Java学到什么程度才能叫精通?
全文分为:基础知识和进阶知识
下文java必会知识附答案!并为大家整理了一个pdf,所有的知识点和答案都在pdf里面。
必会知识点及其答案!!!
Java基础知识(*)
Spring Boot 启动 流程(*)
Spring 一些面试题(*)
匿名内部类编译class(*)
为什么集合类没有实现Cloneable和Serializable接口?
自动装箱原理
final关键字
基于Redis的分布式锁
数据库分布式锁
防备DDOS攻击(*)
什么时候Mysql调用行锁?(*)
CMS,G1(*)
内部类,外部类互访(*)
设计模式(*) 熟背单例模式和工厂模式,会写适配器和建造者也行
深拷贝,浅拷贝(*)
泛型擦除
Java 8 Stream, 函数编程
中断线程
Lock,tryLock,lockInterruptibly区别
JUC
NIO
Start和run区别(*)
jvm内存屏障
Java构造器能被重载,但是不能被重写(*)
HttpSession
Thread类的方法
String是值类型,还是引用类型(*)
Redis 实现消息队列
minor gc full gc 区别(*)
Java如何查看死锁
c3p0,dbcp与druid
Spring Bean 生命周期(*)
Spring的BeanFactory和ApplicationContext的区别?
Java 如何有效地避免OOM:善于利用软引用和弱引用
分布式数据库主键生成策略(*)
String底层(*)
count(1)、count(*)与count(列名)的执行区别
主键,唯一索引区别
- 1)主键一定会创建一个唯一索引,但是有唯一索引的列不一定是主键;
- 2)主键不允许为空值,唯一索引列允许空值;
- 3)一个表只能有一个主键,但是可以有多个唯一索引;
- 4)主键可以被其他表引用为外键,唯一索引列不可以;
- 5)主键是一种约束,而唯一索引是一种索引,是表的冗余数据结构,两者有本质的差别
死锁 产生死锁的四个必要条件:
- 互斥条件:一个资源每次只能被一个进程使用。
- 占有且等待:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不可强行占有:进程已获得的资源,在末使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
避免死锁: https://segmentfault.com/a/1190000000378725
- 确保所有的线程都是按照相同的顺序获得锁,那么死锁就不会发生.
- 另外一个可以避免死锁的方法是在尝试获取锁的时候加一个超时时间,这也就意味着在尝试获取锁的过程中若超过了这个时限该线程则放弃对该锁请求。若一个线程没有在给定的时限内成功获得所有需要的锁,则会进行回退并释放所有已经获得的锁,然后等待一段随机的时间再重试。
- 死锁检测是一个更好的死锁预防机制,它主要是针对那些不可能实现按序加锁并且锁超时也不可行的场景。
乐观锁,悲观锁(*)
公平锁、非公平锁
- 公平锁(Fair):加锁前检查是否有排队等待的线程,优先排队等待的线程,先来先得 非公平锁(Nonfair):加锁时不考虑排队等待问题,直接尝试获取锁,获取不到自动到队尾等待 非公平锁性能比公平锁高5~10倍,因为公平锁需要在多核的情况下维护一个队列 Java中的ReentrantLock 默认的lock()方法采用的是非公平锁。
OOM分析
JVM调优参数 知道-Xms,-Xmx,-XX:NewRatio=n,会算就行,笔试题考过
堆设置
- -Xms:初始堆大小 -Xmx:最大堆大小 -XX:NewSize=n:设置年轻代大小 -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5 -XX:MaxPermSize=n:设置持久代大小
收集器设置
- -XX:+UseSerialGC:设置串行收集器 -XX:+UseParallelGC:设置并行收集器 -XX:+UseParalledlOldGC:设置并行年老代收集器 -XX:+UseConcMarkSweepGC:设置并发收集器
垃圾回收统计信息
- -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:filename
并行收集器设置
- -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。 -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间 -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
- -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。 -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
调优总结 年轻代大小选择
- 响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
年老代大小选择
- 响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得: 并发垃圾收集信息 持久代并发收集次数 传统GC信息 花在年轻代和年老代回收上的时间比例 减少年轻代和年老代花费的时间,一般会提高应用的效率 吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
较小堆引起的碎片问题
- 因为年老代的并发收集器使用标记、清除算法,所以不会对堆进行压缩。当收集器回收时,他会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间较小时,运行一段时间以后,就会出现“碎片”,如果并发收集器找不到足够的空间,那么并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出现“碎片”,可能需要进行如下配置: -XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。 -XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
synchronized实现原理(*)
- https://blog.csdn.net/javazejian/article/details/72828483
- 内存对象头, Mark Word保存锁信息
- JVM层:Monitor对象,字节码中的monitorenter 和 monitorexit 指令
- 无锁,偏向锁,轻量级锁(自选),重量级锁
- 可重入
- notify/notifyAll和wait方法,在使用这3个方法时,必须处于synchronized代码块或者synchronized方法中,否则就会抛出IllegalMonitorStateException异常,这是因为调用这几个方法前必须拿到当前对象的监视器monitor对象,也就是说notify/notifyAll和wait方法依赖于monitor对象,在前面的分析中,我们知道monitor 存在于对象头的Mark Word 中(存储monitor引用指针),而synchronized关键字可以获取 monitor ,这也就是为什么notify/notifyAll和wait方法必须在synchronized代码块或者synchronized方法调用的原因.
synchronized, lock区别(*)
Spring容器中Bean的作用域(*) 当通过Spring容器创建一个Bean实例时,不仅可以完成Bean实例的实例化,还可以为Bean指定特定的作用域。Spring支持如下5种作用域:
- singleton:单例模式,在整个Spring IoC容器中,使用singleton定义的Bean将只有一个实例
- prototype:原型模式,每次通过容器的getBean方法获取prototype定义的Bean时,都将产生一个新的Bean实例
- request:对于每次HTTP请求,使用request定义的Bean都将产生一个新实例,即每次HTTP请求将会产生不同的Bean实例。只有在Web应用中使用Spring时,该作用域才有效
- session:对于每次HTTP Session,使用session定义的Bean产生一个新实例。同样只有在Web应用中使用Spring时,该作用域才有效
- globalsession:每个全局的HTTP Session,使用session定义的Bean都将产生一个新实例。典型情况下,仅在使用portlet context的时候有效。同样只有在Web应用中使用Spring时,该作用域才有效 其中比较常用的是singleton和prototype两种作用域。对于singleton作用域的Bean,每次请求该Bean都将获得相同的实例。容器负责跟踪Bean实例的状态,负责维护Bean实例的生命周期行为;如果一个Bean被设置成prototype作用域,程序每次请求该id的Bean,Spring都会新建一个Bean实例,然后返回给程序。在这种情况下,Spring容器仅仅使用new 关键字创建Bean实例,一旦创建成功,容器不在跟踪实例,也不会维护Bean实例的状态。 如果不指定Bean的作用域,Spring默认使用singleton作用域。Java在创建Java实例时,需要进行内存申请;销毁实例时,需要完成垃圾回收,这些工作都会导致系统开销的增加。因此,prototype作用域Bean的创建、销毁代价比较大。而singleton作用域的Bean实例一旦创建成功,可以重复使用。因此,除非必要,否则尽量避免将Bean被设置成prototype作用域。
Spring IOC实现原理, 相关知识(*)
Spring 启动时读取应用程序提供的Bean配置信息,并在Spring容器中生成一份相应的Bean配置注册表,然后根据这张注册表实例化Bean,装配好Bean之间的依赖关系,为上层应用提供准备就绪的运行环境。
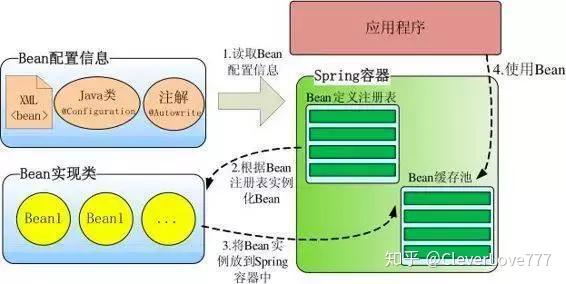
Bean缓存池:HashMap实现
Spring 通过一个配置文件描述 Bean 及 Bean 之间的依赖关系,利用 Java 语言的反射功能实例化 Bean 并建立 Bean 之间的依赖关系。 Spring 的 IoC 容器在完成这些底层工作的基础上,还提供了 Bean 实例缓存、生命周期管理、 Bean 实例代理、事件发布、资源装载等高级服务。
BeanFactory 是 Spring 框架的基础设施,面向 Spring 本身;
ApplicationContext 面向使用 Spring 框架的开发者,几乎所有的应用场合我们都直接使用 ApplicationContext 而非底层的 BeanFactory。
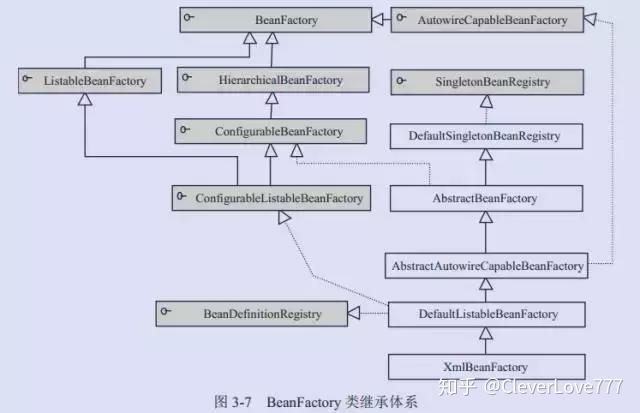
BeanDefinitionRegistry: Spring 配置文件中每一个节点元素在 Spring 容器里都通过一个 BeanDefinition 对象表示,它描述了 Bean 的配置信息。而 BeanDefinitionRegistry 接口提供了向容器手工注册 BeanDefinition 对象的方法。
BeanFactory 接口位于类结构树的顶端 ,它最主要的方法就是 getBean(String beanName),该方法从容器中返回特定名称的 Bean,BeanFactory 的功能通过其他的接口得到不断扩展:
ListableBeanFactory:该接口定义了访问容器中 Bean 基本信息的若干方法,如查看Bean 的个数、获取某一类型 Bean 的配置名、查看容器中是否包括某一 Bean 等方法;
HierarchicalBeanFactory:父子级联 IoC 容器的接口,子容器可以通过接口方法访问父容器; 通过 HierarchicalBeanFactory 接口, Spring 的 IoC 容器可以建立父子层级关联的容器体系,子容器可以访问父容器中的 Bean,但父容器不能访问子容器的 Bean。Spring 使用父子容器实现了很多功能,比如在 Spring MVC 中,展现层 Bean 位于一个子容器中,而业务层和持久层的 Bean 位于父容器中。这样,展现层 Bean 就可以引用业务层和持久层的 Bean,而业务层和持久层的 Bean 则看不到展现层的 Bean。
ConfigurableBeanFactory:是一个重要的接口,增强了 IoC 容器的可定制性,它定义了设置类装载器、属性编辑器、容器初始化后置处理器等方法;
AutowireCapableBeanFactory:定义了将容器中的 Bean 按某种规则(如按名字匹配、按类型匹配等)进行自动装配的方法;
SingletonBeanRegistry:定义了允许在运行期间向容器注册单实例 Bean 的方法;
@Bean, @Component 区别
- Componet 一般放在类上面,Bean放在方法上面,自己可控制是否生成bean. bean 一般会放在classpath scanning路径下面,会自动生成bean. 有Componet /bean生成的bean都提供给autowire使用.
- 在@Component中(@Component标注的类,包括@Service,@Repository, @Controller)使用@Bean注解和在@Configuration中使用是不同的。在@Component类中使用方法或字段时不会使用CGLIB增强(及不使用代理类:调用任何方法,使用任何变量,拿到的是原始对象,后面会有例子解释)。而在@Configuration类中使用方法或字段时则使用CGLIB创造协作对象(及使用代理:拿到的是代理对象);当调用@Bean注解的方法时它不是普通的Java语义,而是从容器中拿到的由Spring生命周期管理、被Spring代理甚至依赖于其他Bean的对象引用。在@Component中调用@Bean注解的方法和字段则是普通的Java语义,不经过CGLIB处理。
如何停止线程?
- 主线程提供volatile boolean flag, 线程内while判断flag
- 线程内while(!this.isInterrupted), 主线程里调用interrupt
- if(this.isInterrupted) throw new InterruptedException() 或return,主线程里调用interrupt
- 将一个线程设置为守护线程后,当进程中没有非守护线程后,守护线程自动结束
多线程实现方式?(*)
- extends Thread
- implements Runnable
- implements Callable, 重写call, 返回future (主线程可以用线程池submit)
线程池(*) 线程池处理过程:
- 如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(注意,执行这一步骤需要获取全局锁)。
- 如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue。
- 如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(注意,执行这一步骤需要获取全局锁)。
- 如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
四种线程池:
- CachedThreadPool
- FixedThreadPool
- ScheduledThreadPool
- SingleThreadExecutor
创建线程池的参数:
- corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
- runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列。 ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序。 LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。 SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于Linked-BlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。 PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
- maximumPoolSize(线程池最大数量):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。
- ThreadFactory:用于设置创建线程的工厂
- RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。在JDK 1.5中Java线程池框架提供了以下4种策略。 AbortPolicy:直接抛出异常。 CallerRunsPolicy:只用调用者所在线程来运行任务。 DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。 DiscardPolicy:不处理,丢弃掉。
**ArrayList,LinkedList **
- ArrayList初始化可以指定大小,知道大小的建议指定 arraylist添加元素的时候,需要判断存放元素的数组是否需要扩容(扩容大小是原来大小的1/2+1)
- LinkedList添加、删除元素通过移动指针 LinkedList遍历比arraylist慢,建议用迭代器
- ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。 对于随机访问get和set,ArrayList优于LinkedList,因为ArrayList可以随机定位,而LinkedList要移动指针一步一步的移动到节点处。(参考数组与链表来思考)
- 对于新增和删除操作add和remove,LinedList比较占优势,只需要对指针进行修改即可,而ArrayList要移动数据来填补被删除的对象的空间。
HashMap原理(*)
- HashMap最多只允许一条Entry的键为Null(多条会覆盖),但允许多条Entry的值为Null
- HashSet 本身就是在 HashMa