Elasticsearch实战- 聚合搜索Aggs聚合及Count,Avg操作
1.聚合搜索 bucket 桶及metric分析计算
- bucket 就是聚合搜索时候的分组,类似Mysql的GroupBy, 比如统计销售部 有张三,李四, 技术部有 王五,赵六 ,group by 部门 部门就是分组 桶 bucket
- metric 就是对桶内的数据进行统计分析,比如 销售部 有2个员工, 技术部有2个员工, 对桶内数据进行统计分析 如 求和,最大值,最小值,平均值 等分析就是 metric
1.1 准备数据
POST /testcopy/_bulk
{"index":{"_id": 1}}
{"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article"}
{"index":{"_id": 2}}
{"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"}
{"index":{"_id": 3}}
{ "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"}
{"index":{"_id": 4}}
{"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"}
{"index":{"_id": 5}}
{ "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"}
{"index":{"_id": 6}}
{"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer"}
{"index":{"_id": 7}}
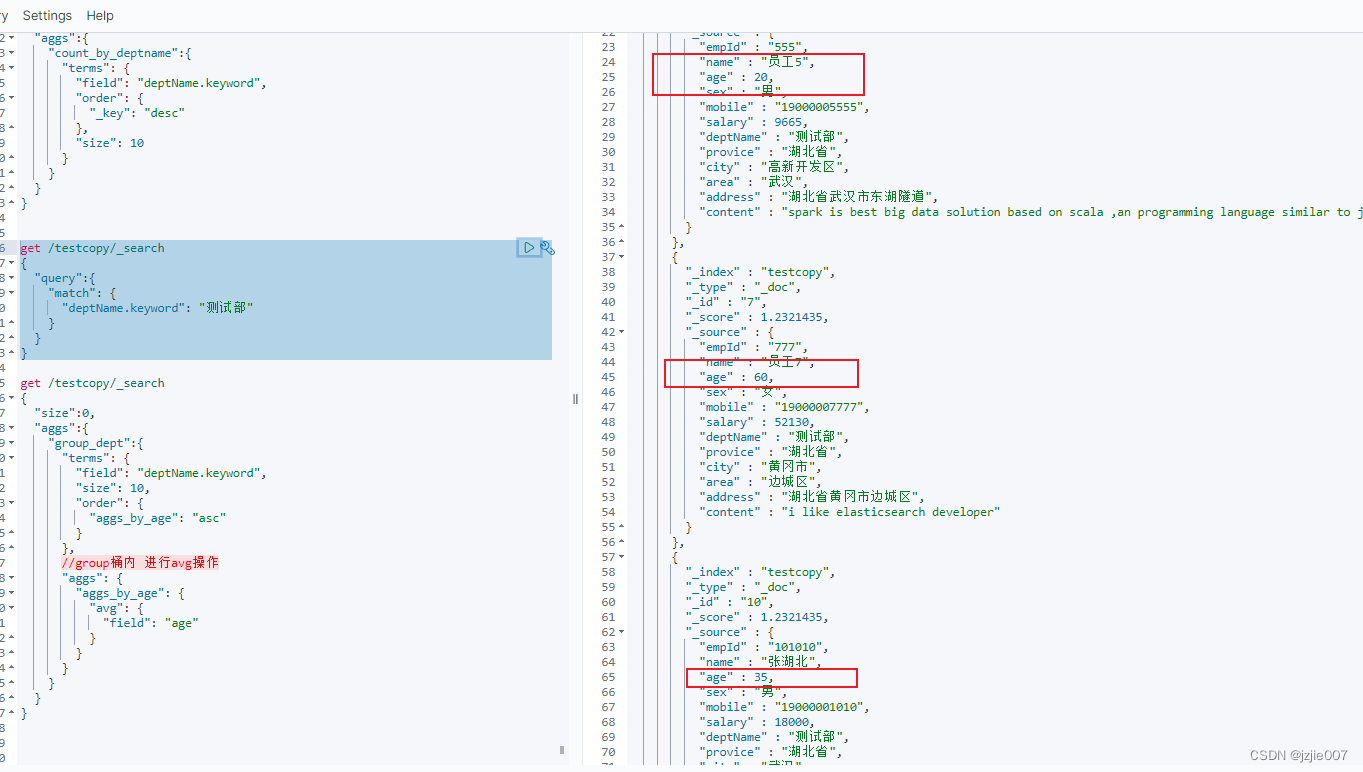
{"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer"}
{"index":{"_id": 8}}
{"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language"}
{"index":{"_id": 9}}
{"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer"}
{"index":{"_id": 10}}
{"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch"}
{"index":{"_id": 11}}
{"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java "}
{"index":{"_id": 12}}
{"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good"}
{"index":{"_id": 13}}
{"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java "}
{"index":{"_id": 14}}
{"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++"}
{"index":{"_id": 15}}
{"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good"}
2.count 统计计数
2.1统计 每个部门有多少人
#统计每个部门多少人
get /testcopy/_search
{
"size":0,
"aggs":{
"count_by_deptname":{
"terms": {
"field": "deptName",
"order": {
"_key": "desc"
},
"size": 10
}
}
}
}
统计出错
“reason” : “Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [deptName] in order to load field data by uninverting the inverted index. Note that this can use significant memory.”
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [deptName] in order to load field data by uninverting the inverted index. Note that this can use significant memory."
}
然后 排查发现是 因为 我要统计的部门 deptName字段 是text类习惯, text类型 没有设置 fielddata=true, 且被用于 aggs聚合排序中,所以要给 需要统计的字段进行 设置 fielddata
解决办法
#执行 设置 fielddata
PUT testcopy/_mapping
{
"properties": {
"deptName": {
"type": "text",
"fielddata": true
}
}
}
查询结果, 可以查处结果,但是不是自己想要的,因为 销售部 被拆分成了 “销”,“售”,"部"单独做了统计,而现在我是要 整个销售部的 统计

修改查询语句, 把整个 deptName 当作keyword 不分词处理查询
get /testcopy/_search
{
"size":0,
"aggs":{
"count_by_deptname":{
"terms": {
"field": "deptName.keyword",
"order": {
"_key": "desc"
},
"size": 10
}
}
}
}
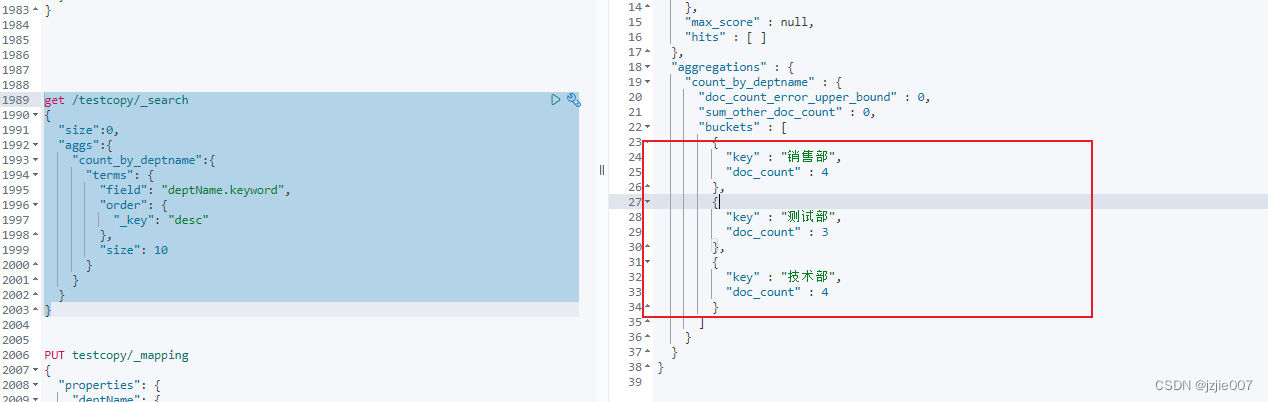
查看结果
是我们想要的, 销售部 4人, 测试部 3人, 技术部 4人
3.Avg求平均,先分组count,然后在求平均数avg
3.1 统计每个部门的人数及平均年龄
求每个部门的 人数及 大家平均的年龄, 就是我先要对部门进行分组, 形成一个桶, 然后对桶内的数据 进行求平均数, 然后按照 年龄的升序排列返回结果
#group_dept组内 再次进行 aggs
get /testcopy/_search
{
"size":0,
"aggs":{
"group_dept":{
"terms": {
"field": "deptName.keyword",
"size": 10,
"order": {
"aggs_by_age": "asc"
}
},
//group桶内 进行avg操作
"aggs": {
"aggs_by_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
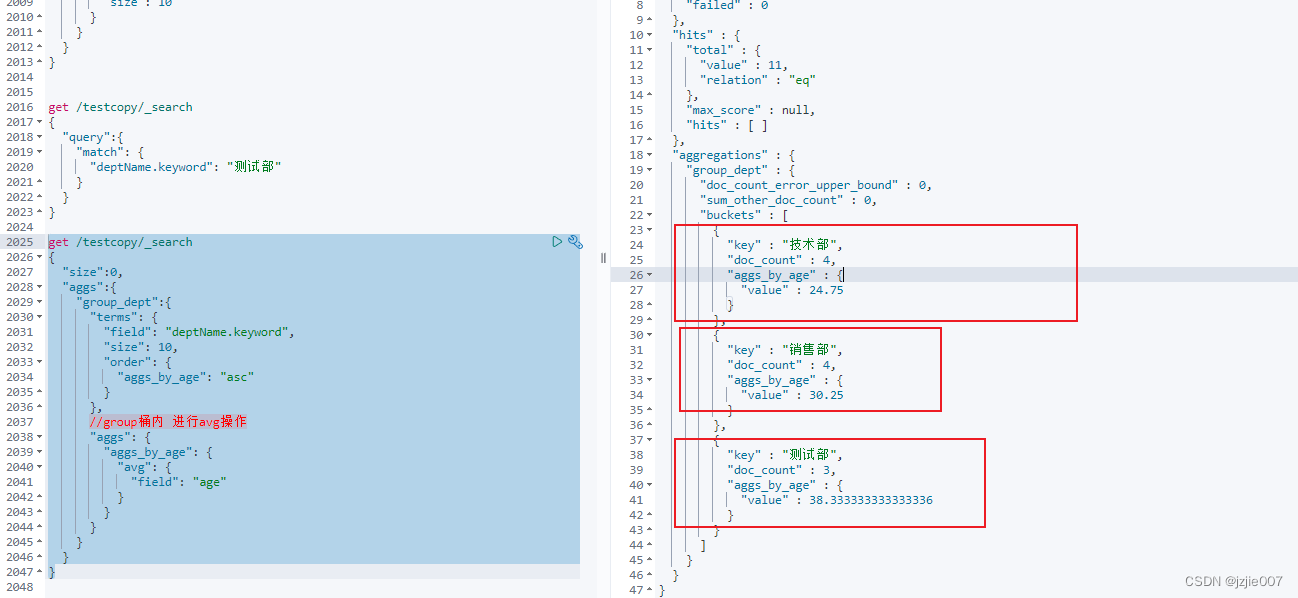
查看结果,结果是按照 平均年龄升序 进行排列
- 技术部 4人,平均年龄 24.75
- 销售部 4人,平均年龄 30.25
- 测试部 3 人,平均年龄 38.33
我们查一下 测试部 ,看看统计是否准确, avg平均年龄计算是否准确
#查看 销售部的人
get /testcopy/_search
{
"query":{
"match": {
"deptName.keyword": "测试部"
}
}
}
查看结果 测试部 3人, 年龄 20+60+35 = 115 , 平均年龄 115 / 3 = 38.33 计算正确
3.2 嵌套分组 先分组,然后组内在分组 如何实现
比如 现在 我想 统计 销售部 下面 有哪些 省份,每个省份有多少人 即 第一次分组 以 销售部分组, 然后再销售部分组内部, 然后再以 provice 省份做分组, 我们先把 provice 要进行 aggs 的字段 加上 fielddata设置
#给 provice 要聚合的字段 加上 fielddata 配置
PUT testcopy/_mapping
{
"properties": {
"provice": {
"type": "text",
"fielddata": true
}
}
}
双重分组, 组内再次进行分组如何实现
#部门分组后, 再桶内 再对省份 分组
get /testcopy/_search
{
"size":0,
"aggs":{
"group_by_dept":{
"terms": {
"field": "deptName.keyword",
"size": 10
},
"aggs": {
"provice_count": {
"terms": {
"field": "provice.keyword",
"size": 10
}
}
}
}
}
}
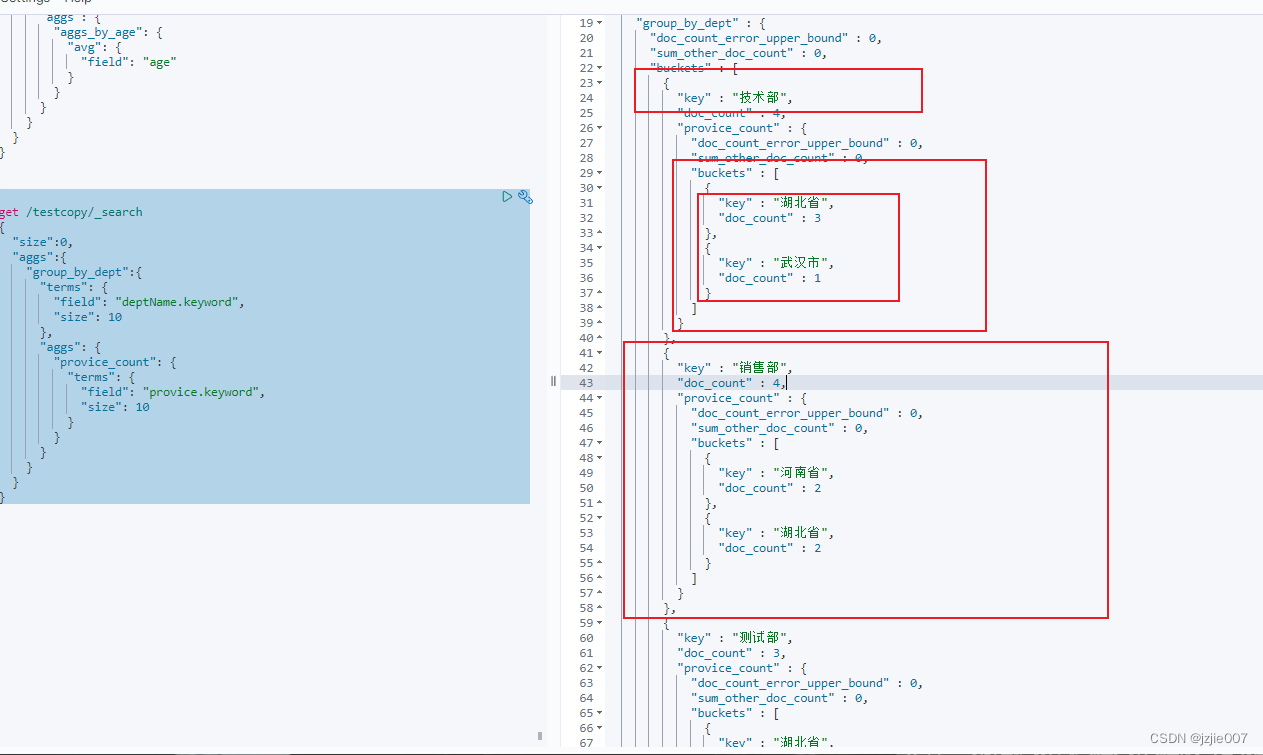
查看结果, 满足我们的需求
- 技术部 4人下面 分了 湖北省 和 武汉市(省份), 然后湖北省 3个人, 武汉市 1个人
- 销售部 4人下面分了 湖北省 和 河南省, 然后 湖北省2人, 河南省 2人
- 测试部 3人,全部都是 湖北省 的
3.3 嵌套分组内 再进行 avg计算
上面我们进行了嵌套分组, 先以部门 分组, 然后以 省份 分组, 现在我想再加一个统计分许, 统计 每个部门,每个省份的人的 平均年龄
等于是 3步操作, 比上一个更加复杂了
- 先分组 部门 deptName
- 在分组 省份 provice
- 然后再aggs 统计avg年龄
#嵌套多层 进行 avg 求平均数
get /testcopy/_search
{
"size":0,
"aggs":{
"group_by_dept":{
"terms": {
"field": "deptName.keyword",
"size": 10
},
//deptname 分组内 进行 aggs
"aggs": {
"group_by_provice": {
"terms": {
"field": "provice.keyword",
"size": 10
},
//provice 分组内 进行 aggs 求avg
"aggs": {
"avg_by_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
}
}
我们查看下结果
技术部 下面 湖北省 3人, 平均年龄 23, 武汉市 1人,平均年龄 30
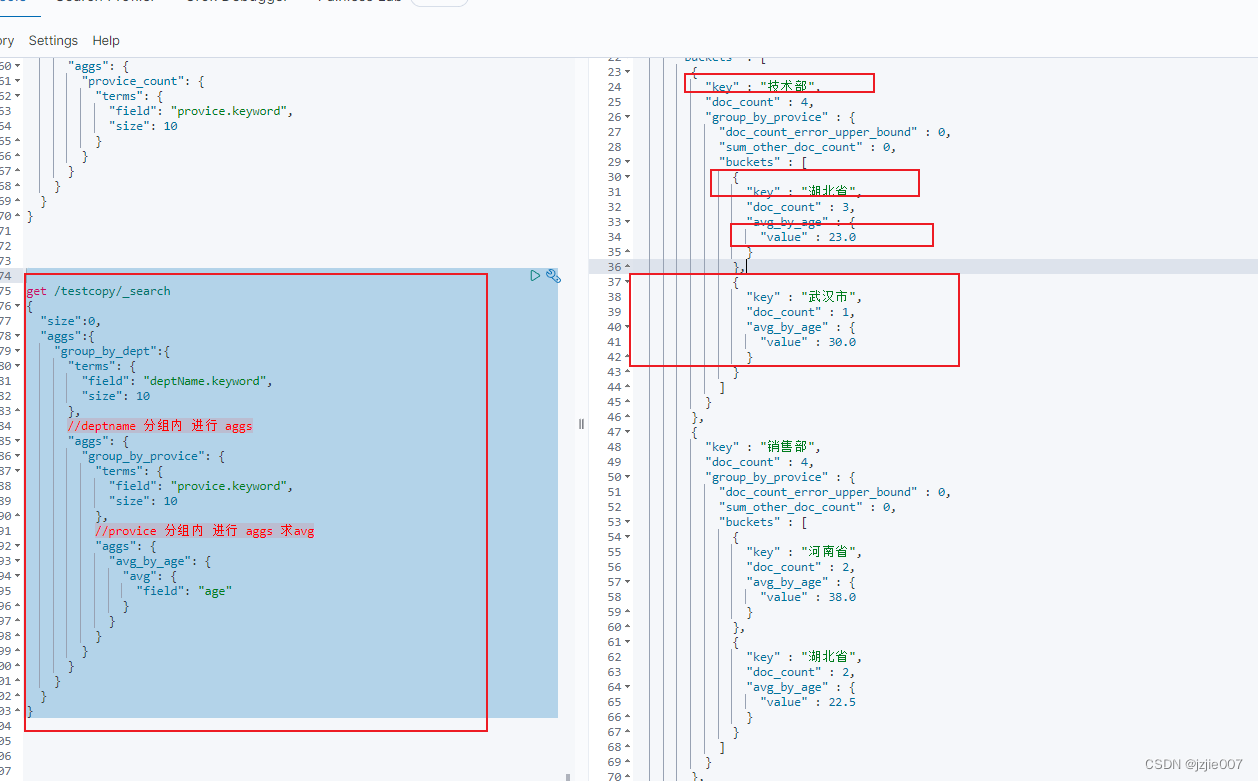
我们现在搜一下 技术部的 人, 看下年龄分布 是不是上面聚合的结果
#查 技术部, 湖北省的人 的年龄
get /testcopy/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"deptName.keyword": "技术部"
}
},
{
"match": {
"provice": "湖北省"
}
}
]
}
},
"_source":["deptName","provice","age"]
}
查询结果 ( 20+30+19 )= 69 / 3 = 23 ,平均年龄就是23 ,上面的聚合结果是准确的
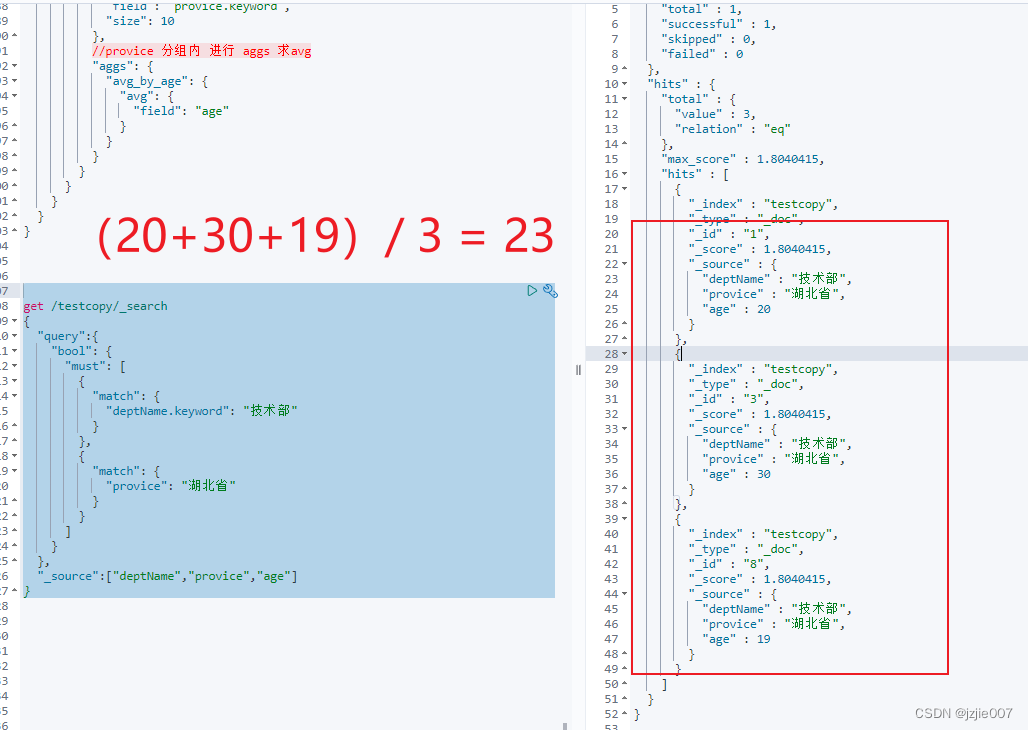
至此 我们已经学习了 聚合搜索 aggs 的基本用法, count , avg等 聚合操作, 下一篇,我们介绍下 更加复杂的聚合操作