首先需要申明的是,本文中所使用到的 PyTorch 版本为:1.4.0 。
当采用 RNN 训练序列样本数据时,会面临序列样本数据长短不一的情况。比如做 NLP 任务、语音处理任务时,每个句子或语音序列的长度经常是不相同。难道要一个序列一个序列的喂给网络进行训练吗?这显然是行不通的。
为了更高效的进行 batch 处理,就需要对样本序列进行填充,保证各个样本长度相同,在 PyTorch 里面使用函数 pad_sequence 对序列进行填充。填充之后的样本序列,虽然长度相同了,但是序列里面可能填充了很多无效值 0 ,将填充值 0 喂给 RNN 进行 forward 计算,不仅浪费计算资源,最后得到的值可能还会存在误差。因此在将序列送给 RNN 进行处理之前,需要采用 pack_padded_sequence 进行压缩,压缩掉无效的填充值。序列经过 RNN 处理之后的输出仍然是压紧的序列,需要采用 pad_packed_sequence 把压紧的序列再填充回来,便于进行后续的处理。
下面详细来说明每个函数的作用,以及每个函数之间的关系。
一,pad_sequence
参数
sequences:表示输入样本序列,为 list 类型,list 中的元素为 tensor 类型。 tensor 的 size 为 L * F 。其中,L 为单个序列的长度,F 为序列中每个时间步(time step)特征的个数,根据任务的不同 F 的维度会有所不同。
batch_first:为 True 对应 [batch_size, seq_len, feature];False 对应[seq_len, batch_size, feature],从习惯上来讲一般设置为 True 比较符合我们的认知。
padding_value:填充值,默认值为 0 。
说明
主要用来对样本进行填充,填充值一般为 0 。我们在训练网络时,一般会采用一个一个 mini-batch 的方式,将训练样本数据喂给网络。在 PyTorch 里面数据都是以 tensor 的形式存在,一个 mini-batch 实际上就是一个高维的 tensor ,每个序列数据的长度必须相同才能组成一个 tensor 。为了使网络可以处理 mini-batch 形式的数据,就必须对序列样本进行填充,保证一个 mini-batch 里面的数据长度是相同的。
在 PyTorch 里面一般是使用 DataLoader 进行数据加载,返回 mini-batch 形式的数据,再将此数据喂给网络进行训练。我们一般会自定义一个 collate_fn 函数,完成对数据的填充。
示例
import torch
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence,pack_padded_sequence,pack_sequence,pad_packed_sequence
class MyData(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def collate_fn(data):
data.sort(key=lambda x: len(x), reverse=True)
data = pad_sequence(data, batch_first=True, padding_value=0)
return data
a = torch.tensor([1,2,3,4])
b = torch.tensor([5,6,7])
c = torch.tensor([7,8])
d = torch.tensor([9])
train_x = [a, b, c, d]
data = MyData(train_x)
data_loader = DataLoader(data, batch_size=2, shuffle=True, collate_fn=collate_fn)
# 采用默认的 collate_fn 会报错
#data_loader = DataLoader(data, batch_size=2, shuffle=True)
batch_x = iter(data_loader).next()
运行程序,得到 batch_x 的值:
# batch_x
tensor([[1, 2, 3, 4],
[9, 0, 0, 0]])
从 batch_x 的值可以看出,第二行填充了三个 0 ,使其长度和第一行保持一致。
需要说明的是,对于长度不同的序列,使用默认的 collate_fn 函数,不自定义 collate_fn 函数完成对序列的填充,上面的程序就会报错。
二,pack_padded_sequence
参数
input:经过 pad_sequence 处理之后的数据。
lengths:mini-batch中各个序列的实际长度。
batch_first:True 对应 [batch_size, seq_len, feature] ;
False 对应 [seq_len, batch_size, feature] 。
enforce_sorted:如果是 True ,则输入应该是按长度降序排序的序列。如果是 False ,会在函数内部进行排序。默认值为 True 。
说明
这个 pack 的意思可以理解为压紧或压缩 ,因为数据在经过填充之后,会有很多冗余的 padding_value,所以需要压缩一下。
为什么要使用这个函数呢?
RNN 读取数据的方式:网络每次吃进去一组同样时间步 (time step) 的数据,也就是 mini-batch 的所有样本中下标相同的数据,然后获得一个 mini-batch 的输出;再移到下一个时间步 (time step),再读入 mini-batch 中所有该时间步的数据,再输出;直到处理完所有的时间步数据。
第一个时间步:

第二个时间步:

mini-batch 中的 0 只是用来做数据对齐的 padding_value ,如果进行 forward 计算时,把 padding_value 也考虑进去,可能会导致RNN通过了非常多无用的 padding_value,这样不仅浪费计算资源,最后得到的值可能还会存在误差。对于上面的序列 2 的数据,通过 RNN 网络:
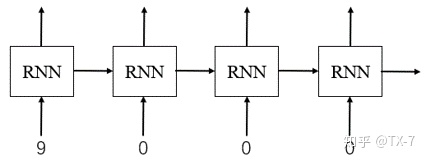
实际上从第 2 个时间步开始一直到最后的计算都是多余的,输入都是无效的 padding_value 而已。
从上面的分析可以看出,为了使 RNN 可以高效的读取数据进行训练,就需要在 pad 之后再使用 pack_padded_sequence 对数据进行处理。
需要注意的是,默认条件下,我们必须把输入数据按照序列长度从大到小排列后才能送入 pack_padded_sequence ,否则会报错。
示例
只需要将上面的例子中的 collate_fn 函数稍作修改即可,其余部分保持不变。
def collate_fn(data):
data.sort(key=lambda x: len(x), reverse=True)
seq_len = [s.size(0) for s in data] # 获取数据真实的长度
data = pad_sequence(data, batch_first=True)
data = pack_padded_sequence(data, seq_len, batch_first=True)
return data
输出:
# batch_x
PackedSequence(data=tensor([1, 9, 2, 3, 4]),
batch_sizes=tensor([2, 1, 1, 1]),
sorted_indices=None, unsorted_indices=None)
可以看出,输出返回一个 PackedSequence 对象,它主要包含两部分:data 和 batch_sizes 。
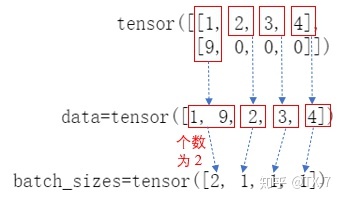
填充值 0 就被跳过了。batch_size 中的值,实际上就是告诉网络每个时间步需要吃进去多少数据。
如果仔细看,其实输出的 PackedSequence 对象还包含两个部分 sorted_indices 和unsorted_indices 。前面说到 pack_padded_sequence 还有一个参数 enforce_sorted ,如果是 True ,则输入应该是按长度降序排序的序列。如果是 False ,会在函数内部进行排序。默认值为 True 。也就是说在输入 pack_padded_sequence 前,我们也可以不对数据进行排序。
现在我们将 enforce_sorted 设置为 False ,且输入数据不预先进行排序。
data = [torch.tensor([9]),
torch.tensor([1,2,3,4]),
torch.tensor([5,6])]
seq_len = [s.size(0) for s in data]
data = pad_sequence(data, batch_first=True)
data = pack_padded_sequence(data, seq_len, batch_first=True, enforce_sorted=False)
输出:
PackedSequence(data=tensor([1, 5, 9, 2, 6, 3, 4]),
batch_sizes=tensor([3, 2, 1, 1]),
sorted_indices=tensor([1, 2, 0]),
unsorted_indices=tensor([2, 0, 1]))
sorted_indices = tensor([1, 2, 0],表示排序之后的结果与原始 data 中的 tensor 的下标对应关系。1 表示原始 data 中 第 1 行最长,排序之后排在最前面,其次是第 2 行、第 0 行。
假设排序之后的结果为:
sort_data = [torch.tensor([1,2,3,4]),
torch.tensor([5,6])
torch.tensor([9]),
]
unsorted_indices = tensor([2, 0, 1],表示未排序前结果。2 表示 sort_data 的第 2 行对应 data 中第 0 行;0 表示 sort_data 的第 0 行对应 data 中的第 1 行;1 表示 sort_data 的第 1 行对应 data 中的第 2 行。
三,pack_sequence
我查阅了 PyTorch 的官方文档,pack_sequence 函数在 0.4.0 以下的版本是没有的。
参数
sequences:输入样本序列,为 list 类型,list 中的元素为 tensor ;tensor 的 size 为 L * F,其中,L 为单个序列的长度,F 为序列中每个时间步(time step)特征的个数,根据任务的不同 F 的维度会有所不同。
enforce_sorted:如果是 True ,则输入应该是按长度降序排序的序列。如果是 False ,会在函数内部进行排序。默认值为 True 。
说明
我们看看 PyTorch 中的源码:
def pack_sequence(sequences, enforce_sorted=True):
lengths = torch.as_tensor([v.size(0) for v in sequences])
return pack_padded_sequence(pad_sequence(sequences),lengths,enforce_sorted=enforce_sorted)
可以看出 pack_sequence 实际上就是对 pad_sequence 和 pack_padded_sequence 操作的一个封装。通过一个函数完成了两步才能完成的工作。
示例
前面的 collate_fn 函数可以进一步修改为:
def collate_fn(data):
data.sort(key=lambda x: len(x), reverse=True)
data = pack_sequence(data)
#seq_len = [s.size(0) for s in data]
#data = pad_sequence(data, batch_first=True)
#data = pack_padded_sequence(data, seq_len, batch_first=True)
return data
输出结果与前面相同:
# batch_x
PackedSequence(data=tensor([1, 9, 2, 3, 4]),
batch_sizes=tensor([2, 1, 1, 1]),
sorted_indices=None, unsorted_indices=None)
四,pad_packed_sequence
参数
sequences:PackedSequence 对象,将要被填充的 batch ;
batch_first:一般设置为 True,返回的数据格式为 [batch_size, seq_len, feature] ;
padding_value:填充值;
total_length:如果不是None,输出将被填充到长度:total_length。
说明
如果在喂给网络数据的时候,用了 pack_sequence 进行打包,pytorch 的 RNN 也会把输出 out 打包成一个 PackedSequence 对象。
这个函数实际上是 pack_padded_sequence 函数的逆向操作。就是把压紧的序列再填充回来。
为啥要填充回来呢?我的理解是,在 collate_fn 函数里面通常也会调用 pad_sequence 对 label 进行填充,RNN 的输出结果为了和 label 对齐,需要将压紧的序列再填充回来,方便后续的计算。
示例
需要说明的是,下面的程序中,为了产生符合 LSTM 输入格式 [batch_size, seq_len, feature] 的数据,使用了函数 unsqueeze 进行升维处理。其中, batch_size 是样本数,seq_len 是序列长度,feature 是特征数。
class MyData(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def collate_fn(data):
data.sort(key=lambda x: len(x), reverse=True)
seq_len = [s.size(0) for s in data]
data = pad_sequence(data, batch_first=True).float()
data = data.unsqueeze(-1)
data = pack_padded_sequence(data, seq_len, batch_first=True)
return data
a = torch.tensor([1,2,3,4])
b = torch.tensor([5,6,7])
c = torch.tensor([7,8])
d = torch.tensor([9])
train_x = [a, b, c, d]
data = MyData(train_x)
data_loader = DataLoader(data, batch_size=2, shuffle=True, collate_fn=collate_fn)
batch_x = iter(data_loader).next()
rnn = nn.LSTM(1, 4, 1, batch_first=True)
h0 = torch.rand(1, 2, 4).float()
c0 = torch.rand(1, 2, 4).float()
out, (h1, c1) = rnn(batch_x, (h0, c0))
得到 out 的结果如下,是一个 PackedSequence 类型的对象,与前面调用 pack_padded_sequence 得到的结果类型相同。
# out
PackedSequence(data=tensor([[-1.3302e-04, 5.7754e-02, 4.3181e-02, 6.4226e-02],
[-2.8673e-02, 3.9089e-02, -2.6875e-03, 4.2686e-03],
[-1.0216e-01, 2.5236e-02, -1.2230e-01, 5.1524e-02],
[-1.6211e-01, 2.1079e-02, -1.5849e-01, 5.2800e-02],
[-1.5774e-01, 2.6749e-02, -1.3333e-01, 4.7894e-02]],
grad_fn=<CatBackward>),
batch_sizes=tensor([2, 1, 1, 1]),
sorted_indices=None, unsorted_indices=None)
对 out 调用 pad_packed_sequence 进行填充:
out_pad, out_len = pad_packed_sequence(out, batch_first=True)
out_pad 和 out_len 的结果如下:
# out_pad
tensor([[[-1.3302e-04, 5.7754e-02, 4.3181e-02, 6.4226e-02],
[-1.0216e-01, 2.5236e-02, -1.2230e-01, 5.1524e-02],
[-1.6211e-01, 2.1079e-02, -1.5849e-01, 5.2800e-02],
[-1.5774e-01, 2.6749e-02, -1.3333e-01, 4.7894e-02]],
[[-2.8673e-02, 3.9089e-02, -2.6875e-03, 4.2686e-03],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]]],
grad_fn=<TransposeBackward0>)
# out_len
tensor([4, 1])
再回想下我们调用 pad_sequence 填充之后的输入:
# batch_x
tensor([[1, 2, 3, 4],
[9, 0, 0, 0]])
这个 out_pad 结果其实就和我们填充之后的输入对应起来了。