我们通过采取动态调整学习率的策略,缓解过拟合问题。
随着训练轮数的增加,学习率逐渐下降会使模型拟合的更好
在这里,我们设定网络结构为:
model = tf.keras.Sequential([
# 0-255共256个,故第一个参数为256,数据为三位数,故第三个参数为3
Embedding(256, 3),
LSTM(3, return_sequences=True),
Dropout(0.2),
LSTM(5),
Dropout(0.2),
Dense(2, activation='softmax')
])
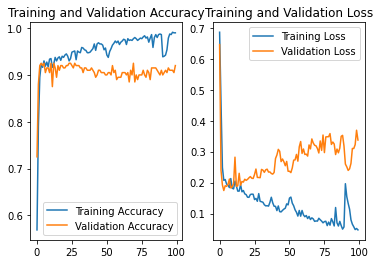
N0.1
batch_size=32
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
initial_learning_rate=0.001,
decay_steps=batch_size*1000,
decay_rate=1,
staircase=False)
InverseTimeDecay()函数:
initial_learning_rate:初始学习率
decay_steps:多少个steps进行一次衰减,其中一个epochs称为一轮,数据集一轮分为steps个batch进行,每个batchs中有batch_size条记录
decay_rate:衰减率
结果:准确率为0.895
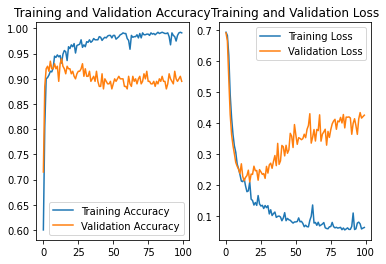
N0.2
设定batch*100
batch=32
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.001,
decay_steps=batch*100,
decay_rate=1,
staircase=False)
结果:准确率为0.88
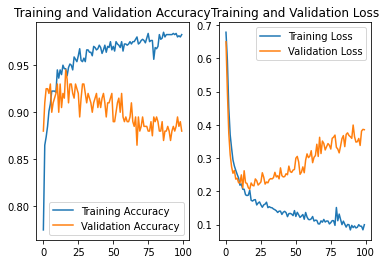
NO.3
调整初始学习率为0.005,batch*1000
batch=32
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.0005,
decay_steps=batch*1000,
decay_rate=1,
staircase=False)
结果:准确率为0.89
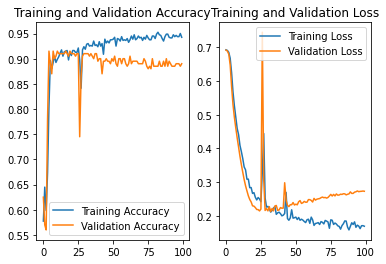
NO.4
设定decay_rate为2
batch=32
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.001,
decay_steps=batch*1000,
decay_rate=2,
staircase=False)
结果:准确率为0.89
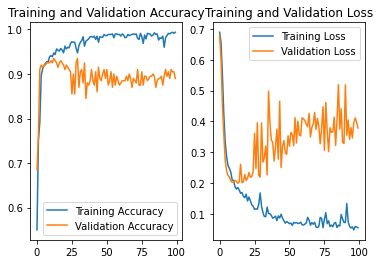
NO.5
设定random_state为2,尝试其他数据集时,准确率为多少
batch=32
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.001,
decay_steps=batch*1000,
decay_rate=1,
staircase=False)
结果:准确率为0.88
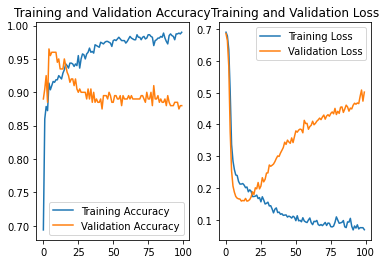
NO.6
继续设定random_state为2,decay_rate=2
batch=32
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.001,
decay_steps=batch*1000,
decay_rate=2,
staircase=False)
结果:准确率为0.915
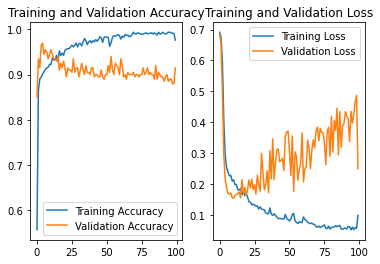
NO.7
改变网络结构
model = tf.keras.Sequential([
# 0-255共256个,故第一个参数为256,数据为三位数,故第三个参数为3
Embedding(256, 3),
LSTM(30, return_sequences=True),
Dropout(0.2),
LSTM(50),
Dropout(0.2),
Dense(2, activation='softmax')
])
学习率和NO.6相同
batch=32
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.001,
decay_steps=batch*1000,
decay_rate=2,
staircase=False)
结果:准确率为0.915
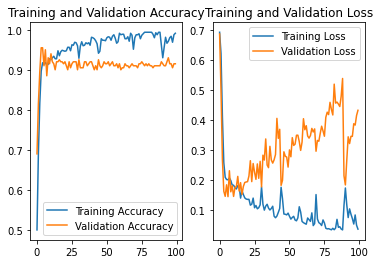
惊讶发现改变网络结构,提高可训练参数数量使得曲线更加平缓,正确率更高
NO.8
参数与NO.7相同,将random_state改为1进行测试
结果:正确率为0.92