sources), and used by references, are listed in TABLE 3.
我们列出了几种广泛使用的综合数据集,用于评估处理概念漂移的学习算法的性能。由于数据实例是由预先定义的规则和特定的参数生成的,因此合成数据集是评估学习算法在不同概念漂移场景下性能的一个很好的选择。表3列出了数据集提供程序、实例数(#Insts.)、属性数(#Attrs.)、类数(#Cls.)、漂移类型(types)、漂移源(sources)以及被引用使用。
Real-World Datasets
In this section, we collect several publicly available real- world datasets, including real-world datasets with syn- thetic drifts. The dataset provider, the number of instances (#Insts.), the number of attributes (#Attrs.), the number of classes (#Cls.), and used by references, are shown in TABLE 4.
Most of these datasets contain temporal concept drift spanning over different period range - e.g. daily (Sensor [108]), seasonally (Electricity [109]) or yearly (Airlines [104], [67]). Others include geographical (Covertype [106]) or categorical (Poker-Hand [106]) concept drift. Certain datesets, mainly text based, are targeting at specific drift types, such as sudden drift (Email data [110]), gradural drift (Spam assassin corpus [111]), recurrent drift (Usenet [112]) or novel class (KDDCup’99 [106], ECUE drift
dataset 2 [113])
在本节中,我们将收集几个公开可用的真实世界数据集,包括具有同步漂移的真实世界数据集。表4显示了数据集提供程序、实例数(#Insts.)、属性数(#Attrs.)、类数(#Cls.),以及由引用使用。
大多数这些数据集包含跨越不同时期范围的时间概念漂移,例如每天(传感器[108])、季节性(电力[109])或每年(航空公司[104]、[67])。其他包括地理(隐蔽型[106])或分类(扑克手[106])概念漂移。某些主要基于文本的数据集针对特定的漂移类型,例如突发漂移(Email data[110])、渐变漂移(Spam assiber corpus[111])、重复漂移(Usenet[112])或新颖类(KDDCup’99[106],ECUE漂移数据集2[113])
These datasets provide realistic benchmark for evaluating differnent concept drift handling methods. There are, however, two limitations of real world data sets: 1) the groud truth of precise start and end time of drifts is un- known; 2) some real datasets may include mixed drift types. These limitations make it difficult to evaluate methods for understanding the drift, and could introduce bias when comparing different machine learning models.
这些数据集为评估不同的概念漂移处理方法提供了现实的基准。然而,真实世界的数据集有两个局限性:1)漂移的精确开始和结束时间的真实性未知;2)一些实际数据集可能包含混合漂移类型。这些局限性使得评估了解漂移,并可能在比较不同的机器学习模型时引入偏差。
The Concept Drift Problem In Other Research Areas
We have observed that handling the concept drift problem is not a standalone research subject but has a large number of indirect usage scenarios. In this section, we adopt this new perspective to review recent developments in other research areas that benefit from handling the concept drift problem.
我们注意到,处理概念漂移问题不是一个独立的研究课题,而是有大量的间接使用场景。在这一部分中,我们采用这个新的视角来回顾其他研究领域的最新进展,这些领域得益于处理概念漂移问题。
Class imbalance
Class imbalance is a common problem in stream data min- ing in addition to concept drift. Research effort has been made to develop effective learning algorithms to tackle both problems at same time. [117] presented two ensemble methods for learning under concept drift with imbalanced class. The first method, Learn++.CDS, is extended from Learn++.NSE and combined with the Synthetic Minority class Oversampling Technique (SMOTE). The second al- gorithm, Learn++.NIE, improves on the previous method by employing a different penalty constraint to prevent prediction accuracy bias and replacing SMOTE with bag- ging to avoid oversampling. ESOS-ELM [118] is another ensemble method which uses Online Sequential Extreme Learning Machine (OS-ELM) as a basic classifier to improve performance with class imbalanced data. A concept drift detector is integrated to retrain the classifier when drift occurs. The author then developed another algorithm [119], which is able to tackle multi-class imbalanced data with concept drift. [120] proposed two learning algorithms OOB and UOB, which build an ensemble model to overcome the class imbalance in real time through resampling and time-decayed metrics. [121] developed an ensemble method which handles concept drift and class imbalance with addi- tional true label data limitation.
类不平衡是流数据挖掘中除概念漂移外的一个常见问题。研究人员致力于开发有效的学习算法来同时解决这两个问题。[117]提出了两种非平衡类概念漂移下的集成学习方法。第一种方法Learn++.CDS是在Learn++.NSE的基础上扩展而来的,并与合成少数类过采样技术(SMOTE)相结合。第二个算法Learn++.NIE改进了前面的方法,通过使用不同的惩罚约束来防止预测精度偏差,并用包封代替SMOTE以避免过采样。ESOS-ELM[118]是另一种集成方法,它使用在线序列极端学习机(OS-ELM)作为基本分类器,以改善类不平衡数据的性能。集成了一个概念漂移检测器,在发生漂移时对分类器进行再训练。然后,作者开发了另一种算法[119],该算法能够处理具有概念漂移的多类不平衡数据。[120]提出了OOB和UOB两种学习算法,通过重采样和时间衰减度量,建立了一个集成模型来实时克服类不平衡。[121]开发了一种集成方法,该方法处理概念漂移和类不平衡,并附加了真实标签数据的限制。
Big Data Mining
Data mining in big data environments faces similar chal- lenges to stream data mining [122]: data is generated at a fast rate (Velocity) and distribution uncertainty always exists in the data, which means that handling concept drift is also crucial in big data applications. Additionally, scalability is an important consideration because in big data environ- ments, a data stream may come in very large and potentially unpredictable quantities (Volume) and cannot be processed in a single computer server. An attempt to handle concept drift in a distributed computing environment was made by [123] in which an Online Map-Reduce Drift Detection Method (OMR-DDM) was proposed, using the combined online error rate of the parallel classification algorithms to identify the changes in a big data stream. A recent study [124] proposed another scalable stream data mining algo- rithm, called Micro-Cluster Nearest Neighbor (MC-NN), based on nearest neighbor classifier. This method extends the original Micro-Cluster algorithm [125] to adapt to con- cept drift by monitoring classification error. This micro- cluster algorithm was further extended to a parallel version using the map-reduce technique in [126] and applied to solve the label-drift classification problem where class labels are not known in advance [127].
大数据环境下的数据挖掘面临着与流式数据挖掘相似的挑战[122]:数据以快速的速度(速度)生成,数据中始终存在分布不确定性,这意味着处理概念漂移在大数据应用中也至关重要。此外,可扩展性这是一个重要的考虑因素,因为在大数据环境中,一个数据流的数量可能非常大,而且可能不可预测,因此无法在单个计算机服务器上进行处理。[123]尝试在分布式计算环境中处理概念漂移,提出了一种在线地图减少漂移检测方法(OMR-DDM),利用并行分类算法的联合在线错误率来识别大数据流中的变化。最近的一项研究[124]提出了另一种基于最近邻分类器的可伸缩流数据挖掘算法,称为微集群最近邻(MC-NN)。该方法扩展了原有的微聚类算法[125],通过监测分类误差来适应漂移。在文献[126]中,利用map-reduce技术将这种微聚类算法进一步扩展到并行版本,并应用于解决类标签未知的标签漂移分类问题[127]。
Active Learning and semi-supervised learning
Active learning is based on the assumption that there is a large amount of unlabeled data but only a fraction of them can be labeled by human effort. This is a common situation in stream data applications, which are often also subject to the concept drift problem. [115] presented a general frame- work that combines active learning and concept drift adap- tation. It first compares different instance-sampling strate- gies for labeling to guarantee that the labeling cost will be under budget, and that distribution bias will be prevented. A drift adaptation mechanism is then adopted, based on the DDM detection method [20]. In [128], the authors proposed a new active learning algorithm that primarily aims to avoid bias in the sampling process of choosing instances for labeling. They also introduced a memory loss factor to the model, enabling it to adapt to concept drift.
主动学习是基于这样一个假设,即存在大量未标记的数据,但只有一小部分数据可以通过人工标注。这是流数据应用中常见的情况,它也常常受到概念漂移问题的影响。[115]提出了一个结合主动学习和概念漂移适应的一般框架。首先比较了不同实例的标签抽样策略,以保证标签成本在预算之内,防止分布偏差。然后基于DDM检测方法采用漂移自适应机制[20]。在文献[128]中,作者提出了一种新的主动学习算法,其主要目的是避免样本选择过程中的偏差。他们还为模型引入了内存损失因子,使其能够适应概念漂移。
Semi-supervised learning concerns how to use limited true label data more efficiently by leveraging unsupervised techniques. In this scenario, additional design effort is re- quired to handle concept drift. For example, in [129], the au- thors applied a Gaussian Mixture model to both labeled and unlabeled data, and assigned labels, which has the ability to adapt to gradual drift. Similarly, [99], [130], [131] are all cluster-based semi-supervised ensemble methods that aim to adapt to drift with limited true label data. The latter are also able to recognize recurring concepts. In [132], the author adopted a new perspective on the true label scarcity problem by considering the true labeled data and unlabeled data as two independent non-stationary data generating processes. Concept drift is handled asynchronously on these two streams. The SAND algorithm [133], [134] is another semi-supervised adaptive method which detects concept drift on cluster boundaries. There are also studies [90, 91] that focus on adapting to concept drift in circumstances where true label data is completely unavailable.
半监督学习关注如何利用无监督技术更有效地使用有限的真实标签数据。在这种情况下,需要额外的设计工作来处理概念漂移。例如,在[129]中,作者将高斯混合模型应用于有标记和未标记的数据,并分配了具有适应渐变漂移能力的标签。类似地,[99]、[130]、[131]都是基于聚类的半监督集成方法,目的是在有限的真实标签数据下适应漂移。后者也能识别重复出现的概念。在文献[132]中,作者对真标记稀缺问题采用了一种新的观点,将真标记数据和未标记数据看作两个独立的非平稳数据生成过程。概念漂移是在这两个流上异步处理的。SAND算法[133],[134]是另一种半监督自适应方法,用于检测簇边界上的概念漂移。也有研究[90,91]关注于在真实标签数据完全不可用的情况下适应概念漂移。
Decision Rules
Data-driven decision support systems need to be able to adapt to concept drift in order to make accurate decisions and decision rules is the main technique for this purpose. [102] proposed a decision rule induction algorithm, Very Fast Decision Rules (VFDR), to effectively process stream data. An extended version, Adaptive VFDR, was developed to handle concept drift by dynamically adding and remov- ing decision rules according to their error rate which is mon- itored by drift detector. Instead of inducing rules from de- cision trees, [135] proposed another decision rule algorithm based on PRISM [136] to directly induce rules from data. This algorithm is also able to adapt to drift by monitoring the performance of each rule on a sliding window of latest data. [137] also developed an adaptive decision making algorithm based on fuzzy rules. The algorithm includes a rule pruning procedure, which removes obsolete rules to adapt to changes, and a rule recal procedure to adapt to recurring concepts.
数据驱动的决策支持系统需要能够适应概念漂移才能做出准确的决策,而决策规则是实现这一目的的主要技术。提出了一种快速决策规则(vfp)的快速决策算法。为了解决概念漂移问题,开发了一个扩展版本,即自适应VFDR,它根据漂移检测器监测的错误率动态地添加和删除决策规则。[135]没有从决策树中归纳规则,而是提出了另一种基于PRISM[136]的决策规则算法,直接从数据中归纳规则。该算法还可以通过在最新数据的滑动窗口上监视每个规则的性能来适应漂移。[137]还开发了一种基于模糊规则的自适应决策算法。该算法包括一个规则剪枝过程,该过程删除过时的规则以适应变化,以及一个规则重排过程,以适应重复出现的概念。
This section by no means attempts to cover every re- search field in which concept drift handling is used. There are many other studies that also consider concept drift as a dual problem. For example, [138] is a dimension reduction algorithm to separate classes based on least squares linear discovery analysis (LSLDA), which is then extended to adapt to drift; [139] considered the concept drift problem in time series and developed an online explicit drift detection method by monitoring time series features; and [140] devel- oped an incremental scaffolding classification algorithm for complex tasks that also involve concept drift.
本节绝不试图涵盖使用概念漂移处理的每个研究领域。还有许多其他的研究也将概念漂移视为一个双重问题。例如,[138]是一种基于最小二乘线性发现分析(LSLDA)的降维算法,然后对其进行扩展以适应漂移;[139]考虑了时间序列中的概念漂移问题,并通过监测时间序列特征开发了一种在线显式漂移检测方法;[140]开发了增量脚手架分类算法的复杂任务也涉及概念漂移。
Conclusion: Findings And Future Directions
We summarize the recent developments of concept drift research, and the following important findings can be ex- tracted:
我们总结了概念漂移研究的最新进展,并得出以下重要结论:
-
Error rate-based and data distribution-based drift de- tection methods are still playing a dominant role in con- cept drift detection research, while multiple hypothesis test methods emerge in recent years;
-
Regarding to concept drift understanding, all drift detection methods can answer “When”, but very few methods have the ability to answer “How” and “Where”;
-
Adaptive models and ensemble techniques have played an increasingly important role in recent concept drift adaptation developments. In contrast, research of re- training models with explicit drift detection has slowed;
-
Most existing drift detection and adaptation algorithms assume the true label is available after classifi- ca or extreme verification latency. Very few research has been conducted to address unsuper- vised or semi-supervised drift detection and adapta- tion.
-
Some computational intelligence techniques, such as fuzzy logic, competence model, have been applied in concept drift;
-
There is no comprehensive analysis on real-world data streams from the concept drift aspect, such as the drift occurrence time, the severity of drift, and the drift regions.
-
An increasing number of other research areas have recognized the importance of handling concept drift, especially in big data community.
1) 基于错误率和基于数据分布的漂移检测方法在概念漂移检测研究中仍占主导地位,近年来出现了多种假设检验方法;
2)关于概念漂移理解,所有漂移检测方法都能回答“何时”,但是很少有方法能够回答“如何”和“在哪里”;
3)自适应模型和集成技术在最近的概念漂移适应发展中起着越来越重要的作用。与此相反,具有显式漂移检测的再训练模型的研究却相对缓慢;
4)现有的漂移检测和自适应算法大多假设在classifi-ca或极端验证延迟之后,真正的标签是可用的。很少有研究涉及无监督或半监督漂移检测和适应。
5) 一些计算智能技术,如模糊逻辑、能力模型等已经被应用到概念漂移中;
6)没有从概念漂移的角度对现实世界的数据流进行全面的分析,如漂移发生的时间、漂移的严重程度和漂移区域。
7) 越来越多的其他研究领域已经认识到处理概念漂移的重要性,特别是在大数据社区。
Based on these findings, we suggest four new directions in future concept drift research:
基于这些发现,我们提出了未来概念漂移研究的四个新方向:
- Drift detection research should not only focus on identi- fying drift occurrence time accurately, but also need to provide the information of drift severity and regions. These information could be utilized for better concept drift adaptation.
1) 漂移检测的研究不仅需要准确地识别漂移发生的时间,而且需要提供漂移严重程度和漂移区域的信息。这些信息可以用来更好地适应概念漂移。
- In the real-world scenario, the cost to acquire true label could be expensive, that is, unsupervised or semi-su-pervised drift detection and adaptation could still be promising in the future.
2) 在现实世界中,获得真实标签的成本可能很高,即无监督或半监督在未来,有监督的漂移检测和适应仍然是有希望的。
-
A framework for selecting real-world data streams should be established for evaluating learning algorithms handling concept drift.
-
Research on effectively integrating concept drift handling techniques with machine learning methodologies for data-driven applications is highly desired.
3) 应建立一个选择真实世界数据流的框架,以评估处理概念漂移的学习算法。
4) 研究如何有效地将概念漂移处理技术与机器学习方法相结合,以应用于数据驱动的应用领域。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)