参考: Shane Cook. CUDA Programming: A developer’s guide to parallel computing with GPUs
背景
计算直方图是图像处理和机器学习等常用的操作.
对于大数据集, 使用串行算法十分浪费时间.
这里使用CUDA来加速直方图的计算.
对于一个较大的整数数组, 值域0~255. 求取直方图.
使用CPU计算
void cpuHist(Cuda8u *pHist_data, Cuda32u* pBin_data, Cuda32u arraySize, Cuda32u binSize)
{
for (Cuda32u i = 0; i < arraySize;i++)
{
if (pHist_data[i] < binSize)
{
pBin_data[pHist_data[i]]++;
}
}
}
main函数调用:
// CPU 数据初始化
const Cuda32u uArraySize = 256*256;
const Cuda32u uBinSize = 256;
Cuda8u *h_puchData = (Cuda8u *)malloc(uArraySize*sizeof(Cuda8u));
for (int i = 0; i < uArraySize; i++)
{
h_puchData[i] = rand() % uBinSize;
}
Cuda32u h_puHist[uBinSize] = { 0 };
Cuda32u N = 64;
Cuda32u iIterNum = 10;
// 使用CPU计算
StartTimer();
for (Cuda32u i = 0; i < iIterNum;i++)
{
cpuHist(h_puchData, h_puHist, uArraySize, uBinSize);
}
double dblTimeElps = GetTimer();
Cuda32u iSumC = 0;
for (Cuda32u i = 0; i < uBinSize; i++)
{
iSumC += h_puHist[i];
}
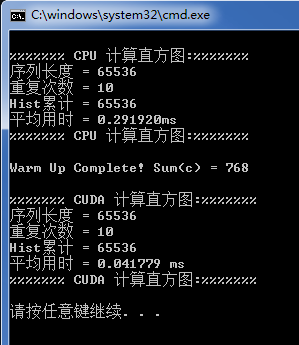
printf("\n%%%%%%%%%%%%%% CPU 计算直方图:%%%%%%%%%%%%%%\n");
printf("序列长度 = %d\n", uArraySize);
printf("重复次数 = %d\n", iIterNum);
printf("Hist累计 = %d\n", iSumC / iIterNum);
printf("平均用时 = %fms\n", dblTimeElps / (Cuda64f)iIterNum);
printf("%%%%%%%%%%%%%% CPU 计算直方图:%%%%%%%%%%%%%%\n");
使用CUDA 原子操作atomicAdd
__global__ void myhistogram256Kernel_01(const Cuda8u *d_hist_data, Cuda32u *d_bin_data)
{
const Cuda32u idx = blockIdx.x*blockDim.x + threadIdx.x;
const Cuda32u idy = blockIdx.y*blockDim.y + threadIdx.y;
const Cuda32u tid = idx + idy*blockDim.x*gridDim.x;
const Cuda8u value = d_hist_data[tid];
atomicAdd(&(d_bin_data[value]), 1);
}
void cudaHist_01(Cuda8u* d_puchData, Cuda32u *d_puHist)
{
// 总的thread数量要和数组长度相同.
dim3 thread_rect(16, 16);
dim3 block_rect(16, 16);
myhistogram256Kernel_01 << <block_rect, thread_rect >> >(d_puchData, d_puHist);
}
main函数调用:
// 先将CPU里的数据搬移到GPU中!
memset((void*)h_puHist, 0, uBinSize*sizeof(Cuda32u));
Cuda8u * d_puchData = NULL;
Cuda32u * d_puHist = NULL;
checkCudaErrors(cudaMalloc((void**)&d_puchData, uArraySize*sizeof(Cuda8u)));
checkCudaErrors(cudaMalloc((void**)&d_puHist, uBinSize*sizeof(Cuda32u)));
checkCudaErrors(cudaMemcpy((void*)d_puchData, (void*)h_puchData, uArraySize*sizeof(Cuda8u), cudaMemcpyHostToDevice));
checkCudaErrors(cudaMemcpy((void*)d_puHist, (void*)h_puHist, uBinSize*sizeof(Cuda32u), cudaMemcpyHostToDevice));
// 预热
cudaAdd();
// 开始计时
cudaEvent_t start, stop;
Cuda32f elapsedTime = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
for (Cuda32u i = 0; i < iIterNum;i++)
{
// 求直方图
//cudaHist_07((Cuda32u*)d_puchData, d_puHist, N);
cudaHist_01(d_puchData, d_puHist);
}
// 结束计时
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
// 将GPU内的数据拷回CPU
checkCudaErrors(cudaMemcpy((void*)h_puHist, (void*)d_puHist, uBinSize*sizeof(Cuda32u), cudaMemcpyDeviceToHost));
iSumC = 0;
for (Cuda32u i = 0; i < uBinSize; i++)
{
iSumC += h_puHist[i];
}
printf("\n%%%%%%%%%%%%%% CUDA 计算直方图:%%%%%%%%%%%%%%\n");
printf("序列长度 = %d\n", uArraySize);
printf("重复次数 = %d\n", iIterNum);
printf("Hist累计 = %d\n", iSumC / iIterNum);
printf("平均用时 = %f ms\n", elapsedTime / (Cuda32u)iIterNum);
printf("%%%%%%%%%%%%%% CUDA 计算直方图:%%%%%%%%%%%%%%\n\n");
// 释放资源
checkCudaErrors(cudaFree((void*)d_puchData));
checkCudaErrors(cudaFree((void*)d_puHist));
cudaDeviceReset();
运行结果: