先前博主购买了腾讯云的GPU服务器后,发现上面预装的环境存在一些问题,因此便来重新部署一下。
为了操作方便,博主这里使用了一个远程控制端软件:Xshell
博主在初始化时已经安装过pytorch了,我们首先看看安装的路径
测试环境
import torch
print(torch.__file__)

修改源
这时博主也发现系统帮我们安装了minconda3,相较于anconda,其体积更小。我们在控制台输入conda测试一下,出现下面界面说明是正常的

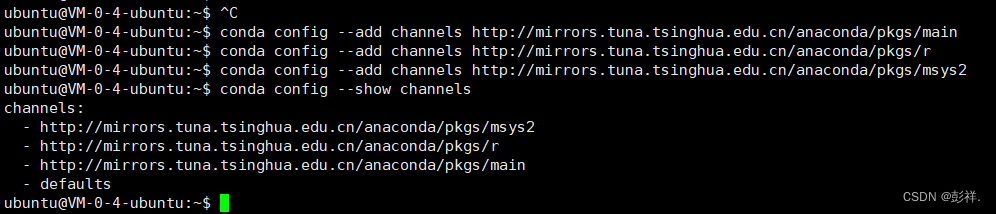
添加清华源镜像,让其安装依赖包速度快些
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
conda config --set show_channel_urls yes
conda config --show channels
在配置时会提示没有权限
CondaError: Cannot write to condarc file at /home/ubuntu/.condarc
Caused by PermissionError(13, ‘Permission denied’)
修改一下:
sudo chown -R ubuntu /home/ubuntu/.condarc
ubuntu是用户名,后面是路径
然后我们再次运行:一切正常
这时我们像之前在window那样创建anconda环境即可
创建环境与安装pytorch
conda create -n yolo python=3.8
此时报错:
NoWritableEnvsDirError: No writeable envs directories configured.
- /home/ubuntu/.conda/envs
- /usr/local/miniconda3/envs
这是没有写入权限造成的,修改一下:
sudo chmod a+w .conda
再次创建环境:成功
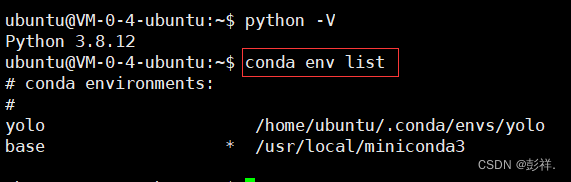
查看安装的环境:
激活环境:source activate yolo

根据cuda版本为11.4安装对应的pytorch

conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.4 -c pytorch
运行却失败了,因此也只能使用原来的命令,安装成功
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pycharm远程连接
我们再次在pycharm中配置
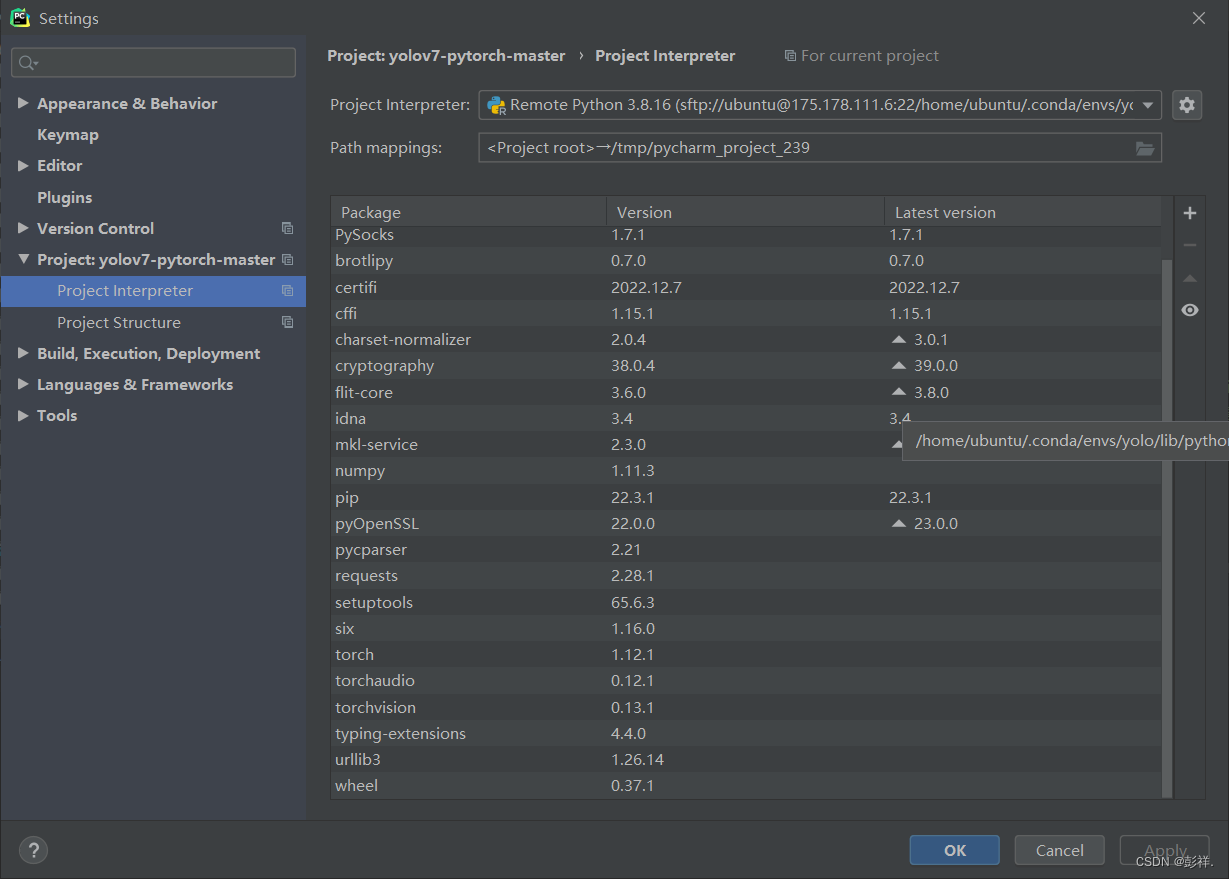
可以看到所需的依赖都加载完成了。
再次运行还是有问题
sudo+ssh://ubuntu@175.178.111.6:22/home/ubuntu/.conda/envs/yolo/bin/python3.8 -u /home/ubuntu/pythonfile/train.py
/home/ubuntu/.conda/envs/yolo/bin/python3.8: can't open file '/home/ubuntu/pythonfile/train.py': [Errno 2] No such file or directory
该问题是没有将本地代码映射到服务器上导致的,在网上找相关资料,配置了很久,看到说可能与映射路径相关,来来回回搞了很多次,发现在本地新建的文件是可以写入的,但先前的文件却无法写入。这说明我们的目录配置是没有问题的。
然后重新上传一下,整个项目右击
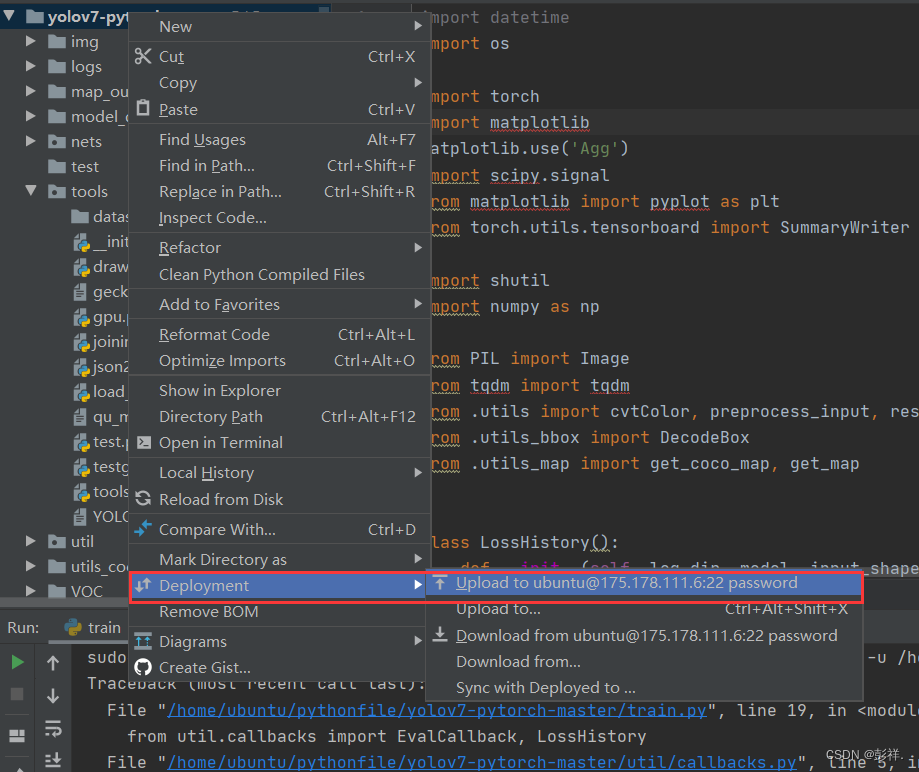
然后等着,这个过程会很漫长,慢慢来。博主晚上导入的,早晨醒过来搞定了

此时我们可以看到,项目已经映射到服务器上了,此时我们再次运行一下:
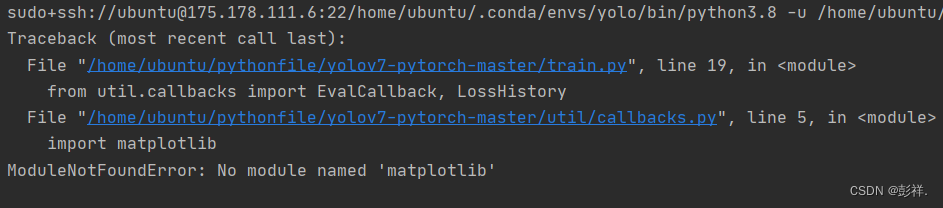
提示我们缺少包了,我们只需要将所需要的包配置好即可了。
添加依赖包
sudo apt-get install python3-matplotlib

当然也可以使用pip install matplotlib命令或者使用pycharm中安装。
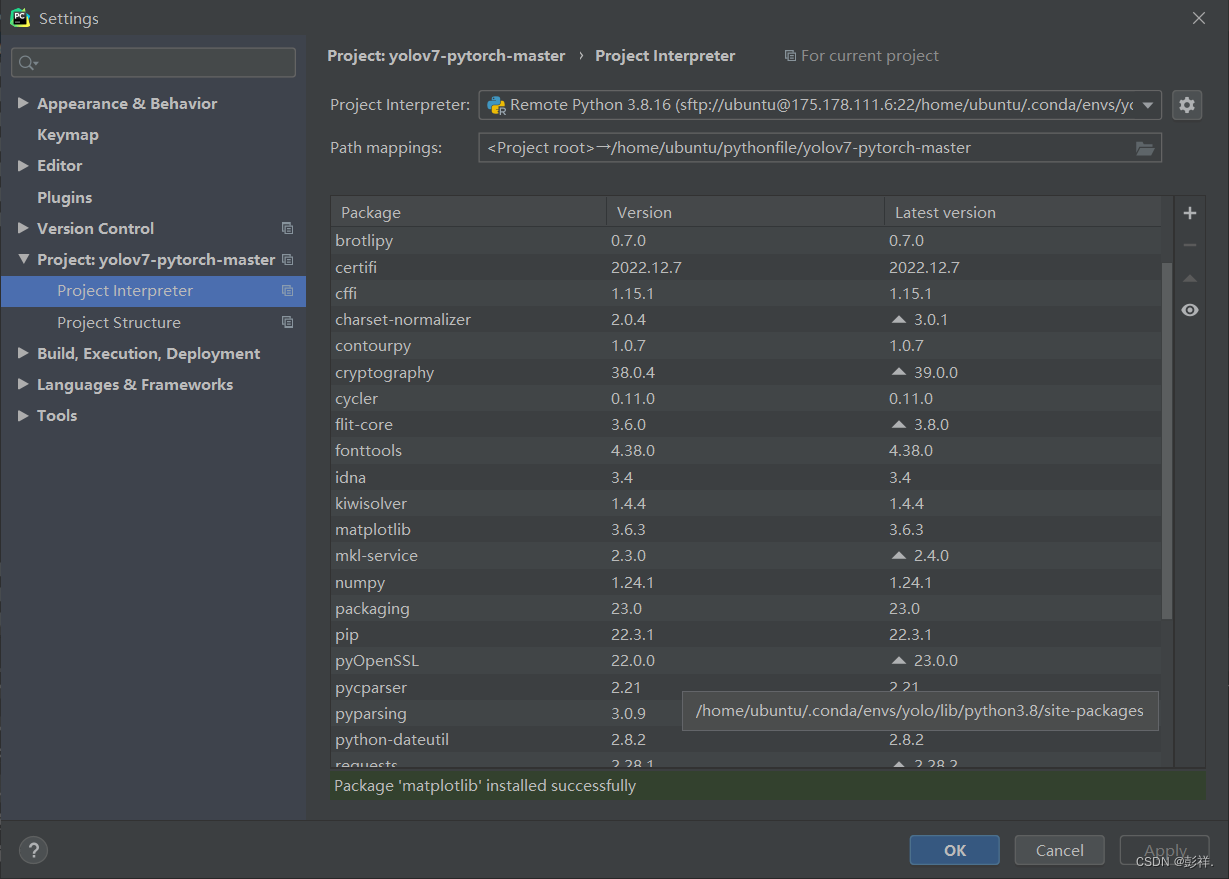
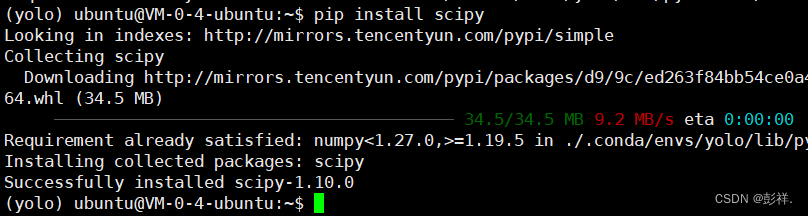
OK了
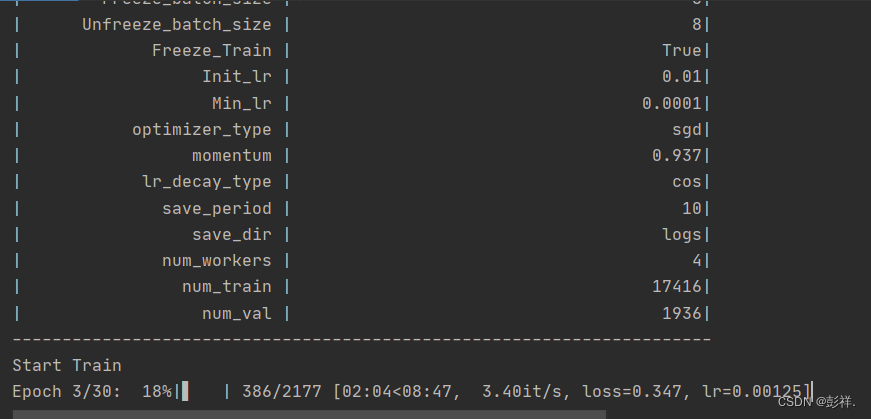
查看一下利用率

不得不说比博主笔记本的性能强太多了。
奈斯
最终,项目大约训练了4个小时便完成了,相较博主原本的笔记本快了不知多少倍,而且每次运行时风扇的呼呼声以及由于系统cpu,内存的占用而导致无法完成其他的事情,可以说真的非常棒,比起之前在谷歌白嫖的colab速度也快了不少,记得当时博主运行12小时也没完成,想必虽然两者是相同的显卡,但后者cpu的调用竞争激烈造成了一些瓶颈。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)