写在前面——这次的R语言习题比上次的中级题目做起来舒服一些。花了四五天的时间整理了一下,因为题目太长,所以划分成两篇文章来写。不过还有地方不明白,先挖个坑,之后来填。需要代码文件的私信我即可。
题目原文:http://www.bio-info-trainee.com/3409.html
参考答案:https://www.jianshu.com/p/dd4e285665e1 https://www.jianshu.com/p/dd4e285665e1
参考答案:https://www.jianshu.com/p/c62cbb9e1a2e
下篇指路:https://blog.csdn.net/narutodzx/article/details/119775994
1. 安装一些R包。
数据包: ALL, CLL, pasilla, airway
软件包:limma,DESeq2,clusterProfiler
工具包:reshape2
绘图包:ggplot2
不同领域的R包使用频率不一样,在生物信息学领域,尤其需要掌握bioconductor系列包。
# R包的安装一般分为两种
# 1.对于bioconductor的安装。可在下面的网站中查询包是否属于bioconductor系列
# https://www.bioconductor.org/packages/release/BiocViews.html#___Software
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install(c('ALL','CLL','pasilla','clusterProfiler'))
BiocManager::install(c('airway','DESeq2','edgeR','limma'))
# 2.对于普通包的安装
install.packages("reshape2", "ggplot2")
2. 了解ExpressionSet对象,比如CLL包里面就有data(sCLLex),找到它包含的元素,提取其表达矩阵(使用exprs函数),查看其大小。
- 参考:http://www.bio-info-trainee.com/bioconductor_China/software/limma.html
- 参考:https://github.com/bioconductor-china/basic/blob/master/ExpressionSet.md

文章地址:https://www.bioconductor.org/packages/release/bioc/vignettes/Biobase/inst/doc/ExpressionSetIntroduction.pdf
ExpressionSet 类旨在将多个不同的信息源组合到一个方便的结构中。
ExpressionSet 可以方便地操作(例如,子集化、复制),并且是许多 Bioconductor 函数的输入或输出。
ExpressionSet类包含:
assayData:微阵列表达数据
phenodata:实验样本的描述
featuredata:实验所用芯片或技术的特点
annotation:注释信息
experimentData:描述实验的一种灵活结构
suppressPackageStartupMessages(library(CLL))
data("sCLLex")
sCLLex
# 获得表达矩阵
exprSet <- exprs(sCLLex)
class(exprSet)
dim(exprSet)
#查看样本编号
sampleNames(sCLLex)
#查看所有表型变量
varMetadata(sCLLex)
#查看基因芯片编码
featureNames(sCLLex)[1:100]
# 取sCLLex中phenoData中的data
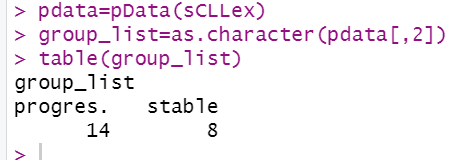
pdata <- pData(sCLLex)
group_list <- as.character(pdata[,2])
table(group_list)

3. 了解 str,head,help函数,作用于第二步提取到的表达矩阵。
# 展示内部结构
str(exprSet)
# 默认展示前6行
head(exprSet)
# 提供帮助文档
help("sCLLex")

4. 安装并了解hgu95av2.db包,看看ls(“package:hgu95av2.db”)后显示的那些变量。
# 使用bioconductor系列包的安装方法
BiocManager::install("hgu95av2.db")
suppressPackageStartupMessages(library(hgu95av2.db))
ls("package:hgu95av2.db")

5. 理解head(toTable(hgu95av2SYMBOL))的用法,找到 TP53 基因对应的探针ID。
# 提供标识符和基因缩写之间的映射(probe_id和symbol的对应关系)
?hgu95av2SYMBOL
# toTable()是S4的一个泛型函数,可以替代as.data.frame()
?toTable
# Lkeys;探针总数是12625,能匹配上的是11683个;
# Rkeys:基因名的总数是62044,实际上只有8776种
# 原因:一般多个探针对应一个基因,取最大表达值探针来作为基因的表达量
summary(hgu95av2SYMBOL)
ids <- toTable(hgu95av2SYMBOL)
# head(ids)
# 正则表达式:https://www.runoob.com/regexp/regexp-syntax.html
ids[grep("^TP53$", ids$symbol),]
# 也可以直接打开ids,在搜索框中搜索TP53(同R语言小作业-中级-第3题)

6. 理解探针与基因的对应关系,总共多少个基因,基因最多对应多少个探针,是哪些基因,是不是因为这些基因很长,所以在其上面设计多个探针呢?
# 探针与基因是多对一的关系
# 对symbol去重然后查看长度,总共有8776个基因
length(unique(ids$symbol))
# 统计symbol中每个基因出现的次数,然后排序取其尾部
# 所得结果即可看出对应探针数目最多的基因
tail(sort(table(ids$symbol)))
# 统计对应不同探针数目的基因
table(sort(table(ids$symbol)))
# 因为基因长度远大于探针长度,所以一般一个基因对应多个探针

7. 第二步提取到的表达矩阵是12625个探针在22个样本的表达量矩阵,找到那些不在hgu95av2.db包收录的对应着SYMBOL的探针。
- 提示:有1165个探针是没有对应基因名字的。
# 统计exprSet中的探针在ids中的存在情况
# FALSE表示不存在,反之亦然
# 在这里为942,而不是1165,怀疑是因为包更新了...
table(rownames(exprSet) %in% ids$probe_id)
# 将exprSet中与ids中不对应的探针提取出来
# %in%是一个二元操作符,返回其左操作数长度的逻辑向量,指示其中的元素是否匹配
new_exprSet <- exprSet[!(rownames(exprSet) %in% ids$probe_id),]
dim(new_exprSet)

8. 过滤表达矩阵,删除那942个没有对应基因名字的探针。
# 将上一题的取反(!)删除即可
exprSet <- exprSet[(rownames(exprSet) %in% ids$probe_id), ]
dim(exprSet)

9. 整合表达矩阵,多个探针对应一个基因的情况下,只保留在所有样本里面平均表达量最大的那个探针。
- 提示,理解 tapply,by,aggregate,split 函数 , 首先对每个基因找到最大表达量的探针。
- 然后根据得到探针去过滤原始表达矩阵。
# 将ids中与exprSet不对应的探针删去
# match返回其第一个参数在第二个参数中的(第一个)匹配位置的向量
ids <- ids[match(rownames(exprSet),ids$probe_id),]
dim(ids)
# match(rownames(exprSet),ids$probe_id)
# head(ids)
# exprSet[1:5,1:5]
# 数据帧被行分割成由一个或多个因子的值子集的数据帧,函数FUN依次应用于每个子集
# 首先根据ids中的symbol,在exprSet中进行匹配,找到对应的行,计算平均表达量
# 挑出平均表达量最大的那一行,将其探针名保留
tmp <- by(exprSet,ids$symbol,function(x) rownames(x)[which.max(rowMeans(x))])
tmp[1:20]
# 将tmp转为字符型
probes <- as.character(tmp)
# 保留在所有样本里面平均表达量最大的那个探针
exprSet <- exprSet[rownames(exprSet) %in% probes, ]
dim(exprSet)
dim(ids)

# 详细介绍一下by那一步
# 这里取ids中按symbol排序的前两个基因为例
# ids[,2]=='AADAC'会返回逻辑值,再与exprSet进行匹配
exprSet[ids[,2]=='AADAC',]
exprSet[ids[,2]=='AAK1',]
str(exprSet[ids[,2]=='AADAC',])
str(exprSet[ids[,2]=='AAK1',])
# 匹配AADAC时,因为只有对应一个探针,所以维度跟其他多对一的不同
# 在这里报错了,但是放在by中能运行,可能自动给添加了维度,这里不明白...
rowMeans(exprSet[ids[,2]=='AADAC',])
rowMeans(exprSet[ids[,2]=='AAK1',])
which.max(rowMeans(exprSet[ids[,2]=='AADAC',]))
which.max(rowMeans(exprSet[ids[,2]=='AAK1',]))
str(which.max(rowMeans(exprSet[ids[,2]=='AAK1',])))
rownames(exprSet[ids[,2]=='AAK1',])[which.max(rowMeans(exprSet[ids[,2]=='AAK1',]))]
# 这里其实最主要依据就是ids中的基因(symbol)与探针(probe_id)的对应关系
# 如果是一对多,则对多的探针求平均表达量,然后保留最大的那个
# 依次对所有基因进行操作即可


10. 把过滤后的表达矩阵更改行名为基因的symbol,因为这个时候探针和基因是一对一关系了。
# 注意此时exprSet和ids的行数还不同,需要把ids中多余的行去除
# 法一
ids <- ids[match(rownames(exprSet),ids$probe_id),]
dim(ids)
rownames(exprSet) <- ids$symbol
exprSet[1:5, 1:5]
# 法二,这个方法可以不用改变ids
rownames(exprSet) <- ids[match(rownames(exprSet),ids$probe_id),2]

11. 对第10步得到的表达矩阵进行探索,先画第一个样本的所有基因的表达量的boxplot,hist,density,然后画所有样本的这些图。
- 参考:http://bio-info-trainee.com/tmp/basic_visualization_for_expression_matrix.html
- 理解ggplot2的绘图语法,数据和图形元素的映射关系。
# 整理数据
library(reshape2)
m_exprSet <- melt(exprSet)
head(m_exprSet)
colnames(m_exprSet) <- c("symbol", "sample", "value")
head(m_exprSet)
m_exprSet$group <- rep(group_list, each = nrow(exprSet))
head(m_exprSet)

library(ggplot2)
# 单独画一个sample的图
ggplot(m_exprSet[m_exprSet[,2]=="CLL11.CEL", ], aes(x = sample, y = value, fill = group)) + geom_boxplot()
# 直接把所有sample都放在一起画
ggplot(m_exprSet, aes(x = sample, y = value, fill = group)) + geom_boxplot()
ggplot(m_exprSet, aes(x = sample, y = value, fill = group)) + geom_violin()
ggplot(m_exprSet, aes(x = value, fill = group)) + geom_histogram(bins = 200)
ggplot(m_exprSet, aes(x = value, fill = group)) + geom_histogram(bins = 200) + facet_wrap(vars(sample), nrow = 4)
ggplot(m_exprSet, aes(x = value, col = group)) + geom_density()
ggplot(m_exprSet, aes(x = value, col = group)) + geom_density() + facet_wrap(~sample, nrow = 4)







# 箱线图美化
p <- ggplot(m_exprSet, aes(x = sample, y = value, fill = group)) + geom_boxplot()
# 计算value的平均值,并以点的形式加入图中
# fun.y被抛弃了,现在流行快乐(手动狗头)
p <- p + stat_summary(fun="mean", geom="point", shape=23, size=3, fill="red")
# 加个经典的暗光ggplot2主题,虽然我没看出来有啥变化
p <- p + theme_set(theme_set(theme_bw(base_size=20)))
# 把字体设置为粗体,修改一下横坐标的显示,把标题置空
p <- p + theme(text=element_text(face='bold'), axis.text.x=element_text(angle=30,hjust=1), axis.title=element_blank())
print(p)
