不管是大型虚拟化云网络,还是嵌入式物联网系统,Linux网络都扮演着重要的角色。借用一句话说,如果说网络是信息系统的基石,那么Linux网络系统就是基石中的钢筋。它经过几十年的发展,它千锤百炼,几乎包含了市面上所有的网络通讯功能,要想一下子把学透是不容易的,只能顺着代码脉络看着前辈们写的文章,边分析边总结吧。先来看一下整体结构:

1. 网络基本结构
Linux网络基本结构我把它分成几个层次,每个层次只是一个逻辑上的概念,并没有严格的定义,只是为了理解上的方便,而且很多模块的代码都是交织混用的,要统一来划分也不容易的。况且,通讯技术不断向前发展,今天定义出一套框架,明天说不定就有新的技术颠覆了,所以只能顺着源码路径,大致的分块来分析。
网络框架
Linux网络框架在我看来是一个特别扭曲的部分,一方面要兼容Linux中“一切皆是文件”的概念,另一方面又引入套接字的逻辑,后来又为虚拟化设计了名字空间,及虚拟网桥等模块,总的来看就像一大杂烩,给用户提供各种复杂的功能。大体上,Linux按协议族来管理各种网络,不同的协议族决定了不同的网络地址类型。而框架部分就是把各种协议族都有机的融合起来,使其能统一在套接字接口下来使用。
网络协议
Linux实现了大部分的网络协议,框架代码按协议族(protocol family)的方式来管理,各种协议族又实现了各自许多协议,常见的协议族有IPv4、IPv6、Bluetooth等,而我们常说的TCP/UDP是在IPv4或IPv6协议族下面实现的。
设备框架
软件总要靠硬件来承载运行,网络程序更是要依赖各式各样的网络适配器来通讯。Linux定义了一套完备的设备模型承上启下,上承内核完成协议通讯,下启设备收发数据。
设备驱动
网卡要在Linux中正确的运行,就要实现设备框架下的各种接口。所幸内核中包含了大量的网卡驱动,一个新的设备要加入进来,很容易从相似的驱动中找到参考代码。
外设接口
每种网卡总依赖某种外设接口来和CPU通讯,比如PCI、USB等。这类接口同样需要驱动,但Linux都实现的大部分(即使不是全部)外设接口,使用起来特别方便。
2. socket的内核对象
我们的程序要用socket来使用各种网络功能,但可能很少人知道socket的内核层对象究竟是怎么样工作的。下面我们来看一下socket在内核层中更详细的信息,先看一下socket函数原型 int socket(int domain, int type, int protocol); 此函数创建一个socket对象并初始化,通常是第一个调用的网络函数。 成功时,返回非负数的socket描述符;失败是返回-1。socket描述符其实等于一个文件描述符,调用socket()函数时,内核将创建立一个socket对象,然后把它映射为一个文件描述符返回用户空间,以体现“一切皆是文件”的思想,实际上一个socket意味着为一个socket数据结构所管理的对象和所分配的存储空间。
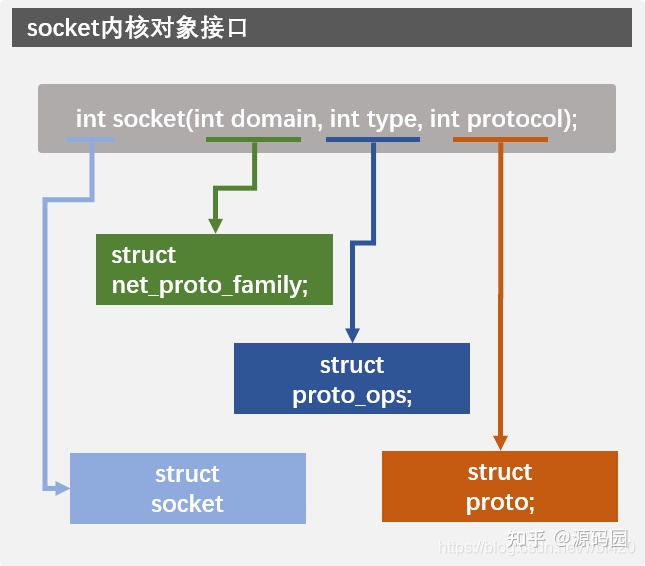
socket函数的三个参数已经包含了在内核实现中具体的功能信息,每一个参数在内核中都有一个对应的结构体与之联系,就算扩展新的网络协议,只需实现新的实例即可。所以了解一下socket对应的对象对扩展新的或理解现有网络类型很有帮组。
domain
指明socket使用的协议族,常用的协议族有,AF_INET、AF_INET6、AF_LOCAL(或称AF_UNIX,Unix域socket)、AF_ROUTE等等。协议族决定了socket的地址类型,在通信中必须采用对应的地址,在内核中每一种协议族用一个struct net_proto_family对象与之对应,各种协议族实现各自的create接口,用以创建不同的socket。比如inet_family_ops的inet_create函数就是实现创建IPv4的socket的函数。
type
指定socket的类型,在IPv4中,SOCK_STREAM表示使用TCP的socket;SOCK_DGRAM表示UDP的socket;SOCK_RAW表示原始的socket,可以使用IP或ICMP数据包直接操作。在socket类型中,内核用struct proto_ops对象来代表它,比如inet_dgram_ops的inet_sendmsg函数就是实现sendmsg接口的。
protocol
这个参数当然就是指具体的协议了,调用的时候可以赋值0让系统自动选择,也可以特别的指定它,比如,17就的代表UDP协议。要看Linux支持多少种协议,可以调用系统API函数getprotoent()获得列表信息。内核中,具体的协议就是要实现struct proto定义的各种接口,比如UDP协议的udp_sendmsg函数就实现了发送UDP数据包的功能。
3.发送数据包基本流程
一个数据包从应用程序发出到网卡出去要经历什么样的旅程呢?从宏观一点的角度来看有利于我们理解Linux内核的各种子模块的层次结构。现在,我们用UDP来做一个简单的流程分析:
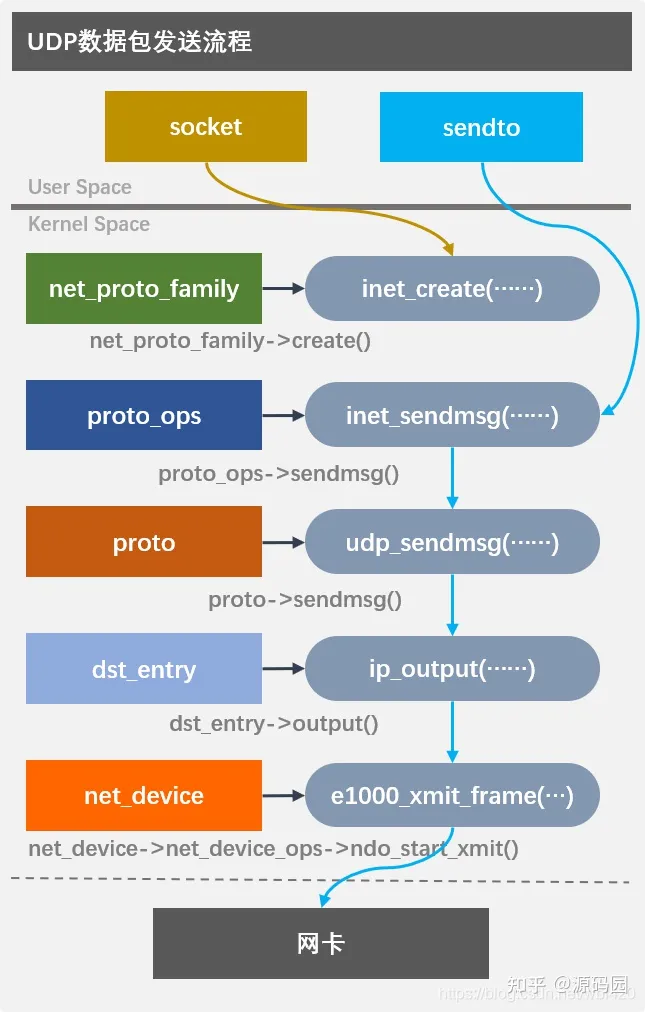
创建socket
socket是内核统一对外的网络描述符,使用之前必须先创建它,内核中每个协议族都有自己的实现方式,inet_create函数就是IPv4创建socket的方法
//net/ipv4/af_inet.c
static int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct inet_sock *inet;
struct proto *answer_prot;
unsigned char answer_flags;
int try_loading_module = 0;
int err;
if (protocol < 0 || protocol >= IPPROTO_MAX)
return -EINVAL;
sock->state = SS_UNCONNECTED;
/* Look for the requested type/protocol pair. */
lookup_protocol:
err = -ESOCKTNOSUPPORT;
rcu_read_lock();
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
err = 0;
/* Check the non-wild match. */
if (protocol == answer->protocol) {
if (protocol != IPPROTO_IP)
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
}
err = -EPROTONOSUPPORT;
}
if (unlikely(err)) {
if (try_loading_module < 2) {
rcu_read_unlock();
/*
* Be more specific, e.g. net-pf-2-proto-132-type-1
* (net-pf-PF_INET-proto-IPPROTO_SCTP-type-SOCK_STREAM)
*/
if (++try_loading_module == 1)
request_module("net-pf-%d-proto-%d-type-%d",
PF_INET, protocol, sock->type);
/*
* Fall back to generic, e.g. net-pf-2-proto-132
* (net-pf-PF_INET-proto-IPPROTO_SCTP)
*/
else
request_module("net-pf-%d-proto-%d",
PF_INET, protocol);
goto lookup_protocol;
} else
goto out_rcu_unlock;
}
err = -EPERM;
if (sock->type == SOCK_RAW && !kern &&
!ns_capable(net->user_ns, CAP_NET_RAW))
goto out_rcu_unlock;
sock->ops = answer->ops;
answer_prot = answer->prot;
answer_flags = answer->flags;
rcu_read_unlock();
WARN_ON(!answer_prot->slab);
err = -ENOBUFS;
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);
if (!sk)
goto out;
err = 0;
if (INET_PROTOSW_REUSE & answer_flags)
sk->sk_reuse = SK_CAN_REUSE;
inet = inet_sk(sk);
inet->is_icsk = (INET_PROTOSW_ICSK & answer_flags) != 0;
inet->nodefrag = 0;
if (SOCK_RAW == sock->type) {
inet->inet_num = protocol;
if (IPPROTO_RAW == protocol)
inet->hdrincl = 1;
}
if (net->ipv4.sysctl_ip_no_pmtu_disc)
inet->pmtudisc = IP_PMTUDISC_DONT;
else
inet->pmtudisc = IP_PMTUDISC_WANT;
inet->inet_id = 0;
sock_init_data(sock, sk);
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv;
inet->uc_ttl = -1;
inet->mc_loop = 1;
inet->mc_ttl = 1;
inet->mc_all = 1;
inet->mc_index = 0;
inet->mc_list = NULL;
inet->rcv_tos = 0;
sk_refcnt_debug_inc(sk);
if (inet->inet_num) {
/* It assumes that any protocol which allows
* the user to assign a number at socket
* creation time automatically
* shares.
*/
inet->inet_sport = htons(inet->inet_num);
/* Add to protocol hash chains. */
err = sk->sk_prot->hash(sk);
if (err) {
sk_common_release(sk);
goto out;
}
}
if (sk->sk_prot->init) {
err = sk->sk_prot->init(sk);
if (err) {
sk_common_release(sk);
goto out;
}
}
if (!kern) {
err = BPF_CGROUP_RUN_PROG_INET_SOCK(sk);
if (err) {
sk_common_release(sk);
goto out;
}
}
out:
return err;
out_rcu_unlock:
rcu_read_unlock();
goto out;
}
发送数据包
inet_sendmsg是IPv4协议族中送数据包的入口,不管是stream包,还是packet包都是由这个函数处理,但它里面并没做什么实事,只是根据socket具体绑定的协议调用tcp_sendmsg或udp_sendmsg函数。
//net/ipv4/af_inet.c
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
if (unlikely(inet_send_prepare(sk)))
return -EAGAIN;
return INDIRECT_CALL_2(sk->sk_prot->sendmsg, tcp_sendmsg, udp_sendmsg,
sk, msg, size);
}
EXPORT_SYMBOL(inet_sendmsg);
UDP组包
UDP协议位于传输层,应该是内核实现的最高层的协议了,再往上面,比如RTP,SIP等就不再在内核中实现,而由应用程序负责了。udp_sendmsg首先调用ip_route_output_flow确定路由对象;然后调用ip_make_skb函数分配sk_buff用于定位内存保存数据,关于数据包的所有信息都保存在sk_buff中,这是协议层和设备层通讯的关键数据结构;最后调用udp_send_skb把数据包发送出去。
//net/ipv4/udp.c
int udp_sendmsg(struct sock *sk, struct msghdr *msg, size_t len)
{
struct inet_sock *inet = inet_sk(sk);
struct udp_sock *up = udp_sk(sk);
DECLARE_SOCKADDR(struct sockaddr_in *, usin, msg->msg_name);
struct flowi4 fl4_stack;
struct flowi4 *fl4;
int ulen = len;
struct ipcm_cookie ipc;
struct rtable *rt = NULL;
int free = 0;
int connected = 0;
__be32 daddr, faddr, saddr;
__be16 dport;
u8 tos;
int err, is_udplite = IS_UDPLITE(sk);
int corkreq = up->corkflag || msg->msg_flags&MSG_MORE;
int (*getfrag)(void *, char *, int, int, int, struct sk_buff *);
struct sk_buff *skb;
struct ip_options_data opt_copy;
if (len > 0xFFFF)
return -EMSGSIZE;
/*
* Check the flags.
*/
if (msg->msg_flags & MSG_OOB) /* Mirror BSD error message compatibility */
return -EOPNOTSUPP;
getfrag = is_udplite ? udplite_getfrag : ip_generic_getfrag;
fl4 = &inet->cork.fl.u.ip4;
if (up->pending) {
/*
* There are pending frames.
* The socket lock must be held while it's corked.
*/
lock_sock(sk);
if (likely(up->pending)) {
if (unlikely(up->pending != AF_INET)) {
release_sock(sk);
return -EINVAL;
}
goto do_append_data;
}
release_sock(sk);
}
ulen += sizeof(struct udphdr);
/*
* Get and verify the address.
*/
if (usin) {
if (msg->msg_namelen < sizeof(*usin))
return -EINVAL;
if (usin->sin_family != AF_INET) {
if (usin->sin_family != AF_UNSPEC)
return -EAFNOSUPPORT;
}
daddr = usin->sin_addr.s_addr;
dport = usin->sin_port;
if (dport == 0)
return -EINVAL;
} else {
if (sk->sk_state != TCP_ESTABLISHED)
return -EDESTADDRREQ;
daddr = inet->inet_daddr;
dport = inet->inet_dport;
/* Open fast path for connected socket.
Route will not be used, if at least one option is set.
*/
connected = 1;
}
ipcm_init_sk(&ipc, inet);
ipc.gso_size = up->gso_size;
if (msg->msg_controllen) {
err = udp_cmsg_send(sk, msg, &ipc.gso_size);
if (err > 0)
err = ip_cmsg_send(sk, msg, &ipc,
sk->sk_family == AF_INET6);
if (unlikely(err < 0)) {
kfree(ipc.opt);
return err;
}
if (ipc.opt)
free = 1;
connected = 0;
}
if (!ipc.opt) {
struct ip_options_rcu *inet_opt;
rcu_read_lock();
inet_opt = rcu_dereference(inet->inet_opt);
if (inet_opt) {
memcpy(&opt_copy, inet_opt,
sizeof(*inet_opt) + inet_opt->opt.optlen);
ipc.opt = &opt_copy.opt;
}
rcu_read_unlock();
}
if (cgroup_bpf_enabled && !connected) {
err = BPF_CGROUP_RUN_PROG_UDP4_SENDMSG_LOCK(sk,
(struct sockaddr *)usin, &ipc.addr);
if (err)
goto out_free;
if (usin) {
if (usin->sin_port == 0) {
/* BPF program set invalid port. Reject it. */
err = -EINVAL;
goto out_free;
}
daddr = usin->sin_addr.s_addr;
dport = usin->sin_port;
}
}
saddr = ipc.addr;
ipc.addr = faddr = daddr;
if (ipc.opt && ipc.opt->opt.srr) {
if (!daddr) {
err = -EINVAL;
goto out_free;
}
faddr = ipc.opt->opt.faddr;
connected = 0;
}
tos = get_rttos(&ipc, inet);
if (sock_flag(sk, SOCK_LOCALROUTE) ||
(msg->msg_flags & MSG_DONTROUTE) ||
(ipc.opt && ipc.opt->opt.is_strictroute)) {
tos |= RTO_ONLINK;
connected = 0;
}
if (ipv4_is_multicast(daddr)) {
if (!ipc.oif || netif_index_is_l3_master(sock_net(sk), ipc.oif))
ipc.oif = inet->mc_index;
if (!saddr)
saddr = inet->mc_addr;
connected = 0;
} else if (!ipc.oif) {
ipc.oif = inet->uc_index;
} else if (ipv4_is_lbcast(daddr) && inet->uc_index) {
/* oif is set, packet is to local broadcast and
* and uc_index is set. oif is most likely set
* by sk_bound_dev_if. If uc_index != oif check if the
* oif is an L3 master and uc_index is an L3 slave.
* If so, we want to allow the send using the uc_index.
*/
if (ipc.oif != inet->uc_index &&
ipc.oif == l3mdev_master_ifindex_by_index(sock_net(sk),
inet->uc_index)) {
ipc.oif = inet->uc_index;
}
}
if (connected)
rt = (struct rtable *)sk_dst_check(sk, 0);
if (!rt) {
struct net *net = sock_net(sk);
__u8 flow_flags = inet_sk_flowi_flags(sk);
fl4 = &fl4_stack;
flowi4_init_output(fl4, ipc.oif, ipc.sockc.mark, tos,
RT_SCOPE_UNIVERSE, sk->sk_protocol,
flow_flags,
faddr, saddr, dport, inet->inet_sport,
sk->sk_uid);
security_sk_classify_flow(sk, flowi4_to_flowi(fl4));
rt = ip_route_output_flow(net, fl4, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
rt = NULL;
if (err == -ENETUNREACH)
IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES);
goto out;
}
err = -EACCES;
if ((rt->rt_flags & RTCF_BROADCAST) &&
!sock_flag(sk, SOCK_BROADCAST))
goto out;
if (connected)
sk_dst_set(sk, dst_clone(&rt->dst));
}
if (msg->msg_flags&MSG_CONFIRM)
goto do_confirm;
back_from_confirm:
saddr = fl4->saddr;
if (!ipc.addr)
daddr = ipc.addr = fl4->daddr;
/* Lockless fast path for the non-corking case. */
if (!corkreq) {
struct inet_cork cork;
skb = ip_make_skb(sk, fl4, getfrag, msg, ulen,
sizeof(struct udphdr), &ipc, &rt,
&cork, msg->msg_flags);
err = PTR_ERR(skb);
if (!IS_ERR_OR_NULL(skb))
err = udp_send_skb(skb, fl4, &cork);
goto out;
}
lock_sock(sk);
if (unlikely(up->pending)) {
/* The socket is already corked while preparing it. */
/* ... which is an evident application bug. --ANK */
release_sock(sk);
net_dbg_ratelimited("socket already corked\n");
err = -EINVAL;
goto out;
}
/*
* Now cork the socket to pend data.
*/
fl4 = &inet->cork.fl.u.ip4;
fl4->daddr = daddr;
fl4->saddr = saddr;
fl4->fl4_dport = dport;
fl4->fl4_sport = inet->inet_sport;
up->pending = AF_INET;
do_append_data:
up->len += ulen;
err = ip_append_data(sk, fl4, getfrag, msg, ulen,
sizeof(struct udphdr), &ipc, &rt,
corkreq ? msg->msg_flags|MSG_MORE : msg->msg_flags);
if (err)
udp_flush_pending_frames(sk);
else if (!corkreq)
err = udp_push_pending_frames(sk);
else if (unlikely(skb_queue_empty(&sk->sk_write_queue)))
up->pending = 0;
release_sock(sk);
out:
ip_rt_put(rt);
out_free:
if (free)
kfree(ipc.opt);
if (!err)
return len;
/*
* ENOBUFS = no kernel mem, SOCK_NOSPACE = no sndbuf space. Reporting
* ENOBUFS might not be good (it's not tunable per se), but otherwise
* we don't have a good statistic (IpOutDiscards but it can be too many
* things). We could add another new stat but at least for now that
* seems like overkill.
*/
if (err == -ENOBUFS || test_bit(SOCK_NOSPACE, &sk->sk_socket->flags)) {
UDP_INC_STATS(sock_net(sk),
UDP_MIB_SNDBUFERRORS, is_udplite);
}
return err;
do_confirm:
if (msg->msg_flags & MSG_PROBE)
dst_confirm_neigh(&rt->dst, &fl4->daddr);
if (!(msg->msg_flags&MSG_PROBE) || len)
goto back_from_confirm;
err = 0;
goto out;
}
EXPORT_SYMBOL(udp_sendmsg);
路由选择
当然,发送数据并没有想象的那么简单,里面涉及到的路由项就有非常复杂的逻辑,这个之后再说,总之发送是由绑定在dst_entry中的output接口负责,一个dst_entry对象代表一个路由表项。单纯的UDP发送就是把它绑定为ip_output函数发往对端的路由项。ip_output中有一个HOOK,这个是网络的一个钩子,这里没有设置,所以直接调用ip_finish_output把数据包发出去。
//net/ipv4/ip_output.c
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev, *indev = skb->dev;
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUT, skb->len);
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, indev, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
设备接口
IP数据包准备好后,调用网络设备框架发送出去。由于各种网络有各种规则,一句两句也说不清楚,单单设备框架的代码就有一万多行(net/core/dev.c),有兴趣细读的朋友可以详细的分析一下。框架代码是比较完善的,但最终的功能还是要由设备驱动来实现,net_device的net_device_ops封装了网络设备的各种接口,驱动代码必须实现其中的某些接口,比如ndo_start_xmit就是发送数据的关键接口,几乎每个网卡驱动都要实现它。Intel的e1000网卡的驱动代码在drivers/net/ethernet/intel/e1000中可以找到。
//drivers/net/ethernet/intel/e1000/e1000_main.c
static netdev_tx_t e1000_xmit_frame(struct sk_buff *skb,
struct net_device *netdev)
{
struct e1000_adapter *adapter = netdev_priv(netdev);
struct e1000_hw *hw = &adapter->hw;
struct e1000_tx_ring *tx_ring;
unsigned int first, max_per_txd = E1000_MAX_DATA_PER_TXD;
unsigned int max_txd_pwr = E1000_MAX_TXD_PWR;
unsigned int tx_flags = 0;
unsigned int len = skb_headlen(skb);
unsigned int nr_frags;
unsigned int mss;
int count = 0;
int tso;
unsigned int f;
__be16 protocol = vlan_get_protocol(skb);
/* This goes back to the question of how to logically map a Tx queue
* to a flow. Right now, performance is impacted slightly negatively
* if using multiple Tx queues. If the stack breaks away from a
* single qdisc implementation, we can look at this again.
*/
tx_ring = adapter->tx_ring;
/* On PCI/PCI-X HW, if packet size is less than ETH_ZLEN,
* packets may get corrupted during padding by HW.
* To WA this issue, pad all small packets manually.
*/
if (eth_skb_pad(skb))
return NETDEV_TX_OK;
mss = skb_shinfo(skb)->gso_size;
/* The controller does a simple calculation to
* make sure there is enough room in the FIFO before
* initiating the DMA for each buffer. The calc is:
* 4 = ceil(buffer len/mss). To make sure we don't
* overrun the FIFO, adjust the max buffer len if mss
* drops.
*/
if (mss) {
u8 hdr_len;
max_per_txd = min(mss << 2, max_per_txd);
max_txd_pwr = fls(max_per_txd) - 1;
hdr_len = skb_transport_offset(skb) + tcp_hdrlen(skb);
if (skb->data_len && hdr_len == len) {
switch (hw->mac_type) {
unsigned int pull_size;
case e1000_82544:
/* Make sure we have room to chop off 4 bytes,
* and that the end alignment will work out to
* this hardware's requirements
* NOTE: this is a TSO only workaround
* if end byte alignment not correct move us
* into the next dword
*/
if ((unsigned long)(skb_tail_pointer(skb) - 1)
& 4)
break;
/* fall through */
pull_size = min((unsigned int)4, skb->data_len);
if (!__pskb_pull_tail(skb, pull_size)) {
e_err(drv, "__pskb_pull_tail "
"failed.\n");
dev_kfree_skb_any(skb);
return NETDEV_TX_OK;
}
len = skb_headlen(skb);
break;
default:
/* do nothing */
break;
}
}
}
/* reserve a descriptor for the offload context */
if ((mss) || (skb->ip_summed == CHECKSUM_PARTIAL))
count++;
count++;
/* Controller Erratum workaround */
if (!skb->data_len && tx_ring->last_tx_tso && !skb_is_gso(skb))
count++;
count += TXD_USE_COUNT(len, max_txd_pwr);
if (adapter->pcix_82544)
count++;
/* work-around for errata 10 and it applies to all controllers
* in PCI-X mode, so add one more descriptor to the count
*/
if (unlikely((hw->bus_type == e1000_bus_type_pcix) &&
(len > 2015)))
count++;
nr_frags = skb_shinfo(skb)->nr_frags;
for (f = 0; f < nr_frags; f++)
count += TXD_USE_COUNT(skb_frag_size(&skb_shinfo(skb)->frags[f]),
max_txd_pwr);
if (adapter->pcix_82544)
count += nr_frags;
/* need: count + 2 desc gap to keep tail from touching
* head, otherwise try next time
*/
if (unlikely(e1000_maybe_stop_tx(netdev, tx_ring, count + 2)))
return NETDEV_TX_BUSY;
if (unlikely((hw->mac_type == e1000_82547) &&
(e1000_82547_fifo_workaround(adapter, skb)))) {
netif_stop_queue(netdev);
if (!test_bit(__E1000_DOWN, &adapter->flags))
schedule_delayed_work(&adapter->fifo_stall_task, 1);
return NETDEV_TX_BUSY;
}
if (skb_vlan_tag_present(skb)) {
tx_flags |= E1000_TX_FLAGS_VLAN;
tx_flags |= (skb_vlan_tag_get(skb) <<
E1000_TX_FLAGS_VLAN_SHIFT);
}
first = tx_ring->next_to_use;
tso = e1000_tso(adapter, tx_ring, skb, protocol);
if (tso < 0) {
dev_kfree_skb_any(skb);
return NETDEV_TX_OK;
}
if (likely(tso)) {
if (likely(hw->mac_type != e1000_82544))
tx_ring->last_tx_tso = true;
tx_flags |= E1000_TX_FLAGS_TSO;
} else if (likely(e1000_tx_csum(adapter, tx_ring, skb, protocol)))
tx_flags |= E1000_TX_FLAGS_CSUM;
if (protocol == htons(ETH_P_IP))
tx_flags |= E1000_TX_FLAGS_IPV4;
if (unlikely(skb->no_fcs))
tx_flags |= E1000_TX_FLAGS_NO_FCS;
count = e1000_tx_map(adapter, tx_ring, skb, first, max_per_txd,
nr_frags, mss);
if (count) {
/* The descriptors needed is higher than other Intel drivers
* due to a number of workarounds. The breakdown is below:
* Data descriptors: MAX_SKB_FRAGS + 1
* Context Descriptor: 1
* Keep head from touching tail: 2
* Workarounds: 3
*/
int desc_needed = MAX_SKB_FRAGS + 7;
netdev_sent_queue(netdev, skb->len);
skb_tx_timestamp(skb);
e1000_tx_queue(adapter, tx_ring, tx_flags, count);
/* 82544 potentially requires twice as many data descriptors
* in order to guarantee buffers don't end on evenly-aligned
* dwords
*/
if (adapter->pcix_82544)
desc_needed += MAX_SKB_FRAGS + 1;
/* Make sure there is space in the ring for the next send. */
e1000_maybe_stop_tx(netdev, tx_ring, desc_needed);
if (!netdev_xmit_more() ||
netif_xmit_stopped(netdev_get_tx_queue(netdev, 0))) {
writel(tx_ring->next_to_use, hw->hw_addr + tx_ring->tdt);
}
} else {
dev_kfree_skb_any(skb);
tx_ring->buffer_info[first].time_stamp = 0;
tx_ring->next_to_use = first;
}
return NETDEV_TX_OK;
}
驱动代码比较复杂,这篇文章主要讲关键流程,就不分析具体的逻辑了。
4.接收数据包基本流程
一个数据包从网卡到应用程序要经历什么样的旅程呢?由于Linux网络系统相当复杂,要分析完全部路径几乎是不可能的,但了解阻塞式UDP接收流程也有助于我们理想内核:

接收比发送要复杂一点,主要包含两个方面,一方面是应用程序调用recvfrom系统调用,然后阻塞在内核,等待数据包的到来;另一方面是数据包到达网卡后,触发硬件中断,中断例程又把执行流转到软中断,然后执行流接收网卡数据,并根据路由信息确定本地数据包,最后把数据包放入队列中,之后唤醒阻塞的进程。
系统调用
Linux内核都是按系统调用提供服务,接收网络数据也一样,先来看一下系统调用的入口函数。
//net/socket.c
SYSCALL_DEFINE6(recvfrom, int, fd, void __user *, ubuf, size_t, size,
unsigned int, flags, struct sockaddr __user *, addr,
int __user *, addr_len)
{
return __sys_recvfrom(fd, ubuf, size, flags, addr, addr_len);
}
系统调用最终把执行流引入到协议层的recvmsg接口。
接收UDP数据包
UDP协议层接收数据包的实现是udp_recvmsg函数。首先调用__skb_recv_udp获取队列中的sk_buff数据包,如果有,就把相关的数据拷贝到用户空间,函数返回。每个socket都有自己的接收队列,保存在udp_sock的reader_queue中,如果队列中没有数据,那就没什么事了,直接把线程挂起来,等待调度吧。
//net/ipv4/udp.c
int udp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int noblock,
int flags, int *addr_len)
{
struct inet_sock *inet = inet_sk(sk);
DECLARE_SOCKADDR(struct sockaddr_in *, sin, msg->msg_name);
struct sk_buff *skb;
unsigned int ulen, copied;
int off, err, peeking = flags & MSG_PEEK;
int is_udplite = IS_UDPLITE(sk);
bool checksum_valid = false;
if (flags & MSG_ERRQUEUE)
return ip_recv_error(sk, msg, len, addr_len);
try_again:
off = sk_peek_offset(sk, flags);
skb = __skb_recv_udp(sk, flags, noblock, &off, &err);
if (!skb)
return err;
ulen = udp_skb_len(skb);
copied = len;
if (copied > ulen - off)
copied = ulen - off;
else if (copied < ulen)
msg->msg_flags |= MSG_TRUNC;
/*
* If checksum is needed at all, try to do it while copying the
* data. If the data is truncated, or if we only want a partial
* coverage checksum (UDP-Lite), do it before the copy.
*/
if (copied < ulen || peeking ||
(is_udplite && UDP_SKB_CB(skb)->partial_cov)) {
checksum_valid = udp_skb_csum_unnecessary(skb) ||
!__udp_lib_checksum_complete(skb);
if (!checksum_valid)
goto csum_copy_err;
}
if (checksum_valid || udp_skb_csum_unnecessary(skb)) {
if (udp_skb_is_linear(skb))
err = copy_linear_skb(skb, copied, off, &msg->msg_iter);
else
err = skb_copy_datagram_msg(skb, off, msg, copied);
} else {
err = skb_copy_and_csum_datagram_msg(skb, off, msg);
if (err == -EINVAL)
goto csum_copy_err;
}
if (unlikely(err)) {
if (!peeking) {
atomic_inc(&sk->sk_drops);
UDP_INC_STATS(sock_net(sk),
UDP_MIB_INERRORS, is_udplite);
}
kfree_skb(skb);
return err;
}
if (!peeking)
UDP_INC_STATS(sock_net(sk),
UDP_MIB_INDATAGRAMS, is_udplite);
sock_recv_ts_and_drops(msg, sk, skb);
/* Copy the address. */
if (sin) {
sin->sin_family = AF_INET;
sin->sin_port = udp_hdr(skb)->source;
sin->sin_addr.s_addr = ip_hdr(skb)->saddr;
memset(sin->sin_zero, 0, sizeof(sin->sin_zero));
*addr_len = sizeof(*sin);
if (cgroup_bpf_enabled)
BPF_CGROUP_RUN_PROG_UDP4_RECVMSG_LOCK(sk,
(struct sockaddr *)sin);
}
if (udp_sk(sk)->gro_enabled)
udp_cmsg_recv(msg, sk, skb);
if (inet->cmsg_flags)
ip_cmsg_recv_offset(msg, sk, skb, sizeof(struct udphdr), off);
err = copied;
if (flags & MSG_TRUNC)
err = ulen;
skb_consume_udp(sk, skb, peeking ? -err : err);
return err;
csum_copy_err:
if (!__sk_queue_drop_skb(sk, &udp_sk(sk)->reader_queue, skb, flags,
udp_skb_destructor)) {
UDP_INC_STATS(sock_net(sk), UDP_MIB_CSUMERRORS, is_udplite);
UDP_INC_STATS(sock_net(sk), UDP_MIB_INERRORS, is_udplite);
}
kfree_skb(skb);
/* starting over for a new packet, but check if we need to yield */
cond_resched();
msg->msg_flags &= ~MSG_TRUNC;
goto try_again;
}
另一方面,网络数据会在某个时刻不经意的时刻到达网卡,这时,网卡会触发硬件中断,中断处理程序又把它转入软中断处理。软中断的执行流其实就是一个内核线程,相当于用一个线程专门地处理网卡的接收工作。收到数据包后,根据数据包的内容确定路由的目的,如果是转发的数据包,就调用ip_forward把它转发出去;如果是本地接收,就调用ip_local_deliver提交到传输层处理。
硬中断
还是以intel网卡为例,e1000_intr函数是注册的中断处理函数,当数据包到达时将会触发。 函数主要功能是调用__napi_schedule转为软中断处理
//drivers/net/ethernet/intel/e1000/e1000_main.c
/**
* e1000_intr - Interrupt Handler
* @irq: interrupt number
* @data: pointer to a network interface device structure
**/
static irqreturn_t e1000_intr(int irq, void *data)
{
struct net_device *netdev = data;
struct e1000_adapter *adapter = netdev_priv(netdev);
struct e1000_hw *hw = &adapter->hw;
u32 icr = er32(ICR);
if (unlikely((!icr)))
return IRQ_NONE; /* Not our interrupt */
/* we might have caused the interrupt, but the above
* read cleared it, and just in case the driver is
* down there is nothing to do so return handled
*/
if (unlikely(test_bit(__E1000_DOWN, &adapter->flags)))
return IRQ_HANDLED;
if (unlikely(icr & (E1000_ICR_RXSEQ | E1000_ICR_LSC))) {
hw->get_link_status = 1;
/* guard against interrupt when we're going down */
if (!test_bit(__E1000_DOWN, &adapter->flags))
schedule_delayed_work(&adapter->watchdog_task, 1);
}
/* disable interrupts, without the synchronize_irq bit */
ew32(IMC, ~0);
E1000_WRITE_FLUSH();
if (likely(napi_schedule_prep(&adapter->napi))) {
adapter->total_tx_bytes = 0;
adapter->total_tx_packets = 0;
adapter->total_rx_bytes = 0;
adapter->total_rx_packets = 0;
__napi_schedule(&adapter->napi);
} else {
/* this really should not happen! if it does it is basically a
* bug, but not a hard error, so enable ints and continue
*/
if (!test_bit(__E1000_DOWN, &adapter->flags))
e1000_irq_enable(adapter);
}
return IRQ_HANDLED;
}
软中断
Linux内核启动的时候会注册一个软中断,open_softirq(NET_RX_SOFTIRQ, net_rx_action);用于处理网卡的接收工作。net_rx_action软中断用budget的方式管理时间窗口,如果时间窗口已用尽则退出,它会允许窗口运行2次,也就是允许平均延迟为1.5/HZ。net_rx_action实际上调用napi_poll函数执行具体的工作。
//net/core/dev.c
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies +
usecs_to_jiffies(netdev_budget_usecs);
int budget = netdev_budget;
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto out;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 ||
time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
net_rps_action_and_irq_enable(sd);
out:
__kfree_skb_flush();
}
接收数据
intel网卡的接收工作放在e1000_clean中,真搞不定老外的命名思路,可能是想把要做的事clean干净的意思吧。adapter->clean_rx实际执行e1000_clean_rx_irq函数,把数据接收完毕,包括分配sk_buff及拷贝数据。
//drivers/net/ethernet/intel/e1000/e1000_main.c
/**
* e1000_clean - NAPI Rx polling callback
* @adapter: board private structure
**/
static int e1000_clean(struct napi_struct *napi, int budget)
{
struct e1000_adapter *adapter = container_of(napi, struct e1000_adapter,
napi);
int tx_clean_complete = 0, work_done = 0;
tx_clean_complete = e1000_clean_tx_irq(adapter, &adapter->tx_ring[0]);
adapter->clean_rx(adapter, &adapter->rx_ring[0], &work_done, budget);
if (!tx_clean_complete || work_done == budget)
return budget;
/* Exit the polling mode, but don't re-enable interrupts if stack might
* poll us due to busy-polling
*/
if (likely(napi_complete_done(napi, work_done))) {
if (likely(adapter->itr_setting & 3))
e1000_set_itr(adapter);
if (!test_bit(__E1000_DOWN, &adapter->flags))
e1000_irq_enable(adapter);
}
return work_done;
}
路由选择
Linux网络路由选择相当复杂,但不管怎么样,总是设置dst_entry的input接口函数来实现具体的功能,如果是转发设置ip_forward;如果是本地接收则设置ip_local_deliver。之后的执行流程涉入的函数非常的多,调用的路径也特别的长,从ip_local_deliver到udp_rcv,再到udp_queue_rcv_skb,最后在__udp_enqueue_schedule_skb中把skb加入队列,然后调用sk_data_ready接口唤醒阻塞的线程。
//net/ipv4/udp.c
int __udp_enqueue_schedule_skb(struct sock *sk, struct sk_buff *skb)
{
struct sk_buff_head *list = &sk->sk_receive_queue;
int rmem, delta, amt, err = -ENOMEM;
spinlock_t *busy = NULL;
int size;
/* try to avoid the costly atomic add/sub pair when the receive
* queue is full; always allow at least a packet
*/
rmem = atomic_read(&sk->sk_rmem_alloc);
if (rmem > sk->sk_rcvbuf)
goto drop;
/* Under mem pressure, it might be helpful to help udp_recvmsg()
* having linear skbs :
* - Reduce memory overhead and thus increase receive queue capacity
* - Less cache line misses at copyout() time
* - Less work at consume_skb() (less alien page frag freeing)
*/
if (rmem > (sk->sk_rcvbuf >> 1)) {
skb_condense(skb);
busy = busylock_acquire(sk);
}
size = skb->truesize;
udp_set_dev_scratch(skb);
/* we drop only if the receive buf is full and the receive
* queue contains some other skb
*/
rmem = atomic_add_return(size, &sk->sk_rmem_alloc);
if (rmem > (size + (unsigned int)sk->sk_rcvbuf))
goto uncharge_drop;
spin_lock(&list->lock);
if (size >= sk->sk_forward_alloc) {
amt = sk_mem_pages(size);
delta = amt << SK_MEM_QUANTUM_SHIFT;
if (!__sk_mem_raise_allocated(sk, delta, amt, SK_MEM_RECV)) {
err = -ENOBUFS;
spin_unlock(&list->lock);
goto uncharge_drop;
}
sk->sk_forward_alloc += delta;
}
sk->sk_forward_alloc -= size;
/* no need to setup a destructor, we will explicitly release the
* forward allocated memory on dequeue
*/
sock_skb_set_dropcount(sk, skb);
__skb_queue_tail(list, skb);
spin_unlock(&list->lock);
if (!sock_flag(sk, SOCK_DEAD))
sk->sk_data_ready(sk);
busylock_release(busy);
return 0;
uncharge_drop:
atomic_sub(skb->truesize, &sk->sk_rmem_alloc);
drop:
atomic_inc(&sk->sk_drops);
busylock_release(busy);
return err;
}
EXPORT_SYMBOL_GPL(__udp_enqueue_schedule_skb);
最后想说的是 Linux网络相当稳健,上文中介绍的路径只在系统负载比较轻的典型场景,如果系统负载很重,执行路径将会发送很大的改变,这需要根据具体情况来分析源码了。
原文链接:https://zhuanlan.zhihu.com/p/402212032