3.2 关系抽取的方法
由于传统机器学习的关系抽取方法选择的特征向量依赖于人工完成,也需要大量领域专业知识,而深度学习的关系抽取方法通过训练大量数据自动获得模型,不需要人工提取特征。2006年Hinton 等人(《Reducing the dimensionality of data with neural networks》)首次正式提出深度学习的概念。深度学习经过多年的发展,逐渐被研究者应用在实体关系抽取方面。目前,研究者大多对基于有监督和远程监督2种深度学习的关系抽取方法进行深入研究。此外,预训练模型Bert(bidirectional encoder representation from transformers)自2018年提出以来就备受关注,广泛应用于命名实体识别、关系抽取等多个领域。
3.2.1 有监督的关系抽取方法
有监督的深度学习关系抽取方法能解决经典方法中存在的人工特征选择、特征提取误差传播2大主要问题,将低层特征进行组合,形成更加抽象的高层特征,用来寻找数据的分布式特征表示。目前,有监督的关系抽取方法主要有流水线学习(pipeline)和联合学习(joint)两种。
3.2.1.1 流水线(pipeline)学习
流水线学习方法是指在实体识别已经完成的基础上直接进行实体之间关系的抽取。早期的流水式学习方法主要采用卷积神经网络(convolutional neural networks, CNNs)和循环神经网络(recurrent neural networks, RNNs)两大类结构。其中,CNNs多样性卷积核的特性有利于识别目标的结构特征,而RNNs能充分考虑长距离词之间的依赖性,其记忆功能有利于识别序列。随着深度学习的不断发展,研究者不断改进和完善CNN 和RNN 的方法,并产生了许多变体,如长短期记忆网络(long short term memory, LSTM)、双向长短期记忆网络(bidirectional long short term memory, Bi-LSTM)等,此外,随着图卷积神经网络(graph convolutional network, GCN)在自然语言处理领域的应用,GCN 也越来越多地用于挖掘和利用实体间的潜在信息,为解决关系重叠、实体重叠提供了新思路,从而进一步促进了关系抽取的发展。
2014年Zeng等人(《Relation classification via convolutional deep neural network》)首次使用CNN 提取词级和句子级的特征,通过隐藏层和softmax层进行关系分类,提高了关系抽取模型的准确性;Liu等人(《Convolution neural network for relation extraction》)在实体关系抽取方面使用简单的CNN 模型,该模型主要由输入层、卷积层、池化层和softmax层组成,输入词向量和距离向量等原始数据进行实体关系抽取;为了消除了文本大小的任意性所带来的不便,Collobert等人(《Natural language processing (almost) from scratch》)利用设置大小固定的滑动窗口和在输入层和卷积层之上增添max层2种办法,提出了一种基于CNN 的自然语言处理模型,方便处理多种任务;Nguyen等人(《Perspective from convolutional neural networks》)设计了多种窗口尺寸的卷积核的CNN 模型,能自动学习句子中的隐含特征,最大限度上减少了对外部工具包和资源的依赖;Santos等人(《Classifying relations by ranking with convolutional neural networks》)使用逐对排序这一新的损失函数,有效地区分了关系类别;Xu等人(《Semantic relation classification via convolutional neural networks with simple negative sampling》)融合卷积神经网络和最短依存路径的优势进行实体关系抽取,在公有数据集SemEval 2010Task8的评估结果中,F1值为85.4%,相比于不使用最短依存路径的方法提高了4.1%,验证了卷积神经网络和最短依存路径结合的有效性;Ye等人(《Jointly extracting relations with class ties via effective deep ranking》)基于关系类别之间的语义联系,利用3 种级别的损失函数AVE,ATT,ExtendedATT,在包含10717条标注样例的SemEval-2010 Task 8中进行模型评估,最佳情况下准确率、召回率、F1值分别达到了83.7%,84.7%,84.1%,有效地提高了关系抽取方法的性能;Fan等人(《structured minimally supervised learning for neural relation extraction》)提出了一种最小监督关系提取的方法,该方法结合了学习表示和结构化学习的优点,并准确地预测了句子级别关系。通过在学习过程中明确推断缺失的数据,该方法可以实现一维CNN 的大规模训练,同时缓解远程监管中固有的标签噪音问题。在中文研究方面,孙建东等人(《Chinese entity relation extraction algorithms based on COAE2016 datasets》)基于COAE2016数据集的988条训练数据和937条测试数据,提出有效结合SVM 和CNN 算法可以用于中文实体关系的抽取方法。传统文本实体关系抽取算法多数是基于特征向量对单一实体对语句进行处理,缺少考虑文本语法结构及针对多对实体关系的抽取算法;基于此,高丹等人(《Entity relation extraction based on CNN in large-scale text data》)提出一种基于CNN 和改进核函数的多实体关系抽取技术,并在25463份法律文书的实体关系抽取上,取得了较好的抽取效果和较高的计算效率。
除CNN 关系分类的方法外,Socher等人(《Semantic compositionality through recursive matrix-vector spaces》)首先采用RNN 的方法进行实体关系抽取。该方法利用循环神经网络对标注文本中的句子进行句法解析,经过不断迭代得到了句子的向量表示,有效地考虑了句子的句法结构;面对纯文本的实体关系抽取任务,Lin等人(《Neural relation extraction with selective attention over instance》)使用了一种多种语言的神经网络关系抽取框架,并在句子级别引入注意力机制(attention),极大地减少了噪音句子的影响,有效地提高了跨语言的一致性和互补性。由于神经网络经常受到有限标记实例的限制,而且这些关系抽取模型是使用先进的架构和特征来实现最前沿的性能;Chen 等人(《Self-training improves recurrent neural networks performance for temporal relation extraction》)提出一种自我训练框架,并在该框架内构建具有多个语义异构嵌入的递归神经网络。该框架利用标记的、未标记的社交媒体数据集THYME实现关系抽取,并且具有较好的可扩展性和可移植性。
为了解决RNN 在自然语言处理任务中出现的梯度消失和梯度爆炸带来的困扰,研究者使用性能更为强大的LSTM。LSTM 是一种特殊的循环神经网络,最早是Hochreiter,Schmidhuber提出。2015年Xu等人(《Classifying relations via long short term memory networks along shortest dependency path》)提出基于LSTM 的方法进行关系抽取,该方法以句法依存分析树的最短路径为基础,融合词向量、词性、WordNet以及句法等特征,使用最大池化层、softmax 层等用于关系分类;Zhang 等人(《Bidirectional long short term memory networks for relation classification》)使用了Bi-LSTM 模型结合当前词语之前和词语之后的信息进行关系抽取,在最佳实验结果中相比于文献[58]的方法提高了14.6%,证实了Bi-LSTM 在关系抽取上具有有效性。
图神经网络最早由Gori等人提出,应用于图结构数据的处理,经过不断发展,逐渐应用于自然语言处理领域。而图卷积神经网络能有效地表示实体间的关系,挖掘实体间的潜在特征,近年来受到了越来越多的关注。Schlichtkrull等人(《Modeling relational data with graph convolutional networks》)提出使用关系图卷积神经网络(R-GCNs)在2个标准知识库上分别完成了链接预测和实体分类,其中链接预测抽取出了缺失的关系,实体分类补全了实体缺失的属性;为有效利用负类数据,Zhang等人(《Graph convolution over pruned dependency trees improves relation extraction》)提出一种扩展的图卷积神经网络,可以有效地平行处理任意依赖结构,便于对实体关系进行抽取。通过在数据集TAC和SemVal-2010Task8上的评估,其最佳的实验结果的准确率、召回率、F1值为71.3%,65.4%,68.2%,该方法的性能优于序列标注和依赖神经网络。此外,作者还提出一种新的剪枝策略,对输入的树结构的信息,可以快速找到2个实体之间的最短路径;图神经网络是最有效的多跳(multi-hop)关系推理方法之一,Zhu等人(《Graph neural networks with generated parameters for relation extraction》)提出一种基于自然语言语句生成图神经网络(GP-GNNs)参数的方法,使神经网络能够对无结构化文本输入进行关系推理;针对多元关系的抽取,Song等人(《N-ary relation extraction using graph state LSTM》)提出了一种图状的LSTM 模型,该模型使用并行状态模拟每个单词,通过消息的反复传递来丰富单词的状态值。该模型保留了原始图形结构,而且可以通过并行化的方式加速计算。不仅提高了模型的计算效率,也实现了对多元关系的抽取;为有效利用依赖树的有效信息,减少无用信息的干扰,Guo等人(《Attention guided graph convolutional networks for relation extraction》)提出一种直接以全依赖树为输入的、基于注意力机制的图卷积网络模型。该模型是一种软剪枝(soft-pruning)的方法,能够有选择地自动学习对关系提取任务有用的相关子结构,支持跨句多元关系提取和大规模句级关系提取。
为了进一步提高关系抽取模型的性能,一些研究者开始采取融合多种方法的方式进行关系抽取。2016年Miwa等人(《End-to-end relation extraction using LSTMs on sequences and tree structures》)使用联合的方法,他们融合Bi-LSTM 和Tree LSTM 模型的优点对实体和句子同时构建模型,分别在3 个公有数据集ACE04,ACE05,SemVal-2010Task8对关系抽取模型进行评估,有效地提高了实体关系抽取的性能;Zhou等人[79]提出一种基于注意力的Bi-LSTM,着重考虑词对关系分类的影响程度,该方法在只有单词向量的情况下,优于大多数当时的方法;Li等人[80]融合Bi-LSTM 和CNN 的特点,利用softmax函数来模拟目标实体之间的最短依赖路径(SDP),并用于临床关系提取的句子序列,在数据集2010i2b2∕VA 的实验结果F1为74.34%,相比于不使用语义特征的方法提高2.5%;陈宇等人[81]提出一种基于DBN(deepbeliefnets)的关系抽取方法,通过将DNB与SVM 和传统神经网络2种方法在ACE04数据集(包含221篇消息文本、10228个实体和5240个关系实例)进行了比较,F1 值分别提高了1.26% 和2.17%,达到了73.28%;召回率分别提高了3.59%和2.92%,达到了70.86%,验证了DBN 方法的有效性。此外,DBN 方法表明,字特征比词特征更适用于中文关系抽取任务,非常适用于基于高维空间特征的信息抽取任务。流水线方法的实验结果相对良好,但容易产生错误传播,影响关系分类的有效性;将命名实体识别和关系抽取分开处理,容易忽视这2个子任务之间的联系,丢失的信息会影响抽取效果;另外,冗余信息也会对模型的性能产生较大的影响。为解决这些问题,研究人员尝试将命名实体识别和关系抽取融合成一个任务,进行联合学习。
3.2.1.2 联合学习
联合学习方法有3种,包括基于参数共享的实体关系抽取方法、基于序列标注的实体关系抽取方法和基于图结构的实体关系抽取方法。
命名实体识别和关系抽取通过共享编码层在训练过程中产生的共享参数相互依赖,最终训练得到最佳的全局参数。因此,基于共享参数方法有效地改善了流水线方法中存在的错误累积传播问题和忽视2个子任务间关系依赖的问题,提高模型的鲁棒性。2016年Miwa等人(《End-to-end relation extraction using LSTMs on sequences and tree structures》)首次利用循环神经网络、词序列以及依存树将命名实体识别和关系抽取作为一个任务进行实验,通过共享编码层的LSTM 的获得最优的全局参数,在数据集ACE04,ACE05分别减少了5.7%和12.1%的错误率,在数据集SemEval-2010Task8的F1达到了84.4%。然而Miwa忽略了实体标签之间的长距离依赖关系,为此Zheng等人(《Joint entity and relation extraction based on a hybrid neural network》)将输入句子通过公用的Embedding层和Bi-LSTM 层,分别使用一个LSTM 进行命名实体识别和一个CNN 进行关系抽取,该方法的F1达到了85.3%,相对Miwa提高了近1%。
由于基于共性参数的方法容易产生信息冗余,因此Zheng等人(《Joint extraction of entities and relations based on a novel tagging scheme》)将命名实体识别和实体关系抽取融合成一个序列标注问题,可以同时识别出实体和关系。该方法利用一个端到端的神经网络模型抽取出实体之间的关系三元组,减少了无效实体对模型的影响,提高了关系抽取的召回率和准确率,分别为72.4%和43.7%.为了充分利用实体间有多种关系,Bekoulis等人(《Joint entity recognition and relation extraction as a multi-head selection problem》)将命名实体识别和关系抽取看作一个多头选择问题,可以表示实体间的多个关系;此外Bekoulis等人(《Adversarial training for multi-context joint entity and relation extraction》)还发现对模型加入轻微的扰动(对抗样本)可以使得WordEmbedding的质量更好,不仅提高了置信度还避免了模型过拟合,模型的性能大大提升。因此首次将对抗学习(adversarial training, AT)加入联合学习的过程中。实验结果表明,在4个公有数据集ACE04,CoNLL04,DREC,ADE的F1提高了0.4%~0.9%。
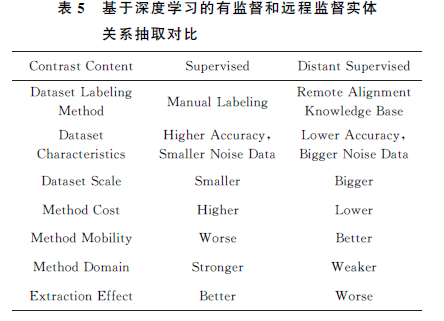
针对前2种方法无法解决的实体重叠、关系重叠问题,基于图结构的方法能有效得解决。Wang等人(《Joint extraction of entities and relations based on a novel graph scheme》)发现生成标记序列后的合并三元组标签过程采用的就近组合无法解决关系重叠问题,因此提出一种新的基于图架构的联合学习模型。该方法不仅能有效解决关系重叠问题,而且使用偏执权重的损失函数强化了相关实体间的关联,实验结果的准确率、召回率及F1值分别为64.3%,42.1%,50.9%。此外,Fu等人(《Modeling text as relational graphs for joint entity and relation extraction》)提出将图卷积神经网络用于联合学习,利用图的节点表示实体,边表示关系,有效地解决了关系重叠和实体重叠问题,不仅如此,还对边(关系)加入了权重,有效挖掘了实体对间的潜在特征,通过使用NYT 和WebNLG 数据集的评估,该方法在最佳情况下准确率、召回率及F1 值可达63.9%,60.0%,61.9%,与文献《Joint extraction of entities and relations based on a novel graph scheme》相比,召回率和F1分别提高17.9%和11.0%。本文选取了几种经典的有监督关系抽取方法进行了综合比较,具体如表4所示。深度学习的有监督方法能够自动地学习大量特征,避免人工选择特征,但对大量没有进行标记的数据,这种方法就显出其弊端。为了减少对大数据的标注的人工成本,研究者尝试使用远程监督的方法进行关系抽取。
3.2.2 远程监督的关系抽取方法
针对海量无标记数据的处理,远程监督的实体关系抽取方法极大地减少了对人工的依赖,可以自动地抽取大量的实体对,从而扩大了知识库的规模。此外,远程监督的方法具有较强的可移植性,比较容易应用到其他领域。远程监督的基本假设是如果2个实体在己知知识库中存在着某种关系,那么涉及这2个实体的所有句子都会以某种方式表达这种关系。Mintz等人(《Distant supervision for relation extraction without labeled data》)首次在ACL会议上将远程监督方法应用于实体关系抽取的任务中。他们将新闻文本与知识图谱FreeBase进行中的实体进行对齐,并利用远程监督标注的数据提取文本特征,训练关系分类模型。这类方法在数据标注过程会带来2个问题:噪音数据和抽取特征的误差传播。基于远程监督的基本假设,海量数据的实体对的关系会被错误标记,从而产生了噪音数据;由于利用自然语言处理工具抽取的特征也存在一定的误差,会引起特征的传播误差和错误积累。本文主要针对减少错误标签和错误传播问题对远程监督的关系抽取方法进行阐述。
1)针对错误标签
由于在不同语境下同一对实体关系可能存在不同含义,为了减少因此而产生的错误关系标签,Alfonseca等人[90]利用FreeBase知识库对关系进行分层处理,以启发式的方式自动识别抽取表示关系的语义和词汇;由于利用启发式的规则标记实体关系时会产生一些错误标记,Takamatsu等人(《Reducing wrong labels in distant supervision for relation extraction》)提出一种产生式模型,用于模拟远程监督的启发式标记过程,使用903000篇Wikipedia文章进行模型的训练,并使用400000篇文章进行测试,实验结果的准确率、召回率和F1 值分别为89.0%,83.2%,82.4%;为了解决Alfonseca提出的方法缺乏实体的知识背景问题,Ji等人(《Distant supervision for relation extraction with sentence-level attention and entity descriptions》)提出了一种在句子级别引入注意力机制的方法来抽取有效的实例,并通过FreeBase和Wikipedia不断地扩充实体的知识背景;之前大多方法对负类数据的利用率较低,Yu等人[93]提出结合从句子级远程监督和半监督集成学习的关系抽取方法,该方法减少了噪声数据,充分利用了负类数据。该方法首先使用远程监督对齐知识库和语料库,并生成关系实例集合,接着使用去噪算法消除关系实例集中的噪声并构建数据集。为了充分利用负类数据,该方法将所有正类数据和部分负类数据组成标注数据集,其余的负类数据组成未标注数据集。通过改进的半监督集成学习算法训练关系分类器的各项性能,然后进行关系实例的抽取。此外,为了减少错误标签产生的噪音数据对关系抽取模型的影响,Wang等人(《Label-free distant supervision for relation extraction via knowledge graph embedding》)提出了一种无标签的远程监督方法;该方法只是使用了知识库中的关系类型,而由2个实体来具体确定关系类型,避免了知识库中的先验知识标签对当前关系类型判别造成影响,也无需使用外部降噪工具包,大大提高了关系抽取的效率和性能;为了进一步提高对数据的使用效率,Ru等人(《Using semantic similarity to reduce wrong labels in distant supervision for relation extraction》)使用Jaccard算法计算知识库中的关系短语与句子中2个实体之间的语义相似性,借此过滤错误的标签。该方法在减少错误标签的过程中,利用具有单词嵌入语义的Jaccard算法选择核心的依赖短语来表示句子中的候选关系,可以提取关系分类的特征,避免以前神经网络模型关系提_取的不相关术语序列引起的负面影响。在关系分类过程中,将CNN 输入的核心依赖短语用于关系分类。实验结果表明,与使用原始远程监督数据的方法相比,使用过滤远程监督数据的方法在关系提取方面结果更佳,可以避免来自不相关术语的负面影响;为了突破距离对关系抽取模型性能的限制,Huang等人(《Distant supervision relationship extraction based on GRU and attention mechanism》)提出一种融合门控循环单元(gated recurrent unit, GRU)和注意力机制的远程监督关系抽取方法,该方法解决了传统深度模型的实体在长距离依赖性差和远程监督中容易产生错误标签的问题;实验结果表明,文献[89]的方法召回率在大于0.2时就开始迅速下降,而该方法在整个过程中都相对稳定,保证了模型的鲁棒性;此外,通过与文献(《Neural relation extraction with selective attention over instances》)的方法进行比较,该方法的召回率平均提高10%,能够充分利用整个句子的序列信息,更适合自然语言任务的处理。
2)针对误差传播
Fan等人(《Distant supervision for relation extraction with matrix completion》)提出远程监督关系提取的本质是一个具有稀疏和噪声特征的不完整多标签的分类问题。针对该问题,Fan使用特征标签矩阵的稀疏性来恢复潜在的低秩矩阵进行实体关系抽取;为了解决自然语言处理工具包提取问题带来的错误传播和错误积累问题,Zeng等人(《Adversarial learning for distant supervised relation extraction》)融合CNN 和远程监督的方法,提出分段卷积神经网络(piecewise convolutional neural network, PCNN)用于实体关系抽取,并尝试将基于CNN 的关系抽取模型扩展到远程监督数据上。该方法可以有效地减少了错误标签的传播和积累,在最佳情况下,准确率、召回率以及F1值达到了48.30%,29.52%,36.64%。针对目前在中文领域实体-属性提取中模型的低性能,He等人(《Chinese entity attributes extraction based on bidirectional LSTM networks》)提出了一种基于Bi-LSTM 的远程监督关系抽取方法。首先,该方法使用Infobox的关系三元组获取百度百科的信息框,从互联网获取训练语料库,然后基于Bi-LSTM 网络训练分类器。与经典方法相比,该方法在数据标注和特征提取方面是全自动的。该方法适用于高维空间的信息提取,与SVM 算法相比,准确率提高了12.1%,召回率提高了1.21%,F1值提高了5.9%,准确率和F1值得到显著提高。有监督的关系抽取方法借助人工标注的方法提高了关系抽取的准确性,但是需要耗费大量人力,其领域泛化能力和迁移性较差。远程监督的方法相对于有监督的方法极大地减少了人工成本,而且领域的迁移性较高。但是,远程监督的方法通过自动标注获得的数据集准确率较低,会影响整个关系抽取模型的性能。因此,目前的远程关系抽取模型的性能仍然和有监督的关系抽取模型有一定的差距,有较大的提升空间。基于深度学习的监督和远程监督方法抽取对比如表5所示:
3.2.3 BERT
2018年GoogleAILanguage发布了BERT模型,该模型在11个NLP任务上的表现刷新了记录,在自然语言处理学界以及工业界都引起了不小的热议。BERT的出现,彻底改变了预训练产生词向量和下游具体NLP任务的关系。在关系抽取领域,应用BERT 作预训练的关系抽取模型越来越多,如Shi等人提出了一种基于BERT的简单模型,可用于关系抽取和语义角色标签。在CoNLL05数据集中,准确率、召回率和F1值分别为88.6%,89.0%,88.8%,相比于baseline方法分别提高了1.0%,0.6%,0.7%;Shen等人借助BERT的强大性能对人际关系进行关系抽取,减少了噪音数据对关系模型的影响。此外,又使用了远程监督可以对大规模数据进行处理,在CCKS2019evalTask3IPRE数据集的结果表明,该方法优于大多数人际关系抽取方法,F1值达到了57.4%。
BERT作为一个预训练语言表示模型,通过上下文全向的方式理解整个语句的语义,并将训练学到的知识(表示)用于关系抽取等领域。但BERT 存在许多不足之处。
1) 不适合用于长文本。
BERT 以基于注意力机制的转换器作为基础,不便于处理长文本,而关系抽
取领域的文本中经常出现超过30个单词的长句,BERT会对关系抽取的性能产生影响。针对长句子的情况,可以另外设计一个深度的注意力机制,以便层级化的捕捉关系。
2)易受到噪音数据的影响。
BERT 适用于短文本,而短文本中若出现不规则表示、错别字等噪音数据,这不仅会对关系触发词的抽取造成一定的影响,而且在联合学习时进行命名实体识别阶段也会产生错误的积累和传播,最终导致模型的性能下降。
3)无法较好地处理一词多义问题。由于传统机器学习的关系抽取方法选择的特征向量依赖于人工完成,也需要大量领域专业知识,而深度学习的关系抽取方法通过训练大量数据自动获得模型,不需要人工提取特征。