原文链接:https://blog.csdn.net/qq_44635691/article/details/106919244
该模型实现的是英文到中文的翻译,下图为了更好展示模型架构借用大佬的图(这里没有用到Embeddings):
本文完整代码:Github
目录
一、处理文本数据
1.获得翻译前后的句子
2.创建关于 字符-index 和 index -字符的字典
3.对中文和英文句子One-Hot编码
二、建立模型
三、decoder预测每个字符
四、训练模型
五、展示

整体由encoder和decoder两大部分组成,每部分都有一个LSTM网络,其中encoder输入原始的句子,输出状态向量;decoder输入的是含有开始符号的翻译后的句子,输出目标句子。
具体步骤为:
1.encoder将输入序列进行编码成状态向量
2.decoder从第一个字符开始预测
3.向decoder喂入状态向量(state_h,state_c)和累计包含之前预测字符的独热编码(第一次的状态向量来自于encoder,后来预测每 目标序列的每个字符时,状态向量来源于decoder,predict出来的状态向量)
4.使用argmax预测对下一个字符的位置,再根据字典查找到对应的字符
5.将上一步骤中的字符添加到 target sequence中
6.直到预测到我们指定结束字符时结束循环
一、处理文本数据
这一步骤包含对原数据进行分割获得翻译前、后的句子,生成字符的字典,最后对翻译前后的句子进行One-Hot编码,便于处理数据。
1.获得翻译前后的句子
先看一下原数据的样式:

首先导入需要的库:
代码1.1.1
import pandas as pd
import numpy as np
from keras.layers import Input, LSTM, Dense, merge,concatenate
from keras.optimizers import Adam, SGD
from keras.models import Model,load_model
from keras.utils import plot_model
from keras.models import Sequential
#定义神经网络的参数
NUM_SAMPLES=3000 #训练样本的大小
batch_size = 64 #一次训练所选取的样本数
epochs = 100 #训练轮数
latent_dim = 256 #LSTM 的单元个数
用pandas读取文件,然后我们只要前两列内容
代码1.1.2
data_path='data/cmn.txt'
df=pd.read_table(data_path,header=None).iloc[:NUM_SAMPLES,0:2]
#添加标题栏
df.columns=['inputs','targets']
#每句中文举手加上‘\t’作为起始标志,句末加上‘\n’终止标志
df['targets']=df['targets'].apply(lambda x:'\t'+x+'\n')
最后是这样的形式:
最后是这样的形式:
代码1.1.3
#获取英文、中文各自的列表
input_texts=df.inputs.values.tolist()
target_texts=df.targets.values.tolist()
#确定中英文各自包含的字符。df.unique()直接取sum可将unique数组中的各个句子拼接成一个长句子
input_characters = sorted(list(set(df.inputs.unique().sum())))
target_characters = sorted(list(set(df.targets.unique().sum())))
#英文字符中不同字符的数量
num_encoder_tokens = len(input_characters)
#中文字符中不同字符的数量
num_decoder_tokens = len(target_characters)
#最大输入长度
INUPT_LENGTH = max([ len(txt) for txt in input_texts])
#最大输出长度
OUTPUT_LENGTH = max([ len(txt) for txt in target_texts])
2.创建关于 字符-index 和 index -字符的字典
代码1.2.1
input_token_index = dict( [(char, i)for i, char in enumerate(input_characters)] )
target_token_index = dict( [(char, i) for i, char in enumerate(target_characters)] )
reverse_input_char_index = dict([(i, char) for i, char in enumerate(input_characters)])
reverse_target_char_index = dict([(i, char) for i, char in enumerate(target_characters)])
3.对中文和英文句子One-Hot编码
代码1.3.1
#需要把每条语料转换成LSTM需要的三维数据输入[n_samples, timestamp, one-hot feature]到模型中
encoder_input_data =np.zeros((NUM_SAMPLES,INUPT_LENGTH,num_encoder_tokens))
decoder_input_data =np.zeros((NUM_SAMPLES,OUTPUT_LENGTH,num_decoder_tokens))
decoder_target_data = np.zeros((NUM_SAMPLES,OUTPUT_LENGTH,num_decoder_tokens))
for i,(input_text,target_text) in enumerate(zip(input_texts,target_texts)):
for t,char in enumerate(input_text):
encoder_input_data[i,t,input_token_index[char]]=1.0
for t, char in enumerate(target_text):
decoder_input_data[i,t,target_token_index[char]]=1.0
if t > 0:
# decoder_target_data 不包含开始字符,并且比decoder_input_data提前一步
decoder_target_data[i, t-1, target_token_index[char]] = 1.0
二、建立模型
代码2.1
#定义编码器的输入
encoder_inputs=Input(shape=(None,num_encoder_tokens))
#定义LSTM层,latent_dim为LSTM单元中每个门的神经元的个数,return_state设为True时才会返回最后时刻的状态h,c
encoder=LSTM(latent_dim,return_state=True)
# 调用编码器,得到编码器的输出(输入其实不需要),以及状态信息 state_h 和 state_c
encoder_outputs,state_h,state_c=encoder(encoder_inputs)
# 丢弃encoder_outputs, 我们只需要编码器的状态
encoder_state=[state_h,state_c]
#定义解码器的输入
decoder_inputs=Input(shape=(None,num_decoder_tokens))
decoder_lstm=LSTM(latent_dim,return_state=True,return_sequences=True)
# 将编码器输出的状态作为初始解码器的初始状态
decoder_outputs,_,_=decoder_lstm(decoder_inputs,initial_state=encoder_state)
#添加全连接层
decoder_dense=Dense(num_decoder_tokens,activation='softmax')
decoder_outputs=decoder_dense(decoder_outputs)
#定义整个模型
model=Model([encoder_inputs,decoder_inputs],decoder_outputs)
model的模型图:
model的模型图:

其中decoder在每个timestep有三个输入分别是来自encoder的两个状态向量state_h,state_c和经过One-Hot编码的中文序列
代码2.2
#定义encoder模型,得到输出encoder_states
encoder_model=Model(encoder_inputs,encoder_state)
decoder_state_input_h=Input(shape=(latent_dim,))
decoder_state_input_c=Input(shape=(latent_dim,))
decoder_state_inputs=[decoder_state_input_h,decoder_state_input_c]
# 得到解码器的输出以及中间状态
decoder_outputs,state_h,state_c=decoder_lstm(decoder_inputs,initial_state=decoder_state_inputs)
decoder_states=[state_h,state_c]
decoder_outputs=decoder_dense(decoder_outputs)
decoder_model=Model([decoder_inputs]+decoder_state_inputs,[decoder_outputs]+decoder_states)
plot_model(model=model,show_shapes=True)
plot_model(model=encoder_model,show_shapes=True)
plot_model(model=decoder_model,show_shapes=True)
return model,encoder_model,decoder_model
encoder的模型图:

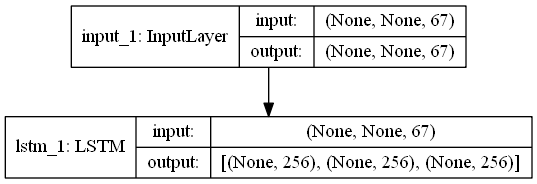
decoder的模型图:

三、decoder预测每个字符
首先encoder根据输入序列生成状态向量states_value 并结合由包含开始字符"\t"的编码一并传入到decoder的输入层,预测出下个字符的位置sampled_token_index ,将新预测到的字符添加到target_seq中再进行One-Hot编码,用预测上个字符生成的状态向量作为新的状态向量。
以上过程在while中不断循环,直到预测到结束字符"\n",结束循环,返回翻译后的句子。从下图可直观的看出对于decoder部分是一个一个生成翻译后的序列,注意蓝线的指向是target_squence,它是不断被填充的。

代码3.1
def decode_sequence(input_seq,encoder_model,decoder_model):
# 将输入序列进行编码生成状态向量
states_value = encoder_model.predict(input_seq)
# 生成一个size=1的空序列
target_seq = np.zeros((1, 1, num_decoder_tokens))
# 将这个空序列的内容设置为开始字符
target_seq[0, 0, target_token_index['\t']] = 1.
# 进行字符恢复
# 简单起见,假设batch_size = 1
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
# print(output_tokens)这里输出的是下个字符出现的位置的概率
# 对下个字符采样 sampled_token_index是要预测下个字符最大概率出现在字典中的位置
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# 退出条件:生成 \n 或者 超过最大序列长度
if sampled_char == '\n' or len(decoded_sentence) >INUPT_LENGTH :
stop_condition = True
# 更新target_seq
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# 更新中间状态
states_value = [h, c]
return decoded_sentence
四、训练模型
model,encoder_model,decoder_model=create_model()
#编译模型
model.compile(optimizer='rmsprop',loss='categorical_crossentropy')
#训练模型
model.fit([encoder_input_data,decoder_input_data],decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
#训练不错的模型为了以后测试可是保存
model.save('s2s.h5')
encoder_model.save('encoder_model.h5')
decoder_model.save('decoder_model.h5')
五、展示
if __name__ == '__main__':
intro=input("select train model or test model:")
if intro=="train":
print("训练模式...........")
train()
else:
print("测试模式.........")
while(1):
test()




训练数据用了3000组 ,大部分是比较短的词组或者单词。效果不能算是太好,但是比起英语渣渣还算可以吧。

Reference:
https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
https://towardsdatascience.com/neural-machine-translation-using-seq2seq-with-keras-c23540453c74