增强现实( AR ) 是一种真实世界环境的交互式体验,其中存在于现实世界中的对象通过计算机生成的感知信息得到增强,有时跨越多种感官模式,包括视觉、听觉、触觉、体感和嗅觉。AR 可以定义为一个包含三个基本特征的系统:真实和虚拟世界的结合、实时交互以及虚拟和真实对象的准确 3D 配准。重叠的感觉信息可以是建设性的(即对自然环境的补充)或破坏性的(即对自然环境的掩蔽)。这种体验与物理世界无缝交织,因此被视为真实环境的沉浸式体验。[4]通过这种方式,增强现实改变了人们对现实世界环境的持续感知,而虚拟现实完全用模拟环境取代了用户的现实世界环境。增强现实与两个主要同义词相关:混合现实和计算机介导的现实。
——以上内容来自Wiki百科
类别
Vision based AR(基于计算机视觉的AR)
Marker-Based AR (基于标定的AR)
如:
Marker-Less AR(基于特征点的AR)
如:
LBS based AR(基于地理位置信息的AR)
如:
本文将具体讲解和实验基于特征点的AR技术
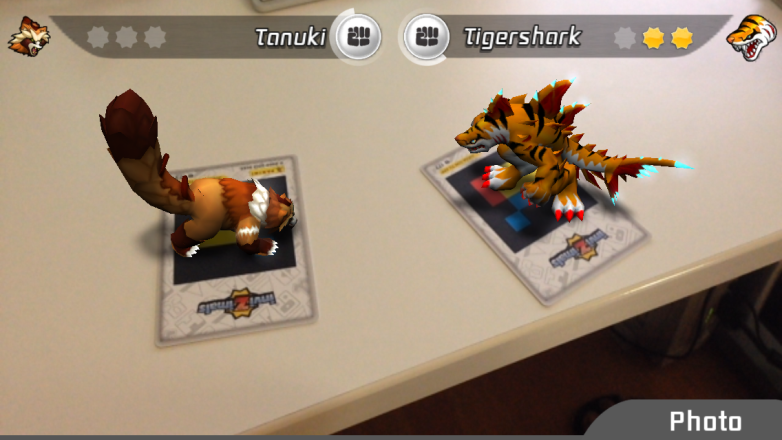
Demo 演示
1. 演示环境
iphone 8 手机:App Store 下载 Focus [+] # 手动对焦拍摄
计算机:vim,python和 conda
OpenCV 棋盘标定纸
2. 准备图片
参考图片
用例图片
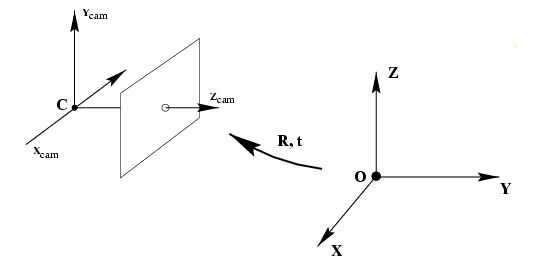
3. 相机标定原理
从世界坐标系转换到图像坐标系,求投影矩阵
P
P
P 的过程
分为两步
3.1 从世界坐标系转换为相机坐标系
这一步是三维点到三维点的转换,包括
R
,
t
R,t
R,t (相机外参)等参数
X
~
c
a
m
=
R
(
X
~
−
C
~
)
\widetilde{X}_{c a m}=R(\widetilde{X}-\widetilde{C})
Xcam=R(X−C)
X
~
\widetilde{X}
X 为
X
X
X 在世界坐标中的位置
R
R
R 为旋转矩阵
C
~
\widetilde{C}
C 为相机原点
C
C
C 所在世界坐标中的位置
X
~
c
a
m
\widetilde{X}_{c a m}
Xcam 为 $ X $ 在相机坐标系中的位置
3.2 从相机坐标系转换为图像坐标系
这一步是三维点到二维点的转换,包括
K
K
K(相机内参)等参数
C
C
C 为相机的中心点,也是相机坐标系的中心点
Z
Z
Z 为相机的主轴
p
p
p 为相机的像平面,也就是图片坐标系所在的二维平面
C
C
C 点到
p
p
p 点的距离
f
f
f,为相机的焦距
可得到
x
=
f
X
/
Z
y
=
f
Y
/
Z
(
X
,
Y
,
Z
)
↦
(
f
X
/
Z
,
f
Y
/
Z
)
\begin{aligned} x &=f X / Z \\ y &=f Y / Z \\ (X, \quad Y, \quad Z) & \mapsto(f X / Z, \quad f Y / Z) \end{aligned}
xy(X,Y,Z)=fX/Z=fY/Z↦(fX/Z,fY/Z)
由图可知偏移量
(
X
,
Y
,
Z
)
↦
(
f
X
/
Z
+
p
x
,
f
Y
/
Z
+
p
y
)
(X, \quad Y, \quad Z) \mapsto\left(f X / Z+p_{x}, \quad f Y / Z+p_{y}\right)
(X,Y,Z)↦(fX/Z+px,fY/Z+py) 矩阵形式为
(
X
Y
Z
1
)
↦
(
f
X
+
Z
p
x
f
Y
+
Z
p
y
Z
)
=
[
f
p
x
0
f
p
y
0
1
0
]
(
X
Y
Z
1
)
\left(\begin{array}{c} X \\ Y \\ Z \\ 1 \end{array}\right) \mapsto\left(\begin{array}{c} f X+Z p_{x} \\ f Y+Z p_{y} \\ Z \end{array}\right)=\left[\begin{array}{ccc} f & p_{x} & 0 \\ & f & p_{y} & 0 \\ & & 1 & 0 \end{array}\right]\left(\begin{array}{c} X \\ Y \\ Z \\ 1 \end{array}\right)
XYZ1↦fX+ZpxfY+ZpyZ=fpxf0py100XYZ1
化简得
(
f
X
+
Z
p
x
f
Y
+
Z
p
y
Z
)
=
[
f
p
x
f
p
y
1
]
[
1
0
1
0
1
0
]
(
X
Y
Z
1
)
\left(\begin{array}{c} f X+Z p_{x} \\ f Y+Z p_{y} \\ Z \end{array}\right)=\left[\begin{array}{cc} f & p_{x} \\ & f & p_{y} \\ & & 1 \end{array}\right]\left[\begin{array}{llll} 1 & & & 0 \\ & 1 & & 0 \\ & & 1 & 0 \end{array}\right]\left(\begin{array}{l} X \\ Y \\ Z \\ 1 \end{array}\right)
fX+ZpxfY+ZpyZ=fpxfpy1111000XYZ1
则
K
=
[
f
p
x
f
p
y
1
]
K=\left[\begin{array}{ccc} f & & p_{x} \\ & f & p_{y} \\ & & 1 \end{array}\right]
K=ffpxpy1
设旋转矩阵
R
R
R 为单位矩阵
I
I
I,平移矩阵
t
t
t 为0
P
=
K
[
R
∣
t
]
=
K
[
I
∣
0
]
\begin{aligned} P &=K[R \mid t] \\ &=K[I \mid 0] \end{aligned}
P=K[R∣t]=K[I∣0]
任选图像中的一点
P
P
P,以该点为圆形,
r
r
r为半径确定一个圆,在圆上均匀取
m
m
m个像素点,设定一个阈值
t
t
t,如果
m
m
m个像素点中,有连续
N
N
N个像素点的大小均大于或小于
t
t
t,则这个点就是角点。但是在进行FAST进行角点检测时,边缘位置的部分易混淆,针对这种情况,ORB算法通过增加图像金字塔和计算角度的方法,用Harris角点检测器把
N
N
N个关键点进行等级排序,使用者可提取前n个自己需要的点。不同的是,ORB在进行特征点匹配时,检测出的角点需要满足尺度不变形和旋转不变性。
采用灰度质心法进行计算每个特征点的主方向
m
p
q
=
∑
x
,
y
x
p
y
q
I
(
x
,
y
)
\mathrm{m}_{p q}=\sum_{x, y} x^{p} y^{q} I(x, y)
mpq=x,y∑xpyqI(x,y) 其中
x
,
y
x,y
x,y分别表示像素点周围圆上所选取点的横坐标和纵坐标,
I
(
x
,
y
)
I(x,y)
I(x,y)表示灰度值大小,
p
,
q
p,q
p,q表示指数,角度计算的方法如下
θ
=
atan
2
(
m
01
,
m
10
)
\theta=\operatorname{atan} 2(\mathrm{m_{01}}, \mathrm{m_{10}})
θ=atan2(m01,m10)
5.2 特征描述
ORB法采用BRIEF描述子计算算法实现,BRIEF算法可分为两步
特征点大小的对比
以特征点为中心,取邻域窗口,在窗口上选择两个点p(x)和p(y),比较两个点像素值的大小
τ
(
p
;
x
,
y
)
:
=
{
1
i
f
p
(
x
)
<
p
(
y
)
0
otherwise
\tau(p ; x, y):=\left\{\begin{array}{cc} 1 & if\quad p(x)<p(y) \\ 0 & \text { otherwise } \end{array}\right.
τ(p;x,y):={10ifp(x)<p(y) otherwise
重复第一步进行像素值大小的比较,形成二进制编码
OBR算法对BRIEF有两种改变,分别为 steer BRIEF 和 rBRIEF
steer BRIEF具备旋转不变形的特征,已知 $ /theta $,将该点周围的点旋转 $ /theta $ 度,得到新的点对
D
θ
=
R
θ
D
D_{\theta}=R_{\theta} D
Dθ=RθD
将参考图像表面的平面的点映射到用例图像的平面上,也就是单应性变换,单应性变换是将一个平面(齐次坐标)中的点映射到另一个平面的二维投影变换
[
x
′
y
′
z
′
]
=
[
h
1
h
2
h
3
h
4
h
5
h
6
h
7
h
8
h
9
]
[
x
y
z
]
\left[\begin{array}{l} x^{\prime} \\ y^{\prime} \\ z^{\prime} \end{array}\right]=\left[\begin{array}{lll} h_{1} & h_{2} & h_{3} \\ h_{4} & h_{5} & h_{6} \\ h_{7} & h_{8} & h_{9} \end{array}\right]\left[\begin{array}{l} x \\ y \\ z \end{array}\right]
x′y′z′=h1h4h7h2h5h8h3h6h9xyz