机器学习19:反卷积算法(转载和整理)
在整理全卷积网络的过程中,被反卷积的概念困扰很久,于是将反卷积算法单独整理为一篇博客,本文主要转载和整理自知乎问题如何通俗易懂地解释反卷积?中的高票答案。
1.反卷积概述:
应用在计算机视觉的深度学习领域,由于输入图像通过卷积神经网络(CNN)提取特征后输出的尺寸往往会变小,从而导致有些情况例如在图像的语义分割过程中,我们需要将图像恢复到原来的尺寸以便进行进一步的计算,这个采用扩大图像尺寸,实现图像由小分辨率到大分辨率的映射的操作,叫做上采样(Upsample)。
上采样有3种常见的方法:双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling),我们这里只讨论反卷积。
这里指的反卷积,也叫转置卷积,它并不是正向卷积的完全逆过程,反卷积是一种特殊的正向卷积,先按照一定的比例通过补0来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。
2.反卷积的数学推导:
(1)正向卷积的实现过程:
假设输入图像尺寸为 4*4,元素矩阵为:

卷积核 kernal尺寸为3*3,元素矩阵为:

步长 strides=1,填充 padding=0,即 i=4,k=3,s=1,p=0,则按照卷积计算公式  ,输出图像的尺寸为 2*2。其中:
,输出图像的尺寸为 2*2。其中:

(2)用矩阵乘法描述卷积:
把输入图像的元素矩阵展开成一个列向量 X:
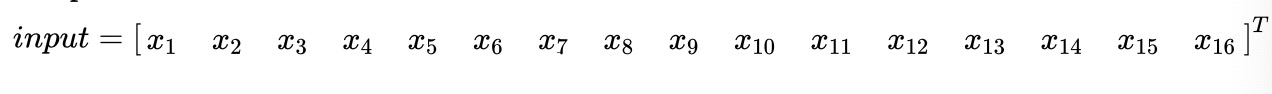
把输出图像 的元素矩阵展开成一个列向量 Y:

对于输入的元素矩阵X和输出的元素矩阵Y,用矩阵运算描述这个过程为:Y=CX
通过推导,我们可以得到稀疏矩阵C:

反卷积的操作就是要对这个矩阵运算过程进行逆运算,即通过 C和Y得到 X,根据各个矩阵的尺寸大小,我们能很轻易的得到计算的过程,即为反卷积的操作:

但是,如果代入数字计算会发现,反卷积的操作只是恢复了矩阵 X的尺寸大小,并不能恢复 X的每个元素值。
(3)反卷积的输入输出尺寸关系:
在进行反卷积时,简单来说,大体上可分为以下两种情况:
1)Relationship 1:(o+2p-k)%s=0
此时反卷积的输入输出尺寸关系为:o=s(i-1)-2p+k
如下图所示,我们选择一个输入尺寸为3*3,卷积核kernal尺寸为3*3,步长strides=2,填充padding=1,即i=3,k=3,s=2,p=1,则输出的尺寸为o=5。

2)Relationship 2:(o+2p-k)%s!=0
此时反卷积的输入输出尺寸关系为:o=s(i-1)-2p+k+(o+2p-k)%
如下图所示,我们选择一个输入尺寸为3*3,卷积核kernal尺寸为3*3,步长strides=2,填充padding=1,即i=3,k=3,s=2,p=1,则输出的尺寸为o=5+1=6。

3.在tensorflow中实现反卷积:
下面用一组实验更直观的解释一下在 tensorflow 中反卷积的过程:
令输入图像为:
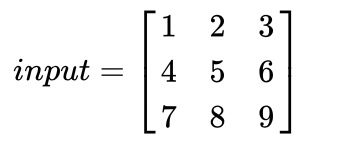
卷积核为:

1)case 1:
如果要使输出的尺寸是 5*5,步数 strides=5,tensorflow 中的命令为:
transpose_conv = tf.nn.conv2d_transpose(value=input,
filter=kernel,
output_shape=[1,5,5,1],
strides=2,
padding='SAME')
当执行 transpose_conv 命令时,tensorflow 会先计算卷积类型、输入尺寸、步数和输出尺寸之间的关系是否成立,如果不成立,会直接提示错误,如果成立,执行如下操作:
1.现根据步数 strides对输入的内部进行填充,这里strides可以理解成输入放大的倍数,即在输入的每个元素之间填充 0,0的个数n与strides的关系为:
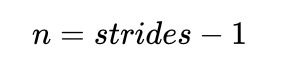
例如这里举例的strides=2,即在输入的每个元素之间填1个0:

因为卷积类型为 same,所以此时i=5,k=3,s=1,p=1。
2. 接下来,用卷积核kernal对填充后的输入进行步长strides=1的正向卷积,根据上文的正向卷积输出尺寸公式得到输出尺寸是5*5,反卷积公式中我们给出的输出尺寸参数也是为5,两者相同,所以可以进行计算,结果为:

与 tensorflow 的运行结果相同。
2)case 2:
我们将 case 1 中的输出尺寸改成6,其他参数均不变,tensorflow 中的命令为:
transpose_conv = tf.nn.conv2d_transpose(value=input,
filter=kernel,
output_shape=[1,6,6,1],
strides=2,
padding='SAME')
卷积类型是 same,我们首先在外围填充一圈0:

这时发现,填充后的输入尺寸与3*3的卷积核卷积后的输出尺寸是5*5,没有达到输出的6*6,这就需要继续填充 0,tensorflow 的计算规则是优先在左侧和上侧填充一排 0,填充后的输入变为:

接下来,再对这个填充后的输入与3*3的卷积核卷积,结果为:

与 tensorflow 的运行结果相同。
4.从工程角度解释反卷积:
如果读深度学习框架的源码可以看到,反卷积前向和后向传播的实现,恰好就是对应卷积的后向和前向传播,这里简单看下caffe反卷积层的前向实现的源码deconv_layer.cpp:

可以看到核心计算部分其实是调用了继承自卷积层的反向传播函数base_conv_layer.cpp:

可以看到卷积的反向传播实现就是一个gemm+col2im,所以只要理解了卷积的反向传播的计算过程,那么反卷积的前向计算过程也就懂了。下面结合卷积运算过程的示例图解释下其前向和反向传播的计算流程:

首先看到卷积的FP(前向传播)计算流程,假设给定卷积输入大小是 Cin * Hin * Win, 卷积输出通道数为Cout,卷积核空间大小 K * K,则权值大小是 Cout * Cin * K * K,卷积运算的一个加速方法是转换成矩阵乘法,就是把输入通过 im2col 操作转成 (Cin * K * K ) x (Hout * Wout)大小的矩阵,然后和同样把每个输出通道对应的权值拉成向量,就可以做矩阵乘法了,可以看到乘法结果就是卷积输出结果。
卷积的反向传播是给定输出梯度反求输入梯度,已知输出梯度大小和卷积输出特征图一致,输入梯度大小和输入特征图一致,如果是3x3且步长为2的卷积且padding 为1,那么输出特征图大小相当于是输入的一半,那么反向传播看起来就像是把输出梯度变大到输入梯度大小的过程,就与反卷积所做的工作一致了。
卷积的反向传播转换成矩阵乘法之后,其求导结果和全连接层求导结果类似,相当于把权值转置然后和输出梯度做乘法,得到输入梯度的中间结果。
如图所示卷积反向传播(BP)部分的中间结果大小是 (Cin * K * K ) x (Hout * Wout),前向卷积过程中的im2col操作的逆操作为col2im,使用col2im操作使中间结果的每一列 Cin * K * K 大小的向量reshape成 (Cin, K,K)的 tensor,然后向输入梯度对应通道的对应位置上回填累加。这里首先会把输入梯度每个位置初始化为0,回填的时候是根据步长滑动回填窗口,与卷积前向时根据步长滑动卷积窗口相同。然后就完成了把输出梯度变大到输入梯度大小的过程了。
理解了卷积的前向和后向计算之后再来看反卷积就很容易理解了,下图最下面一行反卷积的前向过程和卷积的反向过程对照来看:

这里简单绘制一个计算流程图展示卷积的反向传播和反卷积的前向传播过程,假设卷积和反卷积核大小都是3x3,步长为2,卷积输入大小是4x4,现在假设需要卷积输出或反卷积输入大小是2x2,则根据卷积输出大小计算公式(( input + 2 * pad - kernel )/ stride + 1 )则需要pad 1,则现在看下如何从2x2大小的输入反推输出4x4,为了方便理解,假设权值都是1,卷积输出梯度或者反卷积输入值都是1,输入和输出通道都是1:

中间结果矩阵大小为9x4,然后把每一列reshape成 3x3 大小然后往6x6输出上累加,最后再crop出中间部分,就得到结果了。下面用mxnet简单验证下结果:
import mxnet as mx
data_shape = (1, 1, 2, 2)
data = mx.nd.ones(data_shape)
deconv_weight_shape = (1, 1, 3, 3)
deconv_weight = mx.nd.ones(deconv_weight_shape)
# deconvolution forward
data_deconv = mx.nd.Deconvolution(data=data, weight=deconv_weight,
kernel=(3, 3),
pad=(1, 1),
stride=(2, 2),
adj=(1, 1),
num_filter=1)
print(data_deconv)
# convolution backward
data_sym = mx.sym.Variable('data')
conv_sym = mx.sym.Convolution(data=data_sym, kernel=(3, 3), stride=(2, 2), pad=(1, 1), num_filter=1, no_bias=True, name='conv')
executor = conv_sym.simple_bind(data=(1, 1, 4, 4), ctx=mx.cpu())
mx.nd.ones((1, 1, 3, 3)).copyto(executor.arg_dict['conv_weight'])
executor.backward(mx.nd.ones((1, 1, 2, 2)))
print(executor.grad_dict['data'])
从下图结果可以看到打印出的反卷积前向结果和卷积的反向结果与上面计算流程图中的结果一致:

5.参考资料:
(1) 作者:梁德澎
链接:https://www.zhihu.com/question/48279880/answer/838063090
(2)反卷积和上采样+卷积的区别?www.zhihu.com
(3)作者:孙小也
链接:https://www.zhihu.com/question/48279880/answer/525347615
(4) SIGAI:反向传播算法推导-全连接神经网络zhuanlan.zhihu.com
(5)关于im2col的解释可参考博客:caffe im2col 详解blog.csdn.net