蛮力法概述
蛮力法也称穷举法(枚举法)或暴力法,是一种简单的直接解决问题的方法,通常根据问题的描述和所涉及的概念定义,对问题所有可能的状态(结果)一一进行测试,直到找到解或将全部可能的状态都测试一遍为止。
蛮力法的“力”指的是计算机的运算能力,蛮力法是基于计算机运算速度快的特性,减少人的思考而把工作都交给计算机的“懒惰”策略(这里的懒惰指的是人懒,不是算法中的懒惰方法),一般而言是最容易实现的方法。
蛮力法的优点如下:
1.逻辑简单清晰,根据逻辑编写的程序简单清晰。
2.对于一些需要高正确性的重要问题,它产生的算法一般而言是复杂度高但合理的。
3.解决问题的领域广。
4.适用于一些规模较小,时间复杂度要求不高的问题。
5.可以作为其他高校算法的衡量标准,即作为被比较的例子。
主要缺点就是因为缺少人的思考,算法往往设计的简单而缺乏高的效率。
蛮力法依赖的是将每个元素(状态)处理一次的扫描技术,通常在以下几种情况使用蛮力法:
搜索所有的解空间:问题的解存在于规模不大的解空间中。
搜索所有的路径:这类问题中不同的路径对应不同的解。
直接计算:按照基于问题的描述和所涉及的概念定义,直接进行计算。往往是一些简单的题,不需要算法技巧的。
模拟和仿真:按照求解问题的要求直接模拟或仿真问题的过程即可。
作为算法的设计者,不要被这些人为设计的概念框住自己的手脚,通过自己的认识合理的利用资源高效地处理问题才是我们需要做到的。
蛮力法的直接应用
介绍一些直接采用蛮力法解决问题的例子。
直接采用蛮力法的一般格式
在直接采用蛮力法设计算法中,主要是使用循环语句和选择语句:循环语句用于穷举所有可能的情况,而选择语句判定当前的条件是否为所求的解。
模型比较简单就不看了(不要拘泥于模型,去体会思想)。
例题 4.1
编写一个程序,输出2到1000之间的所有完全数。完全数就是指该数的各因子(除该数本身外)之和正好等于该数本身。
直接采用蛮力法的方式就是将2到1000的所有数穷举一遍,对每个可能是完全数的数,求解他们除本身之外的各因子之和与原数进行比较。
for (m=2;m<=1000;m++){
//求出m的所有因子之和s;
if (m==s) 输出s;
}
求解所有因子的过程依旧是一个穷举的过程,除本身之外的因子大小不会超过本身的一半,穷举1到本身的一半判断能够整除即可,结合起来对应的蛮力法如下:
void main(){
int m,i,s;
//穷举2-1000的所有整数
for (m=2;m<=1000;m++){
s=0;//s为因子的和
//穷举1到m/2的所有可能为因子的整数
for (i=1;i<=m/2;i++) if (m%i==0) s+=i;//i是m的一个因子
if (m==s) printf("%d ",m);
}
}
例 4.2
编写一个程序,求这样的四位数:这个四位数的十位是1,个位是2,这个四位数减去7就能被7整除,减去8就能被8整除,减去9就能被9整除。
设这个数的十进制表示为ab12,则数值n=1000*\a+100*b+12,采用穷举法穷举a和b:
int n,a,b;
//穷举a和b,即穷举最后两位为12的四位数
for (a=1;a<=9;a++) for (b=0;b<=9;b++){
n=1000*a+100*b+12;
//判断n是否满足题中的给定条件
//输出n
}
减去7被7整除,减去8被8整除,减去9被9整除就是简单的基本运算的组合,完整的蛮力法如下:
int n,a,b;
//穷举a和b,即穷举最后两位为12的四位数
for (a=1;a<=9;a++) for (b=0;b<=9;b++){
n=1000*a+100*b+12;
//判断n是否满足题中的给定条件
if ((n-7)%7==0&&(n-8)%8==0&&(n-9)%9==0) printf("n=%d\n",n);
}
例 4.3
在象棋算式里,不同的棋子代表不同的数,有以下算式,设计一个算法求这些棋子各代表哪些数字。

直接采用穷举法的思想就是,对于五个棋子的取值分别进行枚举,然后判断对于一套取值是否能在不重复的前提下,满足竖式的要求。
对应的蛮力法如下:
void fun(){
int a,b,c,d,e,m,n,s;
//分别穷举兵,炮,马,卒,车的各种可能
for (a=1;a<=9;a++) for (b=0;b<=9;b++) for (c=0;c<=9;c++) for (d=0;d<=9;d++) for (e=0;e<=9;e++)
//避免取值的重复
if (a==b||a==c||a==d||a==e||b==c||b==d||b==e||c==d||c==e||d==e) continue;
//判断是否满足竖式的条件
else{
m=a*1000+b*100+c*10+d;
n=a*1000+b*100+e*10+d;
s=e*10000+d*1000+c*100+a*10+d;
if (m+n==s)
printf("兵:%d 炮:%d 马:%d卒:%d 车:%d\n",a,b,c,d,e);
}
}
例 4.4
有n个整数,存放在数组a中,设计一个算法从中选出3个正整数组成周长最长的三角形,并输出该三角形的周长,若无法组成三角形就输出0。
穷举出n个整数中选择三条边的所有可能,然后对于每一种可能判断能否组成三角形,在能够组成三角形的前提下,更新最大的周长值。
对应的蛮力法如下:
void solve(int a[],int n){
int i,j,k,len,ma,maxlen=0;
for (i=0;i<n;i++) for (j=i+1;j<n;j++) for (k=j+1;k<n;k++){
len=a[i]+a[j]+a[k];
ma=max3(a[i],a[j],a[k]);
//判断能够穷举出来的一种可能的三条边能否组成一个三角形
if (ma<len-ma){
//更新最大周长
if (len>maxlen) maxlen=len;
}
}
printf("最长三角形的周长=%d\n",maxlen);
}
简单选择排序和冒泡排序
递归那里介绍过了,这里不再做赘述(蛮力法本身是最简单的方法,以蛮力法的模型再去解析简单选择
排序和冒泡排序不会有更好的收获)。
字符串匹配
对于字符串s和t,若t是s子串,返回t在s中的位置(t的首字符在s中对应的下标),否则返回-1。
蛮力法的策略就是找到字符串s中所有长度为t的字符串的长度的连续子串,然后将连续子串与t进行比较,判断t是否为s的子串,这个字符串匹配的算法称为BF算法(Brute-Force算法)也就是暴力算法的意思。
程序的while循环是一位一位匹配的,实际上存在回退的过程,就是将一个一个的连续子串与t进行比较的过程。
//Brute-Force算法,字符串匹配
int BF(string s,string t){
int i=0,j=0;
while (i<s.length()&&j<t.length()){
//匹配当前的连续子串
if (s[i]==t[j]){i++; j++;}
//当前的连续子串匹配失败,对s串进行回退,实际上就是匹配下一个字母开头的连续子串
else{i=i-j+1; j=0;}
}
//t的字符比较完毕
if (j==t.length()) return i-j;//t是s的子串,返回位置
//t不是s的子串,返回-1
else return -1;
}
例 4.5
有两个字符串s和t,设计一个算法求t在s中出现的次数。
用蛮力法处理这个问题的策略和BF算法是一致的,将字符串s中所有与字符串t长度相等的连续子串拿出来进行比较,区别就在于BF算法中完成匹配后直接退出循环,而这里的问题需要计算出t在s中出现的次数,所以t字符串匹配到最后一位后还是要回退直到s字符串匹配完全。
对应的蛮力法算法如下:
//用蛮力法求t在s中出现的次数
int Count(string s,string t){
int num=0;//计数器累计出现次数
int i=0,j=0;
while (i<s.length()&&j<t.length()){
//匹配当前的连续子串
if (s[i]==t[j]){i++; j++;}
//当前的连续子串匹配失败,对s串进行回退,实际上就是匹配下一个字母开头的连续子串
else{i=i-j+1; j=0;}
//匹配成功时,仍然进行回退,计时器+1
if(j==t.length()){
num++; j=0;
}
}
return num;
}
求解最大连续子序列和问题
就是分治法中求解连续最大子序列和的问题。
用蛮力法就是枚举出所有连续的子序列的和,然后找到里面最大的那个子序列,书上的前两种蛮力法都是基于的这种思路,解法二计算从第i个元素开始的连续子序列的和时,计算长度长的连续子序列的和继承前面长度较短的连续子序列的计算结果,相当于减少了重复计算的内容,解法二从某种角度而言其实已经很倾向于动态规划算法了。
蛮力法的两个解法如下:
//蛮力法求解最大连续子序列和问题的解法一
int maxSubSum1(int a[],int n){
int i,j,k;
int maxSum=a[0],thisSum;
//穷举所有的连续子序列
for (i=0;i<n;i++) for (j=i;j<n;j++){
//计算连续的子序列的和
thisSum=0;
for (k=i;k<=j;k++) thisSum+=a[k];
//通过比较求最大连续子序列之和
if (thisSum>maxSum) maxSum=thisSum;
}
return maxSum;
}
//蛮力法求解最大连续子序列和问题的解法二
int maxSubSum2(int a[],int n){
int i,j;
int maxSum=a[0],thisSum;
//穷举所有的连续子序列
//thisSum记录以i为首的连续子序列的和,有点滚动数组的意思
for (i=0;i<n;i++){thisSum=0;
for (j=i;j<n;j++){thisSum+=a[j];
//通过比较求最大连续子序列之和
if (thisSum>maxSum) maxSum=thisSum;
}
}
return maxSum;
}
前一种的复杂度为O(n3),后一种的复杂度为O(n2)。
解法3基于的一个事实就是最大的连续子序列一定不可能由一段和为负的连续子序列后面拼上别的连续子序列,因为舍弃了前面何为负的连续子序列,连续子序列的和变得更大就产生了矛盾。
于是在我们计算从第i个元素开始的连续子序列的和时,我们只需要计算到连续子序列的和小于0之前即可。
我们假设上面过程枚举第i个元素开始的连续子序列的最后一个元素,枚举到第j个元素为止,也就是说对于k(i≤k≤j),都有第i个元素到第k个元素的连续子序列的和非负,当我们考察第k个元素开始的连续子序列时,由于第i个元素到第k-1个元素的连续子序列的和非负,那么第k个元素到第j个元素的连续子序列的和一定小于等于第i个元素到第j个元素的连续子序列和。
也就是说我们枚举第k个元素开始的连续子序列的最后一个元素,做多枚举的不会超过第j个元素,且由于第i个元素到第k-1个元素的连续子序列的和非负,我们枚举的第k个元素开始的连续子序列的值不会超过枚举的第i个元素开始的连续子序列的值。
所以我们枚举完第i个元素开始的连续子序列的最后一个元素,枚举到第j个元素为止后,下一个枚举的元素从第j+1个元素开始,也就是说只需要从前往后的遍历一遍。
对应的算法如下:
//蛮力法求解最大连续子序列和问题的解法三
int maxSubSum3(int a[],int n){
int i,maxSum=0,thisSum=0;
for (i=0;i<n;i++){thisSum+=a[i];
//若当前以第i个元素开头枚举的子序列和为负数,重新开始枚举下一元素开头的连续子序列
if (thisSum<0) thisSum=0;
//比较求最大连续子序列和
if (maxSum<thisSum) maxSum=thisSum;
}
return maxSum;
}
解法三相比解法二倾向于与贪心思想的结合,解法二和解法三严格意义上说都不能称为传统意义上的蛮力法了。
三个解法的合集如下:
//蛮力法求解最大连续子序列和问题的解法一
int maxSubSum1(int a[],int n){
int i,j,k;
int maxSum=a[0],thisSum;
//穷举所有的连续子序列
for (i=0;i<n;i++) for (j=i;j<n;j++){
//计算连续的子序列的和
thisSum=0;
for (k=i;k<=j;k++) thisSum+=a[k];
//通过比较求最大连续子序列之和
if (thisSum>maxSum) maxSum=thisSum;
}
return maxSum;
}
//蛮力法求解最大连续子序列和问题的解法二
int maxSubSum2(int a[],int n){
int i,j;
int maxSum=a[0],thisSum;
//穷举所有的连续子序列
//thisSum记录以i为首的连续子序列的和,有点滚动数组的意思
for (i=0;i<n;i++){thisSum=0;
for (j=i;j<n;j++){thisSum+=a[j];
//通过比较求最大连续子序列之和
if (thisSum>maxSum) maxSum=thisSum;
}
}
return maxSum;
}
//蛮力法求解最大连续子序列和问题的解法三
int maxSubSum3(int a[],int n){
int i,maxSum=0,thisSum=0;
for (i=0;i<n;i++){thisSum+=a[i];
//若当前以第i个元素开头枚举的子序列和为负数,重新开始枚举下一元素开头的连续子序列
if (thisSum<0) thisSum=0;
//比较求最大连续子序列和
if (maxSum<thisSum) maxSum=thisSum;
}
return maxSum;
}
求解幂集问题
对于给定的正整数n,求1到n构成的集合的所有子集(幂集)。例如n=3时,1到n构成的集合的所有子集为:{},{1},{2},{3},{1,2},{1,3},{2,3},{1,2,3}。
这个问题用穷举法解决的策略就是对每个元素考虑选取与不选取的两个情况,即从全不选择,到全都选择穷举所有的可能。
第i个数选择为1不选择为0,于是对于任意一个子集我们可以得到一个长度为n的二进制编码,这些二进制编码对应的十进制数为0到2n-1,例如n=3时对应的二进制编码和十进制数如下:
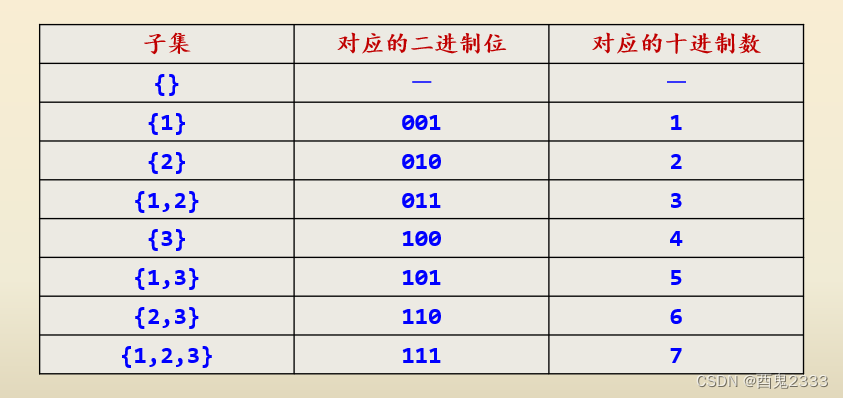
这种穷举法的思路就是将0到2n-1的十进制数全部转化为二进制数,然后根据二进制数得到对应的子集,时间复杂度为2n*n(这种方法称为二进制法,比较简单,书上的写法很糟糕这里就不多赘述了)。
另一种实现方法,设置n层循环,前i层循环得到前i个元素能够构成的2i个幂集,然后根据第i+1个元素选择和不选择得到前i+1个元素能够构成的2i+1个幂集。
vector<vector<int> >ps;//存放幂集
//求1~n的幂集ps
void PSet(int n){
vector<vector<int> >ps1//子幂集
vector<vector<int> >::iterator it;//幂集迭代器
vector<int> s;
ps.push_back(s);//添加{}空集合元素
//i层循环考虑是否添加元素i进入现有的子集,从1~i-1的幂集得到1~i的幂集
for (int i=1;i<=n;i++){
ps1=ps;//ps存放上一层循环得到从1~i-1的幂集,ps1复制1~i-1的幂集
//然后通过1~i-1的幂集后面扩展一个元素i,得到1~i的幂集比起1~i-1的幂集多出来的部分
for (it=ps1.begin();it!=ps1.end();++it) (*it).push_back(i);
for (it=ps1.begin();it!=ps1.end();++it) ps.push_back(*it);
}
}
这个复杂度相对前一种实现方法低,为O(2n),也是用了类似动态规划的思想。
求解0/1背包问题
n个重量分别为w1,w2,…,wn的物品,它们的价值分别为v1,v2,…,vn,给定一个容量为W的背包。
设计从这些物品中选取一部分物品放入该背包的方案,每个物品要么选中要么不选中,要求选中的物品不仅能够放到背包中,而且具有最大的价值。
使用蛮力法的策略就是枚举出所有可能的方案,然后根据选择物品的方案得到它们的重量和价值,然后再用蛮力法将每种方案排查一遍得到满足容量条件中,价值最大的方案。
穷举所有可能选取物品方案的方法和穷举幂集的策略是一样的,对应的蛮力法算法如下:
ector<vector<int> >ps;//存放幂集
//求1~n的幂集ps
void PSet(int n){
vector<vector<int> >ps1//子幂集
vector<vector<int> >::iterator it;//幂集迭代器
vector<int> s;
ps.push_back(s);//添加{}空集合元素
//i层循环考虑是否添加元素i进入现有的子集,从1~i-1的幂集得到1~i的幂集
for (int i=1;i<=n;i++){
ps1=ps;//ps存放上一层循环得到从1~i-1的幂集,ps1复制1~i-1的幂集
//然后通过1~i-1的幂集后面扩展一个元素i,得到1~i的幂集比起1~i-1的幂集多出来的部分
for (it=ps1.begin();it!=ps1.end();++it) (*it).push_back(i);
for (it=ps1.begin();it!=ps1.end();++it) ps.push_back(*it);
}
}
//用蛮力法求所有的方案和最佳方案
void Knap(int w[],int v[],int W){
//用求解幂集的方法穷举出所有的方案
PSet(n);
int count=0;//穷举过程中穷举的方案的编号
int sumw,sumv;//当前穷举的方案的总重量和总价值
int maxi,maxsumw=0,maxsumv=0;//最佳方案的编号,总重量和总价值
vector<vector<int> >::iterator it;//访问幂集中每个子集的迭代器
vector<int>::iterator sit;//访问幂集子集元素的迭代器
//幂集的每一个子集对应一套方案
for (it=ps.begin();it!=ps.end();++it){
sumw=sumv=0;
for (sit=(*it).begin();sit!=(*it).end();++sit){
sumw+=w[*sit-1];//计算该套方案的重量
sumv+=v[*sit-1];//计算该套方案的价值
}
//比较求满足条件的最优方案
if (sumw<=W&&sumv>maxsumv){
maxsumw=sumw;
maxsumv=sumv;
maxi=count;
}
count++;
}
}
求解全排列问题
对于给定的正整数n,求1~n的所有全排列。
例如n=3,1~n的全排列为:123,132,213,231,312,321。
用蛮力法求解全排列问题是个比较经典的问题,一种思路是穷举全排列中每一个排列每一位出现的数字,从第一位穷举到最后一位。
另一种思路就是书上的思路:穷举数字i可能出现的位置,从1穷举到n。和求解幂集问题一样,前i层穷举数字1到i出现的位置,相当于穷举出1到i的全排列,然后在第i+1层循环中穷举数字i+1可能出现的位置,从1到i的全排列扩展到1到i+1的全排列(从思想上近似于动态规划的思想)。
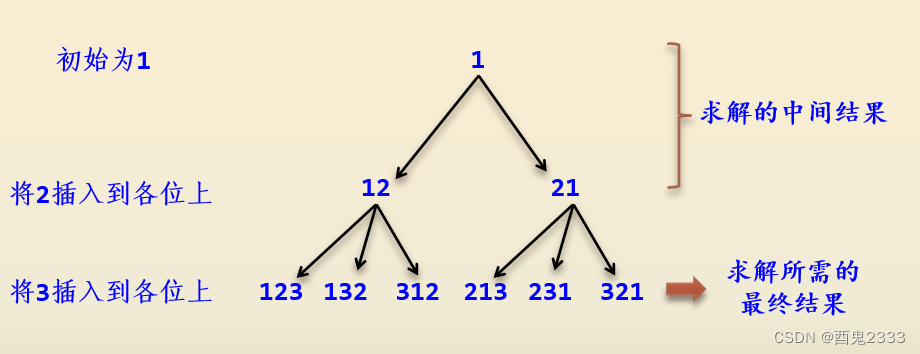
对应的蛮力法的算法如下:
vector<vector<int> >ps;//存放1到n的全排列
//在排列s中寻找能够插入i的位置,将得到的新的s1插入到ps1中
vvoid Insert(vector<int> s,int i,vector<vector<int> > &ps1){
vector<int> s1;
vector<int>::iterator it;
//穷举将i插入到排列s的位置
for (int j=0;j<i;j++){
s1=s;
it=s1.begin()+j;//插入的位置
s1.insert(it,i);//插入整数i
ps1.push_back(s1);//将得到的新的排列加入ps1中
}
}
//求1~n的所有全排列
void Perm(int n){
vector<vector<int> >ps1;//存放1到i-1的全排列
vector<vector<int> >::iterator it;//全排列迭代器
vector<int>s,s1;
s.push_back(1); ps.push_back(s);//在ps中添加{1}集合元素,得到1到1的全排列
//从2开始穷举每一个数字可能出现的位置
for (int i=2;i<=n;i++){
ps1.clear();
//ps存放1到i-1的全排列,在1到i-1的每个排列中寻找i能够插入的位置
//将得到的1到i的全排列中的排列插入到ps1中
for (it=ps.begin();it!=ps.end();++it) Insert(*it,i,ps1);
ps=ps1;
}
}
时间复杂度为O(n*n!)。
求解任务分配问题
有n个任务需要分配给n个人执行,每个任务只能分配给一个人,每个人只能执行一个任务。第i个人执行第j个任务的成本是c[i][j],求出总成本最小的分配方案。
蛮力法的策略就是穷举出所有任务分配的方案,然后计算出每个任务分配的方案的成本,然后比较求解出总成本最小的分配方案。
穷举出所有任务分配的方案,我们将第1个人到第n个人做的任务的编号连在一起得到一个n位的数字序列,所有任务分配的方案对应的n位数字序列的总集就是1~n的全排列,求解任务分配问题蛮力法解决实际上就是求解全排列问题(代码就不做赘述了)。
上面介绍了用蛮力法求解找到满足条件的数的简单数学问题,排序问题,字符串匹配问题,最大连续子序列和问题,幂集问题,0/1背包问题,全排列问题,任务分配问题。
其中蛮力法求解0/1背包问题和任务分配问题分别属于蛮力法求解幂集问题和全排列问题的衍生应用,分别成为子集问题和排列问题。蛮力法求解幂集问题和全排列问题的解法存在比较高的相似性,包括第二种优化的解法(提供给我们动态规划在什么地方使用和框架设计的思路)。
递归在蛮力法中的应用
蛮力法是一种处理问题的算法思想,递归是一种算法的实现方式,很多用蛮力法求解问题的过程都可以采用递归方式来实现,递归算法的分解规模较小的问题(阶段)的框架也给最基础的蛮力法带来一定优化方向上的启发。
用递归方法求解幂集问题,全排列问题
求解幂集问题和全排列问题的第二种解法,都是将问题从最小的规模(空集,1到1的全排列)一步一步扩展(从前i个元素的幂集扩展到前i+1个元素的幂集,从1到i的全排列扩展到1到i+1的全排列),扩展到规模最大的原问题的解(n个元素的幂集,1到n的全排列),本身就是符合递归算法设计的一般步骤的。
我们前面是用循环去实现的,就相当于用循环结构替代递归过程的结果。替换回递归过程的策略是给函数添加一个·属性,然后通过属性值的递减或递增进行一个状态是顺序结构的递归,效果和循环结构是一样的,这里不做赘述。
用递归方法求解组合问题
求从1~n的正整数中取k个不重复整数的所有组合。
因为只取k个不重复整数,而不是将n个整数全部不重复地取出,前面子问题为求1到i放置位置的可能(全排列)的设计在这里就不是很好用。
但我们前面还提到另外一种穷举法的思路:穷举每一个排列每一位出现的数字,从第一位穷举到最后一位。
于是我们可以设规模最大的原问题为1到n中选取k个不重复的数字,规模较小的子问题为1到n中选取i个不重复的数字。但是这么设计需要注意一个问题,就是当我们从规模较小的问题的解去求解规模较大的问题时,选取的i个数字不能在规模较大的问题中进行选取,就是说实际上取数的范围不是1到n,而是1到n中不包括前面选取过的i个数字,我们可以用标记的方法来解决这个问题。
但是不同于全排列1,2,3和1,3,2属于两种不同的排列,不重复数字的组合中的数字不存在次序关系,就是说1,4,7,8和4,8,7,1是一种组合,于是我们可以默认每一种组合中数字都是从小到大排列的。
有一种不使用标记的更好的设计方案:设规模最大的原问题为从1到n中从小到大的选取k个不重复的数字,选取的最大数为max_n。规模较小的子问题为1到n中从小到大的选取i个不重复的数字,选区的最大数为max_i,因为将组合中的元素从小到大的排序且添加了一个max_i的属性,从规模为i的子问题扩展到规模为i+1的子问题,第i+1个数字的选取可以在max_i到n中选取,不用再通过标记的方法来判断是否出现重复,第i+1次选取的数字为max_(i+1)。
前面提到“蛮力法是一种处理问题的算法思想,递归是一种算法的实现方式”,蛮力法算法指的是算法思想,递归算法指的是算法思想,两者并不冲突,我们递归那一章中很多递归算法采用的算法思想也是蛮力法。
我们在使用递归去实现蛮力法算法时,会发现很多子问题(阶段)是重复求解的,我们将子问题的解保存下来,重复求解时直接返回子问题的解能够提高效率(求解全排列问题和幂集问题用到过这个方法),这是我们之后章节要介绍的内容。
图的深度优先和广度优先遍历
图的存储结构
图的存储结构主要就是邻接矩阵存储方式和邻接表存储方式,这主要是数据结构篇章的内容,我们只做略过,不多做赘述。
邻接矩阵存储方法
邻接矩阵作为一个矩阵,第行第j列的值表示结点i到结点是否存在边(或者是带权图中边的权)。


结构体定义如下:
#define MAXV <最大顶点个数>
typedef struct{
int no;//顶点编号
char data[MAXL];//顶点其他信息
}VertexType;//顶点类型
typedef struct{
int edges[MAXV][MAXV];//邻接矩阵,edges[i][j]表示点i到点j是否存在边(边的权)
int n,e;//顶点数,边数
VertexType vexs[MAXV];//顶点信息
}MGraph;//完整的图邻接矩阵存储结构
邻接表存储方法
图的邻接表存储方法是一种链式存储结构。
我们对图的每个顶点建立一个单链表,第i个单链表中存储与顶点i邻接的顶点。n个单链表的表头结点再通过数组的方式存储起来构成一个表头结点数组。
typedef struct ANode{
int adjvex;//邻接顶点的顶点编号
int weight;//结点i到邻接顶点构成的边的权值
struct ANode *nextarc;//指向下一邻接顶点的指针
}ArcNode;
//顶点结构体,存储顶点信息和顶点对应单链表的表头结点
typedef struct Vnode{
char data[MAXL];//顶点信息
ArcNode *firstarc;//firstarc为顶点对应单链表的表头结点
}VNode;
typedef VNode AdjList[MAXV];//AdjList是邻接表类型,存储n个单链表的表头结点
typedef struct{
AdjList adjlist;//邻接表
int n,e;//图中顶点数n和边数e
}ALGraph;
图遍历算法
从给定(连通)图中任意指定的顶点(起始点)出发,按照某种顺序沿着图的边访问图中的所有顶点,使每个顶点仅被访问一次的过程称为图的遍历,对应算法为图遍历算法。
图遍历算法是图算法的设计基础,根据不同的遍历顺序,最经典的两种遍历方式有深度优先遍历和广度优先遍历,他们本质的算法思想都是蛮力法思路(作为搜索算法的算法思想是蛮力法思路,通过穷举每个结点的可能来找到我们需要搜索的目标)。
深度优先遍历
深度优先遍历的策略,简单来说就是在一条分支上将该分支的结点先遍历完,再回溯(这是一个概念上的回溯,不需要进行另外的操作)到前面的祖先结点遍历别的分支,直到所有的结点遍历完全(见上科大课件的lecture 10)。
算法的过程如下:
1.从图中某个初始顶点v出发,首先访问初始顶点v。
2.选择一个与当前正在访问的结点相邻且没被访问过的顶点为下一次访问的当前结点(属性),以该结点进行2的操作;当某个结点无法向下进行2的操作,回到上次访问的结点选择另外一个相邻且没有访问过的顶点进行2的操作(就是递归堆顶元素求解成功,退栈之后代入回新的栈顶元素进行处理的过程),直到图中与顶点v连通的所有顶点都被访问过为止。
显然,这个算法过程是个递归过程(算法正确性的证明过程略)。
以邻接矩阵为存储结构的深度优先遍历算法如下:
//邻接矩阵的DFS算法
void DFS(MGraph g,int v){
visited[v]=1;//标记当前正在访问的结点v已经被访问
//找当前正在访问v的所有相邻点(矩阵值部不为0,不为INF)
for (int w=0;w<g.n;w++)
//且相邻点不能在前面遍历的过程中被访问过
if (g.edges[v][w]!=0&&g.edges[v][w]!=INF&&visited[w]==0) DFS(g,w);
}
时间复杂度为O(n2)。
以邻接表为存储结构的深度优先遍历算法如下(其实单链表也可以用for循环进行遍历):
//邻接表的DFS算法
void DFS(ALGraph *G,int v){
ArcNode *p;
visited[v]=1;
p=G->adjlist[v].firstarc;//p指向顶点v的第一个邻接点
while (p!=NULL){
//若顶点未访问,以该顶点作为下一个访问顶点
if (visited[p->adjvex]==0) DFS(G,p->adjvex);
p=p->nextarc;
}
}
时间复杂度为O(n+e)。
这里visited数组进行标记来避免图的遍历过程中结点被重复遍历。而树作为图的一个特殊大类,树遍历算法不需要进行标记,所以我们往往会先介绍树的遍历算法再从树的概念来解释图遍历算法中为什么需要对结点进行标记的原因。
事实上,通过我们这里图遍历算法的递归过程对应的递归树,也可以从这个递归树的角度来解释为什么树遍历算法不需要进行标记。
例 4.6
假设图G采用邻接表存储,设计一个算法判断图G中从顶点u到v是否存在简单路径。
判断点u到点v是否存在简单路径,就是判断点u与点v是否连通。前面提到图遍历算法可以通过一个顶点访问连通图所有的顶点,就是访问所有与该顶点连通的顶点。
对于这个问题,我们采用图遍历算法,如果存在简单路径,也就是连通,那么通过图遍历算法就能够访问到,否则不能。
对应的算法如下:
//判断G中从顶点u到v是否存在简单路径
bool ExistPath(ALGraph *G,int u,int v){
int w; ArcNode *p;
visited[u]=1;
if (u==v) return true;//当前访问的结点为v,说明u和v连通,返回true
p=G->adjlist[u].firstarc;
while (p!=NULL){
//递归访问未访问过的相邻结点
w=p->adjvex;
if (visited[w]==0){
bool flag=ExistPath(G,w,v);
if (flag) return true;//当前分支连通,就不用回溯到该节点访问下一个相邻节点
}
p=p->nextarc;
}
return false;//没有找到v,返回false
}
例题4.7不仅需要判断路径,还需要输出路径,这个问题我们在前面递归法的章节中讨论过二叉树的版本,前面提到图遍历算法和树遍历算法只有标记的区别,所以不再做赘述(书上的方法是递归章节介绍的第二种方法)。
广度优先遍历
广度优先遍历,就是以到起始结点的边的数量作为优先级,每一层访问同一个优先级的节点,然后通过该层某优先级的结点访问到下一优先级的结点,直到所有的结点全部被访问过为止。
由于结点是按照优先级访问,优先级低的先访问,优先级的后访问,且我们通过优先级扩展到的相邻的结点一定是紧接着的下一优先级的结点(这一点保证添加进容器后,出容器的次序是按照优先级的次序出的),于是我们可以用队列作为宽度优先遍历访问结点的容器。
以邻接矩阵为存储结构的广度优先遍历算法如下:
//邻接矩阵的BFS算法
void BFS(MGraph g,int v){
queue<int>qu;//队列存储需要访问的结点
int w,i;
visited[v]=1;//标记初始结点v已经被访问
qu.push(v);//v进队
while (!qu.empty()){
//出队首结点进行访问并进行标记
w=qu.top(); qu.pop(); visited[w]=1;
//寻找相邻且访问的结点进行扩展(进队),扩展到下一优先级
for (i=0;i<g.n;i++)
if (g.edges[w][i]!=0&&g.edges[w][i]!=INF&&visited[i]==0) qu.push(i);
}
}
复杂度为O(n2),邻接表的广度优先遍历和邻接表的深度优先遍历一样,就是在寻找相邻结点时是遍历一个单链表,复杂度为O(n+e)。
对于邻接矩阵,每遍历一个结点就需要将n个结点检查一遍寻找相邻且为访问过的结点,所以复杂度为O(n2);而对于邻接表,每遍历一个结点也需要将与它相邻的结点检查一遍,但是相邻的结点是通过单链表存储起来的,所以复杂度为所有节点相邻结点的个数之和即为O(e)(加上n是因为还要遍历节点)。
例 4.8
假设图G采用邻接表存储,设计一个算法,求不带权无向连通图G中从顶点u到顶点v的一条最短路径。
例4.8属于广度优先遍历的一个典型应用——无权图中求两个顶点之间的最短路径,因为广度优先遍历是按照距离起始结点的边数为优先级遍历的,当遍历到结点v时一定起始节点u到结点v经过边数最少的一条路径,即最短路径。
对应的算法如下(这里求路径的方式不同于前面的两种方式,而是采用记录扩展过程中前继节点的方式,然后通过前继节点找到最短路径):
//求图G中从顶点u到顶点v的最短路径path
void ShortPath(ALGraph *G,int u,int v,vector<int> &path){
ArcNode *p; int w;
queue<int>qu;//存放需要访问的结点
int pre[MAXV];//pre[i]表示编号为i的结点在广度优先遍历过程中,通过哪个结点扩展到编号为i的结点(前继结点编号)
int visited[MAXV];//标记结点是否被访问过
memset(visited,0,sizeof(visited));//初始化标记用的数组
qu.push(u); visited[u]=1;//标记初始结点v已经被访问
pre[u]=-1;//初始结点作为递归树的根,前继结点的编号为-1
while (!qu.empty()){
//出队首结点进行访问并进行标记
w=qu.front(); qu.pop(); visited[w]=1;
//当前访问的结点为目标节点v,通过前继结点找到路径path
if (w==v){
int d=v;
while (d!=-1){
path.push_back(d); d=pre[d];
}
return;
}
//遍历结点对应的单链表,寻找未访问过的相邻结点加入队列
//并且记录前继结点的编号
p=G->adjlist[w].firstarc;
while (p!=NULL){
if (visited[p->adjvex]==0){
qu.push(p->adjvex); pre[p->adjvex]=w;
}
p=p->nextarc;
}
}
}
保存的路径是逆序的,输出路径时需要反向输出。
求解迷宫问题
给定一个n*n的迷宫图,例如下面8*8的迷宫图:
OXXXXXXX
OOOOOXXX
XOXXOOOX
XOXXOXXO
XOXXXXXX
XOXXOOOX
XOOOOXOO
XXXXXXXO
其中O表示可以走的方块,X表示障碍方块,我们假设入口为最左上角方块,出口为最右下角方块,设计一个程序求入口到出口的路径。
我们将每个可走的方块看作一个节点,如果两个方块上下左右相邻则认为他们之间存在边,于是这个迷宫就转化成了图结构,问题就转化为了在图结构中求解左上角方格对应结点到右下角方格对应结点的路径。
求解路径的方法就是广度优先遍历和宽度优先遍历,因为是数据结构中介绍过的问题这里不再做赘述。
值得一提的是,迷宫问题标记策略是将访问过的O方格修改成星号方格,然后在回溯时修改回O方格。
那为什么这里的标记需要在回溯时取消标记,而前面的BFS算法,DFS算法都不需要取消标记呢?
BFS和DFS的目标都是将与起始结点相通的结点按照一定的顺序进行访问,不会出现一条分支无法访问,而另一条分支可以访问却被前一条无法访问的分支“挡路”的情况。
求解迷宫问题用的也是BFS和DFS算法,只是我们这样直接通过修改进行标记,就不需要将未标记过的结点存储起来进行标记,可以节省一定的空间开销。取消标记不是为了避免“挡路”情况的出现。