前言
hello兄弟们,今天没事干也不晓得更什么内容.就把上次和大家说的可以采用cookies登录12306的方法告诉大家。这个功能熟练了的话还是比较简单的,毕竟可以直接通过pickle(建议大家可以自行搜索下吓唬这个库的功能)获取到cookie的值
页面分析
对于登录模块的页面分析前面的文章也和大家分享过了,就不在这里多说。我本来的思路是设计一个判定来检测本地是否保存有cookie文件。有的话直接获取内部cookie数据登录,没有的话就打开浏览器,由用户扫码登录,然后获取cookie值。但是在扫码登录这一模块出现了问题,在手机上确认登录后网页是不做跳转的,所以我就更换为发送用户密码的方式登录。
代码设计
代码基本上是基于前面文章的自动购票源码改写的,我在这里暂时只添加了判断登录模块,后面的购票暂时未改动。盆友们可以把两篇的源码自行结合,自己尝试修改购票的功能,争取能把‘购’改成‘抢’。
 我们先看第一部分代码
我们先看第一部分代码
if __name__ == '__main__':
opt = Options()
opt.add_experimental_option('excludeSwitches', ['enable-automation']) # 去除浏览器顶部显示受自动化程序控制
opt.add_experimental_option('detach', True) # 规避程序运行完自动退出浏览器
web = Chrome(options=opt)
web.get('https://kyfw.12306.cn/otn/resources/login.html')
# 解除浏览器特征识别selenium
script = 'Object.defineProperty(navigator,"webdriver", {get: () => false,});'
web.execute_script(script)
user = '' # 此处输入账号
pwd = '' # 此处输入密码
首先是对浏览器做一些基本处理,定义了用户名,密码参数。这就是最开始的准备行动。然后我们就要开始加入一个判定了
if __name__ == '__main__':
opt = Options()
opt.add_experimental_option('excludeSwitches', ['enable-automation']) # 去除浏览器顶部显示受自动化程序控制
opt.add_experimental_option('detach', True) # 规避程序运行完自动退出浏览器
web = Chrome(options=opt)
web.get('https://kyfw.12306.cn/otn/resources/login.html')
# 解除浏览器特征识别selenium
script = 'Object.defineProperty(navigator,"webdriver", {get: () => false,});'
web.execute_script(script)
user = '' # 此处输入账号
pwd = '' # 此处输入密码
if not os.path.exists('./12306cookies.pkl'):
login(user, pwd)
web.refresh()
else:
cookies_login()
web.refresh()
在判断中我们首先检测是否为首次运行,通过检测是否存在12306cookies.pkl文件进行判断。如果为首次登录就开启浏览器登录,不是就开启cookie登录。
那么我们就要开始修改浏览器登录函数login(user,pwd)了
# 定义登录方法
def login(user, pwd):
login_choice = web.find_element(By.XPATH, '//*[@id="toolbar_Div"]/div[2]/div[2]/ul/li[1]')
# 点击账号密码登录方式
login_choice.click()
username = web.find_element(By.XPATH, '//*[@id="J-userName"]') # 向账号框传入账号信息
passwd = web.find_element(By.XPATH, '//*[@id="J-password"]') # 向密码框传入密码
username.click()
username.send_keys(user)
passwd.click()
passwd.send_keys(pwd)
# 定位到登录按钮并点击
web.find_element(By.XPATH, '//*[@id="J-login"]').click()
# 设置显示等待直到滑块的span标签被定位到
WebDriverWait(web, 2, 0.5).until(EC.presence_of_element_located((By.ID, 'nc_1_n1z')))
span = web.find_element(By.ID, 'nc_1_n1z')
action = ActionChains(web)
action.click_and_hold(span).move_by_offset(300, 0).perform() # click_and_hold代表点击并保持点击动作。move_by_offset(x, y),其中x代表水平移动距离,y代表垂直移动距离
WebDriverWait(web, 10, 1).until(EC.url_to_be('https://kyfw.12306.cn/otn/view/index.html'))
pickle.dump(web.get_cookies(), open('./12306cookies.pkl', 'wb'))
print('cookies保存成功')
其实对比前文就只是在绕过登录验证后做了一个显示等待并把cookie信息保存到12306cookies.pkl文件中。我这里给大家看下运行效果
可以看到此时我的文件目录下是没有12306cookies.pkl文件的,所以代码运行效果如下
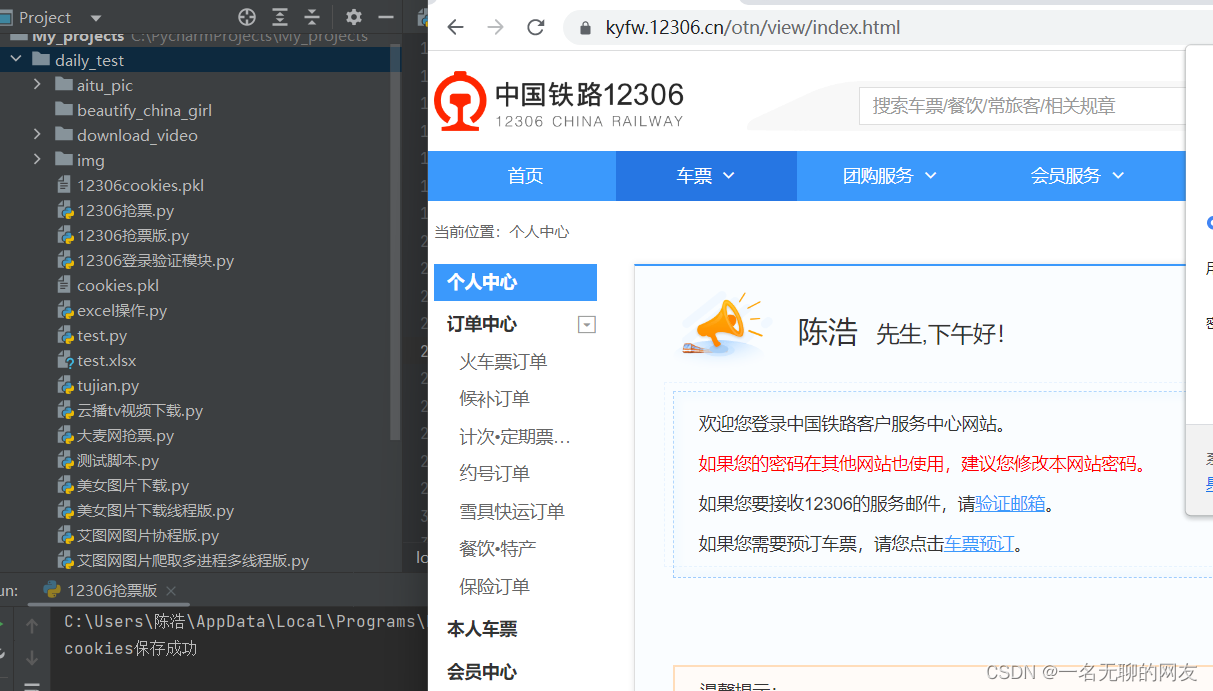
在登录功能事项,目录下保存了我的cookie信息。到了这一步首次登录的功能就实现了。那么我们把目光放到cookie登录上
代码如下
def cookies_login():
cookies = pickle.load(open('./12306cookies.pkl', 'rb'))
for cookie in cookies:
cookie_dic = {
'domain': '.12306.cn',
'name': cookie.get('name'),
'value': cookie.get('value')
}
web.add_cookie(cookie_dic)
web.get('https://kyfw.12306.cn/otn/leftTicket/init')
print('cookies载入成功')
其实操作非常简单,就是加载保存在本地的cookie文件,获取其中保存的关键字段,并使web加载得到的关键字段。我们要注意这里请求的url就不再是登录页面了。而是直接请求到的购票页面。我运行下代码给大家看一下效果
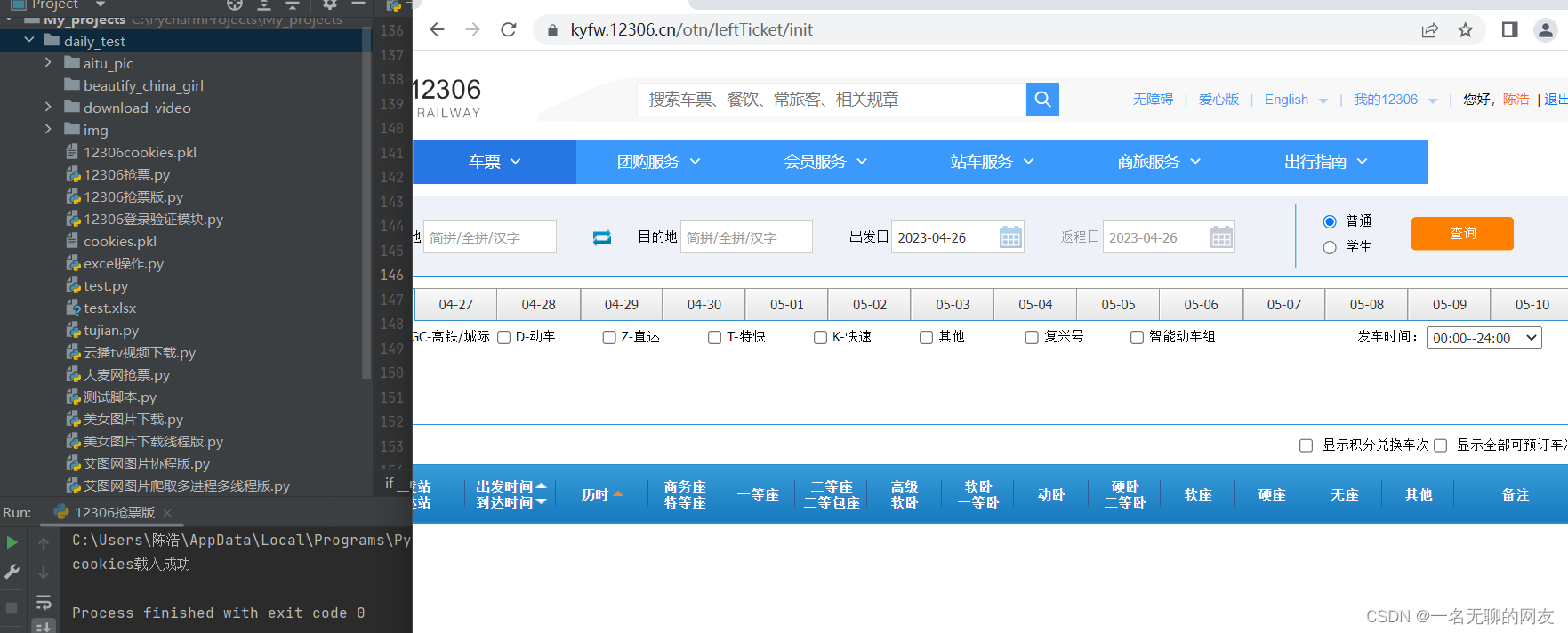 可以看到运行效果非常好,右上角也可以看到我们直接通过本人信息进入到了购票界面。相比前文的普通登录购票要省去很多步骤与时间。时间空余的盆友们可以开始动手试试了。
可以看到运行效果非常好,右上角也可以看到我们直接通过本人信息进入到了购票界面。相比前文的普通登录购票要省去很多步骤与时间。时间空余的盆友们可以开始动手试试了。
关于后面的‘抢票’功能的话,我只能说我还没有深入研究,大家可以自己深入研究研究,但最好也别太深入

另外五一假期临近,后面几天我的课还有点多。假期还要去和好基友happy,假期过后再来和兄弟们交流。大家可以这几天自己动手练练。假期过后我也可能会接着‘研究研究’。就说这么多,五一happy,没事干的朋友也不要久坐于电脑面前,难得的假期记得活动活动。祝大家五一快乐,记得点个小赞赞哦。
