目前神经网络基本是业内无人不知了,在正式了解神经网络之前,有兴趣的爱好者可以了解一下神经网络出现前的一些发展历史。
实际上呢,每个聊神经网络的人,都会先放一张神经元的图片,我就偷懒算了吧,怕大家看吐了。1943年,心理学家W·Mcculloch和数理逻辑学家W·Pitts在分析、总结神经元基本特性的基础上首先提出神经元的数学模型。也就是M-P模型,恩,没有其他意思,用自己的名字命名一波,有问题吗?没问题。
MP模型
先上个自己画的丑图。

M-P模型的数学表达式为:

其中,f为阶跃激活函数, a为给定一个阈值:

在MP模型中w与b都是人为给定,故该模型不能学习。
感知机
单层感知机
但从结构上来看,感知机与MP模型没有任何区别。参考上面的图就OK了。
那么,区别在哪儿呢,最大的区别在于感知机是可以训练的,当然这个训练与现在的神经网络训练不一样,因为那个时候还没有反向传播算法(BP)。先讲一下怎么训练吧。
首先,随机初始化权重向量 w,然后反复对每一个样本进行训练,然后修改权值:

其中:

上面,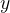 为输出值,
为输出值, 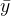 为真实值,
为真实值,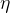 为学习率。
为学习率。
直观的来说,就是通过不停的更新参数来找到一个超平面,完美的分割当前样本。
当样本非线性可分时,问题就来了,这个训练永远都停不下来了。也就说单层感知机解决不了经典的异或问题。
另一种训练方法是Delta学习,后来称为最小二乘方法。
多层感知机 -- 前馈神经网络
首先,我们要明确的是,多层感知机不是单层感知机的简单堆叠。因为无论多少单层感知机堆叠,还是在线性变换的范围里面操作。术语是仿射变换。我的理解是,从公式来看就是多了一些括号的嵌套使得矩阵相乘。如果想要处理非线性问题,则需要在两个简单的感知机中间增加一个非线性的激活函数。(这里呢,有点小问题,非线性的激活函数,也可以处理异或问题,只不过难以进行反向传播训练)
另一个问题是感知机只能进行单层训练,隐含层如何训练与学习是一个大问题。(以下这段抄自百度百科)对此问题的研究有三个基本的结果。一种是使用简单无监督学习规则的竞争学习方法.但它缺乏外部信息.难以确定适合映射的隐层结构。第二条途径是假设一个内部(隐层)的表示方法,这在一些先约条件下是台理的。另一种方法是利用统计手段设计一个学习过程使之能有效地实现适当的内部表示法,Hinton等人(1984年)提出的Bolzmann机是这种方法的典型例子.它要求网络在两个不同的状态下达到平衡,并且只局限于对称网络。Barto和他的同事(1985年)提出了另一条利用统计手段的学习方法。但迄今为止最有效和最实用的方法是Rumelhart、Hinton和Williams(1986年)提出的一般Delta法则,即反向传播(BP)算法。Parter(1985年)也独立地得出过相似的算法,他称之为学习逻辑。此外, Lecun(1985年)也研究出大致相似的学习法则。(bp --yyds)
先上个自己画的丑图:

上图中,我把求和与激活函数画出来了,方便更加直观的学习。
这个网络已经基本接近神经网络了,实际上也就是神经网络中的全连接。整个训练过程就是三个步骤:
- 初始化权重参数,输入数据前向传播
- 计算损失,反向传播
- 根据学习率,更新权重参数
接下来是代码。待补充。
有问题麻烦指正,光速改。