在我上一篇博客文章https://blog.csdn.net/gzroy/article/details/119509552中对21点的策略进行了研究,采用蒙特卡洛的方式来进行多次的模拟,通过对比不同策略的收益来找到最佳的策略,主要是通过概率的思想来进行研究。
这里我打算换一种思路,采用强化学习的回合更新的方法来进行研究。首先我们先简单介绍一下强化学习的基本的一些概念。
强化学习的回合更新算法
21点游戏里面的每一局都可以看做一个回合,可以看做一个Markov决策过程,也就是奖励 和状态
和状态 只依赖于当前的状态
只依赖于当前的状态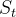 和动作
和动作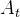 。在21点游戏的轨迹(即每一局游戏)中,每一步的状态都是不同的,即牌的总点数总是变化的,因此在同一回合中的每个状态都是首次访问,不再需要区分是首次还是每次访问。在一个轨迹中,只有最后的一个奖励值是非零值,对于回合制任务可以设置折扣因子γ=1,最后的奖励值就是回合的总奖励值。
。在21点游戏的轨迹(即每一局游戏)中,每一步的状态都是不同的,即牌的总点数总是变化的,因此在同一回合中的每个状态都是首次访问,不再需要区分是首次还是每次访问。在一个轨迹中,只有最后的一个奖励值是非零值,对于回合制任务可以设置折扣因子γ=1,最后的奖励值就是回合的总奖励值。
回合更新分为同策和异策回合更新两类,同策学习是边决策边学习,学习者同时也是决策者。异策学习是通过之前的历史来学习,学习者和决策者可以不同。
对于同策最优策略的求解,可以用带起始探索的同策回合更新算法,或者基于柔性策略的同策回合更新算法,这样可以避免在寻找最优策略的过程中落入局部最优的情况。这里我采用基于柔性策略的同策回合更新算法。
令S表示状态空间,A表示动作空间,R表示奖励,则一个回合内的轨迹可以表示为 ,这里T表示回合的终止时刻。
,这里T表示回合的终止时刻。
强化学习的目标是最大化长期的奖励,我们可以定义在回合制任务中,从步骤t(t<T)以后的回报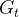 可以定义为未来奖励之和,其中
可以定义为未来奖励之和,其中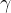 表示折扣率:
表示折扣率:

有了回报之后,我们可以进一步定义价值函数。对于给定的策略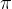 ,状态价值函数
,状态价值函数 表示从状态s开始采用策略的预期回报:
表示从状态s开始采用策略的预期回报:
![v_{\pi}(s)=E_{\pi}[G_{t}|S_{t}=s]](https://latex.csdn.net/eq?v_%7B%5Cpi%7D%28s%29%3DE_%7B%5Cpi%7D%5BG_%7Bt%7D%7CS_%7Bt%7D%3Ds%5D)
动作价值函数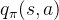 表示在状态s采取动作a后,采用策略的预期回报:
表示在状态s采取动作a后,采用策略的预期回报:
![q_{\pi}(s,a)=E_{\pi}[G_{t}|S_{t}=s, A_{t}=a]](https://latex.csdn.net/eq?q_%7B%5Cpi%7D%28s%2Ca%29%3DE_%7B%5Cpi%7D%5BG_%7Bt%7D%7CS_%7Bt%7D%3Ds%2C%20A_%7Bt%7D%3Da%5D)
状态价值函数和动作价值函数可以互相表示,用t时刻的动作价值函数表示t时刻的状态价值函数:

我们的目的是找到最优的策略 ,使得对于任意的
,使得对于任意的 或者
或者 ,这个策略的价值函数的值都比其他策略的价值函数的值要大,我们称为最优价值函数,包括以下两种:
,这个策略的价值函数的值都比其他策略的价值函数的值要大,我们称为最优价值函数,包括以下两种:
最优状态价值函数

最优动作价值函数

要寻找最优策略,有带起始探索的回合更新以及基于柔性策略的回合更新两种方法。其中带起始探索的方法在实际应用中会有一些限制,因为其要求能指定任何一个状态为回合的开始状态,这在很多环境下是无法满足的,这里我们将采用柔性策略的方法。
柔性策略的定义是,对于某个策略π,如果对于任意的 均有
均有 ,也就是说对于任意一个状态,都可以选择所有可能的动作。所以从一个状态出发可以到达这个状态所能达到的所有状态和所有状态动作对。通常会定义
,也就是说对于任意一个状态,都可以选择所有可能的动作。所以从一个状态出发可以到达这个状态所能达到的所有状态和所有状态动作对。通常会定义 为一个概率值,平均分配到各个动作上,将剩下的(1-)概率分配给动作
为一个概率值,平均分配到各个动作上,将剩下的(1-)概率分配给动作 ,即:
,即:

基于柔性策略的每次访问同策回合更新算法如下所示:
1. 初始化动作价值估计q(s,a) 任意值,初始化计数器c(s,a)0,初始化策略为任意柔性策略
任意值,初始化计数器c(s,a)0,初始化策略为任意柔性策略
2. 对每个回合执行以下操作:
2.1 用策略生成轨迹
2.2 初始化回报G0
2.3 对tT-1, T-2,...,0:
2.3.1 更新回报
2.3.2 更新 以减小
以减小![\left [ G-q(S_{t},A_{t}) \right ]^{2}](https://latex.csdn.net/eq?%5Cleft%20%5B%20G-q%28S_%7Bt%7D%2CA_%7Bt%7D%29%20%5Cright%20%5D%5E%7B2%7D) ,如
,如 ,
,![q(S_{t},A_{t})\leftarrow q(S_{t},A_{t})+\frac{1}{c(S_{t},A_{t})}\left [ G-q(S_{t},A_{t}) \right ]](https://latex.csdn.net/eq?q%28S_%7Bt%7D%2CA_%7Bt%7D%29%5Cleftarrow%20q%28S_%7Bt%7D%2CA_%7Bt%7D%29+%5Cfrac%7B1%7D%7Bc%28S_%7Bt%7D%2CA_%7Bt%7D%29%7D%5Cleft%20%5B%20G-q%28S_%7Bt%7D%2CA_%7Bt%7D%29%20%5Cright%20%5D)
2.3.3  ,更新策略
,更新策略 为柔性策略,如
为柔性策略,如
对以上算法中的关键步骤的解释如下:
2.3.1是采用逆序的方式来更新回报。
2.3.2是采用增量法来对状态动作价值函数进行更新,目的是使得状态动作价值函数的值更接近回报。原理是如果之前已经观测到 这个状态动作对出现了c-1次,对应的回报为
这个状态动作对出现了c-1次,对应的回报为 ,则可以认为
,则可以认为 的估计值为
的估计值为 ,当第c次观察到的回报为
,当第c次观察到的回报为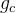 ,则前c次的价值函数的估计值为
,则前c次的价值函数的估计值为 ,可以得出
,可以得出 ,推导过程如下:
,推导过程如下:

换另一个角度,以机器学习的思维来理解,回报类似于我们的学习目标,更新价值函数使得loss值![[G-q(S_{t},A_{t})]^{2}](https://latex.csdn.net/eq?%5Cinline%20%5BG-q%28S_%7Bt%7D%2CA_%7Bt%7D%29%5D%5E%7B2%7D) 不断减小,这个loss值的负梯度就是
不断减小,这个loss值的负梯度就是 ,所以每次更新就是
,所以每次更新就是 ,
, 是学习率
是学习率
2.3.3更新了状态动作价值函数之后,我们就知道了 状态时采取哪个动作能令价值函数取得最大值,从而进一步去更新策略。
状态时采取哪个动作能令价值函数取得最大值,从而进一步去更新策略。
代码实现
首先我们需要先配置一个实验的环境,这里采用了Gym库的环境"Blackjack-v0"来进行模拟。以下代码是建立环境并用随机策略玩一个回合的代码。
import gym
import numpy as np
env = gym.make("Blackjack-v0")
observation = env.reset()
print('Obervation={}'.format(observation))
while True:
print('Player={}, Dealer={}'.format(env.player, env.dealer))
action = np.random.choice(env.action_space.n)
print('Action={}'.format(action))
observation, reward, done, _ = env.step(action)
print('Observation={}, Reward={}, Done={}'.format(observation, reward, done))
if done:
break
在以上代码中, env.reset表示初始化环境,env.action_space.n对应的是action,0表示停牌,1表示要牌。env.step(action)表示执行一步,并返回对环境的观测,奖励,以及是否回合结束。如以上代码执行后的一个输出如下:
Obervation=(7, 10, False)
Player=[2, 5], Dealer=[10, 10]
Action=0
Observation=(7, 10, False), Reward=-1.0, Done=True
初始化之后玩家的两张牌的点数之和为7,庄家的一张牌的点数10(另一张牌也是10点,但是在环境的观测中没有显示,这个可以通过下一行的输出看到),False表示玩家的两张牌里面并没有A计算为11点。然后随机选取的Action=0,即停牌,这时庄家开牌,庄家20点,玩家输,因此奖励为-1.0,Done为True
接下来的代码是基于柔性策略的同策回合更新来求解最优价值函数,代码如下:
def ob2state(observation):
return(observation[0], observation[1], int(observation[2]))
def monte_carlo_with_soft(env, episode_num=500000, epsilon=0.1):
policy = np.ones((22, 11, 2, 2))*0.5
q = np.zeros_like(policy)
c = np.zeros_like(policy)
for _ in range(episode_num):
state_actions = []
observation = env.reset()
while True:
state = ob2state(observation)
action = np.random.choice(env.action_space.n, p=policy[state])
state_actions.append((state, action))
observation, reward, done, _ = env.step(action)
if done:
break
g = reward
for state, action in state_actions:
c[state][action] += 1.
q[state][action] += (g-q[state][action])/c[state][action]
a = q[state].argmax()
policy[state] = epsilon/2.
policy[state][a] += (1.-epsilon)
return policy, q
在以上代码中,policy被初始化为一个4维数组,第一维表示玩家手牌的点数1-21(0和1实际没有用到),第二维表示庄家手牌点数,第三维表示玩家手牌是否有A计算为11点,第四维是玩家要采取的动作(0-停牌,1-要牌)。这个数组所有元素的值初始化为0.5(表示柔性策略)。因为对于21点来说只有回合结束才有非零值的奖励,所以我们就不需要逆序来求各个时间点的回报了。在每个回合中需要记录每个状态动作对的出现次数,并更新起对应的价值函数的值。之后求价值函数每个状态对应哪个动作可以取得最大值,并更新改状态动作对的概率和其他状态动作对的概率。
我们可以运行以下代码来获得最优策略的结果并展示出来:
p,q = monte_carlo_with_soft(env)
blackjack_policy = {}
for i in range(4, 20):
blackjack_policy[str(i)] = []
for j in range(2, 11):
if p[i,j,0,0]<p[i,j,0,1]:
blackjack_policy[str(i)].append('H')
else:
blackjack_policy[str(i)].append('S')
if p[i,1,0,0]<p[i,1,0,1]:
blackjack_policy[str(i)].append('H')
else:
blackjack_policy[str(i)].append('S')
for i in range(13, 20):
key = 'A,'+str(i-11)
blackjack_policy[key] = []
for j in range(2, 11):
if p[i,j,1,0]<p[i,j,1,1]:
blackjack_policy[key].append('H')
else:
blackjack_policy[key].append('S')
if p[i,1,1,0]<p[i,1,1,1]:
blackjack_policy[key].append('H')
else:
blackjack_policy[key].append('S')
with open('blackjack_policy.csv', 'w') as f:
result = 'Player;2;3;4;5;6;7;8;9;10;A\n'
for key in blackjack_policy:
result += (key+';'+';'.join(blackjack_policy[key])+'\n')
f.write(result)
df = pd.read_csv('blackjack_policy.csv', header=0, index_col=0, sep=';')
df.head(100)
用pandas dataframe展示结果如下:
| Player |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
A |
| 4 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 5 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 6 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 7 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 8 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 9 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 10 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 11 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 12 |
H |
S |
H |
S |
S |
H |
H |
H |
H |
H |
| 13 |
S |
S |
S |
S |
S |
H |
H |
H |
H |
H |
| 14 |
S |
S |
S |
S |
S |
H |
H |
H |
H |
H |
| 15 |
S |
S |
S |
S |
S |
H |
H |
H |
H |
H |
| 16 |
S |
S |
S |
S |
S |
H |
H |
S |
S |
H |
| 17 |
S |
S |
S |
S |
S |
S |
S |
S |
S |
S |
| 18 |
S |
S |
S |
S |
S |
S |
S |
S |
S |
S |
| 19 |
S |
S |
S |
S |
S |
S |
S |
S |
S |
S |
| A,2 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,3 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,4 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,5 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,6 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,7 |
S |
S |
S |
S |
S |
S |
S |
H |
H |
H |
| A,8 |
S |
S |
S |
S |
S |
S |
S |
S |
S |
S |
可以看到这个策略和我之前博客里面研究得出的最优策略是比较类似的,但是里面缺少加倍这种策略,因为在Gym的环境里面只有停牌和要牌两种策略。 这里我们可以做一些改进,即通过状态动作价值函数的值来判断是否加倍,停牌或者要牌。如果价值函数的值是正值,那么对应的状态动作是加倍,否则就是停牌或要牌(取决于哪个动作对应的值较大),改进后的代码如下:
blackjack_policy = {}
for i in range(4, 20):
blackjack_policy[str(i)] = []
for j in range(2, 11):
if q[i,j,0,0]<q[i,j,0,1]:
if q[i,j,0,1]>0:
blackjack_policy[str(i)].append('D')
else:
blackjack_policy[str(i)].append('H')
else:
blackjack_policy[str(i)].append('S')
if q[i,1,0,0]<q[i,1,0,1]:
if q[i,j,0,1]>0:
blackjack_policy[str(i)].append('D')
else:
blackjack_policy[str(i)].append('H')
else:
blackjack_policy[str(i)].append('S')
for i in range(13, 21):
key = 'A,'+str(i-11)
blackjack_policy[key] = []
for j in range(2, 11):
if q[i,j,1,0]<q[i,j,1,1]:
if q[i,j,0,1]>0:
blackjack_policy[key].append('D')
else:
blackjack_policy[key].append('H')
else:
blackjack_policy[key].append('S')
if q[i,1,1,0]<q[i,1,1,1]:
if q[i,j,0,1]>0:
blackjack_policy[key].append('D')
else:
blackjack_policy[key].append('H')
else:
blackjack_policy[key].append('S')
with open('blackjack_enhanced_policy.csv', 'w') as f:
result = 'Player;2;3;4;5;6;7;8;9;10;A\n'
for key in blackjack_policy:
result += (key+';'+';'.join(blackjack_policy[key])+'\n')
f.write(result)
df = pd.read_csv('blackjack_enhanced_policy.csv', header=0, index_col=0, sep=';')
df.head(100)
结果如下:
| Player |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
A |
| 4 |
H |
H |
H |
H |
D |
H |
H |
H |
H |
H |
| 5 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 6 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 7 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| 8 |
H |
H |
D |
D |
D |
D |
H |
H |
H |
H |
| 9 |
D |
D |
D |
D |
D |
D |
D |
H |
H |
H |
| 10 |
D |
D |
D |
D |
D |
D |
D |
D |
H |
H |
| 11 |
D |
D |
D |
D |
D |
D |
D |
D |
D |
D |
| 12 |
H |
S |
H |
S |
S |
H |
H |
H |
H |
H |
| 13 |
S |
S |
S |
S |
S |
H |
H |
H |
H |
H |
| 14 |
S |
S |
S |
S |
S |
H |
H |
H |
H |
H |
| 15 |
S |
S |
S |
S |
S |
H |
H |
H |
H |
H |
| 16 |
S |
S |
S |
S |
S |
H |
H |
S |
S |
H |
| 17 |
S |
S |
S |
S |
S |
S |
S |
S |
S |
S |
| 18 |
S |
S |
S |
S |
S |
S |
S |
S |
S |
S |
| 19 |
S |
S |
S |
S |
S |
S |
S |
S |
S |
S |
| A,2 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,3 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,4 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,5 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,6 |
H |
H |
H |
H |
H |
H |
H |
H |
H |
H |
| A,7 |
S |
S |
S |
S |
S |
S |
S |
H |
H |
H |
| A,8 |
S |
S |
S |
S |
S |
S |
S |
S |
S |
S |
| A,9 |
S |
S |
S |
S |
S |
S |
S |
S |
S |
S |
可以看到以上结果有所改进,更加接近真实的最优策略。
除此之外在21点游戏中,如果玩家的头两张牌是相同的,玩家还可以选择分牌的策略,但是在目前的Gym的环境中是没有这个动作的,因此暂时无法模拟这种动作。可以考虑以后对Gym的环境做进一步的改进。