在机器学习建模过程中,针对不同的问题,需采用不同的模型评估指标。
主要分为两大类:分类、回归。
1、混淆矩阵
2、准确率(Accuracy)
3、错误率(Error rate)
4、精确率(Precision)
5、召回率(Recall)
6、F1 score
7、ROC曲线
8、AUC
9、PR曲线
10、对数损失(log_loss)
11、分类指标的文本报告(classification_report)
1、平均绝对误差(MAE)
2、均方误差(MSE)
3、均方根误差(RMSE)
4、归一化均方根误差(NRMSE)
5、决定系数(R2)
一、分类模型评估指标
1、混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵中的每一行代表实例的
预测类别,每一列代表实例的
真实类别。
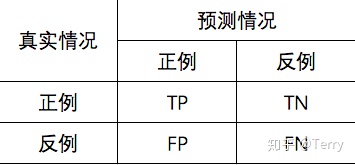
真正(True Positive , TP):被模型预测为正的正样本。
假正(False Positive , FP):被模型预测为正的负样本。
假负(False Negative , FN):被模型预测为负的正样本。
真负(True Negative , TN):被模型预测为负的负样本。
-------------------------------------------------------------------------------------------
真正率(True Positive Rate,TPR)或灵敏度(sensitivity)
TPR=TP/(TP+FN) ===> 正样本预测结果数 / 正样本实际数
-------------------------------------------------------------------------------------------
真负率(True Negative Rate, TNR)或特指度/特异度(specificity)
TNR = TN /(TN + FP) ===> 负样本预测结果数 / 负样本实际数
-------------------------------------------------------------------------------------------
假正率 (False Positive Rate, FPR)
FPR = FP /(FP + TN) ===> 被预测为正的负样本结果数 /负样本实际数
-------------------------------------------------------------------------------------------
假负率(False Negative Rate , FNR)
FNR = FN /(TP + FN) ===> 被预测为负的正样本结果数 / 正样本实际数
2、准确率(Accuracy)
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
#normalize:默认值为True,返回正确分类的比例;如果为False,返回正确分类的样本数
正确率,是最常用的分类性能指标。
Accuracy = (TP+TN)/(TP+FN+FP+TN)
即正确预测的正反例数 /总数
3、错误率(Error rate)
正确率与错误率是分别从正反两方面进行评价的指标,两者数值相加刚好等于1。正确率高,错误率就低;正确率低,错误率就高。
Error rate = (FP+FN)/(TP+FN+FP+TN)
即错误预测的正反例数/总数
4、精确率(Precision)
from sklearn.metrics import precision_score
precision_score(y_true, y_pred, labels=None, pos_label=1, average='binary')
只针对预测正确的正样本,表现为预测为正的里面有多少真正是正的。可理解为查准率。
Precision = TP/(TP+FP)
即正确预测的正例数 /实际正例总数
5、召回率(Recall)
from sklearn.metrics import recall_score
sklearn.metrics.recall_score(y_true, y_pred, labels=None, pos_label=1,average='binary', sample_weight=None)
召回率表现出在实际正样本中,分类器能预测出多少。与真正率相等,可理解为查全率。
Recall = TP/(TP+FN)
即正确预测的正例数 /实际正例总数
6、F1 score
from sklearn.metrics import f1_score
f1_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None)
F1 score 又称 F-Measure,是一个综合评价指标。
F值是精确率和召回率的调和值,更接近于两个数较小的那个,所以精确率和召回率接近时,F值最大。很多推荐系统的评测指标就是用F值的。
2/F1 = 1/Precision + 1/Recall


除了F1分数之外,F2分数和F0.5分数在统计学中也得到大量的应用。其中,F2分数中,召回率的权重高于精确率,而F0.5分数中,精确率的权重高于召回率。
7、ROC曲线
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
y_predict = model.predict(x_test)
y_probs = model.predict_proba(x_test) #模型的预测得分
fpr, tpr, thresholds = roc_curve(y_true,y_score, pos_label=None, sample_weight=None, drop_intermediate=True)
roc_auc = auc(fpr, tpr) #auc为Roc曲线下的面积
#开始画ROC曲线
plt.plot(fpr, tpr, 'b',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.1,1.1])
plt.ylim([-0.1,1.1])
plt.xlabel('False Positive Rate') #横坐标是fpr
plt.ylabel('True Positive Rate') #纵坐标是tpr
plt.title('Receiver operating characteristic example')
plt.show()
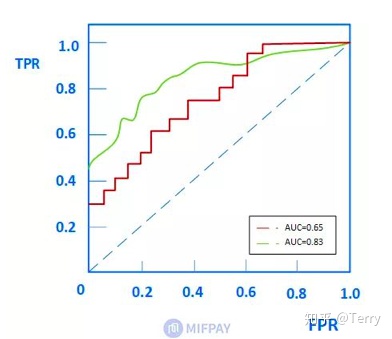
ROC曲线,又称 感受性曲线。
X轴:假正率(FPR)(1-TNR)(1-specificity)
Y轴:真正率(TPR)(sensitivity)
ROC曲线离对角线越近,模型的准确率越低。
8、AUC
from sklearn.metrics import auc
auc(fpr, tpr)
from sklearn.metrics import roc_auc_score #常用
roc_auc_score(y_ture, y_pred)
#直接根据真实值(必须是二值)、预测值(可以是0/1,也可以是proba值)计算出auc值,中间过程的roc计算省略。
AUC(Area Under Curve)被定义为ROC曲线下的面积(ROC的积分),通常大于0.5小于1。随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是 AUC 值。AUC值(面积)越大的分类器,性能越好。
9、PR曲线
# 绘制PR曲线
def PR_curve(y,pred):
pos = np.sum(y == 1)
neg = np.sum(y == 0)
pred_sort = np.sort(pred)[::-1] # 从大到小排序
index = np.argsort(pred)[::-1] # 从大到小排序
y_sort = y[index]
print(y_sort)
Pre = []
Rec = []
for i, item in enumerate(pred_sort):
if i == 0:#因为计算precision的时候分母要用到i,当i为0时会出错,所以单独列出
Pre.append(1)
Rec.append(0)
else:
Pre.append(np.sum((y_sort[:i] == 1)) /i)
Rec.append(np.sum((y_sort[:i] == 1)) / pos)
print(Pre)
print(Rec)
## 画图
plt.plot(Rec, Pre, 'k')
# plt.legend(loc='lower right')
plt.title('Receiver Operating Characteristic')
plt.plot([(0, 0), (1, 1)], 'r--')
plt.xlim([-0.01, 1.01])
plt.ylim([-0.01, 01.01])
plt.ylabel('Precision')
plt.xlabel('Recall')
plt.show()
PR曲线的横坐标是精确率P,纵坐标是召回率R。评价标准和ROC一样,先看平滑不平滑(越平滑越好)。一般来说,在同一测试集,上面的比下面的好(绿线比红线好)。当P和R的值接近时,F1值最大,此时画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好像AUC对于ROC一样。一个数字比一条线更方便调型。

PR曲线下的面积称为AP(Average Precision),表示召回率从0-1的平均精度值。AP可用积分进行计算。
AP面积的不会大于1。PR曲线下的面积越大,模型性能则越好。性能优的模型应是在召回率(R)增长的同时保持精度(P)值都在一个较高的水平,而性能较低的模型往往需要牺牲很多P值才能换来R值的提高。
10、对数损失 log_loss
from sklearn.metrics import log_loss
log_loss(y_true,y_pred)
11、classification_report 分类指标的文本报告
classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息。

二、回归模型评估指标
1、MAE(mean absolute error)平均绝对误差
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_true, y_pred, sample_weight=None, multioutput='uniform_average')

2、MSE(mean squared error)均方误差
from sklearn.metrics import mean_squared_error
mean_squared_error(y_true, y_pred, sample_weight=None, multioutput='uniform_average')
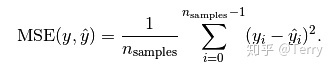
3、RMSE(root mean squared error)均方根误差
from sklearn.metrics import mean_squared_error np.sqrt(mean_squared_error(y_test,y_predict))

4、NRMSE (normalized root mean squared error)归一化均方根误差

5、R2 决定系数
from sklearn.metrics import r2_score
r2_score(y_true, y_pred, sample_weight=None, multioutput='uniform_average')

R2 是多元回归中的回归平方和占总平方和的比例,它是度量多元回归方程中拟合程度的一个统计量,反映了在因变量y的变差中被估计的回归方程所解释的比例。
R2 越接近1,表明回归平方和占总平方和的比例越大,回归线与各观测点越接近,用x的变化来解释y值变差的部分就越多,回归的拟合程度就越好。
注:以上为常用指标,还有部分模型评估指标未赘述······
文章来源:机器学习模型评估指标 - 知乎