1 离散控制与连续控制
之前的无论是DQN,Q-learning,A2C,REINFORCEMENT,SARSA什么的,都是针对离散动作空间,不能直接解决连续控制问题。
考虑这样一个问题:我们需要控制一只机械手臂,完成某些任务,获取奖励。机械 手臂有两个关节,分别可以在 [0◦, 360◦] 与 [0◦, 180◦] 的范围内转动。这个问题的自由度 是 d = 2,动作是二维向量,动作空间是连续集合 A = [0, 360] × [0, 180]。
如果想把此前学过的离散控制方法应用到连续控制上,必须要对连续动作空间做离散化(网格化)。
比如把连续集合 A = [0, 360] × [0, 180] 变成离散集合 A′ = {0, 20, 40, · · · , 360} × {0, 20, 40, · · · , 180};
-
对动作空间做离散化之后,就可以应用之前学过的方法训练 DQN 或者策略网络,用 于控制机械手臂
-
可是用离散化解决连续控制问题有个缺点。
-
把自由度记作 d。自由度 d 越大,网格上的点就越多,而且数量随着 d 指数增长,会造成维度灾难。
-
动作空间的 大小即网格上点的数量。如果动作空间太大,DQN 和策略网络的训练都变得很困难,强 化学习的结果会不好。
- ——>上述离散化方法只适用于自由度 d 很小的情况;如果 d 不是很小, 就应该使用连续控制方法。
2 确定策略梯度
确定策略梯度 (Deterministic Policy Gradient, DPG))
是最常用的连续控制方法。
DPG是一种 Actor-Critic
方法,它有一个策略网络(演员),一个价值网络(评委)。
策略网络控制智能体做运动,它基于状态 s
做出动作
a
。
价值网络基于状态
s
给动作
a
打分,从而指导策略网络做出改进。

2.1 确定性策略网络
- 这里的策略网络和之前DQN,A2C的策略网络略有不同:
actor-critic中的策略网络:
2.2 价值网络
价值网络同样是对动作价值函数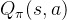 的近似,但形式上也有不同:
的近似,但形式上也有不同:

actor-critic中的价值网络: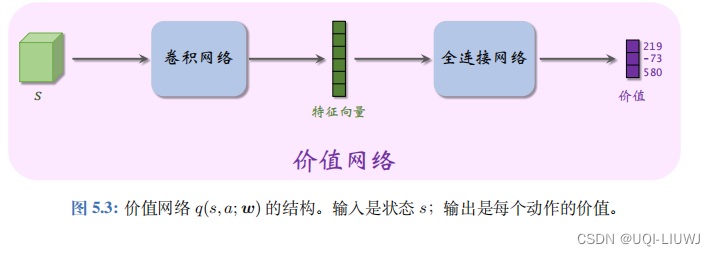
3 算法推导
DPG可以看作一种异策略(off-policy)的方法。
我们把agent的轨迹整理成 的四元组。
的四元组。
训练的时候,随机取一组四元组,其中训练策略网络μ(s;θ)的时候,只用到状态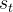 ;训练价值网络q(s,a;w)的时候,需要用到四元组中的所有元素
;训练价值网络q(s,a;w)的时候,需要用到四元组中的所有元素

这里的ε指的是噪声
3.1 训练策略网络

- 给定状态s,策略网络会输出动作 a=μ(s;θ)
- 然后价值网络会根据s和a打一个分数q(s,a;w)
- 参数θ影响a,进而影响q
- 训练策略网络的时候,如果当前状态是s,那么策略网络会输出动作μ(s,θ)
- 那么此时价值网络的打分就是

- 我们希望打分的期望越高越好,所以此时目标函数定义为打分的期望:

我们用梯度上升来增大J(θ),每一次用随机变量S的一组观测值来计算梯度

- gj是
 的无偏估计,叫做确定策略梯度(DPG deterministic policy gradient)
的无偏估计,叫做确定策略梯度(DPG deterministic policy gradient)
这里我们是
所以使用链式法则 求出gj:
求出gj:
3.2 训练价值网络
价值网络的目的是为了让q(s,a;w)的预测接近于真实价值函数
同样地,我们使用TD来训练价值网络
4 整体训练流程
记当前策略网络和价值网络的参数为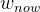 ,
,
- 1 从经验回放数组中取出一个四元组
- 2 让策略网络做预测

- 注意!!!
- 计算动作
 使用的是当前的策略网络
使用的是当前的策略网络 ,用 来更新
,用 来更新
- 而从经验回放中得到的aj则是用过时的策略网络
 算出来的,它是用来更新
算出来的,它是用来更新
- ——>诠释了DPG是一个异策略的网络
- 3 让价值网络做预测(注意什么地方用aj,什么地方用)

- 4 计算TD目标和TD误差

- 5 更新价值网络 (注意什么地方用aj,什么地方用)

- 6 更新策略网络 (注意什么地方用aj,什么地方用)
