引言
密集连接网络和卷积神经网络都有主要的特点,那就是它们没有记忆。它们单独处理每个输入,在输入和输入之间没有保存任何状态。举个例子:当你在阅读一个句子的时候,你需要记住之前的内容,我们才能动态的了解这个句子想表达的含义。生物智能已渐进的方式处理信息,同时保存一个关于所处理内容的内部模型,此模型是根据过去额信息构建的,并随着新的信息进入不断更新。比如股票预测、气温预测等等。
一、mlp和RNN结构

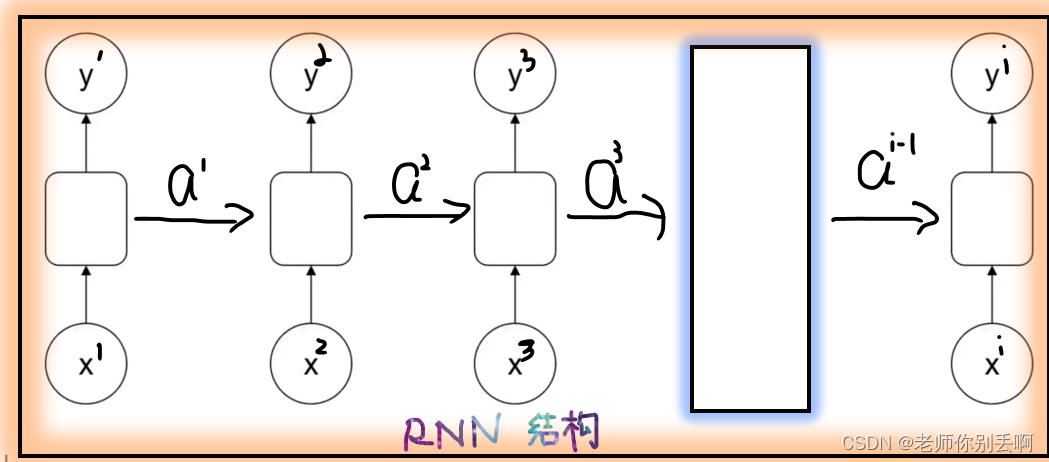
RNN特点:前部序列的信息经处理后,作为输入信息传递后部序列。
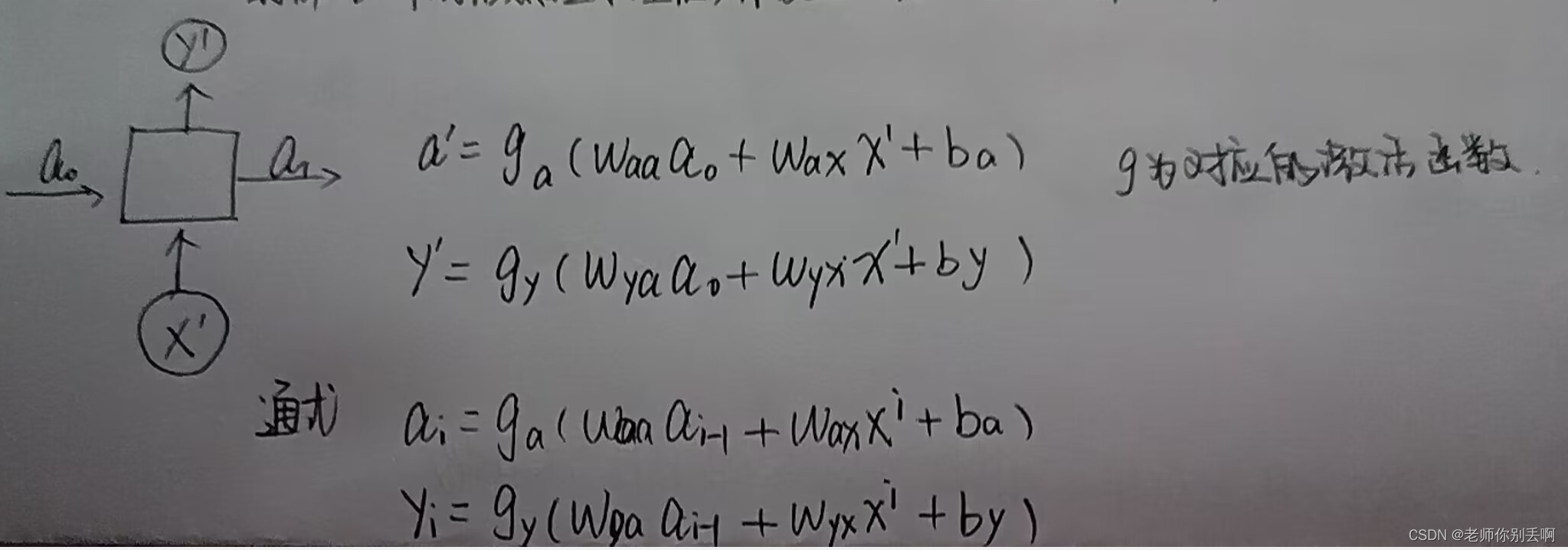
手写一下啦,本博主有点懒,懂了就阔以啦! 肯定权重是一样的。
二、不同的RNN结构
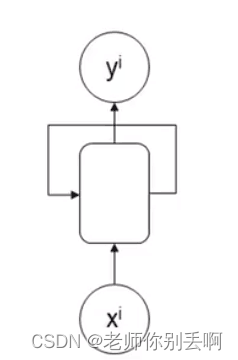
(1)多输入多输出,维度相同RNN结构
应用:特定信息识别
结构如图:
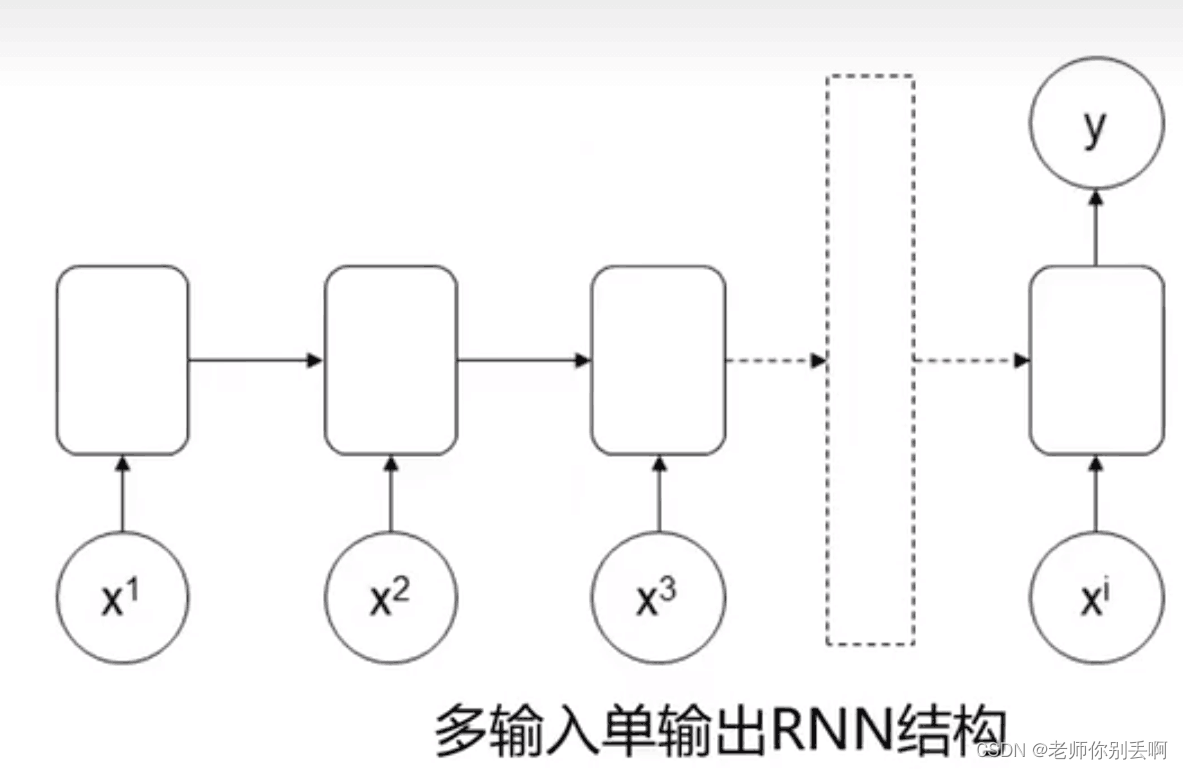
(2)多输入单输出
应用:情感识别
举例:I feel very happy.
判断:positive
结构如图:
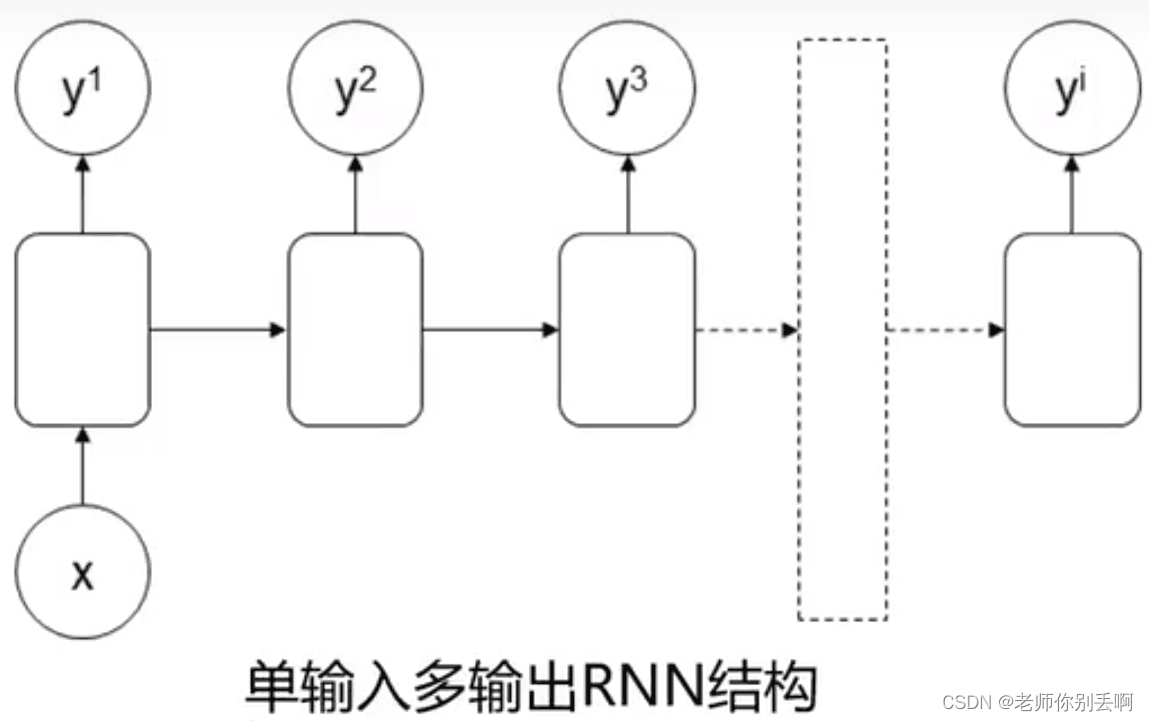
(3)单输入多输出
应用:序列数据生成
举例:文章生成(输入标题直接出文章)
结构如图:
(4)多输入多输出(i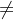 j)
j)
应用:语言翻译
举例:what is artificial intelligence?
什么是人工智能?
结构如图:
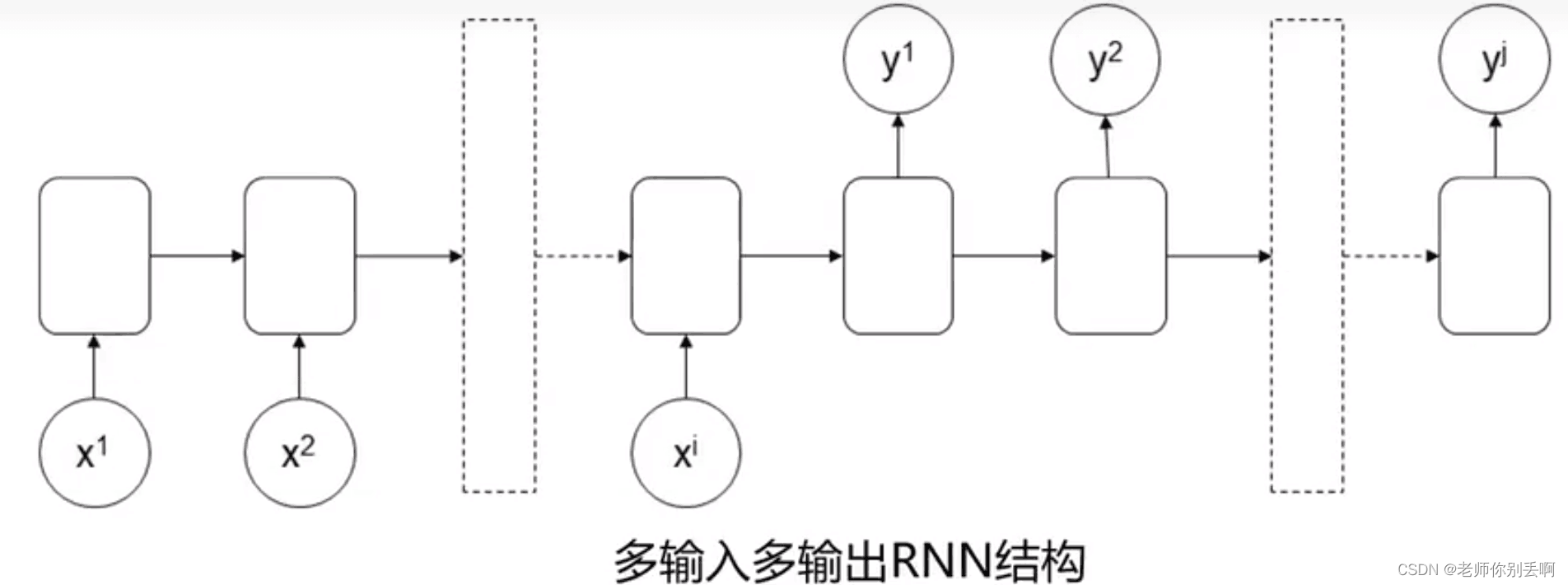
介绍了常见的RNN结构。但是这些结构在当前部序列信息在传递到后部的同时,信息权重下降,导致重要信息丢失。也称为(梯度消失)。由于这个问题接下来提出了长短期记忆网络(LSTM)。
三、长短期记忆网络(LSTM)

通过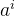 传递前部序列信息,距离越远信息丢失越多(从彩色图可以很好的体现)。
传递前部序列信息,距离越远信息丢失越多(从彩色图可以很好的体现)。
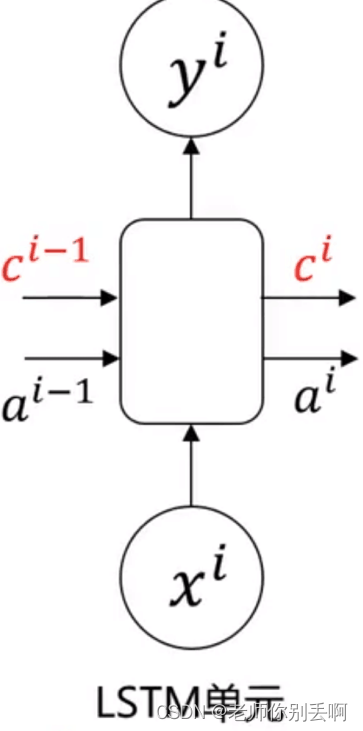 增加记忆细胞
增加记忆细胞 ,可以传递前部远处部位信息,且在传递过程中信息丢失少。
,可以传递前部远处部位信息,且在传递过程中信息丢失少。
内部结构: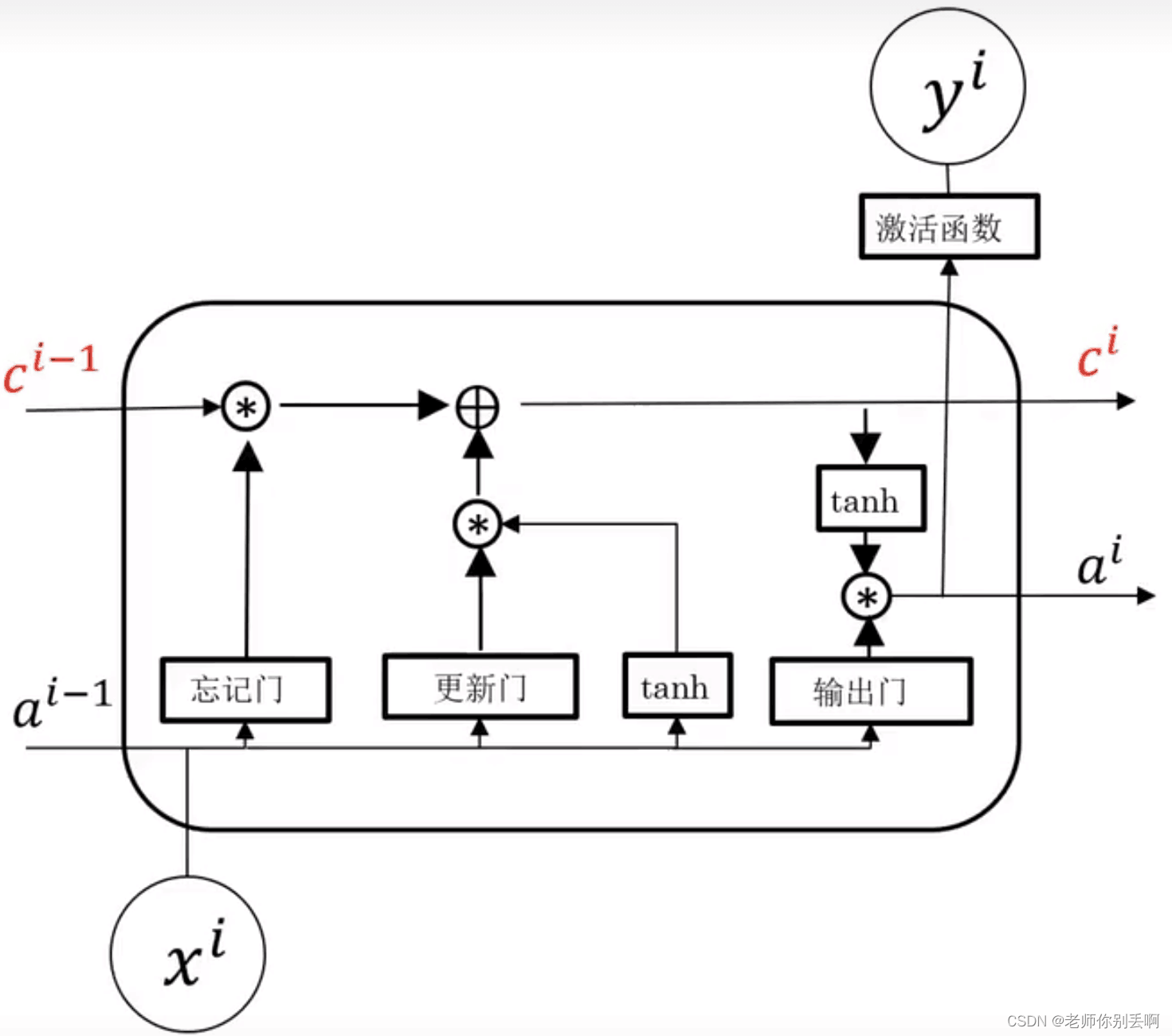
忘记门:选择性丢弃
与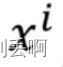 中不重要的信息。
中不重要的信息。
更新门:确定给记忆细胞添加哪些信息。
输出门:筛选需要输出的信息。
结构如图:

在网络结构很深(很多层)的情况下,也能保留保留重要的信息;
解决了普通RNN求解过程中的梯度消失问题。
四、温度预测问题——神经网络基于GUR
数据集介绍:
除了语言处理,其他许多问题中也都用到了序列数据。温度预测数据集,每十分钟记录14分不同的量(比如气温、气压、湿度、风向等)我们将利用2009-2016年的数据集构建模型,输入最近数据,预测24小时之后的气温。¶
(一)读入数据两种方式介绍:
(1)dataframe格式:
注意:
Initializing from file failed
由于文件中存在中文所以加后面engine='python'
data1=pd.read_csv('/data/jena_climate_2009_2016.csv',engine='python')
后续简单操作代码如下:转化成数组
data=data1.copy()
df=data.values
data=df[:,1:]
data
data = np.array(data, dtype=np.float64)#方便后面数据标准化
(2)str格式:
import os
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
data_dir='/data'
fname=os.path.join(data_dir,'jena_climate_2009_2016.csv')
f=open(fname)
data=f.read()
f.close()
lines=data.split('\n')
header=lines[0].split(',')
header
后续简单操作代码如下:转化成数组
float_data=np.zeros((len(lines),len(header)-1))
for i,line in enumerate(lines):
values=[float(x) for x in line.split(',')[1:]]
float_data[i,:]=values
结果如图:

补充 :enumerate()函数
英语翻译:就是枚举
names = ["Alice","Bob","Carl"]
for index,value in enumerate(names):
print(f'{index}: {value}')
看结果就懂了:
0: Alice
1: Bob
2: Carl
(二)分析数据,数据可视化
from matplotlib import pyplot as plt
temp=data[:,1]
plt.plot(range(len(temp)),temp)#可以看出每年温度的周期性变化
#看完整体看局部前十天的温度变化
#首先呢每十分钟记录一个数据点,一天则可以记录144个数据点,则十天记录1440个数据点
plt.plot(range(1440),temp[:1440])#后面是冬季
结果如图:
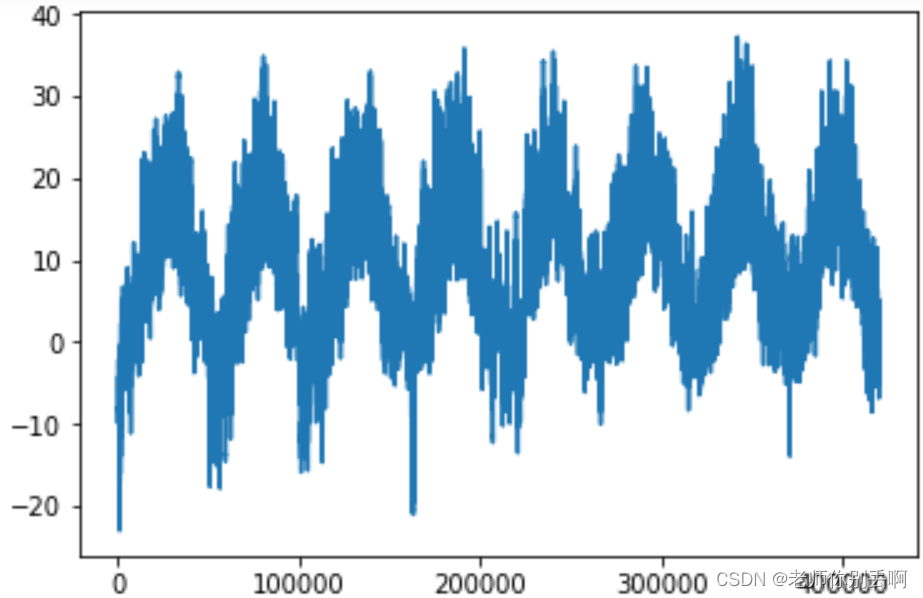
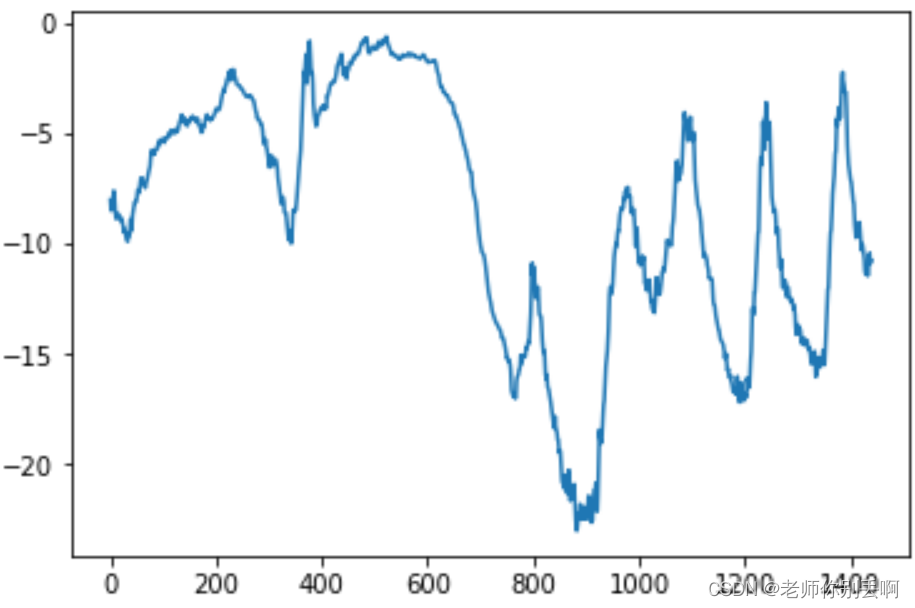
(三)处理数据,可以输入RNN模型
(1) 首先数据预处理(将数据处理为神经网络可以处理的格式,由于已经是数值型的,所以不需要向量化)。
但是由于数据每个时间序列位于不同的范围所以我们需要对每个时间序列进行标准化,让他们在相似范围内都取较小的值。
我们采取200 000个时间作为训练数据。
mean=data[:200000].mean(axis=0)
print(mean)
std=data[:200000].std(axis=0)
print(std)
data_-=mean
data_/=std
(2)提取序列数据
首先介绍Input_shape=(samples,time_steps,features)
举个例子:比如700个数据,我用8个数据去预测第九个数据:
[1 , 2 , . . . ,8] ----9 ——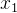
[2 , 3 , . . . ,9] ----10 ——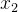
[3 , 4 , . . . ,10]
.
.
.
and so on。 ——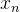 n 代表samples
n 代表samples
time_steps=8
features:样本特征维数(自然语言处理十分重要 one-hot格式比如001对应三),这里数据是单维度则为1.
def extract_data(data,time_step):
X=[]
y=[]
#0,1,2,3...,9:10个样本;time_step=8;0,1...7;2,3...8两个样本
for i in range(len(data)-time_step):
X.append([a for a in data[i:i+time_step]])
y.append(data[i+time_step])
X=np.array(X)
#X=X.reshape(X.shape[0],X.shape[1],1)
return X,y
五、单层lstm股票预测
(一)导包读入数据
%matplotlib inline
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data_=pd.read_csv('/data/zgpa.csv',engine='python')
data_.head()
(二)数据预处理
close=np.array(close,dtype=np.float64)
mean=close.mean(axis=0)
print(mean)
std=close.std(axis=0)
print(std)
close-=mean
close/=std
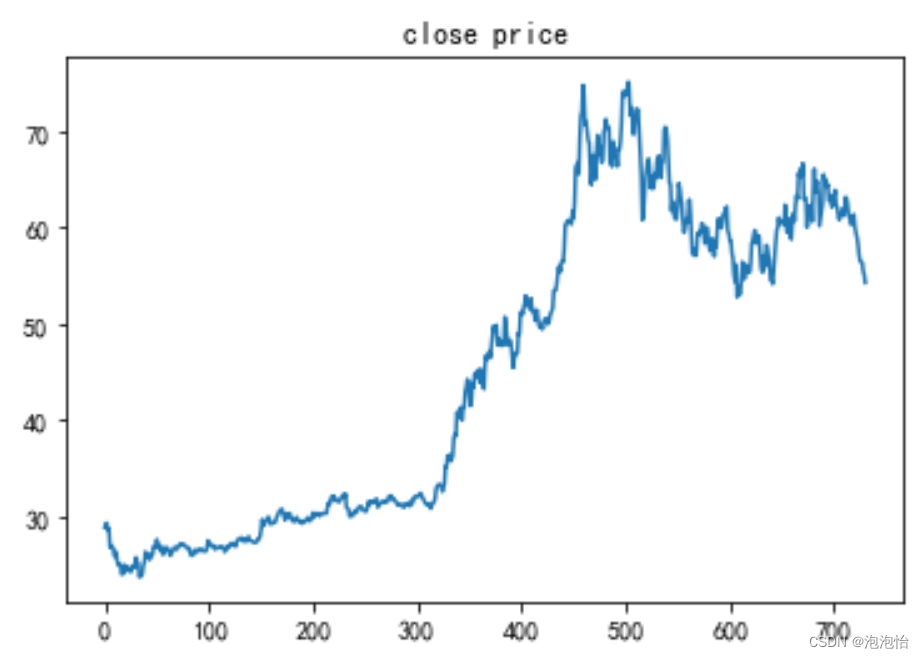
(三)时间序列数据可视化
#首先我们看一下收盘价格时间序列的趋势
close=data_['close']
close
plt.plot(range(len(close)),close)
plt.title('close price')
结果如图:
(四)提取序列数据与上面一样略
调用:
X,y=extract_data(close,time_step)
print(X[0,:,:])
print(y)
(五)建立单个LSTM模型
from keras.models import Sequential
from keras.layers import Dense,SimpleRNN
model=Sequential()
#add rnn layer
model.add(SimpleRNN(units=8,input_shape=(time_step,1),activation='relu'))
#add output layer
model.add(Dense(units=1,activation='linear'))
#configure the model
model.compile(optimizer='adam',loss='mean_squared_error')
model.summary()
结果如图:

(六)训练模型
y=np.array(y)
model.fit(X,y,batch_size=30,epochs=200)
结果如图:

(七)预测与真实可视化
y_train_predict=(model.predict(X)*std)+mean
y_train=(y*std)+mean
fig1=plt.figure(figsize=(8,5))
plt.plot(y_train,label='real price')
plt.plot(y_train_predict,label='predict price')
plt.title('close price')
plt.xlabel('time')
plt.ylabel('price')
plt.legend()
plt.show()
结果如图:
