牛顿法通常都是用来寻找一个根,同时也可以理解为最大化目标函数的局部二次近似。设我们的目标函数为f(x),那么一个关于x0的二次近似就有:

我们用f进行匹配:

可以得到:

如果b<0,g的最大值为a,得到更新规则:

这是牛顿法在最优化方面的表述,但是一旦 ,牛顿法就不适用了,我们必须要使用其他的优化算法。
,牛顿法就不适用了,我们必须要使用其他的优化算法。
下面给出一种非二次的变形:
在Dirichlet分布的最大似然估计中,我们接触到目标函数:

这个目标函数是凸函数,但是牛顿法在计算负的x时仍然不适用。我们可以使用一种更快更稳定的局部近似算法:
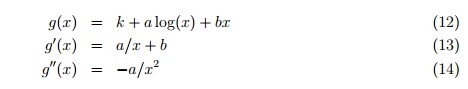
我们用f进行匹配:

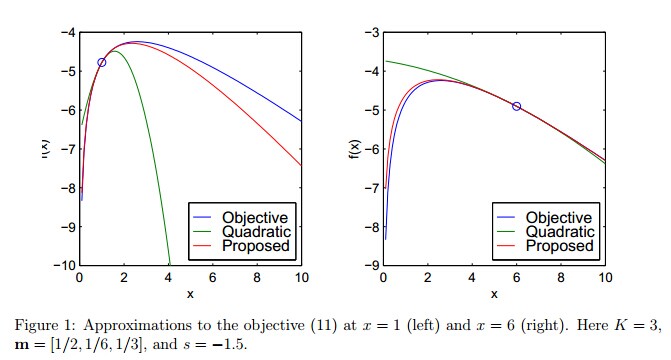
Figure 1给出这种近似相比于二次近似的高性能:
既然对所有x来说都有 ,我们知道
,我们知道 ,如果还有b < 0,那么g的最大值就是−a/b,得到更新规则:
,如果还有b < 0,那么g的最大值就是−a/b,得到更新规则:

如果 ,就要用到其他的方法。
,就要用到其他的方法。
这种更新规则并不是简单地改变f的参数化。比如,如果我们令f(x) = f(1/y),并在y上使用二次近似,更新规则为:

既然x必须是正的,可以令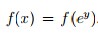 ,更新规则为:
,更新规则为:
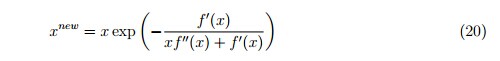
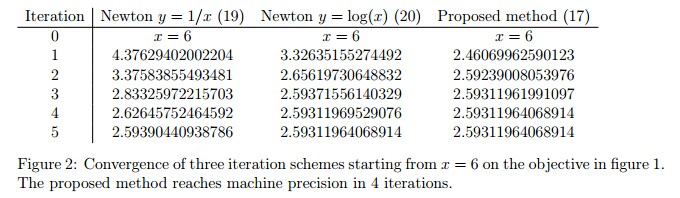
Figure 2比较了这三种更新规则的收敛率:
当然牛顿法的迭代方式可以推向更高的维:

H被称为Hessian矩阵,有这样的定义:
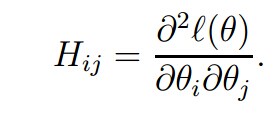
另外,为了控制收敛的速度,我们引入步长r,r>0:

牛顿法通常比梯度下降收敛得更快,在靠近最优解的时候,需要更少的迭代次数。当然,牛顿法的每一次迭代都比梯度下降代价更高。为了避免计算高维的H的逆,我们转而计算向量
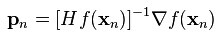
当牛顿法被用来处理logistic regression的最大似然函数ℓ(θ)的时候,这种方法被称为:Fisher scoring(渔民得分?)