--《大规模分布式存储系统:原理解析与架构实战》读书笔记
之前研究了Bitcask存储模型,今天来看看LSM存储模型,两者虽然同属于基于键值的日志型存储模型。但是Bitcask使用哈希表建立索引,而LSM使用跳跃表建立索引。这一差别导致了两个存储系统的构造出现明显的分化。为此,我还先去捣腾了一番跳跃表的实现.今天算是进入了正题。
LSM的结构
LSM的基本思想是将修改的数据保存在内存,达到一定数量后在将修改的数据批量写入磁盘,在写入的过程中与之前已经存在的数据做合并。同B树存储模型一样,LSM存储模型也支持增、删、读、改以及顺序扫描操作。LSM模型利用批量写入解决了随机写入的问题,虽然牺牲了部分读的性能,但是大大提高了写的性能。
MemTable
LSM本身由MemTable,Immutable MemTable,SSTable等多个部分组成,其中MemTable在内存,用于记录最近修改的数据,一般用跳跃表来组织。当MemTable达到一定大小后,将其冻结起来变成Immutable MemTable,然后开辟一个新的MemTable用来记录新的记录。而Immutable MemTable则等待转存到磁盘。
Immutable MemTable
所谓Immutable MemTable,即是只能读不能写的内存表。内存部分已经有了MemTable,为什么还要使用Immutable MemTable?个人认为其原因是为了不阻塞写操作。因为转存的过程中必然要保证内存表的记录不变,否则如果新插入的记录夹在两条已经转存到磁盘的记录中间,处理上会很麻烦,转存期间势必要锁住全表,这样一来就会阻塞写操作。所以不如将原有的MemTable变成只读Immutable MemTable,在开辟一个新的MemTable用于写入,即简单,又不影响写操作。
SSTable
SSTable是本意是指有序的键值对集合( a set of sorted key-value pairs )。是一个简单有用的集合,正如它的名字一样,它存储的就是一系列的键值对。当文件较大的时候,还可以为其建立一个键-值的位置的索引,指明每个键在SSTable文件中的偏移距离。这样可以加速在SSTable中的查询。(当然这一点是可选的,同时让我想去了Bitcask模型中hint文件,通过记录 键-值的位置 ,来加速索引构建)

使用MemTable和SSTable这两个组件,可以构建一个最简单的LSM存储模型。这个模型与Bitcask模型相比,不存在启动时间长的问题,但是这个模型的读性能非常的差,因为一但在MemTable找不到相应的键,则需要在根据SSTable文件生成的时间,从最近到较早在SSTable中寻找,如果都不存在的话,则会遍历完所有的SSTable文件。
如果SSTable文件个数很多或者没有建立SSTable的文件内索引的话,读性能则会大大下降。
除了在对SSTable内部建立索引外,还可以使用Bloom Fileter,提高Key不在SSTable的判定速度。同样,定期合并旧的SSTable文件,在减少存储的空间的同时,也能提高读取的速度。下面这幅图很好的描述了在LSM的大部分结构和操作
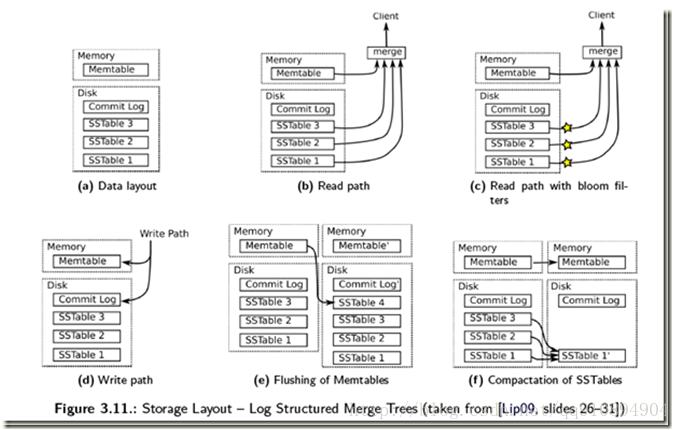
LevelDB如何优化读性能
Leveldb是一个轻量级的,快速的以存储为目的的key-value存储引擎。其使用的正是LSM存储模型。我们可以看看LevelDB是如何来优化读性能的。在LevelDB中,存在一种元信息文件MANIFEST,用于记录leveldb的元信息,比如DB使用的Comparator名,以及各SSTable文件的管理信息:如Level层数、文件名、最小key和最大key等等。相比而言,元信息文件而SSTable文件的数目成正比,一般来说不会太多,是可以载入内存的,因此Level可以通过查询元信息,从而判断哪些文件中存在我们需要的Key对应的记录,减少SSTable文件读取次数。此外,LevelDB的合并操作Compaction是分层次进行的,每一层都有多个SSTable文件,每次合并后除了Level0和内存的MemTable,Immutable MemTable中会有重复的键值外,LevelN(N>=1)的各层内部的SSTable文件不会再有重复的键值。同时,如果在Level N 层读到了数据,那么就不需要再往后读Level N+1,Level N+2等层的数据了.因为Level N层的数据总是比Level N+1等层的数据更“新鲜”。
实现一个简单的LSM存储模型
根据上面讲述的原理,实现了一个简单的LSM模型(https://github.com/Winnerhust/Code-of-Book/blob/master/Large-Scale-Distributed-Storage-System/lsm_tree.py)。这个模型也内存表为一个跳跃表,SSTable就是简单的有序键值对集合,没有SSTable内部使用索引,没有使用Bloom过滤器。其实能就是将我之前的Bitcask模型进行了简单的改造:
- 将原来的哈希表换成了跳跃表;
- 原来读取记录完全依赖哈希表,现在如果在跳跃表中没有的话,就去读取文件SSTable文件中的数据,根据文件编号从大到小进行,编号越大,表示数据越新;
- 去掉了加载数据的功能(LSM不需要);
简单起见,没有完成对范围扫描的支持,不过内存表和SSTable都是有序的,因此这个也不是很难。
参考:
详解SSTable结构和LSMTree索引
欢迎光临我的网站----蝴蝶忽然的博客园----人既无名的专栏。
如果阅读本文过程中有任何问题,请联系作者,转载请注明出处!