在之前的文章中,我介绍了概率论的基本概念和基本公理。数学家会为这些感到兴奋,但在实践中,概率论中比较常用的是概率分布。
概率分布用于许多领域,但我们很少看到相应的解释。通常作者会假定读者已经了解概率分布了。本文将尝试解释什么是概率分布。
什么是概率分布?
回忆一下,随机变量是值为一个随机事件的结果的变量(如果不知所云,请温习下本系列的第一篇)。例如,掷骰子的点数或抛硬币的结果是随机变量。
概率分布是随机变量所有可能结果及其相应概率的列表。
例如,均匀6面骰的概率分布为:

更明确地说,这是一个有限支持的离散单元概率分布的例子。这读起来比较拗口,所以让我分解这一表述,逐步理解。
离散(discrete) 这意味着如果我选择任意两个连续的结果,我无法取得位于两者之间的结果。例如,考虑投掷六面骰的结果1点和2点,我没法得到两者之间的点数(例如,我没法掷出1.5点)。在数学上,我们会说,结果列表是可数的(不过我不会进一步定义可数集和不可数集了,否则就没完没了了)。你大概可以猜想,当我们涉及连续(continuous)概率分布时,这一点会不成立。
单元(univariate) 这意味着我们只有一个(随机)变量。在这一情形下,我们只有掷骰的结果。相反,如果我们有不止一个变量,那我们称其为多元分布(multivariate distribution)。如果我们有两个变量,那么这一多元分布的特例称为二元分布(bivariate distribution)。
有限支持(finite support) 这意味着结果的数目是有限的。基本上,支持是定义概率分布的结果。所以,在我们的例子中,支持是1、2、3、4、5、6. 由于这些值不是无限的,所以我们说这是有限支持的概率分布。
函数入门
我们为何谈论函数?
在上面的投掷六面骰的例子中,只有六种可能的结果,所以我们可以在一个表格中写下整个概率分布。但在很多场景中,结果的数量可能很大,用表格罗列会很枯燥乏味。更糟的是,可能结果的数目也许是无限的,在那样的情形下,就没法编写表格了。
为了免去为每个分布编写表格的麻烦,我们可以转而定义一个函数。函数允许我们简洁地定义一个概率分布。
所以,让我们首先介绍一般意义上的函数,接着再介绍用于概率分布的函数。
什么是函数?
从一个非常抽象的层次上说,函数是一个接受输入并返回输出的盒子。在大多数情况下,函数事实上需要对输入进行一些处理,以得到有用的输出。
让我们自行定义一个函数。比方说,这个函数接受一个数字作为输入,在输入数字上加2,并返回新数字作为输出,如下图所示:
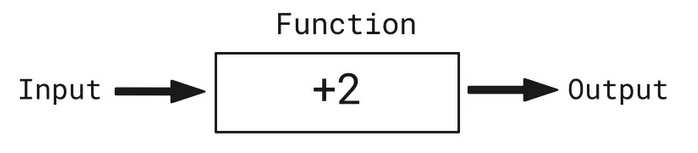
所以,如果输入是5,我们的函数会加上2,并返回输出5 + 2 = 7
函数记法
给我们想要创建的所有函数画示意图是件枯燥乏味的工作。我们转而使用符号/字母,以便更简洁地表示函数。我们用“x”替换单词“input”(输入),用“f”替换单词“function”(函数),用“f(x)”替换单词“输出”。所以,上面的示意图现在变成这样了:
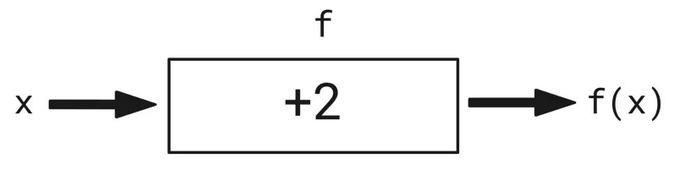
这要好一点,不过,需要画示意图表示函数做了什么这个问题仍然存在。数学家可不想浪费宝贵的精力画盒子,所以发明了更好的表示函数的方式,什么也不用画。在数学上,我们的函数可以定义为:
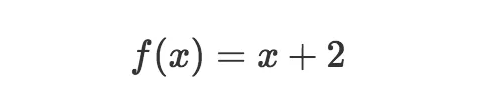
这和上面的示意图是等价的,因为我们可以明确看到函数的输入是x,我们的函数称为f,并且我们知道函数在输入上加2,并返回x + 2作为输出。
值得注意的是,函数名和输入的字母选择是任意的。我可以说输入是“a”,将函数称为“add_two”(加二):
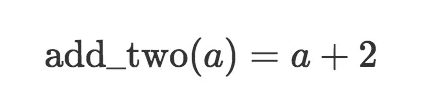
这和之前的函数定义完全等价。
这里关键的一点是,有了函数定义,我们可以看到如何转换任何输入。给定函数f(x) = x + 2,我们会知道如果输入是10做什么,或者如果输入是10000做什么。所以我们不用像之前那样列出一个表格。
这里需要指出的是,我们即将使用的函数的输入和输出都是数字。然而,函数可以接受任何你喜欢的东西作为输入,并输出任何你喜欢的东西(甚至什么都不输出)。例如,我们可以在编程语言中编写一个函数,接受一个文本字符串作为输入,并输出字符串的第一个字母。下面是用Python编程语言写的一个例子:
def get_first_letter(my_string):
return my_string[0]
get_first_letter('Hello World') # 结果为 'H'
译者注:这里仅为示例,实际定义函数的时候还需要考虑输入字符串为空的情况,需要捕获IndexError异常或先行判断字符串是否为空。
用图像表示函数
函数的主要优势之一是让我们知道如何转换任何输入,所以我们可以利用这一知识可视化函数。回到之前的例子f(x) = x + 2. 它的图像是这样的:

底下的横轴表示输入数字,相应地,左侧的纵轴表示输出值f(x) = x + 2. 例如,我们看到,表示函数的蓝线穿过了x = 1处的(白色)纵线和f(x) = 3处的(白色)横线。这从图像上显示了f(1) = 1 + 2 = 3.
函数的参数
函数最重要的特征之一是参数。参数是函数内部不必作为输入传入的数字。在我们的例子f(x) = x + 2中,数字“2”是一个参数,因为我们需要它来定义函数,但没有将它纳入函数的输入。
参数之所以重要,是因为它们直接决定输出。例如,定义另一个函数h(x) = x + 3. 函数f(x) = x + 2和新定义的函数h(x) = x + 3之间唯一的区别是参数值(新函数的参数是“3”而不是“2”)。这一差异意味着相同输入得到的输出完全不同。让我们看下相应的图像:

参数可以算是概率(分布)函数最重要的特征了,因为它们定义了函数的输出,告诉我们随机过程得到特定结果的似然。在数据科学问题中,我们常常试图估计参数,我之前曾经介绍过两种估计参数的方法:最大似然估计和贝叶斯推断。
现在我们可以用函数语言讨论概率分布了。
概率质量函数:离散概率分布
当我们使用概率函数描述离散概率分布时,我们将其称为概率质量函数(probability mass function),通常缩写为pmf.
还记得我们在这个系列的第一篇提到的随机变量概率的记法吗?我们将随机变量记为大写的X,而将变量的值记为小写的x,随机变量概率则记为P(X=x). 因此,如果我们的随机变量是投掷骰子的点数,我们可以将掷出3点的概率记为P(X=3) = 1/6.
概率质量函数(记为“f”)返回结果的概率:
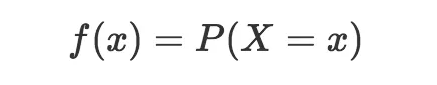
我知道这里开始有点吓人,但请多容忍一点数学。上面的公式不过是表明,概率质量函数“f”返回结果x的概率。
所以让我们回到均匀6面骰的例子(你大概已经厌烦这个例子了吧?)。概率质量函数f不过是返回结果的概率。因此掷出三点的概率是f(3) = 1/6.
由于概率质量函数返回概率,所以它必须遵循我在前一篇描述的概率法则(公理)。也就是说,概率质量函数输出0到1之间的值(含),而所有结果的概率质量函数输出之和等于1. 在数学上,我们可以将这两个条件表达为:

所以说,我们可以用表格和函数表示离散概率分布。我们也可以用图形表示投掷骰子这个例子:

离散概率分布示例:伯努利分布
有些概率分布出现得非常频繁,人们对它们进行了全面的研究,并命名了这些概率分布。伯努利分布(Bernoulli distribution)就是一个例子。它是描述有两种可能结果的过程的概率分布,比如抛硬币。
伯努利分布的概率质量函数为:
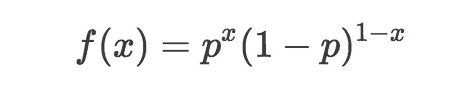
这里,x表示结果,值为1或0. 所以我们可以说正面 = 1,反面 = 0. p是表示结果为1的概率的参数。所以在扔均匀硬币问题中,扔出正面或反面的概率是0.5,因此我们令p = 0.5.
我们经常想要明确标出概率质量函数中包含的参数,所以伯努利分布的概率质量函数可以表示为:
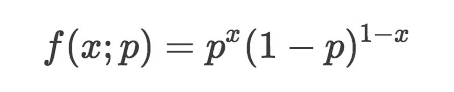
注意,这里我们使用分号隔开输入变量和参数。
概率密度函数:连续概率分布
有时我们关心具有连续结果的随机变量的概率。例如,从某个族群中随机抽取的成人的身高,出租车司机等待下一个乘客的时间。在这些例子中,用连续概率分布描述随机变量更合适。
当我们使用概率函数描述连续概率分布时,我们称其为概率密度函数(probability density function),通常缩写为pdf.
概率密度函数的概念比概率质量函数要稍微复杂一点,不过别担心,我们能够理解。我觉得先讲一个连续概率分布的例子,再讨论连续概率分布的性质,比较容易理解。
连续概率分布示例:正态分布
正态分布大概是所有概率和统计学问题中最常见的分布了。它如此常见的原因之一是中央极限定理。本文不会深入介绍这个定理,不过你可以参考Carson Forter写的博客文章The Only Theorem Data Scientists Need To Know,其中解释了这个定理是什么,还有它和正态分布的关系。
正态分布的概率密度函数定义为:

其中,参数(分号后的符号)μ表示均值(分布的中心点),σ表示标准差(分布的散布程度)。
如果我们将均值设为零(μ=0),标准差设为1(σ=1),那么我们将得到如下图所示的分布:

正态分布是一个无限支持的连续单元概率分布。无限支持意味着我们可以为负无穷大到正无穷大之前的所有结果计算概率密度函数值。在数学上,我们有时称其支持整条实直线(vhole real line)
连续概率分布性质
首先需要注意的是纵轴从0开始向上延伸。这是概率密度函数需要遵守的规则。概率密度函数的任何输出值大于等于零,或者说,输出非负:
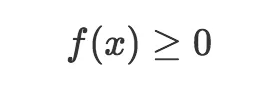
然而,和概率质量函数不同,概率密度函数的输出不是概率值。这是一个极为重要的差别。
要从概率密度函数求得概率,我们需要找到曲线下的面积。例如,假设我们的样本分布均值 = 3,标准差 = 1,我们在下图中画出结果位于0到1之间的概率:

数学上表达为:
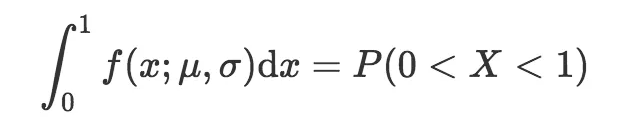
上式的意思是,概率密度函数0到1之间的积分(等式左边)等于随机变量的结果位于0到1之间的概率(等式右边)。
原谅我没有明确地介绍积分是什么,积分是如何工作的(我在本系列的边缘化一文中简短地介绍了积分的概念,但没有涉及如何计算积分)。如果你不了解积分,那么目前而言你需要知道的是积分是一种求曲线下面积的方法,在这里给我们提供结果的概率。也许我需要撰写一个简短的系列,初步介绍微积分。
现在我们看到了概率密度函数的另一个性质。也就是两个结果之间的概率,是概率密度函数在这两点间的积分(等价于求出概率密度函数在两点之间的曲线下的面积)。数学上,这可以表示为:
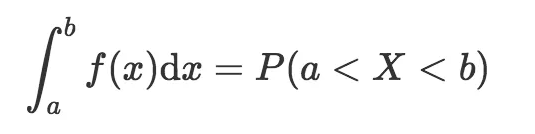
别忘了我们仍然需要遵循概率分布的规则,也就是所有可能结果之和等于1. 如果我们将范围设定为“负无穷大”到“正无穷大”,那么就可以覆盖所有可能的情形。因此,对概率密度函数而言:

也就是说,负无穷大到正无穷大之间的曲线下面积等于1.
连续概率分布重要的一个性质(可能看起来很怪异)是随机变量取得特定结果的概率为0. 例如,如果我们尝试求解结果等于数字2的概率,我们将得到:

这个概念可能看起来很诡异,但如果你理解微积分,就比较容易理解这点。本文不会介绍微积分。相反,我想从中总结出一点,我们只讨论两个值之间的概率,或者讨论出现大于或小于特定值的结果的概率。我们不讨论结果等于特定值的概率。
眼尖的读者可能注意到我用了“小于号(<)”和“大于号(>)”,而不是“大于等于号(≤)”和“小于等于号(≥)”。就连续概率分布而言,这实际上并没有关系,两者是一样的。
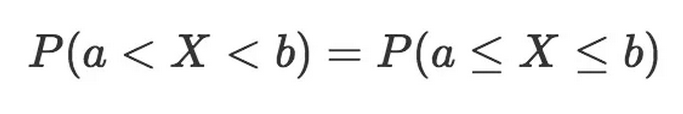
所以随机变量取a和b之间的值的概率等于取a和b之间(含)的概率。
参数的重要性
我们之前提到,参数可以改变函数的输出值,在概率分布上也是一样。

上图是两个正态分布的概率密度函数的图像。蓝色分布的参数值为μ=0、σ=1,而红色分布的参数值为μ=2、σ=0.5.
很明显,使用错误的参数值会得到离你的期望相差很远的结果。
总结
哇!这篇文章比我预想的要长很多。让我们总结一下要点:
-
概率分布是结果及相应概率的列表。
- 我们可以用表格罗列小分布的结果和概率,但大分布用函数概括更方便。
- 离散概率分布的表示函数称为概率质量函数。
- 连续概率分布的表示函数称为概率密度函数。
- 表示概率分布的函数同样遵循概率法则。
-
概率质量函数的输出是概率,概率密度函数曲线下面积表示概率。
- 概率函数的参数在定义随机变量结果概率上起关键作用。
我原本打算在这篇文章中介绍多元分布的,但是因为本文已经很长了,所以会在之后的文章中介绍。
现在你已经初步理解了什么是概率分布,请阅读Sean Owen的Common Probability Distributions: The Data Scientist’s Crib Sheet。如果想要了解更多概率分布,可以查看维基百科上的列表(相当长的一个列表)。