TransUNet论文笔记
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Abstract
医学图像分割是开发医疗保健系统,尤其是疾病诊断和治疗计划的必要前提。在各种医学图像分割任务中,u-shaped体系结构(也称为U-Net)已成为事实上的标准,并取得了巨大成功。然而,由于卷积运算的固有局部性,U-Net通常在显式建模长期依赖性方面存在局限性。设计用于序列到序列预测的transformers已经成为具有先天性全局自我注意机制的替代体系结构,但由于低层次细节不足,可能会导致有限的定位能力。在本文中,我们提出Transune作为医学图像分割的一个强有力的替代方案,它同时具有Transformers和U网络的优点。一方面,Transformers将卷积神经网络(CNN)特征映射中的标记化图像块编码为用于提取全局上下文的输入序列。另一方面,解码器对编码的特征进行上采样,然后将其与高分辨率CNN特征图结合,以实现精确定位。
我们认为,Transformers可以作为医学图像分割任务的强大编码器,与U-Net结合,通过恢复局部空间信息来增强更精细的细节。TransUNet在不同的医学应用中,包括多器官分割和心脏分割,取得了优于各种竞争方法的性能。代码和模型可在https://github.com/Beckschen/TransUNet。
1 Introduction
卷积神经网络(CNN),尤其是完全卷积网络(FCN)[8],在医学图像分割中占据主导地位。在不同的变体中,U-Net[12]已经成为事实上的选择,它由一个对称的编码器-解码器网络组成,带有跳过连接以增强细节保留。基于这一方法,在广泛的医学应用中取得了巨大的成功,例如磁共振心脏分割(MR)[16],来自计算机断层扫描(CT)的器官分割[7,17,19]和来自结肠镜视频的息肉分割[20]。
尽管基于CNN的方法具有非凡的表现力,但由于卷积运算的固有局部性,它们在建模显式远程关系时通常表现出局限性。因此,这些结构通常会产生较弱的性能,尤其是对于在纹理、形状和大小方面表现出较大患者间差异的目标结构。为了克服这一局限性,现有研究建议基于CNN特征建立自我注意机制[13,15]。另一方面,设计用于序列到序列预测的Transformers已成为替代架构,其完全采用分散卷积算子,而完全依赖注意机制[14]。与之前基于CNN的方法不同,Transformers不仅在建模全局环境方面非常强大,而且在大规模预培训下,还表现出了对下游任务的出色可转移性。这种成功在机器翻译和自然语言处理(NLP)领域已经得到了广泛的证明[3,14]。最近,在各种图像识别任务中,尝试也达到甚至超过了最先进的水平[4,18]。
在本文中,我们提出了第一项研究,探讨了Transformers在医学图像分割中的潜力。然而,有趣的是,我们发现单纯的使用(即,使用Transformers对标记化的图像块进行编码,然后直接将隐藏的特征表示放大为全分辨率的密集输出)无法产生令人满意的结果。
**这是因为Transformers将输入视为1D序列,并专门关注在所有阶段对全局环境进行建模,因此会导致缺乏详细定位信息的低分辨率特征。**而这种信息不能通过直接上采样有效地恢复到完全分辨率,因此会导致粗分割结果。另一方面,CNN架构(例如U-Net[12])提供了一种提取低级视觉线索的途径,可以很好地弥补这些细微的空间细节。
为此,我们提出了第一个医学图像分割框架Transune,它从序列到序列预测的角度建立了自我注意机制。为了补偿Transformers带来的特征分辨率损失,Transune采用了一种混合的CNN-Transformers体系结构,利用CNN特征的详细高分辨率空间信息和Transformers编码的全局上下文。受u形建筑设计的启发,由Transformers编码的自我关注功能随后被上采样,与编码路径中跳过的不同高分辨率CNN功能组合,以实现精确定位。我们表明,这样的设计允许我们的框架保留Transformers的优点,也有利于医学图像分割。实证结果表明,与之前基于CNN的自我注意方法相比,我们基于Transformers的架构提供了更好的利用自我注意的方法。此外,我们观察到,低级别特征的更密集结合通常会导致更好的分割精度。大量实验证明了该方法的优越性可以用在各种医学图像分割任务中,我们的方法与其他竞争方法相比有很多优势。
2 Related Works
Combining CNNs with self-attention mechanisms
各种研究试图通过基于特征映射的所有像素的全局交互建模,将自我注意机制整合到CNN中。例如,Wang等人设计了一个非局部算子,可以插入多个中间卷积层[15]。Schlemper等人[13]在编码器-解码器u形架构的基础上,提出了集成到跳过连接中的附加注意门模块。与这些方法不同,我们在方法中使用了Transformers来嵌入全局自我关注。
Transformers.
Transformers最初由[14]提出用于机器翻译,并在许多NLP任务中建立了最先进的技术。为了使Transformers也适用于计算机视觉任务,进行了几次修改。例如,Parmar等人[11]只在每个查询像素的局部社区应用自我关注,而不是全局应用。Child等人[1]提出了稀疏变换,它采用可伸缩的近似值来实现全局自我关注。最近,Vision Transformer(ViT)[4]通过直接将具有全局自我关注的转换器应用于全尺寸图像,实现了ImageNet分类的最新技术。据我们所知,Transune是第一个基于Transformer的医学图像分割框架,它建立在非常成功的ViT基础上。
3 Method
给出一张图像
x
∈
R
H
×
W
×
C
\mathbf{x} \in \mathbb{R}^{H \times W \times C}
x∈RH×W×C,空间分辨率为H×W,通道数为C。我们的目标是预测相应的像素级labelmap,大小为H×W。最常见的方法是直接训练CNN(例如,UNet)首先将图像编码为高级特征表示,然后解码回完整的空间分辨率。与现有方法不同,我们的方法通过使用Transformers将自我注意机制引入编码器设计。在第3.1节中,我们将首先介绍如何直接应用transformer对分解图像块的特征表示进行编码。然后,Transune的总体框架将在第3.2节中详细阐述。
3.1 Transformer as Encoder
Image Sequentialization
在[4]之后,我们首先通过将输入x重塑为一系列平坦的2Dpatch
{
x
p
i
∈
R
P
2
⋅
C
∣
i
=
1
,
.
.
,
N
}
\left\{\mathbf{x}_{p}^{i} \in \mathbb{R}^{P^{2} \cdot C} \mid i=1,..,N \right \}
{xpi∈RP2⋅C∣i=1,..,N} ,其中每个patch的大小为P×P,
N
=
H
W
P
2
N=\frac{H W}{P^{2}}
N=P2HW是图像patch的数量(即输入序列长度)。
Patch Embedding
我们使用可训练线性投影将矢量化patch
x
p
x_p
xp映射到潜在的D维嵌入空间。为了对patch空间信息进行编码,我们学习了特定的位置嵌入,这些嵌入被添加到patch嵌入中,以保留位置信息,如下所示:
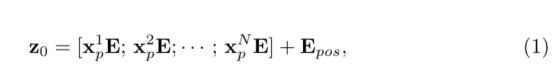
E
∈
R
(
P
2
⋅
C
)
×
D
\mathbf{E} \in \mathbb{R}^{\left(P^{2} \cdot C\right) \times D}
E∈R(P2⋅C)×D为patch embedding,
E
p
o
s
∈
R
N
×
D
\mathbf{E}_{p o s} \in \mathbb{R}^{N \times D}
Epos∈RN×D为position embedding
Transformer编码器由L层多头自我注意(MSA)和多层感知机(MLP)块组成(等式(2)(3))。因此,l-th(第l层)层的输出可以写为:
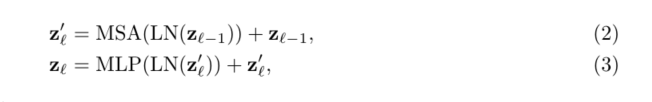
LN(·)表示层标准化运算符,
z
L
z_L
zL表示编码图像表示。Transformers层的结构如图1(a)所示。

3.2 TransUNet
出于分割目的,直观的解决方案是简单地对编码的特征表示进行上采样为
Z
L
∈
R
H
W
P
2
×
D
\mathbf{Z}_{L} \in \mathbb{R}^{\frac{H W}{P^{2}} \times D}
ZL∈RP2HW×D去预测密集输出的全分辨率。在这里,为了恢复空间顺序,编码特征的大小应该首先从
H
W
P
2
to
H
P
×
W
P
\frac{H W}{P^{2}} \text { to } \frac{H}{P} \times \frac{W}{P}
P2HW to PH×PW。我们使用1×1卷积将重构后的特征通道大小减少到类数,然后将特征图直接双线性上采样到全分辨率H×W,以预测最终的分割结果。在第4.3节后面的比较中,我们在解码器设计中将这种"幼稚"的上采样基线表示为“无”。
尽管将Transformers与原始上采样相结合已经产生了合理的性能,如上所述,但这种策略并不是分割中Transformers的最佳使用,因为
H
P
×
W
P
\frac{H}{P} \times \frac{W}{P}
PH×PW通常比原始图像分辨率H×W小得多,因此不可避免地会导致低层次细节的丢失(例如器官的形状和边界)。因此,为了补偿这种信息损失,Transune采用了混合CNNTransformers结构作为编码器以及级联上采样器,以实现精确定位。图1描述了拟建Transune的概况。
CNN-Transformer Hybrid as Encoder
Transune没有使用纯Transformers作为编码器(第3.1节),而是采用CNNTransformers混合模型,CNN首先用作特征提取器,为输入生成特征映射。将patch嵌入从CNN特征图中提取的1×1patch,而不是从原始图像中提取
我们之所以选择这种设计,是因为1)它允许我们在解码路径中利用中间的高分辨率CNN特征图;2)我们发现,混合CNNTransformers编码器的性能优于单纯使用纯Transformers作为编码器。
Cascaded Upsampler
我们介绍了一种级联上采样器(CUP),它由多个上采样步骤组成,用于解码隐藏的特征以输出最终的分割掩码。对隐藏特征序列
Z
L
∈
R
H
W
P
2
×
D
\mathbf{Z}_{L} \in \mathbb{R}^{\frac{H W}{P^{2}} \times D}
ZL∈RP2HW×D进行reshape后到
H
P
×
W
P
\frac{H}{P} \times \frac{W}{P}
PH×PW的形状,我们通过级联多个上采样块来实现CUP,以达到从
H
P
×
W
P
\frac{H}{P} \times \frac{W}{P}
PH×PW到H×W的全分辨率,其中每个块依次由一个2×上采样算子、一个3×3卷积层和一个ReLU层组成
我们可以看到,CUP与混合编码器一起形成了一个u形架构,它通过跳过连接实现了不同分辨率级别的功能聚合。图1(b)显示了CUP以及中间跳车连接的详细结构。
4 Experiments and Discussion
4.1 Dataset and Evaluation
Synapse多器官分割数据集1。我们在MICCAI 2015多图谱腹部标记挑战中使用了30次腹部CT扫描,总共有3779次轴向对比增强腹部临床CT图像
每个CT体积由85∼ 198个组成512×512像素的切片,体素空间分辨率为([0.54])∼ 0.54] × [0.98 ∼ 0.98] × [2.5 ∼ 5.0])mm3。在[5]之后,我们报告了平均DSC和平均Hausdorff距离(HD)在8个腹部器官(主动脉、胆囊、脾脏、左肾、右肾、肝、胰腺、脾脏、胃)上随机分为18个训练病例(2212个轴向切片)和12个验证病例。
Automated cardiac diagnosis challenge
ACDC挑战收集从MRI扫描仪获得的不同患者的检查。电影磁共振图像是在屏气状态下获得的,一系列短轴切片从左心室底部到心尖覆盖心脏,切片厚度为5至8mm。短轴平面内空间分辨率从0.83到1.75 mm2/像素。
每个患者扫描都会手动标注左心室(LV)、右心室(RV)和心肌(MYO)的基本事实。我们报告了70例训练病例(1930个轴向切片)的平均DSC,10例用于验证,20例用于测试。
4.2 Implementation Details
对于所有实验,我们都使用简单的数据扩充,例如随机旋转和翻转。
对于基于纯Transformers的编码器,我们只需采用具有12个Transformers层的ViT[4]。在混合编码器的设计中,我们结合了ResNet-50[6]和ViT(表示为“R50-ViT”),贯穿本文。所有Transformers主干(即ViT)和ResNet-50(表示为“R-50”)都在ImageNet上进行了预训练[2]。除非另有规定,否则输入分辨率和patch大小P设置为224×224和16。因此,我们需要在CUP中连续级联四个2×上采样块以达到完全分辨率。对于模型,使用SGD优化器进行训练,学习率为0.01,动量为0.9,权重衰减为1e-4。ACDC数据集的默认批量大小为24,训练迭代的默认次数分别为20k和14k。所有实验都是使用一个Nvidia RTX2080Ti GPU进行的。
[17,19]之后,以逐片方式推断所有3D体积,并将预测的2D切片堆叠在一起,以重建3D预测以进行评估。
4.3 Comparison with State-of-the-arts
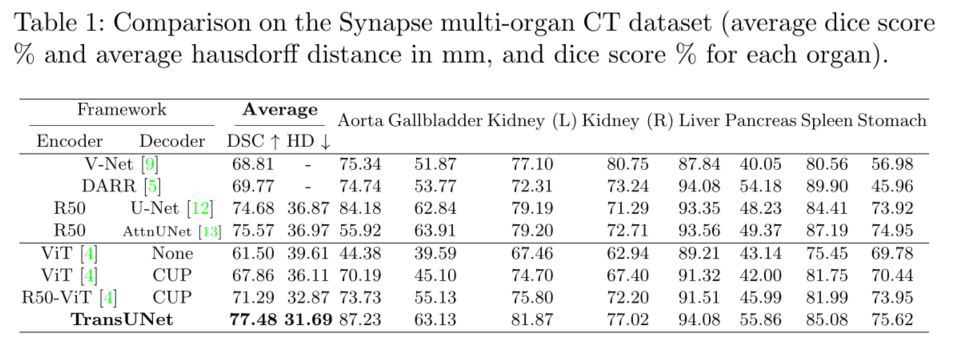
我们在Synapse多器官分割数据集上进行了主要实验,将我们的TransUNet与之前的四个最新技术进行了比较:1)V-Net[9];2) DARR[5];3) U-Net[12]和4)AttnUNet[13]。
为了证明我们的CUP解码器的有效性,我们使用ViT[4]作为编码器,并分别使用naive upsampling(“无”)和CUP作为解码器比较结果;为了证明我们的混合编码器设计的有效性,我们使用CUP作为解码器,并分别比较使用ViT和R50ViT作为编码器的结果。为了公平地与ViThybrid基线(R50 ViT CUP)和我们的TransUNet进行比较,我们还用ImageNet预训练的ResNet-50替换了U-Net[12]和Attnune[10]的原始编码器。DSC和平均hausdorff距离(单位:mm)的结果如表1所示。
注:
Dice系数是一种集合相似度度量指标,通常用于计算两个样本的相似度,对分割出的内部填充比较敏感
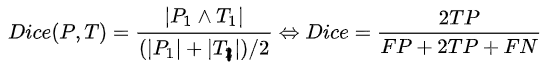
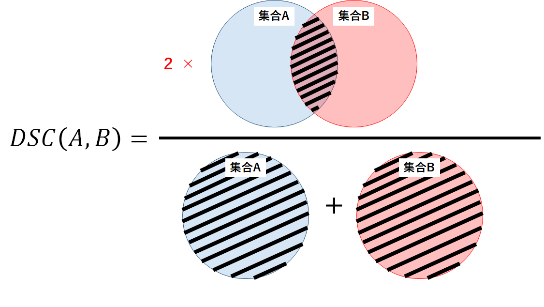
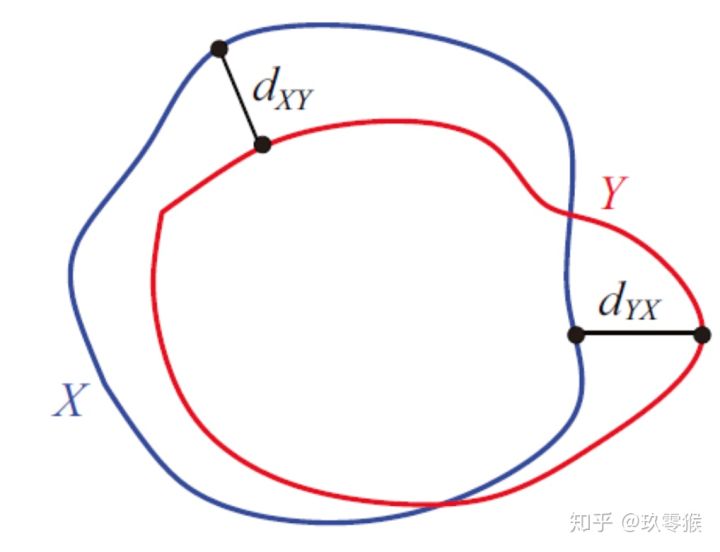
Hausdorff_95 (95% HD):Dice系数,而hausdorff distance 对分割出的边界比较敏感。
单向:先找最小,再找最大
双向:先找单向,再找最大
Hausdorff_95就是是最后的值乘以95%,目的是为了消除离群值的一个非常小的子集的影响。
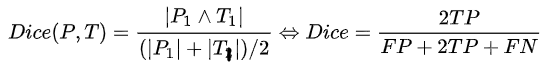
首先,我们可以看到,与ViT None相比,ViT CUP的平均DSC和Hausdorff距离分别提高了6.36%和3.50 mm。这种改进表明,我们的CUP设计比直接上采样提供了更好的解码策略。同样,与ViT CUP相比,R50 ViT CUP还表明DSC和Hausdorff距离分别提高了3.43%和3.24 mm,这证明了我们的混合编码器的有效性。基于R50 ViT CUP,我们的TransUNet也配备了跳跃式连接,在基于Transformers的不同型号中实现了最佳效果。
其次,表1还显示,与现有技术相比,拟议的Transune有显著的改进,例如,考虑到平均DSC,性能增益范围从1.91%到8.67%。特别是,直接应用Transformers进行多器官分割可以产生合理的结果(ViT CUP的DSC为67.86%),但无法与U-Net或attnUNet的性能相匹配。这是因为Transformers能够很好地捕捉高级语义,这有利于分类任务,但缺乏用于分割医学图像精细形状的低级线索。另一方面,将Transformers与CNN(即R50 ViTCUP)相结合,其性能优于V-Net和DARR,但仍低于基于CNN的R50-U-Net和R50 AttnUNet。最后,当通过跳过连接与U-Net结构相结合时,所提出的Transune开创了一种新的技术状态,分别比R50 ViT CUP和以前的最佳R50 AttnUNet高出6.19%和1.91%,显示了Transune学习高级语义特征和低级细节的强大能力,这在医学图像分割中至关重要。平均Hausdorff距离也有类似的趋势,这进一步证明了我们的TransUNet比这些基于CNN的方法的优势。
4.4 Analytical Study
为了彻底评估拟议的Transune框架,并验证其在不同环境下的性能,进行了多种消融研究, 包括:1)跳过连接的数量;2) 输入分辨率;3) 序列长度和patch大小以及4)模型缩放。
The Number of Skip-connections
如上所述,集成U-Netlike skip连接有助于通过恢复低级空间信息来增强更精细的分割细节。这项研究的目的是测试在Transune中添加不同数量的跳过连接的影响。通过将跳过连接的数量更改为0(R50 ViT CUP)/1/3,所有8个测试器官的平均DSC分段性能如图2所示。请注意,在“1-skip”设置中,我们仅在1/4分辨率范围内添加skip连接。我们可以看到,添加更多的跳过连接通常会导致更好的分段性能。通过将跳过连接插入CUP的所有三个中间上采样步骤(输出层除外),即在1/2、1/4和1/8分辨率标度下(如图1所示),可以获得最佳的平均DSC和HD。因此,我们的Transune采用这种配置。还值得一提的是,较小器官(即主动脉、胆囊、肾脏、胰腺)的性能增益比较大器官(即肝、脾、胃)的性能增益更明显。这些结果强化了我们最初的直觉,即将类似U网的跳过连接集成到Transformers设计中,以便能够学习精确的低级细节。
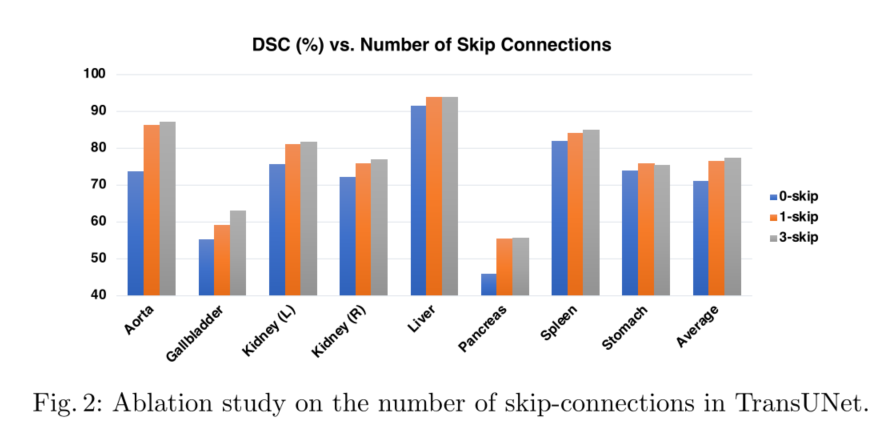
作为一项有趣的研究,我们在跳跃连接中应用了加法Transformers,类似于[13](attention-Unet论文同作者的一篇论文,大量相似也有大量修改-Attention Gated Networks),并发现这种新型的跳跃连接可以进一步提高分段性能。由于GPU内存的限制,我们在1/8分辨率的跳过连接中使用了一个光Transformers,同时保持其他两个跳过连接不变。因此,这一简单的改动使DSC的性能提高了1.4%。
On the Influence of Input Resolution
Transune的默认输入分辨率为224×224。这里,我们还提供了在高分辨率512×512上训练Transune的结果,如表2所示。当使用512×512作为输入时,我们保持相同的patch大小(即16),这会产生近似的结果5×Transformers的较大序列长度。如[4]所示,增加有效序列长度显示出稳健的改进。对于TransUNet,将分辨率比例从224×224更改为512×512会使平均DSC提高6.88%,但计算成本要高得多。因此,考虑到计算成本,本文中的所有实验比较均以224×224的默认分辨率进行,以证明TransUNet的有效性。

On the Influence of Patch Size/Sequence Length
我们还研究了patch大小对TransUNet的影响。结果汇总在表3中。据观察,较小的patch尺寸通常可以获得较高的分割性能。请注意,Transformers的序列长度与patch大小的平方成反比(例如,patch大小16对应的序列长度为196,而patch大小32对应的序列长度较短,为49),因此减小patch大小(或增加有效序列长度)显示出稳健的改进,随着转换器对每个元素之间更复杂的依赖关系进行编码,以获得更长的输入序列。按照ViT[4]中的设置,我们在本文中使用16×16作为默认patch大小。

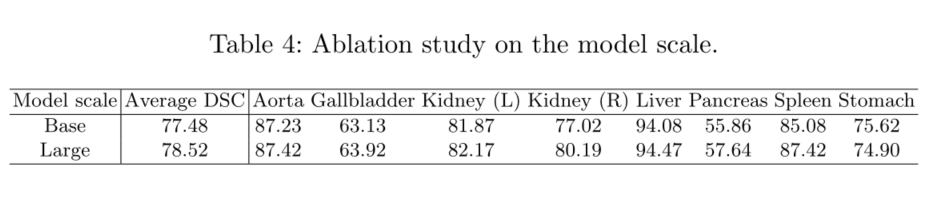
Model Scaling
最后但并非最不重要的一点是,我们对不同模型尺寸的Transune进行了削减研究。特别是,我们研究了两种不同的Transune配置,“基本”和“大型”模型。对于“基本”模型,隐藏大小D、层数、MLP大小和头数分别设置为12、768、3072和12,而“大型”模型的超参数分别为24、1024、4096和16。从表4我们可以得出结论,模型越大,性能越好。考虑到计算成本,所有实验均采用“基本”模型。
4.5 Visualizations
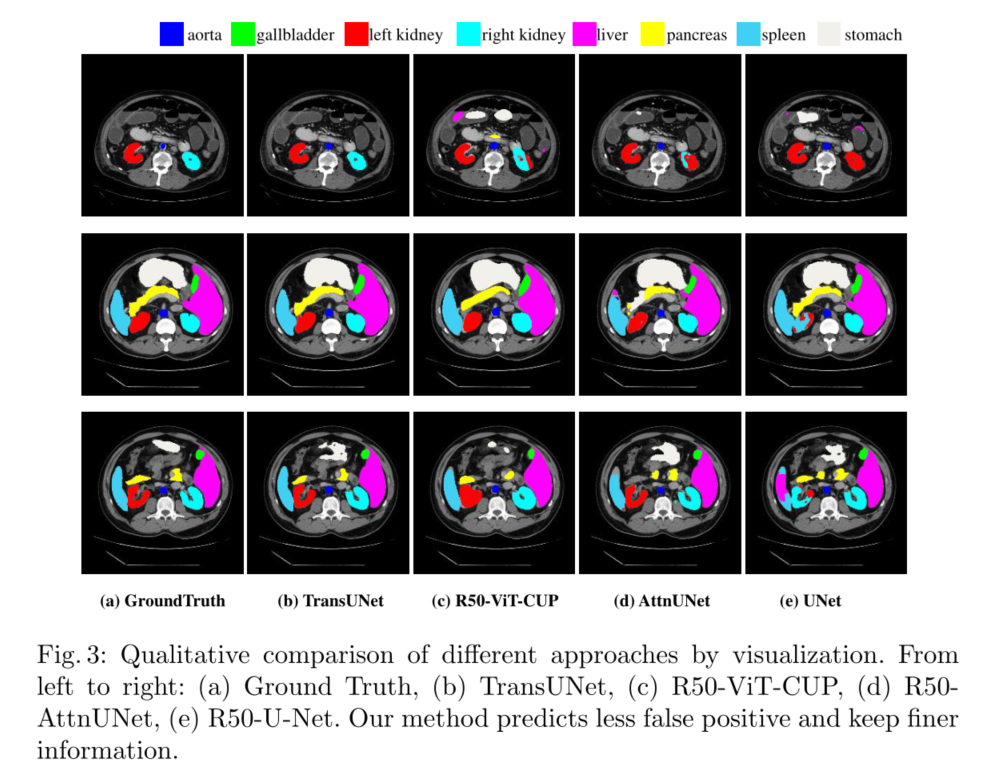
我们提供了Synapse数据集的定性比较结果,如图3所示。可以看出:1)基于纯CNN的方法U-Net和ATTNUET更可能过度分割或不足分割器官(例如,在第二排,脾脏被ATTNUET过度分割,而被UNet过度分割),这表明基于变压器的模型,例如我们的TransUNet或R50 ViT CUP,具有更强的全局上下文编码和语义区分能力。2) 第一行的结果显示,与其他方法相比,我们的Transune预测的误报更少,这表明Transune在抑制这些噪声预测方面比其他方法更有利。3) 为了在基于变压器的模型内进行比较,我们可以观察到,R50 ViT CUP的预测在边界和形状方面往往比Transune的预测更粗糙(例如,第二行胰腺的预测),此外,在第三排,当R50 ViT杯错误地填充左肾的内孔时,Transune可以正确预测左肾和右肾。这些观察结果表明,Transune能够进行更精细的分割,并保留详细的形状信息。原因是Transune既享受高级全局上下文信息的好处,也享受低级细节的好处,而R50 ViT CUP仅依赖高级语义特征。这再次验证了我们最初的直觉,即将类似U网的跳过连接集成到变压器设计中,以实现精确定位。
4.6 Generalization to Other Datasets
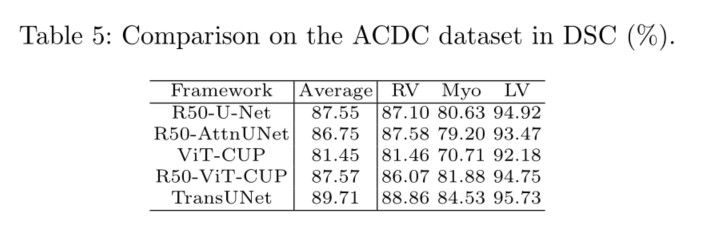
为了展示Transune的泛化能力,我们进一步评估了其他成像模式,即旨在自动心脏分割的MR数据集ACDC。我们观察到,与基于纯CNN的方法(R50 UNet和R50 ATTNUET)和其他基于转换器的基线(ViT CUP和R50 ViT CUP)相比,TransUNet的性能得到了持续改进,这与之前在Synapse CT数据集上的结果类似。
5 Conclusion
Transformers被称为具有强大内在自我注意机制的架构。在本文中,我们提出了第一项研究,以调查变压器的使用一般医学图像分割。为了充分利用Transformers的力量,提出了Transune,它不仅通过将图像特征视为序列来编码强大的全局上下文,而且还通过u形混合架构设计很好地利用了低级CNN特征。作为主流的基于FCN的医学图像分割方法的替代框架,Transune获得了比各种竞争方法更好的性能,包括基于CNN的自我注意方法。