一、绪论
- 什么是数据挖掘
就是通过算法从大量的数据中搜索隐藏在其中的信息。
- 数据挖掘的基本任务
聚类分析、异常检测、关联分析和预测建模
- 高维性和维灾难
随着维度的增加计算复杂度也随之增加。
二、数据
- 不同的属性类型
标称:例如,邮政编码。定性数据
序数:矿石的硬度,街道的号码,定性数据
区间:日历日期,摄氏温度,定量数据
比率:绝对温度,年龄,电流。定量数据
- 什么是维度
是数据集中对象具有的属性数目
- 精度
同一个量重复测量值之间的接近程度
- 准确率
被测量的测量值和实际值之间的接近度
- 离群点
某种意义上具有不同数据集中的其他大部分数据对象的特征的数据对象,或者相对于该属性的典型值来说不寻常的属性值,我们也称为异常。
- 维规约
就是降低维度
维灾难是指随着数据维度的增加,许多数据分析变得越来越困难,特别是随着数据的增加,数据在它所占据的空间越来越稀疏。
- 特征子集选择:如果说数据的一个属性对于要预测的属性没有太大的用处的话,我们可以选择将这个属性去除。
- 数据离散化和多元化及其原因
在数据挖掘中的某些分类算法中,要求数据是分类属性形式。发现关联模式的算法,要求数据是二元属性形式。这样需要将连续属性变换成分类属性(离散化),并且连续属性和离散属性有时候可能都需要变换成一个或者多个二元属性(多元化)。
- 欧几里得距离
对应坐标数据的差的平方之和,再开根号。
四和五、分类
-
什么叫分类
分类的任务就是通过学习得到一个目标函数,分类之前必须要有分类的准则。
-
预测性建模
用于预测未知记录的类标号。在预测之前首先要建立相应的数学模型。
-
混淆矩阵
共有150个样本数据,预测为1、2、3类各50个。
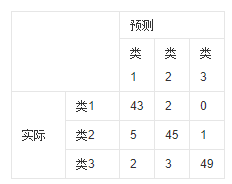
每一行中的数据加起来表示类别真实样本数量,每一列加起来表示被预测的样本数量。
举个例子,43表示预测为类1的50个样本中实际属于类1的样本数位43个。
-
准确率和错误率
正确率:正确预测数和预测总数的比值
错误率:错误预测数和预测总数的比值
-
决策树归纳的设计问题
如何分裂训练记录
如何停止分裂记录
-
决策树算法-计算题-课本P97页
信息熵和信息增益的计算
决策树算法只产生二元划分
-
分类和聚类的区别和联系
-
监督学习和非监督学习的区别和联系
-
过分拟合中的训练误差和泛化误差
-
过分拟合、导致过分拟合的原因以及如何消减过分拟合
-
训练集、检验集和测试集
-
如何处理过分拟合
先剪枝
后剪枝
子树提升
子树替换
-
分类规则的质量可以用覆盖率和准确率来度量。
准确率
覆盖率
-
基于规则分类器所产生的规则的两个重要性质
互斥规则
穷举规则
-
了解基于规则的排序方案和基于类的排序方案的区别
-
重点朴素贝叶斯–课本P141
-
装袋、提升和随机森林
-
不平衡问题中的召回率和精度
-
ROC曲线
六、关联分析
- 支持度和置信度
- 关联规则挖掘任务中的频繁项集的产生和规则的产生
- Apriori算法
最小支持度
七、聚类分析
- 聚类分析的基本概念
- 不同的聚类类型
划分聚类
层次聚类
- 不同的簇类型
- k均值-计算质心
- 二分k均值
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)