目录
docker定义
docker解决了什么问题
docker技术边界
docker给我们带来了哪些改变
docker和虚拟机的区别
docker基本架构
基本架构图
RootFs
Linux Namespace
进程命名空间
查看元祖进程命名空间
查看当前用户进程命名空间
容器进程命名空间
容器进程命名空间的具体体现
1. 开启docker user命名空间配置,/etc/docker/daemon.json 文件添加以下选项
2. 重启docker服务
3. 宿主机上查看docker容器默认生成的用户配置
4. User命名空间:启动新的nginx容器,查看user命名空间
5. UTS命名空间:启动新容器,设置hostname与domain
6. mount、PID、Network 命名空间:启动一个工具容器
cgroups
cpu子系统:
CFS
RT
cpuset子系统:
cpuacct子系统
memory子系统:
blkio子系统
devices子系统
freezer子系统
net_cls子系统
net_prio子系统
perf_event
hugetlb
docker定义
根据官方的定义,Docker是以Docker容器为资源分割和调度的基本单位,封装整个软件运行时环境,为开发者和系统管理员设计的,用于构建、发布和运行分布式应用的平台。 引用网图:

docker解决了什么问题
1. 解决了应用程序本地运行环境与生产运行环境不一致的问题
2. 解决了应用程序资源使用的问题,docker会一开始就为每个程序指定内存分配和CPU分配 3. 让快速扩展、弹性伸缩变得简单
docker技术边界
docker是容器化技术,针对的是应用及应用所依赖的环境做容器化。遵循单一原则,一个容器只运行一 个主进程。多个进程都部署在一个容器中,弊端很多。比如更新某个进程的镜像时,其他进程也会被迫 重启,如果一个进程出问题导致容器挂了,所有进程都将无法访问。再根据官网的提倡的原则而言,容器 = 应用 + 依赖的执行环境而不是像虚拟机一样,把一堆进程都部署在一起。
docker给我们带来了哪些改变

1. 软件交付方式发生了变化
2. 替代了虚拟机
3. 改变了我们体验软件的模式
4. 降低了企业成本
5. 促进了持续集成、持续部署的发展
6. 促进了微服务的发展
docker和虚拟机的区别
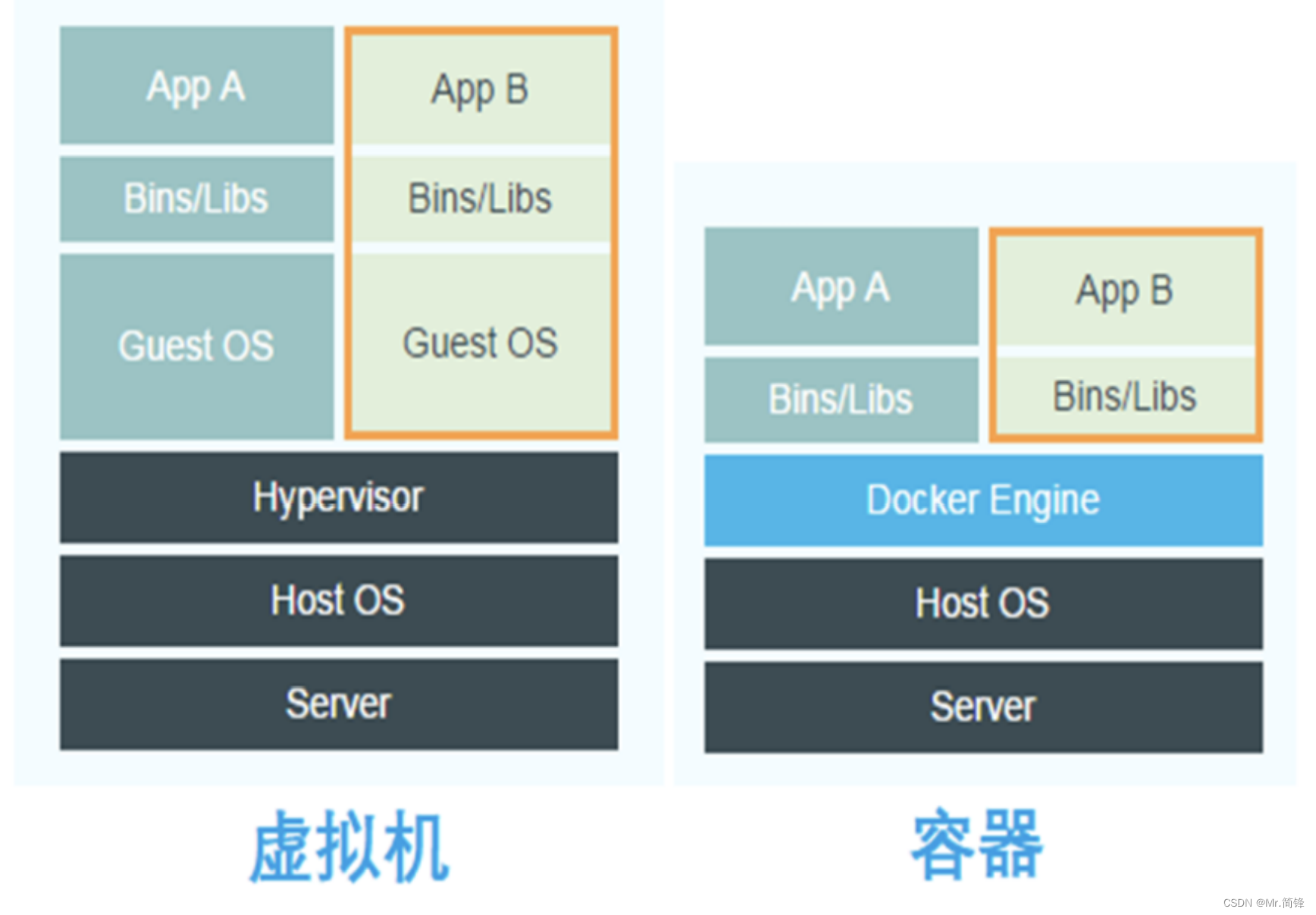
1. vm(虚拟机)与docker(容器)框架,直观上来讲vm多了一层guest OS,同时Hypervisor会对硬件资源进行虚拟化,docker直接使用硬件资源,所以资源利用率相对docker低
2. 服务器虚拟化解决的核心问题是资源调配,而容器解决的核心问题是应用开发、测试和部署。
3. 容器技术严格来说并不是虚拟化,没有客户机操作系统,是共享内核的。
docker基本架构
基本架构图

涉及概念
1. 镜像(Image):Docker 镜像是用于创建 Docker 容器的模板,比如 Ubuntu 系统
2. 容器(Container):容器是独立运行的一个或一组应用,是镜像运行时的实体
3. 客户端(client):Docker 客户端通过命令行或者其他工具使用 Docker SDK (https://docs.docker.com/develop/sdk/)) 与 Docker 的守护进程通信
4. 主机(host):一个物理或者虚拟的机器用于执行 Docker 守护进程和容器
5. 注册中心(Registry):Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hub(https://hub.docker.com)) 提供了庞大的镜像集合供使用。
6. Docker Machine:Docker Machine是一个简化Docker安装的命令行工具,通过一个简单的命令行即可在相应的平台上安装Docker。
直观感受client请求server
client 通过http协议访问 host
sudo apt install socat
socat -v UNIX-LISTEN:/tmp/dockerapi.sock UNIX-CONNECT:/var/run/docker.sock &
这条命令中,-v 用于提高输出的可读性,带有数据流的指示。UNIX-LISTEN 部分是让socat 在一个Unix 套接字上进行监听,而UNIX-CONNECT 是让socat 连接到Docker 的Unix套接字。
docker -H unix:///tmp/dockerapi.sock ps

RootFs
rootfs 是Docker 容器在启动时内部进程可见的文件系统,即Docker容器的根目录。rootfs通常包含一个操作系统运行所需的文件系统,例如可能包含经典的类Unix操作系统中的目录系统, 如/dev、/proc、/bin、/etc、/lib、/usr、/tmp及运行Docker容器所需的配置文件、工具等。
cd /proc 可以看到当前进程的文件信息
cd pid 里面可以看到有些有root的文件
sudo ls root 可以看到当前进程的根文件系统
Linux Namespace
Namespace是 Linux 内核用来隔离内核资源的方式。Linux实现了六种不同类型的命名空间。每个命名空间的用途是将特定的全局系统资源包装在抽象中,使命名空间中的进程看起来它们具有自己的全局资源独立实例。命名空间的总体目标之一是支持容器的实现。

进程命名空间
lsns 命令说明
列出系统命名空间
-p、 --task<pid>打印进程命名空间
1. NS:命名空间标识符(索引节点号)
2. TYPE:命名空间类型
3. PATH:命名空间的PATH路径
4. NPROCS:命名空间中的进程数
5. PID:命名空间中的最小PID
6. PPID:PID的父级PID
7. COMMAND:PID的命令行
8. UID:PID的UID
9. USER:PID的User
10. NETNSID:网络子系统使用的命名空间ID
11. NSFS:nsfs 文件系统挂载点(通常用于网络子系统)
查看元祖进程命名空间
1. 列出系统所有命名空间
sudo lsns --output-all

上图红色框内命名空间所属进程ID为1,表示元祖进程的命名空间,即系统默认命名空间。进程没有特殊 指定需要创建新的命名空间的情况下,命名空间将与父进程保持一致。
2. 通过文件查看元祖进程命名空间
sudo ls -al /proc/1/ns --color

查看当前用户进程命名空间
1. 查看当前用户进程命名空间列表
lsns --output-all

2. fork一个新的进程,并且不共享父进程命名空间
# 创建新的进程
# 若没有指定-U则需要超级权限
unshare --fork -m -u -i -n -p -U -C sleep 100
# 查看所有命名空间
lsns --output-all
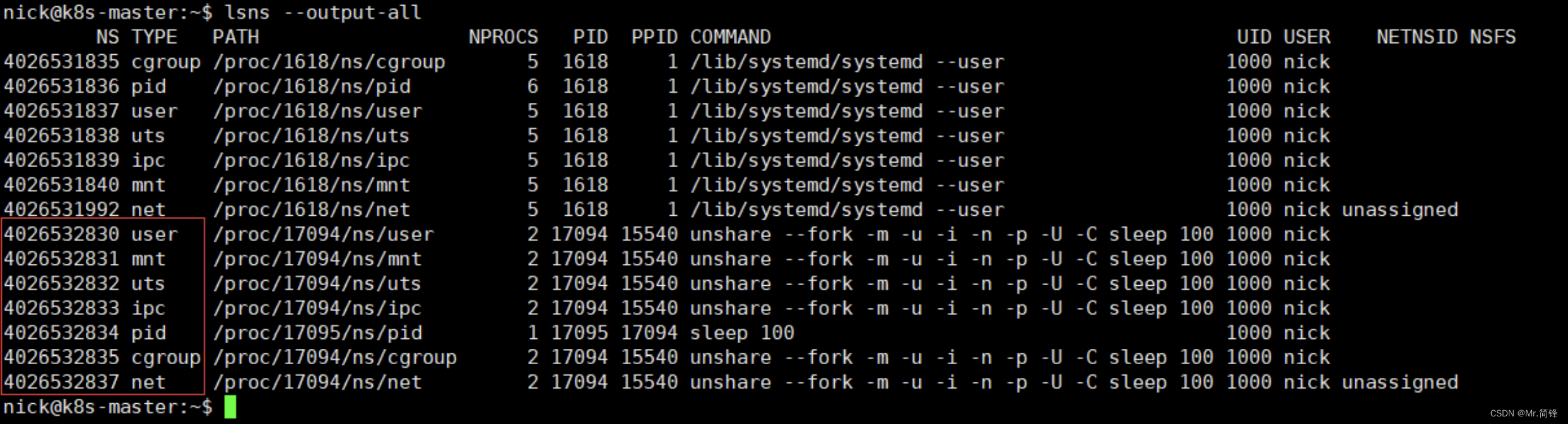
新fork出来的进程,在指定新命名空间后,其命名空间字段的值与系统默认命名空间不一致,说明进程创建了新的命名空间。
容器进程命名空间
查看容器进程命名空间列表
1. 运行容器,获取进程ID
# 启动nginx 容器
docker run -d --name mynginx nginx
# 获取nginx主进程ID
docker top mynginx
# 查看进程命名空间
sudo lsns -p <pid> --output-all
2. 查看容器进程的命名空间情况

nginx容器默认使用了mnt、uts、ipc、pid、net 命名空间隔离,而user与cgroup则继承系统默认命名空间。网络命名空间指定了文件系统挂载点
容器进程命名空间的具体体现
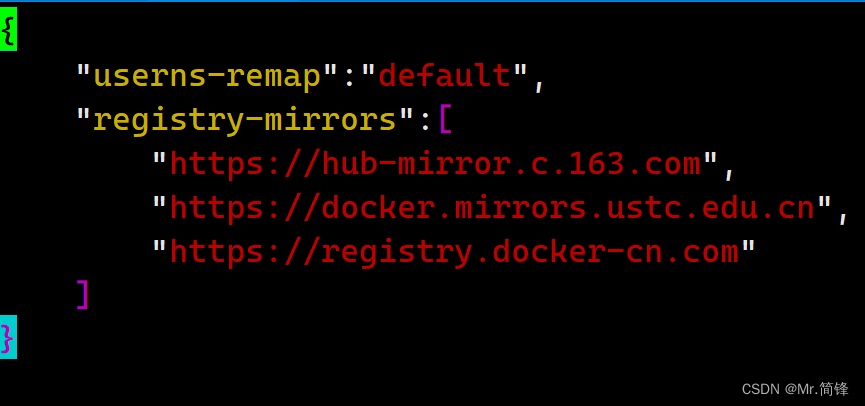
1. 开启docker user命名空间配置,/etc/docker/daemon.json 文件添加以下选项
// 默认生成
"userns-remap":"default"
或
// 指定已存在用户和组
"userns-remap":"user:group"
2. 重启docker服务
sudo systemctl restart docker.service
3. 宿主机上查看docker容器默认生成的用户配置
cat /etc/subuid
cat /etc/subgid
id <user>
/etc/subuid文件:dockremap:165536:65536 表示宿主机使用dockremap用户,容器使用其从属ID, 范围从0~65536,与之对应的宿主机ID范围:165536~165536+65536 /etc/subgid文件:针对用户组与/etc/subuid 类似
4. User命名空间:启动新的nginx容器,查看user命名空间
# 运行容器,指定私有cgroupns,指定user
docker run -d --cgroupns private --user root --name mynginx1 nginx
# 查看容器在宿主机上的进程信息,UID显示并不是root
docker top mynginx1
# 与容器交互,查看当前用户信息,显示为root,也可通过id查看用户信息
docker exec -it mynginx1 bash
# 查看进程命名空间,进程拥有独立的命名空间
sudo lsns -p <pid> --output-all

5. UTS命名空间:启动新容器,设置hostname与domain
# 运行容器,指定hostname与域名
docker run -d --domainname abc.nick.com --hostname abcdefg --userns host --name
mynginx2 nginx
# 与容器交互,进入交互模式
docker exec -it mynginx2 bash
# 访问hostname 与 domainname
hostname
domainname
# 通过hostname与domainname访问应用
curl http://abcdefg
curl http://abcdefg.abc.nick.com
# 通过文件查看hostname与domainname
cat /proc/sys/kernel/hostname
cat /proc/sys/kernel/domainname
6. mount、PID、Network 命名空间:启动一个工具容器
# 运行工具容器
docker run -dit --name mycurl radial/busyboxplus:curl
# 进入交互模式
docker exec -it mycurl sh
mount命名空间:容器内部执行mount 与宿主机内执行mount命令对比,即可看出各自拥有不同的 mounts。mounts文件位于:/proc/mounts 和 /proc/{PID}/mounts。 mounts文件列说明:
Device mount的设备
Mount Point 挂载点,也就是挂载的路径
File System Type 文件系统类型,如ext4、xfs等
Options 挂载选项,包括读写权限等参数
无用内容,保持内容和/etc/fstab格式一致
无用内容,保持内容和/etc/fstab格式一致
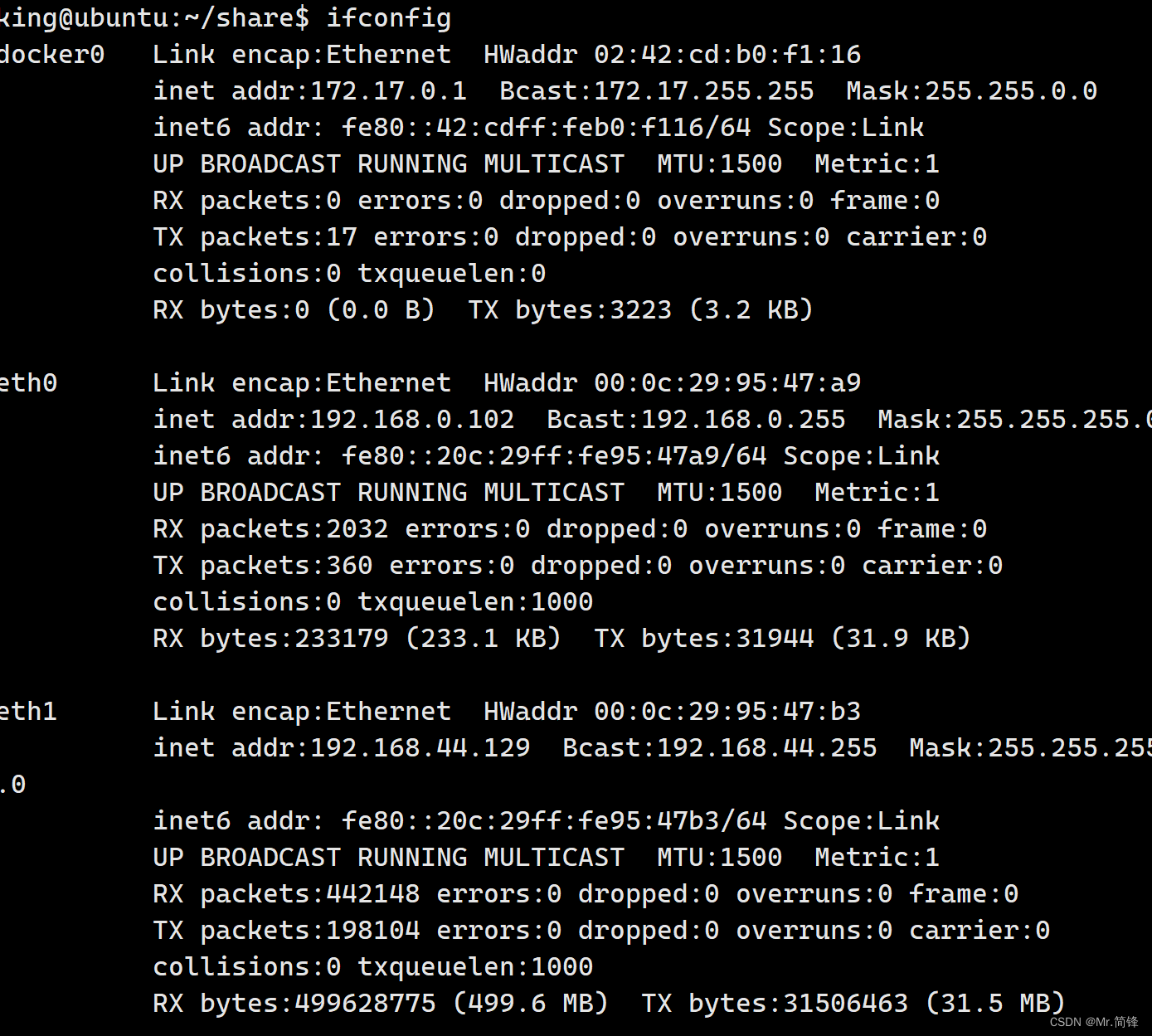
PID命名空间:容器内部进程ID为1,宿主机内进程ID不为1
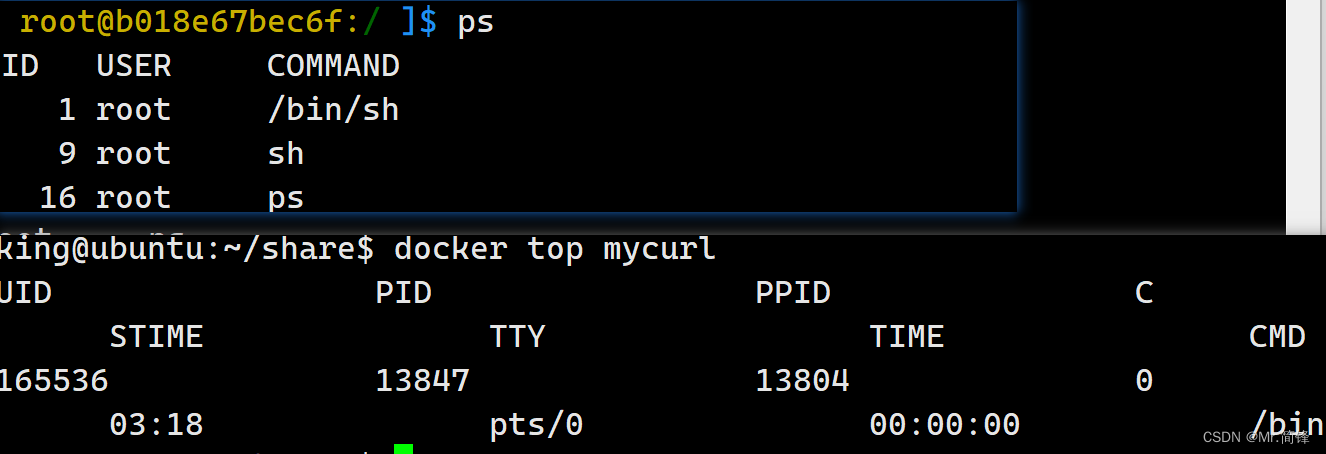
NetWork命名空间:通过ifconfig工具,查看网络信息。容器与宿主机网络完全是两个独立的网络栈

cgroups
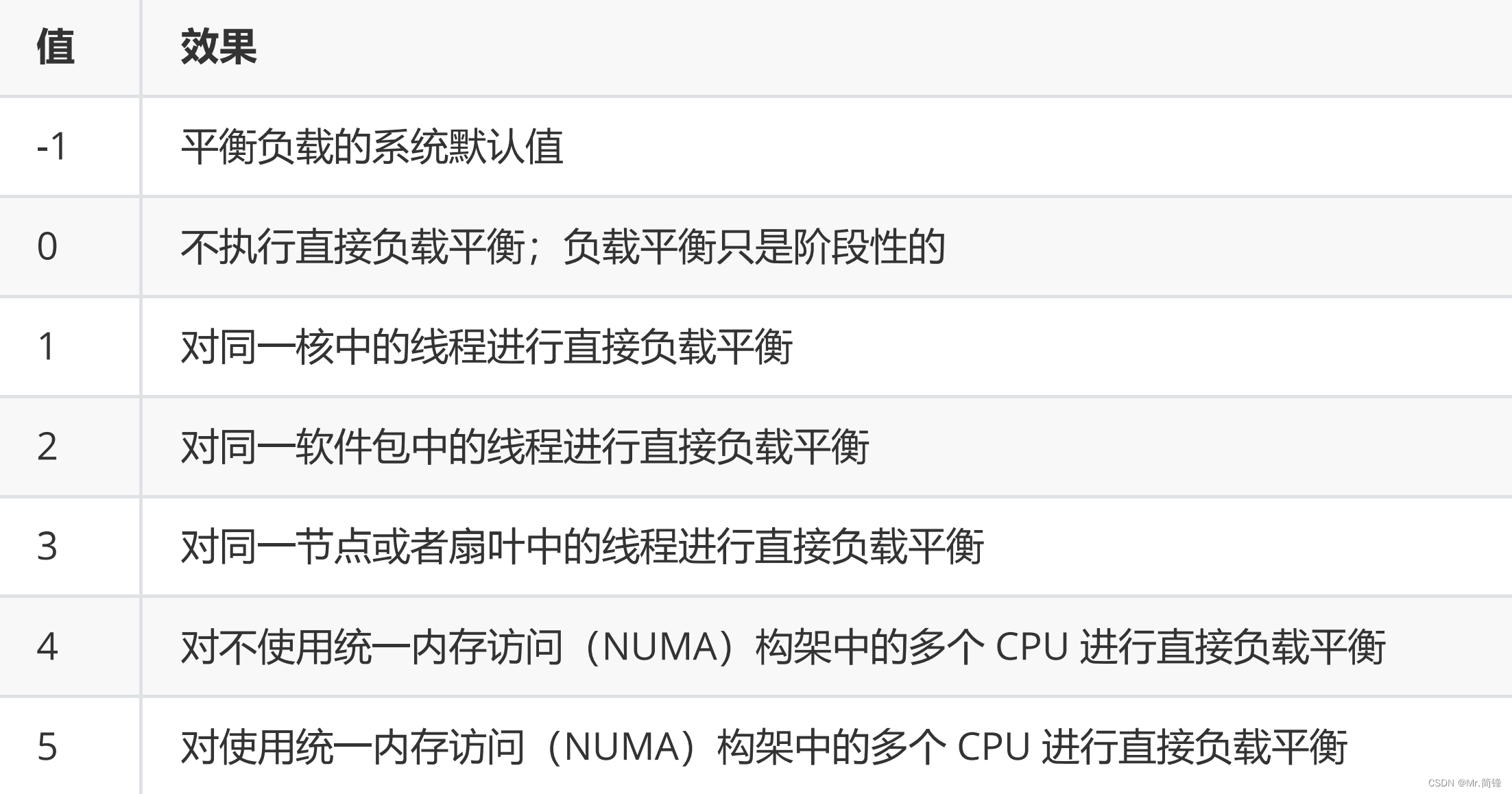
cgroup全称是control groups,被整合在了linux内核当中,把进程(tasks)放到组里面,对组设置权限,对进程进行控制。可以理解为用户和组的概念,用户会继承它所在组的权限
cpu子系统:
调度 cgroup 对 CPU 的获取量。可用以下两个调度程序来管理对 CPU 资源的获取:
1. 完全公平调度程序(CFS) — 一个比例分配调度程序,可根据任务优先级 ∕ 权重或 cgroup 分得的份额,在任务群组(cgroups)间按比例分配 CPU 时间(CPU 带宽)
2. 实时调度程序(RT) — 一个任务调度程序,可对实时任务使用 CPU 的时间进行限定
CFS
1. cpu.cfs_period_us:此参数可以设定重新分配 cgroup 可用 CPU 资源的时间间隔,单位为微秒, 上限1秒,下限1000微秒。即设置单个CPU重新分配周期
2. cpu.cfs_quota_us:此参数可以设定在某一阶段(由 cpu.cfs_period_us 规定)某个 cgroup 中所 有任务可运行的时间总量,单位为微秒。即每个周期时间内,可以使用多长时间的CPU(单个), 该值可以大于cfs_period_us的值,表示可以利用多个CPU来满足CPU使用时长
3. cpu.shares:用一个整数来设定cgroup中任务CPU可用时间的相对比例。该参数是对系统所有CPU 做分配,不是单个CPU。
4. cpu.stat:报告 CPU 时间统计 ,
nr_periods : 经过的周期间隔数
nr_throttled : cgroup 中任务被节流的次数(即耗尽所有按配额分得的可用时间后,被禁止运行) throttled_time : cgroup 中任务被节流的时间总计(以纳秒为单位)
RT
RT 调度程序与 CFS 类似,但只限制实时任务对 CPU 的存取。
1. cpu.rt_period_us:此参数可以设定在某个时间段中 ,每隔多久,cgroup 对 CPU 资源的存取就要 重新分配,单位为微秒(µs,这里以“us”表示),只可用于实时调度任务
2. cpu.rt_runtime_us:此参数可以指定在某个时间段中, cgroup 中的任务对 CPU 资源的最长连续 访问时间,单位为微秒(µs,这里以“us”表示),只可用于实时调度任务
示例
1. 一个 cgroup 使用一个 CPU 的 25%,同时另一个 cgroup 使用此 CPU 的 75%
echo 250 > /cgroup/cpu/blue/cpu.shares
echo 750 > /cgroup/cpu/red/cpu.shares
2. 一个 cgroup 完全使用一个 CPU
echo 10000 > /cgroup/cpu/red/cpu.cfs_quota_us
echo 10000 > /cgroup/cpu/red/cpu.cfs_period_us
3. 一个 cgroup 使用 CPU 的 10%
echo 10000 > /cgroup/cpu/red/cpu.cfs_quota_us
echo 100000 > /cgroup/cpu/red/cpu.cfs_period_us
4. 多核系统中,如要让一个 cgroup 完全使用两个 CPU 核
echo 200000 > /cgroup/cpu/red/cpu.cfs_quota_us
echo 100000 > /cgroup/cpu/red/cpu.cfs_period_us
cpuset子系统:
可以为 cgroup 分配独立 CPU 和内存节点
1. cpuset.cpu_exclusive:包含标签(0 或者 1),它可以指定:其它 cpuset 及其父、子 cpuset 是 否可共享该 cpuset 的特定 CPU。默认情况下(0),CPU 不会专门分配给某个 cpuset
2. cpuset.cpus(强制):设定该 cgroup 任务可以访问的 CPU。这是一个逗号分隔列表,格式为 ASCII,小横线("-")代表范围。例如:0-2,16 表示cpu 0、1、2 和 16
3. cpuset.mem_exclusive:包含标签(0 或者 1),它可以指定:其它 cpuset 是否可共享该 cpuset 的特定内存节点。默认情况下(0),内存节点不会专门分配给某个 cpuset 。为某个 cpuset 保留 其专用内存节点(1)与使用 cpuset.mem_hardwall 参数启用内存 hardwall 功能是一样的
4. cpuset.mem_hardwall:包含标签(0 或者 1),它可以指定:内存页和缓冲数据的 kernel 分配 是否受到 cpuset 特定内存节点的限制。默认情况下 0,页面和缓冲数据在多用户进程间共享。启 用 hardwall 时(1)每个任务的用户分配可以保持独立
5. cpuset.memory_migrate:包含一个标签(0 或者 1),用来指定当 cpuset.mems 的值更改时, 是否应该将内存中的页迁移到新节点。默认情况下禁止内存迁移(0)且页就保留在原来分配的节 点中,即使此节点不再是 cpuset.mems 指定的节点。如果启用(1),系统会将页迁移到 cpuset.mems 指定的新参数的内存节点中,如果可能的话会保留其相对位置。
6. cpuset.memory_pressure:一份只读文件,包含该 cpuset 进程生成的“内存压力”运行平均。启用 cpuset.memory_pressure_enabled 时,该伪文件中的值会自动更新,除非伪文件包含 0 值。
7. cpuset.memory_pressure_enabled:包含标签(0 或者 1),它可以设定系统是否计算该 cgroup 进程生成的“内存压力”。计算出的值会输出到 cpuset.memory_pressure,代表进程试图释放被占 用内存的速率,报告值为:每秒尝试回收内存的整数值再乘以 1000。
8. cpuset.memory_spread_page:包含标签(0 或者 1),它可以设定文件系统缓冲是否应在该 cpuset 的内存节点中均匀分布。默认情况下 0,系统不会为这些缓冲平均分配内存页面,缓冲被置 于生成缓冲的进程所运行的同一节点中。
9. cpuset.memory_spread_slab:包含标签(0 或者 1),它可以设定是否在 cpuset 间平均分配用 于文件输入 / 输出操作的 kernel 高速缓存板。默认情况下 0,kernel 高速缓存板不被平均分配,高速缓存板被置于生成它们的进程所运行的同一节点中。
10. cpuset.mems(强制):设定该 cgroup 中任务可以访问的内存节点。这是一个逗号分隔列表,格 式为 ASCII,小横线("-")代表范围。例如:0-2,16 表示内存节点 0、1、2 和 16。内存节点:内 存被划分为节点,每一个节点关联到一个cpu
11. cpuset.sched_load_balance:包含标签(0 或者 1),它可以设定 kernel 是否在该 cpuset 的 CPU 中平衡负载。默认情况下 1,kernel 将超载 CPU 中的进程移动到负载较低的 CPU 中以便平衡 负载。如果父cgroup设置了,子cgroup的设置将没有任何作用
12. cpuset.sched_relax_domain_level:包含 -1 到一个小正数间的整数,它代表 kernel 应尝试平衡负 载的 CPU 宽度范围。如果禁用 cpuset.sched_load_balance,则该值无意义
cpuacct子系统
自动生成报告来显示 cgroup 任务所使用的 CPU 资源,其中包括子群组任务
1. cpuacct.stat:报告此 cgroup 的所有任务(包括层级中的低端任务)使用的用户和系统 CPU 时间 user: 用户模式中任务使用的 CPU 时间 system: 系统(kernel)模式中任务使用的 CPU 时间
2. cpuacct.usage:报告此 cgroup 中所有任务(包括层级中的低端任务)使用 CPU 的总时间(纳 秒)
3. cpuacct.usage_percpu:报告 cgroup 中所有任务(包括层级中的低端任务)在每个 CPU 中使用 的 CPU 时间(纳秒)
memory子系统:
自动生成 cgroup 任务使用内存资源的报告,并限定这些任务所用内存的大小
1. memory.failcnt:报告内存达到 memory.limit_in_bytes 设定的限制值的次数
2. memory.force_empty:当设定为 0 时,该 cgroup 中任务所用的所有页面内存都将被清空。这个 接口只可在 cgroup 没有任务时使用。如果无法清空内存,请在可能的情况下将其移动到父 cgroup 中。移除 cgroup 前请使用 memory.force_empty 参数以免将废弃的页面缓存移动到它的父 cgroup 中
3. memory.limit_in_bytes:设定用户内存(包括文件缓存)的最大用量。如果没有指定单位,则该 数值将被解读为字节。但是可以使用后缀代表更大的单位 —— k 或者 K 代表千字节,m 或者 M 代 表兆字节 ,g 或者 G 代表千兆字节。在 memory.limit_in_bytes 中写入 -1 可以移除全部已有限 制。
4. memory.max_usage_in_bytes:报告 cgroup 中进程所用的最大内存量(以字节为单位)
5. move_charge_at_immigrate:当将一个task移动到另一个cgroup中时,此task的内存页可能会被 重新统计到新的cgroup中,这取决于是否设置了move_charge_at_immigrate
6. numa_stat: 每个numa节点的内存使用数量
7. memory.oom_control:设置or查看内存超限控制信息(OOM killer)
8. memory.pressure_level:设置内存压力通知
9. memory.soft_limit_in_bytes:内存软限制
10. memory.stat:报告大范围内存统计
11. memory.swappiness:将 kernel 倾向设定为换出该 cgroup 中任务所使用的进程内存,而不是从 页高速缓冲中再生页面。
12. memory.usage_in_bytes:报告 cgroup 中进程当前所用的内存总量(以字节为单位) 13. memory.use_hierarchy:包含标签(0 或者 1),它可以设定是否将内存用量计入 cgroup 层级的 吞吐量中。如果启用(1),内存子系统会从超过其内存限制的子进程中再生内存。默认情况下 (0),子系统不从任务的子进程中再生内存
内核内存:专用于Linux内核系统服务使用,是不可swap的
14. memory.kmem.failcnt:报告内核内存达到 memory.kmem.limit_in_bytes 设定的限制值的次数
15. memory.kmem.limit_in_bytes:设定内核内存(包括文件缓存)的最大用量。如果没有指定单 位,则该数值将被解读为字节
16. memory.kmem.max_usage_in_bytes:报告 cgroup 中进程所用的最大内核内存量(以字节为单 位)
17. memory.kmem.slabinfo:查看内核内存分配情况
18. memory.kmem.usage_in_bytes:报告 cgroup 中进程当前所用的内核内存总量(以字节为单位)
19. memory.kmem.tcp.failcnt:报告tcp缓存内存达到memory.kmem.tcp.limit_in_bytes设定限制值 的次数
20. memory.kmem.tcp.limit_in_bytes:设置或查看TCP缓冲区的内存使用限制
21. memory.kmem.tcp.max_usage_in_bytes:报告cgroup中进程所用的最大tcp缓存内存量 22. memory.kmem.tcp.usage_in_bytes:报告cgroup中进程当前所用TCP缓冲区的内存使用量
示例
1. cgroup 中任务可用的内存量设定为 100MB
echo 104857600 > memory.limit_in_bytes
blkio子系统
控制并监控 cgroup 中的任务对块设备 I/O 的存取。对一些伪文件写入值可以限制存取次数或带宽,从伪文件中读取值可以获得关于 I/O 操作的信息。
1. blkio.reset_stats:此参数用于重设其它伪文件记录的统计数据。请在此文件中写入整数来为 cgroup 重设统计数据
2. blkio.throttle.io_service_bytes:此参数用于报告 cgroup 传送到具体设备或者由具体设备中传送 出的字节数。
3. blkio.throttle.io_serviced:此参数用于报告 cgroup 根据节流方式在具体设备中执行的 I/O 操作 数。
4. blkio.throttle.read_bps_device:此参数用于设定设备执行“读”操作字节的上限。“读”的操作率以 每秒的字节数来限定。
5. blkio.throttle.read_iops_device:此参数用于设定设备执行“读”操作次数的上限。“读”的操作率以 每秒的操作次数来表示。
6. blkio.throttle.write_bps_device:此参数用于设定设备执行“写”操作次数的上限。“写”的操作率用 “字节/秒”来表示
7. blkio.throttle.write_iops_device:此参数用于设定设备执行 “写” 操作次数的上限。“写”的操作率 以每秒的操作次数来表示。
devices子系统
允许或者拒绝 cgroup 任务存取设备
1. devices.allow:指定 cgroup 任务可访问的设备
2. devices.deny:指定 cgroup 任务无权访问的设备
3. devices.list:报告 cgroup 任务对其访问受限的设备
freezer子系统
暂停或者恢复 cgroup 中的任务
1. freezer.state:
FROZEN: cgroup 中的任务已被暂停
FREEZING:系统正在暂停 cgroup 中的任务
THAWED: cgroup 中的任务已恢复
net_cls子系统
使用等级识别符(classid)标记网络数据包,这让 Linux 流量管控器(tc)可以识别从特定 cgroup 中 生成的数据包。可配置流量管控器,让其为不同 cgroup 中的数据包设定不同的优先级
1. net_cls.classid: 包含表示流量控制 handle 的单一数值。从 net_cls.classid 文件中读取的 classid 值是十进制格式,但写入该文件的值则为十六进制格式
net_prio子系统
可以为各个 cgroup 中的应用程序动态配置每个网络接口的流量优先级。网络优先级是一个分配给网络 流量的数值,可在系统内部和网络设备间使用。网络优先级用来区分发送、排队以及丢失的数据包
1. net_prio.prioidx:只读文件。它包含一个特有整数值,kernel 使用该整数值作为这个 cgroup 的 内部代表。
2. net_prio.ifpriomap:包含优先级图谱,这些优先级被分配给源于此群组进程的流量以及通过不同 接口离开系统的流量
perf_event
允许使用perf工具来监控cgroup
hugetlb
允许使用大篇幅的虚拟内存页,并且给这些内存页强制设定可用资源量