由于笔记内容过多,我把它放到语雀上了。
1. 应对面试中的设计模式相关问题
2. 告别写被人吐槽的烂代码
3. 提高复杂代码的设计和开发能力
4. 让读源码、学框架事半功倍
5. 为你的职场发展做铺垫
最常用的评价标准有可维护性、可读性、可扩展性、灵活性、简洁性(简单、复杂)、可复用性、可测试性。
1. 可维护性(maintainability)
如果 bug 容易修复,修改、添加功能能够轻松完成,那我们就可以主观地认为代码对我们来说易维护。有很强的主观性。
2. 可读性(readability)
“任何傻瓜都会编写计算机能理解的代码。好的程序员能够编写人能够理解的代码。”
我们需要看代码是否符合编码规范、命名是否达意、注释是否详尽、函数是否长短合适、模块划分是否清晰、是否符合高内聚低耦合等等。code review 是一个很好的测验代码可读性的手段。如果你的同事可以轻松地读懂你写的代码,那说明你的代码可读性很好;如果同事在读你的代码时,有很多疑问,那就说明你的代码可读性有待提高了。
3. 可扩展性(extensibility)
代码的可扩展性表示,我们在不修改或少量修改原有代码的情况下,通过扩展的方式添加新的功能代码。代码预留了一些功能扩展点,你可以把新功能代码,直接插到扩展点上,而不需要因为要添加一个功能而大动干戈,改动大量的原始代码。
4. 灵活性(flexibility)
5. 简洁性(simplicity)
KISS 原则:“Keep It Simple,Stupid”。尽量保持代码简单。
思从深而行从简,真正的高手能云淡风轻地用最简单的方法解决最复杂的问题。这也是一个编程老手跟编程新手的本质区别之一。
6. 可复用性(reusability)
尽量减少重复代码的编写,复用已有的代码。
当讲到面向对象特性的时候,我们会讲到继承、多态存在的目的之一,就是为了提高代码的可复用性;当讲到设计原则的时候,我们会讲到单一职责原则也跟代码的可复用性相关;当讲到重构技巧的时候,我们会讲到解耦、高内聚、模块化等都能提高代码的可复用性。可见,可复用性也是一个非常重要的代码评价标准,是很多设计原则、思想、模式等所要达到的最终效果。
7. 可测试性(testability)
代码可测试性的好坏,能从侧面上非常准确地反应代码质量的好坏。代码的可测试性差,比较难写单元测试,那基本上就能说明代码设计得有问题。

五者之间的联系
重构的工具是面向对象设计思想、设计原则、设计模式、编码规范。
虽然使用设计模式可以提高代码的可扩展性,但过度不恰当地使用,也会增加代码的复杂度,影响代码的可读性。在开发初期,除非特别必须,我们一定不要过度设计,应用复杂的设计模式。而是当代码出现问题的时候,我们再针对问题,应用原则和模式进行重构。这样就能有效避免前期的过度设计。
面向对象编程的英文缩写是 OOP,全称是 Object Oriented Programming。
面向对象编程语言的英文缩写是 OOPL,全称是 Object Oriented Programming Language。
面向对象分析英文缩写是 OOA,全称是 Object Oriented Analysis;
面向对象设计的英文缩写是 OOD,全称是 Object Oriented Design。
OOA、OOD、OOP 三个连在一起就是面向对象分析、设计、编程(实现),正好是面向对象软件开发要经历的三个阶段。
UML(Unified Model Language),统一建模语言。
大部分情况下,我们随手画个不那么规范的草图,能够表达意思,方便沟通就够了,而完全按照 UML 规范来将草图标准化,所付出的代价是不值得的。
面向对象编程是一种编程范式或编程风格。它以类或对象作为组织代码的基本单元,并将封装、抽象、继承、多态四个特性,作为代码设计和实现的基石 。
面向对象编程语言是支持类或对象的语法机制,并有现成的语法机制,能方便地实现面向对象编程四大特性(封装、抽象、继承、多态)的编程语言。
1、什么是面向对象分析和面向对象设计?
面向对象分析就是要搞清楚做什么,面向对象设计就是要搞清楚怎么做。两个阶段最终的产出是类的设计,包括程序被拆解为哪些类,每个类有哪些属性方法、类与类之间如何交互等等。
2、如何判定一个编程语言是否是面向对象编程语言?
如果按照严格的的定义,需要有现成的语法支持类、对象、四大特性才能叫作面向对象编程语言。如果放宽要求的话,只要某种编程语言支持类、对象的语法机制,那基本上就可以说这种编程语言是面向对象编程语言了,不一定非得要求具有所有的四大特性。
3、面向对象编程和面向对象编程语言之间有何关系?
面向对象编程一般使用面向对象编程语言来进行,但是,不用面向对象编程语言,我们照样可以进行面向对象编程。反过来讲,即便我们使用面向对象编程语言,写出来的代码也不一定是面向对象编程风格的,也有可能是面向过程编程风格的。
问题
在文章中,我讲到 UML 的学习成本很高,沟通成本也不低,不推荐在面向对象分析、设计的过程中使用,对此你有何看法?
有关面向对象的概念和知识点,除了我们今天讲到的,你还能想到其他哪些吗?
封装也叫作信息隐藏或者数据访问保护。面向对象封装的定义是:通过访问权限控制,隐藏内部数据,外部仅能通过类提供的有限的接口访问、修改内部数据。例如 Java 中的 private、protected、public 关键字。private 关键字修饰的属性只能类本身访问,可以保护其不被类之外的代码直接访问。
封装特性存在的意义,
一方面是保护数据不被随意修改,提高代码的可维护性。如果不对属性和方法的访问做限制,那么任何代码都可以去访问它们,这些修改逻辑可能散落在各个角落。势必影响代码的可读性、可维护性。
另一方面是仅暴露有限的必要接口,提高类的易用性。如果暴露了很多属性和方法给调用者,调用者需要去了解这些东西的用法,会增加调用者的使用成本。
虽然我们将它们定义成 private 私有属性,但是提供了 public 的 getter、setter 方法,这就跟将这两个属性定义为 public 公有属性,没有什么两样了。外部可以通过 setter 方法随意地修改这两个属性的值。这是不对的。暴露不应该暴露的 setter 方法,明显违反了面向对象的封装特性。数据没有访问权限控制,任何代码都可以随意修改它,代码就退化成了面向过程编程风格的了。
当然,我们可以用封装的思想来控制private属性修改的方式。

package test1;
public class Man {
private int age = 2;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
package test2;
import test1.Man;
public class Boy {
public static void main(String[] args){
Man man = new Man();
System.out.println(man.getAge());
man.setAge(33);
System.out.println(man.getAge());
}
}
封装主要讲如何隐藏信息、保护数据,那抽象就是讲如何隐藏方法的具体实现,让使用者只需要关心方法提供了哪些功能,不需要知道这些功能是如何实现的。抽象可以通过接口类或者抽象类来实现,但也并不需要特殊的语法机制来支持。
抽象存在的意义,
一方面是提高代码的可扩展性、维护性,修改实现不需要改变定义,减少代码的改动范围;我们在定义(或者叫命名)类的方法的时候,也要有抽象思维,不要在方法定义中,暴露太多的实现细节,以保证在某个时间点需要改变方法的实现逻辑的时候,不用去修改其定义。比如 getAliyunPictureUrl() 就不是一个具有抽象思维的命名,因为某一天如果我们不再把图片存储在阿里云上,而是存储在私有云上,那这个命名也要随之被修改。相反,如果我们定义一个比较抽象的函数,比如叫作 getPictureUrl(),那即便内部存储方式修改了,我们也不需要修改命名。
另一方面,它也是处理复杂系统的有效手段,能有效地过滤掉不必要关注的信息。
public interface IPictureStorage {
void savePicture(Picture picture);
Image getPicture(String pictureId);
void deletePicture(String pictureId);
void modifyMetaInfo(String pictureId, PictureMetaInfo metaInfo);
}
public class PictureStorage implements IPictureStorage {
// ...省略其他属性...
@Override
public void savePicture(Picture picture) { ... }
@Override
public Image getPicture(String pictureId) { ... }
@Override
public void deletePicture(String pictureId) { ... }
@Override
public void modifyMetaInfo(String pictureId, PictureMetaInfo metaInfo) { ... }
}
在面向对象编程中,我们常借助编程语言提供的接口类(比如 Java 中的 interface 、implements关键字语法)或者抽象类(比如 Java 中的 abstract、extends 关键字语法)这两种语法机制,来实现抽象这一特性。
即便不编写 IPictureStorage 接口类,单纯的 PictureStorage 类本身就满足抽象特性。因为类的方法是通过“函数”这一语法机制来实现的。通过函数包裹具体的实现逻辑,这本身就是一种抽象。调用者在使用函数的时候,并不需要去研究函数内部的实现逻辑,只需要通过函数的命名、注释或者文档,了解其提供了什么功能,就可以直接使用了。比如,我们在使用 C 语言的 malloc() 函数的时候,并不需要了解它的底层代码是怎么实现的。
为什么抽象有时候会被排除在面向对象的四大特性之外?
抽象这个概念是一个非常通用的设计思想,并不单单用在面向对象编程中。只需要编程语言提供“函数”这一基础的语法机制,就可以实现抽象特性。所以,它没有很强的“特异性”,有时候并不被看作面向对象编程的特性之一。
继承是用来表示类之间的 is-a 关系,分为两种模式:单继承和多继承。单继承表示一个子类只继承一个父类,多继承表示一个子类可以继承多个父类。为了实现继承这个特性,编程语言需要提供特殊的语法机制来支持。继承主要是用来解决代码复用的问题。
继承的意义:
1、代码复用。假如两个类有一些相同的属性和方法,我们就可以将这些相同的部分,抽取到父类中,让两个子类继承父类。这样,两个子类就可以重用父类中的代码,避免代码重复写多遍。
2、非常符合人类的认知。我们代码中有一个猫类,有一个哺乳动物类。猫属于哺乳动物,从人类认知的角度上来说,是一种 is-a 关系。
缺点:过度使用继承,继承层次过深过复杂,就会导致代码可读性、可维护性变差。
继承主要有三个作用:表示 is-a 关系,支持多态特性,代码复用。
多态是指子类可以替换父类,在实际的代码运行过程中,调用子类的方法实现。
多态特性的实现方式:
①继承加方法重写。
有三点:支持继承;父类对象可以引用子类对象;子类可以重写(override)父类中的方法。
public class DynamicArray {
private static final int DEFAULT_CAPACITY = 10;
protected int size = 0;
protected int capacity = DEFAULT_CAPACITY;
protected Integer[] elements = new Integer[DEFAULT_CAPACITY];
public int size() { return this.size; }
public Integer get(int index) { return elements[index];}
//...省略n多方法...
public void add(Integer e) {
ensureCapacity();
elements[size++] = e;
}
protected void ensureCapacity() {
//...如果数组满了就扩容...代码省略...
}
}
public class SortedDynamicArray extends DynamicArray {
@Override
public void add(Integer e) {
ensureCapacity();
int i;
for (i = size-1; i>=0; --i) { //保证数组中的数据有序
if (elements[i] > e) {
elements[i+1] = elements[i];
} else {
break;
}
}
elements[i+1] = e;
++size;
}
}
public class Example {
public static void test(DynamicArray dynamicArray) {
dynamicArray.add(5);
dynamicArray.add(1);
dynamicArray.add(3);
for (int i = 0; i < dynamicArray.size(); ++i) {
System.out.println(dynamicArray.get(i));
}
}
public static void main(String args[]) {
DynamicArray dynamicArray = new SortedDynamicArray();
test(dynamicArray); // 打印结果:1、3、5
}
}
②利用接口类语法。比如 C++ 就不支持接口类语法。
public interface Iterator {
boolean hasNext();
String next();
String remove();
}
public class Array implements Iterator {
private String[] data;
public boolean hasNext() { ... }
public String next() { ... }
public String remove() { ... }
//...省略其他方法...
}
public class LinkedList implements Iterator {
private LinkedListNode head;
public boolean hasNext() { ... }
public String next() { ... }
public String remove() { ... }
//...省略其他方法...
}
public class Demo {
private static void print(Iterator iterator) {
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
public static void main(String[] args) {
Iterator arrayIterator = new Array();
print(arrayIterator);
Iterator linkedListIterator = new LinkedList();
print(linkedListIterator);
}
}
③利用 duck-typing 语法。只有一些动态语言才支持,比如 Python、JavaScript 等。
class Logger:
def record(self):
print(“I write a log into file.”)
class DB:
def record(self):
print(“I insert data into db. ”)
def test(recorder):
recorder.record()
def demo():
logger = Logger()
db = DB()
test(logger)
test(db)
只要两个类具有相同的方法,就可以实现多态,并不要求两个类之间有任何关系,这就是所谓的 duck-typing,是一些动态语言所特有的语法机制。而像 Java 这样的静态语言,通过继承实现多态特性,必须要求两个类之间有继承关系,通过接口实现多态特性,类必须实现对应的接口。
多态可以提高代码的扩展性和复用性,是很多设计模式、设计原则、编程技巧的代码实现基础。
扩展性:第二个代码实例(Iterator 的例子)中,利用多态的特性,仅用一个 print() 函数就可以实现遍历打印不同类型(Array、LinkedList)集合的数据。当再增加一种要遍历打印的类型的时候,比如 HashMap,我们只需让 HashMap 实现 Iterator 接口,重新实现自己的 hasNext()、next() 等方法就可以了,完全不需要改动 print() 函数的代码。
复用性:如果我们不使用多态特性,我们就无法将不同的集合类型(Array、LinkedList)传递给相同的函数(print(Iterator iterator) 函数)。我们需要针对每种要遍历打印的集合,分别实现不同的 print() 函数,比如针对 Array,我们要实现 print(Array array) 函数,针对 LinkedList,我们要实现 print(LinkedList linkedList) 函数。而利用多态特性,我们只需要实现一个 print() 函数的打印逻辑,就能应对各种集合数据的打印操作,这显然提高了代码的复用性。
你熟悉的编程语言是否支持多重继承?如果不支持,请说一下为什么不支持。如果支持,请说一下它是如何避免多重继承的副作用的。
你熟悉的编程语言对于四大特性是否都有现成的语法支持?对于支持的特性,是通过什么语法机制实现的?对于不支持的特性,又是基于什么原因做的取舍?
面向过程编程和面向过程编程语言并没有严格的官方定义。相较于面向对象编程以类为组织代码的基本单元,面向过程编程则是以过程(或方法)作为组织代码的基本单元。它最主要的特点就是数据和方法相分离。相较于面向对象编程语言,面向过程编程语言最大的特点就是不支持丰富的面向对象编程特性,比如继承、多态、封装。
面向过程编程也是一种编程范式或编程风格。它以过程(可以理解为方法、函数、操作)作为组织代码的基本单元,以数据(可以理解为成员变量、属性)与方法相分离为最主要的特点。面向过程风格是一种流程化的编程风格,通过拼接一组顺序执行的方法来操作数据完成一项功能。
面向过程编程语言,它最大的特点是不支持类和对象两个语法概念,不支持丰富的面向对象编程特性(比如继承、多态、封装),仅支持面向过程编程。
面向过程和面向对象最基本的区别就是,代码的组织方式不同。面向过程风格的代码被组织成了一组方法集合及其数据结构(struct User),方法和数据结构的定义是分开的。面向对象风格的代码被组织成一组类,方法和数据结构被绑定一起,定义在类中。
面向对象编程相比起面向过程编程的优势主要有三个。
对于大规模复杂程序的开发,程序的处理流程并非单一的一条主线,而是错综复杂的网状结构。面向对象编程比起面向过程编程,更能应对这种复杂类型的程序开发。面向对象编程相比面向过程编程,具有更加丰富的特性(封装、抽象、继承、多态)。利用这些特性编写出来的代码,更加易扩展、易复用、易维护。从编程语言跟机器打交道的方式的演进规律中,我们可以总结出:面向对象编程语言比起面向过程编程语言,更加人性化、更加高级、更加智能。
1.OOP 更加能够应对大规模复杂程序的开发
利用面向过程的编程语言照样可以写出面向对象风格的代码,只不过可能代价要高一些。
2.OOP 风格的代码更易复用、易扩展、易维护
封装、抽象、继承、多态。
3.OOP 语言更加人性化、更加高级、更加智能
在平时的开发中,多留心一下自己编写的代码是否满足面向对象风格。违反面向对象编程风格的例子.
有同事定义完类的属性之后,就顺手把这些属性的 getter、setter 方法都定义上。有些同事更加省事,直接用 IDE 或者 Lombok 插件(如果是 Java 项目的话)自动生成所有属性的 getter、setter 方法。这样的做法我是非常不推荐的。它违反了面向对象编程的封装特性,相当于将面向对象编程风格退化成了面向过程编程风格。
public class ShoppingCart {
private int itemsCount;
private double totalPrice;
private List<ShoppingCartItem> items = new ArrayList<>();
public int getItemsCount() {
return this.itemsCount;
}
public void setItemsCount(int itemsCount) {
this.itemsCount = itemsCount;
}
public double getTotalPrice() {
return this.totalPrice;
}
public void setTotalPrice(double totalPrice) {
this.totalPrice = totalPrice;
}
public List<ShoppingCartItem> getItems() {
return this.items;
}
public void addItem(ShoppingCartItem item) {
items.add(item);
itemsCount++;
totalPrice += item.getPrice();
}
// ...省略其他方法...
}
itemsCount 和 totalPrice。虽然我们将它们定义成 private 私有属性,但是提供了 public 的 getter、setter 方法。等价于将这两个属性定义为 public 公有属性。
对于 itemsCount 和 totalPrice 这两个属性来说,定义一个 public 的 getter 方法,确实无伤大雅,毕竟 getter 方法不会修改数据。但是,对于 items 属性就不一样了,这是因为 items 属性的 getter 方法,返回的是一个 List集合容器。外部调用者在拿到这个容器之后,是可以操作容器内部数据的,也就是说,外部代码还是能修改 items 中的数据。
但是这样的代码写法,会导致 itemsCount、totalPrice、items 三者数据不一致。我们不应该将清空购物车的业务逻辑暴露给上层代码。正确的做法应该是,在 ShoppingCart 类中定义一个 clear() 方法,将清空购物车的业务逻辑封装在里面,透明地给调用者使用。
ShoppingCart cart = new ShoppCart(); ... cart.getItems().clear(); // 清空购物车
public class ShoppingCart {
// ...省略其他代码...
public void clear() {
items.clear();
itemsCount = 0;
totalPrice = 0.0;
}
}
在面向对象编程中,常见的全局变量有单例类对象、静态成员变量、常量等,常见的全局方法有静态方法。Constants 类和 Utils 类最常用到。
如果把程序中所有用到的常量,都集中地放到一个Constants 类中。定义一个如此大而全的Constants 类的缺点:
1、会影响代码的可维护性。当常量很多的时候,查找修改某个常量也会变得比较费时,而且还会增加提交代码冲突的概率。
2、增加代码的编译时间。当 Constants 类中包含很多常量定义的时候,依赖这个类的代码就会很多。那每次修改 Constants 类,都会导致依赖它的类文件重新编译。
3、影响代码的复用性。如果我们要在另一个项目中,复用本项目开发的某个类,而这个类又依赖 Constants 类。即便这个类只依赖 Constants 类中的一小部分常量,我们仍然需要把整个 Constants 类也一并引入,也就引入了很多无关的常量到新的项目中。
改进Constants 类的设计思路:
1、将 Constants 类拆解为功能更加单一的多个类,比如跟 MySQL 配置相关的常量,我们放到 MysqlConstants 类中;跟 Redis 配置相关的常量,我们放到 RedisConstants 类中。
2、哪个类用到了某个常量,我们就把这个常量定义到这个类中。比如,RedisConfig 类用到了 Redis 配置相关的常量,那我们就直接将这些常量定义在 RedisConfig 中。
Utils 类的意义:A和B两个类要用到一块相同的功能逻辑。但A和B从业务上来看,不是继承关系,为了避免代码重复,用Utils类。
只包含静态方法不包含任何属性的 Utils 类,是彻彻底底的面向过程的编程风格。并不是说,我们就要杜绝使用 Utils 类了。实际上,从 Utils 类存在的目的来看,它在软件开发中还是挺有用的,能解决代码复用问题。要尽量避免滥用,不要不加思考地随意去定义 Utils 类。
有的时候,从业务含义上,A 类和 B 类并不一定具有继承关系,比如 Crawler 类和 PageAnalyzer 类,它们都用到了 URL 拼接和分割的功能,但并不具有继承关系(既不是父子关系,也不是兄弟关系)。我们可以定义一个新的类,实现 URL 拼接和分割的方法。而拼接和分割两个方法,不需要共享任何数据,所以新的类不需要定义任何属性,这个时候,我们就可以把它定义为只包含静态方法的 Utils 类了。
设计 Utils 类的时候,最好也能细化一下,针对不同的功能,设计不同的 Utils 类,比如 FileUtils、IOUtils、StringUtils、UrlUtils 等,不要设计一个过于大而全的 Utils 类。
在生活中,你去完成一个任务,你一般都会思考,应该先做什么、后做什么,如何一步一步地顺序执行一系列操作,最后完成整个任务。面向过程编程风格恰恰符合人的这种流程化思维方式。而面向对象编程风格正好相反。它是一种自底向上的思考方式。它不是先去按照执行流程来分解任务,而是将任务翻译成一个一个的小的模块(也就是类),设计类之间的交互,最后按照流程将类组装起来,完成整个任务。
面向对象编程要比面向过程编程难一些。要去思考如何封装合适的数据和方法到一个类里,如何设计类之间的关系,如何设计类之间的交互等等诸多设计问题。
不管使用面向过程还是面向对象哪种风格来写代码,我们最终的目的还是写出易维护、易读、易复用、易扩展的高质量代码。只要我们能避免面向过程编程风格的一些弊端,控制好它的副作用,在掌控范围内为我们所用,我们就大可不用避讳在面向对象编程中写面向过程风格的代码。
代码示例:08 | 理论五:接口vs抽象类的区别?如何用普通的类模拟抽象类和接口?-极客时间
Java的变量分为:类变量、实例变量、局部变量。
public class Boy {
public Boy() {
System.out.println("这是Boy的构造方法");
}
public void Boy(){
System.out.println("这是Boy的普通public方法");
}
public static void main(String[] args){
Boy boy = new Boy();
boy.Boy();
}
}
特性
1、抽象类不允许被实例化,只能被继承。也就是说,不能 new 一个抽象类的对象出来。一个类只能继承一个抽象类。抽象类可以有构造器。抽象类的构造器不能用于创建实例(不能被new调用),主要用于被其子类调用,完成属于抽象类的初始化操作。
但是我们可以用匿名类的方式来new一个抽象类。
public abstract class SimulateInterface {
protected SimulateInterface() {
}
public abstract void test();
}
public class Boy extends SimulateInterface {
public static void main(String[] args){
SimulateInterface i = new SimulateInterface() {
@Override
public void test() {
}
};
}
@Override
public void test() {
}
}
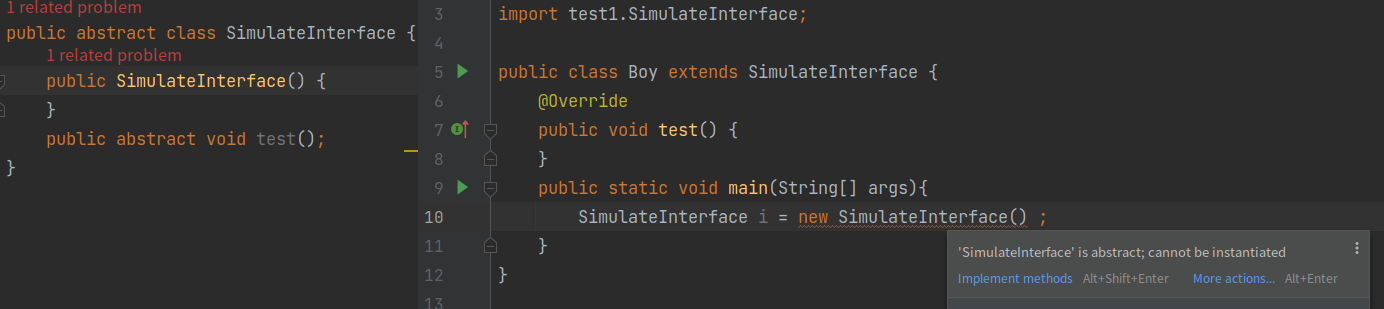
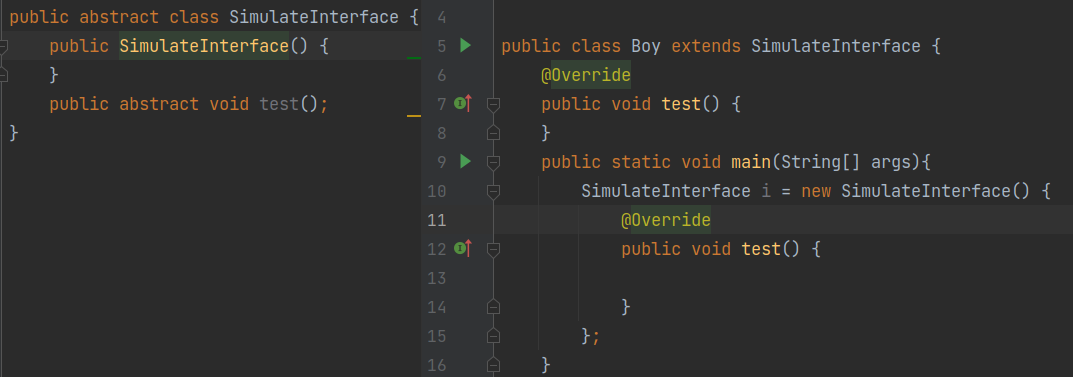

反正直接new抽象类是不行的。抽象类的构造方法的修饰符影响的是 通过匿名类的方式new 抽象类。
2、抽象类可以包含属性和方法。方法既可以包含代码实现(比如 Logger 中的 log() 方法),也可以不包含代码实现(抽象方法,比如 Logger 中的 doLog() 方法)。
3、子类继承抽象类,必须实现抽象类中的所有抽象方法。
4、抽象类只不过是一种特殊的类,普通类上加abstract。继承关系是一种 is-a 的关系。
5、抽象类可以有main方法并且可以运行它。
特性
1、接口不能包含实例变量。接口的变量只能是静态常量,总是使用public static final修饰,只能在定义时指定默认值。一个类可以实现多个接口。接口可以继承多个接口。接口只能继承接口,不能继承类。接口没有构造器。
2、接口只能声明方法,方法不能包含代码实现。接口的方法只能是抽象方法、类方法、默认方法。接口的抽象方法都是public abstract修饰,类方法都是public static修饰,默认方法都是default修饰。
3、类实现接口的时候,必须实现接口中声明的所有方法。
4、接口表示一种 has-a 关系,表示具有某些功能。对于接口,有一个更加形象的叫法,那就是协议(contract)。
5、接口没有main方法。
接口不能直接new。

继承能解决代码复用的问题。所以,抽象类也是为代码复用而生的。多个子类可以继承抽象类中定义的属性和方法,避免在子类中,重复编写相同的代码。
使用抽象类,编译器会强制要求子类重写抽象类中的抽象方法,否则会报编译错误。这样我们可以更加优雅地使用多态的特性。
抽象类更多的是为了代码复用,而接口就更侧重于解耦。接口是一个比抽象类应用更加广泛,比如,经常提到的“基于接口而非实现编程”。接口是为了解决解耦问题,隔离接口和具体的实现,提高代码的扩展性。
接口的定义:接口中没有实例变量,只有方法声明,没有方法实现,实现接口的类必须实现接口中的所有方法。只要满足这样几点,从设计的角度上来说,我们就可以把它叫作接口。
抽象类模拟接口
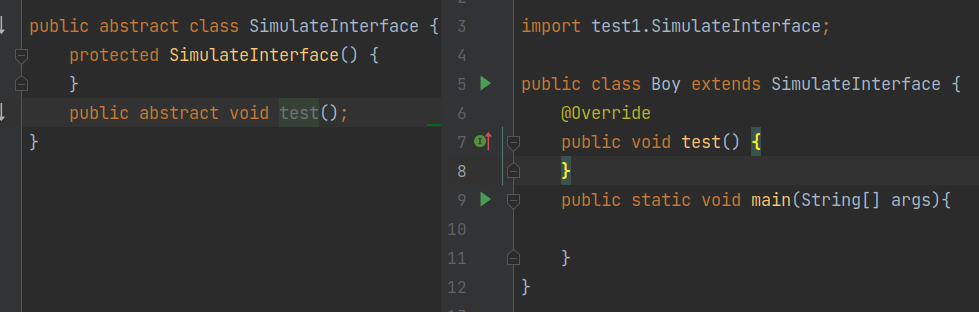
抽象类 SimulateInterface 没有定义任何属性,并且所有的方法都是抽象方法,这样,所有的方法都不能有代码实现,并且所有继承这个抽象类的子类,都要实现这些方法。从语法特性上来看,这个抽象类就相当于一个接口。
普通类模拟接口
public class MockInteface {
protected MockInteface() {}
public void funcA() {
throw new Exception();
}
}
类中的方法必须包含实现,这个不符合接口的定义。但是,我们可以让类中的方法抛出 Exception 异常,来模拟不包含实现的接口,并且能强迫子类在继承这个父类的时候,都去主动实现父类的方法,否则就会在运行时强制抛出异常。我们将构造函数设置成 protected 属性的,这样就能避免非同包下的类去实例化 MockInterface。不过,这样还是无法避免同包中的类去实例化 MockInterface。为了解决这个问题,我们可以学习 Google Guava 中 @VisibleForTesting 注解的做法,自定义一个注解,人为表明不可实例化。
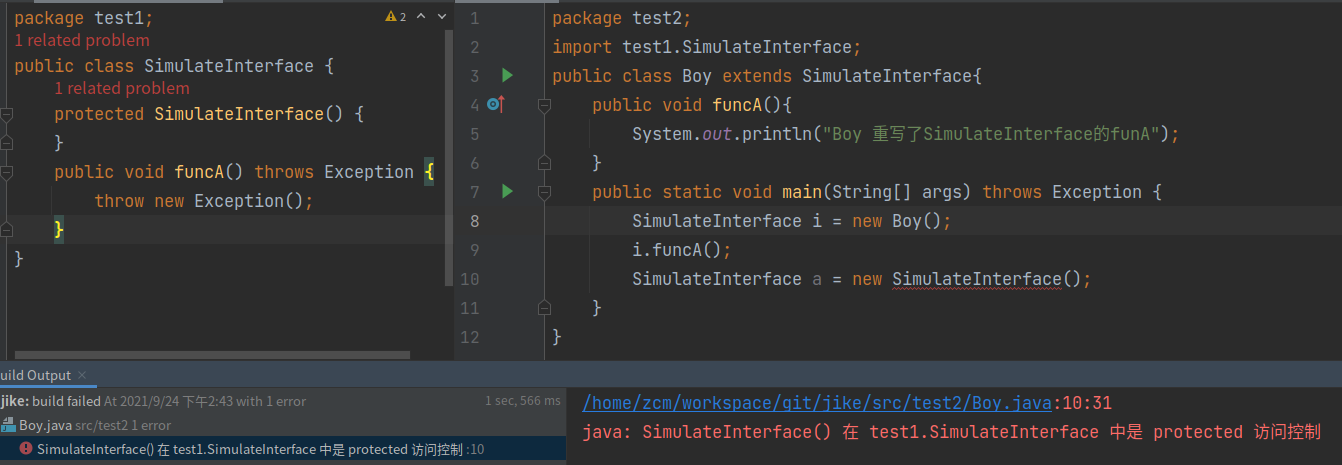
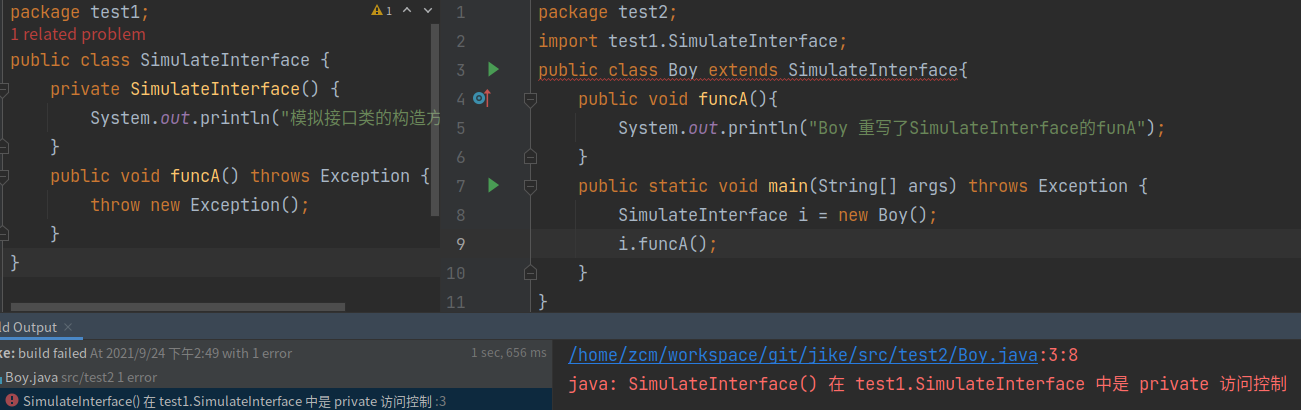
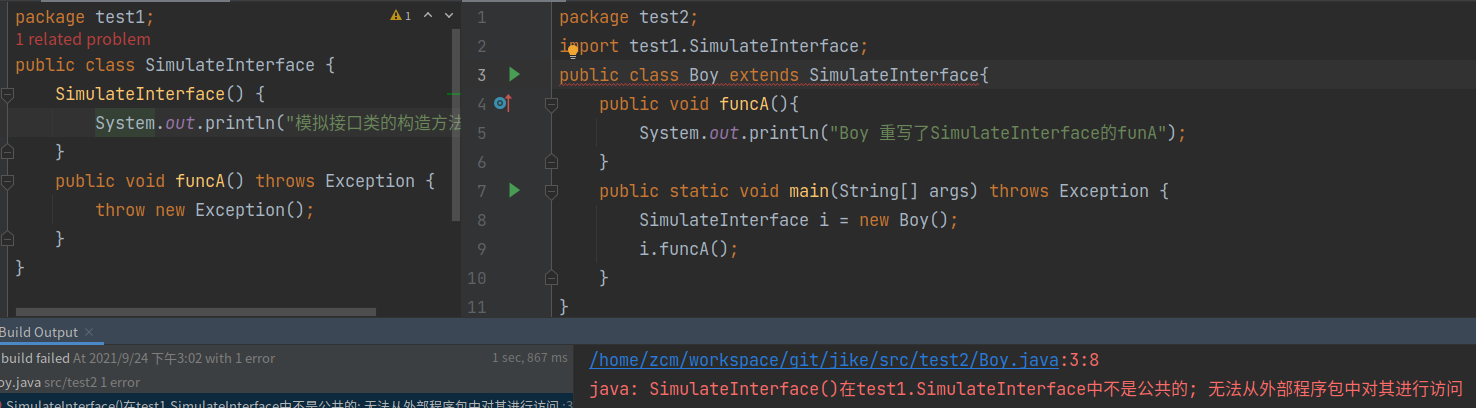
为什么模拟接口类的构造器用protected修饰?因为public肯定是不行的。default、private的话,继承,子类在初始化的时候,会调用父类的构造器。
如果我们要表示一种 is-a 的关系,并且是为了解决代码复用的问题,我们就用抽象类;如果我们要表示一种 has-a 关系,并且是为了解决抽象而非代码复用的问题,那我们就可以使用接口。
从类的继承层次上来看,抽象类是一种自下而上的设计思路,先有子类的代码重复,然后再抽象成上层的父类(也就是抽象类)。而接口正好相反,它是一种自上而下的设计思路。我们在编程的时候,一般都是先设计接口,再去考虑具体的实现。
代码示例:09 | 理论六:为什么基于接口而非实现编程?有必要为每个类都定义接口吗?-极客时间
“基于接口而非实现编程”这条原则的另一个表述方式,是“基于抽象而非实现编程”。
将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低代码间的耦合性,提高代码的扩展性。
重新设计实现一个存储图片到私有云的 PrivateImageStore 类,并用它替换掉项目中所有的 AliyunImageStore 类对象。
为了解决
AliyunImageStore 类中有些函数命名暴露了实现细节,比如,uploadToAliyun() 和 downloadFromAliyun()。
将图片存储到阿里云的流程,跟存储到私有云的流程,可能并不是完全一致的。比如,阿里云的图片上传和下载的过程中,需要生产 access token,而私有云不需要 access token。
的问题。
在编写代码的时候,要遵从“基于接口而非实现编程”的原则,具体来讲,我们需要做到下面这 3 点。
1、函数的命名不能暴露任何实现细节。比如,前面提到的 uploadToAliyun() 就不符合要求,应该改为去掉 aliyun 这样的字眼,改为更加抽象的命名方式,比如:upload()。
2、封装具体的实现细节。比如,跟阿里云相关的特殊上传(或下载)流程不应该暴露给调用者。我们对上传(或下载)流程进行封装,对外提供一个包裹所有上传(或下载)细节的方法,给调用者使用。
3、为实现类定义抽象的接口。具体的实现类都依赖统一的接口定义,遵从一致的上传功能协议。使用者依赖接口,而不是具体的实现类来编程。
如果希望通过实现类来反推接口的定义。将实现类的方法搬移到接口定义中的时候,要有选择性的搬移,不要将跟具体实现相关的方法搬移到接口中,比如 AliyunImageStore 中的 generateAccessToken() 方法。
我们在做软件开发的时候,一定要有抽象意识、封装意识、接口意识。在定义接口的时候,不要暴露任何实现细节。接口的定义只表明做什么,而不是怎么做。而且,在设计接口的时候,我们要多思考一下,这样的接口设计是否足够通用,是否能够做到在替换具体的接口实现的时候,不需要任何接口定义的改动。
我们在定义接口的时候,一方面,命名要足够通用,不能包含跟具体实现相关的字眼;另一方面,与特定实现有关的方法不要定义在接口中。
我们做权衡的根本依据,还是要回归到设计原则诞生的初衷上来。只要搞清楚了这条原则是为了解决什么样的问题而产生的,你就会发现,很多之前模棱两可的问题,都会变得豁然开朗。
如果在我们的业务场景中,某个功能只有一种实现方式,未来也不可能被其他实现方式替换,那我们就没有必要为其设计接口,也没有必要基于接口编程,直接使用实现类就可以了。除此之外,越是不稳定的系统,我们越是要在代码的扩展性、维护性上下功夫。相反,如果某个系统特别稳定,在开发完之后,基本上不需要做维护,那我们就没有必要为其扩展性,投入不必要的开发时间。
在今天举的代码例子中,尽管我们通过接口来隔离了两个具体的实现。但是,在项目中很多地方,我们都是通过下面第 8 行的方式来使用接口的。这就会产生一个问题,那就是,如果我们要替换图片存储方式,还是需要修改很多类似第 8 行那样的代码。这样的设计还是不够完美,对此,你有更好的实现思路吗?
// ImageStore的使用举例
public class ImageProcessingJob {
private static final String BUCKET_NAME = "ai_images_bucket";
//...省略其他无关代码...
public void process() {
Image image = ...;//处理图片,并封装为Image对象
ImageStore imageStore = new PrivateImageStore(/*省略构造函数*/);
imagestore.upload(image, BUCKET_NAME);
}
继承是面向对象的四大特性之一,用来表示类之间的 is-a 关系,可以解决代码复用的问题。虽然继承有诸多作用,但继承层次过深、过复杂,也会影响到代码的可维护性。在这种情况下,我们应该尽量少用,甚至不用继承。
继承最大的问题就在于:继承层次过深、继承关系过于复杂会影响到代码的可读性和可维护性。
继承主要有三个作用:表示 is-a 关系,支持多态特性,代码复用。而这三个作用都可以通过组合、接口、委托三个技术手段来达成。除此之外,利用组合还能解决层次过深、过复杂的继承关系影响代码可维护性的问题。接口表示具有某种行为特性。
is-a 关系,我们可以通过组合和接口的 has-a 关系来替代;
多态特性我们可以利用接口来实现;
代码复用我们可以通过组合和委托来实现。
从理论上讲,通过组合、接口、委托三个技术手段,我们完全可以替换掉继承。
public interface Flyable {
void fly();
}
public class FlyAbility implements Flyable {
@Override
public void fly() { //... }
}
//省略Tweetable/TweetAbility/EggLayable/EggLayAbility
public class Ostrich implements Tweetable, EggLayable {//鸵鸟
private TweetAbility tweetAbility = new TweetAbility(); //组合
private EggLayAbility eggLayAbility = new EggLayAbility(); //组合
//... 省略其他属性和方法...
@Override
public void tweet() {
tweetAbility.tweet(); // 委托
}
@Override
public void layEgg() {
eggLayAbility.layEgg(); // 委托
}
}
尽管我们鼓励多用组合少用继承,但组合也并不是完美的,继承也并非一无是处。
继承改写成组合意味着要做更细粒度的类的拆分。这也就意味着,我们要定义更多的类和接口。类和接口的增多也就或多或少地增加代码的复杂程度和维护成本。所以,在实际的项目开发中,我们还是要根据具体的情况,来具体选择该用继承还是组合。
如果类之间的继承结构稳定(不会轻易改变),继承层次比较浅(比如,最多有两层继承关系),继承关系不复杂,我们就可以大胆地使用继承。反之,系统越不稳定,继承层次很深,继承关系复杂,我们就尽量使用组合来替代继承。
除此之外,还有一些设计模式、特殊的应用场景,会固定使用继承或者组合。比如,装饰者模式(decorator pattern)、策略模式(strategy pattern)、组合模式(composite pattern)等都使用了组合关系,而模板模式(template pattern)使用了继承关系。
举例1:从业务含义上,A 类和 B 类并不一定具有继承关系。比如,Crawler 类和 PageAnalyzer 类,它们都用到了 URL 拼接和分割的功能,但并不具有继承关系(既不是父子关系,也不是兄弟关系)。这时候用组合。
public class Url {
//...省略属性和方法
}
public class Crawler {
private Url url; // 组合
public Crawler() {
this.url = new Url();
}
//...
}
public class PageAnalyzer {
private Url url; // 组合
public PageAnalyzer() {
this.url = new Url();
}
//..
}
举例2:特殊的场景要求我们必须使用继承。有一个方法的形参是类,不是接口,我们也不能改变形参类型。为了支持多态的特性,只能使用继承。
比如下面这样一段代码,其中 FeignClient 是一个外部类,我们没有权限去修改这部分代码,但是我们希望能重写这个类在运行时执行的 encode() 函数。这个时候,我们只能采用继承来实现了。
public class FeignClient { // Feign Client框架代码
//...省略其他代码...
public void encode(String url) { //... }
}
public void demofunction(FeignClient feignClient) {
//...
feignClient.encode(url);
//...
}
public class CustomizedFeignClient extends FeignClient {
@Override
public void encode(String url) { //...重写encode的实现...}
}
// 调用
FeignClient client = new CustomizedFeignClient();
demofunction(client);
package test2;
import test1.People;
public class Woman extends People {
public void eat(){
System.out.println("女人吃蔬菜");
}
public static void startEat(People People){
People.eat();
}
public static void main(String[] args){
People people = new Woman();
startEat(people);
}
}
package test1;
public class People {
public void eat(){
System.out.println("人吃食物");
}
}
我们平时做 Web 项目的业务开发,大部分都是基于贫血模型的 MVC 三层架构,在专栏中我把它称为传统的开发模式。之所以称之为“传统”,是相对于新兴的基于充血模型的 DDD 开发模式来说的。基于贫血模型的传统开发模式,是典型的面向过程的编程风格。相反,基于充血模型的 DDD 开发模式,是典型的面向对象的编程风格。
MVC 三层架构中的 M 表示 Model,V 表示 View,C 表示 Controller。它将整个项目分为三层:展示层、逻辑层、数据层。
现在很多 Web 或者 App 项目都是前后端分离的,后端负责暴露接口给前端调用。这种情况下,我们一般就将后端项目分为 Repository 层、Service 层、Controller 层。其中,Repository 层负责数据访问,Service 层负责业务逻辑,Controller 层负责暴露接口。当然,这只是其中一种分层和命名方式。不同的项目、不同的团队,可能会对此有所调整。不过,只要是依赖数据库开发的 Web 项目,基本的分层思路都差不多。
在贫血模型中,数据和业务逻辑被分割到不同的类中。充血模型(Rich Domain Model),数据和对应的业务逻辑被封装到同一个类中。
基于充血模型的 DDD 开发模式实现的代码,也是按照 MVC 三层架构分层的。Controller 层还是负责暴露接口,Repository 层还是负责数据存取,Service 层负责核心业务逻辑。它跟基于贫血模型的传统开发模式的区别主要在 Service 层。
不过,DDD 也并非银弹。对于业务不复杂的系统开发来说,基于贫血模型的传统开发模式简单够用,基于充血模型的 DDD 开发模式有点大材小用,无法发挥作用。相反,对于业务复杂的系统开发来说,基于充血模型的 DDD 开发模式,因为前期需要在设计上投入更多时间和精力,来提高代码的复用性和可维护性,所以相比基于贫血模型的开发模式,更加有优势。
public class VirtualWalletController {
// 通过构造函数或者IOC框架注入
private VirtualWalletService virtualWalletService;
public BigDecimal getBalance(Long walletId) { ... } //查询余额
public void debit(Long walletId, BigDecimal amount) { ... } //出账
public void credit(Long walletId, BigDecimal amount) { ... } //入账
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) { ...} //转账
//省略查询transaction的接口
}
public class VirtualWalletBo {//省略getter/setter/constructor方法
private Long id;
private Long createTime;
private BigDecimal balance;
}
public Enum TransactionType {
DEBIT,
CREDIT,
TRANSFER;
}
public class VirtualWalletService {
// 通过构造函数或者IOC框架注入
private VirtualWalletRepository walletRepo;
private VirtualWalletTransactionRepository transactionRepo;
public VirtualWalletBo getVirtualWallet(Long walletId) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWalletBo walletBo = convert(walletEntity);
return walletBo;
}
public BigDecimal getBalance(Long walletId) {
return walletRepo.getBalance(walletId);
}
@Transactional
public void debit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
BigDecimal balance = walletEntity.getBalance();
if (balance.compareTo(amount) < 0) {
throw new NoSufficientBalanceException(...);
}
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.DEBIT);
transactionEntity.setFromWalletId(walletId);
transactionRepo.saveTransaction(transactionEntity);
walletRepo.updateBalance(walletId, balance.subtract(amount));
}
@Transactional
public void credit(Long walletId, BigDecimal amount) {
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.CREDIT);
transactionEntity.setFromWalletId(walletId);
transactionRepo.saveTransaction(transactionEntity);
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
BigDecimal balance = walletEntity.getBalance();
walletRepo.updateBalance(walletId, balance.add(amount));
}
@Transactional
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.TRANSFER);
transactionEntity.setFromWalletId(fromWalletId);
transactionEntity.setToWalletId(toWalletId);
transactionRepo.saveTransaction(transactionEntity);
debit(fromWalletId, amount);
credit(toWalletId, amount);
}
}
Controller 中,主要就是调用 Service 的方法。Service 和 BO 负责核心业务逻辑,Repository 和 Entity 负责数据存取。
基于充血模型的 DDD 开发模式,跟基于贫血模型的传统开发模式的主要区别就在 Service 层,Controller 层和 Repository 层的代码基本上相同。
把虚拟钱包 VirtualWallet 类设计成一个充血的 Domain 领域模型,并且将原来在 Service 类中的部分业务逻辑移动到 VirtualWallet 类中,让 Service 类的实现依赖 VirtualWallet 类。
public class VirtualWallet { // Domain领域模型(充血模型)
private Long id;
private Long createTime = System.currentTimeMillis();;
private BigDecimal balance = BigDecimal.ZERO;
public VirtualWallet(Long preAllocatedId) {
this.id = preAllocatedId;
}
public BigDecimal balance() {
return this.balance;
}
public void debit(BigDecimal amount) {
if (this.balance.compareTo(amount) < 0) {
throw new InsufficientBalanceException(...);
}
this.balance = this.balance.subtract(amount);
}
public void credit(BigDecimal amount) {
if (amount.compareTo(BigDecimal.ZERO) < 0) {
throw new InvalidAmountException(...);
}
this.balance = this.balance.add(amount);
}
}
public class VirtualWalletService {
// 通过构造函数或者IOC框架注入
private VirtualWalletRepository walletRepo;
private VirtualWalletTransactionRepository transactionRepo;
public VirtualWallet getVirtualWallet(Long walletId) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
return wallet;
}
public BigDecimal getBalance(Long walletId) {
return walletRepo.getBalance(walletId);
}
@Transactional
public void debit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.debit(amount);
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.DEBIT);
transactionEntity.setFromWalletId(walletId);
transactionRepo.saveTransaction(transactionEntity);
walletRepo.updateBalance(walletId, wallet.balance());
}
@Transactional
public void credit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.credit(amount);
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setType(TransactionType.CREDIT);
transactionEntity.setFromWalletId(walletId);
transactionRepo.saveTransaction(transactionEntity);
walletRepo.updateBalance(walletId, wallet.balance());
}
@Transactional
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
//...跟基于贫血模型的传统开发模式的代码一样...
}
}
领域模型 VirtualWallet 类很单薄,包含的业务逻辑很简单。相对于原来的贫血模型的设计思路,这种充血模型的设计思路,貌似并没有太大优势。你说得没错!这也是大部分业务系统都使用基于贫血模型开发的原因。不过,如果虚拟钱包系统需要支持更复杂的业务逻辑,那充血模型的优势就显现出来了。比如,我们要支持透支一定额度和冻结部分余额的功能。这个时候,我们重新来看一下 VirtualWallet 类的实现代码。
public class VirtualWallet {
private Long id;
private Long createTime = System.currentTimeMillis();;
private BigDecimal balance = BigDecimal.ZERO;
private boolean isAllowedOverdraft = true;
private BigDecimal overdraftAmount = BigDecimal.ZERO;
private BigDecimal frozenAmount = BigDecimal.ZERO;
public VirtualWallet(Long preAllocatedId) {
this.id = preAllocatedId;
}
public void freeze(BigDecimal amount) { ... }
public void unfreeze(BigDecimal amount) { ...}
public void increaseOverdraftAmount(BigDecimal amount) { ... }
public void decreaseOverdraftAmount(BigDecimal amount) { ... }
public void closeOverdraft() { ... }
public void openOverdraft() { ... }
public BigDecimal balance() {
return this.balance;
}
public BigDecimal getAvaliableBalance() {
BigDecimal totalAvaliableBalance = this.balance.subtract(this.frozenAmount);
if (isAllowedOverdraft) {
totalAvaliableBalance += this.overdraftAmount;
}
return totalAvaliableBalance;
}
public void debit(BigDecimal amount) {
BigDecimal totalAvaliableBalance = getAvaliableBalance();
if (totoalAvaliableBalance.compareTo(amount) < 0) {
throw new InsufficientBalanceException(...);
}
this.balance = this.balance.subtract(amount);
}
public void credit(BigDecimal amount) {
if (amount.compareTo(BigDecimal.ZERO) < 0) {
throw new InvalidAmountException(...);
}
this.balance = this.balance.add(amount);
}
}
第一个要讨论的问题是:在基于充血模型的 DDD 开发模式中,将业务逻辑移动到 Domain 中,Service 类变得很薄,但在我们的代码设计与实现中,并没有完全将 Service 类去掉,这是为什么?或者说,Service 类在这种情况下担当的职责是什么?哪些功能逻辑会放到 Service 类中?
区别于 Domain 的职责,Service 类主要有下面这样几个职责。
1.Service 类负责与 Repository 交流。在我的设计与代码实现中,VirtualWalletService 类负责与 Repository 层打交道,调用 Respository 类的方法,获取数据库中的数据,转化成领域模型 VirtualWallet,然后由领域模型 VirtualWallet 来完成业务逻辑,最后调用 Repository 类的方法,将数据存回数据库。
之所以让 VirtualWalletService 类与 Repository 打交道,而不是让领域模型 VirtualWallet 与 Repository 打交道,那是因为我们想保持领域模型的独立性,不与任何其他层的代码(Repository 层的代码)或开发框架(比如 Spring、MyBatis)耦合在一起,将流程性的代码逻辑(比如从 DB 中取数据、映射数据)与领域模型的业务逻辑解耦,让领域模型更加可复用。
2.Service 类负责跨领域模型的业务聚合功能。VirtualWalletService 类中的 transfer() 转账函数会涉及两个钱包的操作,因此这部分业务逻辑无法放到 VirtualWallet 类中,所以,我们暂且把转账业务放到 VirtualWalletService 类中了。当然,虽然功能演进,使得转账业务变得复杂起来之后,我们也可以将转账业务抽取出来,设计成一个独立的领域模型。
3.Service 类负责一些非功能性及与三方系统交互的工作。比如幂等、事务、发邮件、发消息、记录日志、调用其他系统的 RPC 接口等,都可以放到 Service 类中。
第二个要讨论问题是:在基于充血模型的 DDD 开发模式中,尽管 Service 层被改造成了充血模型,但是 Controller 层和 Repository 层还是贫血模型,是否有必要也进行充血领域建模呢?
答案是没有必要。Controller 层主要负责接口的暴露,Repository 层主要负责与数据库打交道,这两层包含的业务逻辑并不多,前面我们也提到了,如果业务逻辑比较简单,就没必要做充血建模,即便设计成充血模型,类也非常单薄,看起来也很奇怪。
Repository 的 Entity 来说,即便它被设计成贫血模型,违反面向对象编程的封装特性,有被任意代码修改数据的风险,但 Entity 的生命周期是有限的。一般来讲,我们把它传递到 Service 层之后,就会转化成 BO 或者 Domain 来继续后面的业务逻辑。Entity 的生命周期到此就结束了,所以也并不会被到处任意修改。
Controller 层的 VO。实际上 VO 是一种 DTO(Data Transfer Object,数据传输对象)。它主要是作为接口的数据传输承载体,将数据发送给其他系统。从功能上来讲,它理应不包含业务逻辑、只包含数据。所以,我们将它设计成贫血模型也是比较合理的。
业务逻辑主要集中在 Service 层。所以,Repository 层和 Controller 层继续沿用贫血模型的设计思路是没有问题的。
如何进行面向对象分析、设计与编程。
尽管针对框架、组件、类库等非业务系统的开发,我们一定要有组件化意识、框架意识、抽象意识,开发出来的东西要足够通用,不能局限于单一的某个业务需求,但这并不代表我们就可以脱离具体的应用场景,闷头拍脑袋做需求分析。多跟业务团队聊聊天,甚至自己去参与几个业务系统的开发,只有这样,我们才能真正知道业务系统的痛点,才能分析出最有价值的需求。
针对鉴权这一功能的开发,最大的需求方还是我们自己,所以,我们也可以先从满足我们自己系统的需求开始,然后再迭代优化。
针对鉴权这个功能的开发,我们该如何做需求分析?(面向对象分析(OOA))
最简单的解决方案就是,通过用户名加密码来做认证。我们给每个允许访问我们服务的调用方,派发一个应用名(或者叫应用 ID、AppID)和一个对应的密码(或者叫秘钥)。调用方每次进行接口请求的时候,都携带自己的 AppID 和密码。微服务在接收到接口调用请求之后,会解析出 AppID 和密码,跟存储在微服务端的 AppID 和密码进行比对。如果一致,说明认证成功,则允许接口调用请求;否则,就拒绝接口调用请求。
每次都要明文传输密码。密码很容易被截获,是不安全的。即使对密码进行加密之后,照样可以被未认证系统(或者说黑客)截获,未认证系统可以携带这个加密之后的密码以及对应的 AppID,伪装成已认证系统来访问我们的接口。这就是典型的“重放攻击”。
解决:借助 OAuth 的验证思路来解决。调用方将请求接口的 URL 跟 AppID、密码拼接在一起,然后进行加密,生成一个 token。调用方在进行接口请求的的时候,将这个 token 及 AppID,随 URL 一块传递给微服务端。微服务端接收到这些数据之后,根据 AppID 从数据库中取出对应的密码,并通过同样的 token 生成算法,生成另外一个 token。用这个新生成的 token 跟调用方传递过来的 token 对比。如果一致,则允许接口调用请求;否则,就拒绝接口调用请求。
每个 URL 拼接上 AppID、密码生成的 token 都是固定的。未认证系统截获 URL、token 和 AppID 之后,还是可以通过重放攻击的方式,伪装成认证系统,调用这个 URL 对应的接口。
解决:优化 token 生成算法,引入一个随机变量,让每次接口请求生成的 token 都不一样。我们可以选择时间戳作为随机变量。原来的 token 是对 URL、AppID、密码三者进行加密生成的,现在我们将 URL、AppID、密码、时间戳四者进行加密来生成 token。调用方在进行接口请求的时候,将 token、AppID、时间戳,随 URL 一并传递给微服务端。
微服务端在收到这些数据之后,会验证当前时间戳跟传递过来的时间戳,是否在一定的时间窗口内(比如一分钟)。如果超过一分钟,则判定 token 过期,拒绝接口请求。如果没有超过一分钟,则说明 token 没有过期,就再通过同样的 token 生成算法,在服务端生成新的 token,与调用方传递过来的 token 比对,看是否一致。如果一致,则允许接口调用请求;否则,就拒绝接口调用请求。

这个方案虽然还有漏洞,但是实现起来足够简单,而且不会过度影响接口本身的性能(比如响应时间)。所以,权衡安全性、开发成本、对系统性能的影响,这个方案算是比较折中、比较合理的了。
如何在微服务端存储每个授权调用方的 AppID 和密码?
开发像鉴权这样的非业务功能,最好不要与具体的第三方系统有过度的耦合。
针对 AppID 和密码的存储,我们最好能灵活地支持各种不同的存储方式,比如 ZooKeeper、本地配置文件、自研配置中心、MySQL、Redis 等。我们不一定针对每种存储方式都去做代码实现,但起码要留有扩展点,保证系统有足够的灵活性和扩展性,能够在我们切换存储方式的时候,尽可能地减少代码的改动。
5. 最终确定需求
针对框架、类库、组件等非业务系统的开发,其中一个比较大的难点就是,需求一般都比较抽象、模糊,需要你自己去挖掘,做合理取舍、权衡、假设,把抽象的问题具象化,最终产生清晰的、可落地的需求定义。需求定义是否清晰、合理,直接影响了后续的设计、编码实现是否顺畅。所以,作为程序员,你一定不要只关心设计与实现,前期的需求分析同等重要。
需求分析的过程实际上是一个不断迭代优化的过程。我们不要试图一下就能给出一个完美的解决方案,而是先给出一个粗糙的、基础的方案,有一个迭代的基础,然后再慢慢优化,这样一个思考过程能让我们摆脱无从下手的窘境。
面向对象分析的产出是详细的需求描述,那面向对象设计的产出就是类。在面向对象设计环节,我们将需求描述转化为具体的类的设计。我们把这一设计环节拆解细化一下,主要包含以下几个部分:
划分职责进而识别出有哪些类;
定义类及其属性和方法;
定义类与类之间的交互关系;
将类组装起来并提供执行入口。
识别类的三种方法:
1、类是现实世界中事物的一个建模。但是,并不是每个需求都能映射到现实世界,也并不是每个类都与现实世界中的事物一一对应。对于一些抽象的概念,我们是无法通过映射现实世界中的事物的方式来定义类的。
2、把需求描述中的名词罗列出来,作为可能的候选类,然后再进行筛选。对于没有经验的初学者来说,这个方法比较简单、明确,可以直接照着做。
3、根据需求描述,把其中涉及的功能点,一个一个罗列出来,然后再去看哪些功能点职责相近,操作同样的属性,是否应该归为同一个类。

首先,我们要做的是逐句阅读上面的需求描述,拆解成小的功能点,一条一条罗列下来。注意,拆解出来的每个功能点要尽可能的小。每个功能点只负责做一件很小的事情(专业叫法是“单一职责”)。
功能点列表:

1、2、6、7 都是跟 token 有关,负责 token 的生成、验证;3、4 都是在处理 URL,负责 URL 的拼接、解析;5 是操作 AppID 和密码,负责从存储中读取 AppID 和密码。所以,我们可以粗略地得到三个核心的类:AuthToken、Url、CredentialStorage。AuthToken 负责实现 1、2、6、7 这四个操作;Url 负责 3、4 两个操作;CredentialStorage 负责 5 这个操作。
这是一个初步的类的划分,其他一些不重要的、边边角角的类,我们可能暂时没法一下子想全,但这也没关系,面向对象分析、设计、编程本来就是一个循环迭代、不断优化的过程。根据需求,我们先给出一个粗糙版本的设计方案,然后基于这样一个基础,再去迭代优化,会更加容易一些,思路也会更加清晰一些。
接口调用鉴权这个开发需求比较简单,所以,需求对应的面向对象设计并不复杂,识别出来的类也并不多。但如果我们面对的是更加大型的软件开发、更加复杂的需求开发,涉及的功能点可能会很多,对应的类也会比较多,像刚刚那样根据需求逐句罗列功能点的方法,最后会得到一个长长的列表,就会有点凌乱、没有规律。针对这种复杂的需求开发,我们首先要做的是进行模块划分,将需求先简单划分成几个小的、独立的功能模块,然后再在模块内部,应用我们刚刚讲的方法,进行面向对象设计。而模块的划分和识别,跟类的划分和识别,是类似的套路。
刚刚我们通过分析需求描述,识别出了三个核心的类,它们分别是 AuthToken、Url 和 CredentialStorage。
从功能点列表中挖掘,每个类都有哪些属性和方法。

对于方法的识别,识别出需求描述中的动词,作为候选的方法,再进一步过滤筛选。类比一下方法的识别,我们可以把功能点中涉及的名词,作为候选属性,然后同样进行过滤筛选。

从上面的类图中,我们可以发现这样三个小细节。

第一个细节告诉我们,从业务模型上来说,不应该属于这个类的属性和方法,不应该被放到这个类里。比如 URL、AppID 这些信息,从业务模型上来说,不应该属于 AuthToken,所以我们不应该放到这个类中。
第二、第三个细节告诉我们,在设计类具有哪些属性和方法的时候,不能单纯地依赖当下的需求,还要分析这个类从业务模型上来讲,理应具有哪些属性和方法。这样可以一方面保证类定义的完整性,另一方面不仅为当下的需求还为未来的需求做些准备。
Url 类相关的功能点有两个:

虽然需求描述中,我们都是以 URL 来代指接口请求,但是,接口请求并不一定是以 URL 的形式来表达,还有可能是 Dubbo、RPC 等其他形式。为了让这个类更加通用,命名更加贴切,我们接下来把它命名为 ApiRequest。

CredentialStorage 类相关的功能点有一个:从存储中取出 AppID 和对应的密码。
为了做到抽象封装具体的存储方式,我们将 CredentialStorage 设计成了接口,基于接口而非具体的实现编程。

类与类之间都有哪些交互关系呢?UML 统一建模语言中定义了六种类之间的关系。它们分别是:泛化、实现、关联、聚合、组合、依赖。
泛化(Generalization)可以简单理解为继承关系。

实现(Realization)一般是指接口和实现类之间的关系。

聚合(Aggregation)是一种包含关系,A 类对象包含 B 类对象,B 类对象的生命周期可以不依赖 A 类对象的生命周期,也就是说可以单独销毁 A 类对象而不影响 B 对象,比如课程与学生之间的关系。

组合(Composition)也是一种包含关系。A 类对象包含 B 类对象,B 类对象的生命周期依赖 A 类对象的生命周期,B 类对象不可单独存在,比如鸟与翅膀之间的关系。

关联(Association)是一种非常弱的关系,包含聚合、组合两种关系。具体到代码层面,如果 B 类对象是 A 类的成员变量,那 B 类和 A 类就是关联关系。


依赖(Dependency)是一种比关联关系更加弱的关系,包含关联关系。不管是 B 类对象是 A 类对象的成员变量,还是 A 类的方法使用 B 类对象作为参数或者返回值、局部变量,只要 B 类对象和 A 类对象有任何使用关系,我们都称它们有依赖关系。



从更加贴近编程的角度,对类与类之间的关系做了调整,只保留了四个关系:泛化、实现、组合、依赖。其中,泛化、实现、依赖的定义不变,组合关系替代 UML 中组合、聚合、关联三个概念。
之所以这样重新命名,是为了跟我们前面讲的“多用组合少用继承”设计原则中的“组合”统一含义。只要 B 类对象是 A 类对象的成员变量,那我们就称,A 类跟 B 类是组合关系。
因为目前只有三个核心的类,所以只用到了实现关系,也即 CredentialStorage 和 MysqlCredentialStorage 之间的关系。接下来讲到组装类的时候,我们还会用到依赖关系、组合关系,但是泛化关系暂时没有用到。
类定义好了,类之间必要的交互关系也设计好了,接下来我们要将所有的类组装在一起,提供一个执行入口。这个入口可能是一个 main() 函数,也可能是一组给外部用的 API 接口。通过这个入口,我们能触发整个代码跑起来。
接口鉴权并不是一个独立运行的系统,而是一个集成在系统上运行的组件,所以,我们封装所有的实现细节,设计了一个最顶层的 ApiAuthenticator 接口类,暴露一组给外部调用者使用的 API 接口,作为触发执行鉴权逻辑的入口。

面向对象设计完成之后,我们已经定义清晰了类、属性、方法、类之间的交互,并且将所有的类组装起来,提供了统一的执行入口。接下来,面向对象编程的工作,就是将这些设计思路翻译成代码实现。
比如ApiAuthenticator 的实现。
public interface ApiAuthenticator {
void auth(String url);
void auth(ApiRequest apiRequest);
}
public class DefaultApiAuthenticatorImpl implements ApiAuthenticator {
private CredentialStorage credentialStorage;
public DefaultApiAuthenticatorImpl() {
this.credentialStorage = new MysqlCredentialStorage();
}
public DefaultApiAuthenticatorImpl(CredentialStorage credentialStorage) {
this.credentialStorage = credentialStorage;
}
@Override
public void auth(String url) {
ApiRequest apiRequest = ApiRequest.buildFromUrl(url);
auth(apiRequest);
}
@Override
public void auth(ApiRequest apiRequest) {
String appId = apiRequest.getAppId();
String token = apiRequest.getToken();
long timestamp = apiRequest.getTimestamp();
String originalUrl = apiRequest.getOriginalUrl();
AuthToken clientAuthToken = new AuthToken(token, timestamp);
if (clientAuthToken.isExpired()) {
throw new RuntimeException("Token is expired.");
}
String password = credentialStorage.getPasswordByAppId(appId);
AuthToken serverAuthToken = AuthToken.generate(originalUrl, appId, password, timestamp);
if (!serverAuthToken.match(clientAuthToken)) {
throw new RuntimeException("Token verfication failed.");
}
}
}
在之前的讲解中,面向对象分析、设计、实现,每个环节的界限划分都比较清楚。而且,设计和实现基本上是按照功能点的描述,逐句照着翻译过来的。这样做的好处是先做什么、后做什么,非常清晰、明确,有章可循,即便是没有太多设计经验的初级工程师,都可以按部就班地参照着这个流程来做分析、设计和实现。
在平时的工作中,大部分程序员往往都是在脑子里或者草纸上完成面向对象分析和设计,然后就开始写代码了,边写边思考边重构,并不会严格地按照刚刚的流程来执行。而且,说实话,即便我们在写代码之前,花很多时间做分析和设计,绘制出完美的类图、UML 图,也不可能把每个细节、交互都想得很清楚。在落实到代码的时候,我们还是要反复迭代、重构、打破重写。
整个软件开发本来就是一个迭代、修修补补、遇到问题解决问题的过程,是一个不断重构的过程。我们没法严格地按照顺序执行各个步骤。
类似你去学驾照,驾校教的都是比较正规的流程,先做什么,后做什么,你只要照着做就能顺利倒车入库,但实际上,等你开熟练了,倒车入库很多时候靠的都是经验和感觉。
SOLID 原则是由 5 个设计原则组成的,它们分别是:单一职责原则、开闭原则、里式替换原则、接口隔离原则和依赖反转原则,依次对应 SOLID 中的 S、O、L、I、D 这 5 个英文字母。
单一职责原则的英文是 Single Responsibility Principle,缩写为 SRP。对应“S”。
A class or module should have a single responsibility。
一个类或者模块只负责完成一个职责(或者功能)。
一个是类(class),一个是模块(module)。
有两种理解方式。一种理解是:把模块看作比类更加抽象的概念,类也可以看作模块。另一种理解是:把模块看作比类更加粗粒度的代码块,模块中包含多个类,多个类组成一个模块。
从“类”设计的角度,来讲解如何应用这个设计原则。
不要设计大而全的类,要设计粒度小、功能单一的类。换个角度来讲就是,一个类包含了两个或者两个以上业务不相干的功能,那我们就说它职责不够单一,应该将它拆分成多个功能更加单一、粒度更细的类。
比如,一个类里既包含订单的一些操作,又包含用户的一些操作。而订单和用户是两个独立的业务领域模型,我们将两个不相干的功能放到同一个类中,那就违反了单一职责原则。为了满足单一职责原则,我们需要将这个类拆分成两个粒度更细、功能更加单一的两个类:订单类和用户类。
大部分情况下,类里的方法是归为同一类功能,还是归为不相关的两类功能,并不是那么容易判定的。在真实的软件开发中,对于一个类是否职责单一的判定,是很难拿捏的。
评价一个类的职责是否足够单一,我们并没有一个非常明确的、可以量化的标准,可以说,这是件非常主观、仁者见仁智者见智的事情。实际上,在真正的软件开发中,我们也没必要过于未雨绸缪,过度设计。所以,我们可以先写一个粗粒度的类,满足业务需求。随着业务的发展,如果粗粒度的类越来越庞大,代码越来越多,这个时候,我们就可以将这个粗粒度的类,拆分成几个更细粒度的类。这就是所谓的持续重构。
一些小技巧,能够很好地帮你,从侧面上判定一个类的职责是否够单一。
那多少行代码才算是行数过多呢?多少个函数、属性才称得上过多呢?比较初级的工程师经常会问这类问题。实际上,这个问题并不好定量地回答,就像你问大厨“放盐少许”中的“少许”是多少,大厨也很难告诉你一个特别具体的量值。
一些菜谱确实给出了,做某某菜需要放多少克盐,放多少克油的具体量值啊。我想说的是,那是给家庭主妇用的,那不是给专业的大厨看的。
实际上, 从另一个角度来看,当一个类的代码,读起来让你头大了,实现某个功能时不知道该用哪个函数了,想用哪个函数翻半天都找不到了,只用到一个小功能要引入整个类(类中包含很多无关此功能实现的函数)的时候,这就说明类的行数、函数、属性过多了。实际上,等你做多项目了,代码写多了,在开发中慢慢“品尝”,自然就知道什么是“放盐少许”了,这就是所谓的“专业第六感”。
为了满足单一职责原则,是不是把类拆得越细就越好呢?答案是否定的。
举例:Serialization 类实现了一个简单协议的序列化和反序列功能。
如果我们想让类的职责更加单一,我们对 Serialization 类进一步拆分,拆分成一个只负责序列化工作的 Serializer 类和另一个只负责反序列化工作的 Deserializer 类。
虽然经过拆分之后,Serializer 类和 Deserializer 类的职责更加单一了,但也随之带来了新的问题。如果我们修改了协议的格式,数据标识从“UEUEUE”改为“DFDFDF”,或者序列化方式从 JSON 改为了 XML,那 Serializer 类和 Deserializer 类都需要做相应的修改,代码的内聚性显然没有原来 Serialization 高了。而且,如果我们仅仅对 Serializer 类做了协议修改,而忘记了修改 Deserializer 类的代码,那就会导致序列化、反序列化不匹配,程序运行出错,也就是说,拆分之后,代码的可维护性变差了。
实际上,不管是应用设计原则还是设计模式,最终的目的还是提高代码的可读性、可扩展性、复用性、可维护性等。我们在考虑应用某一个设计原则是否合理的时候,也可以以此作为最终的考量标准。
开闭原则是 SOLID 中最难理解、最难掌握,同时也是最有用的一条原则。对应“O”。
最有用,那是因为,扩展性是代码质量最重要的衡量标准之一。在 23 种经典设计模式中,大部分设计模式都是为了解决代码的扩展性问题而存在的,主要遵从的设计原则就是开闭原则。
我们要时刻具备扩展意识、抽象意识、封装意识。在写代码的时候,我们要多花点时间思考一下,这段代码未来可能有哪些需求变更,如何设计代码结构,事先留好扩展点,以便在未来需求变更的时候,在不改动代码整体结构、做到最小代码改动的情况下,将新的代码灵活地插入到扩展点上。
很多设计原则、设计思想、设计模式,都是以提高代码的扩展性为最终目的的。最常用来提高代码扩展性的方法有:多态、依赖注入、基于接口而非实现编程,以及大部分的设计模式(比如,装饰、策略、模板、职责链、状态)。
开闭原则,Open Closed Principle,简写为 OCP。
software entities (modules, classes, functions, etc.) should be open for extension , but closed for modification。
软件实体(模块、类、方法等)应该“对扩展开放、对修改关闭”。
就是,添加一个新的功能应该是,在已有代码基础上扩展代码(新增模块、类、方法等),而非修改已有代码(修改模块、类、方法等)。
关于定义,我们有两点要注意。第一点是,开闭原则并不是说完全杜绝修改,而是以最小的修改代码的代价来完成新功能的开发。第二点是,同样的代码改动,在粗代码粒度下,可能被认定为“修改”;在细代码粒度下,可能又被认定为“扩展”。
比如:这是一段 API 接口监控告警的代码。
其中,AlertRule 存储告警规则,可以自由设置。Notification 是告警通知类,支持邮件、短信、微信、手机等多种通知渠道。NotificationEmergencyLevel 表示通知的紧急程度,包括 SEVERE(严重)、URGENCY(紧急)、NORMAL(普通)、TRIVIAL(无关紧要),不同的紧急程度对应不同的发送渠道。
public class Alert {
private AlertRule rule;
private Notification notification;
public Alert(AlertRule rule, Notification notification) {
this.rule = rule;
this.notification = notification;
}
public void check(String api, long requestCount, long errorCount, long durationOfSeconds) {
long tps = requestCount / durationOfSeconds;
if (tps > rule.getMatchedRule(api).getMaxTps()) {
notification.notify(NotificationEmergencyLevel.URGENCY, "...");
}
if (errorCount > rule.getMatchedRule(api).getMaxErrorCount()) {
notification.notify(NotificationEmergencyLevel.SEVERE, "...");
}
}
}
业务逻辑主要集中在 check() 函数中。当接口的 TPS 超过某个预先设置的最大值时,以及当接口请求出错数大于某个最大允许值时,就会触发告警,通知接口的相关负责人或者团队。
现在,如果我们需要添加一个功能,当每秒钟接口超时请求个数,超过某个预先设置的最大阈值时,我们也要触发告警发送通知。这个时候,我们该如何改动代码呢?主要的改动有两处:第一处是修改 check() 函数的入参,添加一个新的统计数据 timeoutCount,表示超时接口请求数;第二处是在 check() 函数中添加新的告警逻辑。
public class Alert {
// ...省略AlertRule/Notification属性和构造函数...
// 改动一:添加参数timeoutCount
public void check(String api, long requestCount, long errorCount, long timeoutCount, long durationOfSeconds) {
long tps = requestCount / durationOfSeconds;
if (tps > rule.getMatchedRule(api).getMaxTps()) {
notification.notify(NotificationEmergencyLevel.URGENCY, "...");
}
if (errorCount > rule.getMatchedRule(api).getMaxErrorCount()) {
notification.notify(NotificationEmergencyLevel.SEVERE, "...");
}
// 改动二:添加接口超时处理逻辑
long timeoutTps = timeoutCount / durationOfSeconds;
if (timeoutTps > rule.getMatchedRule(api).getMaxTimeoutTps()) {
notification.notify(NotificationEmergencyLevel.URGENCY, "...");
}
}
}
这样的代码修改实际上存在挺多问题的。一方面,我们对接口进行了修改,这就意味着调用这个接口的代码都要做相应的修改。另一方面,修改了 check() 函数,相应的单元测试都需要修改。
上面的代码改动是基于“修改”的方式来实现新功能的。如果我们遵循开闭原则,也就是“对扩展开放、对修改关闭”。那如何通过“扩展”的方式,来实现同样的功能呢?
先重构一下之前的 Alert 代码,让它的扩展性更好一些。重构的内容主要包含两部分:

public class Alert {
private List<AlertHandler> alertHandlers = new ArrayList<>();
public void addAlertHandler(AlertHandler alertHandler) {
this.alertHandlers.add(alertHandler);
}
public void check(ApiStatInfo apiStatInfo) {
for (AlertHandler handler : alertHandlers) {
handler.check(apiStatInfo);
}
}
}
public class ApiStatInfo {//省略constructor/getter/setter方法
private String api;
private long requestCount;
private long errorCount;
private long durationOfSeconds;
}
public abstract class AlertHandler {
protected AlertRule rule;
protected Notification notification;
public AlertHandler(AlertRule rule, Notification notification) {
this.rule = rule;
this.notification = notification;
}
public abstract void check(ApiStatInfo apiStatInfo);
}
public class TpsAlertHandler extends AlertHandler {
public TpsAlertHandler(AlertRule rule, Notification notification) {
super(rule, notification);
}
@Override
public void check(ApiStatInfo apiStatInfo) {
long tps = apiStatInfo.getRequestCount()/ apiStatInfo.getDurationOfSeconds();
if (tps > rule.getMatchedRule(apiStatInfo.getApi()).getMaxTps()) {
notification.notify(NotificationEmergencyLevel.URGENCY, "...");
}
}
}
public class ErrorAlertHandler extends AlertHandler {
public ErrorAlertHandler(AlertRule rule, Notification notification){
super(rule, notification);
}
@Override
public void check(ApiStatInfo apiStatInfo) {
if (apiStatInfo.getErrorCount() > rule.getMatchedRule(apiStatInfo.getApi()).getMaxErrorCount()) {
notification.notify(NotificationEmergencyLevel.SEVERE, "...");
}
}
}
上面的代码是对 Alert 的重构,我们再来看下,重构之后的 Alert 该如何使用呢?具体的使用代码我也写在这里了。
其中,ApplicationContext 是一个单例类,负责 Alert 的创建、组装(alertRule 和 notification 的依赖注入)、初始化(添加 handlers)工作。
public class ApplicationContext {
private AlertRule alertRule;
private Notification notification;
private Alert alert;
public void initializeBeans() {
alertRule = new AlertRule(/*.省略参数.*/); //省略一些初始化代码
notification = new Notification(/*.省略参数.*/); //省略一些初始化代码
alert = new Alert();
alert.addAlertHandler(new TpsAlertHandler(alertRule, notification));
alert.addAlertHandler(new ErrorAlertHandler(alertRule, notification));
}
public Alert getAlert() { return alert; }
// 饿汉式单例
private static final ApplicationContext instance = new ApplicationContext();
private ApplicationContext() {
initializeBeans();
}
public static ApplicationContext getInstance() {
return instance;
}
}
public class Demo {
public static void main(String[] args) {
ApiStatInfo apiStatInfo = new ApiStatInfo();
// ...省略设置apiStatInfo数据值的代码
ApplicationContext.getInstance().getAlert().check(apiStatInfo);
}
}
基于重构之后的代码,如果再添加上面讲到的那个新功能,每秒钟接口超时请求个数超过某个最大阈值就告警,我们又该如何改动代码呢?

public class Alert { // 代码未改动... }
public class ApiStatInfo {//省略constructor/getter/setter方法
private String api;
private long requestCount;
private long errorCount;
private long durationOfSeconds;
private long timeoutCount; // 改动一:添加新字段
}
public abstract class AlertHandler { //代码未改动... }
public class TpsAlertHandler extends AlertHandler {//代码未改动...}
public class ErrorAlertHandler extends AlertHandler {//代码未改动...}
// 改动二:添加新的handler
public class TimeoutAlertHandler extends AlertHandler {//省略代码...}
public class ApplicationContext {
private AlertRule alertRule;
private Notification notification;
private Alert alert;
public void initializeBeans() {
alertRule = new AlertRule(/*.省略参数.*/); //省略一些初始化代码
notification = new Notification(/*.省略参数.*/); //省略一些初始化代码
alert = new Alert();
alert.addAlertHandler(new TpsAlertHandler(alertRule, notification));
alert.addAlertHandler(new ErrorAlertHandler(alertRule, notification));
// 改动三:注册handler
alert.addAlertHandler(new TimeoutAlertHandler(alertRule, notification));
}
//...省略其他未改动代码...
}
public class Demo {
public static void main(String[] args) {
ApiStatInfo apiStatInfo = new ApiStatInfo();
// ...省略apiStatInfo的set字段代码
apiStatInfo.setTimeoutCount(289); // 改动四:设置tiemoutCount值
ApplicationContext.getInstance().getAlert().check(apiStatInfo);
}
重构之后的代码更加灵活和易扩展。如果我们要想添加新的告警逻辑,只需要基于扩展的方式创建新的 handler 类即可,不需要改动原来的 check() 函数的逻辑。而且,我们只需要为新的 handler 类添加单元测试,老的单元测试都不会失败,也不用修改。
对于改动一:往 ApiStatInfo 类中添加新的属性 timeoutCount。
不仅往 ApiStatInfo 类中添加了属性,还添加了对应的 getter/setter 方法。那这个问题就转化为:给类中添加新的属性和方法,算作“修改”还是“扩展”?
从定义中,我们可以看出,开闭原则可以应用在不同粒度的代码中,可以是模块,也可以类,还可以是方法(及其属性)。同样一个代码改动,在粗代码粒度下,被认定为“修改”,在细代码粒度下,又可以被认定为“扩展”。比如,改动一,添加属性和方法相当于修改类,在类这个层面,这个代码改动可以被认定为“修改”;但这个代码改动并没有修改已有的属性和方法,在方法(及其属性)这一层面,它又可以被认定为“扩展”。
没必要纠结某个代码改动是“修改”还是“扩展”,更没必要太纠结它是否违反“开闭原则”。我们回到这条原则的设计初衷:只要它没有破坏原有的代码的正常运行,没有破坏原有的单元测试,我们就可以说,这是一个合格的代码改动。
对于改动三和改动四:在 ApplicationContext 类的 initializeBeans() 方法中,往 alert 对象中注册新的 timeoutAlertHandler;在使用 Alert 类的时候,需要给 check() 函数的入参 apiStatInfo 对象设置 timeoutCount 的值。
这两处改动都是在方法内部进行的,是地地道道的“修改”。不过,有些修改是在所难免的,是可以被接受的。因为:
在重构之后的 Alert 代码中,我们的核心逻辑集中在 Alert 类及其各个 handler 中,当我们在添加新的告警逻辑的时候,Alert 类完全不需要修改,而只需要扩展一个新 handler 类。如果我们把 Alert 类及各个 handler 类合起来看作一个“模块”,那模块本身在添加新的功能的时候,完全满足开闭原则。
添加一个新功能,类需要创建、组装、并且做一些初始化操作,才能构建成可运行的的程序,这部分代码的修改是在所难免的。我们要做的是尽量让修改操作更集中、更少、更上层,尽量让最核心、最复杂的那部分逻辑代码满足开闭原则。
在刚刚的例子中,我们通过引入一组 handler 的方式来实现支持开闭原则。能想到这个方法,要靠理论知识和实战经验。
开闭原则讲的就是代码的扩展性问题,是判断一段代码是否易扩展的“金标准”。如果某段代码在应对未来需求变化的时候,能够做到“对扩展开放、对修改关闭”,那就说明这段代码的扩展性比较好。
实现开闭原则的一些偏向顶层的指导思想:
为了尽量写出扩展性好的代码,我们要时刻具备扩展意识、抽象意识、封装意识。这些“潜意识”可能比任何开发技巧都重要。
在写代码的时候后,我们要多花点时间往前多思考一下,这段代码未来可能有哪些需求变更、如何设计代码结构,事先留好扩展点,以便在未来需求变更的时候,不需要改动代码整体结构、做到最小代码改动的情况下,新的代码能够很灵活地插入到扩展点上,做到“对扩展开放、对修改关闭”。
还有,在识别出代码可变部分和不可变部分之后,我们要将可变部分封装起来,隔离变化,提供抽象化的不可变接口,给上层系统使用。当具体的实现发生变化的时候,我们只需要基于相同的抽象接口,扩展一个新的实现,替换掉老的实现即可,上游系统的代码几乎不需要修改。
支持开闭原则的具体的方法论
利用多态、依赖注入、基于接口而非实现编程,来实现“对扩展开放、对修改关闭”。
多态、依赖注入、基于接口而非实现编程,以及前面提到的抽象意识,说的都是同一种设计思路,只是从不同的角度、不同的层面来阐述而已。这也体现了“很多设计原则、思想、模式都是相通的”这一思想。
比如,我们代码中通过 Kafka 来发送异步消息。对于这样一个功能的开发,我们要学会将其抽象成一组跟具体消息队列(Kafka)无关的异步消息接口。所有上层系统都依赖这组抽象的接口编程,并且通过依赖注入的方式来调用。当我们要替换新的消息队列的时候,比如将 Kafka 替换成 RocketMQ,可以很方便地拔掉老的消息队列实现,插入新的消息队列实现。具体代码如下所示:
// 这一部分体现了抽象意识
public interface MessageQueue { //... }
public class KafkaMessageQueue implements MessageQueue { //... }
public class RocketMQMessageQueue implements MessageQueue {//...}
public interface MessageFromatter { //... }
public class JsonMessageFromatter implements MessageFromatter {//...}
public class ProtoBufMessageFromatter implements MessageFromatter {//...}
public class Demo {
private MessageQueue msgQueue; // 基于接口而非实现编程
public Demo(MessageQueue msgQueue) { // 依赖注入
this.msgQueue = msgQueue;
}
// msgFormatter:多态、依赖注入
public void sendNotification(Notification notification, MessageFormatter msgFormatter) {
//...
}
}
如何在项目中灵活应用开闭原则?
写出支持“对扩展开放、对修改关闭”的代码的关键是预留扩展点。
如果你开发的是一个业务导向的系统,比如金融系统、电商系统、物流系统等,要想识别出尽可能多的扩展点,就要对业务有足够的了解,能够知道当下以及未来可能要支持的业务需求。如果你开发的是跟业务无关的、通用的、偏底层的系统,比如,框架、组件、类库,你需要了解“它们会被如何使用?今后你打算添加哪些功能?使用者未来会有哪些更多的功能需求?”等问题。
唯一不变的只有变化本身。
最合理的做法是,对于一些比较确定的、短期内可能就会扩展,或者需求改动对代码结构影响比较大的情况,或者实现成本不高的扩展点,在编写代码的时候之后,我们就可以事先做些扩展性设计。但对于一些不确定未来是否要支持的需求,或者实现起来比较复杂的扩展点,我们可以等到有需求驱动的时候,再通过重构代码的方式来支持扩展的需求。
有些情况下,代码的扩展性会跟可读性相冲突。比如,我们之前举的 Alert 告警的例子。为了更好地支持扩展性,我们对代码进行了重构,重构之后的代码要比之前的代码复杂很多,理解起来也更加有难度。很多时候,我们都需要在扩展性和可读性之间做权衡。在某些场景下,代码的扩展性很重要,我们就可以适当地牺牲一些代码的可读性;在另一些场景下,代码的可读性更加重要,那我们就适当地牺牲一些代码的可扩展性。
在我们之前举的 Alert 告警的例子中,如果告警规则并不是很多、也不复杂,那 check() 函数中的 if 语句就不会很多,代码逻辑也不复杂,代码行数也不多,那最初的第一种代码实现思路简单易读,就是比较合理的选择。相反,如果告警规则很多、很复杂,check() 函数的 if 语句、代码逻辑就会很多、很复杂,相应的代码行数也会很多,可读性、可维护性就会变差,那重构之后的第二种代码实现思路就是更加合理的选择了。总之,这里没有一个放之四海而皆准的参考标准,全凭实际的应用场景来决定。
SOLID 中的“L”对应的原则:里式替换原则。
里式替换原则,Liskov Substitution Principle,缩写为 LSP,也叫“按照协议来设计”。
子类对象(object of subtype/derived class)能够替换程序(program)中父类对象(object of base/parent class)出现的任何地方,并且保证原来程序的逻辑行为(behavior)不变及正确性不被破坏。
比如:父类 Transporter 使用 org.apache.http 库中的 HttpClient 类来传输网络数据。子类 SecurityTransporter 继承父类 Transporter,增加了额外的功能,支持传输 appId 和 appToken 安全认证信息。
public class Transporter {
private HttpClient httpClient;
public Transporter(HttpClient httpClient) {
this.httpClient = httpClient;
}
public Response sendRequest(Request request) {
// ...use httpClient to send request
}
}
public class SecurityTransporter extends Transporter {
private String appId;
private String appToken;
public SecurityTransporter(HttpClient httpClient, String appId, String appToken) {
super(httpClient);
this.appId = appId;
this.appToken = appToken;
}
@Override
public Response sendRequest(Request request) {
if (StringUtils.isNotBlank(appId) && StringUtils.isNotBlank(appToken)) {
request.addPayload("app-id", appId);
request.addPayload("app-token", appToken);
}
return super.sendRequest(request);
}
}
public class Demo {
public void demoFunction(Transporter transporter) {
Reuqest request = new Request();
//...省略设置request中数据值的代码...
Response response = transporter.sendRequest(request);
//...省略其他逻辑...
}
}
// 里式替换原则
Demo demo = new Demo();
demo.demofunction(new SecurityTransporter(/*省略参数*/););
在上面的代码中,子类 SecurityTransporter 的设计完全符合里式替换原则,可以替换父类出现的任何位置,并且原来代码的逻辑行为不变且正确性也没有被破坏。
从定义描述和代码实现上来看,多态和里式替换有点类似,但它们关注的角度是不一样的。多态是面向对象编程的一大特性,也是面向对象编程语言的一种语法。它是一种代码实现的思路。而里式替换是一种设计原则,是用来指导继承关系中子类该如何设计的,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑以及不破坏原有程序的正确性。
比如:
// 改造前:
public class SecurityTransporter extends Transporter {
//...省略其他代码..
@Override
public Response sendRequest(Request request) {
if (StringUtils.isNotBlank(appId) && StringUtils.isNotBlank(appToken)) {
request.addPayload("app-id", appId);
request.addPayload("app-token", appToken);
}
return super.sendRequest(request);
}
}
// 改造后:
public class SecurityTransporter extends Transporter {
//...省略其他代码..
@Override
public Response sendRequest(Request request) {
if (StringUtils.isBlank(appId) || StringUtils.isBlank(appToken)) {
throw new NoAuthorizationRuntimeException(...);
}
request.addPayload("app-id", appId);
request.addPayload("app-token", appToken);
return super.sendRequest(request);
}
}
在改造之后的代码中,如果传递进 demoFunction() 函数的是父类 Transporter 对象,那 demoFunction() 函数并不会有异常抛出,但如果传递给 demoFunction() 函数的是子类 SecurityTransporter 对象,那 demoFunction() 有可能会有异常抛出。尽管代码中抛出的是运行时异常(Runtime Exception),我们可以不在代码中显式地捕获处理,但子类替换父类传递进 demoFunction 函数之后,整个程序的逻辑行为有了改变。
改造之后的代码仍然可以通过 Java 的多态语法,动态地用子类 SecurityTransporter 来替换父类 Transporter,也并不会导致程序编译或者运行报错。但是,从设计思路上来讲,SecurityTransporter 的设计是不符合里式替换原则的。
里式替换原则,也叫“按照协议来设计”。
子类在设计的时候,要遵守父类的行为约定(或者叫协议)。父类定义了函数的行为约定,那子类可以改变函数的内部实现逻辑,但不能改变函数原有的行为约定。这里的行为约定包括:函数声明要实现的功能;对输入、输出、异常的约定;甚至包括注释中所罗列的任何特殊说明。实际上,定义中父类和子类之间的关系,也可以替换成接口和实现类之间的关系。
违反里式替换原则的例子:
1. 子类违背父类声明要实现的功能
父类中提供的 sortOrdersByAmount() 订单排序函数,是按照金额从小到大来给订单排序的,而子类重写这个 sortOrdersByAmount() 订单排序函数之后,是按照创建日期来给订单排序的。那子类的设计就违背里式替换原则。
2. 子类违背父类对输入、输出、异常的约定
3. 子类违背父类注释中所罗列的任何特殊说明
父类中定义的 withdraw() 提现函数的注释是这么写的:“用户的提现金额不得超过账户余额……”,而子类重写 withdraw() 函数之后,针对 VIP 账号实现了透支提现的功能,也就是提现金额可以大于账户余额,那这个子类的设计也是不符合里式替换原则的。
除此之外,判断子类的设计实现是否违背里式替换原则,还有一个小窍门,那就是拿父类的单元测试去验证子类的代码。如果某些单元测试运行失败,就有可能说明,子类的设计实现没有完全地遵守父类的约定,子类有可能违背了里式替换原则。
接口隔离原则。它对应 SOLID 中的英文字母“I”。
Interface Segregation Principle,缩写为 ISP。
接口的调用者或者使用者不应该被强迫依赖它不需要的接口。
理解接口隔离原则的关键,就是理解其中的“接口”二字。在这条原则中,我们可以把“接口”理解为下面三种东西:一组 API 接口集合、单个 API 接口或函数、OOP 中的接口概念。
微服务用户系统提供了一组跟用户相关的 API 给其他系统使用,比如:注册、登录、获取用户信息等。
public interface UserService {
boolean register(String cellphone, String password);
boolean login(String cellphone, String password);
UserInfo getUserInfoById(long id);
UserInfo getUserInfoByCellphone(String cellphone);
}
public class UserServiceImpl implements UserService {
//...
}
我们的后台管理系统要实现删除用户的功能,希望用户系统提供一个删除用户的接口。
删除用户是一个非常慎重的操作,我们只希望通过后台管理系统来执行,所以这个接口只限于给后台管理系统使用。如果我们把它放到 UserService 中,那所有使用到 UserService 的系统,都可以调用这个接口。不加限制地被其他业务系统调用,就有可能导致误删用户。
最好的解决方案是从架构设计的层面,通过接口鉴权的方式来限制接口的调用。不过,如果暂时没有鉴权框架来支持,我们还可以从代码设计的层面,尽量避免接口被误用。我们参照接口隔离原则,调用者不应该强迫依赖它不需要的接口,将删除接口单独放到另外一个接口 RestrictedUserService 中,然后将 RestrictedUserService 只打包提供给后台管理系统来使用。
public interface UserService {
boolean register(String cellphone, String password);
boolean login(String cellphone, String password);
UserInfo getUserInfoById(long id);
UserInfo getUserInfoByCellphone(String cellphone);
}
public interface RestrictedUserService {
boolean deleteUserByCellphone(String cellphone);
boolean deleteUserById(long id);
}
public class UserServiceImpl implements UserService, RestrictedUserService {
// ...省略实现代码...
}
在设计微服务或者类库接口的时候,如果部分接口只被部分调用者使用,那我们就需要将这部分接口隔离出来,单独给对应的调用者使用,而不是强迫其他调用者也依赖这部分不会被用到的接口。
接口隔离原则就可以理解为:函数的设计要功能单一,不要将多个不同的功能逻辑在一个函数中实现。部分调用者只需要函数中的部分功能,那我们就需要把函数拆分成粒度更细的多个函数,让调用者只依赖它需要的那个细粒度函数。
public class Statistics {
private Long max;
private Long min;
private Long average;
private Long sum;
private Long percentile99;
private Long percentile999;
//...省略constructor/getter/setter等方法...
}
public Statistics count(Collection<Long> dataSet) {
Statistics statistics = new Statistics();
//...省略计算逻辑...
return statistics;
}
在上面的代码中,count() 函数的功能不够单一,包含很多不同的统计功能,比如,求最大值、最小值、平均值等等。按照接口隔离原则,我们应该把 count() 函数拆成几个更小粒度的函数,每个函数负责一个独立的统计功能。
public Long max(Collection<Long> dataSet) { //... }
public Long min(Collection<Long> dataSet) { //... }
public Long average(Colletion<Long> dataSet) { //... }
// ...省略其他统计函数...
判定功能是否单一,除了很强的主观性,还需要结合具体的场景。
如果在项目中,对每个统计需求,Statistics 定义的那几个统计信息都有涉及,那 count() 函数的设计就是合理的。相反,如果每个统计需求只涉及 Statistics 罗列的统计信息中一部分,比如,有的只需要用到 max、min、average 这三类统计信息,有的只需要用到 average、sum。而 count() 函数每次都会把所有的统计信息计算一遍,就会做很多无用功,势必影响代码的性能,特别是在需要统计的数据量很大的时候。所以,在这个应用场景下,count() 函数的设计就有点不合理了,我们应该按照第二种设计思路,将其拆分成粒度更细的多个统计函数。
单一职责原则针对的是模块、类、接口的设计。而接口隔离原则相对于单一职责原则,一方面它更侧重于接口的设计,另一方面它的思考的角度不同。它提供了一种判断接口是否职责单一的标准:通过调用者如何使用接口来间接地判定。如果调用者只使用部分接口或接口的部分功能,那接口的设计就不够职责单一。
接口的设计要尽量单一,不要让接口的实现类和调用者,依赖不需要的接口方法。假设我们的项目中用到了三个外部系统:Redis、MySQL、Kafka。每个系统都对应一系列配置信息,比如地址、端口、访问超时时间等。为了在内存中存储这些配置信息,供项目中的其他模块来使用,我们分别设计实现了三个 Configuration 类:RedisConfig、MysqlConfig、KafkaConfig。
public class RedisConfig {
private ConfigSource configSource; //配置中心(比如zookeeper)
private String address;
private int timeout;
private int maxTotal;
//省略其他配置: maxWaitMillis,maxIdle,minIdle...
public RedisConfig(ConfigSource configSource) {
this.configSource = configSource;
}
public String getAddress() {
return this.address;
}
//...省略其他get()、init()方法...
public void update() {
//从configSource加载配置到address/timeout/maxTotal...
}
}
public class KafkaConfig { //...省略... }
public class MysqlConfig { //...省略... }
新的功能需求,希望支持 Redis 和 Kafka 配置信息的热更新。所谓“热更新(hot update)”就是,如果在配置中心中更改了配置信息,我们希望在不用重启系统的情况下,能将最新的配置信息加载到内存中(也就是 RedisConfig、KafkaConfig 类中)。但是,因为某些原因,我们并不希望对 MySQL 的配置信息进行热更新。
设计实现了一个 ScheduledUpdater 类,以固定时间频率(periodInSeconds)来调用 RedisConfig、KafkaConfig 的 update() 方法更新配置信息。
新的监控功能需求。通过命令行来查看 Zookeeper 中的配置信息是比较麻烦的。所以,我们希望能有一种更加方便的配置信息查看方式。我们可以在项目中开发一个内嵌的 SimpleHttpServer,输出项目的配置信息到一个固定的 HTTP 地址,比如:http://127.0.0.1:2389/config 。我们只需要在浏览器中输入这个地址,就可以显示出系统的配置信息。不过,出于某些原因,我们只想暴露 MySQL 和 Redis 的配置信息,不想暴露 Kafka 的配置信息。
public interface Updater {
void update();
}
public interface Viewer {
String outputInPlainText();
Map<String, String> output();
}
public class RedisConfig implemets Updater, Viewer {
//...省略其他属性和方法...
@Override
public void update() { //... }
@Override
public String outputInPlainText() { //... }
@Override
public Map<String, String> output() { //...}
}
public class KafkaConfig implements Updater {
//...省略其他属性和方法...
@Override
public void update() { //... }
}
public class MysqlConfig implements Viewer {
//...省略其他属性和方法...
@Override
public String outputInPlainText() { //... }
@Override
public Map<String, String> output() { //...}
}
public class SimpleHttpServer {
private String host;
private int port;
private Map<String, List<Viewer>> viewers = new HashMap<>();
public SimpleHttpServer(String host, int port) {//...}
public void addViewers(String urlDirectory, Viewer viewer) {
if (!viewers.containsKey(urlDirectory)) {
viewers.put(urlDirectory, new ArrayList<Viewer>());
}
this.viewers.get(urlDirectory).add(viewer);
}
public void run() { //... }
}
public class Application {
ConfigSource configSource = new ZookeeperConfigSource();
public static final RedisConfig redisConfig = new RedisConfig(configSource);
public static final KafkaConfig kafkaConfig = new KakfaConfig(configSource);
public static final MySqlConfig mysqlConfig = new MySqlConfig(configSource);
public static void main(String[] args) {
ScheduledUpdater redisConfigUpdater =
new ScheduledUpdater(redisConfig, 300, 300);
redisConfigUpdater.run();
ScheduledUpdater kafkaConfigUpdater =
new ScheduledUpdater(kafkaConfig, 60, 60);
redisConfigUpdater.run();
SimpleHttpServer simpleHttpServer = new SimpleHttpServer(“127.0.0.1”, 2389);
simpleHttpServer.addViewer("/config", redisConfig);
simpleHttpServer.addViewer("/config", mysqlConfig);
simpleHttpServer.run();
}
}
我们设计了两个功能非常单一的接口:Updater 和 Viewer。ScheduledUpdater 只依赖 Updater 这个跟热更新相关的接口,不需要被强迫去依赖不需要的 Viewer 接口,满足接口隔离原则。同理,SimpleHttpServer 只依赖跟查看信息相关的 Viewer 接口,不依赖不需要的 Updater 接口,也满足接口隔离原则。
如果我们不遵守接口隔离原则,不设计 Updater 和 Viewer 两个小接口,而是设计一个大而全的 Config 接口,让 RedisConfig、KafkaConfig、MysqlConfig 都实现这个 Config 接口,并且将原来传递给 ScheduledUpdater 的 Updater 和传递给 SimpleHttpServer 的 Viewer,都替换为 Config,那会有什么问题呢?
public interface Config {
void update();
String outputInPlainText();
Map<String, String> output();
}
public class RedisConfig implements Config {
//...需要实现Config的三个接口update/outputIn.../output
}
public class KafkaConfig implements Config {
//...需要实现Config的三个接口update/outputIn.../output
}
public class MysqlConfig implements Config {
//...需要实现Config的三个接口update/outputIn.../output
}
public class ScheduledUpdater {
//...省略其他属性和方法..
private Config config;
public ScheduleUpdater(Config config, long initialDelayInSeconds, long periodInSeconds) {
this.config = config;
//...
}
//...
}
public class SimpleHttpServer {
private String host;
private int port;
private Map<String, List<Config>> viewers = new HashMap<>();
public SimpleHttpServer(String host, int port) {//...}
public void addViewer(String urlDirectory, Config config) {
if (!viewers.containsKey(urlDirectory)) {
viewers.put(urlDirectory, new ArrayList<Config>());
}
viewers.get(urlDirectory).add(config);
}
public void run() { //... }
}
对比前后两个设计思路,在同样的代码量、实现复杂度、同等可读性的情况下,第一种设计思路显然要比第二种好很多。主要有两点原因。
首先,第一种设计思路更加灵活、易扩展、易复用。因为 Updater、Viewer 职责更加单一,单一就意味了通用、复用性好。比如,我们现在又有一个新的需求,开发一个 Metrics 性能统计模块,并且希望将 Metrics 也通过 SimpleHttpServer 显示在网页上,以方便查看。这个时候,尽管 Metrics 跟 RedisConfig 等没有任何关系,但我们仍然可以让 Metrics 类实现非常通用的 Viewer 接口,复用 SimpleHttpServer 的代码实现。
public class ApiMetrics implements Viewer {//...}
public class DbMetrics implements Viewer {//...}
public class Application {
ConfigSource configSource = new ZookeeperConfigSource();
public static final RedisConfig redisConfig = new RedisConfig(configSource);
public static final KafkaConfig kafkaConfig = new KakfaConfig(configSource);
public static final MySqlConfig mySqlConfig = new MySqlConfig(configSource);
public static final ApiMetrics apiMetrics = new ApiMetrics();
public static final DbMetrics dbMetrics = new DbMetrics();
public static void main(String[] args) {
SimpleHttpServer simpleHttpServer = new SimpleHttpServer(“127.0.0.1”, 2389);
simpleHttpServer.addViewer("/config", redisConfig);
simpleHttpServer.addViewer("/config", mySqlConfig);
simpleHttpServer.addViewer("/metrics", apiMetrics);
simpleHttpServer.addViewer("/metrics", dbMetrics);
simpleHttpServer.run();
}
}
其次,第二种设计思路在代码实现上做了一些无用功。因为 Config 接口中包含两类不相关的接口,一类是 update(),一类是 output() 和 outputInPlainText()。理论上,KafkaConfig 只需要实现 update() 接口,并不需要实现 output() 相关的接口。同理,MysqlConfig 只需要实现 output() 相关接口,并需要实现 update() 接口。但第二种设计思路要求 RedisConfig、KafkaConfig、MySqlConfig 必须同时实现 Config 的所有接口函数(update、output、outputInPlainText)。除此之外,如果我们要往 Config 中继续添加一个新的接口,那所有的实现类都要改动。相反,如果我们的接口粒度比较小,那涉及改动的类就比较少。
SOLID 原则的“D”,依赖反转原则。
控制反转是一个比较笼统的设计思想,并不是一种具体的实现方法,一般用来指导框架层面的设计。这里所说的“控制”指的是对程序执行流程的控制,而“反转”指的是在没有使用框架之前,程序员自己控制整个程序的执行。在使用框架之后,整个程序的执行流程通过框架来控制。流程的控制权从程序员“反转”给了框架。
框架提供了一个可扩展的代码骨架,用来组装对象、管理整个执行流程。程序员利用框架进行开发的时候,只需要往预留的扩展点上,添加跟自己业务相关的代码,就可以利用框架来驱动整个程序流程的执行。
public class UserServiceTest {
public static boolean doTest() {
// ...
}
public static void main(String[] args) {//这部分逻辑可以放到框架中
if (doTest()) {
System.out.println("Test succeed.");
} else {
System.out.println("Test failed.");
}
}
}
在上面的代码中,所有的流程都由程序员来控制。改造:只需要在框架预留的扩展点,也就是 TestCase 类中的 doTest() 抽象函数中,填充具体的测试代码就可以实现之前的功能了,完全不需要写负责执行流程的 main() 函数了。
public abstract class TestCase {
public void run() {
if (doTest()) {
System.out.println("Test succeed.");
} else {
System.out.println("Test failed.");
}
}
public abstract boolean doTest();
}
public class JunitApplication {
private static final List<TestCase> testCases = new ArrayList<>();
public static void register(TestCase testCase) {
testCases.add(testCase);
}
public static final void main(String[] args) {
for (TestCase case: testCases) {
case.run();
}
}
public class UserServiceTest extends TestCase {
@Override
public boolean doTest() {
// ...
}
}
// 注册操作还可以通过配置的方式来实现,不需要程序员显示调用register()
JunitApplication.register(new UserServiceTest();
依赖注入和控制反转恰恰相反,它是一种具体的编码技巧。Dependency Injection,缩写为 DI。依赖注入是实现代码可测试性的最有效的手段。
我们不通过 new 的方式在类内部创建依赖类的对象,而是将依赖的类对象在外部创建好之后,通过构造函数、函数参数等方式传递(或注入)给类来使用。
比如:Notification 类负责消息推送,依赖 MessageSender 类实现推送商品促销、验证码等消息给用户。
// 非依赖注入实现方式
public class Notification {
private MessageSender messageSender;
public Notification() {
this.messageSender = new MessageSender(); //此处有点像hardcode
}
public void sendMessage(String cellphone, String message) {
//...省略校验逻辑等...
this.messageSender.send(cellphone, message);
}
}
public class MessageSender {
public void send(String cellphone, String message) {
//....
}
}
// 使用Notification
Notification notification = new Notification();
// 依赖注入的实现方式
public class Notification {
private MessageSender messageSender;
// 通过构造函数将messageSender传递进来
public Notification(MessageSender messageSender) {
this.messageSender = messageSender;
}
public void sendMessage(String cellphone, String message) {
//...省略校验逻辑等...
this.messageSender.send(cellphone, message);
}
}
//使用Notification
MessageSender messageSender = new MessageSender();
Notification notification = new Notification(messageSender);
通过依赖注入的方式来将依赖的类对象传递进来,这样就提高了代码的扩展性,我们可以灵活地替换依赖的类。
继续优化,把 MessageSender 定义成接口,基于接口而非实现编程。
public class Notification {
private MessageSender messageSender;
public Notification(MessageSender messageSender) {
this.messageSender = messageSender;
}
public void sendMessage(String cellphone, String message) {
this.messageSender.send(cellphone, message);
}
}
public interface MessageSender {
void send(String cellphone, String message);
}
// 短信发送类
public class SmsSender implements MessageSender {
@Override
public void send(String cellphone, String message) {
//....
}
}
// 站内信发送类
public class InboxSender implements MessageSender {
@Override
public void send(String cellphone, String message) {
//....
}
}
//使用Notification
MessageSender messageSender = new SmsSender();
Notification notification = new Notification(messageSender);
通过依赖注入框架提供的扩展点,简单配置一下所有需要的类及其类与类之间依赖关系,就可以实现由框架来自动创建对象、管理对象的生命周期、依赖注入等原本需要程序员来做的事情。
对象创建和依赖注入的工作,本身跟具体的业务无关,我们完全可以抽象成框架来自动完成。
依赖反转原则也叫作依赖倒置原则。Dependency Inversion Principle,缩写为 DIP。
这条原则跟控制反转有点类似,主要用来指导框架层面的设计。高层模块不依赖低层模块,它们共同依赖同一个抽象。抽象不要依赖具体实现细节,具体实现细节依赖抽象。
Keep It Simple and Stupid. 尽量保持简单。
KISS 原则就是保持代码可读和可维护的重要手段。代码足够简单,也就意味着很容易读懂,bug 比较难隐藏。即便出现 bug,修复起来也比较简单。
检查输入的字符串 ipAddress 是否是合法的 IP 地址。一个合法的 IP 地址由四个数字组成,并且通过“.”来进行分割。每组数字的取值范围是 0~255。第一组数字比较特殊,不允许为 0。
// 第一种实现方式: 使用正则表达式
public boolean isValidIpAddressV1(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String regex = "^(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[1-9])\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)$";
return ipAddress.matches(regex);
}
// 第二种实现方式: 使用现成的工具类
public boolean isValidIpAddressV2(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String[] ipUnits = StringUtils.split(ipAddress, '.');
if (ipUnits.length != 4) {
return false;
}
for (int i = 0; i < 4; ++i) {
int ipUnitIntValue;
try {
ipUnitIntValue = Integer.parseInt(ipUnits[i]);
} catch (NumberFormatException e) {
return false;
}
if (ipUnitIntValue < 0 || ipUnitIntValue > 255) {
return false;
}
if (i == 0 && ipUnitIntValue == 0) {
return false;
}
}
return true;
}
// 第三种实现方式: 不使用任何工具类
public boolean isValidIpAddressV3(String ipAddress) {
char[] ipChars = ipAddress.toCharArray();
int length = ipChars.length;
int ipUnitIntValue = -1;
boolean isFirstUnit = true;
int unitsCount = 0;
for (int i = 0; i < length; ++i) {
char c = ipChars[i];
if (c == '.') {
if (ipUnitIntValue < 0 || ipUnitIntValue > 255) return false;
if (isFirstUnit && ipUnitIntValue == 0) return false;
if (isFirstUnit) isFirstUnit = false;
ipUnitIntValue = -1;
unitsCount++;
continue;
}
if (c < '0' || c > '9') {
return false;
}
if (ipUnitIntValue == -1) ipUnitIntValue = 0;
ipUnitIntValue = ipUnitIntValue * 10 + (c - '0');
}
if (ipUnitIntValue < 0 || ipUnitIntValue > 255) return false;
if (unitsCount != 3) return false;
return true;
}
正则表达式本身是比较复杂的,写出完全没有 bug 的正则表达本身就比较有挑战;不符合 KISS 原则。
第二种实现方式使用了 StringUtils 类、Integer 类提供的一些现成的工具函数,来处理 IP 地址字符串。第三种实现方式,不使用任何工具函数,而是通过逐一处理 IP 地址中的字符,来判断是否合法。从代码行数上来说,这两种方式差不多。但是,第三种要比第二种更加有难度,更容易写出 bug。从可读性上来说,第二种实现方式的代码逻辑更清晰、更好理解。所以,在这两种实现方式中,第二种实现方式更加“简单”,更加符合 KISS 原则。
第三种实现方式性能会更高一些。一般来说,工具类的功能都比较通用和全面,所以,在代码实现上,需要考虑和处理更多的细节,执行效率就会有所影响。而第三种实现方式,完全是自己操作底层字符,只针对 IP 地址这一种格式的数据输入来做处理,没有太多多余的函数调用和其他不必要的处理逻辑,所以,在执行效率上,这种类似定制化的处理代码方式肯定比通用的工具类要高些。
更倾向于选择第二种实现方法。那是因为第三种实现方式实际上是一种过度优化。除非 isValidIpAddress() 函数是影响系统性能的瓶颈代码,否则,这样优化的投入产出比并不高,增加了代码实现的难度、牺牲了代码的可读性,性能上的提升却并不明显。
// KMP algorithm: a, b分别是主串和模式串;n, m分别是主串和模式串的长度。
public static int kmp(char[] a, int n, char[] b, int m) {
int[] next = getNexts(b, m);
int j = 0;
for (int i = 0; i < n; ++i) {
while (j > 0 && a[i] != b[j]) { // 一直找到a[i]和b[j]
j = next[j - 1] + 1;
}
if (a[i] == b[j]) {
++j;
}
if (j == m) { // 找到匹配模式串的了
return i - m + 1;
}
}
return -1;
}
// b表示模式串,m表示模式串的长度
private static int[] getNexts(char[] b, int m) {
int[] next = new int[m];
next[0] = -1;
int k = -1;
for (int i = 1; i < m; ++i) {
while (k != -1 && b[k + 1] != b[i]) {
k = next[k];
}
if (b[k + 1] == b[i]) {
++k;
}
next[i] = k;
}
return next;
}
KMP 算法以快速高效著称。当我们需要处理长文本字符串匹配问题(几百 MB 大小文本内容的匹配),或者字符串匹配是某个产品的核心功能(比如 Vim、Word 等文本编辑器),又或者字符串匹配算法是系统性能瓶颈的时候,我们就应该选择尽可能高效的 KMP 算法。而 KMP 算法本身具有逻辑复杂、实现难度大、可读性差的特点。本身就复杂的问题,用复杂的方法解决,并不违背 KISS 原则。
针对比较小的文本。在这种情况下,直接调用编程语言提供的现成的字符串匹配函数就足够了。

评判代码是否简单,还有一个很有效的间接方法,那就是 code review。如果在 code review 的时候,同事对你的代码有很多疑问,那就说明你的代码有可能不够“简单”,需要优化啦。
在做开发的时候,一定不要过度设计,不要觉得简单的东西就没有技术含量。实际上,越是能用简单的方法解决复杂的问题,越能体现一个人的能力。
YAGNI 原则,You Ain’t Gonna Need It。你不会需要它。
不要去设计当前用不到的功能;不要去编写当前用不到的代码。核心思想就是:不要做过度设计。
比如,我们的系统暂时只用 Redis 存储配置信息,以后可能会用到 ZooKeeper。根据 YAGNI 原则,在未用到 ZooKeeper 之前,我们没必要提前编写这部分代码。当然,这并不是说我们就不需要考虑代码的扩展性。我们还是要预留好扩展点,等到需要的时候,再去实现 ZooKeeper 存储配置信息这部分代码。
再比如,我们不要在项目中提前引入不需要依赖的开发包。对于 Java 程序员来说,我们经常使用 Maven 或者 Gradle 来管理依赖的类库(library)。我发现,有些同事为了避免开发中 library 包缺失而频繁地修改 Maven 或者 Gradle 配置文件,提前往项目里引入大量常用的 library 包。实际上,这样的做法也是违背 YAGNI 原则的。
KISS 原则讲的是“如何做”的问题(尽量保持简单)。
YAGNI 原则说的是“要不要做”的问题(当前不需要的就不要做)。
Don’t Repeat Yourself。不要重复自己。不要写重复的代码。
实际上,重复的代码不一定违反 DRY 原则,而且有些看似不重复的代码也有可能违反 DRY 原则。
三种典型的代码重复情况,它们分别是:实现逻辑重复、功能语义重复和代码执行重复。
public class UserAuthenticator {
public void authenticate(String username, String password) {
if (!isValidUsername(username)) {
// ...throw InvalidUsernameException...
}
if (!isValidPassword(password)) {
// ...throw InvalidPasswordException...
}
//...省略其他代码...
}
private boolean isValidUsername(String username) {
// check not null, not empty
if (StringUtils.isBlank(username)) {
return false;
}
// check length: 4~64
int length = username.length();
if (length < 4 || length > 64) {
return false;
}
// contains only lowcase characters
if (!StringUtils.isAllLowerCase(username)) {
return false;
}
// contains only a~z,0~9,dot
for (int i = 0; i < length; ++i) {
char c = username.charAt(i);
if (!(c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '.') {
return false;
}
}
return true;
}
private boolean isValidPassword(String password) {
// check not null, not empty
if (StringUtils.isBlank(password)) {
return false;
}
// check length: 4~64
int length = password.length();
if (length < 4 || length > 64) {
return false;
}
// contains only lowcase characters
if (!StringUtils.isAllLowerCase(password)) {
return false;
}
// contains only a~z,0~9,dot
for (int i = 0; i < length; ++i) {
char c = password.charAt(i);
if (!(c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '.') {
return false;
}
}
return true;
}
}
在代码中,有两处非常明显的重复的代码片段:isValidUserName() 函数和 isValidPassword() 函数。重复的代码被敲了两遍,或者简单 copy-paste 了一下,看起来明显违反 DRY 原则。为了移除重复的代码,我们对上面的代码做下重构,将 isValidUserName() 函数和 isValidPassword() 函数,合并为一个更通用的函数 isValidUserNameOrPassword()。
public class UserAuthenticatorV2 {
public void authenticate(String userName, String password) {
if (!isValidUsernameOrPassword(userName)) {
// ...throw InvalidUsernameException...
}
if (!isValidUsernameOrPassword(password)) {
// ...throw InvalidPasswordException...
}
}
private boolean isValidUsernameOrPassword(String usernameOrPassword) {
//省略实现逻辑
//跟原来的isValidUsername()或isValidPassword()的实现逻辑一样...
return true;
}
}
经过重构之后,代码行数减少了,也没有重复的代码了。
但是,合并之后的 isValidUserNameOrPassword() 函数,负责两件事情:验证用户名和验证密码,违反了“单一职责原则”和“接口隔离原则”。
因为 isValidUserName() 和 isValidPassword() 两个函数,虽然从代码实现逻辑上看起来是重复的,但是从语义上并不重复。所谓“语义不重复”指的是:从功能上来看,这两个函数干的是完全不重复的两件事情,一个是校验用户名,另一个是校验密码。尽管在目前的设计中,两个校验逻辑是完全一样的,但如果按照第二种写法,将两个函数的合并,那就会存在潜在的问题。在未来的某一天,如果我们修改了密码的校验逻辑,比如,允许密码包含大写字符,允许密码的长度为 8 到 64 个字符,那这个时候,isValidUserName() 和 isValidPassword() 的实现逻辑就会不相同。我们就要把合并后的函数,重新拆成合并前的那两个函数。
尽管代码的实现逻辑是相同的,但语义不同,我们判定它并不违反 DRY 原则。对于包含重复代码的问题,我们可以通过抽象成更细粒度函数的方式来解决。比如将校验只包含 a~z、0~9、dot 的逻辑封装成 boolean onlyContains(String str, String charlist); 函数。
在同一个项目代码中有下面两个函数:isValidIp() 和 checkIfIpValid()。尽管两个函数的命名不同,实现逻辑不同,但功能是相同的,都是用来判定 IP 地址是否合法的。
之所以在同一个项目中会有两个功能相同的函数,那是因为这两个函数是由两个不同的同事开发的,其中一个同事在不知道已经有了 isValidIp() 的情况下,自己又定义并实现了同样用来校验 IP 地址是否合法的 checkIfIpValid() 函数。
public boolean isValidIp(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String regex = "^(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[1-9])\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)$";
return ipAddress.matches(regex);
}
public boolean checkIfIpValid(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String[] ipUnits = StringUtils.split(ipAddress, '.');
if (ipUnits.length != 4) {
return false;
}
for (int i = 0; i < 4; ++i) {
int ipUnitIntValue;
try {
ipUnitIntValue = Integer.parseInt(ipUnits[i]);
} catch (NumberFormatException e) {
return false;
}
if (ipUnitIntValue < 0 || ipUnitIntValue > 255) {
return false;
}
if (i == 0 && ipUnitIntValue == 0) {
return false;
}
}
return true;
}
尽管两段代码的实现逻辑不重复,但语义重复,也就是功能重复,我们认为它违反了 DRY 原则。在项目中,统一一种实现思路,所有用到判断 IP 地址是否合法的地方,都统一调用同一个函数。
假设我们不统一实现思路,那有些地方调用了 isValidIp() 函数,有些地方又调用了 checkIfIpValid() 函数的缺陷:
(1)给不熟悉这部分代码的同事增加了阅读的难度。同事有可能研究了半天,觉得功能是一样的,但又有点疑惑,觉得是不是有更高深的考量,才定义了两个功能类似的函数,最终发现居然是代码设计的问题。
(2)如果哪天项目中 IP 地址是否合法的判定规则改变了,比如:255.255.255.255 不再被判定为合法的了,相应地,我们对 isValidIp() 的实现逻辑做了相应的修改,但却忘记了修改 checkIfIpValid() 函数。又或者,我们压根就不知道还存在一个功能相同的 checkIfIpValid() 函数,这样就会导致有些代码仍然使用老的 IP 地址判断逻辑,导致出现一些莫名其妙的 bug。
UserService 中 login() 函数用来校验用户登录是否成功。如果失败,就返回异常;如果成功,就返回用户信息。
public class UserService {
private UserRepo userRepo;//通过依赖注入或者IOC框架注入
public User login(String email, String password) {
boolean existed = userRepo.checkIfUserExisted(email, password);
if (!existed) {
// ... throw AuthenticationFailureException...
}
User user = userRepo.getUserByEmail(email);
return user;
}
}
public class UserRepo {
public boolean checkIfUserExisted(String email, String password) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
if (!PasswordValidation.validate(password)) {
// ... throw InvalidPasswordException...
}
//...query db to check if email&password exists...
}
public User getUserByEmail(String email) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
//...query db to get user by email...
}
}
重复执行(1),就是在 login() 函数中,email 的校验逻辑被执行了两次。一次是在调用 checkIfUserExisted() 函数的时候,另一次是调用 getUserByEmail() 函数的时候。
解决:将校验逻辑从 UserRepo 中移除,统一放到 UserService 中就可以了。
重复执行(2),login() 函数并不需要调用 checkIfUserExisted() 函数,只需要调用一次 getUserByEmail() 函数,从数据库中获取到用户的 email、password 等信息,然后跟用户输入的 email、password 信息做对比,依次判断是否登录成功。
这样的优化是很有必要的。因为 checkIfUserExisted() 函数和 getUserByEmail() 函数都需要查询数据库,而数据库这类的 I/O 操作是比较耗时的。我们在写代码的时候,应当尽量减少这类 I/O 操作。
重构后的代码:
public class UserService {
private UserRepo userRepo;//通过依赖注入或者IOC框架注入
public User login(String email, String password) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
if (!PasswordValidation.validate(password)) {
// ... throw InvalidPasswordException...
}
User user = userRepo.getUserByEmail(email);
if (user == null || !password.equals(user.getPassword()) {
// ... throw AuthenticationFailureException...
}
return user;
}
}
public class UserRepo {
public boolean checkIfUserExisted(String email, String password) {
//...query db to check if email&password exists
}
public User getUserByEmail(String email) {
//...query db to get user by email...
}
}
代码复用性(Code Reusability)、代码复用(Code Resue)和 DRY 原则。
三者实际上要达到的目的都是类似的,都是为了减少代码量,提高代码的可读性、可维护性。除此之外,复用已经经过测试的老代码,bug 会比从零重新开发要少。
相比于代码的可复用性,DRY 原则适用性更强一些。我们可以不写可复用的代码,但一定不能写重复的代码。
代码复用表示一种行为:我们在开发新功能的时候,尽量复用已经存在的代码。代码的可复用性表示一段代码可被复用的特性或能力:我们在编写代码的时候,让代码尽量可复用。
DRY 原则是一条原则:不要写重复的代码。
代码“不重复”并不代表“可复用”。
“复用”和“可复用性”关注角度不同。代码“可复用性”是从代码开发者的角度来讲的,“复用”是从代码使用者的角度来讲的。比如,A 同事编写了一个 UrlUtils 类,代码的“可复用性”很好。B 同事在开发新功能的时候,直接“复用”A 同事编写的 UrlUtils 类。
1、减少代码耦合
2、满足单一职责原则。越细粒度的代码,代码的通用性会越好,越容易被复用。
3、模块化。不单单指一组类构成的模块,还可以理解为单个类、函数。我们要善于将功能独立的代码,封装成模块。
4、业务与非业务逻辑分离。
越是跟业务无关的代码越是容易复用,越是针对特定业务的代码越难复用。为了复用跟业务无关的代码,我们将业务和非业务逻辑代码分离,抽取成一些通用的框架、类库、组件等。
5、通用代码下沉。
从分层的角度来看,越底层的代码越通用、会被越多的模块调用,越应该设计得足够可复用。一般情况下,在代码分层之后,为了避免交叉调用导致调用关系混乱,我们只允许上层代码调用下层代码及同层代码之间的调用,杜绝下层代码调用上层代码。所以,通用的代码我们尽量下沉到更下层。
6、继承、多态、抽象、封装
利用继承,可以将公共的代码抽取到父类,子类复用父类的属性和方法。利用多态,我们可以动态地替换一段代码的部分逻辑,让这段代码可复用。越抽象、越不依赖具体的实现,越容易复用。代码封装成模块,隐藏可变的细节、暴露不变的接口,就越容易复用。
7、应用模板等设计模式
比如,模板模式利用了多态来实现,可以灵活地替换其中的部分代码,整个流程模板代码可复用。
还有一些跟编程语言相关的特性,也能提高代码的复用性,比如泛型编程等。实际上,除了上面讲到的这些方法之外,复用意识也非常重要。在写代码的时候,我们要多去思考一下,这个部分代码是否可以抽取出来,作为一个独立的模块、类或者函数供多处使用。在设计每个模块、类、函数的时候,要像设计一个外部 API 那样,去思考它的复用性。
编写可复用的代码并不简单。如果我们在编写代码的时候,已经有复用的需求场景,那根据复用的需求去开发可复用的代码,可能还不算难。但是,如果当下并没有复用的需求,我们只是希望现在编写的代码具有可复用的特点,能在未来某个同事开发某个新功能的时候复用得上。在这种没有具体复用需求的情况下,我们就需要去预测将来代码会如何复用,这就比较有挑战了。
实际上,除非有非常明确的复用需求,否则,为了暂时用不到的复用需求,花费太多的时间、精力,投入太多的开发成本,并不是一个值得推荐的做法。这也违反我们之前讲到的 YAGNI 原则。
第一次编写代码的时候,我们不考虑复用性;第二次遇到复用场景的时候,再进行重构使其复用。需要注意的是,“Rule of Three”中的“Three”并不是真的就指确切的“三”,这里就是指“二”。
我们在第一次写代码的时候,如果当下没有复用的需求,而未来的复用需求也不是特别明确,并且开发可复用代码的成本比较高,那我们就不需要考虑代码的复用性。在之后我们开发新的功能的时候,发现可以复用之前写的这段代码,那我们就重构这段代码,让其变得更加可复用。
“高内聚、松耦合”是一个非常重要的设计思想,能够有效地提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。比如,单一职责原则、基于接口而非实现编程等。 它可以用来指导不同粒度代码的设计与开发,比如系统、模块、类,甚至是函数,也可以应用到不同的开发场景中,比如微服务、框架、组件、类库等。
“高内聚”用来指导类本身的设计,“松耦合”用来指导类与类之间依赖关系的设计。
高内聚有助于松耦合,松耦合又需要高内聚的支持。
什么是“高内聚”呢?
高内聚,就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一个类中。相近的功能往往会被同时修改,放到同一个类中,修改会比较集中,代码容易维护。实际上,我们前面讲过的单一职责原则是实现代码高内聚非常有效的设计原则。
什么是“松耦合”?
松耦合是说,在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动不会或者很少导致依赖类的代码改动。实际上,我们前面讲的依赖注入、接口隔离、基于接口而非实现编程,以及今天讲的迪米特法则,都是为了实现代码的松耦合。
图中左边部分的代码结构是“高内聚、松耦合”;右边部分正好相反,是“低内聚、紧耦合”。

左边部分的代码设计中,类的粒度比较小,每个类的职责都比较单一。相近的功能都放到了一个类中,不相近的功能被分割到了多个类中。这样类更加独立,代码的内聚性更好。因为职责单一,所以每个类被依赖的类就会比较少,代码低耦合。一个类的修改,只会影响到一个依赖类的代码改动。我们只需要测试这一个依赖类是否还能正常工作就行了。
右边部分的代码设计中,类粒度比较大,低内聚,功能大而全,不相近的功能放到了一个类中。这就导致很多其他类都依赖这个类。当我们修改这个类的某一个功能代码的时候,会影响依赖它的多个类。我们需要测试这三个依赖类,是否还能正常工作。这也就是所谓的“牵一发而动全身”。
迪米特法则,Law of Demeter,缩写是 LOD。也叫作最小知识原则,英文翻译为:The Least Knowledge Principle。
每个模块只应该了解那些与它关系密切的模块的有限知识。或者说,每个模块只和自己的朋友“说话”,不和陌生人“说话”。
大部分设计原则和思想都非常抽象,有各种各样的解读,要想灵活地应用到实际的开发中,需要有实战经验的积累。
不应该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口(也就是定义中的“有限知识”)。迪米特法则是希望减少类之间的耦合,让类越独立越好。每个类都应该少了解系统的其他部分。一旦发生变化,需要了解这一变化的类就会比较少。
不该有直接依赖关系的类之间,不要有依赖。举例:
实现简化版的搜索引擎爬取网页的功能。代码中包含三个主要的类。其中,NetworkTransporter 类负责底层网络通信,根据请求获取数据;HtmlDownloader 类用来通过 URL 获取网页;Document 表示网页文档,后续的网页内容抽取、分词、索引都是以此为处理对象。
public class NetworkTransporter {
// 省略属性和其他方法...
public Byte[] send(HtmlRequest htmlRequest) {
//...
}
}
public class HtmlDownloader {
private NetworkTransporter transporter;//通过构造函数或IOC注入
public Html downloadHtml(String url) {
Byte[] rawHtml = transporter.send(new HtmlRequest(url));
return new Html(rawHtml);
}
}
public class Document {
private Html html;
private String url;
public Document(String url) {
this.url = url;
HtmlDownloader downloader = new HtmlDownloader();
this.html = downloader.downloadHtml(url);
}
//...
}
NetworkTransporter 类。作为一个底层网络通信类,我们希望它的功能尽可能通用,而不只是服务于下载 HTML,所以,我们不应该直接依赖太具体的发送对象 HtmlRequest。从这一点上讲,NetworkTransporter 类的设计违背迪米特法则,依赖了不该有直接依赖关系的 HtmlRequest 类。
假如你现在要去商店买东西,你肯定不会直接把钱包给收银员,让收银员自己从里面拿钱,而是你从钱包里把钱拿出来交给收银员。这里的 HtmlRequest 对象就相当于钱包,HtmlRequest 里的 address 和 content 对象就相当于钱。我们应该把 address 和 content 交给 NetworkTransporter,而非是直接把 HtmlRequest 交给 NetworkTransporter。
重构,让 NetworkTransporter 类满足迪米特法则。
public class NetworkTransporter {
// 省略属性和其他方法...
public Byte[] send(String address, Byte[] data) {
//...
}
}
public class HtmlDownloader {
private NetworkTransporter transporter;//通过构造函数或IOC注入
// HtmlDownloader这里也要有相应的修改
public Html downloadHtml(String url) {
HtmlRequest htmlRequest = new HtmlRequest(url);
Byte[] rawHtml = transporter.send(
htmlRequest.getAddress(), htmlRequest.getContent().getBytes());
return new Html(rawHtml);
}
}
Document 类。问题主要有三点。第一,构造函数中的 downloader.downloadHtml() 逻辑复杂,耗时长,不应该放到构造函数中,会影响代码的可测试性。第二,HtmlDownloader 对象在构造函数中通过 new 来创建,违反了基于接口而非实现编程的设计思想,也会影响到代码的可测试性。第三,从业务含义上来讲,Document 网页文档没必要依赖 HtmlDownloader 类,违背了迪米特法则。
重构
public class Document {
private Html html;
private String url;
public Document(String url, Html html) {
this.html = html;
this.url = url;
}
//...
}
// 通过一个工厂方法来创建Document
public class DocumentFactory {
private HtmlDownloader downloader;
public DocumentFactory(HtmlDownloader downloader) {
this.downloader = downloader;
}
public Document createDocument(String url) {
Html html = downloader.downloadHtml(url);
return new Document(url, html);
}
}
有依赖关系的类之间,尽量只依赖必要的接口。
Serialization 类负责对象的序列化和反序列化。
public class Serialization {
public String serialize(Object object) {
String serializedResult = ...;
//...
return serializedResult;
}
public Object deserialize(String str) {
Object deserializedResult = ...;
//...
return deserializedResult;
}
}
假设在我们的项目中,有些类只用到了序列化操作,而另一些类只用到反序列化操作。那基于迪米特法则后半部分“有依赖关系的类之间,尽量只依赖必要的接口”,只用到序列化操作的那部分类不应该依赖反序列化接口。同理,只用到反序列化操作的那部分类不应该依赖序列化接口。
根据这个思路,我们应该将 Serialization 类拆分为两个更小粒度的类,一个只负责序列化(Serializer 类),一个只负责反序列化(Deserializer 类)。拆分之后,使用序列化操作的类只需要依赖 Serializer 类,使用反序列化操作的类只需要依赖 Deserializer 类。
public class Serializer {
public String serialize(Object object) {
String serializedResult = ...;
...
return serializedResult;
}
}
public class Deserializer {
public Object deserialize(String str) {
Object deserializedResult = ...;
...
return deserializedResult;
}
}
尽管拆分之后的代码更能满足迪米特法则,但却违背了高内聚的设计思想。高内聚要求相近的功能要放到同一个类中,这样可以方便功能修改的时候,修改的地方不至于过于分散。对于刚刚这个例子来说,如果我们修改了序列化的实现方式,比如从 JSON 换成了 XML,那反序列化的实现逻辑也需要一并修改。在未拆分的情况下,我们只需要修改一个类即可。在拆分之后,我们需要修改两个类。显然,这种设计思路的代码改动范围变大了。
如果我们既不想违背高内聚的设计思想,也不想违背迪米特法则,那我们该如何解决这个问题呢?实际上,通过引入两个接口就能轻松解决这个问题,“接口隔离原则”。
public interface Serializable {
String serialize(Object object);
}
public interface Deserializable {
Object deserialize(String text);
}
public class Serialization implements Serializable, Deserializable {
@Override
public String serialize(Object object) {
String serializedResult = ...;
...
return serializedResult;
}
@Override
public Object deserialize(String str) {
Object deserializedResult = ...;
...
return deserializedResult;
}
}
public class DemoClass_1 {
private Serializable serializer;
public Demo(Serializable serializer) {
this.serializer = serializer;
}
//...
}
public class DemoClass_2 {
private Deserializable deserializer;
public Demo(Deserializable deserializer) {
this.deserializer = deserializer;
}
//...
}
尽管我们还是要往 DemoClass_1 的构造函数中,传入包含序列化和反序列化的 Serialization 实现类,但是,我们依赖的 Serializable 接口只包含序列化操作,DemoClass_1 无法使用 Serialization 类中的反序列化接口,对反序列化操作无感知,这也就符合了迪米特法则后半部分所说的“依赖有限接口”的要求。
上面的的代码实现思路,也体现了“基于接口而非实现编程”的设计原则,结合迪米特法则,我们可以总结出一条新的设计原则,那就是“基于最小接口而非最大实现编程”。
新的设计模式和设计原则是怎么创造出来的?
就是在大量的实践中,针对开发痛点总结归纳出来的套路。
整个类只包含序列化和反序列化两个操作,只用到序列化操作的使用者,即便能够感知到仅有的一个反序列化函数,问题也不大。那为了满足迪米特法则,我们将一个非常简单的类,拆分出两个接口,是否有点过度设计的意思呢?
设计原则本身没有对错,只有能否用对之说。不要为了应用设计原则而应用设计原则,我们在应用设计原则的时候,一定要具体问题具体分析。
对于刚刚这个 Serialization 类来说,只包含两个操作,确实没有太大必要拆分成两个接口。但是,如果我们对 Serialization 类添加更多的功能,实现更多更好用的序列化、反序列化函数,我们来重新考虑一下这个问题。
public class Serializer { // 参看JSON的接口定义
public String serialize(Object object) { //... }
public String serializeMap(Map map) { //... }
public String serializeList(List list) { //... }
public Object deserialize(String objectString) { //... }
public Map deserializeMap(String mapString) { //... }
public List deserializeList(String listString) { //... }
}
在这种场景下,第二种设计思路要更好些。因为基于之前的应用场景来说,大部分代码只需要用到序列化的功能。对于这部分使用者,没必要了解反序列化的“知识”,而修改之后的 Serialization 类,反序列化的“知识”,从一个函数变成了三个。一旦任一反序列化操作有代码改动,我们都需要检查、测试所有依赖 Serialization 类的代码是否还能正常工作。为了减少耦合和测试工作量,我们应该按照迪米特法则,将反序列化和序列化的功能隔离开来。
大部分业务系统的开发都可以分为三层:Contoller 层、Service 层、Repository 层。
1. 分层能起到代码复用的作用
同一个 Repository 可能会被多个 Service 来调用,同一个 Service 可能会被多个 Controller 调用。比如,UserService 中的 getUserById() 接口封装了通过 ID 获取用户信息的逻辑,这部分逻辑可能会被 UserController 和 AdminController 等多个 Controller 使用。如果没有 Service 层,每个 Controller 都要重复实现这部分逻辑,显然会违反 DRY 原则。
2. 分层能起到隔离变化的作用
分层体现了一种抽象和封装的设计思想。比如,Repository 层封装了对数据库访问的操作,提供了抽象的数据访问接口。基于接口而非实现编程的设计思想,Service 层使用 Repository 层提供的接口,并不关心其底层依赖的是哪种具体的数据库。当我们需要替换数据库的时候,比如从 MySQL 到 Oracle,从 Oracle 到 Redis,只需要改动 Repository 层的代码,Service 层的代码完全不需要修改。
Controller、Service、Repository 三层代码的稳定程度不同、引起变化的原因不同,所以分成三层来组织代码,能有效地隔离变化。比如,Repository 层基于数据库表,而数据库表改动的可能性很小,所以 Repository 层的代码最稳定,而 Controller 层提供适配给外部使用的接口,代码经常会变动。分层之后,Controller 层中代码的频繁改动并不会影响到稳定的 Repository 层。
3. 分层能起到隔离关注点的作用
Repository 层只关注数据的读写。Service 层只关注业务逻辑,不关注数据的来源。Controller 层只关注与外界打交道,数据校验、封装、格式转换,并不关心业务逻辑。三层之间的关注点不同,分层之后,职责分明,更加符合单一职责原则,代码的内聚性更好。
4. 分层能提高代码的可测试性
单元测试不依赖不可控的外部组件,比如数据库。分层之后,Repsitory 层的代码通过依赖注入的方式供 Service 层使用,当要测试包含核心业务逻辑的 Service 层代码的时候,我们可以用 mock 的数据源替代真实的数据库,注入到 Service 层代码中。
5. 分层能应对系统的复杂性
所有的代码都放到一个类中,那这个类的代码就会因为需求的迭代而无限膨胀。我们知道,当一个类或一个函数的代码过多之后,可读性、可维护性就会变差。那我们就要想办法拆分。拆分有垂直和水平两个方向。水平方向基于业务来做拆分,就是模块化;垂直方向基于流程来做拆分,就是这里说的分层。
不管是分层、模块化,还是 OOP、DDD,以及各种设计模式、原则和思想,都是为了应对复杂系统,应对系统的复杂性。对于简单系统来说,其实是发挥不了作用的,就是俗话说的“杀鸡焉用牛刀”。
针对 Controller、Service、Repository 三层,每层都会定义相应的数据对象,它们分别是 VO(View Object)、BO(Business Object)、Entity,例如 UserVo、UserBo、UserEntity。在实际的开发中,VO、BO、Entity 可能存在大量的重复字段,甚至三者包含的字段完全一样。
但每层定义自己的对象,主要有三个原因:
(1)VO、BO、Entity 并非完全一样。比如,我们可以在 UserEntity、UserBo 中定义 Password 字段,但显然不能在 UserVo 中定义 Password 字段,否则就会将用户的密码暴露出去。
(2)VO、BO、Entity 三个类虽然代码重复,但功能语义不重复,从职责上讲是不一样的。所以,也并不能算违背 DRY 原则。在前面讲到 DRY 原则的时候,针对这种情况,如果合并为同一个类,那也会存在后期因为需求的变化而需要再拆分的问题。
(3)为了尽量减少每层之间的耦合,把职责边界划分明确,每层都会维护自己的数据对象,层与层之间通过接口交互。数据从下一层传递到上一层的时候,将下一层的数据对象转化成上一层的数据对象,再继续处理。虽然需要做数据对象之间的转化,但是分层清晰。对于非常大的项目来说,结构清晰是第一位的!
VO、BO、Entity 的设计思路并不违反 DRY 原则,为了分层清晰、减少耦合,多维护几个类的成本也并不是不能接受的。
(1)继承可以解决代码重复问题。我们可以将公共的字段定义在父类中,让 VO、BO、Entity 都继承这个父类,各自只定义特有的字段。
(2)组合
对于稍微复杂系统的开发,可以借鉴 TDD(测试驱动开发)和 Prototype(最小原型)的思想,先聚焦于一个简单的应用场景,基于此设计实现一个简单的原型。尽管这个最小原型系统在功能和非功能特性上都不完善,但它能够看得见、摸得着,比较具体、不抽象,能够很有效地帮助我缕清更复杂的设计思路,是迭代设计的基础。
这就好比做算法题目。当我们想要一下子就想出一个最优解法时,可以先写几组测试数据,找找规律,再先想一个最简单的算法去解决它。虽然这个最简单的算法在时间、空间复杂度上可能都不令人满意,但是我们可以基于此来做优化,这样思路就会更加顺畅。
对于非业务通用框架的开发,我们在做需求分析的时候,除了功能性需求分析之外,还需要考虑框架的非功能性需求。比如,框架的易用性、性能、扩展性、容错性、通用性等。
对于复杂框架的设计,很多人往往觉得无从下手。今天我们分享了几个小技巧,其中包括:画产品线框图、聚焦简单应用场景、设计实现最小原型、画系统设计图等。这些方法的目的都是为了让问题简化、具体、明确,提供一个迭代设计开发的基础,逐步推进。
实际上,不仅仅是软件设计开发,不管做任何事情,如果我们总是等到所有的东西都想好了再开始,那这件事情可能永远都开始不了。有句老话讲:万事开头难,所以,先迈出第一步很重要。
小步快跑、逐步迭代
最小原型为我们奠定了迭代开发的基础,但离我们最终期望的框架的样子还有很大的距离。
试图去实现上面罗列的所有功能需求,希望写出一个完美的框架,发现这是件挺烧脑的事情。
对于没有太多经验的开发者来说,想一下子把所有需求都实现出来,更是一件非常有挑战的事情。一旦无法顺利完成,你可能就会有很强的挫败感,就会陷入自我否定的情绪中。
不过,即便你有能力将所有需求都实现,可能也要花费很大的设计精力和开发时间,迟迟没有产出,你的 leader 会因此产生很强的不可控感。对于现在的互联网项目来说,小步快跑、逐步迭代是一种更好的开发模式。所以,我们应该分多个版本逐步完善这个框架。第一个版本可以先实现一些基本功能,对于更高级、更复杂的功能,以及非功能性需求不做过高的要求,在后续的 v2.0、v3.0……版本中继续迭代优化。
针对这个框架的开发,我们在 v1.0 版本中,暂时只实现下面这些功能。剩下的功能留在 v2.0、v3.0 版本。
上一节课中的最小原型的实现,所有的代码都耦合在一个类中,这显然是不合理的。
1. 划分职责进而识别出有哪些类
2. 定义类及类与类之间的关系
面向对象设计和实现要做的事情,就是把合适的代码放到合适的类中。让代码尽量地满足低耦合、高内聚、单一职责、对扩展开放对修改关闭等之前讲到的各种设计原则和思想,尽量地让设计满足代码易复用、易读、易扩展、易维护。
3. 将类组装起来并提供执行入口
4、Review 设计与实现

重构是一种对软件内部结构的改善,目的是在不改变软件外部的可见行为的情况下,使其更易理解,修改成本更低。
理解为,在保持功能不变的前提下,利用设计思想、原则、模式、编程规范等理论来优化代码,修改设计上的不足,提高代码质量。
重构实际上就是将我们学习的经典设计思想、设计原则、设计模式、编程规范,应用到实践的一个很好的场景,能够锻炼我们熟练使用这些理论知识的能力。
初级工程师在已有代码框架下修改 bug、修改添加功能代码;高级工程师从零开始设计代码结构、搭建代码框架;而资深工程师为代码质量负责,需要发觉代码存在的问题,重构代码,时刻保证代码质量处于一个可控的状态。
大型重构指的是对顶层代码设计的重构,包括:系统、模块、代码结构、类与类之间的关系等的重构,重构的手段有:分层、模块化、解耦、抽象可复用组件等等。这类重构涉及的代码改动会比较多,影响面会比较大,所以难度也较大,耗时会比较长,引入 bug 的风险也会相对比较大。
小型重构指的是对代码细节的重构,主要是针对类、函数、变量等代码级别的重构,比如规范命名、规范注释、消除超大类或函数、提取重复代码等等。小型重构更多的是利用我们能后面要讲到的编码规范。这类重构要修改的地方比较集中,比较简单,可操作性较强,耗时会比较短,引入 bug 的风险相对来说也会比较小。
重构策略是持续重构,建立持续重构意识。
平时没有事情的时候,看看项目中有哪些写得不够好的、可以优化的代码,主动去重构一下。或者,在修改、添加某个功能代码的时候,你也可以顺手把不符合编码规范、不好的设计重构一下。总之,就像把单元测试、Code Review 作为开发的一部分,我们如果能把持续重构也作为开发的一部分,成为一种开发习惯,对项目、对自己都会很有好处。
我们要正确地看待代码质量和重构这件事情。技术在更新、需求在变化、人员在流动,代码质量总会在下降,代码总会存在不完美,重构就会持续在进行。时刻具有持续重构意识,才能避免开发初期就过度设计,避免代码维护的过程中质量的下降。而那些看到别人代码有点瑕疵就一顿乱骂,或者花尽心思去构思一个完美设计的人,往往都是因为没有树立正确的代码质量观,没有持续重构意识。
在进行大型重构的时候,我们要提前做好完善的重构计划,分阶段来进行。每个阶段完成一小部分代码的重构,然后提交、测试、运行,发现没有问题之后,再继续进行下一阶段的重构,保证代码仓库中的代码一直处于可运行、逻辑正确的状态。每个阶段,我们都要控制好重构影响到的代码范围,考虑好如何兼容老的代码逻辑,必要的时候还需要写一些兼容过渡代码。只有这样,我们才能让每一阶段的重构都不至于耗时太长(最好一天就能完成),不至于与新的功能开发相冲突。
大规模高层次的重构一定是有组织、有计划,并且非常谨慎的,需要有经验、熟悉业务的资深同事来主导。而小规模低层次的重构,因为影响范围小,改动耗时短,所以,只要你愿意并且有时间,随时都可以去做。实际上,除了人工去发现低层次的质量问题,我们还可以借助很多成熟的静态代码分析工具(比如 CheckStyle、FindBugs、PMD),来自动发现代码中的问题,然后针对性地进行重构优化。
对于重构这件事情,资深的工程师、项目 leader 要负起责任来,没事就重构一下代码,时刻保证代码质量处在一个良好的状态。否则,一旦出现“破窗效应”。
最可落地执行、最有效的保证重构不出错的手段应该就是单元测试(Unit Testing)了。当重构完成之后,如果新的代码仍然能通过单元测试,那就说明代码原有逻辑的正确性未被破坏,原有的外部可见行为未变。
单元测试相对于集成测试(Integration Testing)来说,测试的粒度更小一些。
集成测试的测试对象是整个系统或者某个功能模块,比如测试用户注册、登录功能是否正常,是一种端到端(end to end)的测试。
单元测试的测试对象是类或者函数,用来测试一个类和函数是否都按照预期的逻辑执行。这是代码层级的测试。
写单元测试本身不需要什么高深技术。它更多的是考验程序员思维的缜密程度,看能否设计出覆盖各种正常及异常情况的测试用例,来保证代码在任何预期或非预期的情况下都能正确运行。
public class Text {
private String content;
public Text(String content) {
this.content = content;
}
/**
* 将字符串转化成数字,忽略字符串中的首尾空格;
* 如果字符串中包含除首尾空格之外的非数字字符,则返回null。
*/
public Integer toNumber() {
if (content == null || content.isEmpty()) {
return null;
}
//...省略代码实现...
return null;
}
}
测试 Text 类中的 toNumber() 函数的正确性,应该如何编写单元测试呢?

public class Assert {
public static void assertEquals(Integer expectedValue, Integer actualValue) {
if (actualValue != expectedValue) {
String message = String.format(
"Test failed, expected: %d, actual: %d.", expectedValue, actualValue);
System.out.println(message);
} else {
System.out.println("Test succeeded.");
}
}
public static boolean assertNull(Integer actualValue) {
boolean isNull = actualValue == null;
if (isNull) {
System.out.println("Test succeeded.");
} else {
System.out.println("Test failed, the value is not null:" + actualValue);
}
return isNull;
}
}
public class TestCaseRunner {
public static void main(String[] args) {
System.out.println("Run testToNumber()");
new TextTest().testToNumber();
System.out.println("Run testToNumber_nullorEmpty()");
new TextTest().testToNumber_nullorEmpty();
System.out.println("Run testToNumber_containsLeadingAndTrailingSpaces()");
new TextTest().testToNumber_containsLeadingAndTrailingSpaces();
System.out.println("Run testToNumber_containsMultiLeadingAndTrailingSpaces()");
new TextTest().testToNumber_containsMultiLeadingAndTrailingSpaces();
System.out.println("Run testToNumber_containsInvalidCharaters()");
new TextTest().testToNumber_containsInvalidCharaters();
}
}
public class TextTest {
public void testToNumber() {
Text text = new Text("123");
Assert.assertEquals(123, text.toNumber());
}
public void testToNumber_nullorEmpty() {
Text text1 = new Text(null);
Assert.assertNull(text1.toNumber());
Text text2 = new Text("");
Assert.assertNull(text2.toNumber());
}
public void testToNumber_containsLeadingAndTrailingSpaces() {
Text text1 = new Text(" 123");
Assert.assertEquals(123, text1.toNumber());
Text text2 = new Text("123 ");
Assert.assertEquals(123, text2.toNumber());
Text text3 = new Text(" 123 ");
Assert.assertEquals(123, text3.toNumber());
}
public void testToNumber_containsMultiLeadingAndTrailingSpaces() {
Text text1 = new Text(" 123");
Assert.assertEquals(123, text1.toNumber());
Text text2 = new Text("123 ");
Assert.assertEquals(123, text2.toNumber());
Text text3 = new Text(" 123 ");
Assert.assertEquals(123, text3.toNumber());
}
public void testToNumber_containsInvalidCharaters() {
Text text1 = new Text("123a4");
Assert.assertNull(text1.toNumber());
Text text2 = new Text("123 4");
Assert.assertNull(text2.toNumber());
}
}
单元测试保证重构不出错,也是保证代码质量最有效的两个手段之一(另一个是 Code Review)。
写单元测试的过程本身就是代码 Code Review 和重构的过程,能有效地发现代码中的 bug 和代码设计上的问题。单元测试还是对集成测试的有力补充,还能帮助我们快速熟悉代码,是 TDD 可落地执行的改进方案。
单元测试的好处
1. 单元测试能有效地帮你发现代码中的 bug
能否写出 bug free 的代码,是判断工程师编码能力的重要标准之一。通过单元测试也常常会发现代码中的很多考虑不全面的地方。
2. 写单元测试能帮你发现代码设计上的问题
代码的可测试性是评判代码质量的一个重要标准。对于一段代码,如果很难为其编写单元测试,或者单元测试写起来很吃力,需要依靠单元测试框架里很高级的特性才能完成,那往往就意味着代码设计得不够合理,比如,没有使用依赖注入、大量使用静态函数、全局变量、代码高度耦合等。
3. 单元测试是对集成测试的有力补充
程序运行的 bug 往往出现在一些边界条件、异常情况下,比如,除数未判空、网络超时。而大部分异常情况都比较难在测试环境中模拟。而单元测试可以利用下一节课中讲到的 mock 的方式,控制 mock 的对象返回我们需要模拟的异常,来测试代码在这些异常情况的表现。
对于一些复杂系统来说,集成测试也无法覆盖得很全面。复杂系统往往有很多模块。每个模块都有各种输入、输出、异常情况,组合起来,整个系统就有无数测试场景需要模拟,无数的测试用例需要设计,再强大的测试团队也无法穷举完备。
尽管单元测试无法完全替代集成测试,但如果我们能保证每个类、每个函数都能按照我们的预期来执行,底层 bug 少了,那组装起来的整个系统,出问题的概率也就相应减少了。
4. 写单元测试的过程本身就是代码重构的过程
设计和实现代码的时候,我们很难把所有的问题都想清楚。而编写单元测试就相当于对代码的一次自我 Code Review,在这个过程中,我们可以发现一些设计上的问题(比如代码设计的不可测试)以及代码编写方面的问题(比如一些边界条件处理不当)等,然后针对性的进行重构。
5. 阅读单元测试能帮助你快速熟悉代码
阅读代码最有效的手段,就是先了解它的业务背景和设计思路,然后再去看代码,这样代码读起来就会轻松很多。在没有文档和注释的情况下,单元测试就起了替代性作用。单元测试用例实际上就是用户用例,反映了代码的功能和如何使用。借助单元测试,我们不需要深入的阅读代码,便能知道代码实现了什么功能,有哪些特殊情况需要考虑,有哪些边界条件需要处理。
6. 单元测试是 TDD 可落地执行的改进方案
测试驱动开发(Test-Driven Development,简称 TDD)是一个经常被提及但很少被执行的开发模式。它的核心指导思想就是测试用例先于代码编写。不过,要让程序员能彻底地接受和习惯这种开发模式还是挺难的。
单元测试正好是对 TDD 的一种改进方案,先写代码,紧接着写单元测试,最后根据单元测试反馈出来问题,再回过头去重构代码。这个开发流程更加容易被接受,更加容易落地执行,而且又兼顾了 TDD 的优点。
写单元测试就是针对代码设计覆盖各种输入、异常、边界条件的测试用例,并将这些测试用例翻译成代码的过程。
可以利用单元测试框架,来简化测试代码的编写。比如,Java 中比较出名的单元测试框架有 Junit、TestNG、Spring Test 等。这些框架提供了通用的执行流程(比如执行测试用例的 TestCaseRunner)和工具类库(比如各种 Assert 判断函数)等。借助它们,我们在编写测试代码的时候,只需要关注测试用例本身的编写即可。
针对 toNumber() 函数的测试用例,我们利用 Junit 单元测试框架重新实现一下。
import org.junit.Assert;
import org.junit.Test;
public class TextTest {
@Test
public void testToNumber() {
Text text = new Text("123");
Assert.assertEquals(new Integer(123), text.toNumber());
}
@Test
public void testToNumber_nullorEmpty() {
Text text1 = new Text(null);
Assert.assertNull(text1.toNumber());
Text text2 = new Text("");
Assert.assertNull(text2.toNumber());
}
@Test
public void testToNumber_containsLeadingAndTrailingSpaces() {
Text text1 = new Text(" 123");
Assert.assertEquals(new Integer(123), text1.toNumber());
Text text2 = new Text("123 ");
Assert.assertEquals(new Integer(123), text2.toNumber());
Text text3 = new Text(" 123 ");
Assert.assertEquals(new Integer(123), text3.toNumber());
}
@Test
public void testToNumber_containsMultiLeadingAndTrailingSpaces() {
Text text1 = new Text(" 123");
Assert.assertEquals(new Integer(123), text1.toNumber());
Text text2 = new Text("123 ");
Assert.assertEquals(new Integer(123), text2.toNumber());
Text text3 = new Text(" 123 ");
Assert.assertEquals(new Integer(123), text3.toNumber());
}
@Test
public void testToNumber_containsInvalidCharaters() {
Text text1 = new Text("123a4");
Assert.assertNull(text1.toNumber());
Text text2 = new Text("123 4");
Assert.assertNull(text2.toNumber());
}
}
1. 编写单元测试尽管繁琐,但并不是太耗时;
不需要考虑太多代码设计上的问题,测试代码实现起来也比较简单。不同测试用例之间的代码差别可能并不是很大,简单 copy-paste 改改就行。
2. 我们可以稍微放低对单元测试代码质量的要求;
单元测试毕竟不会在产线上运行,而且每个类的测试代码也比较独立,基本不互相依赖。所以,相对于被测代码,我们对单元测试代码的质量可以放低一些要求。命名稍微有些不规范,代码稍微有些重复,也都是没有问题的。
3. 覆盖率作为衡量单元测试质量的唯一标准是不合理的;
单元测试覆盖率是比较容易量化的指标,常常作为单元测试写得好坏的评判标准。有很多现成的工具专门用来做覆盖率统计,比如,JaCoCo、Cobertura、Emma、Clover。覆盖率的计算方式有很多种,比较简单的是语句覆盖,稍微高级点的有:条件覆盖、判定覆盖、路径覆盖。
不管覆盖率的计算方式如何高级,衡量单元测试质量,不能光看覆盖率。实际上,更重要的是要看测试用例是否覆盖了所有可能的情况,特别是一些 corner case。
像下面这段代码,我们只需要一个测试用例就可以做到 100% 覆盖率,比如 cal(10.0, 2.0),但并不代表测试足够全面了,我们还需要考虑,当除数等于0的情况下,代码执行是否符合预期。
public double cal(double a, double b) {
if (b != 0) {
return a / b;
}
}
过度关注单元测试的覆盖率会导致开发人员为了提高覆盖率,写很多没有必要的测试代码,比如 get、set 方法非常简单,没有必要测试。从过往的经验上来讲,一个项目的单元测试覆盖率在 60~70% 即可上线。如果项目对代码质量要求比较高,可以适当提高单元测试覆盖率的要求。
4. 单元测试不要依赖被测代码的具体实现逻辑;
单元测试不要依赖被测试函数的具体实现逻辑,它只关心被测函数实现了什么功能。我们切不可为了追求覆盖率,逐行阅读代码,然后针对实现逻辑编写单元测试。否则,一旦对代码进行重构,在代码的外部行为不变的情况下,对代码的实现逻辑进行了修改,那原本的单元测试都会运行失败,也就起不到为重构保驾护航的作用了,也违背了我们写单元测试的初衷。
5. 单元测试框架无法测试,多半是因为代码的可测试性不好;
写单元测试本身不需要太复杂的技术,大部分单元测试框架都能满足。在公司内部,起码团队内部需要统一单元测试框架。如果自己写的代码用已经选定的单元测试框架无法测试,那多半是代码写得不够好,代码的可测试性不够好。这个时候,我们要重构自己的代码,让其更容易测试,而不是去找另一个更加高级的单元测试框架。
单元测试为何难落地执行?
29 | 理论三:什么是代码的可测试性?如何写出可测试性好的代码?-极客时间
这里面讲的是
编写可测试代码案例实战
描述比较复杂,需要用到的时候,再去看吧!
单元测试主要是测试程序员自己编写的代码逻辑的正确性,并非是端到端的集成测试,它不需要测试所依赖的外部系统(分布式锁、Wallet RPC 服务)的逻辑正确性。所以,如果代码中依赖了外部系统或者不可控组件,比如,需要依赖数据库、网络通信、文件系统等,那我们就需要将被测代码与外部系统解依赖,而这种解依赖的方法就叫作“mock”。所谓的 mock 就是用一个“假”的服务替换真正的服务。mock 的服务完全在我们的控制之下,模拟输出我们想要的数据。
mock 的方式主要有两种,手动 mock 和利用框架 mock。
依赖注入是实现代码可测试性的最有效的手段。
RedisDistributedLock 是一个单例类。单例相当于一个全局变量,我们无法 mock(无法继承和重写方法),也无法通过依赖注入的方式来替换。
如果 RedisDistributedLock 是我们自己维护的,可以自由修改、重构,那我们可以将其改为非单例的模式,或者定义一个接口,比如 IDistributedLock,让 RedisDistributedLock 实现这个接口。这样我们就可以像前面 WalletRpcService 的替换方式那样,替换 RedisDistributedLock 为 MockRedisDistributedLock 了。但如果 RedisDistributedLock 不是我们维护的,我们无权去修改这部分代码。但是可以 二次封装.......
代码中包含跟“时间”有关的“未决行为”逻辑。我们一般的处理方式是将这种未决行为逻辑重新封装。
1. 未决行为
未决行为逻辑就是,代码的输出是随机或者说不确定的,比如,跟时间、随机数有关的代码。
2. 全局变量
滥用全局变量也让编写单元测试变得困难。
3. 静态方法
在代码中调用静态方法,有时候会导致代码不易测试。主要原因是静态方法也很难 mock。但是,这个要分情况来看。只有在这个静态方法执行耗时太长、依赖外部资源、逻辑复杂、行为未决等情况下,我们才需要在单元测试中 mock 这个静态方法。除此之外,如果只是类似 Math.abs() 这样的简单静态方法,并不会影响代码的可测试性,因为本身并不需要 mock。
4. 复杂继承
如果我们利用组合而非继承来组织类之间的关系,类之间的结构层次比较扁平,在编写单元测试的时候,只需要 mock 类所组合依赖的对象即可。
5. 高耦合代码
如果一个类职责很重,需要依赖十几个外部对象才能完成工作,代码高度耦合,那我们在编写单元测试的时候,可能需要 mock 这十几个依赖的对象。不管是从代码设计的角度来说,还是从编写单元测试的角度来说,这都是不合理的。
“高内聚、松耦合”是一个比较通用的设计思想,不仅可以指导细粒度的类和类之间关系的设计,还能指导粗粒度的系统、架构、模块的设计。相对于编码规范,它能够在更高层次上提高代码的可读性和可维护性。
过于复杂的代码往往在可读性、可维护性上都不友好。解耦保证代码松耦合、高内聚,是控制代码复杂度的有效手段。
解耦的思想到处可见,比如,Spring 中的 AOP 能实现业务与非业务代码的解耦,IOC 能实现对象的构造和使用的解耦。
“高内聚、松耦合”的特性可以让我们聚焦在某一模块或类中,不需要了解太多其他模块或类的代码,让我们的焦点不至于过于发散,降低了阅读和修改代码的难度。而且,因为依赖关系简单,耦合小,修改代码不至于牵一发而动全身,代码改动比较集中,引入 bug 的风险也就减少了很多。同时,“高内聚、松耦合”的代码可测试性也更加好,容易 mock 或者很少需要 mock 外部依赖的模块或者类。
代码“高内聚、松耦合”,也就意味着,代码结构清晰、分层和模块化合理、依赖关系简单、模块或类之间的耦合小,那代码整体的质量就不会差。即便某个具体的类或者模块设计得不怎么合理,代码质量不怎么高,影响的范围是非常有限的。我们可以聚焦于这个模块或者类,做相应的小型重构。而相对于代码结构的调整,这种改动范围比较集中的小型重构的难度就容易多了。
1、看修改代码会不会牵一发而动全身。
2、在阅读源码的时候经常会用到的,那就是把模块与模块之间、类与类之间的依赖关系画出来,根据依赖关系图的复杂性来判断是否需要解耦重构。
如果依赖关系复杂、混乱,那从代码结构上来讲,可读性和可维护性肯定不是太好,那我们就需要考虑是否可以通过解耦的方法,让依赖关系变得清晰、简单。当然,这种判断还是有比较强的主观色彩。
1. 封装与抽象
封装和抽象可以有效地隐藏实现的复杂性,隔离实现的易变性,给依赖的模块提供稳定且易用的抽象接口。
比如,Unix 系统提供的 open() 文件操作函数,我们用起来非常简单,但是底层实现却非常复杂,涉及权限控制、并发控制、物理存储等等。我们通过将其封装成一个抽象的 open() 函数,能够有效控制代码复杂性的蔓延,将复杂性封装在局部代码中。除此之外,因为 open() 函数基于抽象而非具体的实现来定义,所以我们在改动 open() 函数的底层实现的时候,并不需要改动依赖它的上层代码,也符合我们前面提到的“高内聚、松耦合”代码的评判标准。
2. 中间层
引入中间层能简化模块或类之间的依赖关系。
在引入数据存储中间层之前,A、B、C 三个模块都要依赖内存一级缓存、Redis 二级缓存、DB 持久化存储三个模块。在引入中间层之后,三个模块只需要依赖数据存储一个模块即可。从图上可以看出,中间层的引入明显地简化了依赖关系,让代码结构更加清晰。

除此之外,我们在进行重构的时候,引入中间层可以起到过渡的作用,能够让开发和重构同步进行,不互相干扰。比如,某个接口设计得有问题,我们需要修改它的定义,同时,所有调用这个接口的代码都要做相应的改动。如果新开发的代码也用到这个接口,那开发就跟重构冲突了。为了让重构能小步快跑,我们可以分下面四个阶段来完成接口的修改。

这样,每个阶段的开发工作量都不会很大,都可以在很短的时间内完成。重构跟开发冲突的概率也变小了。
3. 模块化
模块化是构建复杂系统常用的手段。
对于一个大型复杂系统来说,没有人能掌控所有的细节。之所以我们能搭建出如此复杂的系统,并且能维护得了,最主要的原因就是将系统划分成各个独立的模块,让不同的人负责不同的模块,这样即便在不了解全部细节的情况下,管理者也能协调各个模块,让整个系统有效运转。
聚焦到软件开发上面,很多大型软件(比如 Windows)之所以能做到几百、上千人有条不紊地协作开发,也归功于模块化做得好。不同的模块之间通过 API 来进行通信,每个模块之间耦合很小,每个小的团队聚焦于一个独立的高内聚模块来开发,最终像搭积木一样将各个模块组装起来,构建成一个超级复杂的系统。
聚焦到代码层面。合理地划分模块能有效地解耦代码,提高代码的可读性和可维护性。所以,我们在开发代码的时候,一定要有模块化意识,将每个模块都当作一个独立的 lib 一样来开发,只提供封装了内部实现细节的接口给其他模块使用,这样可以减少不同模块之间的耦合度。
模块化的思想无处不在,像 SOA、微服务、lib 库、系统内模块划分,甚至是类、函数的设计,都体现了模块化思想。如果追本溯源,模块化思想更加本质的东西就是分而治之。
4. 其他设计思想和原则
以下设计原则都以实现代码的“高内聚、松耦合”为目的:
(1)单一职责原则
内聚性和耦合性并非独立的。高内聚会让代码更加松耦合,而实现高内聚的重要指导原则就是单一职责原则。模块或者类的职责设计得单一,而不是大而全,那依赖它的类和它依赖的类就会比较少,代码耦合也就相应的降低了。
(2)基于接口而非实现编程
基于接口而非实现编程能通过接口这样一个中间层,隔离变化和具体的实现。这样做的好处是,在有依赖关系的两个模块或类之间,一个模块或者类的改动,不会影响到另一个模块或类。实际上,这就相当于将一种强依赖关系(强耦合)解耦为了弱依赖关系(弱耦合)。
(3)依赖注入
跟基于接口而非实现编程思想类似,依赖注入也是将代码之间的强耦合变为弱耦合。尽管依赖注入无法将本应该有依赖关系的两个类,解耦为没有依赖关系,但可以让耦合关系没那么紧密,容易做到插拔替换。
(4)多用组合少用继承
继承是一种强依赖关系,父类与子类高度耦合,且这种耦合关系非常脆弱,牵一发而动全身,父类的每一次改动都会影响所有的子类。相反,组合关系是一种弱依赖关系,这种关系更加灵活,所以,对于继承结构比较复杂的代码,利用组合来替换继承,也是一种解耦的有效手段。
(5)迪米特法则
迪米特法则讲的是,不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。从定义上,我们明显可以看出,这条原则的目的就是为了实现代码的松耦合。
(6)还有一些设计模式也是为了解耦依赖,比如观察者模式
持续低层次、小规模重构依赖的基本上都是编码规范,这也是改善代码可读性的有效手段。
项目名、模块名、包名、对外暴露的接口,类名、函数名、变量名、参数名。对于影响范围比较大的命名,比如包名、接口、类名,我们一定要反复斟酌、推敲。实在想不到好名字的时候,可以去 GitHub 上用相关的关键词联想搜索一下,看看类似的代码是怎么命名的。
1. 命名多长最合适?
在足够表达其含义的情况下,命名当然是越短越好。但是,大部分情况下,短的命名都没有长的命名更能达意。所以,很多书籍或者文章都不推荐在命名时使用缩写。对于一些默认的、大家都比较熟知的词,我比较推荐用缩写。这样一方面能让命名短一些,另一方面又不影响阅读理解,比如,sec 表示 second、str 表示 string、num 表示 number、doc 表示 document。除此之外,对于作用域比较小的变量,我们可以使用相对短的命名,比如一些函数内的临时变量。相反,对于类名这种作用域比较大的,我更推荐用长的命名方式。
命名的一个原则就是以能准确达意为目标。
命名的时候,我们一定要学会换位思考,假设自己不熟悉这块代码,从代码阅读者的角度去考量命名是否足够直观。
2. 利用上下文简化命名
public class User {
private String userName;
private String userPassword;
private String userAvatarUrl;
//...
}
在 User 类这样一个上下文中,我们没有在成员变量的命名中重复添加“user”这样一个前缀单词,而是直接命名为 name、password、avatarUrl。在使用这些属性时候,我们能借助对象这样一个上下文,表意也足够明确。
User user = new User(); user.getName(); // 借助user对象这个上下文
除了类之外,函数参数也可以借助函数这个上下文来简化命名。
public void uploadUserAvatarImageToAliyun(String userAvatarImageUri); //利用上下文简化为: public void uploadUserAvatarImageToAliyun(String imageUri);
3. 命名要可读、可搜索
可读,指的是不要用一些特别生僻、难发音的英文单词来命名。
得让大部分人看一眼就能知道怎么读。比如, 一个项目,名叫 inkstone,虽然你不一定知道它表示什么意思,但基本上都能读得上来,不影响沟通交流,这就算是一个比较好的项目命名。
命名可搜索。我们在 IDE 中编写代码的时候,经常会用“关键词联想”的方法来自动补全和搜索。比如,键入某个对象“.get”,希望 IDE 返回这个对象的所有 get 开头的方法。再比如,通过在 IDE 搜索框中输入“Array”,搜索 JDK 中数组相关的类。所以,我们在命名的时候,最好能符合整个项目的命名习惯。大家都用“selectXXX”表示查询,你就不要用“queryXXX”;大家都用“insertXXX”表示插入一条数据,你就要不用“addXXX”,统一规约是很重要的,能减少很多不必要的麻烦。
4. 如何命名接口和抽象类?
对于接口的命名,一般有两种比较常见的方式。一种是加前缀“I”,表示一个 Interface。比如 IUserService,对应的实现类命名为 UserService。另一种是不加前缀,比如 UserService,对应的实现类加后缀“Impl”,比如 UserServiceImpl。
对于抽象类的命名,也有两种方式,一种是带上前缀“Abstract”,比如 AbstractConfiguration;另一种是不带前缀“Abstract”。实际上,对于接口和抽象类,选择哪种命名方式都是可以的,只要项目里能够统一就行。
命名再好,毕竟有长度限制,不可能足够详尽,而这个时候,注释就是一个很好的补充。
1. 注释到底该写什么?
注释的目的就是让代码更容易看懂。只要符合这个要求的内容,你就可以将它写到注释里。总结一下,注释的内容主要包含这样三个方面:做什么、为什么、怎么做。
/**
* (what) Bean factory to create beans.
*
* (why) The class likes Spring IOC framework, but is more lightweight.
*
* (how) Create objects from different sources sequentially:
* user specified object > SPI > configuration > default object.
*/
public class BeansFactory {
// ...
}
注释起到总结性作用、文档的作用
在注释中,关于具体的代码实现思路,我们可以写一些总结性的说明、特殊情况的说明。这样能够让阅读代码的人通过注释就能大概了解代码的实现思路,阅读起来就会更加容易。
对于有些比较复杂的类或者接口,我们可能还需要在注释中写清楚“如何用”,举一些简单的 quick start 的例子,让使用者在不阅读代码的情况下,快速地知道该如何使用。
一些总结性注释能让代码结构更清晰
对于逻辑比较复杂的代码或者比较长的函数,如果不好提炼、不好拆分成小的函数调用,那我们可以借助总结性的注释来让代码结构更清晰、更有条理。
public boolean isValidPasword(String password) {
// check if password is null or empty
if (StringUtils.isBlank(password)) {
return false;
}
// check if the length of password is between 4 and 64
int length = password.length();
if (length < 4 || length > 64) {
return false;
}
// check if password contains only a~z,0~9,dot
for (int i = 0; i < length; ++i) {
char c = password.charAt(i);
if (!((c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '.')) {
return false;
}
}
return true;
}
2. 应该写多少注释?
类和方法一定要写注释,而且要写得尽可能全面、详细,而函数内部的注释要相对少一些,一般都是靠好的命名、提炼函数、解释性变量、总结性注释来提高代码的可读性。
1. 类、函数多大才合适?
或函数的代码行数不能太多,但也不能太少。类中代码太多,可读性差。类中代码太少了,分割出来的类会变多、类之间的调用关系会变复杂。
那一个类或函数有多少行代码才最合适呢?要给出一个精确的量化值是很难的。当时我们还跟做饭做了类比,对于“放盐少许”中的“少许”,即便是大厨也很难告诉你一个特别具体的量值。
对于方法代码行数的最大限制,网上有一种说法,那就是不要超过一个显示屏的垂直高度。
对于类的代码行数的最大限制,这个就更难给出一个确切的值了。我们在第 15 讲中也给出了一个间接的判断标准,那就是,当一个类的代码读起来让你感觉头大了,实现某个功能时不知道该用哪个函数了,想用哪个函数翻半天都找不到了,只用到一个小功能要引入整个类(类中包含很多无关此功能实现的函数)的时候,这就说明类的行数过多了。
2. 一行代码多长最合适?
一行代码最长不能超过 IDE 显示的宽度。需要滚动鼠标才能查看一行的全部代码,显然不利于代码的阅读。当然,这个限制也不能太小,太小会导致很多稍长点的语句被折成两行,也会影响到代码的整洁,不利于阅读。
3. 善用空行分割单元块
对于比较长的函数,如果逻辑上可以分为几个独立的代码块,在不方便将这些独立的代码块抽取成小函数的情况下,为了让逻辑更加清晰,除了上一节课中提到的用总结性注释的方法之外,我们还可以使用空行来分割各个代码块。
在类的成员变量与函数之间、静态成员变量与普通成员变量之间、各函数之间、甚至各成员变量之间,我们都可以通过添加空行的方式,让这些不同模块的代码之间,界限更加明确。写代码就类似写文章,善于应用空行,可以让代码的整体结构看起来更加有清晰、有条理。
4. 四格缩进还是两格缩进?
不管是用两格缩进还是四格缩进,一定不要用 tab 键缩进。因为在不同的 IDE 下,tab 键的显示宽度不同,有的显示为四格缩进,有的显示为两格缩进。如果在同一个项目中,不同的同事使用不同的缩进方式(空格缩进或 tab 键缩进),有可能会导致有的代码显示为两格缩进、有的代码显示为四格缩进。
这一点,留意一下,就行。
5. 大括号是否要另起一行?
只要团队统一、业内统一、跟开源项目看齐就好了。可以用IDEA的代码格式化功能。
6. 类中成员的排列顺序
依赖类按照字母序从小到大排列。类中先写成员变量后写函数。成员变量之间或函数之间,先写静态成员变量或函数,后写普通变量或函数,并且按照作用域大小依次排列。
1. 把代码分割成更小的单元块
// 重构前的代码
public void invest(long userId, long financialProductId) {
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
calendar.set(Calendar.DATE, (calendar.get(Calendar.DATE) + 1));
if (calendar.get(Calendar.DAY_OF_MONTH) == 1) {
return;
}
//...
}
// 重构后的代码:提炼函数之后逻辑更加清晰
public void invest(long userId, long financialProductId) {
if (isLastDayOfMonth(new Date())) {
return;
}
//...
}
public boolean isLastDayOfMonth(Date date) {
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
calendar.set(Calendar.DATE, (calendar.get(Calendar.DATE) + 1));
if (calendar.get(Calendar.DAY_OF_MONTH) == 1) {
return true;
}
return false;
}
2. 避免函数参数过多
针对参数过多的情况,一般有 2 种处理方法。
(1)考虑函数是否职责单一,是否能通过拆分成多个函数的方式来减少参数。
public User getUser(String username, String telephone, String email); // 拆分成多个函数 public User getUserByUsername(String username); public User getUserByTelephone(String telephone); public User getUserByEmail(String email);
(2)将函数的参数封装成对象。
public void postBlog(String title, String summary, String keywords, String content, String category, long authorId);
// 将参数封装成对象
public class Blog {
private String title;
private String summary;
private String keywords;
private Strint content;
private String category;
private long authorId;
}
public void postBlog(Blog blog);
如果函数是对外暴露的远程接口,将参数封装成对象,还可以提高接口的兼容性。在往接口中添加新的参数的时候,老的远程接口调用者有可能就不需要修改代码来兼容新的接口了。
3. 勿用函数参数来控制逻辑
不要在函数中使用布尔类型的标识参数来控制内部逻辑,true 的时候走这块逻辑,false 的时候走另一块逻辑。这明显违背了单一职责原则和接口隔离原则。
public void buyCourse(long userId, long courseId, boolean isVip); // 将其拆分成两个函数 public void buyCourse(long userId, long courseId); public void buyCourseForVip(long userId, long courseId);
不过,如果函数是 private 私有函数,影响范围有限,或者拆分之后的两个函数经常同时被调用,我们可以酌情考虑保留标识参数。
// 拆分成两个函数的调用方式
boolean isVip = false;
//...省略其他逻辑...
if (isVip) {
buyCourseForVip(userId, courseId);
} else {
buyCourse(userId, courseId);
}
// 保留标识参数的调用方式更加简洁
boolean isVip = false;
//...省略其他逻辑...
buyCourse(userId, courseId, isVip);
针对“根据参数是否为 null”来控制逻辑的情况,应该将其拆分成多个函数。拆分之后的函数职责更明确,不容易用错。
public List<Transaction> selectTransactions(Long userId, Date startDate, Date endDate) {
if (startDate != null && endDate != null) {
// 查询两个时间区间的transactions
}
if (startDate != null && endDate == null) {
// 查询startDate之后的所有transactions
}
if (startDate == null && endDate != null) {
// 查询endDate之前的所有transactions
}
if (startDate == null && endDate == null) {
// 查询所有的transactions
}
}
// 拆分成多个public函数,更加清晰、易用
public List<Transaction> selectTransactionsBetween(Long userId, Date startDate, Date endDate) {
return selectTransactions(userId, startDate, endDate);
}
public List<Transaction> selectTransactionsStartWith(Long userId, Date startDate) {
return selectTransactions(userId, startDate, null);
}
public List<Transaction> selectTransactionsEndWith(Long userId, Date endDate) {
return selectTransactions(userId, null, endDate);
}
public List<Transaction> selectAllTransactions(Long userId) {
return selectTransactions(userId, null, null);
}
private List<Transaction> selectTransactions(Long userId, Date startDate, Date endDate) {
// ...
}
4. 方法设计要职责单一
相对于类和模块,方法的粒度比较小,代码行数少,所以在应用单一职责原则的时候,没有像应用到类或者模块那样模棱两可,能多单一就多单一。
public boolean checkUserIfExisting(String telephone, String username, String email) {
if (!StringUtils.isBlank(telephone)) {
User user = userRepo.selectUserByTelephone(telephone);
return user != null;
}
if (!StringUtils.isBlank(username)) {
User user = userRepo.selectUserByUsername(username);
return user != null;
}
if (!StringUtils.isBlank(email)) {
User user = userRepo.selectUserByEmail(email);
return user != null;
}
return false;
}
// 拆分成三个函数
public boolean checkUserIfExistingByTelephone(String telephone);
public boolean checkUserIfExistingByUsername(String username);
public boolean checkUserIfExistingByEmail(String email);
5. 移除过深的嵌套层次
if-else、switch-case、for 循环过度嵌套导致的嵌套层次过深。我个人建议,嵌套最好不超过两层,超过两层之后就要思考一下是否可以减少嵌套。
去掉多余的 if 或 else 语句。
// 示例一
public double caculateTotalAmount(List<Order> orders) {
if (orders == null || orders.isEmpty()) {
return 0.0;
} else { // 此处的else可以去掉
double amount = 0.0;
for (Order order : orders) {
if (order != null) {
amount += (order.getCount() * order.getPrice());
}
}
return amount;
}
}
// 示例二
public List<String> matchStrings(List<String> strList,String substr) {
List<String> matchedStrings = new ArrayList<>();
if (strList != null && substr != null) {
for (String str : strList) {
if (str != null) { // 跟下面的if语句可以合并在一起
if (str.contains(substr)) {
matchedStrings.add(str);
}
}
}
}
return matchedStrings;
}
使用编程语言提供的 continue、break、return 关键字,提前退出嵌套。
// 重构前的代码
public List<String> matchStrings(List<String> strList,String substr) {
List<String> matchedStrings = new ArrayList<>();
if (strList != null && substr != null){
for (String str : strList) {
if (str != null && str.contains(substr)) {
matchedStrings.add(str);
// 此处还有10行代码...
}
}
}
return matchedStrings;
}
// 重构后的代码:使用continue提前退出
public List<String> matchStrings(List<String> strList,String substr) {
List<String> matchedStrings = new ArrayList<>();
if (strList != null && substr != null){
for (String str : strList) {
if (str == null || !str.contains(substr)) {
continue;
}
matchedStrings.add(str);
// 此处还有10行代码...
}
}
return matchedStrings;
}
调整执行顺序来减少嵌套。
// 重构前的代码
public List<String> matchStrings(List<String> strList,String substr) {
List<String> matchedStrings = new ArrayList<>();
if (strList != null && substr != null) {
for (String str : strList) {
if (str != null) {
if (str.contains(substr)) {
matchedStrings.add(str);
}
}
}
}
return matchedStrings;
}
// 重构后的代码:先执行判空逻辑,再执行正常逻辑
public List<String> matchStrings(List<String> strList,String substr) {
if (strList == null || substr == null) { //先判空
return Collections.emptyList();
}
List<String> matchedStrings = new ArrayList<>();
for (String str : strList) {
if (str != null) {
if (str.contains(substr)) {
matchedStrings.add(str);
}
}
}
return matchedStrings;
}
将部分嵌套逻辑封装成函数调用,以此来减少嵌套。
// 重构前的代码
public List<String> appendSalts(List<String> passwords) {
if (passwords == null || passwords.isEmpty()) {
return Collections.emptyList();
}
List<String> passwordsWithSalt = new ArrayList<>();
for (String password : passwords) {
if (password == null) {
continue;
}
if (password.length() < 8) {
// ...
} else {
// ...
}
}
return passwordsWithSalt;
}
// 重构后的代码:将部分逻辑抽成函数
public List<String> appendSalts(List<String> passwords) {
if (passwords == null || passwords.isEmpty()) {
return Collections.emptyList();
}
List<String> passwordsWithSalt = new ArrayList<>();
for (String password : passwords) {
if (password == null) {
continue;
}
passwordsWithSalt.add(appendSalt(password));
}
return passwordsWithSalt;
}
private String appendSalt(String password) {
String passwordWithSalt = password;
if (password.length() < 8) {
// ...
} else {
// ...
}
return passwordWithSalt;
}
6. 学会使用解释性变量
public double CalculateCircularArea(double radius) {
return (3.1415) * radius * radius;
}
// 常量替代魔法数字
public static final Double PI = 3.1415;
public double CalculateCircularArea(double radius) {
return PI * radius * radius;
}
if (date.after(SUMMER_START) && date.before(SUMMER_END)) {
// ...
} else {
// ...
}
// 引入解释性变量后逻辑更加清晰
boolean isSummer = date.after(SUMMER_START)&&date.before(SUMMER_END);
if (isSummer) {
// ...
} else {
// ...
}
如果没有知识点的全面积累,我们就无法构建出大的知识框架,更不知道知识的边界在哪里,也就无法形成系统的方法论。即便你能歪打误撞回答全面,也不会像现在这样对自己的答案如此自信和笃定。


打印日志的 Logger 对象被定义为 static final 的,并且在类内部创建,这是否影响到代码的可测试性?是否应该将 Logger 对象通过依赖注入的方式注入到类中呢?
依赖注入之所以能提高代码可测试性,主要是因为,通过这样的方式我们能轻松地用 mock 对象替换依赖的真实对象。那我们为什么要 mock 这个对象呢?这是因为,这个对象参与逻辑执行(比如,我们要依赖它输出的数据做后续的计算)但又不可控。对于 Logger 对象来说,我们只往里写入数据,并不读取数据,不参与业务逻辑的执行,不会影响代码逻辑的正确性,所以,我们没有必要 mock Logger 对象。
除此之外,一些只是为了存储数据的值对象,比如 String、Map、UseVo,我们也没必要通过依赖注入的方式来创建,直接在类中通过 new 创建就可以了。
运行时异常也叫作非受检异常,编译时异常也叫作受检异常。