论文地址:https://arxiv.org/abs/1706.03762
谷歌于2017年发布论文《Attention Is All You Need》,提出了一个只基于attention的结构来处理序列模型相关的问题,比如机器翻译。相比传统的CNN与RNN来作为encoder-decoder的模型,谷歌这个模型摒弃了固有的方式,并没有使用任何的CNN或者RNN的结构,该模型可以高度并行的工作,相比以前串行并且无法叠加多层、效率低的问题。那么Transorformer可以高度并行的工作,所以在提升翻译性能的同时训练速度也特别快。
目录
0x01 传统的RNN存在的问题
0x02 Encorder
(一)输入处理
(二)Self-Attention与Multi-Attention注意力机制
(三)Multi-Head机制
(四) 残差和Layer Normalization
0x03 Decoder

作用是在机器翻译中,可以使用此神经网络进行机器翻译,从而得到正确的输出,它的基本组成也是一个Seq2Seq的结构:

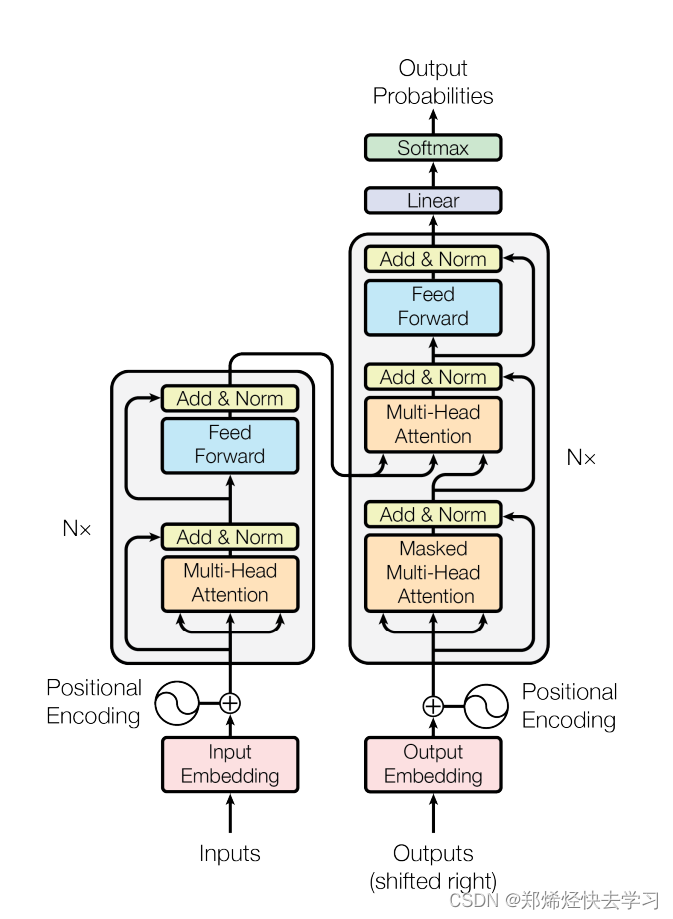
那么transformer的原理可以使用下图来进行表达:那么左边即为encorder,右边为decorder:
0x01 传统的RNN存在的问题
RNN也可以称为递归神经网络,RNN为一类以序列数据为输入,在序列的演进方向进行递归且所有节点按链式连接的递归神经网络。

那么它存在的问题有如下:
-
串行结构无法做复杂的神经网络,此结构时间复杂度高,有人会说可以把它扩展为一层或者两层神经网络,可是他的本质还是在做不断地堆叠,其效率很低,建起来也就那么几层。
-
对于输入我们称为token,我们把一句话分为好几个token之后进行处理。输入的词我们称为向量对于向量我们要进行更新,但是RNN中最大的问题就是这些向量是不会更新的,它不会随机应变。
-
RNN只会考虑上文,不会考虑下文,对于一句话来说,对于一段话的处理其实不是很理想,它不会去考虑下文的联系。
那么在NLP邻域中,RNN并不适合作为自然语言处理最好的方式,就像下面这个例子:

其中的it根据上下文可以解析为不同的意思。那么如何解决呢,在论文中引入了注意力机制这一概念。
0x02 Encorder
(一)输入处理
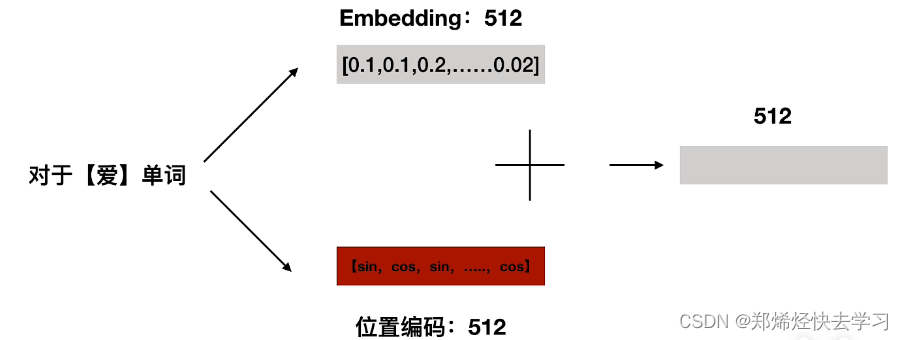
(1)Embedding
编码器和解码器的输入就是利用学习好的embedding将tokens转化为向量。常见的操作方法为word2vec。
(2)位置编码
对于普通的RNN,其输入的数据进行训练时,只使用了一套参数进行训练,RNN的梯度变为0,是因为它的梯度被近距离梯度主导,被远距离的梯度忽略。但是对于transorformer,其输入为并行化处理的,一句话一起处理的时候,我们需要注意其位置关系以及先后关系,这个时候就需要位置编码。
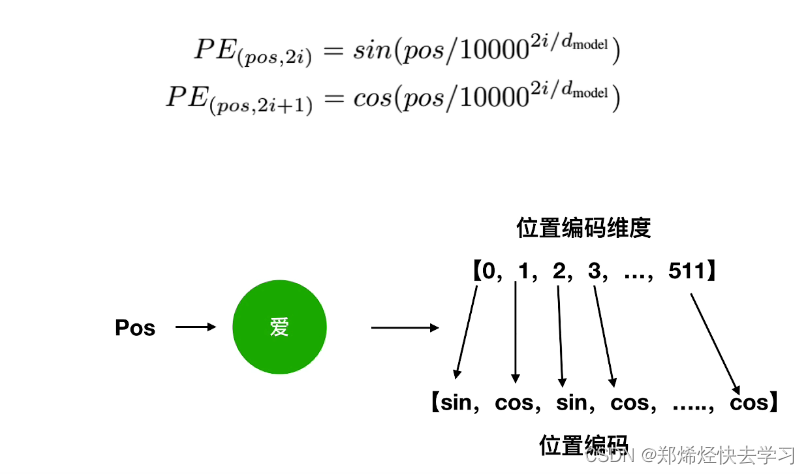
那么对于我们输入的词,它的处理是这样的:
那么使用cos以及sin进行位置嵌入会有用呢:
我们可以使用位置编码得到一个绝对位置,但是相对位置怎么办,利用三角函数的性质:

我们可以得到:

可以得到的是,对于pos+k位置的位置向量某一维2i或2i+1而言,可以表示为,pos位置与k位置的位置向量的2i和2i+1维的线性组合,这样的线性组合意味着位置向量中蕴含了相对位置信息。但是这种相对位置信息会在注意力机制那里消失。
(二)Self-Attention与Multi-Attention注意力机制
我们可以抛出两个问题:
对于输入的数据,我们的关注点在哪?如何才能让计算机关注到这些有用的信息?
如何使计算机区分不同的语境?
Attention用于计算“相关程度”,例如在翻译的过程中,不同的英文对中文的依赖程度不同,我们融入权重,代表上下文的影响,对文本进行重构。那么如何去计算:
-
输入经过编码后得到的向量。
-
想得到当前上下文之间的关系,通过下面的计算公式,可以理解为是在加权。
-
对于Queries这个向量,可以理解为是去询问别人,我们之间的关系怎么样。
-
相反,对于Key这个向量,我们可以理解为是去回答别人,我们之间的关系是这样的。
-
我们需要构建Queries、Key、Value这三个向量进行穿当前词与其他词的关系,表达我们的特征向量。
计算公式:
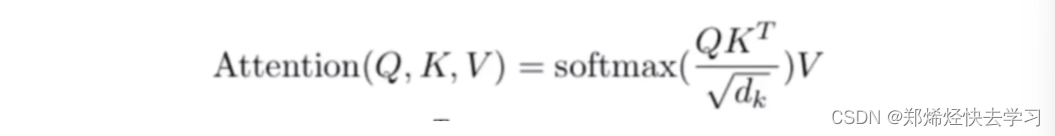

那么这个到底怎么运算的,简单来说就是根据我们输入的QK矩阵进行计算,下面的根号dk是为了避免维数不同而造成的差异,我们不可以因为一个图像它的维度多,我们就认为它是重要的,之后再进行归一化,生成0~1范围内的数,表示它的影响程度,最后再乘以V。
对于我们输入向量X1,我们会去逐个点乘包括自己的Key向量,反映了两个向量之间的相似度,如果点乘的结果越大表示向量的相似度越多,那我们就更加关注他:
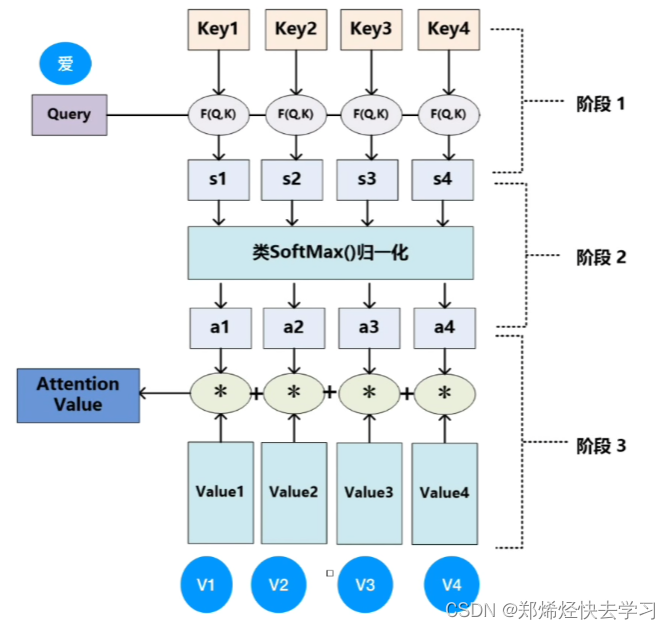
那么QKV向量如何获取呢:
在我们只有单词向量的情况下,获取的方式如下,我们需要三个权重参数Wq、Wk、Wv,这三个权重参数是通过我们神经网络进行训练出来的。X1 = Wq * q1、X2 = Wq * q2...

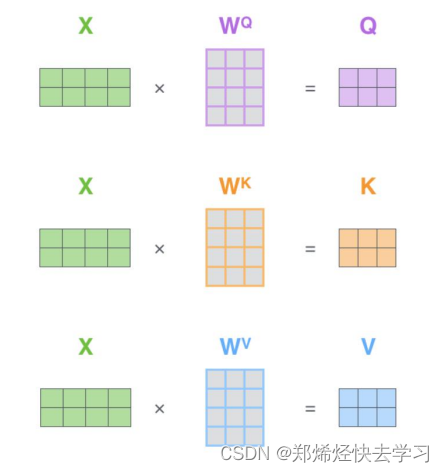
那么计算完后如何操作呢:
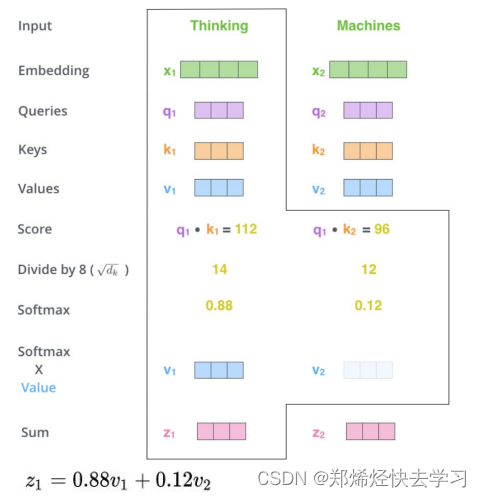
其实就是根据我们上面的公式进行计算,之后除以一个根号dk,dk作用为减小维度,我们不可以因为一副图像他维度大,我们就觉得它的特征大,它是对的。在实际的代码操作中,我们方便使用矩阵,方便并行:

(三)Multi-Head机制
多头注意力机制是什么,其实就是我们上面所说的一个字节的注意力机制,我们使用了很多套参数去进行训练,在不同的空间上进行学习,通过不同的head得到多个特征表达,最后将所有的特征拼接到一起,可以再通过一层全连接来进行降维。
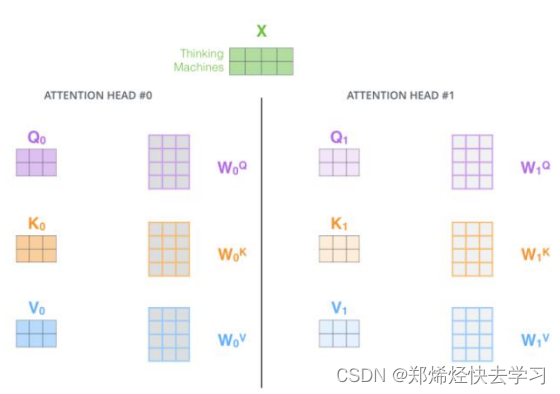
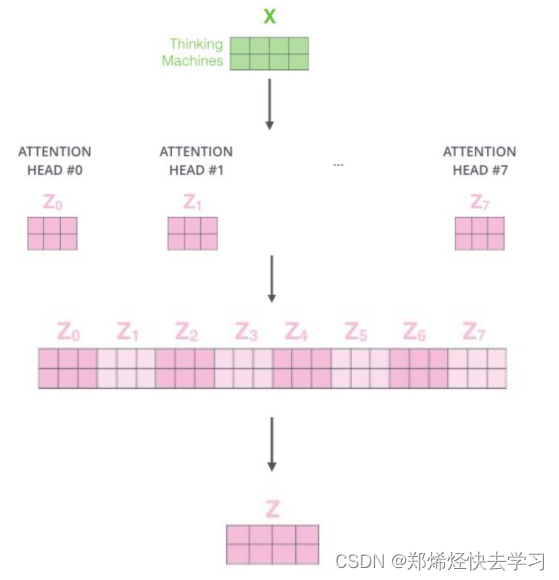
使用了多头注意力机制,可以让特征更加丰富,可以得到不同的注意力结果。

(四) 残差和Layer Normalization
首先看看transorformer的整体架构:
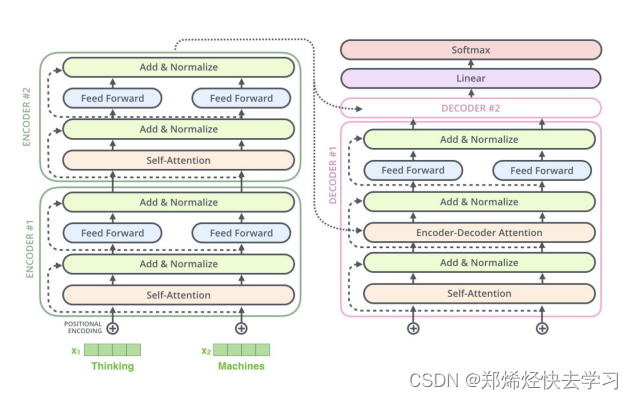
在上面,我们已经实现了Self-Attention,接下来看看Add与normalize(加速训练的作用):
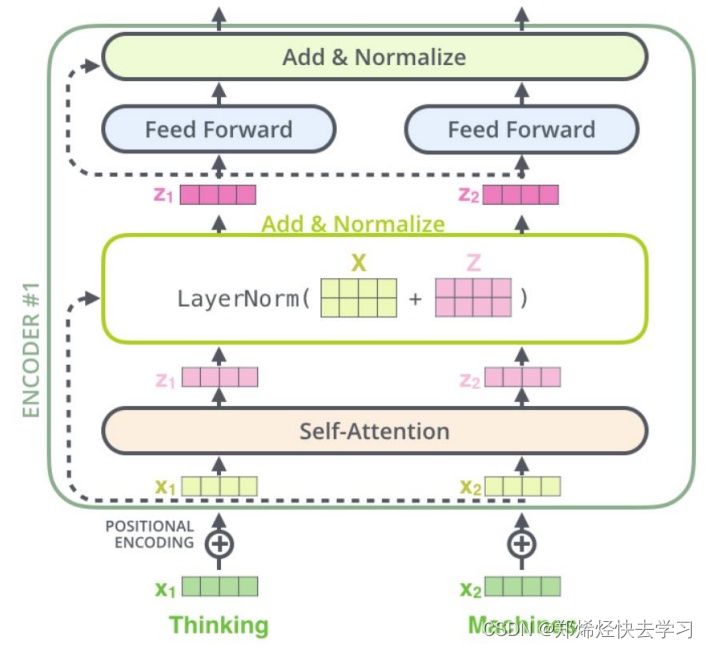
下面是指我们将输入的向量与其位置编码进行相加,一路送到Attention中进行计算,另外一路原封不动地送入残差连接:
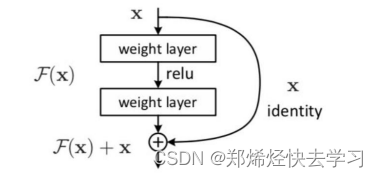
那么这样有什么作用?我们可以这么理解,我们要做两手准备,防止上一次处理的结果不理想,用一句话概括来说:至少不比原来差。
那么根据数学公式:
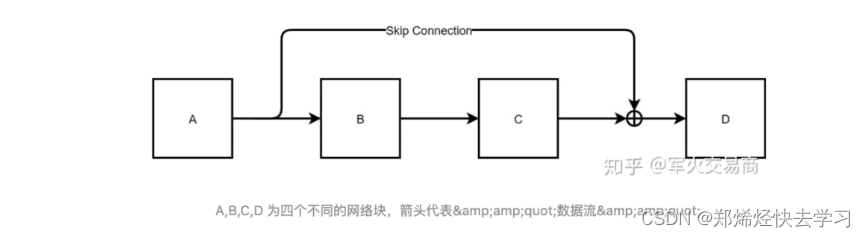
根据后向传播的链式法则:

很多时候梯度消失都是因为连乘所引起的,当我们加入原先的输入时,我们保证了尽管连乘最后导致的结果为0,但是我们还是有一个1,这个梯度不会为0。缓解了梯度消失的原因,所以这个网络结构才可以更加深层的进行。这也是为什么不使用RNN进行NLP的原因所在。
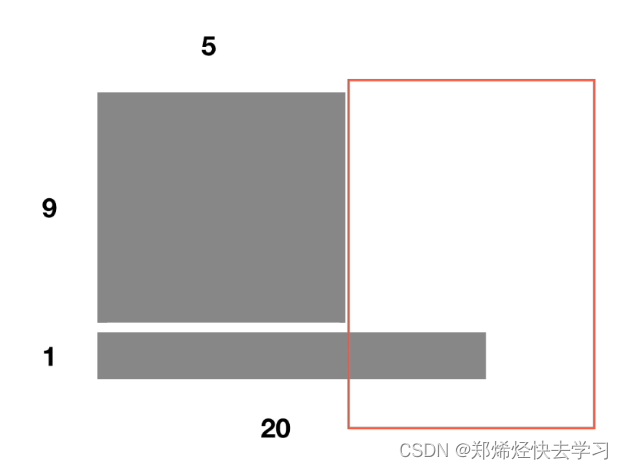
为什么使用Layer Normalization而不是用Batch Normalization:
-
BN中,如果batch_size较小的时候,效果差。
-
BN在RNN中的效果比较差。当向量维度不同时,我们不可以有效地将其做有效的处理。
-
LN单独对一个样本所有单词做缩放可以起到效果。以上的点也如下图
那么看看下面这张Normalize:
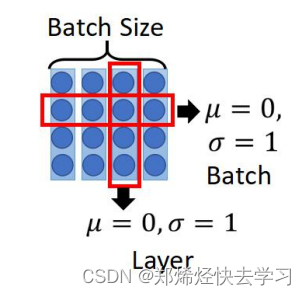
我们可以看到对于BN他是在不同输入中进行同一行的比较,可是我们每一句话所对应的意思肯定不一样,语境都不一样我们怎么去比对,我们只能看看自己本身,自己体验自己的语境。
0x03 Decoder
我们再看看详细的图:

那么他与decoder有什么不同呢,这么看起来好像都是差不多的处理:
那么关于Decoder的结构:
(1)第一个是Masked multi-head self-attention,也是计算输入的self-attention,但是因为是生成过程,因此在时刻i的时候,大于i的时刻都没有结果,只有小于i的时刻有结果,因此需要做Mask。
(2)第二个sub-layer是对encoder的输入进行attention的计算,这里仍然是multi-head的attention结构,只不过输入的分别是decoder的输出和encoder的输出。(交互层)

那么如何交互呢:
我们使用encoder生成了两个KV矩阵,注意,是KV矩阵。而Q矩阵在decoder中生成,最后行成多头注意力机制:
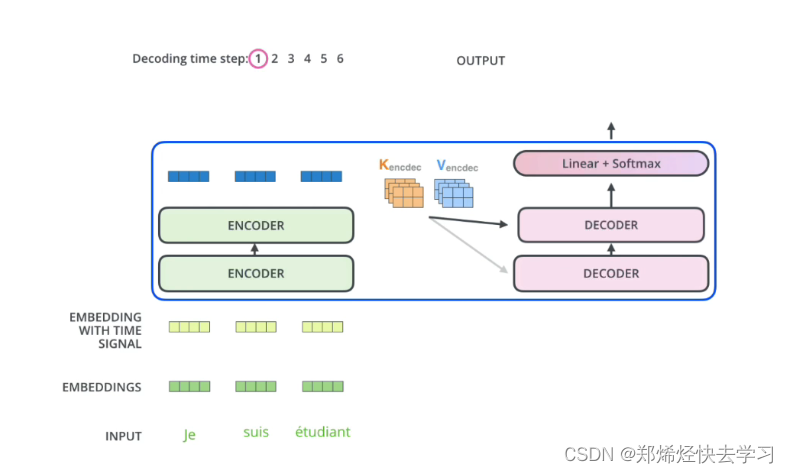
(3)第三个sub-layer是全连接网络,与encoder相同。最后进行模型的输出:
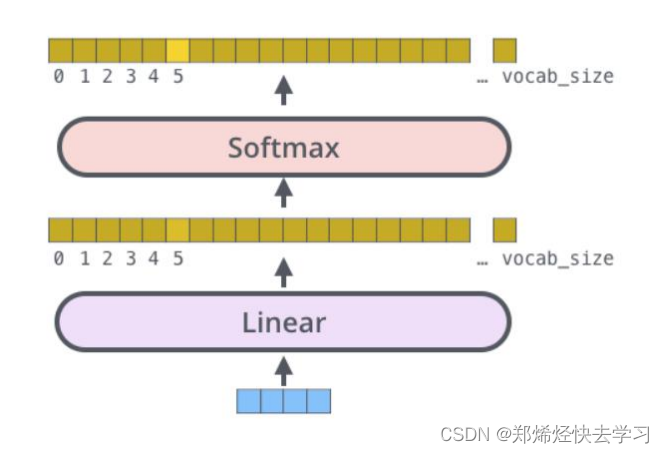
那么关于这篇的论文的分析到这里。