Abstract
从心脏磁共振成像(多层二维电影MRI)勾画左心室腔、心肌和右心室是常见的临床诊断任务。因此,相应任务的自动化在过去的几十年里一直是深入研究的主题。在本文中,我们介绍了“自动心脏诊断挑战”数据集(ACDC),用于心脏MRI(CMR)评估的最大的公开可用的和完全注释的数据集。该数据集包含来自150个多设备CMRI记录的数据,包括来自两位医学专家的参考测量和分类。本文的首要目标是衡量最先进的深度学习方法在评估CMRI方面能走多远,即分割心肌和两个心室以及病理分类。结果表明,最佳的方法忠实地再现了专家分析,自动提取临床指标的相关评分均值为0.97,自动诊断的准确性为0.96。这些结果清楚地为心脏CMRI的高精度和全自动分析打开了大门。我们还确定了那些深度学习方法仍然失败的场景。数据集和详细的结果都可以在网上公开获得,平台也将继续开放新的提交。
关键词:心脏分割和诊断,深度学习,MRI,左右心室,心肌。
1.引言
心功能分析在临床心脏病学的患者管理、疾病诊断、风险评估和治疗决策[1]-[3]中发挥着重要作用。多亏了数字图像,从不同心脏的结构计算评估出的一组互补指数是心脏诊断的常规任务。由于其众所周知的区分不同类型组织的能力,心脏 MRI (CMR)(由一系列平行短轴切片构建)被认为是通过评估左心室和右心室射血分数进行心脏功能分析的金标准 (EF) 和每搏输出量 (SV)、左心室质量和心肌厚度。这需要在舒张末期(ED)和收缩期末期(ES)病例中准确描述左心室心内膜和心外膜,以及右心室心内膜。在临床实践中,由于全自动心脏分割方法缺乏准确性,半自动分割仍是一种日常实践。这导致了一些耗时的任务,容易产生观察者内部和观察者间的可变性[4]。
CMR分割的困难已经被明确识别,[5]:i)心肌和周围结构之间存在的对比差(相反,血液之间存在高对比a由于血流,左心室/右心室腔的亮度异质性;iii)存在骨小梁和乳头肌,其强度与心肌相似;iv)由于沿长轴的CMR分辨率有限而造成的非均匀的部分体积效应;v)由于运动伪影和心脏动力学引起的固有噪声;vi)不同患者和病理之间的心脏结构的形状和强度变异性;vii)条带伪影的存在。
为了衡量最先进的CMR分割方法的性能,在过去的十年里,[6]-[9]已经组织了四个国际挑战(都有一个独特的数据集)[6]-[9]。如第二节所述,有三个数据集集中在左心室,另一个集中在右心室。由于其中三项挑战是在2012年之前组织起来的,因此没有一个参与者实施了深度学习方法。至于第四个方法是,由于该数据集只包含ED和ES心室体积的地面真实值(而不是轮廓),因此很难确定哪种心脏分割方法是最准确的地方和失败的地方。
在本文中,我们提出了一个名为ACDC(自动心脏诊断挑战)的新数据集,并在2017年国际MICCAI组织了挑战。数据集的丰富度为由于它与日常的临床问题紧密相连,因此有可能使机器学习方法能够充分分析心脏MRI数据。ACDC比以前的心脏数据集有更大的范围t包括人工专家分割的右心室(RV)和左心室(LV)腔,以及心肌(更具体的是心外膜轮廓)。ACDC还包含了来自5个不同类型的患者主要医学组包括:扩张型心肌病(、肥厚性心肌病(HCM)、伴有左心室射血分数改变的心肌梗死、右心室异常(ARV)和无心脏病的患者(NOR)。
本文的首要目标是提供以下四个问题的答案:
1)最近提出的分割方法在给临床Mr图像中描绘左心室、右心室和心肌方面有多准确?
2)最近提出的分类方法在预测具有临床Mr图像的患者的病理方面有多准确?
3)当方法失败时,它们在哪里失败?
4)我们离“解决”自动CMRI分析的问题还有多远?
考虑到这些问题,我们首先详细介绍了之前的MRI心脏数据集,以及第二节中的CMRI分割方法。然后,我们将在第三节和第四节中描述我们的评估框架以及被评估的深度学习架构。我们在第五节中分析了在MICCAI-ACDC挑战期间获得的结果,最后在第六节和第七节中得出结论。
2.以往的工作
A.以前的MRI心脏数据集
在过去的十年里,四大临床CMRI数据集已经被社区广泛接受。这些数据集是与一个国际挑战一起发布的对最先进的方法进行基准测试。
Sunnybrook 心脏 MR左心室分割挑战-MICCAI 2009提供了一个包含45个心脏cine-MR图像的数据库,即:心力衰竭血症、无缺血的心力衰竭、肥厚性心肌病和正常受试者。数据提供了两个手动绘制的轮廓,一个为心内膜,一个为心外膜[6]。Al虽然该数据库仍然公开,但没有整理的结果或比较研究发表,从而减少了这一事件的影响。然而,最近的论文[5],[10],[11]分析了自2009年的挑战以来发表的几种自动和半自动分割方法的结果。根据这些结果,最高的性能的方法(其中许多只关注心内膜分割)报告的心内膜和/或心外膜的Dice评分在0.90-0.94之间,平均垂直距离小于2.0 mm,平均2D Hausdorff 距离在3.0和5.0mm之间。
LV分割数据集和挑战-MICCAISTACOM 2011重点比较了左心室分割方法[12]。该数据库包括200名冠状动脉疾病和既往心肌梗死患者的CMR采集(100例用于训练,100例用于检测)。在本研究中,作者基于贡献的证据引入了客观基础真理的概念几个评分者。特别是,为测试集的100名患者计算的基本真实信息是由使用结果的期望最大化框架(主要算法)[13]生成的两种全自动方法(自动评分)和三种手动输入的半自动方法(手动评分)。本研究中没有涉及100%手动注释的地面真相。从推导出的地面事实中,得到了分割精度的最佳评分结果,Jaccard平均得分为0.84[14]。
右心室分割数据集-MICCAI 2012旨在比较基于48个心脏心脏cine-MR数据的右心室分割方法与由一名心脏放射科医生绘制的轮廓(16个为训练,32个为测试)[8]。通过这一挑战,我们评估了3种全自动方法和4种半自动方法。早在2012年,挑战的结果显示,最好的分数是通过半自动方法获得的,如格罗斯乔治等人的[15]的图形切割方法,达到了平均Dice得分为0.78,平均2D Hausdorff 距离为8.62。在最近的一篇文章中,Tran[16]展示了一个微调的全卷积神经网络[17]如何能够优于所有的半自动方法,平均Dice得分为0.85。
2015年Kaggle第二届年度数据科学大赛是190多支队伍竞争赢得20万美元的一个挑战,目标是从CMR中自动测量ED和ES卷。挑战者得到了一个由500名培训患者和200名测试患者组成的数据库。训练图像只提供了ED和ES参考卷,而没有提供针对其他三个数据集的手动分割地面真相。挑战的结果显示,表现最好的方法依赖于深度学习技术,特别是全卷积网络(fCNN)[17]和U-Net[18]。不幸的是,在这一挑战之后,没有提供任何摘要文件。
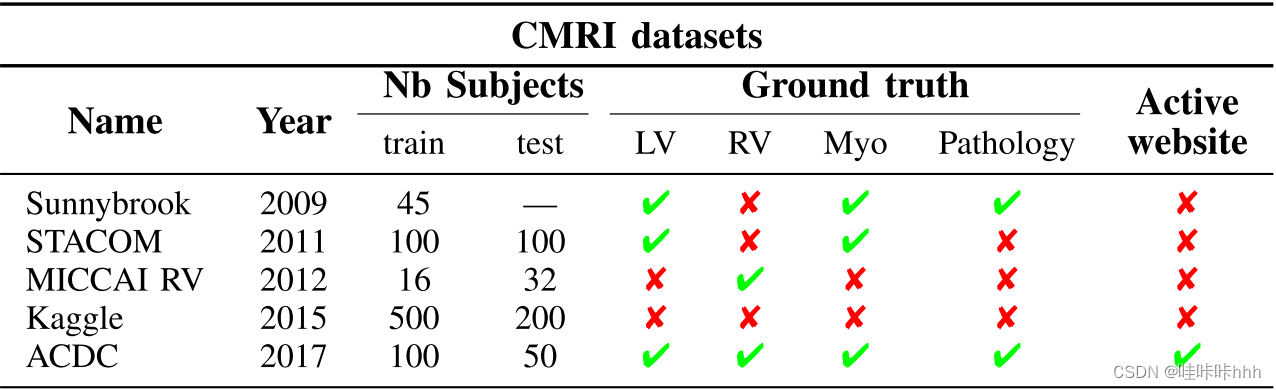
表1 现有的公开可供比较之用的心脏MRI数据集的完整总结
表一总结了上面提到的MRI心脏数据集。让我们还提到,其他完全注释的心脏数据集已经发布,如HVSMR 2016和多模式全心脏分割数据集。虽然很有趣,但这些数据集包含了临床上不典型的图像,这一主题超出了本研究的重点。此外,在不受挑战约束的情况下,英国生物样本库[19]对应的是现有最大的CMR数据库,该数据库可以用于训练和测试深度学习方法这些图像的符号将被公开。然而,这个数据库的一个限制是它不是免费的,这不可避免地限制了研究团队对它的访问,因此不符合开放的科学倡议,如挑战。
B. 非深度学习方法
与这些挑战同时,Petitjean和Dacher[20]在2011年提出了一个对在短轴心脏Mr图像中描绘左心室或右心室的分割方法的完整综述。在这项研究中,作者列出了发表在70多篇同行评审出版物上的研究结果。对于上述四个挑战,所报告的方法可分为两大类:弱先验方法和强先验方法。第一组涉及到微弱的假设,如空间、强度或解剖信息。它包括基于图像的技术(阈值,动态规划)[21],像素分类方法(聚类,高斯混合模型拟合)[22],可变形模型(主动轮廓,水平集)[23]和基于图的方法(图切割)[24]。第二组使用方法强先验包括基于形状先验的变形模型[5],主动形状和外观模型[25]和基于图集的方法[26],都需要一个手动注释的训练数据集。虽然这项巨大的工作提供了在LV/RV分割中最先进的方法的性能的完整图片,但它确实用一个独特的数据集对这些技术进行了基准测试。因此,这种比较仍然是我们社区中一个突出的问题。
C. 深度学习方法
据我们所知,在2013年之前,没有使用深度学习技术来分析CMRI。然而,在2015年Kaggle第二年度数据科学碗期间发生了剧烈的变化深度学习方法的力量。从那时起,在CMRI分析的主题上发表了12篇深度学习论文。大多数论文使用二维卷积神经技术网络(CNNs),并对MRI数据进行切片分析。
有三篇论文使用深度学习框架提取相关特征进行分割。Emad等人[27]使用一个分段的CNN来定位在CMRI切片中的LV。Kong等人[28]开发了一个时间回归框架,通过将二维CNN与递归神经网络(RNN)集成,从心脏周期中识别舒张期和收缩期末期的实例。其中CNN用于编码空间信息,而RNN用于解码时间信息。最后,Zhang等人[29]使用一个简单的CNN自动检测心脏检查中缺失的切片(根尖和基底),以评估MRI获取的质量。
有四篇论文使用了深度学习方法和经典的心脏分割工具。Rupprecht等人[30]将一个基于补丁的CNN集成到一个半自动主动轮廓分割心脏结构的系统中。Ngo等人。[31]使用了一个深度信念网络(DBN)来准确地初始化和指导一个水平集模型来分割左心室。Yang等人[32]采用CNN和多图谱的方法进行左室分割。特别是,我们训练了一个深度体系结构来学习深度特征,以实现在多图谱分割中经典的标签融合操作的最佳性能。另外,Avendi等人[10]提出了一种结合深度学习和可变形模型的方法来自动分割左心室。该方法的工作原理如下:i)一个简单的CNN定位和裁剪LV;ii)一堆自动编码器对LV形状进行预分割;iii)用一个可变形的模型对预分割的形状进行细化。尽管作者报告了2009年Sunnybrook的几乎完美的结果,目前还不清楚他们的方法如何推广到多个心脏区域。
最后,有三篇论文使用独立的深度学习技术从CMR数据中分割心脏结构。Poudel等人[33]提出了一种递归全卷积网络(RFCN),从二维切片的全堆栈中学习图像表示。派生的体系结构允许通过内部内存单元来利用层间的空间依赖关系。Tran[16]开发了一种深度的全卷积神经网络结构来分割左心室和右心室的结构。最后,Oktay等人[34]提出了一种基于残差卷积神经网络模型的图像超分辨率方法。这个它的关键思想是从二维图像堆栈中重建高分辨率的三维体积,以获得更准确的图像分析。
有关深度学习方法应用于医学图像分析(包括心脏MRI分割)的更多细节,请参考Litjens等人[35]和Havaei等人[36]。
3.评价框架
A. CMR数据
1)患者选择:ACDC数据集是根据在第戎大学医院(法国)获得的真实临床检查创建的。我们的数据集涵盖了几个定义良好的病理学,有足够的案例来正确地训练机器学习方法,并清楚地评估从这些数据集中获得的主要生理参数的核磁共振成像的可变性(特别是舒张容量和射血分数)。这个目标人群由150例患者组成,根据生理参数平均分为5类,特征明确。这些检查最初被归类为分类到医疗报告。本研究排除了临床指标不明确的患者。下面给出了不同的子组:
- NOR:心脏解剖和功能正常。男性射血分数大于50%,舒张期壁厚低于12mm,男性左室舒张期容积低于90 mL/m2女性[37]的浓度为80mL/m2。每个患者的右心室均正常(右心室容积小于100 mL/m2,右心室射血分数高于40%)。节段性左心室和右心室心肌收缩的视觉分析正常。
- MINF:收缩期心力衰竭伴心肌梗死的患者。受试者的射血分数低于40%,心肌收缩异常。一些受试者左室舒张量高,由于左室重构以补偿心肌梗死。
- DCM:扩张型心肌病患者的射血分数低于40%,左室容积大于100 mL/m2,舒张期壁厚小于12mm。由于左心室的扩张,一些这类患者有右心室扩张和/或高左心室肿块。
- HCM:肥厚性心肌病患者,即心功能正常(射血分数大于55%),但舒张期心肌节段厚大于15 mm。在这类患者中,心脏质量指数异常,数值超过110g/m2。
- ARV:男性右心室异常患者右心室容积大于110 mL/m2,女性[38]患者右心室容积大于100 mL/m2或右心室射血分数低于40%。该亚组中几乎所有受试者左室均正常。
2)采集协议:在6年的时间里,使用两台不同磁性强度的MRI扫描仪(1.5 T-西门子地区,西门子医疗解决方案,德国和3.0 T-西门子,西门子医疗解决方案,德国)。CMR图像采用常规SSFP序列屏气,回顾性或前瞻性门控[39]。在获得长轴切片后,获得了从基部到心尖的一系列短轴切片,切片厚度为5 mm到10mm(一般为5 mm),有时片间间隙为5 mm。空间稀释度从1.34到1.68mm2/像素不等。根据患者的不同,获得28-40个体积,以覆盖完全(回顾性门控)或部分(前瞻性门控)一个心脏周期。在后一种情况下,只有5-10%的心周期结束被省略。完整的数据集是在临床常规检查中获得的,导致了图像质量的自然变化(内在噪声,患者运动、条带伪影、MRI低频强度波动等),可变视场和低压的积分或几乎积分覆盖。最后,要遵守先例心脏MRI分割的挑战,没有提供长轴切片。即使使用长轴切片可以提供关于基部、心尖和纵向运动的额外信息脑室离子,短轴和长轴切片的分析通常是独立的,超出了本项目的范围。
3)训练和测试数据集:每个受试者的数据被转换为一般的4D图像表示格式(nifti),而不损失分辨率。ED和ES帧是由单一专家根据二尖瓣从长轴方向的运动来确定的。训练数据和测试数据都包含完整的短轴切片。最基底和顶端切片的识别也没有提供,而舒张期和收缩期被指出。为了让挑战者正常化生理参数(主要是左心室和右心室的体积和MYO质量)与体表面积(BSA),每个患者的体重和身高都包括在数据集中。例如,BSA可以根据Du Bois和Du Bois[40]的公式计算出来,即BSA=0.007184·(体重0.425·身高0.725)和归一化参数可以通过简单地将它们的值除以相应的BSA来计算。训练数据库由100例患者组成,即每组20例患者。对于所有这些数据,都提供了相应的手工参考资料以及患者组。测试数据集由50例患者组成,即每组10例患者。测试数据的手动参考和组标签保持保密。
B.参考分割和轮廓协议
专家参考文献是手工绘制的左室和右心室腔以及ED和ES门心肌的三维体积。右心室的心外膜边界不被考虑,因为其交流在鼻中隔旁的导管位置很难确定,而且右心室的心肌厚度与空间分辨率是相同的数量级。这些轮廓由两名独立专家(10年和20年的经验)绘制并进行了复核,他们必须在不一致的情况下达成共识。
保留以下标注规则:左心室和右心室必须完全覆盖,乳头肌被纳入腔内,左室基部没有肌肉插值(轮廓遵循主动脉瓣定义的极限)。标注RV的主要困难在于正确定位肺漏斗区域。该区域不能包含在右心室注释中,右心室腔和肺动脉根部之间必须有清晰的分离。由于右心室的收缩期缩短,第一个基底切片在舒张期和收缩期并不是强制性的。另一个困难是在收缩期图像上准确地分离右心房和右心房。因此,我们将RV定义为心脏右侧的区域在心室舒张期和收缩期之间有明显的收缩,即右心室舒张期的表面积必须高于心室收缩期。为了更容易理解在补充资料中提供了注释规则的说明。
地面真实标签图像以nifti格式存储。标签值从0到3不等,代表属于背景(0)、右心室腔(1)、心肌(2)和左心室腔室的体素 (3)。
C. 评价指标
为了以公平和可重复的方式评估测试方法,我们定制了一个专用的Girder7在线平台。这个平台现在已经可用,只要这些数据仍然与临床研究相关将被维护和保持开放。基于这个平台,从几何学和临床学的角度比较了最先进的方法性能。这意味着使用本文[41]中描述的互补度量集。
1)几何指标:为了测量给定方法提供的分割输出(左心内膜、心肌或右心内膜)的准确性,我们使用了Dice度量和三维Hausdorff距离。
a)Dice相似度指数:Dice相似度指数定义为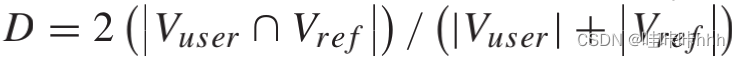 ,是从一种方法中提取的分割体积Vuser与对应的参考体积Vref之间重叠的度量。Dice指数给出了一个介于0(无重叠)和1(完全重叠)之间的测量值。
,是从一种方法中提取的分割体积Vuser与对应的参考体积Vref之间重叠的度量。Dice指数给出了一个介于0(无重叠)和1(完全重叠)之间的测量值。
b)Hausdorff表面距离(dH):Hausdorff距离dH,测量两个表面Suser和Sref之间的局部最大距离。这是使用接近查询包(PQP)[42]有效地执行的,我们稍微修改了它来计算点到三角形的距离。此外,为了最小化Suser和Sref的采样密度之间的差异,我们对包含最小顶点数的曲面应用了一个线性细分算子。与一些报道二维Hausdorff距离[5],[10],[11]的MRI心脏分割论文不同,我们报道了3D dH,它允许一个内在的管理解决了末端切片上缺失的分割问题。
2)临床表现:我们还对临床参数实施了三个指标,即相关性(corr)、偏差和标准偏差(std)值。这三个度量都是从度量中计算出来的其中:i)ED体积(左室和右心室的LV EDV和RV EDV分别以mL/m2表示);ii)射血分数(LV EF和RV EF分别以左室和右心室的百分比表示);iii)心肌质量(MYMass以g/m2表达,以舒张期计算)。偏差和标准差的结合也提供了相应的协议值极限的有用信息。
让我们提的是,这些几何和临床指标是互补的,因为在一个指标上的好分数并不必然意味着在其他指标上的好分数。这个特性对于防止我们的系统意外地偏爱某些方法而不是其他方法非常重要。例如,一个较低的EF误差并不总是意味着可以很好地描述ED和ES心室,因为EF依赖于ED和ES体积之间的差异。例如,自EF以来,低EF误差并不总是意味着ED和ES心室依赖于ED和ES卷之间的差异。因此,一种在ED和ES上系统地高估或低估心室大小的方法是可能具有低EF偏差,低平均平均误差和高EF相关性,但同时具有低Dice得分和较大的Hausdorff距离。
3)分类性能:对于分类上下文,提供了一个预测精度度量。这一准确性是针对整个测试数据库的检查和每种疾病进行计算的。为了突出显示结果,我们创建了混淆矩阵。
D. MICCAI 2017框架
该评估框架是在已举行的“自动心脏诊断挑战(ACDC)”研讨会期间启动的与2017年9月10日在加拿大魁北克市举行的第20届医学图像计算和计算机辅助干预国际会议(MICCAI)合作。在公开邀请人们参加这次挑战后,在挑战网站上创建了106个账户。10个团队在指定的时间内上传了有意义的结果而有4个团队参加了诊断比赛。
4.评估架构
在本节中,我们将描述分割竞赛中涉及的不同架构以及分类竞赛中提出的方法。

表2在ACDC挑战中评估的方法的概述
A.心脏多结构分割的体系结构
表二总结了本研究中涉及的10个架构。9种方法实现了深度卷积体系结构,其中大多数是类似U-Net的网络[18]分析3逐片处理D数据。唯一的例外是Tziritas和Grinias[49]的方法实现了Chan-Vese水平集方法,然后采用MRF图切割分割方法和样条拟合来平滑结果倾斜的边界。
有四篇论文重复使用了U-Net架构。Baumgartner等人[43]测试了具有各种超参数的U-Net和FCN架构。他们还测试了使用2D和3D卷积的影响N层以及训练Dice损失与交叉熵损失。他们最好的架构最终是一个U-Net,用交叉熵损失训练二维卷积层。Isensee等人[44]补充了一个2D和3D U-Net架构的集合(沿着上采样层的剩余连接)。在三维网络中,由于输入图像的片间间隙较大,池化和算法只在短轴平面上进行升级操作。此外,由于对内存的需求,这3D网络涉及到较少数量的特征图。这两个网络都用Dice损失训练。
与Baumgartner的研究类似, Patravali等人的[47]测试了一个用不同的Dice和交叉熵损失训练的2D和3D U-Net。从他们的实验来看,性能最好的架构是Dice损失的2D U-Net。最后,Yang等人的[51]实现了一个3D U-Net,但使用了剩余的连接,而不是通常的连接操作符。他们还使用了预先训练好的权值来进行降采样路径,并使用了已知的C3D网络,它在视频分类任务[54]上工作得很好。他们的网络采用了多级Dice损失训练。
有四篇论文使用了U-Net的修改版。Jang等人[45]实现了一个“M-Net”[55]架构,其与U-Net的主要区别在于[55]的解码层的特征映射与前一层的那些层连接起来。采用加权交叉熵损失训练。Khened等人[46]实现了一个密集的U-Net。他们的方法首先用傅里叶变换找到感兴趣的区域,然后在第一次谐波图像上使用Canny边缘检测器,并在之前生成的边缘映射上进行一个圆形的霍夫变换计算出LV 的近似半径和中心。然后,他们使用一个带有密集块的U-Net,而不是基本的卷积块,以使系统更轻。这个网络的第一层也对应于一个初始层。系统用Dice和交叉熵损失进行训练。Rohe等人[48]开发了一种多图谱算法,首先将训练数据中的所有图像注册目标图像,然后使用像素级置信度度量与软融合方法合并。该注册模块实现了一个名为SVF-Net[56]的编解码器网络。此外,Zotti等人[52]实现了一个“Grid Net”网格网架构,它对应于一个沿着跳跃连接具有卷积层的U-Net。该体系结构还注册了一个形状先验,在执行最终决定之前被用作附加的特征映射。该模型采用四项损失函数进行训练。
Wolterink等人[50]是唯一一个没有编解码器架构实现CNN的团队。相反,他们使用了一系列随着水平不断增加的核扩展卷积层,以确保使用足够的图像上下文为每个像素的标签预测。该CNN同时输入空间对应的ED和ES 2D切片,而网络的输出被分成两个,一个softmax为ED,一个为ES。
B.心脏自动诊断的解决方案
分割挑战的三个参与者使用他们的分割结果来提取特征进行心脏诊断。Isensee[44]等人从中提取了一系列的实例和动态特征分割映射并使用50个多层感知器(MLP)和一个随机森林进行分类。Khened等人的[46]使用了11个特征,其中9个来自于他们的分割图除了病人的体重和身高。根据这些特征,他们训练了一个100棵树的随机森林分类器。Wolterink等人[50]提取了14个特征(12个来自分割图+患者体重和身高),并使用五类随机森林与1000棵决策树分类器。
Cetin等人[53]是唯一一种采用半自动分割方法来手动提取心脏结构轮廓的人。基于这些轮廓,他们计算了567个特征公司提示生理特征(如身高和体重)和放射性特征,如基于形状的特征、强度统计和各种纹理特征。为了防止他们的方法过拟合,他们选择了最具区别性的特征,并使用SVM进行分类。
5.结果
A.分割挑战
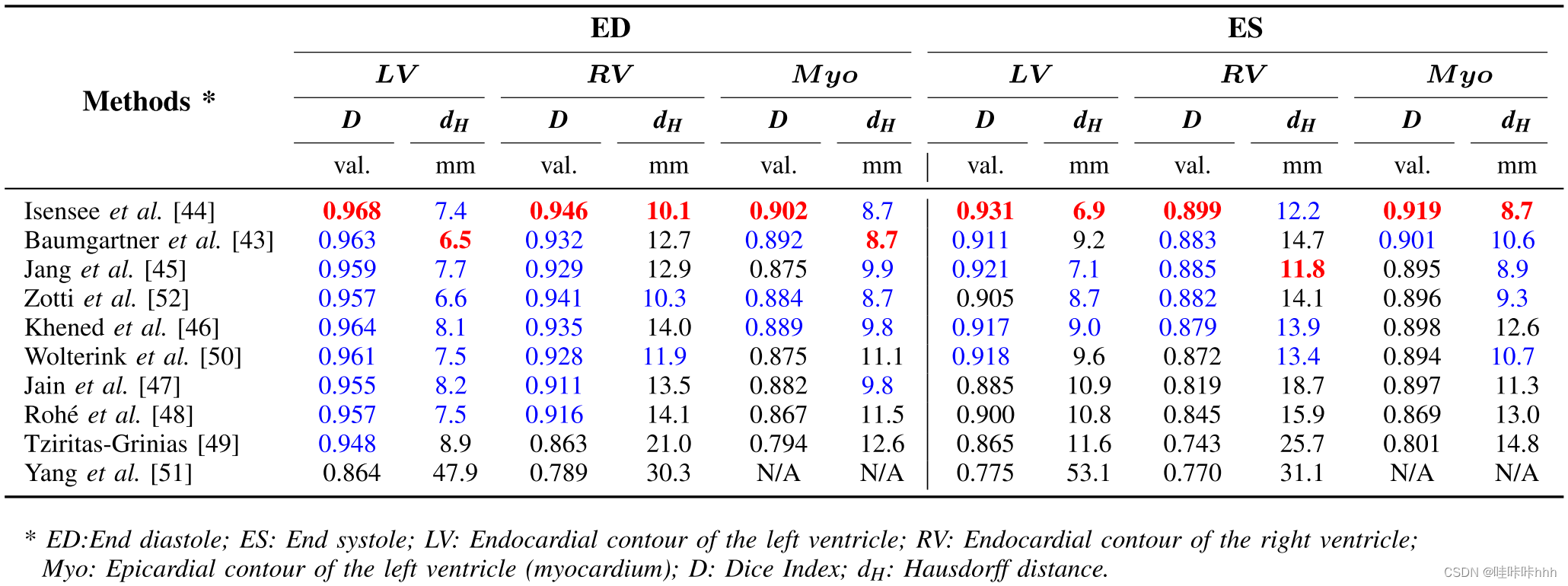
表三:10种评价方法在测试数据集上的分割精度。红色是最好的方法,蓝色是在一致的范围内的方法(Dice指数为0.02和Hausdorff距离最佳位置2.26毫米)
为了对结果进行详细的分析,在补充材料中提供了一组分割输出(可在补充文件/多媒体选项卡中提供)。这应该有助于更好的评估这是最佳方法的质量。表三显示了所有10种算法的分割测试精度(50例患者)。红色的值对应于每个指标的得分最好的值,而蓝色的值对应于距离顶部方法一个像素的方法。我们使用这个颜色代码来强调所涉及的方法之间的紧密性。温度湿度指数Hausdorff距离(两个像素之间的最大平面内对角线距离: )为2.3 mm,Dice度量为0.02一种方法的分割图与被1像素放大或侵蚀1像素的相同分割图之间的Dice平均分数)。这个一个像素标准来自于这两位专家给自己提供了一个像素标准像素误差范围,即当两个注释的二维Hausdorff距离小于或等于一个像素时,这两个注释被认为是相同的。
)为2.3 mm,Dice度量为0.02一种方法的分割图与被1像素放大或侵蚀1像素的相同分割图之间的Dice平均分数)。这个一个像素标准来自于这两位专家给自己提供了一个像素标准像素误差范围,即当两个注释的二维Hausdorff距离小于或等于一个像素时,这两个注释被认为是相同的。
从这些结果中可以看出,由Isensee等人[44]提出的2D-3D U-Net集成模型总体上是性能最好的方法(相应的代码可以通过以下文件公开获得这种方法与其他方法密切相似,特别是对于在ED处的LV和RV。例如,Baumgartner等人,Jang等人,Zotti 等人和Khened等人在12个指标中的9个的最佳表现方法的一致范围内。而Tziritas和Grinias的无深度学习方法则相对较远从顶部,特别是对RV和MYO。

表四为测试数据集上的10种评估方法的临床指标。RED是最好的方法,蓝色是根据偏差和STD测量的Ap值大于0.05的方法
表四包含了所有10种方法的临床指标。对于分割部分,红色的值对应于每个度量的最佳分数。蓝色的值对应于具有p值的方法与最佳方法相比,大于5%(我们使用了不相等的方差双样本t检验)。
在临床指标方面,Khened等人的[46]在全球表现优于其他方法,20个指标中有14个接近表现最好的方法(即红色和蓝色指标)。在相关性方面指标,大多数方法获得高度准确的结果,值超过0.96。方法也得到了良好的LV EF结果,相关性得分高,偏差接近于0(0.8%在平均),一个小的平均值绝对误差(平均3.2%)和小标准差(4.3%)。最难以估计的临床指标是右心室的EF,最佳方法的相关性得分为0.9。
表III和表4的联合分析显示,心肌(特别是ES)的结果是变化最大的。这可能部分解释为,准确的心肌分割意味着精确的描绘两个壁,而不是左室和右心室。方法也要与RV作斗争。RV通常有最高的Hausdorff距离,最低的Dice得分,最低的相关值,和最大的偏差。为了进一步强调这一观察结果,我们在表V中记录了预测EF小于5%的患者百分比真相(5%通常被认为是可接受的误差幅度[57])。虽然前六种方法准确预测了87%患者的左室射血分数,但这个数字急剧下降到59%。
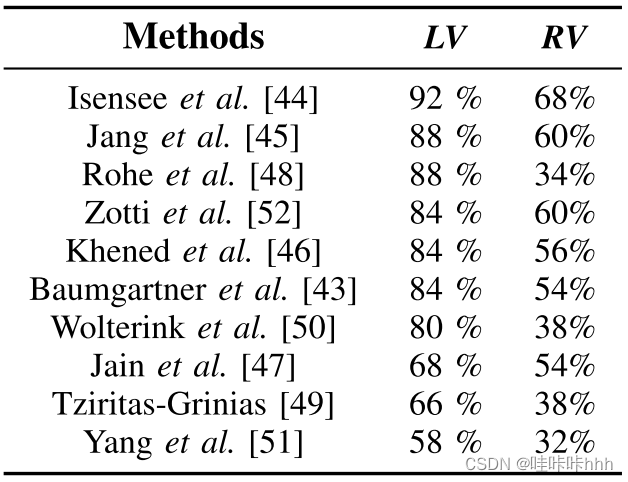

表V中EF误差低于5%的患者的百分比 图1 分类挑战[46]的获胜者的混淆矩阵
B.分类挑战

表六 关于分类挑战的结果
表六给出了4种评价方法的分类性能的概述。由于样本数量较少(50例患者),必须谨慎考虑评分,因为错过分类会导致准确率下降2%。从这个表中可以看到Khened等人[46]获得几乎是完美的结果,有48例患者被正确分类。该方法的混淆矩阵如图1所示。请注意,接下来的两种方法都要严格遵循最好的方法其准确率为92%。
值得一提的是,虽然MINF和DCM在视觉上相似,但与DCM相比,MINF意味着局部缺乏心肌收缩。此外,对于DCM,低压必须超过100mL/m2。这就是为什么机器学习方法能够成功地区分这些病理学。
C. 讨论
1)我们离解决CMRI分析问题有多远?:自动分类结果(健康受试者和4种不同病理的患者)显示,最佳方法非常接近,准确率在92%以上。尽管这些老板错误必须在更多的患者身上进行验证,从这项研究中似乎设计良好机器学习技术可以达到接近完美的分类分数。
然而,对于分割任务来说,结论并不是那么简单。虽然在LV上获得的结果具有竞争力,但似乎仍然难以获得相同水平的精度的RV和MYO。因此,相对于专家的可变性,评估顶级方法的性能是很重要的。不幸的是,ACDC数据集的实际版本为每个主题带有一个专家注释,并且没有提供任何观察者间或观察者内部的误差范围。

表七:观察者之间和观察者内部的Dice和Hausdorff距离ii)每个提交的深度学习(DL)方法的平均值和iii)分割挑战的获胜者。“红色颜色”观察者内部或以上的结果。最后5行对应于没有顶端和基底切片计算的指标
为了评估观察者间和观察者内的变量,我们询问了共同注释ACDC基本事实的两个专家O1和O2,独立地重新标记50个测试的图像用户。O1对图像进行了两次注释(我们称这些注释为O1a和O1b),而O2对图像进行了一次注释。O1a、O1b和O2之间的平均几何距离以t的形式在表七的前三行给出。正如我们可以看到的,Dice分数在0.86到0.96之间振荡,而HD在4毫米到14.1毫米之间振荡。毫无疑问,ES上的RV是最难注释的区域,即使对实验观察者也是如此。同样有趣的是,Dice的变化(特别是对于内部观察者与Bai et al.[58]最近发表的一篇文章非常接近。至于dH值,表七中报告的值大于Wenjia等人的论文,因为我们的dH实现考虑了Wenjia的三维结构心由于层间厚度为10mm(平均),两个注释之间的任何轻微的横向移动都会大大增加dH评分(请参考参考文献中的补充材料补充文件/多媒体选项卡以了解更多细节)。
在表七中给出的观察者之间和观察者内部的结果下面,我们提供了i)由挑战中涉及的深度学习方法获得的平均几何指标和ii)获得的分数他是分割挑战的获胜者。有趣的是,他们的Dice得分都在观察者间和观察者内部得分之间。这表明,最先进的深度学习技术已经已经达到了一个平台,在这个指标下。虽然进一步应该进行调查来验证这一断言(特别是对于从一组更异构的设置中获得的图像),所获得的结果倾向于表明,当经过适当的训练时,深度学习技术能够一路提高那些专家的Dice分数。对于dH分数,方法略高于观察者间分数,但仅为2到3毫米。

表八:LVEDV、RVEDV和MYMass的平均绝对误差的观察者间和观察者内的变化。下面是挑战的获胜者和深度学习方法与AC相比的平均深度学习方法华盛顿的地面真相。红色是观察者间和观察者内方差之间的结果
在表八中,我们将从LVEDV、RVEDV和MYMass度量计算出的观察者间和观察者内部的平均绝对误差。从给定的数字中,我们可以看到观察者间和观察者内的得分与Bai等人的[58]报道的非常接近。此外,Isensee等人获得的结果和平均深度学习方法在观察者间和观察者内部得分之间。
2)方法在哪里失败?:根据到目前为止报告的结果,根据Dice得分和临床指标,顶级的深度学习分割方法似乎在人类期望的范围内,但仍然是2到3毫米外来自专家们关于三维豪斯多夫的距离。因此,人们可能会想知道,方法在哪里失败了?一种假设可能是,患有病理疾病的心脏可能更难分割。为了验证这一假设,我们在图2中分解了由测试集上的挑战者获得的每个病理的平均Dice和Hausdorff指标(我们提醒每个病理病例对应于相同数量的患者,包括是在训练阶段和测试阶段)。正如我们所看到的,没有病理方法系统地失败。例如,虽然HCM的Dice得分有点高LV-ES的低(当然是由于难以看到心脏腔),它比MYO-ES和MYO-ED的其他病理要大。此外,与人们可能认为的相反,来自健康受试者(NOR)的图像并不比来自病理病例的图像更容易分割,因为相对于这一组的分数得分最大为LV-ED和LV-ES的距离。
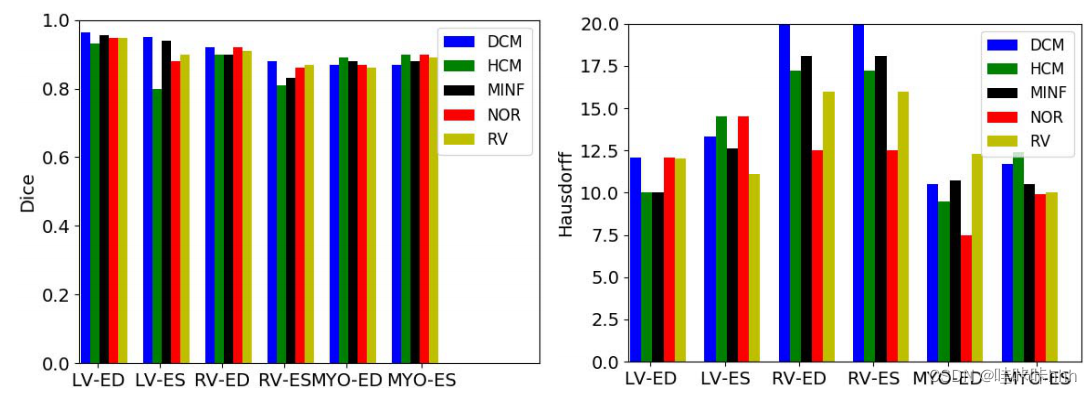
图2 表三中报告的每种方法的平均Dice指数和Hausdorff距离对每种病理进行了分类
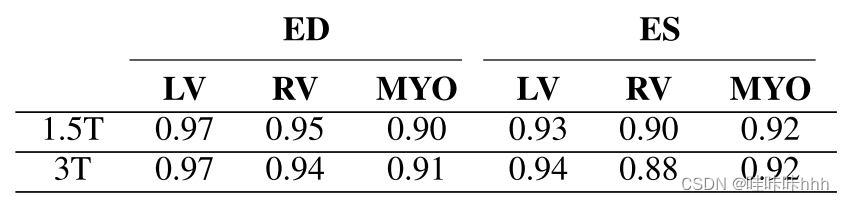
表九 分割挑战[44]的获胜者在1.5T和3T CMR图像上的得分
另一种假设是,由于固有的低信噪比,1.5T的图像比3T图像的CMR图像更难分割。然而,经过仔细分析分割结果,我们发现部分1.5T和3T结果之间没有特别的差异,如表九所示。其中一个原因可以解释为,1.5T和3T的图像都包含在训练集中神经网络学习两种磁场的表示。为了能够目测1.5T和3T CMR图像之间的差异,我们在补充材料(可在补充文件/多媒体选项卡中获得)中输入了一个这些图像的例子以及它们相应的MRI直方图。
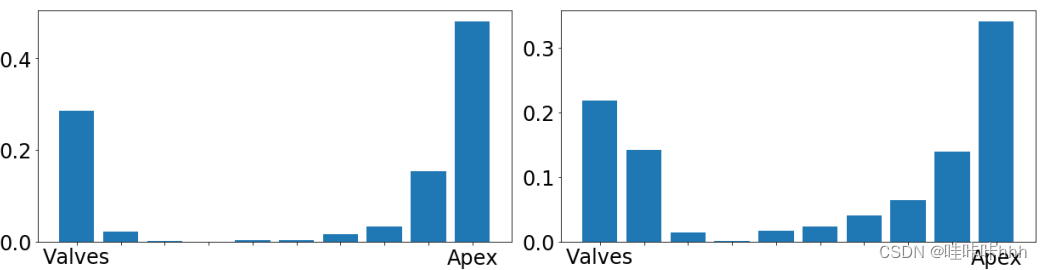 图3 退化切片ED(左)和ES(右)的直方图
图3 退化切片ED(左)和ES(右)的直方图

图4 典型的心脏基部退化的结果,左输入图像中间地面真相右预测
另一个社区普遍接受的假设是,由于与周围结构的部分体积效应,瓣膜和/或心室顶端附近的切片更难分割。为了研究这一假设,我们计算了由LV、MYO或RV的Dice得分低于0.70的每种方法所产生的2D分割结果的总数。相应的分辨率错误是通过图3中的直方图进行总结,其中x轴代表切片的位置(从左侧的瓣膜到右侧的顶端)。请注意,由于切片的数量是从一个患者到另一个患者,我们将每种方法的二维分割结果堆叠,并制作一个三维体积。然后用最近邻域插值方法将每个体积调整为10个切片。从这个图中可以看出,在瓣膜和顶点附近获得的分割结果更容易出错。特别是,我们注意到几乎50%的结果的Dice得分非常低心尖(通常是因为LV/MYO/RV在那个位置非常小)。至于基部,我们观察到,这些方法通常很难区分右心室、左心室、心房和周围的结构(c.f.图4)。我们还在表七中列出了Dice指数和Hausdorff指标计算,没有顶端和基底切片。虽然Dice的分数几乎相同,Hausdorff距离显著减少,有时会减少两倍。有趣的是,学习方法属于观察者间和观察者内的变量(除了在ES的RV的Hausdorff度量),这表明,分割根尖和基底切片要困难得多,即使对专家来说也是困难。
最后,值得指出的是,使用比本项目中所涉及的数据库更大的数据库可能有助于解决所列出的剩余问题。例如,英国生物样本库[19]可能是一个重要的候选者。因此,我们认为英国生物样本库和我们的数据库是为即将到来的研究提供材料的强大潜力的补充。
3)需要一个新的度量:迄今为止报告的结果表明,顶级的深度学习方法非常接近于观察者间的可变性。然而,对他们的分割的视觉检查结果显示,与专家不同,深度学习方法有时会产生解剖学上不可能产生的结果,如图4所示。有趣的是,用于衡量性能的指标似乎很有弹性这样的异常。为了测量解剖学上不可能的结果的数量,我们的一位专家通过Isensee等人[44]的测试结果。这显示,50例患者中有41例至少有一个切片的解剖上不可能分割,如右心室与MYO断开或左心室腔接触背景(在补充文件/多媒体选项卡中提供的补充材料中给出了几个详细的例子)。这41例患者的平均1.6个切片的结果有问题它们大部分位于阀门或顶端附近。这清楚地强调了这样一个事实,即用于评估结果的临床和几何指标有重要的限制,而方法在观察者间的可变性可能仍然容易出错。这表明,在人们可能声称方法已经达到专家的准确性之前,需要新的评估指标。
6、临床意义
到目前为止的结果表明,我们正处于全自动CMRI分析螺母的前夕。这将允许减少花在分析原始数据上的时间,因此结论可在离开放射科前向患者提供检查。在今天的临床实践中,最新的系统提供预先填充的放射学报告与一个集成的自动语音识别技术,使医生可以决定各种生理和技术参数。因此,一个自动的CMRI分析软件可以很容易地集成在这个框架中。话虽如此,在这些软件获得认证机构(CE标志、FDA、ISO等)的批准之前,仍需要进行进一步的调查。并集成到核磁共振控制台中。此外,尽管类识别软件得到了近乎完美的结果,“诊断黑盒”的使用不能像在临床实践中那样集成。除了病理预测,医疗报告必须总是包含了病人以某种方式被诊断出的生理原因。这需要心脏参数,如EF,体积和质量估计的分割方法,在深度学习方法的背景,有时可能在顶端和底部失败,甚至产生解剖学上不可能的结果。还应对广泛采集的图像进行进一步分析各种具有不同采集协议的MRI扫描仪,以更好地评估机器学习算法的真实泛化精度。
还需要对其他病理患者的数据进行进一步的研究。虽然我们相信其他一些病理,如炎症性心肌病可以被成功诊断随着提出的机器学习方法,其他(更复杂的)疾病,如先天性心脏病或心脏缺陷,将需要专门的研究。
7.结论
心电图门控序列,如Cine-MRI允许准确分析左和右心室功能。心室心内膜和心外膜的轮廓允许不同的计算参数,如LV EF、RV EF、心肌质量、心肌厚度、远收缩期和远舒张期心室容积。这些测量是放射科医生检查解释的一个组成部分,是诊断许多心肌病的必要条件。在本文中,我们展示了一种最先进的机器学习方法可以成功地对患者数据进行分类,并得到高精度的分割结果。结果还显示,最好的卷积神经网络在临床指标上获得准确的相关评分,在两种最常见的LV EDV和LV EF上获得低偏差和标准偏差常用的生理措施。然而,特别是考虑到Hausdorff距离时,方法在底部和顶端仍然失败。
本文为学习原文时所做翻译笔记,如有侵权请联系删除。