为什么要用分桶表?
单个分区或者表中的数据量越来越大,当分区不能更细粒的划分数据时,所以会采用分桶技术将数据更细粒度的划分和管理
分区提供了一个隔离数据和优化查询的便利的方式.但是当分区的数量过多时,会产生过多的小分区,这样会给namenode带来较大的压力.分桶是将数据集分解成更容易管理的若干部分的另一个技术.
分桶的意义:
1、为了保存分桶查询结果的分桶结构(数据已经按照分桶字段进行了hash散列)
2、分桶表数据进行抽样和JOIN时可以提高MR程序效率
分桶技术:
[CLUSTERED BY (col_name, col_name, …) [SORTED BY (col_name
[ASC|DESC], …)] INTO num_buckets BUCKETS]
关键字:BUCKET
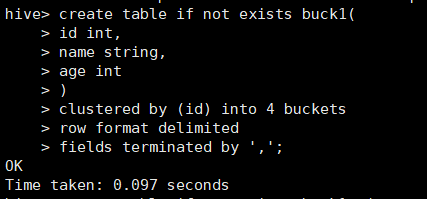
创建一张分桶表
create table if not exists buck1(
id int,
name string,
age int
)
clustered by (id) into 4 buckets
row format delimited
fields terminated by ','
;
创建成功
在我们导入数据前,需要将hive.enforce.bucketing的值设置为true,
这个参数将强制控制ruduce的个数去和我们指定的分桶个数相适配.
set hive.enforce.bucketing = true;
如果我们直接load数据到我们的分桶表是创建不出来的,是假的分桶
正确导入数据的方式
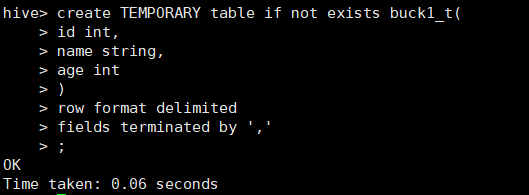
我们要先创建一张临时表(表的字段都一样,不要是分桶)将数据导入临时表,从临时表中导入数据到分桶表
create TEMPORARY table if not exists buck1_t(
id int,
name string,
age int
)
row format delimited
fields terminated by ','
;
创建临时表成功
将数据导入临时表

加载数据
load data local inpath '/opt/bbb' into table buck1_t;
加载成功

将临时表的数据导入分桶表中
insert into table buck1
select * from buck1_t
cluster by id;
查看web界面分桶成功

我们可以看到,我们的客户数据被分成了四份.那么这四份是如何进行划分的呢?其实我们已经制定了按照id进行划分,因此hive使用hash散列的方式,将id个数对桶个数求余数,我们id为12个,对桶个数(4个)求余数,结果为3.这样每个桶最少有4条数据,同时这样的方式得到的桶内数据其实相当于是随机的.
我们再次执行select查询时,会发现数据是按照分桶显示的

cluster by和distribute by

在上面的select语句中,我们使用了cluster by语句执行分桶的方式.我们发现其实桶内的数据是按照id字段进行升序排列的.其实cluster by相当于distribute by+sort by.sort by默认按照升序进行排列.distribute by+sort by的组合会更加的灵活,因此我们可以去按照id分桶,按照age去进行排序.我们可以做如下的试验.
清空分桶表中数据 重新写入
truncate table buck1;
按照id分桶,按照age降序排序 ,age为表中字段 desc可以换成asc代表升序
insert into table buck1
select * from buck1_t
distribute by id
sort by age desc;
排序成功!id无序,age有序

对分桶表的查询 :
查询所有
select * from buck1 tablesample(bucket 1 out of 1 on id)
查询第1个桶的数据
select * from buck1 tablesample(bucket 1 out of 4 on id);

那个1可以为1-4,为几就是第几桶开始,查询1桶
分桶查询公式:
select * from t_bucket tablesample(bucket x out of y on xx);
x表示从哪个bucket进行抽样,桶计数从1开始.y用来计算抽取数据的量,计算方式为分桶数/y.假设我们一共分了128个桶,y设置为32,则表示要抽取4个bucket,如果x为12,则抽取的数据来自于12/13/14/15.y的值可以不为桶个数的公约数,可以为任意值.
分桶的好处
1.分桶加快了join查询的速度.
对于map端连接的情况,两个表以相同方式划分桶。处理左边表内某个桶的 mapper知道右边表内相匹配的行在对应的桶内。因此,mapper只需要获取那个桶 (这只是右边表内存储数据的一小部分)即可进行连接。这一优化方法并不一定要求 两个表必须桶的个数相同,两个表的桶个数是倍数关系也可以.这样便采用了Map-side join的方式,避免全表进行笛卡尔积的操作.
关于桶内排序的意义:
桶中的数据可以根据一个或多个列另外进行排序。由于这样对每个桶的连接变成了高效的归并排序(merge-sort), 因此可以进一步提升map端连接的效率。
分桶个数:
如果两个表的分桶个数之间没有什么倍数的关系,这样分桶表在做join时并不会提升效率,因为数据随机分发,桶和桶之间并没有对应关系.
2.使取样(sampling)更加的高效
在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便.
使用上面的 buck1_t我们进行演示.
假如我们使用的为一个大规模的数据集,我们只想去抽取部分数据进行查看.使用bucket表可以变得更加的高效